
Cursus
Data Engineering begrijpen
2 Hr
362.2K
Laten we beginnen met de basisvragen over de kernconcepten in Snowflake.
Snowflake is een cloudgebaseerd datawarehouseplatform dat compute scheidt van storage, waardoor gebruikers hun verwerkingsresources en dataopslag onafhankelijk kunnen schalen. Dit is kostenefficiënter en levert hoge prestaties op.
Een van de belangrijkste functies is auto-scaling, waarmee resources worden aangepast op basis van de vraag van workloads en dat multi-cloudomgevingen worden ondersteund. Een andere essentiële functie is de platformaanpak voor datadeling, die ervoor zorgt dat toegang tot data binnen de organisatie veilig en eenvoudig is, zonder dat data verplaatst hoeft te worden.
De architectuur van Snowflake is het unieke verkooppunt. Het is ontworpen voor de cloud, met functies zoals multi-cluster, gedeelde data-architectuur en geweldige opslagmogelijkheden. De Snowflake-architectuur is verdeeld in drie lagen:
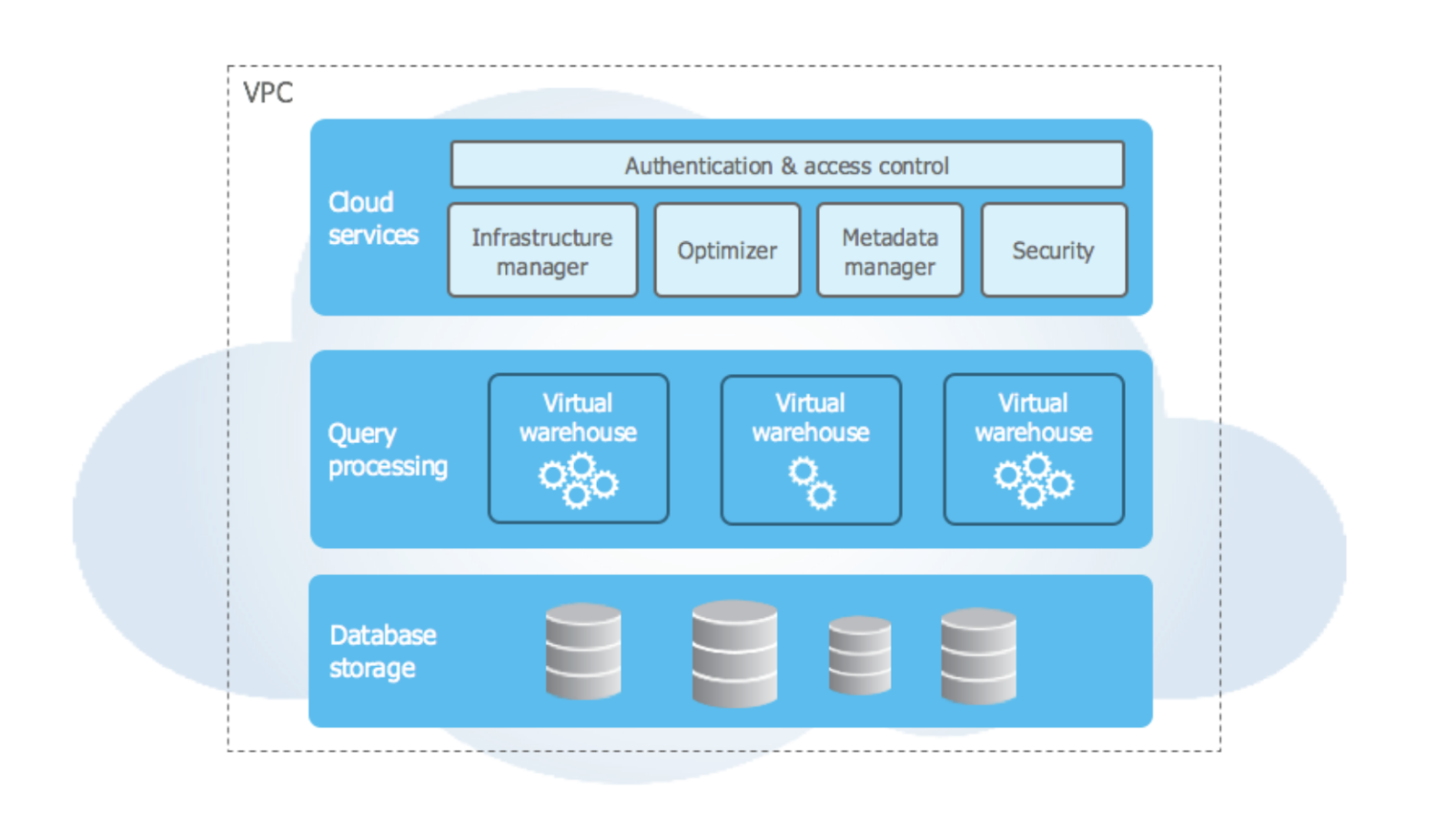
Hoogoverarchitectuur van Snowflake. Beeldbron: Snowflake-documentatie.
Micro-partities zijn een fundamenteel onderdeel van Snowflakes aanpak van dataopslag. Het zijn gecomprimeerde, beheerde en kolomgebaseerde opslagunits die Snowflake gebruikt om data op te slaan, variërend van 50 MB tot 150 MB. Het kolomformaat maakt efficiënte datacompressie en encodingschema’s mogelijk.
Dankzij de mogelijkheid van micro-partities om data te comprimeren, kunnen grote hoeveelheden data efficiënt worden beheerd, omdat de vereiste fysieke opslagruimte afneemt, wat ook de opslagkosten vermindert. De queryprestaties verbeteren ook door data pruning, waarbij alleen relevante micro-partities worden benaderd. Deze selectieve toegang is zeer gunstig voor data-opvraging en -analyse.
Micro-partities worden automatisch beheerd door Snowflake, waardoor handmatige invoer voor datapartitionering of indexing overbodig wordt. Dit zorgt voor optimale dataopslag en vermindert tevens de administratieve kosten.
Virtuele warehouses zijn verantwoordelijk voor het uitvoeren van alle dataverwerkingstaken. Ze hebben dus een grote impact op de schaalbaarheid, prestaties en kostenbeheersing van dataverwerkingstaken.
Hun dynamische schaalbaarheidsfuncties stellen gebruikers in staat hun compute-resources op of af te schalen op basis van de workloadvereisten. Wanneer de vraag naar je dataverwerkingstaken toeneemt, kun je extra compute-resources toewijzen zonder impact op lopende operaties.
Elk virtueel warehouse beïnvloedt een ander niet, wat zorgt voor hoge prestaties en consistentie bij specifieke dataverwerkingstaken zoals tijdkritische analyses. Bij het afhandelen van dataverwerkingstaken betaal je voor de compute-resources die je gebruikt, wat kostenbeheersingsmogelijkheden biedt in vergelijking met traditionele datawarehouseoplossingen.
De volgende tabel vergelijkt virtuele warehouses met traditionele compute-resources:
| Functie | Virtuele warehouses (Snowflake) | Traditionele compute-resources |
|---|---|---|
| Schaalbaarheid | Auto-scaling, multi-cluster; kan de grootte aanpassen op basis van workloaddruk zonder impact op operaties. | Meestal vaste capaciteit; handmatige upgrades nodig voor schalen. |
| Isolatie | Isoleren computeclusters, zodat gelijktijdige workloads onafhankelijk draaien. | Resource-sharing leidt vaak tot concurrentie tussen taken. |
| Kostenbeheer | Betaal alleen voor de actieve tijd en schaal op of af naar behoefte, minimale idle-kosten. | Vaste kosten ongeacht veranderingen in de workload, mogelijk hogere idle-kosten. |
| Prestatie-optimalisatie | Onafhankelijke schaalvergroting/-verkleining maakt aparte tuning per taak mogelijk, hoge prestaties voor tijdkritische queries. | Beperkte tuningopties, omdat schalen alle workloads gelijk beïnvloedt. |
ANSI SQL staat voor American National Standards Institute Structured Query Language en is de standaardtaal voor relationele databasesystemen.
Dit betekent dat Snowflake-gebruikers vertrouwde SQL-syntaxis en -operaties kunnen gebruiken voor het bevragen van data, zoals JOINs. Dit is een geweldige functie voor SQL-ervaren gebruikers om over te stappen naar Snowflake. Een andere eigenschap van de compatibiliteit met ANSI SQL is de naadloze integratie van verschillende datatypes, waardoor gebruikers hun data kunnen bevragen zonder deze eerst te hoeven transformeren of in een vooraf gedefinieerd schema te laden.
Als je een certificering wilt halen voor het gebruik van het Snowflake-platform, bekijk dan Which is the Best Snowflake Certification For 2026?
Snowflakes Time Travel-functie stelt gebruikers in staat om historische data gedurende een bepaalde periode te benaderen en te bevragen, doorgaans tot 90 dagen, afhankelijk van het accounttype. Deze functie is nuttig voor dataterugwinning, auditdoeleinden en datavergelijking. Gebruikers kunnen bijvoorbeeld per ongeluk verwijderde tabellen herstellen of eerdere datatoestanden bekijken.
Time Travel vermindert de noodzaak van externe back-ups en vereenvoudigt dataversiebeheer, met ingebouwde mogelijkheden voor dataterugwinning en retrospectieve analyse.
Snowflakes datadeling stelt organisaties in staat om live data veilig en realtime te delen met externe gebruikers of partners zonder extra datakopieën te maken. Dit gebeurt via Snowflakes Secure Data Sharing-functionaliteit, die Snowflakes multi-cluster, gedeelde data-architectuur gebruikt om directe toegang tot data te bieden.
De voordelen van datadeling zijn onder andere:
Zero-copy cloning is een functie in Snowflake waarmee gebruikers een kopie van een database, schema of tabel kunnen maken zonder de onderliggende opslag te dupliceren. Wanneer een zero-copy clone wordt gemaakt, verwijst deze naar de oorspronkelijke data en slaat hij alleen de wijzigingen aan de gekloonde data op, wat aanzienlijke opslagbesparingen oplevert. Deze functie is waardevol voor het creëren van ontwikkel- en testomgevingen of het genereren van historische snapshots zonder stijgende opslagkosten. Het verbetert de efficiëntie van databeheer door snelle, kosteneffectieve dataduplicatie voor verschillende use-cases mogelijk te maken.
Voel je je zeker over de basisvragen? Laten we doorgaan met wat meer gevorderde vragen.
Snowflake wil het hoogste niveau van databescherming en -beveiliging voor zijn gebruikers waarborgen met de implementatie van always-on-encryptie. Dit is de automatische versleuteling van data zonder dat gebruikers iets hoeven in te stellen of te configureren, zodat alle soorten data, van ruwe data tot metadata, worden versleuteld met een sterk encryptie-algoritme. De encryptie wordt beheerd via een hiërarchisch sleutelschema waarbij een master key andere sleutels versleutelt en Snowflake deze sleutels roteert om de beveiliging te versterken.
Bij gegevensoverdracht gebruikt Snowflake TLS (Transport Layer Security) om data te versleutelen die tussen Snowflake en clients wordt verzonden. Deze end-to-end-versleuteling zorgt ervoor dat de data altijd versleuteld is, waar die zich ook bevindt in de levenscyclus, waardoor het risico op datalekken en inbreuken wordt verminderd.
De Extract, Transform, Load (ETL) en Extract, Load, Transform (ELT)-processen worden veel gebruikt op het Snowflake-platform dankzij de architectuur en mogelijkheden. Het platform voorziet in uiteenlopende behoeften aan dataintegratie en -transformatie, waardoor organisaties hun dataverwerkingsworkflow effectiever kunnen optimaliseren.
Bij ETL wordt data uit verschillende bronnen geëxtraheerd en vervolgens getransformeerd naar het gewenste formaat van de gebruiker voordat deze in het datawarehouse wordt geladen. Snowflake is een krachtige SQL-engine waarmee complexe transformaties kunnen worden uitgevoerd met SQL-queries nadat de data is geladen.
Bij ELT wordt de data eerst in ruwe vorm in het datawarehouse geladen en daarna in het warehouse getransformeerd. Dankzij de scheiding van compute en storage in Snowflake kan ruwe data snel in het datawarehouse worden geladen. Transformaties worden uitgevoerd met virtuele warehouses. Snowflake ondersteunt ook semi-gestructureerde dataformaten zoals JSON en XML, waardoor ruwe data eenvoudig kan worden geladen zonder voorafgaande transformatie.
Snowflake ondersteunt een reeks ETL-tools, zodat organisaties hun favoriete tools kunnen gebruiken voor taken rondom dataintegratie en -transformatie. De volgende tools kunnen worden gebruikt op Snowflakes cloud-dataplatform om data te verwerken en naar Snowflake te verplaatsen voor verdere analyse:
Snowpipe is een service voor continue data-ingestie van Snowflake die bestanden binnen enkele minuten kan laden. Met Snowpipe kun je data in kleine groepen (micro-batches) laden, waardoor gebruikers in de hele organisatie binnen enkele minuten toegang hebben tot de data, wat de analyse eenvoudiger maakt.
Gebruikers geven het cloudopslagpad op waar databestanden worden geplaatst en ook de doeltabel in Snowflake waar de data wordt geladen. Dit is een geautomatiseerd laadproces waarbij Snowpipe automatisch detecteert wanneer er nieuwe bestanden aan het opslagpad zijn toegevoegd. Zodra deze nieuwe bestanden zijn gedetecteerd, neemt Snowpipe de data op in Snowflake en laadt deze in de opgegeven tabel.
Dit near-realtime proces zorgt ervoor dat de data zo snel mogelijk beschikbaar is. Snowpipe werkt op een serverloze architectuur, wat betekent dat het automatisch de compute-resources beheert die specifiek nodig zijn voor het data-ingestieproces.
Hoogoverarchitectuur van Snowpipe Streaming. Beeldbron: Snowflake-documentatie.
Snowflake is ontworpen als een datawarehouseoplossing die is geoptimaliseerd voor Online Analytical Processing (OLAP)-workloads. OLAP is een softwaretechnologie die wordt gebruikt om bedrijfsdata vanuit verschillende invalshoeken te analyseren. Dat maakt Snowflake de gouden standaard, omdat de architectuur en functies zijn afgestemd op grootschalige datataken, complexe queries en meer. Kenmerken van Snowflakes OLAP-benadering zijn de scheiding van compute en storage, massively parallel processing (MPP) en de ondersteuning van verschillende datastructuren om efficiënte analytische verwerking mogelijk te maken.
Daarnaast zijn er Online Transaction Processing (OLTP)-workloads, waarvoor Snowflake niet traditioneel is ontworpen. OLTP-workloads treden op wanneer een database zowel verzoeken om data ontvangt als meerdere wijzigingen in die data door verschillende gebruikers in de tijd; deze wijzigingen heten transacties. Ze kenmerken zich door hoge volumes korte transacties zoals inserts en updates. Deze kenmerken horen meer bij operationele databases dan bij datawarehouseoplossingen zoals Snowflake.
In Snowflake organiseert clustering data binnen micro-partities om de queryprestaties te optimaliseren. Standaard handelt Snowflake clustering automatisch af, maar voor grote tabellen met een natuurlijke ordening (bijv. tijdreeksdata) kan handmatige clustering nuttig zijn.
Handmatige clustering houdt in dat je een cluster key aanmaakt op kolommen die vaak in queries worden gebruikt. Dit maakt efficiëntere data pruning mogelijk, omdat Snowflake irrelevante partities kan overslaan tijdens queries. Gebruik handmatige clustering echter alleen wanneer de prestatievoordelen opwegen tegen de kosten van herclustering van grote datasets, omdat dit impact kan hebben op opslag- en computekosten.
Fail-safe is een functie voor dataterugwinning in Snowflake, ontworpen om data te herstellen die is verwijderd of gewijzigd buiten de Time Travel-retentieperiode. Terwijl Time Travel gebruikers in staat stelt historische data binnen een ingestelde periode (tot 90 dagen) te benaderen, is fail-safe een periode van zeven dagen na Time Travel waarin Snowflake data behoudt uitsluitend voor rampenherstel.
In tegenstelling tot Time Travel hebben gebruikers geen directe toegang tot fail-safe-data; tussenkomst van Snowflake Support is vereist.
Fail-safe biedt een extra laag databeveiliging, maar brengt hogere kosten met zich mee en moet worden gezien als laatste redmiddel na Time Travel.
Materialized views in Snowflake slaan de resultaten van een query fysiek op, waardoor sneller kan worden opgehaald bij complexe of vaak gebruikte queries. In tegenstelling tot standaardviews, die bij elke query opnieuw worden berekend, behouden materialized views de resultset totdat de data wordt bijgewerkt. Dit kan de queryprestaties aanzienlijk verbeteren, vooral voor analytische workloads met grote tabellen.
Use-cases voor materialized views zijn onder andere rapportagedashboards en geaggregeerde queryresultaten waarbij data niet vaak verandert. Houd er rekening mee dat materialized views periodiek onderhoud vereisen en de opslagkosten kunnen verhogen, dus ze zijn het meest geschikt voor statische of langzaam veranderende datasets.
Hier is een tabel met use-cases voor materialized views versus standaardviews in Snowflake:
| Aspect | Standaardviews | Materialized views |
|---|---|---|
| Dataopslag | Geen fysieke opslag; views worden bij querytijd berekend | Slaat queryresultaten fysiek op, wat de querysnelheid verbetert |
| Prestaties | Geschikt voor kleinere, infrequente queries | Ideaal voor grote of complexe datasets met frequente queries |
| Onderhoudskosten | Minimaal, omdat ze geen opslag nodig hebben | Hoger vanwege opslag en periodieke refreshvereisten |
| Use-cases | Ad-hocqueries en data-exploratie | Rapportagedashboards, voorgecomputeerde aggregaten |
Op basis van Snowflakes unieke architectuur moet je de ins en outs kennen en je kennis testen.
Shared-disk en shared-nothing zijn twee verschillende benaderingen van database- en datawarehousedesign. Het belangrijkste verschil is hoe ze de opslag en verwerking van data over meerdere nodes in een systeem beheren.
In een shared-disk-architectuur hebben de nodes in het systeem toegang tot schijfopslag, wat betekent dat elke node in dat systeem van elke schijf kan lezen of erop kan schrijven. Dit zorgt voor hoge beschikbaarheid, omdat het uitvallen van één node niet leidt tot dataverlies of onbeschikbaarheid. Het vereenvoudigt ook het databeheer, omdat data niet over nodes hoeft te worden gepartitioneerd of gerepliceerd.
Bij een shared-nothing-architectuur daarentegen heeft elke node in het systeem zijn eigen private opslag, die niet met andere nodes wordt gedeeld. De data wordt over de nodes gepartitioneerd, wat betekent dat elke node verantwoordelijk is voor een subset van de data. Dit biedt schaalbaarheid, omdat je meer nodes kunt toevoegen, elk met eigen opslag, wat leidt tot betere prestaties.
Wanneer je data in een stage in Snowflake laadt, heet dat ‘Staging’. Externe staging is wanneer de data in een andere cloudregio wordt bewaard, en interne staging is wanneer de data binnen Snowflake wordt bewaard. De interne staging is geïntegreerd in de Snowflake-omgeving en slaat bestanden en data op om in Snowflake-tabellen te laden. Het Snowflake-platform gebruikt externe opslagaanbieders zoals AWS, Google Cloud Platform en Azure om data op te slaan die moet worden geladen of opgeslagen.
Snowflake kent drie soorten caching. Hier is een tabel met een vergelijking en enkele use-cases per type:
| Type cache | Beschrijving | Duur | Use-case |
|---|---|---|---|
| Result cache | Cachet queryresultaten over alle virtuele warehouses, zodat herhaalde queries direct resultaten kunnen ophalen. | 24 uur | Versnellen van identieke queries met dezelfde resultaten |
| Local disk cache | Slaat recent benaderde data op de lokale schijf van elk virtueel warehouse op, voor snellere toegang tot veelgevraagde data. | Tot het virtuele warehouse wordt gepauzeerd | Verbetert prestaties van herhaalde queries op hetzelfde warehouse |
| Remote cache | Lange termijn opslag van data op remote schijven voor duurzaamheid, waardoor data toegankelijk blijft na storingen. | Permanent, met 99,999999999% duurzaamheid | Zorgt dat data beschikbaar en veerkrachtig is bij uitval van een datacenter |
Er zijn 3 verschillende statussen van het Snowflake Virtual Warehouse:
Snowflake behandelt datadistributie via micro-partities, die automatisch door Snowflake worden aangemaakt en beheerd. Dit zijn kleine opslagunits (elk 50–150 MB) die data in kolomformaat opslaan.
Snowflakes automatische clustering zorgt voor efficiënte datadistributie, waardoor handmatige partitionering minimaal nodig is. Door micro-partities is data pruning mogelijk, waarbij tijdens queries alleen relevante partities worden benaderd, wat de prestaties verbetert. In tegenstelling tot traditionele databases abstraheert Snowflake datapartitionering, zodat gebruikers de datadistributie niet handmatig hoeven te beheren. Dit zorgt voor betere schaalbaarheid en gebruiksgemak.
Hier is een tabel die deze mechanismen contrasteert:
| Mechanisme | Beschrijving | Voordeel |
|---|---|---|
| Micro-partities | Kleine, kolomgebaseerde opslagunits die data organiseren en comprimeren. | Maakt data pruning mogelijk, minder gescande data en snellere queries. |
| Automatische clustering | Snowflake onderhoudt automatisch de clustering van data binnen micro-partities en past zich aan bij dataveranderingen. | Vereenvoudigt databeheer, geen handmatige herclustering nodig |
| Data pruning | Alleen relevante micro-partities worden benaderd op basis van metadata, waardoor onnodig scannen wordt geminimaliseerd. | Verbetert queryprestaties door alleen benodigde data te benaderen |
De Metadata Service in Snowflake maakt deel uit van de Cloud Services-laag en speelt een cruciale rol bij query-optimalisatie en databeheer. Deze service houdt opslaglocaties van data, toegangspatronen en metadata voor tabellen, kolommen en partities bij. Door snel metadata op te halen, maakt deze service data pruning tijdens query-executie mogelijk, wat de hoeveelheid gescande data vermindert en prestaties verbetert.
Bovendien beheert de Metadata Service de Result Cache en werkt deze bij, wat zorgt voor snellere query-opvragingen wanneer vergelijkbare queries binnen korte tijd worden uitgevoerd. Al met al verhoogt de Metadata Service de query-efficiëntie en verlaagt ze het resourceverbruik.
Snowflakes functies auto-suspend en auto-resume helpen het gebruik van compute-resources te optimaliseren en kosten te verlagen. Wanneer een virtueel warehouse gedurende een gedefinieerde periode idle blijft, schakelt auto-suspend het warehouse automatisch uit om onnodige compute-kosten te vermijden.
Omgekeerd start de auto-resume-functie het warehouse automatisch wanneer een nieuwe query binnenkomt. Dit zorgt ervoor dat gebruikers alleen voor computetijd betalen wanneer het warehouse actief queries verwerkt.
Deze functies zijn vooral nuttig in omgevingen met sporadische workloads, omdat ze kostenefficiëntie optimaliseren en toch de beschikbaarheid behouden.
Een virtueel warehouse kan worden aangemaakt via de webinterface of met SQL. Dit zijn de 3 verschillende methoden:
CREATE [ OR REPLACE ] WAREHOUSE [ IF NOT EXISTS ] <name>
[ [ WITH ] objectProperties ]
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ objectParams ]Om een Snowflake-taak te maken, gebruik je “CREATE TASK”. Je moet de SQL-instructie of stored procedure in de taakdefinitie definiëren en ervoor zorgen dat je de benodigde rechten hebt om taken te maken. Dit zijn de stappen:
CREATE TASK’, gevolgd door de naam van je taak.WAREHOUSE’SCHEDULE’.AS’.CALL’ waarbij je de stored procedure gebruikt.Bijvoorbeeld:
CREATE TASK daily_sales_datacamp
WAREHOUSE = 'datacampwarehouse'
SCHEDULE = 'USING CRON 0 1 * * * UTC'
AS
CALL daily_sales_datacamp();Deze query laat zien hoe je met semi-gestructureerde JSON-data in Snowflake werkt:
SELECT
feedback_details:customer_id::INT AS customer_id,
feedback_details:feedback_text::STRING AS feedback_text,
feedback_details:timestamp::TIMESTAMP AS feedback_timestamp
FROM
customer_feedback
WHERE
feedback_details:customer_id::INT = 123; -- Replace 123 with the specific customer_id you're interested inOm de geschiedenis van een Snowflake-taak te controleren, kun je de ‘TASK_HISTORY’-tabelfunctie gebruiken. Deze geeft je gedetailleerde informatie over de uitvoering van taken binnen een specifieke tijdsperiode.
SELECT *
FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY(
TASK_NAME => '<task_name>',
START_TIME => '<start_time>',
END_TIME => '<end_time>'
))
ORDER BY SCHEDULED_TIME DESC;Hiervoor gebruik je de instructie ‘CREATE TEMPORARY TABLE’ in Snowflake. Hiermee maak je een sessiespecifieke tabel die alleen bestaat voor de door de gebruiker ingestelde duur.
CREATE TEMPORARY TABLE table_name (
column_name1 data_type1,
column_name2 data_type2,
...
);Snowflake biedt de functie CONVERT_TIMEZONE om timestamps tussen tijdzones om te zetten. Hier is een voorbeeld om een timestamp van UTC naar Eastern Standard Time (EST) om te zetten:
SELECT
customer_id,
CONVERT_TIMEZONE('UTC', 'America/New_York', order_timestamp) AS order_timestamp_est
FROM
orders;Vervang in deze query customer_id en order_timestamp door de specifieke kolommen in je tabel. Deze functie biedt flexibele tijdzoneconversies en is ideaal voor globale rapportage.
Je kunt een zero-copy clone van een tabel maken in Snowflake met de instructie CREATE TABLE ... CLONE. Deze clone deelt dezelfde onderliggende opslag, wat kosten en opslagruimte bespaart.
CREATE TABLE cloned_table_name CLONE original_table_name;Als je bijvoorbeeld een tabel met de naam sales_data wilt klonen, is de syntaxis:
CREATE TABLE sales_data_clone CLONE sales_data;Deze gekloonde tabel heeft dezelfde data en schema als het origineel op het moment van klonen. Eventuele wijzigingen aan de gekloonde tabel na de creatie hebben geen invloed op het origineel.
Je kunt de GROUP BY-clausule gebruiken met ORDER BY en LIMIT om de top 5 meest voorkomende waarden in een specifieke kolom op te halen. Als je bijvoorbeeld de top 5 meest voorkomende producten in de kolom product_id wilt vinden:
SELECT
product_id,
COUNT(*) AS frequency
FROM
sales
GROUP BY
product_id
ORDER BY
frequency DESC
LIMIT 5;Deze query groepeert de kolom product_id op frequentie, sorteert aflopend en beperkt de resultaten tot de top 5, zodat je de meest verkochte producten ziet.
Bij de voorbereiding op elk sollicitatiegesprek is het belangrijk om het volgende te doen:
Tot slot: wees zelfverzekerd en geef het je best!
In dit artikel hebben we Snowflake-sollicitatievragen voor 4 verschillende niveaus behandeld:
Zoek je bronnen om je Snowflake-vaardigheden op te frissen of te testen? Bekijk dan onze tutorials Introduction to Snowflake en Getting Started with Data Analysis in Snowflake using Python and SQL en ook onze cursus Introduction to NoSQL, waar je leert hoe je Snowflake gebruikt om met big data te werken.
Luister ook naar onze podcastepisode met voormalig Snowflake-CEO Bob Muglia over ‘Why AI will Change Everything’.
Begin vandaag nog met je Snowflake-reis!
Cursus
Cursus
blog
Adel Nehme
15 min
