
Corso
Progettazione di database
4 h
126.2K
Quando ho incontrato per la prima volta il data modeling, mi è sembrato solo un altro passaggio tecnico nel lavoro con i database. Ma approfondendo, ho capito quanto sia essenziale per garantire che i dati siano ben strutturati, facilmente accessibili e pronti per l’analisi. Senza un modello dati solido, anche i database più potenti possono diventare difficili da gestire, causando inefficienze e incoerenze.
Che tu stia progettando un database da zero o perfezionando un sistema esistente, capire il data modeling è la chiave per far lavorare i dati a tuo favore.
In questo post, esploreremo le tecniche fondamentali di data modeling, le best practice e esempi reali per aiutarti a costruire modelli efficaci!
Il data modeling è un processo dettagliato che prevede la creazione di una rappresentazione visiva dei dati e delle loro relazioni. Funziona come un blueprint di come i dati sono strutturati, archiviati e accessibili per garantire coerenza e chiarezza nella data management.
Definire gli elementi dei dati e le loro relazioni aiuta i team a organizzare le informazioni per supportare archiviazione, recupero e analisi efficienti, migliorando sia le prestazioni sia il processo decisionale.
Esistono tre principali tipi di modelli dati. Esploriamoli in questa sezione.
Un modello concettuale offre una vista di alto livello dei dati. Definisce le principali entità di business (ad esempio clienti, prodotti e ordini) e le loro relazioni senza entrare nei dettagli tecnici.
Il modello logico definisce come saranno strutturati i dati. Si concentra sull’organizzazione dei dati senza essere legato a uno specifico database o tecnologia. Include informazioni dettagliate su attributi, relazioni e vincoli dei dati, fungendo così da ponte tra i requisiti di business e l’implementazione fisica dei dati.
Un modello dati fisico rappresenta come i dati sono effettivamente archiviati in un database. Definisce le specifiche strutture delle tabelle, gli indici e i meccanismi di storage necessari per ottimizzare le prestazioni e garantire l’integrità dei dati. Traduce il design logico in un formato adatto ai sistemi di database.
Il data modeling non è un processo unico per tutti. Si utilizzano tecniche diverse a seconda della complessità dei dati e degli obiettivi. In questa sezione, esploreremo alcuni degli approcci più diffusi.
L’ER modeling è una delle tecniche più comuni per rappresentare i dati. Si concentra sulla definizione di tre elementi chiave:
Il modello ER offre una rappresentazione visiva chiara di come sono strutturati i dati per aiutare a mappare le connessioni tra i diversi punti dati.
Considera un negozio online. Potresti avere le seguenti entità:
Customer_ID, Name ed Email)Order_ID, Order_Date, Total_Amount)Product_ID, Product_Name, Price)Le relazioni potrebbero essere:
Ecco come appare l’ER:
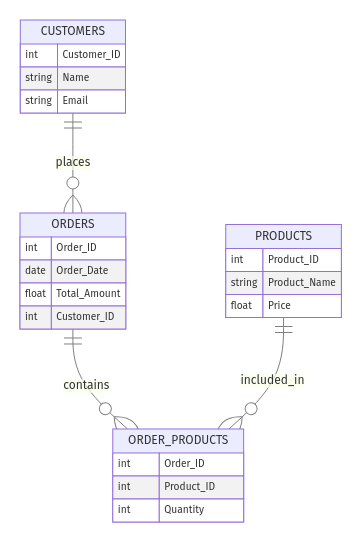
Esempio di modello ER per un e-commerce. Immagine dell’autore
Il modeling dimensionale è ampiamente utilizzato nel data warehousing e nell’analisi, dove i dati sono spesso rappresentati in termini di fatti e dimensioni. Questa tecnica semplifica i dati complessi organizzandoli in uno schema a stella o a fiocco di neve, favorendo interrogazioni e report efficienti.
Immagina di dover analizzare i dati di vendita. Li struttureresti così:
Sales (memorizza i dati transazionali, ad es. Sales_ID, Revenue, Quantity_Sold)Time (ad es., Date, Month, Year)Product (ad es., Product_ID, Category, Brand)Customer (ad es., Customer_ID, Location, Segment)In uno schema a stella, la tabella dei fatti Sales si collega direttamente alle tabelle dimensionali, consentendo agli analisti di generare con efficienza report come il fatturato totale per mese o i prodotti più venduti per categoria. Ecco come appare lo schema:
Esempio di schema a stella per la reportistica sulle vendite. Immagine dell’autore
💡 Vuoi approfondire il modeling dimensionale? Dai un’occhiata alla nostra guida Star Schema vs. Snowflake Schema per capire quando usare l’uno o l’altro per prestazioni ottimali.
Il modeling orientato agli oggetti è usato per rappresentare sistemi complessi, in cui dati e funzioni che vi operano sono incapsulati come oggetti. Questa tecnica è utile per modellare applicazioni con dati e comportamenti complessi e interrelati, soprattutto nell’ingegneria del software e nella programmazione.
Supponiamo che tu stia progettando un sistema di gestione di una biblioteca. Potresti definire oggetti come:
Title, Author, ISBN, Status)Name, Membership_ID, Checked_Out_Books)Name, Employee_ID, Role)Ogni oggetto include sia attributi (campi dati) sia metodi (funzioni). Ad esempio, un oggetto Book potrebbe avere un metodo .check_out() che aggiorna lo stato del libro quando è preso in prestito.
Questo approccio è particolarmente utile nei linguaggi di programmazione OOP come Java e Python, dove i modelli dati possono essere mappati direttamente a classi e oggetti.
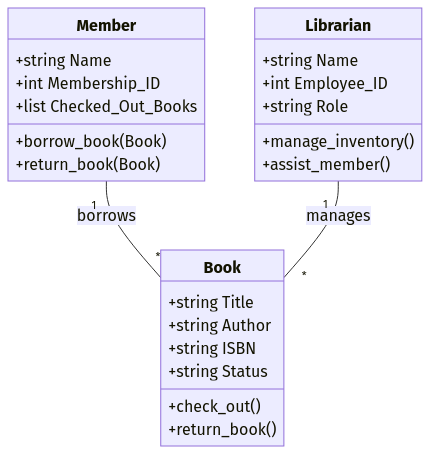
Esempio di modello dati orientato agli oggetti. Immagine dell’autore
💡 Vuoi imparare a implementare la programmazione orientata agli oggetti in Python? Dai un’occhiata al corso di DataCamp Object-Oriented Programming in Python per padroneggiare e applicare i concetti OOP in progetti reali.
NoSQL e le tecniche di modeling basate su documenti sono progettate per database flessibili e senza schema.
Questa tecnica è spesso usata quando le strutture dei dati sono meno rigide o evolvono nel tempo. Questi modelli consentono di archiviare e gestire dati non strutturati o semi-strutturati, come documenti JSON, senza schemi predefiniti.
Nei database NoSQL come MongoDB, un modello basato su documenti organizza i dati in raccolte di documenti, dove ogni documento può avere una struttura unica. Questa flessibilità consente iterazioni e scalabilità più rapide, in particolare in ambienti big data o in applicazioni che richiedono accesso ai dati ad alta velocità.
In un database relazionale, i profili utente potrebbero essere distribuiti su più tabelle. Ma in un modello basato su documenti NoSQL come MongoDB, i dati di un utente possono essere archiviati in un singolo documento simile a JSON:
{
"user_id": 123,
"name": "Alice Smith",
"email": "alice@example.com",
"address": {
"street": "123 Main St",
"city": "New York",
"zip": "10001"
},
"purchases": [
{ "product_id": 101, "price": 19.99 },
{ "product_id": 202, "price": 49.99 }
]
}Ogni tecnica di data modeling si allinea a diverse fasi della progettazione del database, dalla pianificazione di alto livello all’implementazione fisica. Ecco come si collegano ai tipi visti in precedenza nell’articolo:
Scopri di più sul data engineering con questi corsi!
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

