
Courses
Tìm hiểu Data Engineering
2 giờ
362.2K
Hãy bắt đầu với các câu hỏi cơ bản về những khái niệm then chốt trong Snowflake.
Snowflake là nền tảng kho dữ liệu đám mây tách biệt tính toán khỏi lưu trữ, cho phép người dùng mở rộng tài nguyên xử lý và lưu trữ dữ liệu một cách độc lập. Cách tiếp cận này tiết kiệm chi phí hơn và mang lại hiệu năng cao.
Một trong những tính năng chính là tự động mở rộng, cho phép điều chỉnh tài nguyên dựa trên nhu cầu tải công việc và hỗ trợ môi trường đa đám mây. Một tính năng quan trọng khác là cách tiếp cận chia sẻ dữ liệu ở cấp nền tảng, đảm bảo truy cập dữ liệu an toàn, dễ dàng trên toàn tổ chức mà không cần di chuyển dữ liệu.
Kiến trúc của Snowflake là điểm bán hàng độc đáo của nền tảng. Nó được thiết kế cho đám mây, với các đặc điểm như đa cụm, kiến trúc dữ liệu dùng chung và khả năng lưu trữ vượt trội. Kiến trúc Snowflake được chia thành ba lớp:
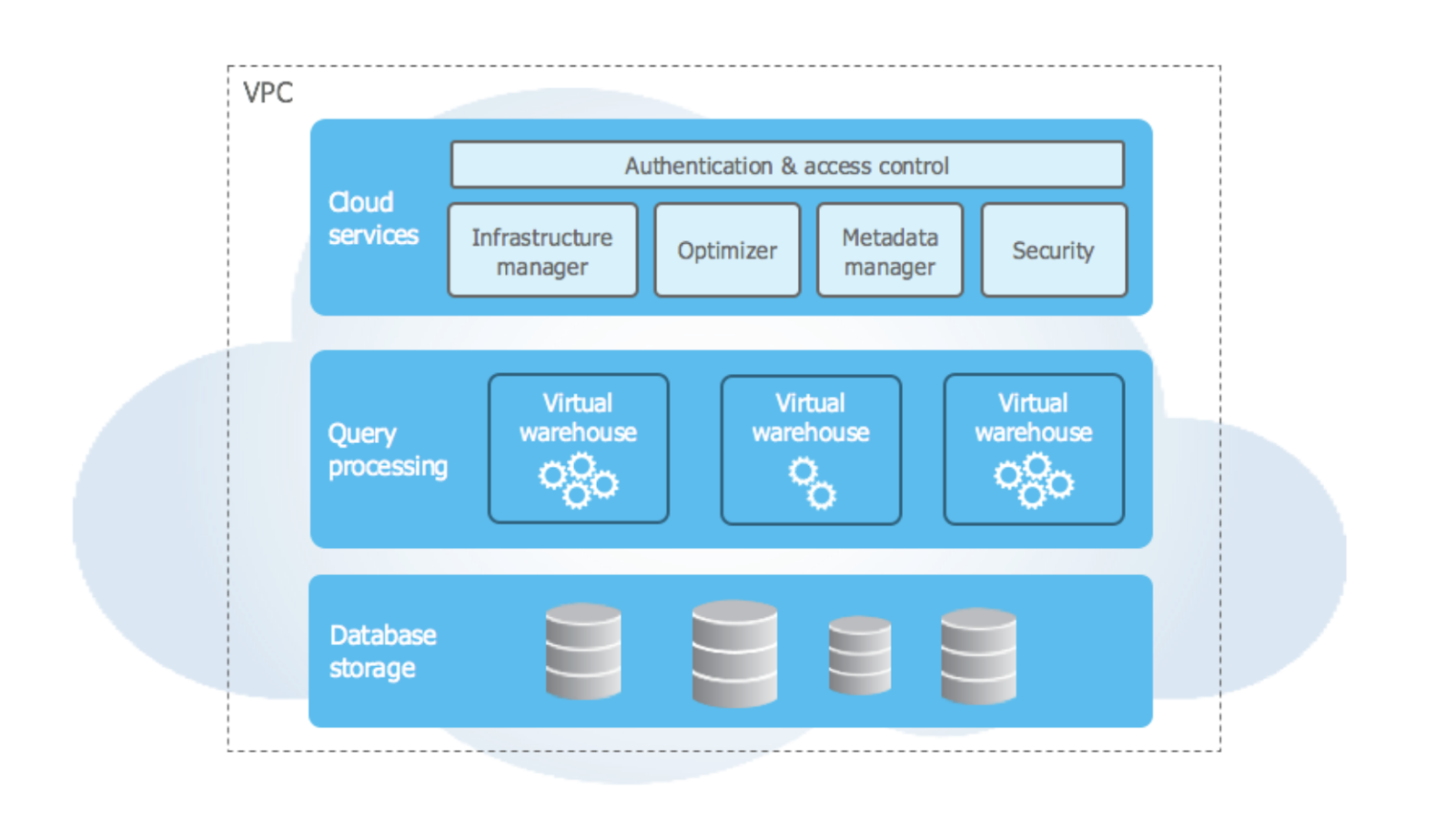
Kiến trúc cấp cao của Snowflake. Nguồn ảnh: tài liệu Snowflake.
Micro-partition là thành phần cốt lõi trong cách Snowflake lưu trữ dữ liệu. Chúng là các đơn vị lưu trữ dạng cột được nén và quản lý mà Snowflake dùng để lưu dữ liệu, kích thước trong khoảng 50MB đến 150MB. Định dạng dạng cột cho phép nén dữ liệu và các sơ đồ mã hóa hiệu quả.
Khả năng nén dữ liệu của micro-partition cho phép quản lý hiệu quả các khối dữ liệu lớn do giảm không gian lưu trữ vật lý cần thiết, từ đó giảm chi phí lưu trữ. Hiệu năng truy vấn cũng được cải thiện nhờ cắt tỉa dữ liệu, tức là chỉ truy cập các micro-partition liên quan. Cách truy cập chọn lọc này rất hữu ích cho truy xuất và phân tích dữ liệu.
Micro-partition được Snowflake quản lý tự động, loại bỏ nhu cầu phân vùng hay lập chỉ mục thủ công, đảm bảo lưu trữ tối ưu và cắt giảm chi phí quản trị.
Kho dữ liệu ảo chịu trách nhiệm thực hiện mọi tác vụ xử lý dữ liệu. Do đó, chúng tác động mạnh đến khả năng mở rộng, hiệu năng và quản lý chi phí của các tác vụ này.
Tính năng mở rộng linh hoạt cho phép người dùng tăng hoặc giảm tài nguyên tính toán dựa trên yêu cầu tải công việc. Khi nhu cầu xử lý dữ liệu tăng, bạn có thể cấp thêm tài nguyên tính toán mà không ảnh hưởng đến hoạt động đang diễn ra.
Mỗi kho dữ liệu ảo không tác động tới kho khác, cho phép hiệu năng cao và nhất quán đối với các tác vụ xử lý dữ liệu cụ thể như phân tích nhạy thời gian. Khi xử lý dữ liệu, bạn trả tiền cho tài nguyên tính toán đã dùng, nhờ đó quản lý chi phí tốt hơn so với các giải pháp kho dữ liệu truyền thống.
Bảng sau so sánh kho dữ liệu ảo với tài nguyên tính toán truyền thống:
| Tính năng | Kho dữ liệu ảo (Snowflake) | Tài nguyên tính toán truyền thống |
|---|---|---|
| Khả năng mở rộng | Tự động mở rộng, đa cụm; có thể tăng/giảm kích thước theo nhu cầu tải mà không ảnh hưởng vận hành. | Thường có dung lượng cố định, cần nâng cấp thủ công để mở rộng. |
| Cô lập | Cô lập các cụm tính toán, cho phép tải đồng thời chạy độc lập. | Chia sẻ tài nguyên thường dẫn đến cạnh tranh giữa các tác vụ. |
| Quản lý chi phí | Chỉ trả phí cho thời gian hoạt động và có thể mở rộng/thu hẹp khi cần, giảm chi phí nhàn rỗi. | Chi phí cố định bất kể thay đổi tải, có thể cao khi nhàn rỗi. |
| Tối ưu hiệu năng | Mở rộng độc lập cho phép tinh chỉnh riêng cho từng tác vụ, duy trì hiệu năng cao cho truy vấn nhạy thời gian. | Tùy chọn tinh chỉnh hạn chế, vì mở rộng ảnh hưởng đồng đều đến mọi tải. |
ANSI SQL là viết tắt của American National Standards Institute Structured Query Language, ngôn ngữ chuẩn cho các hệ quản trị cơ sở dữ liệu quan hệ.
Điều này có nghĩa người dùng Snowflake có thể dùng cú pháp và thao tác SQL quen thuộc để truy vấn dữ liệu, như các JOIN, giúp người dùng giàu kinh nghiệm SQL chuyển sang Snowflake thuận lợi. Một lợi điểm khác của việc tương thích ANSI SQL là tích hợp trơn tru nhiều kiểu dữ liệu, cho phép truy vấn dữ liệu mà không cần biến đổi hay nạp vào một lược đồ định sẵn trước.
Nếu bạn muốn lấy chứng chỉ sử dụng nền tảng Snowflake, hãy xem Chứng chỉ Snowflake tốt nhất cho năm 2026 là gì?
Tính năng Time Travel của Snowflake cho phép người dùng truy cập và truy vấn dữ liệu lịch sử trong một khoảng thời gian xác định, thường lên đến 90 ngày tùy loại tài khoản. Tính năng này hữu ích cho khôi phục dữ liệu, mục đích kiểm toán và so sánh dữ liệu. Ví dụ, người dùng có thể khôi phục bảng bị xóa nhầm hoặc xem lại trạng thái dữ liệu trước đó.
Time Travel giảm nhu cầu sao lưu bên ngoài và đơn giản hóa quản lý phiên bản dữ liệu, cung cấp sẵn khả năng khôi phục và phân tích hồi cứu.
Tính năng chia sẻ dữ liệu của Snowflake cho phép tổ chức chia sẻ dữ liệu trực tiếp, an toàn và theo thời gian thực với người dùng hoặc đối tác bên ngoài mà không tạo thêm bản sao dữ liệu. Điều này đạt được nhờ Secure Data Sharing của Snowflake, sử dụng kiến trúc đa cụm, dữ liệu dùng chung để cung cấp truy cập trực tiếp.
Ưu điểm của chia sẻ dữ liệu gồm:
Zero-copy cloning là tính năng cho phép tạo bản sao cơ sở dữ liệu, schema hoặc bảng mà không nhân đôi lớp lưu trữ bên dưới. Khi tạo bản sao zero-copy, nó trỏ tới dữ liệu gốc và chỉ lưu các thay đổi phát sinh trên bản sao, giúp tiết kiệm lưu trữ đáng kể. Tính năng này hữu ích để tạo môi trường phát triển/kiểm thử hoặc tạo ảnh chụp lịch sử mà không làm tăng chi phí lưu trữ. Nó nâng cao hiệu quả quản lý dữ liệu bằng cách cho phép nhân bản dữ liệu nhanh, tiết kiệm chi phí cho nhiều trường hợp sử dụng.
Bạn đã tự tin với các câu hỏi cơ bản? Hãy chuyển sang những câu hỏi nâng cao hơn.
Snowflake hướng tới mức độ bảo vệ và an ninh dữ liệu cao nhất cho người dùng bằng cơ chế mã hóa luôn bật. Đây là việc mã hóa dữ liệu tự động mà không cần người dùng thiết lập hay cấu hình, đảm bảo mọi loại dữ liệu từ thô đến siêu dữ liệu đều được mã hóa bằng thuật toán mạnh. Cơ chế mã hóa được quản lý theo mô hình khóa phân cấp, trong đó khóa chủ mã hóa các khóa khác và Snowflake luân phiên thay đổi khóa để tăng cường bảo mật.
Khi truyền dữ liệu, Snowflake sử dụng TLS (Transport Layer Security) để mã hóa dữ liệu đi giữa Snowflake và khách hàng. Mã hóa đầu-cuối này đảm bảo dữ liệu luôn được mã hóa ở mọi giai đoạn vòng đời, giảm nguy cơ rò rỉ và xâm phạm dữ liệu.
Extract, Transform, Load (ETL) và Extract, Load, Transform (ELT) được sử dụng rộng rãi trên Snowflake nhờ kiến trúc và khả năng của nền tảng. Nền tảng đáp ứng đa dạng nhu cầu tích hợp và biến đổi dữ liệu, cho phép tổ chức tối ưu luồng xử lý dữ liệu hiệu quả hơn.
Trong ETL, dữ liệu được trích xuất từ nhiều nguồn rồi chuyển đổi về định dạng mong muốn trước khi nạp vào kho dữ liệu. Snowflake là một công cụ SQL mạnh cho phép thực hiện các biến đổi phức tạp bằng truy vấn SQL sau khi dữ liệu được nạp.
Trong ELT, dữ liệu được nạp vào kho trước ở dạng thô rồi mới biến đổi bên trong kho. Việc tách biệt tính toán và lưu trữ của Snowflake cho phép nạp nhanh dữ liệu thô vào kho. Các biến đổi được thực thi bằng các kho dữ liệu ảo. Snowflake cũng hỗ trợ định dạng bán cấu trúc như JSON và XML, giúp nạp dữ liệu thô vào kho dễ dàng mà không cần biến đổi trước.
Snowflake hỗ trợ nhiều công cụ ETL, cho phép tổ chức sử dụng công cụ ưa thích trong tác vụ tích hợp và biến đổi dữ liệu. Các công cụ dưới đây có thể dùng trên nền tảng dữ liệu đám mây của Snowflake để xử lý và chuyển dữ liệu vào Snowflake phục vụ phân tích:
Snowpipe là dịch vụ nạp dữ liệu liên tục do Snowflake cung cấp, có thể nạp tệp trong vài phút. Với Snowpipe, bạn có thể nạp dữ liệu theo nhóm nhỏ (micro-batch), cho phép người dùng trên toàn tổ chức truy cập dữ liệu trong vài phút, giúp dữ liệu dễ phân tích hơn.
Người dùng chỉ định đường dẫn lưu trữ đám mây nơi đặt các tệp dữ liệu và bảng đích trong Snowflake nơi dữ liệu sẽ được nạp. Đây là quy trình nạp dữ liệu tự động: Snowpipe tự phát hiện khi có tệp mới thêm vào đường dẫn lưu trữ. Khi phát hiện, Snowpipe sẽ lấy dữ liệu vào Snowflake và nạp vào bảng đã chỉ định.
Quy trình gần thời gian thực này đảm bảo dữ liệu sẵn sàng sớm nhất có thể. Snowpipe hoạt động trên kiến trúc serverless, tức là tự động quản lý tài nguyên tính toán cần cho quá trình nạp.
Kiến trúc cấp cao của Snowpipe Streaming. Nguồn ảnh: tài liệu Snowflake.
Snowflake được thiết kế như giải pháp kho dữ liệu tối ưu cho tải công việc Xử lý Phân tích Trực tuyến (OLAP). OLAP là công nghệ phần mềm dùng để phân tích dữ liệu kinh doanh từ nhiều góc độ. Điều này khiến Snowflake trở thành tiêu chuẩn vàng vì kiến trúc và tính năng được xây dựng để hỗ trợ tác vụ dữ liệu quy mô lớn, truy vấn phức tạp, và hơn thế nữa. Các đặc điểm của cách tiếp cận OLAP trong Snowflake gồm tách biệt tính toán và lưu trữ, xử lý song song quy mô lớn (MPP), và hỗ trợ nhiều cấu trúc dữ liệu để cho phép xử lý phân tích hiệu quả.
Bạn cũng có tải công việc Xử lý Giao dịch Trực tuyến (OLTP), nhưng Snowflake không được thiết kế truyền thống cho loại này. OLTP là khi cơ sở dữ liệu vừa nhận yêu cầu dữ liệu vừa có nhiều thay đổi từ nhiều người dùng theo thời gian, những thay đổi này gọi là giao dịch. OLTP đặc trưng bởi khối lượng lớn các giao dịch ngắn như chèn và cập nhật. Những đặc điểm này phù hợp với cơ sở dữ liệu vận hành hơn là các giải pháp kho dữ liệu như Snowflake.
Trong Snowflake, clustering tổ chức dữ liệu bên trong các micro-partition để tối ưu hiệu năng truy vấn. Mặc định, Snowflake xử lý clustering tự động, nhưng với các bảng lớn có trật tự tự nhiên (ví dụ dữ liệu chuỗi thời gian), clustering thủ công có thể hữu ích.
Clustering thủ công liên quan đến việc tạo khóa cụm (cluster key) trên các cột thường được dùng trong truy vấn. Điều này cho phép cắt tỉa dữ liệu hiệu quả hơn, vì Snowflake có thể bỏ qua các partition không liên quan khi truy vấn. Tuy nhiên, chỉ nên dùng clustering thủ công khi lợi ích hiệu năng vượt chi phí tái-cluster với tập dữ liệu lớn, do có thể ảnh hưởng chi phí lưu trữ và tính toán.
Fail-safe là tính năng khôi phục dữ liệu trong Snowflake được thiết kế để phục hồi dữ liệu đã bị xóa hoặc sửa đổi vượt quá thời hạn lưu giữ của Time Travel. Trong khi Time Travel cho phép truy cập dữ liệu lịch sử trong khung thời gian thiết lập (tối đa 90 ngày), fail-safe là giai đoạn bảy ngày sau Time Travel, trong đó Snowflake giữ dữ liệu chỉ nhằm khôi phục thảm họa.
Không giống Time Travel, người dùng không thể truy cập trực tiếp dữ liệu fail-safe mà cần sự can thiệp của Snowflake Support.
Fail-safe cung cấp một lớp bảo vệ dữ liệu bổ sung nhưng tốn chi phí cao hơn và nên dùng như biện pháp cuối cùng sau Time Travel.
Materialized view trong Snowflake lưu trữ vật lý kết quả truy vấn, cho phép truy xuất nhanh hơn cho các truy vấn phức tạp hoặc thường xuyên dùng. Khác với view tiêu chuẩn, vốn được tính lại mỗi lần truy vấn, materialized view duy trì tập kết quả cho đến khi dữ liệu được cập nhật. Điều này có thể cải thiện đáng kể hiệu năng truy vấn, đặc biệt với tải phân tích trên các bảng lớn.
Trường hợp sử dụng gồm bảng điều khiển báo cáo và các kết quả tổng hợp nơi dữ liệu thay đổi không thường xuyên. Tuy nhiên, materialized view cần bảo trì định kỳ và có thể tăng chi phí lưu trữ, nên phù hợp nhất với tập dữ liệu tĩnh hoặc thay đổi chậm.
Dưới đây là bảng nêu trường hợp sử dụng materialized view so với view tiêu chuẩn trong Snowflake:
| Khía cạnh | View tiêu chuẩn | Materialized view |
|---|---|---|
| Lưu trữ dữ liệu | Không lưu trữ vật lý; view được tính tại thời điểm truy vấn | Lưu trữ vật lý kết quả truy vấn, tăng tốc độ truy vấn |
| Hiệu năng | Phù hợp truy vấn nhỏ, không thường xuyên | Lý tưởng cho tập dữ liệu lớn/phức tạp với truy vấn thường xuyên |
| Chi phí bảo trì | Tối thiểu, vì không cần lưu trữ | Cao hơn do yêu cầu lưu trữ và làm mới định kỳ |
| Trường hợp sử dụng | Truy vấn ngẫu hứng và khám phá dữ liệu | Bảng điều khiển báo cáo, tổng hợp tính sẵn |
Dựa trên kiến trúc độc đáo của Snowflake, bạn cần nắm rõ từng ngóc ngách và tự kiểm tra kiến thức của mình.
Shared-disk và shared-nothing là hai cách tiếp cận khác nhau trong thiết kế cơ sở dữ liệu và kho dữ liệu. Khác biệt chính là cách quản lý lưu trữ và xử lý dữ liệu trên nhiều nút trong hệ thống.
Trong kiến trúc shared-disk, các nút trong hệ thống có quyền truy cập chung vào lưu trữ đĩa, nghĩa là bất kỳ nút nào cũng có thể đọc/ghi lên bất kỳ đĩa nào trong hệ. Điều này mang lại tính sẵn sàng cao vì hỏng một nút đơn lẻ không gây mất mát hay ngưng trệ dữ liệu. Nó cũng đơn giản hóa quản lý dữ liệu, vì không cần phân vùng hoặc nhân bản dữ liệu giữa các nút.
Ngược lại, kiến trúc shared-nothing là khi mỗi nút có lưu trữ riêng, không chia sẻ với nút khác. Dữ liệu được phân vùng giữa các nút, tức mỗi nút chịu trách nhiệm một phần dữ liệu. Cách này mang lại khả năng mở rộng vì có thể bổ sung thêm nút, mỗi nút có lưu trữ riêng, dẫn tới hiệu năng tốt hơn.
Khi bạn nạp dữ liệu vào một stage trong Snowflake, đó được gọi là ‘Staging’. Staging bên ngoài là khi dữ liệu được lưu ở vùng đám mây khác, còn staging nội bộ là khi dữ liệu lưu trong Snowflake. Staging nội bộ được tích hợp trong môi trường Snowflake và lưu trữ tệp, dữ liệu để nạp vào các bảng Snowflake. Nền tảng Snowflake sử dụng các nhà cung cấp vị trí lưu trữ bên ngoài như AWS, Google Cloud Platform và Azure để lưu dữ liệu cần nạp hoặc lưu trữ.
Snowflake có ba loại bộ nhớ đệm. Dưới đây là bảng so sánh và nêu một số trường hợp sử dụng cho từng loại:
| Loại cache | Mô tả | Thời gian | Trường hợp sử dụng |
|---|---|---|---|
| Result cache | Bộ nhớ đệm kết quả truy vấn trên tất cả kho dữ liệu ảo, nên truy vấn lặp lại có thể lấy kết quả ngay. | 24 giờ | Tăng tốc các truy vấn trùng lặp cho cùng kết quả |
| Local disk cache | Lưu dữ liệu truy cập gần đây trên đĩa cục bộ của mỗi kho dữ liệu ảo, cho phép truy xuất nhanh dữ liệu thường xuyên dùng. | Cho đến khi kho dữ liệu ảo bị tạm dừng | Cải thiện hiệu năng truy vấn lặp lại trên cùng kho |
| Remote cache | Lưu trữ dài hạn trên đĩa từ xa để đảm bảo bền vững, cho phép truy cập dữ liệu ngay cả sau gián đoạn dịch vụ. | Vĩnh viễn, với độ bền 99,999999999% | Đảm bảo dữ liệu sẵn sàng và bền bỉ khi trung tâm dữ liệu gặp sự cố |
Có 3 trạng thái khác nhau của Snowflake Virtual Warehouse:
Snowflake xử lý phân phối dữ liệu thông qua micro-partition, được Snowflake tự động tạo và quản lý. Các micro-partition là đơn vị lưu trữ nhỏ (50–150 MB mỗi đơn vị) lưu dữ liệu theo định dạng cột.
Tính năng clustering tự động của Snowflake đảm bảo phân phối dữ liệu hiệu quả, giảm nhu cầu phân vùng thủ công. Việc dùng micro-partition cho phép cắt tỉa dữ liệu, chỉ truy cập partition liên quan trong khi truy vấn, cải thiện hiệu năng. Không như cơ sở dữ liệu truyền thống, Snowflake trừu tượng hóa việc phân vùng dữ liệu, giúp người dùng không cần quản lý thủ công, từ đó tăng khả năng mở rộng và dễ sử dụng.
Dưới đây là bảng đối chiếu các cơ chế này:
| Cơ chế | Mô tả | Lợi ích |
|---|---|---|
| Micro-partition | Đơn vị lưu trữ nhỏ dạng cột, tổ chức và nén dữ liệu. | Cho phép cắt tỉa dữ liệu, giảm dữ liệu cần quét để truy vấn nhanh hơn. |
| Clustering tự động | Snowflake tự động duy trì clustering của dữ liệu trong micro-partition, thích ứng khi dữ liệu thay đổi. | Đơn giản hóa quản lý dữ liệu, không cần tái-cluster thủ công |
| Cắt tỉa dữ liệu | Chỉ truy cập micro-partition liên quan dựa trên siêu dữ liệu, giảm quét dữ liệu không cần thiết. | Cải thiện hiệu năng truy vấn bằng cách chỉ truy cập dữ liệu cần thiết |
Metadata Service trong Snowflake là một phần của Lớp Dịch vụ Đám mây, đóng vai trò quan trọng trong tối ưu truy vấn và quản lý dữ liệu. Dịch vụ này theo dõi vị trí lưu trữ dữ liệu, mẫu truy cập và siêu dữ liệu cho bảng, cột và partition. Bằng cách truy xuất nhanh siêu dữ liệu, nó cho phép cắt tỉa dữ liệu trong quá trình thực thi truy vấn, giảm lượng dữ liệu phải quét và cải thiện hiệu năng.
Ngoài ra, Metadata Service quản lý và cập nhật Result Cache, cho phép truy xuất truy vấn nhanh hơn khi các truy vấn tương tự được chạy trong khoảng thời gian ngắn. Tổng thể, Metadata Service tăng hiệu quả truy vấn và giảm tiêu thụ tài nguyên.
Tính năng auto-suspend và auto-resume giúp tối ưu sử dụng tài nguyên tính toán và giảm chi phí. Khi một kho dữ liệu ảo không hoạt động trong thời gian xác định, auto-suspend sẽ tự động tắt kho để tránh phí tính toán không cần thiết.
Ngược lại, auto-resume sẽ tự động khởi động kho khi có truy vấn mới. Điều này đảm bảo người dùng chỉ trả phí cho thời gian tính toán khi kho đang xử lý truy vấn.
Các tính năng này đặc biệt hữu ích trong môi trường có tải gián đoạn, vì tối ưu chi phí trong khi vẫn đảm bảo sẵn sàng.
Có thể tạo kho dữ liệu ảo qua giao diện web hoặc bằng SQL. Có 3 phương thức:
CREATE [ OR REPLACE ] WAREHOUSE [ IF NOT EXISTS ] <name>
[ [ WITH ] objectProperties ]
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ objectParams ]Để tạo một task Snowflake, bạn sẽ dùng “CREATE TASK”. Bạn cần định nghĩa câu lệnh SQL hoặc stored procedure trong định nghĩa task và đảm bảo có quyền cần thiết để tạo task. Các bước thực hiện:
CREATE TASK’, theo sau là tên task.WAREHOUSE’SCHEDULE’.AS’.CALL’ để gọi stored procedure.Ví dụ:
CREATE TASK daily_sales_datacamp
WAREHOUSE = 'datacampwarehouse'
SCHEDULE = 'USING CRON 0 1 * * * UTC'
AS
CALL daily_sales_datacamp();Truy vấn này minh họa cách làm việc với dữ liệu JSON bán cấu trúc trong Snowflake:
SELECT
feedback_details:customer_id::INT AS customer_id,
feedback_details:feedback_text::STRING AS feedback_text,
feedback_details:timestamp::TIMESTAMP AS feedback_timestamp
FROM
customer_feedback
WHERE
feedback_details:customer_id::INT = 123; -- Replace 123 with the specific customer_id you're interested inĐể kiểm tra lịch sử một task Snowflake, bạn có thể dùng hàm bảng ‘TASK_HISTORY’. Hàm này cung cấp thông tin chi tiết về lịch sử thực thi các task trong một khoảng thời gian cụ thể.
SELECT *
FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY(
TASK_NAME => '<task_name>',
START_TIME => '<start_time>',
END_TIME => '<end_time>'
))
ORDER BY SCHEDULED_TIME DESC;Bạn cần dùng câu lệnh ‘CREATE TEMPORARY TABLE’ trong Snowflake. Lệnh này sẽ tạo một bảng theo phiên làm việc (session-specific) chỉ tồn tại trong thời lượng do người dùng thiết lập.
CREATE TEMPORARY TABLE table_name (
column_name1 data_type1,
column_name2 data_type2,
...
);Snowflake cung cấp hàm CONVERT_TIMEZONE để chuyển đổi timestamp giữa các múi giờ. Ví dụ sau chuyển timestamp từ UTC sang Eastern Standard Time (EST):
SELECT
customer_id,
CONVERT_TIMEZONE('UTC', 'America/New_York', order_timestamp) AS order_timestamp_est
FROM
orders;Trong truy vấn này, hãy thay customer_id và order_timestamp bằng các cột cụ thể trong bảng của bạn. Hàm này cho phép chuyển đổi múi giờ linh hoạt, lý tưởng cho báo cáo toàn cầu.
Bạn có thể tạo bản sao zero-copy của một bảng trong Snowflake bằng câu lệnh CREATE TABLE ... CLONE. Bản sao dùng chung lớp lưu trữ bên dưới, giúp tiết kiệm chi phí và dung lượng.
CREATE TABLE cloned_table_name CLONE original_table_name;Ví dụ, để clone bảng sales_data, cú pháp sẽ là:
CREATE TABLE sales_data_clone CLONE sales_data;Bảng clone này sẽ có cùng dữ liệu và schema như bản gốc tại thời điểm clone. Mọi thay đổi với bảng clone sau khi tạo sẽ không ảnh hưởng đến bảng gốc.
Bạn có thể dùng GROUP BY kết hợp ORDER BY và LIMIT để lấy 5 giá trị xuất hiện nhiều nhất trong một cột cụ thể. Ví dụ, nếu muốn tìm 5 sản phẩm phổ biến nhất trong cột product_id:
SELECT
product_id,
COUNT(*) AS frequency
FROM
sales
GROUP BY
product_id
ORDER BY
frequency DESC
LIMIT 5;Truy vấn này nhóm cột product_id theo tần suất, sắp xếp giảm dần và giới hạn 5 kết quả hàng đầu, cho thấy các sản phẩm bán chạy nhất.
Khi chuẩn bị cho bất kỳ cuộc phỏng vấn nào, điều quan trọng là thực hiện những việc sau:
Cuối cùng nhưng không kém phần quan trọng, hãy tự tin và cố gắng hết mình!
Trong bài viết này, chúng ta đã đề cập các câu hỏi phỏng vấn Snowflake cho 4 cấp độ khác nhau:
Nếu bạn đang tìm tài nguyên để ôn luyện hoặc kiểm tra kỹ năng Snowflake, hãy xem các hướng dẫn Introduction to Snowflake và Bắt đầu Phân tích Dữ liệu trong Snowflake bằng Python và SQL cũng như khóa học Introduction to NoSQL, nơi bạn sẽ học cách dùng Snowflake để làm việc với dữ liệu lớn.
Ngoài ra, hãy nghe tập podcast của chúng tôi với cựu CEO Snowflake Bob Muglia về chủ đề ‘Vì sao AI sẽ thay đổi tất cả’.
Bắt đầu hành trình với Snowflake ngay hôm nay!
Courses
Courses