
Kursus
Memahami Rekayasa Data
2 Hr
362.2K
Mari mulai dengan pertanyaan dasar tentang konsep kunci di Snowflake.
Snowflake adalah platform gudang data berbasis cloud yang memisahkan komputasi dari penyimpanan, sehingga pengguna dapat menskalakan sumber daya pemrosesan dan penyimpanan data secara independen. Proses ini lebih hemat biaya dan menghasilkan kinerja tinggi.
Salah satu fitur utamanya adalah penskalaan otomatis, yang memungkinkan penyesuaian sumber daya berdasarkan permintaan beban kerja dan mendukung lingkungan multi-cloud. Fitur penting lainnya adalah pendekatan platform terhadap berbagi data, memastikan akses data di seluruh organisasi aman dan mudah, tanpa perlu memindahkan data.
Arsitektur Snowflake adalah keunggulan utamanya. Platform ini dirancang untuk cloud, dengan fitur seperti arsitektur data bersama multi-kluster dan kemampuan penyimpanan yang unggul. Arsitektur Snowflake terbagi menjadi tiga lapisan:
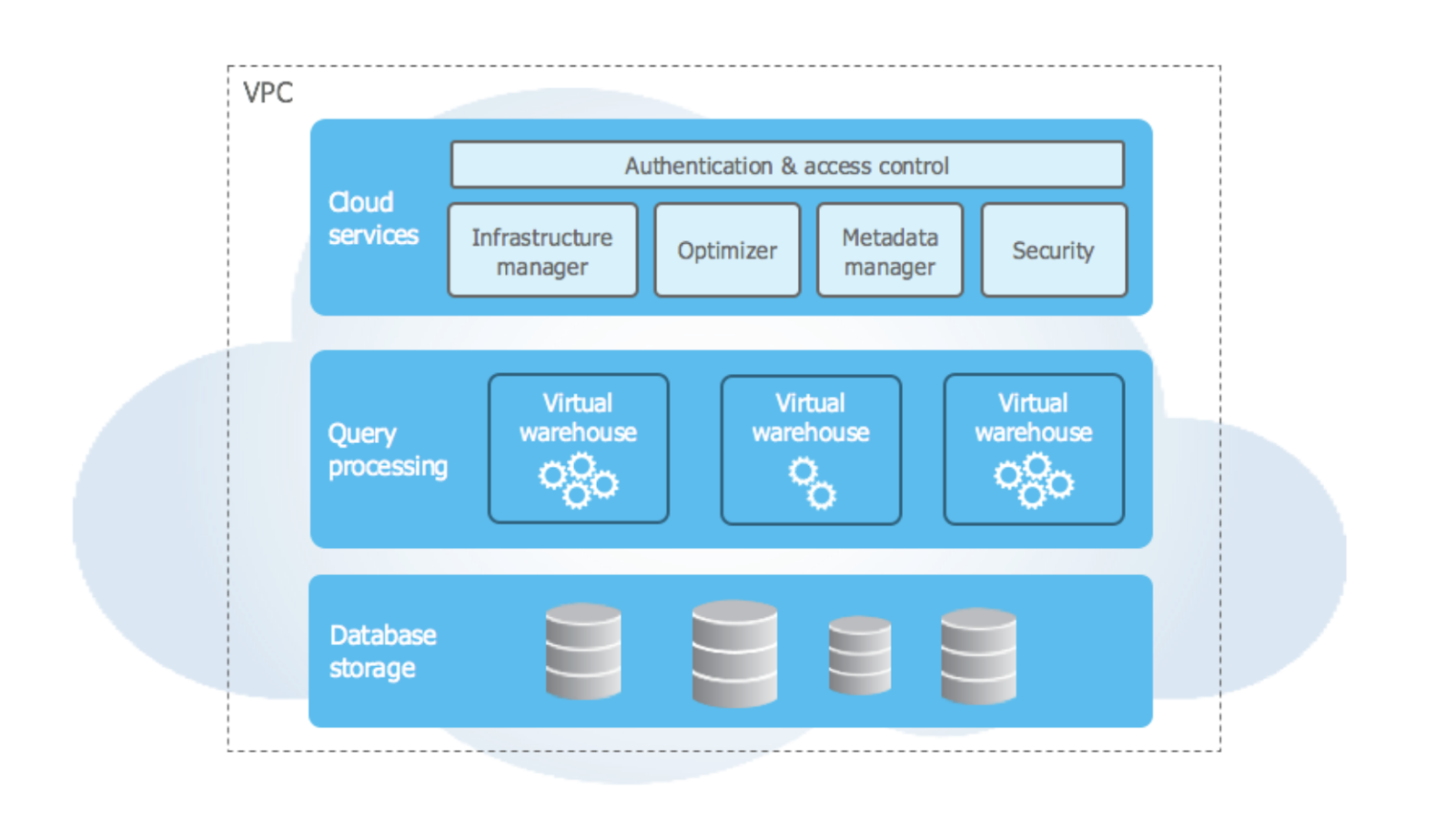
Arsitektur tingkat tinggi Snowflake. Sumber gambar: dokumentasi Snowflake.
Mikro-partisi adalah aspek fundamental dari pendekatan penyimpanan data Snowflake. Ini adalah unit penyimpanan kolumnar yang dikompresi dan dikelola, yang digunakan Snowflake untuk menyimpan data berukuran 50MB hingga 150MB. Format kolumnar memungkinkan kompresi data dan skema pengodean yang efisien.
Kemampuan mikro-partisi untuk mengompresi data memungkinkan volume data besar dikelola secara efisien karena mengurangi ruang penyimpanan fisik yang diperlukan, sekaligus menurunkan biaya penyimpanan. Kinerja kueri juga meningkat berkat pruning data, yakni hanya mikro-partisi relevan yang diakses. Pendekatan akses selektif ini sangat bermanfaat untuk pengambilan dan analitik data.
Mikro-partisi dikelola secara otomatis oleh Snowflake, sehingga tidak diperlukan partisi atau pengindeksan data secara manual, memastikan penyimpanan data optimal dan memangkas biaya administrasi.
Gudang virtual bertanggung jawab menjalankan semua tugas pemrosesan data. Karena itu, pengaruhnya sangat besar terhadap skalabilitas, kinerja, dan pengelolaan biaya tugas pemrosesan data.
Fitur skalabilitas dinamisnya memungkinkan pengguna menambah atau mengurangi sumber daya komputasi berdasarkan kebutuhan beban kerja. Saat permintaan pemrosesan data meningkat, Anda dapat menyediakan sumber daya komputasi tambahan tanpa mengganggu operasi yang sedang berjalan.
Setiap gudang virtual tidak memengaruhi yang lain, sehingga kinerja tinggi dan konsistensi tetap terjaga untuk tugas pemrosesan data spesifik seperti analitik sensitif waktu. Saat menangani tugas pemrosesan data, Anda membayar sumber daya komputasi yang digunakan, sehingga menyediakan fitur pengelolaan biaya dibanding solusi gudang data tradisional.
Tabel berikut membandingkan gudang virtual dengan sumber daya komputasi tradisional:
| Fitur | Gudang virtual (Snowflake) | Sumber daya komputasi tradisional |
|---|---|---|
| Skalabilitas | Auto-scaling, multi-kluster; dapat menyesuaikan ukuran naik atau turun berdasarkan permintaan beban kerja tanpa mengganggu operasi. | Biasanya kapasitas tetap, memerlukan peningkatan manual untuk penskalaan. |
| Isolasi | Mengisolasi kluster komputasi, sehingga beban kerja bersamaan berjalan independen. | Berbagi sumber daya sering menimbulkan kompetisi antar tugas. |
| Pengelolaan biaya | Bayar hanya untuk waktu aktif dan skala sesuai kebutuhan, meminimalkan biaya menganggur. | Biaya tetap terlepas dari perubahan beban kerja, berpotensi biaya menganggur lebih tinggi. |
| Optimasi kinerja | Penskalaan independen memungkinkan penyetelan terpisah untuk tugas spesifik, menjaga kinerja tinggi untuk kueri sensitif waktu. | Opsi penyetelan terbatas, karena penskalaan memengaruhi semua beban kerja secara setara. |
ANSI SQL adalah singkatan dari American National Standards Institute Structured Query Language dan merupakan bahasa standar untuk sistem manajemen basis data relasional.
Ini berarti pengguna Snowflake dapat menggunakan sintaks dan operasi SQL yang familier untuk melakukan kueri data, seperti JOIN, sehingga menjadi fitur hebat bagi pengguna berpengalaman SQL untuk beralih ke Snowflake. Fitur lain dari kompatibilitas ANSI SQL adalah integrasi mulus berbagai tipe data, memungkinkan pengguna mengkueri data tanpa perlu mentransformasi atau memuatnya terlebih dahulu ke dalam skema pradefinisi.
Jika Anda ingin meraih sertifikasi penggunaan platform Snowflake, lihat Which is the Best Snowflake Certification For 2026?
Fitur Time Travel Snowflake memungkinkan pengguna mengakses dan mengkueri data historis untuk jangka waktu tertentu, biasanya hingga 90 hari, tergantung tipe akun. Fitur ini berguna untuk pemulihan data, keperluan audit, dan perbandingan data. Misalnya, pengguna dapat memulihkan tabel yang terhapus secara tidak sengaja atau meninjau keadaan data sebelumnya.
Time Travel meminimalkan kebutuhan pencadangan eksternal dan menyederhanakan versi data, menyediakan kemampuan pemulihan data dan analisis retrospektif bawaan.
Fitur berbagi data Snowflake memungkinkan organisasi berbagi data langsung secara aman dan real time dengan pengguna atau mitra eksternal tanpa membuat salinan data tambahan. Ini dicapai melalui fungsi Secure Data Sharing Snowflake, yang menggunakan arsitektur data bersama multi-kluster Snowflake untuk memberikan akses langsung ke data.
Keuntungan berbagi data meliputi:
Zero-copy cloning adalah fitur di Snowflake yang memungkinkan pengguna membuat salinan basis data, skema, atau tabel tanpa menduplikasi penyimpanan dasarnya. Saat klon zero-copy dibuat, ia merujuk ke data asli dan hanya menyimpan perubahan yang dilakukan pada data hasil kloning, sehingga menghemat penyimpanan secara signifikan. Fitur ini berharga untuk membuat lingkungan pengembangan dan pengujian atau menghasilkan snapshot historis tanpa meningkatkan biaya penyimpanan. Ini meningkatkan efisiensi pengelolaan data dengan memungkinkan duplikasi data yang cepat dan hemat biaya untuk berbagai kasus penggunaan.
Sudah percaya diri dengan pertanyaan dasar? Mari beralih ke beberapa pertanyaan yang lebih mendalam.
Snowflake bertujuan memastikan tingkat perlindungan dan keamanan data tertinggi bagi penggunanya dengan menerapkan proses enkripsi always-on. Ini adalah enkripsi data otomatis tanpa perlu pengaturan atau konfigurasi pengguna, memastikan semua jenis data dari data mentah hingga metadata dienkripsi dengan algoritma enkripsi yang kuat. Enkripsi dikelola melalui model kunci hierarkis di mana kunci master mengenkripsi kunci lainnya dan Snowflake melakukan rotasi kunci untuk meningkatkan keamanan.
Saat mentransfer data, Snowflake menggunakan proses TLS (Transport Layer Security) untuk mengenkripsi data yang transit antara Snowflake dan klien. Enkripsi end-to-end ini memastikan data selalu terenkripsi, di mana pun posisinya dalam siklus hidup, sehingga mengurangi risiko kebocoran dan pelanggaran data.
Proses Extract, Transform, Load (ETL) dan Extract, Load, Transform (ELT) banyak digunakan di platform Snowflake karena arsitektur dan kemampuannya. Platform ini memenuhi beragam kebutuhan integrasi dan transformasi data, memungkinkan organisasi mengoptimalkan alur pemrosesan data secara lebih efektif.
Dalam ETL, data diekstrak dari berbagai sumber lalu ditransformasi ke format yang diinginkan pengguna sebelum dimuat ke gudang data. Snowflake adalah mesin SQL yang kuat yang memungkinkan transformasi kompleks menggunakan kueri SQL setelah data dimuat.
Dalam ELT, data dimuat terlebih dahulu ke gudang data dalam bentuk mentah lalu ditransformasi di dalam gudang. Fitur pemisahan komputasi dan penyimpanan Snowflake memungkinkan data mentah dimuat dengan cepat ke gudang data. Transformasi data dilakukan menggunakan gudang virtual. Snowflake juga mendukung format data semi-terstruktur seperti JSON dan XML sehingga memudahkan pemuatan data mentah ke gudang data tanpa harus ditransformasi terlebih dahulu.
Snowflake mendukung beragam alat ETL, memungkinkan organisasi menggunakan alat pilihan mereka untuk tugas integrasi dan transformasi data. Alat berikut dapat digunakan di platform data cloud Snowflake untuk memroses dan memindahkan data ke Snowflake untuk analisis lebih lanjut:
Snowpipe adalah layanan ingestion data berkelanjutan dari Snowflake yang dapat memuat file dalam hitungan menit. Dengan Snowpipe Anda dapat memuat data dalam kelompok kecil (micro-batches), memungkinkan pengguna di seluruh organisasi mengakses data dalam beberapa menit, sehingga lebih mudah dianalisis.
Pengguna menentukan path penyimpanan cloud tempat file data akan ditempatkan dan juga tabel target di Snowflake tempat data akan dimuat. Ini adalah proses pemuatan data otomatis di mana Snowpipe secara otomatis mendeteksi saat file baru ditambahkan ke path penyimpanan. Setelah file baru terdeteksi, Snowpipe mengingest data ke Snowflake dan memuatnya ke tabel yang ditentukan.
Proses near real-time ini memastikan data tersedia secepat mungkin. Snowpipe beroperasi pada arsitektur tanpa server (serverless), artinya secara otomatis mengelola sumber daya komputasi yang diperlukan khusus untuk proses ingestion data.
Arsitektur tingkat tinggi Snowpipe Streaming. Sumber gambar: dokumentasi Snowflake.
Snowflake dirancang sebagai solusi gudang data yang dioptimalkan untuk beban kerja Online Analytical Processing (OLAP). OLAP adalah teknologi perangkat lunak yang digunakan untuk menganalisis data bisnis dari berbagai sudut pandang. Hal ini menjadikan Snowflake standar emas karena desain arsitekturnya beserta fitur-fiturnya disesuaikan untuk mendukung tugas data skala besar, kueri kompleks, dan lainnya. Fitur pendekatan OLAP Snowflake meliputi pemisahan komputasi dan penyimpanan, pemrosesan paralel masif (MPP), serta dukungan beragam struktur data untuk memfasilitasi pemrosesan analitik yang efisien.
Ada juga beban kerja Online Transaction Processing (OLTP), yang secara tradisional bukan fokus desain Snowflake. Beban kerja OLTP terjadi ketika basis data menerima permintaan data sekaligus banyak perubahan pada data tersebut dari beberapa pengguna seiring waktu, dan modifikasi ini disebut transaksi. Ciri-cirinya adalah volume tinggi transaksi pendek seperti insert dan update. Fitur-fitur ini lebih berfokus pada basis data operasional dibanding solusi gudang data seperti Snowflake.
Di Snowflake, clustering mengatur data dalam mikro-partisi untuk mengoptimalkan kinerja kueri. Secara default, Snowflake menangani clustering secara otomatis, tetapi untuk tabel besar dengan urutan alami (misalnya data deret waktu), clustering manual bisa menguntungkan.
Clustering manual melibatkan pembuatan kunci kluster pada kolom yang sering digunakan dalam kueri. Ini memungkinkan pruning data yang lebih efisien, karena Snowflake dapat melewati partisi yang tidak relevan saat kueri dijalankan. Namun, clustering manual sebaiknya digunakan hanya ketika manfaat kinerja kueri lebih besar daripada biaya re-clustering dataset besar, karena dapat berdampak pada biaya penyimpanan dan komputasi.
Fail-safe adalah fitur pemulihan data di Snowflake yang dirancang untuk memulihkan data yang telah dihapus atau diubah melampaui periode retensi Time Travel. Sementara Time Travel memungkinkan pengguna mengakses data historis dalam jangka waktu tertentu (hingga 90 hari), fail-safe adalah periode tujuh hari setelah Time Travel di mana Snowflake menyimpan data semata-mata untuk pemulihan bencana.
Berbeda dengan Time Travel, pengguna tidak dapat mengakses data fail-safe secara langsung karena memerlukan intervensi dari Snowflake Support.
Fail-safe memberikan lapisan perlindungan data tambahan namun menimbulkan biaya lebih tinggi dan sebaiknya digunakan sebagai upaya terakhir setelah Time Travel.
Materialized view di Snowflake menyimpan hasil kueri secara fisik, sehingga pengambilan untuk kueri kompleks atau yang sering digunakan menjadi lebih cepat. Tidak seperti standard view yang dihitung ulang setiap kali dikueri, materialized view mempertahankan himpunan hasil hingga data diperbarui. Ini dapat meningkatkan kinerja kueri secara signifikan, terutama untuk beban kerja analitik yang melibatkan tabel besar.
Kasus penggunaan materialized view meliputi dasbor pelaporan dan hasil kueri teragregasi di mana data jarang berubah. Namun, materialized view memerlukan pemeliharaan berkala dan dapat meningkatkan biaya penyimpanan, sehingga paling cocok untuk dataset statis atau berubah perlahan.
Berikut tabel yang membahas kasus penggunaan materialized view vs. standard view di Snowflake:
| Aspek | Standard view | Materialized view |
|---|---|---|
| Penyimpanan data | Tidak ada penyimpanan fisik; view dihitung saat waktu kueri | Menyimpan hasil kueri secara fisik, meningkatkan kecepatan kueri |
| Kinerja | Cocok untuk kueri kecil dan jarang | Ideal untuk dataset besar atau kompleks dengan kueri sering |
| Biaya pemeliharaan | Minimal, karena tidak membutuhkan penyimpanan | Lebih tinggi karena kebutuhan penyimpanan dan penyegaran berkala |
| Kasus penggunaan | Kueri ad-hoc dan eksplorasi data | Dasbor pelaporan, agregat pra-hitung |
Berdasarkan arsitektur unik Snowflake, Anda harus memahami seluk-beluknya dan menguji pengetahuan Anda.
Shared-disk dan shared-nothing adalah dua pendekatan berbeda dalam desain basis data dan gudang data. Perbedaan utama di antara keduanya adalah bagaimana mereka mengelola penyimpanan dan pemrosesan data di beberapa node dalam suatu sistem.
Dalam arsitektur shared-disk, node-node dalam sistem memiliki akses ke penyimpanan disk, yang berarti node mana pun dalam sistem dapat membaca atau menulis ke disk mana pun dalam sistem tersebut. Ini memungkinkan ketersediaan tinggi karena kegagalan satu node tidak menyebabkan kehilangan data atau ketidaktersediaan. Selain itu, proses manajemen data menjadi lebih sederhana karena data tidak perlu dipartisi atau direplikasi di antara node.
Di sisi lain, arsitektur shared-nothing adalah ketika setiap node dalam sistem memiliki penyimpanan pribadi yang tidak dibagikan dengan node lain. Data dipartisi di antara node, yang berarti setiap node bertanggung jawab atas sebagian data. Ini memberikan skalabilitas karena memungkinkan penambahan lebih banyak node, masing-masing dengan penyimpanan sendiri, sehingga meningkatkan kinerja.
Saat Anda memuat data ke sebuah stage di Snowflake, ini dikenal sebagai ‘Staging.’ Staging eksternal adalah ketika data disimpan di wilayah cloud lain, dan staging internal adalah ketika data disimpan di dalam Snowflake. Staging internal terintegrasi dalam lingkungan Snowflake dan menyimpan file serta data untuk dimuat ke tabel Snowflake. Platform Snowflake menggunakan penyedia lokasi penyimpanan eksternal seperti AWS, Google Cloud Platform, dan Azure untuk menyimpan data yang perlu dimuat atau disimpan.
Snowflake memiliki tiga jenis caching. Berikut tabel perbandingan sekaligus menyoroti beberapa kasus penggunaan masing-masing:
| Jenis cache | Deskripsi | Durasi | Kasus penggunaan |
|---|---|---|---|
| Result cache | Mencache hasil kueri di seluruh gudang virtual, sehingga kueri berulang dapat mengambil hasil seketika. | 24 jam | Mempercepat kueri identik dengan hasil yang sama |
| Local disk cache | Menyimpan data yang baru diakses pada disk lokal tiap gudang virtual, memungkinkan pengambilan lebih cepat untuk data yang sering diakses. | Hingga gudang virtual disuspensi | Meningkatkan kinerja kueri berulang pada gudang yang sama |
| Remote cache | Penyimpanan jangka panjang pada disk jarak jauh untuk daya tahan, memungkinkan akses data bahkan setelah gangguan layanan. | Permanen, dengan durabilitas 99,999999999% | Memastikan data tersedia dan tangguh jika terjadi kegagalan pusat data |
Ada 3 status berbeda untuk Snowflake Virtual Warehouse:
Snowflake menangani distribusi data melalui mikro-partisi, yang dibuat dan dikelola secara otomatis oleh Snowflake. Mikro-partisi ini adalah unit penyimpanan kecil (masing-masing 50–150 MB) yang menyimpan data dalam format kolumnar.
Clustering otomatis Snowflake memastikan distribusi data yang efisien, meminimalkan kebutuhan pemartisian manual. Penggunaan mikro-partisi memungkinkan pruning data, di mana hanya partisi relevan yang diakses saat kueri, sehingga meningkatkan kinerja. Berbeda dengan basis data tradisional, Snowflake mengabstraksikan pemartisian data, sehingga pengguna tidak perlu mengelola distribusi data secara manual, memungkinkan skalabilitas dan kemudahan penggunaan yang lebih baik.
Berikut tabel yang membandingkan mekanisme ini:
| Mekanisme | Deskripsi | Manfaat |
|---|---|---|
| Mikro-partisi | Unit penyimpanan kecil berbasis kolom yang mengatur dan mengompresi data. | Memungkinkan pruning data, mengurangi jumlah data yang dipindai agar kueri lebih cepat. |
| Clustering otomatis | Snowflake secara otomatis mempertahankan clustering data dalam mikro-partisi, menyesuaikan saat data berubah. | Menyederhanakan manajemen data, tidak perlu re-clustering manual |
| Pruning data | Hanya mikro-partisi relevan yang diakses berdasarkan metadata, meminimalkan pemindaian data yang tidak perlu. | Meningkatkan kinerja kueri dengan mengakses hanya data yang diperlukan |
Metadata Service di Snowflake merupakan bagian dari Cloud Services Layer, dan berperan penting dalam pengoptimalan kueri dan manajemen data. Layanan ini melacak lokasi penyimpanan data, pola akses, dan metadata untuk tabel, kolom, dan partisi. Dengan mengambil metadata secara cepat, layanan ini memungkinkan pruning data selama eksekusi kueri, yang mengurangi jumlah data yang dipindai dan meningkatkan kinerja.
Selain itu, Metadata Service mengelola dan memperbarui Result Cache, memungkinkan pengambilan kueri lebih cepat saat kueri serupa dijalankan dalam rentang waktu singkat. Secara keseluruhan, Metadata Service meningkatkan efisiensi kueri dan mengurangi konsumsi sumber daya.
Fitur auto-suspend dan auto-resume Snowflake membantu mengoptimalkan penggunaan sumber daya komputasi dan mengurangi biaya. Ketika gudang virtual tetap menganggur selama periode tertentu, auto-suspend akan secara otomatis mematikan gudang untuk menghindari biaya komputasi yang tidak perlu.
Sebaliknya, fitur auto-resume akan memulai gudang secara otomatis saat kueri baru diterima. Ini memastikan pengguna hanya membayar waktu komputasi ketika gudang secara aktif memproses kueri.
Fitur-fitur ini sangat bermanfaat di lingkungan dengan beban kerja sporadis, karena mengoptimalkan efisiensi biaya sambil mempertahankan ketersediaan.
Gudang virtual dapat dibuat melalui antarmuka web atau menggunakan SQL. Berikut 3 metodenya:
CREATE [ OR REPLACE ] WAREHOUSE [ IF NOT EXISTS ] <name>
[ [ WITH ] objectProperties ]
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ objectParams ]Untuk membuat tugas Snowflake, Anda harus menggunakan “CREATE TASK”. Anda perlu mendefinisikan pernyataan SQL atau stored procedure dalam definisi tugas dan memastikan Anda memiliki izin yang diperlukan untuk membuat tugas. Langkah-langkahnya sebagai berikut:
CREATE TASK’, diikuti nama tugas Anda.WAREHOUSE’SCHEDULE’.AS’.CALL’ pada stored procedure.Contoh:
CREATE TASK daily_sales_datacamp
WAREHOUSE = 'datacampwarehouse'
SCHEDULE = 'USING CRON 0 1 * * * UTC'
AS
CALL daily_sales_datacamp();Kueri ini menunjukkan cara bekerja dengan data JSON semi-terstruktur di Snowflake:
SELECT
feedback_details:customer_id::INT AS customer_id,
feedback_details:feedback_text::STRING AS feedback_text,
feedback_details:timestamp::TIMESTAMP AS feedback_timestamp
FROM
customer_feedback
WHERE
feedback_details:customer_id::INT = 123; -- Replace 123 with the specific customer_id you're interested inUntuk memverifikasi riwayat sebuah tugas Snowflake, Anda dapat menggunakan fungsi tabel ‘TASK_HISTORY’. Ini akan memberi Anda informasi terperinci tentang riwayat eksekusi tugas dalam rentang waktu tertentu.
SELECT *
FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY(
TASK_NAME => '<task_name>',
START_TIME => '<start_time>',
END_TIME => '<end_time>'
))
ORDER BY SCHEDULED_TIME DESC;Anda perlu menggunakan pernyataan ‘CREATE TEMPORARY TABLE’ di Snowflake. Ini akan membuat tabel spesifik-sesi yang hanya ada selama durasi yang ditentukan pengguna.
CREATE TEMPORARY TABLE table_name (
column_name1 data_type1,
column_name2 data_type2,
...
);Snowflake menyediakan fungsi CONVERT_TIMEZONE untuk mengonversi timestamp antar zona waktu. Berikut contoh cara mengonversi timestamp dari UTC ke Eastern Standard Time (EST):
SELECT
customer_id,
CONVERT_TIMEZONE('UTC', 'America/New_York', order_timestamp) AS order_timestamp_est
FROM
orders;Dalam kueri ini, ganti customer_id dan order_timestamp dengan kolom spesifik di tabel Anda. Fungsi ini memungkinkan konversi zona waktu yang fleksibel, ideal untuk pelaporan global.
Anda dapat membuat klon zero-copy dari sebuah tabel di Snowflake menggunakan pernyataan CREATE TABLE ... CLONE. Klon ini berbagi penyimpanan yang sama di bawahnya, sehingga menghemat biaya dan ruang penyimpanan.
CREATE TABLE cloned_table_name CLONE original_table_name;Sebagai contoh, untuk mengklon tabel bernama sales_data, sintaksnya sebagai berikut:
CREATE TABLE sales_data_clone CLONE sales_data;Tabel hasil kloning ini akan memiliki data dan skema yang sama dengan tabel asli pada saat pengklonan. Perubahan apa pun yang dilakukan pada tabel klon setelah dibuat tidak akan memengaruhi tabel asli.
Anda dapat menggunakan klausa GROUP BY dengan ORDER BY dan LIMIT untuk mengambil 5 nilai paling sering muncul dalam kolom tertentu. Misalnya, jika Anda ingin menemukan 5 produk paling umum pada kolom product_id:
SELECT
product_id,
COUNT(*) AS frequency
FROM
sales
GROUP BY
product_id
ORDER BY
frequency DESC
LIMIT 5;Kueri ini mengelompokkan kolom product_id berdasarkan frekuensi, mengurutkannya secara menurun, dan membatasi hasil ke 5 teratas, menampilkan produk yang paling sering terjual.
Saat mempersiapkan wawancara apa pun, penting untuk melakukan hal berikut:
Terakhir namun tak kalah penting, percaya dirilah dan berikan yang terbaik!
Dalam artikel ini kami telah membahas pertanyaan wawancara Snowflake untuk 4 level berbeda:
Jika Anda mencari sumber daya untuk menyegarkan kembali atau menguji keterampilan Snowflake Anda, lihat tutorial kami tentang Introduction to Snowflake dan Getting Started with Data Analysis in Snowflake using Python and SQL serta kursus Introduction to NoSQL, di mana Anda akan mempelajari cara menggunakan Snowflake untuk bekerja dengan big data.
Selain itu, dengarkan episode podcast kami bersama mantan CEO Snowflake Bob Muglia tentang ‘Mengapa AI Akan Mengubah Segalanya’.
Mulai Perjalanan Snowflake Anda Hari Ini!
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
