
Corso
Capire il Data Engineering
2 h
362.2K
Iniziamo con le domande fondamentali sui concetti chiave di Snowflake.
Snowflake è una piattaforma di data warehousing basata sul cloud che separa il calcolo dallo storage, permettendo agli utenti di scalare in modo indipendente le risorse di elaborazione e l’archiviazione dei dati. Questo approccio è più conveniente e offre alte prestazioni.
Una delle principali funzionalità è l’auto-scaling, che consente di adeguare le risorse in base alla domanda dei carichi di lavoro e supporta ambienti multi-cloud. Un’altra caratteristica fondamentale è l’approccio di piattaforma alla condivisione dei dati, che garantisce un accesso sicuro e semplice ai dati in tutta l’organizzazione, senza spostamento dei dati.
L’architettura di Snowflake è il suo principale punto di forza. È stata progettata per il cloud, con caratteristiche come l’architettura multi-cluster a dati condivisi e notevoli capacità di storage. L’architettura di Snowflake è suddivisa in tre livelli:
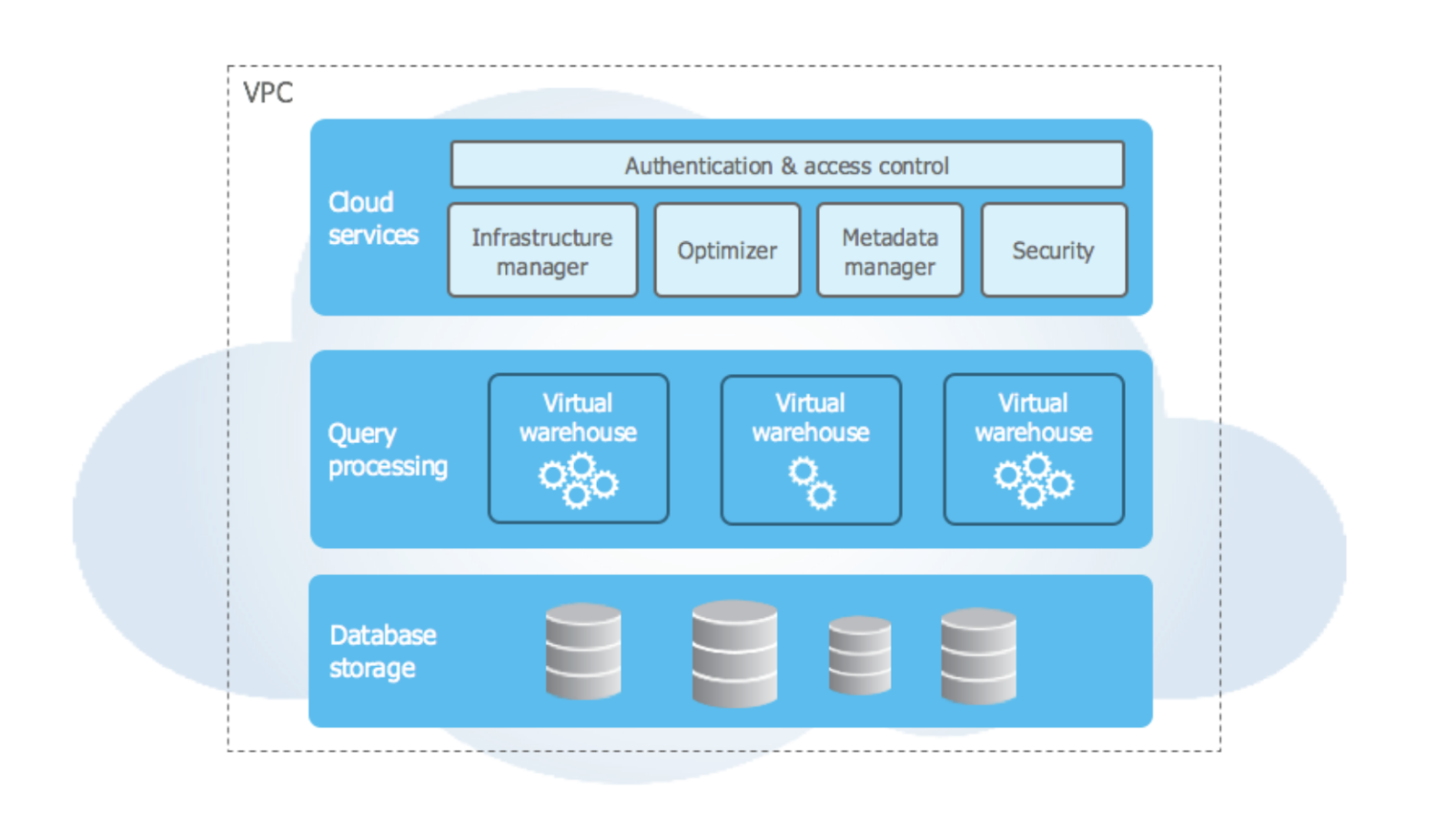
Architettura di alto livello di Snowflake. Fonte immagine: documentazione Snowflake.
Le micro-partizioni sono un elemento fondamentale dell’approccio di Snowflake all’archiviazione dei dati. Sono unità di storage compresse, gestite e in formato colonnare che Snowflake utilizza per archiviare dati con dimensioni comprese tra 50 MB e 150 MB. Il formato colonnare consente una compressione dei dati efficiente e schemi di codifica ottimali.
La capacità delle micro-partizioni di comprimere i dati consente di gestire in modo efficiente grandi volumi, riducendo lo spazio fisico richiesto e quindi i costi di storage. Anche le prestazioni delle query migliorano grazie al data pruning, che prevede l’accesso solo alle micro-partizioni rilevanti. Questo accesso selettivo è molto vantaggioso per il recupero e l’analisi dei dati.
Le micro-partizioni sono gestite automaticamente da Snowflake, il che elimina la necessità di partizionamento o indicizzazione manuale dei dati, garantendo un’archiviazione ottimale e riducendo anche i costi amministrativi.
I warehouse virtuali sono responsabili dell’esecuzione di tutte le attività di elaborazione dei dati. Di conseguenza, hanno un impatto rilevante su scalabilità, prestazioni e gestione dei costi delle attività di elaborazione.
Le loro funzionalità di scalabilità dinamica consentono agli utenti di aumentare o ridurre le risorse di calcolo in base ai requisiti del carico di lavoro. Quando la domanda di elaborazione dei dati aumenta, puoi fornire risorse di calcolo aggiuntive senza impattare le operazioni in corso.
Ogni warehouse virtuale non influisce sugli altri, garantendo alte prestazioni e coerenza per attività specifiche come le analisi sensibili al tempo. Durante l’esecuzione delle attività, paghi per le risorse di calcolo utilizzate, offrendo una migliore gestione dei costi rispetto alle soluzioni di data warehousing tradizionali.
La seguente tabella confronta i warehouse virtuali con le risorse di calcolo tradizionali:
| Funzionalità | Warehouse virtuali (Snowflake) | Risorse di calcolo tradizionali |
|---|---|---|
| Scalabilità | Auto-scaling, multi-cluster; possono aumentare o ridurre la dimensione in base alla domanda senza impattare le operazioni. | Capacità tipicamente fissa, con upgrade manuali per scalare. |
| Isolamento | Isola i cluster di calcolo, così i carichi concorrenti funzionano in modo indipendente. | La condivisione delle risorse spesso porta a competizione tra attività. |
| Gestione dei costi | Paghi solo per il tempo attivo e puoi scalare secondo necessità, minimizzando i costi di inattività. | Costi fissi indipendentemente dalle variazioni di carico, con potenziali costi di inattività più elevati. |
| Ottimizzazione delle prestazioni | La scalabilità indipendente consente regolazioni specifiche per singoli compiti, mantenendo alte prestazioni per query sensibili al tempo. | Opzioni di tuning limitate, poiché la scalabilità influisce su tutti i carichi allo stesso modo. |
ANSI SQL sta per American National Standards Institute Structured Query Language ed è il linguaggio standard per i sistemi di gestione di database relazionali.
Ciò significa che gli utenti Snowflake possono utilizzare la sintassi e le operazioni SQL familiari per interrogare i dati, come i JOIN, rendendo questa caratteristica ideale per chi ha esperienza SQL e vuole passare a Snowflake. Un altro vantaggio della compatibilità con ANSI SQL è l’integrazione fluida di vari tipi di dati, che consente di interrogare i dati senza doverli prima trasformare o caricare in uno schema predefinito.
Se vuoi ottenere una certificazione sulla piattaforma Snowflake, dai un’occhiata a Qual è la migliore certificazione Snowflake per il 2026?
La funzionalità Time Travel di Snowflake consente di accedere e interrogare i dati storici per un periodo specificato, in genere fino a 90 giorni, a seconda del tipo di account. Questa funzione è utile per il ripristino dei dati, per audit e per confronti. Ad esempio, gli utenti possono ripristinare tabelle eliminate accidentalmente o consultare stati precedenti dei dati.
Time Travel riduce la necessità di backup esterni e semplifica il versioning dei dati, offrendo funzionalità integrate di ripristino e analisi retrospettiva.
La condivisione dei dati di Snowflake consente alle organizzazioni di condividere dati live in modo sicuro e in tempo reale con utenti o partner esterni senza creare copie aggiuntive. Questo è reso possibile dalla funzionalità Secure Data Sharing di Snowflake, che sfrutta l’architettura multi-cluster a dati condivisi per fornire accesso diretto ai dati.
I vantaggi della condivisione includono:
Il cloning a copia zero è una funzione di Snowflake che consente di creare una copia di un database, schema o tabella senza duplicare lo storage sottostante. Quando si crea un clone a copia zero, questo punta ai dati originali e memorizza solo le modifiche apportate ai dati clonati, con notevoli risparmi di spazio. Questa funzione è preziosa per creare ambienti di sviluppo e test o per generare snapshot storici senza aumentare i costi di archiviazione. Migliora l’efficienza della gestione dei dati consentendo duplicazioni rapide ed economiche per vari casi d’uso.
Ti senti sicuro con le domande di base? Passiamo ad alcune domande più avanzate.
Snowflake mira a garantire il massimo livello di protezione e sicurezza dei dati per i propri utenti grazie all’implementazione della crittografia always-on. Si tratta della crittografia automatica dei dati senza necessità di impostazioni o configurazioni da parte degli utenti, assicurando che tutti i tipi di dati, dai grezzi ai metadati, siano protetti con un algoritmo di crittografia forte. La crittografia è gestita tramite un modello gerarchico di chiavi in cui una master key crittografa le altre chiavi e Snowflake esegue la rotazione di queste chiavi per aumentare la sicurezza.
Durante il trasferimento, Snowflake utilizza TLS (Transport Layer Security) per crittografare i dati in transito tra Snowflake e i client. Questa crittografia end-to-end garantisce che i dati siano sempre crittografati, ovunque si trovino nel ciclo di vita, riducendo il rischio di perdite e violazioni.
I processi Extract, Transform, Load (ETL) ed Extract, Load, Transform (ELT) sono ampiamente utilizzati sulla piattaforma Snowflake grazie alla sua architettura e alle sue capacità. La piattaforma copre un’ampia gamma di esigenze di integrazione e trasformazione dei dati, consentendo alle organizzazioni di ottimizzare in modo efficace i flussi di elaborazione.
Nell’ETL, i dati vengono estratti da varie fonti e poi trasformati nel formato desiderato prima di essere caricati nel data warehouse. Snowflake è un potente motore SQL che consente trasformazioni complesse tramite query SQL dopo il caricamento dei dati.
Nell’ELT, i dati vengono prima caricati nel data warehouse in forma grezza e poi trasformati nel warehouse. La separazione tra capacità di calcolo e storage di Snowflake consente di caricare rapidamente i dati grezzi. Le trasformazioni vengono eseguite utilizzando i warehouse virtuali. Snowflake supporta anche formati semi-strutturati come JSON e XML, rendendo semplice caricare i dati grezzi nel data warehouse senza doverli trasformare preventivamente.
Snowflake supporta una gamma di strumenti ETL, consentendo alle organizzazioni di usare quelli preferiti per le attività di integrazione e trasformazione. I seguenti strumenti possono essere utilizzati sulla piattaforma cloud di Snowflake per elaborare e spostare i dati in Snowflake per ulteriori analisi:
Snowpipe è un servizio di ingestione continua dei dati fornito da Snowflake che può caricare file in pochi minuti. Con Snowpipe puoi caricare dati in piccoli gruppi (micro-batch), consentendo agli utenti in tutta l’organizzazione di accedere ai dati in pochi minuti, facilitandone l’analisi.
Gli utenti specificano il percorso di cloud storage in cui verranno posizionati i file di dati e anche la tabella di destinazione in Snowflake, dove i dati verranno caricati. Si tratta di un processo di caricamento automatizzato: Snowpipe rileva automaticamente quando nuovi file vengono aggiunti al percorso di storage. Una volta rilevati, Snowpipe ingerisce i dati in Snowflake e li carica nella tabella specificata.
Questo processo quasi in tempo reale garantisce che i dati siano disponibili il prima possibile. Snowpipe opera con un’architettura serverless, il che significa che gestisce automaticamente le risorse di calcolo specifiche necessarie per l’ingestione.
Architettura di alto livello di Snowpipe Streaming. Fonte immagine: documentazione Snowflake.
Snowflake è stato progettato come soluzione di data warehousing ottimizzata per carichi OLAP (Online Analytical Processing). L’OLAP è una tecnologia software utilizzata per analizzare i dati aziendali da diversi punti di vista. Snowflake è quindi lo standard di riferimento poiché l’architettura e le funzionalità sono pensate per supportare attività su larga scala, query complesse e altro. Le caratteristiche dell’approccio OLAP di Snowflake includono separazione tra calcolo e storage, elaborazione massivamente parallela (MPP) e supporto di diverse strutture dati per abilitare un’analisi efficiente.
Esistono anche carichi OLTP (Online Transaction Processing), per i quali Snowflake non è tradizionalmente progettato. I carichi OLTP si verificano quando un database riceve sia richieste di dati sia numerose modifiche da più utenti nel tempo; queste modifiche sono chiamate transazioni. Sono caratterizzati da alti volumi di transazioni brevi, come insert e update. Queste esigenze si concentrano più su database operazionali che su soluzioni di data warehousing come Snowflake.
In Snowflake, il clustering organizza i dati all’interno delle micro-partizioni per ottimizzare le prestazioni delle query. Per impostazione predefinita, Snowflake gestisce automaticamente il clustering, ma per tabelle grandi con un ordine naturale (ad esempio dati di serie storiche) il clustering manuale può essere vantaggioso.
Il clustering manuale prevede la creazione di una chiave di cluster sulle colonne usate più spesso nelle query. Ciò consente un pruning più efficiente, poiché Snowflake può saltare le partizioni irrilevanti durante le query. Tuttavia, il clustering manuale dovrebbe essere utilizzato solo quando i benefici in termini di prestazioni superano i costi di ri-clustering di grandi dataset, poiché può incidere su storage e calcolo.
Il fail-safe è una funzionalità di recupero dati in Snowflake progettata per ripristinare dati eliminati o modificati oltre il periodo di conservazione di Time Travel. Mentre Time Travel consente l’accesso ai dati storici entro una finestra definita (fino a 90 giorni), il fail-safe è un periodo di sette giorni successivo a Time Travel durante il quale Snowflake conserva i dati esclusivamente per il disaster recovery.
A differenza di Time Travel, gli utenti non possono accedere direttamente ai dati in fail-safe: è necessario l’intervento del Supporto Snowflake.
Il fail-safe fornisce un ulteriore livello di protezione dei dati ma comporta costi più elevati e andrebbe usato come ultima risorsa dopo Time Travel.
Le viste materializzate in Snowflake memorizzano fisicamente i risultati di una query, consentendo un recupero più rapido per query complesse o molto frequenti. A differenza delle viste standard, ricalcolate a ogni esecuzione, le viste materializzate mantengono il result set fino all’aggiornamento dei dati. Questo può migliorare significativamente le prestazioni, in particolare per carichi analitici su tabelle grandi.
I casi d’uso includono dashboard di reportistica e risultati aggregati dove i dati cambiano poco. Tuttavia, le viste materializzate richiedono manutenzione periodica e possono aumentare i costi di storage, quindi sono più adatte a dataset statici o a variazione lenta.
Ecco una tabella che copre i casi d’uso delle viste materializzate vs. viste standard in Snowflake:
| Aspetto | Viste standard | Viste materializzate |
|---|---|---|
| Archiviazione dati | Nessuno storage fisico; le viste sono calcolate al momento della query | Memorizza fisicamente i risultati, migliorando la velocità delle query |
| Prestazioni | Adatte a query piccole e poco frequenti | Ideali per dataset grandi o complessi con query frequenti |
| Costo di manutenzione | Minimo, poiché non richiedono storage | Più elevato per via di storage e refresh periodici |
| Casi d’uso | Query ad hoc ed esplorazione dati | Dashboard di reportistica, aggregazioni pre-calcolate |
Data l’architettura unica di Snowflake, è importante conoscerla a fondo e mettersi alla prova.
Le architetture shared-disk e shared-nothing sono due approcci diversi alla progettazione di database e data warehouse. La differenza principale riguarda la gestione dello storage e dell’elaborazione dei dati tra più nodi in un sistema.
In un’architettura shared-disk, i nodi del sistema hanno accesso allo storage su disco, il che significa che qualsiasi nodo può leggere o scrivere su qualunque disco del sistema. Questo offre alta disponibilità, poiché il guasto di un singolo nodo non causa perdita o indisponibilità dei dati. Inoltre, semplifica la gestione, dato che i dati non devono essere partizionati o replicati tra nodi.
Al contrario, nell’architettura shared-nothing ogni nodo ha uno storage privato non condiviso con altri. I dati sono partizionati tra i nodi, quindi ciascuno è responsabile di un sottoinsieme dei dati. Questo offre scalabilità, poiché è possibile aggiungere nodi ognuno con il proprio storage, migliorando le prestazioni.
Quando carichi dati in uno stage in Snowflake, si parla di “Staging”. Lo staging esterno si ha quando i dati sono conservati in un altro cloud, mentre lo staging interno è quando i dati sono mantenuti all’interno di Snowflake. Lo staging interno è integrato nell’ambiente Snowflake e memorizza file e dati da caricare nelle tabelle di Snowflake. La piattaforma Snowflake utilizza provider di storage esterni come AWS, Google Cloud Platform e Azure per archiviare dati da caricare o salvare.
Snowflake comprende tre tipi di caching. Ecco una tabella che li confronta e ne evidenzia alcuni casi d’uso:
| Tipo di cache | Descrizione | Durata | Caso d’uso |
|---|---|---|---|
| Result cache | Memorizza i risultati delle query in tutti i warehouse virtuali, così le query ripetute possono recuperare i risultati istantaneamente. | 24 ore | Accelerare query identiche con gli stessi risultati |
| Local disk cache | Archivia i dati recentemente accessi sul disco locale di ciascun warehouse virtuale, permettendo recuperi più rapidi per dati consultati di frequente. | Fino alla sospensione del warehouse virtuale | Migliora le prestazioni delle query ripetute sullo stesso warehouse |
| Remote cache | Archiviazione a lungo termine su dischi remoti per durabilità, consentendo l’accesso ai dati anche dopo interruzioni del servizio. | Permanente, con durabilità al 99,999999999% | Garantisce disponibilità e resilienza in caso di guasto del data center |
Esistono 3 stati diversi del Virtual Warehouse di Snowflake:
Snowflake gestisce la distribuzione dei dati tramite micro-partizioni, create e gestite automaticamente. Queste micro-partizioni sono piccole unità di storage (50–150 MB ciascuna) che conservano i dati in formato colonnare.
L’automatic clustering di Snowflake garantisce una distribuzione efficiente, riducendo al minimo la necessità di partizionamento manuale. L’uso delle micro-partizioni consente il data pruning, in cui durante le query vengono accedute solo le partizioni rilevanti, migliorando le prestazioni. Diversamente dai database tradizionali, Snowflake astrae il partizionamento, così gli utenti non devono gestire manualmente la distribuzione, ottenendo migliore scalabilità e semplicità d’uso.
Ecco una tabella che mette a confronto questi meccanismi:
| Meccanismo | Descrizione | Vantaggio |
|---|---|---|
| Micro-partizioni | Piccole unità di storage colonnare che organizzano e comprimono i dati. | Abilitano il data pruning, riducendo i dati scansionati per query più veloci. |
| Automatic clustering | Snowflake mantiene automaticamente il clustering dei dati nelle micro-partizioni, adattandosi ai cambiamenti. | Semplifica la gestione, senza necessità di re-clustering manuale |
| Data pruning | Si accede solo alle micro-partizioni rilevanti in base ai metadati, minimizzando la scansione inutile. | Migliora le prestazioni delle query accedendo solo ai dati necessari |
Il Metadata Service in Snowflake fa parte del Cloud Services Layer e svolge un ruolo critico nell’ottimizzazione delle query e nella gestione dei dati. Questo servizio tiene traccia delle posizioni di archiviazione dei dati, dei pattern di accesso e dei metadati per tabelle, colonne e partizioni. Recuperando rapidamente i metadati, abilita il data pruning durante l’esecuzione delle query, riducendo la quantità di dati scansionati e migliorando le prestazioni.
Inoltre, il Metadata Service gestisce e aggiorna la Result Cache, consentendo recuperi più rapidi quando query simili vengono eseguite in un breve intervallo di tempo. Nel complesso, il Metadata Service aumenta l’efficienza delle query e riduce il consumo di risorse.
Le funzionalità di auto-suspend e auto-resume di Snowflake aiutano a ottimizzare l’uso delle risorse di calcolo e a ridurre i costi. Quando un warehouse virtuale resta inattivo per un periodo definito, l’auto-suspend lo arresta automaticamente per evitare addebiti inutili.
Al contrario, l’auto-resume avvia automaticamente il warehouse quando arriva una nuova query. Ciò assicura che si paghi il tempo di calcolo solo quando il warehouse elabora attivamente query.
Queste funzioni sono particolarmente utili in ambienti con carichi sporadici, poiché ottimizzano i costi mantenendo la disponibilità.
Un warehouse virtuale può essere creato tramite interfaccia web o usando SQL. Ecco i 3 metodi:
CREATE [ OR REPLACE ] WAREHOUSE [ IF NOT EXISTS ] <name>
[ [ WITH ] objectProperties ]
[ [ WITH ] TAG ( <tag_name> = '<tag_value>' [ , <tag_name> = '<tag_value>' , ... ] ) ]
[ objectParams ]Per creare un task in Snowflake, devi usare “CREATE TASK”. Dovrai definire l’istruzione SQL o la stored procedure nella definizione del task e assicurarti di avere i permessi necessari per creare task. Ecco i passaggi:
CREATE TASK’, seguito dal nome del task.WAREHOUSE’SCHEDULE’.AS’.CALL’ usando la stored procedure.Per esempio:
CREATE TASK daily_sales_datacamp
WAREHOUSE = 'datacampwarehouse'
SCHEDULE = 'USING CRON 0 1 * * * UTC'
AS
CALL daily_sales_datacamp();Questa query mostra come lavorare con dati JSON semi-strutturati in Snowflake:
SELECT
feedback_details:customer_id::INT AS customer_id,
feedback_details:feedback_text::STRING AS feedback_text,
feedback_details:timestamp::TIMESTAMP AS feedback_timestamp
FROM
customer_feedback
WHERE
feedback_details:customer_id::INT = 123; -- Replace 123 with the specific customer_id you're interested inPer verificare la cronologia di un task in Snowflake, puoi utilizzare la funzione di tabella ‘TASK_HISTORY’. Fornisce informazioni dettagliate sulla cronologia di esecuzione dei task in un intervallo temporale specifico.
SELECT *
FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY(
TASK_NAME => '<task_name>',
START_TIME => '<start_time>',
END_TIME => '<end_time>'
))
ORDER BY SCHEDULED_TIME DESC;Devi usare l’istruzione ‘CREATE TEMPORARY TABLE’ in Snowflake. Questo crea una tabella specifica di sessione che esiste solo per la durata impostata dall’utente.
CREATE TEMPORARY TABLE table_name (
column_name1 data_type1,
column_name2 data_type2,
...
);Snowflake fornisce la funzione CONVERT_TIMEZONE per convertire timestamp tra fusi orari. Ecco un esempio di conversione da UTC a Eastern Standard Time (EST):
SELECT
customer_id,
CONVERT_TIMEZONE('UTC', 'America/New_York', order_timestamp) AS order_timestamp_est
FROM
orders;In questa query, sostituisci customer_id e order_timestamp con le colonne specifiche della tua tabella. Questa funzione consente conversioni flessibili dei fusi orari, ideale per la reportistica globale.
Puoi creare un clone a copia zero di una tabella in Snowflake usando l’istruzione CREATE TABLE ... CLONE. Questo clone condivide lo storage sottostante, risparmiando costi e spazio.
CREATE TABLE cloned_table_name CLONE original_table_name;Per esempio, per clonare una tabella chiamata sales_data, la sintassi sarebbe:
CREATE TABLE sales_data_clone CLONE sales_data;Questa tabella clonata avrà gli stessi dati e schema dell’originale al momento del cloning. Eventuali modifiche apportate al clone dopo la creazione non influenzeranno l’originale.
Puoi usare GROUP BY con ORDER BY e LIMIT per recuperare i 5 valori più frequenti in una colonna specifica. Ad esempio, se vuoi trovare i 5 prodotti più comuni nella colonna product_id:
SELECT
product_id,
COUNT(*) AS frequency
FROM
sales
GROUP BY
product_id
ORDER BY
frequency DESC
LIMIT 5;Questa query raggruppa la colonna product_id per frequenza, ordina in ordine decrescente e limita i risultati ai primi 5, mostrando i prodotti più venduti.
Quando ti prepari per un colloquio è importante fare quanto segue:
Ultimo ma non meno importante, sii sicuro di te e dai il massimo!
In questo articolo abbiamo coperto domande da colloquio su Snowflake per 4 livelli diversi:
Se cerchi risorse per ripassare o mettere alla prova le tue abilità su Snowflake, dai un’occhiata ai nostri tutorial su Introduction to Snowflake e Getting Started with Data Analysis in Snowflake using Python and SQL, e anche al nostro corso Introduction to NoSQL, dove imparerai a usare Snowflake per lavorare con big data.
Ascolta anche il nostro episodio di podcast con l’ex CEO di Snowflake Bob Muglia su “Why AI will Change Everything”.
Inizia oggi il tuo percorso con Snowflake!
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min

