
Curso
Diseño de bases de datos
4 h
124.2K
Cuando conocí el modelado de datos, me pareció un paso técnico más en el trabajo con bases de datos. Pero a medida que lo exploraba más, me di cuenta de lo esencial que es para garantizar que los datos estén bien estructurados, sean fácilmente accesibles y estén listos para el análisis. Sin un modelo de datos sólido, incluso las bases de datos más potentes pueden resultar difíciles de gestionar, lo que provoca ineficacias e incoherencias.
Tanto si estás diseñando una base de datos desde cero como perfeccionando un sistema existente, comprender el modelado de datos es clave para hacer que los datos trabajen para ti.
En este post, exploraremos las técnicas fundamentales de modelado de datos, las mejores prácticas y ejemplos del mundo real para ayudarte a construir modelos eficaces.
El modelado de datos es un proceso detallado que consiste en crear una representación visual de los datos y sus relaciones. Sirve como modelo de cómo se estructuran, almacenan y acceden a los datos para garantizar su coherencia y claridad en la gestión de datos.
Definir los elementos de los datos y sus relaciones ayuda a los equipos a organizar la información para que el almacenamiento, la recuperación y el análisis sean eficaces, mejorando tanto el rendimiento como la toma de decisiones.
Hay tres tipos principales de modelos de datos. Explorémoslos en esta sección.
Un modelo conceptual proporciona una visión de alto nivel de los datos. Este modelo define las entidades empresariales clave (por ejemplo, clientes, productos y pedidos) y sus relaciones, sin entrar en detalles técnicos.
El modelo lógico define cómo se estructurarán los datos. Este modelo se centra en la organización de los datos sin estar vinculado a ninguna base de datos o tecnología específica. Incluye información detallada sobre los atributos, relaciones y restricciones de los datos, ofreciendo así un puente entre los requisitos empresariales y la implementación física de los datos.
Un modelo físico de datos representa cómo se almacenan realmente los datos en una base de datos. Este modelo define las estructuras específicas de las tablas, los índices y los mecanismos de almacenamiento necesarios para optimizar el rendimiento y garantizar la integridad de los datos. Traduce el diseño lógico a un formato adecuado para los sistemas de bases de datos.
El modelado de datos no es un proceso único. Se emplean distintas técnicas según la complejidad de los datos y los objetivos. En esta sección, exploraremos algunos de los enfoques de modelado de datos más populares.
El modelado ER es una de las técnicas más utilizadas para representar datos. Se trata de definir tres elementos clave:
El modelo ER proporciona una representación clara y visual de cómo están estructurados los datos para ayudar a trazar las conexiones entre los distintos puntos de datos.
Piensa en una tienda online. Podrías tener las siguientes entidades:
Customer_ID, Name, y Email)Order_ID, Order_Date, Total_Amount)Product_ID, Product_Name, Price)Las relaciones podrían ser:
Este es el aspecto de la ERD:
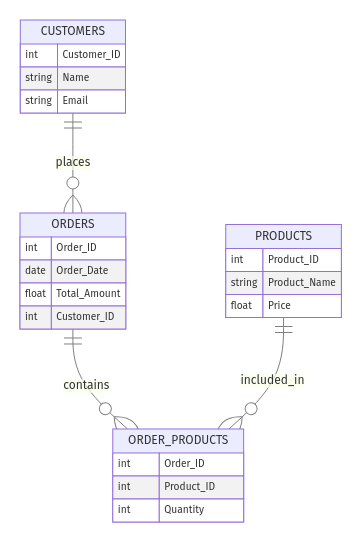
Ejemplo de modelo ER para una tienda de comercio electrónico. Imagen del autor
El modelado dimensional se utiliza ampliamente en el almacenamiento de datos y la analítica, donde los datos suelen representarse en términos de hechos y dimensiones. Esta técnica simplifica los datos complejos organizándolos en un esquema de estrella o copo de nieve, que ayuda a realizar consultas e informes eficientes.
Imagina que necesitas analizar datos de ventas. Lo estructurarías de la siguiente manera:
Sales (almacena datos transaccionales, por ejemplo, Sales_ID, Revenue, Quantity_Sold)Time (por ejemplo, Date, Month, Year)Product (por ejemplo, ID_producto, Categoría, Marca)Customer (por ejemplo, Customer_ID, Location, Segment)En un esquema en estrella, la tabla de hechos Sales enlaza directamente con las tablas de dimensiones, lo que permite a los analistas generar con eficacia informes como los ingresos totales por mes o los productos más vendidos por categoría. Este es el aspecto del esquema:
Ejemplo de esquema estrella para informes de ventas. Imagen del autor
💡 ¿Quieres profundizar en el modelado dimensional de datos? Consulta nuestra página Esquema Estrella vs. Esquema Estrella. Guía Snowflake Schema para saber cuándo utilizar cada uno de ellos para un rendimiento óptimo.
El modelado orientado a objetos se utiliza para representar sistemas complejos, en los que los datos y las funciones que operan sobre ellos se encapsulan como objetos. Esta técnica es útil para modelar aplicaciones con datos y comportamientos complejos e interrelacionados, especialmente en ingeniería y programación de software.
Supón que estás diseñando un sistema de gestión de bibliotecas. Podrías definir objetos como
Title, Author, ISBN, Status)Name, Membership_ID, Checked_Out_Books)Name, Employee_ID, Role)Cada objeto incluye tanto atributos (campos de datos) como métodos (funciones). Por ejemplo, un objeto Book puede tener un método .check_out() que actualiza el estado del libro cuando está prestado.
Este enfoque es especialmente beneficioso en lenguajes de programación orientada a objetos (POO) como Java y Python, donde los modelos de datos se pueden asignar directamente a clases y objetos.
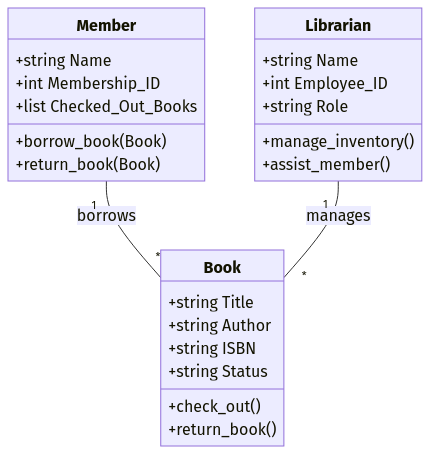
Ejemplo de modelo de datos orientado a objetos. Imagen del autor
💡 ¿Quieres aprender a aplicar la programación orientada a objetos en Python? Echa un vistazo al curso de Programación Orientada a Objetos en Python de DataCamp para dominar y aplicar los conceptos de POO en proyectos del mundo real.
Las técnicas de modelado NoSQL y basadas en documentos están diseñadas para bases de datos flexibles y sin esquema.
Esta técnica suele utilizarse cuando las estructuras de datos son menos rígidas o evolucionan con el tiempo. Estos modelos permiten almacenar y gestionar datos no estructurados o semiestructurados, como documentos JSON, sin esquemas predefinidos.
En las bases de datos NoSQL como MongoDB, un modelo basado en documentos organiza los datos en colecciones de documentos, donde cada documento puede tener una estructura única. Esta flexibilidad permite una iteración y un escalado más rápidos, sobre todo en entornos de big data o aplicaciones que requieren un acceso a los datos de alta velocidad.
En una base de datos relacional, los perfiles de usuario pueden almacenarse en varias tablas. Pero en un modelo NoSQL basado en documentos como MongoDB, los datos de un usuario pueden almacenarse en un único documento de tipo JSON:
{
"user_id": 123,
"name": "Alice Smith",
"email": "alice@example.com",
"address": {
"street": "123 Main St",
"city": "New York",
"zip": "10001"
},
"purchases": [
{ "product_id": 101, "price": 19.99 },
{ "product_id": 202, "price": 49.99 }
]
}Cada técnica de modelado de datos se alinea con diferentes etapas del diseño de la base de datos, desde la planificación de alto nivel hasta la implementación física. He aquí cómo se relacionan con los tipos que vimos anteriormente en el artículo:
¡Aprende más sobre ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Tim Lu
12 min
blog
Matt Crabtree
10 min
blog
Javier Canales Luna
12 min
blog
Matt Crabtree
15 min
Tutorial
Joleen Bothma
Tutorial
Kurtis Pykes



