
Kurs
Veri Mühendisliğini Anlamak
2 sa
362K
Snowflake’teki temel kavramlarla ilgili temel mülakat sorularıyla başlayalım.
Snowflake, işlemi depolamadan ayıran bulut tabanlı bir veri ambarı platformudur; bu sayede kullanıcılar işlem kaynaklarını ve veri depolamayı birbirinden bağımsız ölçekleyebilir. Bu yaklaşım daha maliyet-etkin olup yüksek performans sağlar.
Başlıca özelliklerden biri, iş yükü talebine göre kaynakların ayarlanmasını sağlayan ve çoklu bulut ortamlarını destekleyen otomatik ölçeklendirmedir. Bir diğer temel özellik, veri paylaşımına platform yaklaşımıdır; bu sayede kuruluş genelinde veriye erişim herhangi bir veri taşımaya gerek kalmadan güvenli ve kolay hale gelir.
Snowflake’in mimarisi, onu öne çıkaran en önemli noktadır. Bulut için tasarlanmıştır; çoklu küme, paylaşımlı veri mimarisi ve etkileyici depolama yetenekleri gibi özelliklere sahiptir. Snowflake mimarisi üç katmana ayrılır:
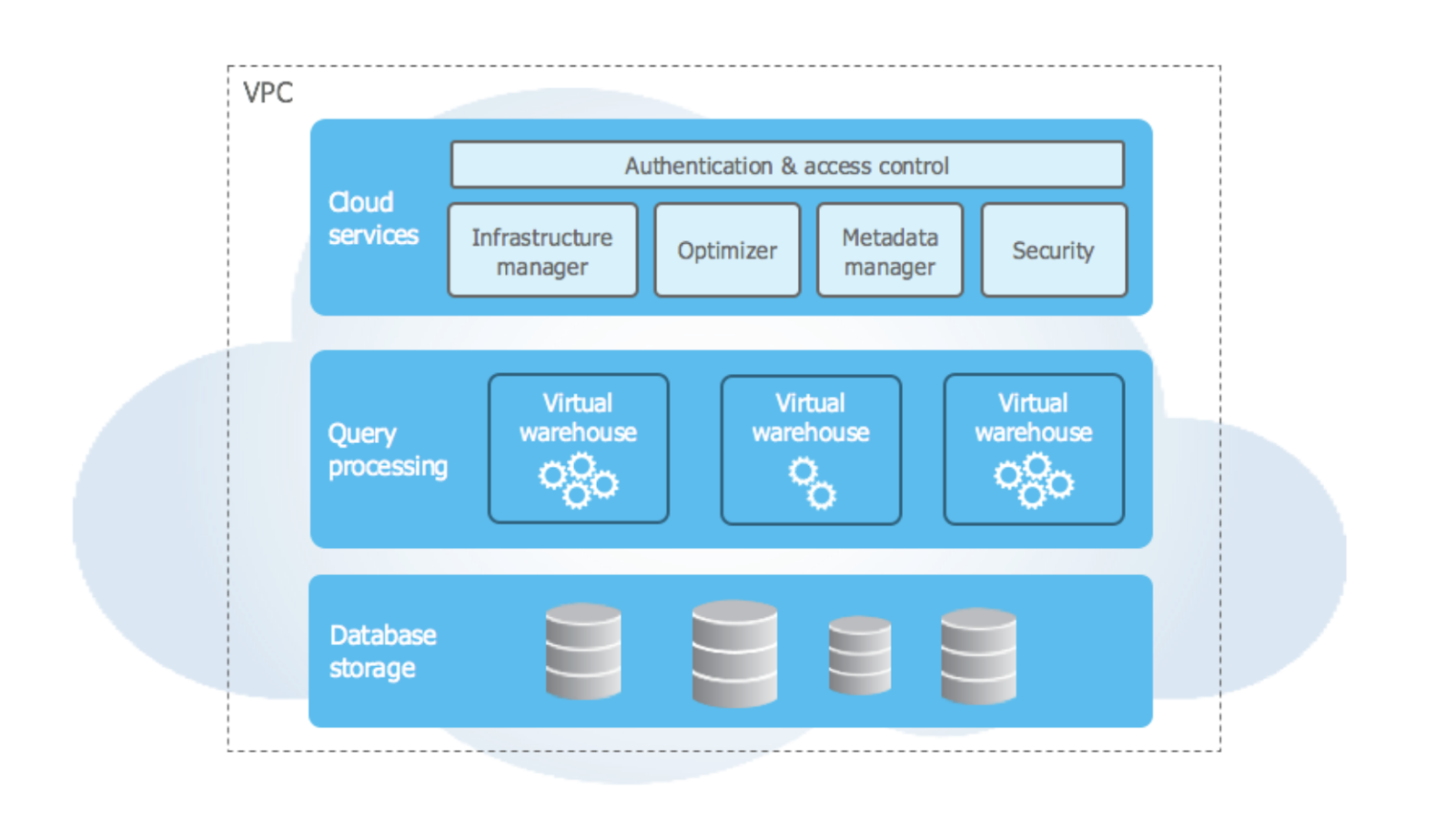
Snowflake’in üst düzey mimarisi. Görsel kaynağı: Snowflake dokümantasyonu.
Mikro-bölümler, Snowflake’in veri depolama yaklaşımının temel bir unsurudur. Snowflake’in 50 MB ile 150 MB arasında değişen verileri saklamak için kullandığı sıkıştırılmış, yönetilen ve kolonsal depolama birimleridir. Kolonsal biçim, verimli veri sıkıştırma ve kodlama şemaları sağlar.
Mikro-bölümlerin veriyi sıkıştırma yeteneği, gereken fiziksel depolama alanını azaltarak depolama maliyetlerini düşürür ve büyük veri hacimlerinin verimli yönetilmesini sağlar. Sorgu performansı da, ilgili mikro-bölümlere erişilmesini içeren veri budama (data pruning) sayesinde iyileşir. Bu seçici erişim yaklaşımı, veri geri getirme ve analitik için oldukça avantajlıdır.
Mikro-bölümler Snowflake tarafından otomatik olarak yönetilir; bu da manuel bölümlendirme veya indeksleme ihtiyacını ortadan kaldırır, en iyi veri depolamasını sağlar ve yönetim iş gücü maliyetini düşürür.
Sanal depolar tüm veri işleme görevlerini gerçekleştirir. Bu nedenle, veri işleme görevlerinin ölçeklenebilirliği, performansı ve maliyet yönetimi üzerinde büyük etkileri vardır.
Dinamik ölçeklenebilirlik özellikleri, kullanıcıların iş yükü gereksinimlerine göre hesaplama kaynaklarını artırıp azaltmasına olanak tanır. Veri işleme talebiniz arttığında, devam eden operasyonlarınızı etkilemeden ek hesaplama kaynakları sağlayabilirsiniz.
Her sanal depo diğerini etkilemez; bu da zaman hassasiyeti olan analitik gibi belirli veri işleme görevlerinde yüksek performans ve tutarlılık sağlar. Veri işleme görevlerini yürütürken yalnızca kullandığınız hesaplama kaynakları için ödeme yaparsınız; bu da geleneksel veri ambarı çözümlerine kıyasla maliyet yönetimi avantajı sunar.
Aşağıdaki tablo, sanal depoları geleneksel hesaplama kaynaklarıyla karşılaştırır:
| Özellik | Sanal depolar (Snowflake) | Geleneksel hesaplama kaynakları |
|---|---|---|
| Ölçeklenebilirlik | Otomatik ölçeklendirme, çoklu küme; iş yükü talebine göre boyutu operasyonları etkilemeden artırıp azaltabilir. | Genellikle sabit kapasite; ölçekleme için manuel yükseltme gerekir. |
| Yalıtım | Hesaplama kümelerini yalıtır; eşzamanlı iş yükleri bağımsız çalışır. | Kaynak paylaşımı, görevler arasında sıklıkla rekabete yol açar. |
| Maliyet yönetimi | Yalnızca aktif süre için ödeme yapın; gerektiğinde ölçeklendirerek atıl maliyetleri en aza indirin. | İş yükü değişimlerinden bağımsız sabit maliyetler; atıl maliyetler daha yüksek olabilir. |
| Performans optimizasyonu | Bağımsız ölçeklendirme, belirli görevler için ayrı ayar yapmayı sağlar; zaman hassasiyeti olan sorgularda yüksek performans sürdürülür. | Ölçekleme tüm iş yüklerini eşit etkilediğinden sınırlı ayar seçenekleri. |
ANSI SQL, American National Standards Institute Structured Query Language’ın kısaltmasıdır ve ilişkisel veritabanı yönetim sistemleri için standart bir dildir.
Bu, Snowflake kullanıcılarının verileri sorgulamak için JOIN’ler gibi alışıldık SQL sözdizimini ve işlemlerini kullanabileceği anlamına gelir; bu da SQL deneyimi olan kullanıcılar için Snowflake’e geçişi kolaylaştıran bir özelliktir. ANSI SQL ile uyumluluğun bir başka getirisi de çeşitli veri türlerinin sorunsuz entegrasyonudur; kullanıcılar, verilerini önceden tanımlı bir şemaya dönüştürmeden veya yüklemeden sorgulayabilir.
Snowflake platformunu kullanma konusunda sertifika almak istiyorsanız, 2026 İçin En İyi Snowflake Sertifikasyonu Hangisi? yazımıza göz atın.
Snowflake’in Time Travel özelliği, kullanıcılara hesap türüne bağlı olarak genellikle 90 güne kadar belirli bir süre için geçmiş verilere erişme ve bu verileri sorgulama imkânı verir. Bu özellik, veri kurtarma, denetim ve veri karşılaştırma amaçları için kullanışlıdır. Örneğin, kullanıcılar yanlışlıkla silinmiş tabloları geri yükleyebilir veya önceki veri durumlarını inceleyebilir.
Time Travel, harici yedekleme ihtiyacını en aza indirir ve yerleşik veri kurtarma ile geriye dönük analiz kabiliyetleri sunarak sürümlemeyi basitleştirir.
Snowflake’in veri paylaşımı özelliği, kuruluşların harici kullanıcılar veya ortaklarla canlı veriyi güvenli ve gerçek zamanlı olarak, ek veri kopyaları üretmeden paylaşmasına olanak tanır. Bu, Snowflake’in Çoklu Küme, Paylaşımlı Veri mimarisinden yararlanan Secure Data Sharing işleviyle, veriye doğrudan erişim sağlayarak gerçekleştirilir.
Veri paylaşımının avantajları şunlardır:
Zero-copy cloning, altta yatan depolamayı çoğaltmadan bir veritabanının, şemanın veya tablonun kopyasını oluşturmayı sağlayan bir Snowflake özelliğidir. Sıfır kopya klon oluşturulduğunda, özgün veriye işaret eder ve yalnızca klonlanmış veride yapılan değişiklikleri saklar; bu da önemli depolama tasarrufu sağlar. Bu özellik, geliştirme ve test ortamları yaratmak veya depolama maliyetlerini artırmadan geçmiş anlık görüntüler üretmek için değerlidir. Farklı kullanım senaryolarında hızlı ve maliyet-etkin veri çoğaltma imkânı sunarak veri yönetimi verimliliğini artırır.
Temel sorularda kendinize güveniyor musunuz? Hadi biraz daha ileri düzey sorulara geçelim.
Snowflake, her zaman açık şifreleme sürecini uygulayarak kullanıcılarına en yüksek düzeyde veri koruması ve güvenlik sağlamayı hedefler. Bu, verinin kullanıcılar tarafından herhangi bir ayar veya yapılandırma gerekmeksizin otomatik olarak şifrelenmesidir; ham veriden meta verilere kadar tüm veri türleri güçlü bir şifreleme algoritmasıyla korunur. Şifreleme, bir ana anahtarın diğer anahtarları şifrelediği hiyerarşik bir anahtar modeliyle yönetilir ve Snowflake güvenliği artırmak için bu anahtarları döndürür.
Veri aktarımında, Snowflake istemciler ile Snowflake arasında taşınan veriyi şifrelemek için TLS (Transport Layer Security) kullanır. Uçtan uca bu şifreleme, verinin yaşam döngüsünün her aşamasında şifreli kalmasını sağlayarak veri sızıntısı ve ihlali riskini azaltır.
Extract, Transform, Load (ETL) ve Extract, Load, Transform (ELT) süreçleri, Snowflake platformunda mimarisi ve yetenekleri nedeniyle yaygın şekilde kullanılır. Platform, kullanıcıların geniş kapsamlı veri entegrasyonu ve dönüşüm ihtiyaçlarına cevap vererek kuruluşların veri işleme iş akışlarını daha etkili biçimde optimize etmesini sağlar.
ETL’de veri, çeşitli kaynaklardan çıkarılır ve veri ambarına yüklenmeden önce kullanıcının istediği formata dönüştürülür. Snowflake, veri yüklendikten sonra SQL sorguları kullanarak karmaşık dönüşümlere izin veren güçlü bir SQL motorudur.
ELT’de veri, önce ham hâliyle veri ambarına yüklenir ve dönüşüm daha sonra ambar içinde gerçekleştirilir. Snowflake’in hesaplama ve depolamayı ayırma özelliği, ham verinin veri ambarına hızlıca yüklenmesini sağlar. Veri dönüşümleri sanal depolar kullanılarak yapılır. Snowflake, JSON ve XML gibi yarı yapılandırılmış veri biçimlerini de destekler; bu da ham verinin dönüşüme gerek kalmadan veri ambarına yüklenmesini kolaylaştırır.
Snowflake, kuruluşların veri entegrasyonu ve dönüşüm görevlerinde tercih ettikleri araçları kullanmalarına olanak tanıyan çeşitli ETL araçlarını destekler. Aşağıdaki araçlar, veriyi işlemek ve daha fazla analiz için Snowflake’e taşımak amacıyla Snowflake’in bulut veri platformunda kullanılabilir:
Snowpipe, Snowflake tarafından sunulan ve dosyaları dakikalar içinde yükleyebilen sürekli veri alımı hizmetidir. Snowpipe ile veriyi küçük gruplar (mikro-batch) hâlinde yükleyebilir, böylece kuruluş genelindeki kullanıcılar veriye dakikalar içinde erişerek analizi kolaylaştırabilir.
Kullanıcılar, veri dosyalarının yerleştirileceği bulut depolama yolunu ve verinin yükleneceği hedef Snowflake tablosunu belirtir. Bu otomatik bir veri yükleme sürecidir; Snowpipe, depolama yoluna yeni dosyalar eklendiğini otomatik olarak algılar. Yeni dosyalar algılandıktan sonra Snowpipe veriyi Snowflake’e alır ve belirtilen tabloya yükler.
Gerçeğe yakın zamanlı bu süreç, verinin mümkün olan en kısa sürede erişilebilir olmasını sağlar. Snowpipe, sunucusuz bir mimaride çalışır; yani veri alım süreci için gereken hesaplama kaynaklarını otomatik olarak yönetir.
Snowpipe Streaming’in üst düzey mimarisi. Görsel kaynağı: Snowflake dokümantasyonu.
Snowflake, Çevrimiçi Analitik İşleme (OLAP) iş yükleri için optimize edilmiş bir veri ambarı çözümü olarak tasarlanmıştır. OLAP, iş verilerini farklı açılardan analiz etmek için kullanılan bir yazılım teknolojisidir. Snowflake’i “altın standart” yapan şey, mimari tasarımının ve özelliklerinin büyük ölçekli veri görevlerini, karmaşık sorguları ve daha fazlasını destekleyecek şekilde kurgulanmış olmasıdır. Snowflake’in OLAP yaklaşımının özellikleri arasında hesaplama ve depolamanın ayrılması, büyük ölçekte paralel işleme (MPP) ve verimli analitik işlemeyi mümkün kılan farklı veri yapılarının desteği bulunur.
Buna karşılık, Snowflake geleneksel olarak Çevrimiçi İşlem İşleme (OLTP) iş yükleri için tasarlanmamıştır. OLTP iş yükleri, veritabanının zaman içinde birden çok kullanıcıdan hem veri talebi hem de bu veride çok sayıda değişiklik aldığı durumlardır ve bu değişikliklere işlem (transaction) denir. Kısa süreli ve yüksek hacimli işlemler (insert ve update gibi) ile karakterizedir. Bu özellikler, Snowflake gibi veri ambarı çözümlerinden ziyade operasyonel veritabanlarına odaklanır.
Snowflake’te kümeleme, sorgu performansını optimize etmek için veriyi mikro-bölümler içinde düzenler. Varsayılan olarak Snowflake kümelemeyi otomatik yönetir; ancak doğal bir sıralamaya sahip büyük tablolar (ör. zaman serisi verileri) için manuel kümeleme faydalı olabilir.
Manuel kümeleme, sorgularda sık kullanılan sütunlar üzerinde bir küme anahtarı (cluster key) oluşturmayı içerir. Bu, Snowflake’in sorgular sırasında ilgisiz bölümleri atlamasını sağlayarak daha verimli veri budamasını mümkün kılar. Ancak manuel kümeleme, yeniden kümeleme maliyetlerinin büyük veri kümeleri için depolama ve hesaplama maliyetlerini etkileyebileceği durumlarda, performans kazanımları bu maliyetleri aştığında tercih edilmelidir.
Fail-safe, Time Travel saklama süresinin ötesinde silinmiş veya değiştirilmiş veriyi geri yüklemek için tasarlanmış bir Snowflake veri kurtarma özelliğidir. Time Travel kullanıcılara belirli bir zaman aralığında (90 güne kadar) geçmiş verilere erişim sağlarken, fail-safe Time Travel’dan sonraki yedi günlük bir dönemdir ve Snowflake bu süre boyunca veriyi yalnızca felaket kurtarma için saklar.
Time Travel’ın aksine, fail-safe verisine kullanıcılar doğrudan erişemez; Snowflake Support müdahalesi gerekir.
Fail-safe, ek bir veri koruma katmanı sağlar; ancak daha yüksek maliyetlidir ve Time Travel sonrası son çare olarak kullanılmalıdır.
Snowflake’te maddileştirilmiş görünümler bir sorgunun sonuçlarını fiziksel olarak saklar; bu da karmaşık veya sık kullanılan sorgular için daha hızlı geri getirime olanak tanır. Her sorgulandığında yeniden hesaplanan standart görünümlerin aksine, maddileştirilmiş görünümler veri güncellenene kadar sonuç kümesini korur. Bu, özellikle büyük tabloları içeren analitik iş yüklerinde sorgu performansını önemli ölçüde artırabilir.
Maddileştirilmiş görünümler için kullanım alanları arasında raporlama panoları ve verinin seyrek değiştiği toplulaştırılmış sorgu sonuçları yer alır. Ancak maddileştirilmiş görünümler periyodik bakım gerektirir ve depolama maliyetini artırabilir; bu nedenle statik veya yavaş değişen veri kümeleri için daha uygundur.
Aşağıda Snowflake’te standart görünümler ile maddileştirilmiş görünümlerin kullanım alanlarını karşılaştıran bir tablo yer almaktadır:
| Boyut | Standart görünümler | Maddileştirilmiş görünümler |
|---|---|---|
| Veri depolama | Fiziksel depolama yok; görünümler sorgu anında hesaplanır | Sorgu sonuçlarını fiziksel olarak saklar; sorgu hızını artırır |
| Performans | Daha küçük, seyrek sorgular için uygundur | Sık sorgulanan büyük veya karmaşık veri kümeleri için idealdir |
| Bakım maliyeti | Depolama gerekmediğinden asgari | Depolama ve periyodik yenileme gereksinimleri nedeniyle daha yüksek |
| Kullanım alanları | Ad-hoc sorgular ve veri keşfi | Raporlama panoları, önceden hesaplanmış toplamlar |
Snowflake’in benzersiz mimarisine dayanarak, her yönünü bilmeniz ve bilginizi sınamanız gerekir.
Paylaşımlı disk ve paylaşımsız mimariler, veritabanı ve veri ambarı tasarımında iki farklı yaklaşımdır. İkisi arasındaki temel fark, bir sistemdeki birden çok düğüm (node) arasında verinin depolanması ve işlenmesinin nasıl yönetildiğidir.
Paylaşımlı disk mimarisinde, sistemdeki düğümler disk depolamaya erişir; yani sistemdeki herhangi bir düğüm, bu sistemdeki herhangi bir diske okuma/yazma yapabilir. Bu, tek bir düğümün arızalanmasının veri kaybı veya erişilemezliğe yol açmaması nedeniyle yüksek erişilebilirlik sağlar. Ayrıca verinin düğümler arasında bölümlenmesi veya çoğaltılması gerekmediğinden veri yönetimini basitleştirir.
Buna karşılık paylaşımsız mimaride, sistemdeki her düğüm diğerleriyle paylaşmadığı kendine ait özel depolamaya sahiptir. Veri düğümler arasında bölümlenir; yani her düğüm verinin bir alt kümesinden sorumludur. Bu, her biri kendi depolamasına sahip daha fazla düğüm ekleme olanağı sunduğundan ölçeklenebilirlik sağlar ve daha iyi performansa yol açar.
Veriyi Snowflake’te bir aşama alanına (stage) yüklediğinizde buna ‘Staging’ denir. Dış aşamalandırma (external staging), verinin başka bir bulut bölgesinde tutulması; iç aşamalandırma (internal staging) ise verinin Snowflake içinde tutulmasıdır. İç aşamalandırma Snowflake ortamına entegredir ve Snowflake tablolarına yüklenecek dosyaları ve verileri depolar. Snowflake platformu, yüklenmesi veya saklanması gereken verileri barındırmak için AWS, Google Cloud Platform ve Azure gibi harici depolama sağlayıcılarını kullanır.
Snowflake üç tür önbellekten oluşur. İşte bunları karşılaştıran ve her biri için bazı kullanım örneklerini vurgulayan bir tablo:
| Önbellek türü | Açıklama | Süre | Kullanım alanı |
|---|---|---|---|
| Sonuç önbelleği | Sorgu sonuçlarını tüm sanal depolar arasında önbelleğe alır; tekrarlanan sorgular sonuçları anında alabilir. | 24 saat | Aynı sonuçları üreten özdeş sorguları hızlandırma |
| Yerel disk önbelleği | Sık erişilen verileri her sanal deponun yerel diskinde saklar; sık erişilen veri için daha hızlı getirime olanak verir. | Sanal depo askıya alınana kadar | Aynı depoda tekrarlanan sorguların performansını iyileştirir |
| Uzak önbellek | Dayanıklılık için verilerin uzak disklerde uzun süreli depolanması; hizmet kesintilerinden sonra dahi veriye erişim sağlar. | Kalıcı, %99,999999999 dayanıklılık ile | Veri merkezi arızasında verinin erişilebilir ve dirençli olmasını sağlar |
Snowflake Sanal Deposunun 3 farklı durumu vardır:
Snowflake, veri dağıtımını Snowflake tarafından otomatik olarak oluşturulup yönetilen mikro-bölümler aracılığıyla gerçekleştirir. Bu mikro-bölümler, veriyi kolonsal biçimde saklayan küçük depolama birimleridir (her biri 50–150 MB).
Snowflake’in otomatik kümeleme özelliği, manuel bölümlendirme ihtiyacını en aza indirerek verimli veri dağıtımı sağlar. Mikro-bölümler, yalnızca ilgili bölümlere erişilen veri budamayı mümkün kılar ve bu da performansı artırır. Geleneksel veritabanlarının aksine, Snowflake veri bölümlendirmesini soyutlar; böylece kullanıcıların veri dağıtımını manuel olarak yönetmesi gerekmez; bu da daha iyi ölçeklenebilirlik ve kullanım kolaylığı sağlar.
İşte bu mekanizmaları karşılaştıran bir tablo:
| Mekanizma | Açıklama | Fayda |
|---|---|---|
| Mikro-bölümler | Veriyi düzenleyen ve sıkıştıran küçük, kolonsal depolama birimleri. | Veri budamayı etkinleştirir; daha hızlı sorgular için taranan veri miktarını azaltır. |
| Otomatik kümeleme | Snowflake, verideki değişikliklere uyum sağlayarak mikro-bölümler içinde kümelenmeyi otomatik sürdürür. | Veri yönetimini basitleştirir, manuel yeniden kümelemeye gerek yoktur |
| Veri budama | Yalnızca meta verilere göre ilgili mikro-bölümlere erişilir; gereksiz veri taraması en aza indirilir. | Yalnızca gerekli veriye erişerek sorgu performansını iyileştirir |
Snowflake’te Metadata Service, Bulut Hizmetleri Katmanının bir parçasıdır ve sorgu iyileştirme ile veri yönetiminde kritik rol oynar. Bu hizmet, tablolar, sütunlar ve bölümler için veri depolama konumlarını, erişim örüntülerini ve meta verileri izler. Meta verilere hızlı erişim sağlayarak sorgu yürütümü sırasında veri budamayı mümkün kılar; bu da taranan veri miktarını azaltır ve performansı artırır.
Ayrıca Metadata Service, Sonuç Önbelleğini yönetir ve günceller; böylece kısa süre içinde benzer sorgular çalıştırıldığında daha hızlı geri getirime olanak tanır. Genel olarak, Metadata Service sorgu verimliliğini artırır ve kaynak tüketimini azaltır.
Snowflake’in otomatik askıya alma ve otomatik devam özellikleri, hesaplama kaynağı kullanımını optimize eder ve maliyetleri düşürür. Bir sanal depo tanımlı bir süre boyunca boşta kalırsa, otomatik askıya alma gereksiz hesaplama ücretlerini önlemek için depoyu otomatik olarak kapatır.
Tersine, otomatik devam özelliği yeni bir sorgu alındığında depoyu otomatik olarak başlatır. Bu, kullanıcıların yalnızca depo etkin olarak sorgu işlediğinde hesaplama süresi için ödeme yapmasını sağlar.
Bu özellikler, düzensiz iş yüklerine sahip ortamlarda özellikle faydalıdır; maliyet verimliliğini en üst düzeye çıkarırken erişilebilirliği korur.
Sanal depo, web arayüzü üzerinden veya SQL kullanılarak oluşturulabilir. Üç farklı yöntem şunlardır:
CREATE [ OR REPLACE ] WAREHOUSE [ IF NOT EXISTS ] <name>
[ [ WITH ] objectProperties ]
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ objectParams ]Bir Snowflake görevi oluşturmak için “CREATE TASK” kullanmanız gerekir. Görev tanımında SQL ifadesini veya saklı yordamı (stored procedure) tanımlamalı ve görev oluşturma iznine sahip olduğunuzdan emin olmalısınız. Adımlar şunlardır:
CREATE TASK’ komutunu, görevinizin adını takip edecek şekilde kullanarak yeni bir görev oluşturun.WAREHOUSE’ ile belirtin.SCHEDULE’ içinde tanımlayın; örneğin her gün 01:00 UTC.AS’ anahtar sözcüğüyle girin.CALL’ ile belirtin.Örneğin:
CREATE TASK daily_sales_datacamp
WAREHOUSE = 'datacampwarehouse'
SCHEDULE = 'USING CRON 0 1 * * * UTC'
AS
CALL daily_sales_datacamp();Bu sorgu, Snowflake’te yarı yapılandırılmış JSON verisiyle nasıl çalışılacağını gösterir:
SELECT
feedback_details:customer_id::INT AS customer_id,
feedback_details:feedback_text::STRING AS feedback_text,
feedback_details:timestamp::TIMESTAMP AS feedback_timestamp
FROM
customer_feedback
WHERE
feedback_details:customer_id::INT = 123; -- Replace 123 with the specific customer_id you're interested inBir Snowflake görevinin geçmişini doğrulamak için ‘TASK_HISTORY’ tablo fonksiyonunu kullanabilirsiniz. Bu, belirli bir zaman aralığındaki görev yürütme geçmişi hakkında ayrıntılı bilgi verir.
SELECT *
FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY(
TASK_NAME => '<task_name>',
START_TIME => '<start_time>',
END_TIME => '<end_time>'
))
ORDER BY SCHEDULED_TIME DESC;Snowflake’te ‘CREATE TEMPORARY TABLE’ deyimini kullanmanız gerekir. Bu, kullanıcı tarafından belirlenen süre boyunca var olacak oturum-özel bir tablo oluşturur.
CREATE TEMPORARY TABLE table_name (
column_name1 data_type1,
column_name2 data_type2,
...
);Snowflake, zaman damgalarını saat dilimleri arasında dönüştürmek için CONVERT_TIMEZONE fonksiyonunu sağlar. İşte bir zaman damgasını UTC’den Doğu Standart Saati’ne (EST) dönüştürme örneği:
SELECT
customer_id,
CONVERT_TIMEZONE('UTC', 'America/New_York', order_timestamp) AS order_timestamp_est
FROM
orders;Bu sorguda, customer_id ve order_timestamp sütunlarını tablonuzdaki özel sütunlarla değiştirin. Bu fonksiyon esnek saat dilimi dönüşümleri sağlar ve küresel raporlama için idealdir.
Snowflake’te CREATE TABLE ... CLONE ifadesini kullanarak bir tablonun sıfır kopya klonunu oluşturabilirsiniz. Bu klon, aynı altta yatan depolamayı paylaşır; böylece maliyet ve depolama alanı tasarrufu sağlar.
CREATE TABLE cloned_table_name CLONE original_table_name;Örneğin, sales_data adlı bir tabloyu klonlamak için sözdizimi şöyledir:
CREATE TABLE sales_data_clone CLONE sales_data;Bu klonlanmış tablo, klonlama anındaki orijinal tabloyla aynı veri ve şemaya sahip olacaktır. Oluşturulduktan sonra klon tabloda yapılan değişiklikler orijinali etkilemez.
Belirli bir sütunda en sık görülen ilk 5 değeri getirmek için GROUP BY yan tümcesini ORDER BY ve LIMIT ile birlikte kullanabilirsiniz. Örneğin, product_id sütunundaki en yaygın 5 ürünü bulmak için:
SELECT
product_id,
COUNT(*) AS frequency
FROM
sales
GROUP BY
product_id
ORDER BY
frequency DESC
LIMIT 5;Bu sorgu, product_id sütununu sıklığa göre gruplar, azalan düzende sıralar ve sonuçları en sık satılan 5 ürünü gösterecek şekilde sınırlar.
Herhangi bir mülakata hazırlanırken aşağıdakileri yapmak önemlidir:
Son olarak, kendinize güvenin ve elinizden gelenin en iyisini yapın!
Bu yazıda 4 farklı seviyede Snowflake mülakat sorularını ele aldık:
Snowflake becerilerinizi tazelemek veya test etmek için kaynak arıyorsanız, Introduction to Snowflake ve Python ve SQL kullanarak Snowflake’te Veri Analizine Başlangıç eğitimlerimize ve ayrıca büyük veriyle çalışmak için Snowflake kullanımını da öğreneceğiniz Introduction to NoSQL kursumuza göz atın.
Ayrıca, eski Snowflake CEO’su Bob Muglia ile yaptığımız ‘Yapay Zekâ Neden Her Şeyi Değiştirecek’ başlıklı podcast bölümümüzü de dinleyin.
Snowflake Yolculuğunuza Bugün Başlayın!
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
