Kurs
Python'da Unsupervised Learning
4 sa
181.2K

Makine öğrenmesi, insanların öğrenme biçimini taklit eden yöntemleri anlamaya ve oluşturmaya adanmış bir yapay zeka alt alanıdır. Bu yöntemler, bazı görevler kümesi üzerindeki performansı iyileştirmek için algoritma ve verilerin kullanımını içerir ve genellikle en yaygın üç öğrenme türünden birine girer:
Skikit-learn, sklearn olarak da bilinen, açık kaynaklı ve sağlam bir Python makine öğrenmesi kütüphanesidir. Python’da makine öğrenmesi ve istatistiksel modellerin uygulanmasını basitleştirmek için oluşturulmuştur.
Kütüphane, uygulayıcıların tutarlı bir arayüz aracılığıyla çok çeşitli gözetimli ve gözetimsiz makine öğrenmesi algoritmalarını hızla uygulamasını sağlar. Sklearn, SciPy üzerine inşa edilmiştir ve NumPy dizileri, SciPy seyrek matrisleri ve Pandas DataFrame’leri gibi sayısal dizilere dönüştürülebilen tüm diğer veri türleri olarak saklanan her türlü sayısal veri üzerinde çalışır.
Bu uygulamalı sklearn eğitiminde, veri işleme, model eğitimi ve model değerlendirme gibi makine öğrenmesi yaşam döngüsünün çeşitli yönlerini ele alacağız.
Kodla birlikte ilerlemek için bu DataCamp çalışma alanına göz atın.
Keşfedeceğimiz sklearn’ün ilk yönü veridir; Scikit-learn, standart bazı makine öğrenmesi veri kümeleriyle birlikte gelir, bu da onları harici bir web sitesinden veya veritabanından indirmeniz gerekmediği anlamına gelir.
sklearn’de bulunan oyuncak veri kümelerine örnek olarak sınıflandırma için iris veri kümesi ve regresyon için diyabet veri kümesi verilebilir. Bizim örneğimizde şarap veri kümesini kullanacağız.
Hafızaya yükleyelim:
from sklearn.datasets import load_wine
wine_data = load_wine() Yukarıdaki kodu çalıştırmak, verileri ve içerdiği verilerle ilgili üst verileri içeren sözlük benzeri bir nesne döndürür.
İhtiyacımız olan veri, .data özniteliğinde, load_wine() tarafından döndürülür. Buna, wine_data örneğinin bir özniteliği olarak şu şekilde erişebiliriz:
wine_data.dataBu, N örnek sayısını ve M özellik sayısını ifade edecek şekilde N x M boyutunda bir dizi döndürür.
Bu bilgiyi kullanarak verimizi bir pandas DataFrame’ine yükleyelim; bu yapı verileri düzenlemek ve analiz etmek için çok daha kolaydır.
import pandas as pd
from sklearn.datasets import load_wine
wine_data = load_wine()
# Convert data to pandas dataframe
wine_df = pd.DataFrame(wine_data.data, columns=wine_data.feature_names)
# Add the target label
wine_df["target"] = wine_data.target
# Take a preview
wine_df.head()
Artık biraz veri keşfi yapmaya hazırsınız.
Pandas DataFrame’leri, sütunlardan oluşan ve farklı veri adımları içerebilen iki boyutlu, etiketli veri yapıları olarak tanımlanır. Bir DataFrame’i kavramsallaştırmanın en kolay yolu, onu bir araya gelmiş üç bileşen olarak düşünmektir; bu bileşenler 1) veriler, 2) bir indeks ve 3) sütunlardır.
Veri keşfi bu makalenin ana odağı değildir ancak herhangi bir veri projesinde son derece önemli bir adımdır – bunun hakkında daha fazlasını Python Keşifsel Veri Analizi eğitimimizde öğrenebilirsiniz. Veri kümesinin neler içerdiğine dair daha iyi bir fikir edinmek için kısa bir keşif yapacağız; bu, verileri nasıl işleyeceğimize dair bize daha iyi bir fikir verecek.
Yapacağımız ilk şey, pandas DataFrame’imiz üzerinde info() metodunu çağırmak; bu, DataFrame’de yer alan şarap verilerinin kısa bir özetini yazdıracaktır.
wine_df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 178 entries, 0 to 177
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 alcohol 178 non-null float64
1 malic_acid 178 non-null float64
2 ash 178 non-null float64
3 alcalinity_of_ash 178 non-null float64
4 magnesium 178 non-null float64
5 total_phenols 178 non-null float64
6 flavanoids 178 non-null float64
7 nonflavanoid_phenols 178 non-null float64
8 proanthocyanins 178 non-null float64
9 color_intensity 178 non-null float64
10 hue 178 non-null float64
11 od280/od315_of_diluted_wines 178 non-null float64
12 proline 178 non-null float64
13 target 178 non-null int64
dtypes: float64(13), int64(1)
memory usage: 19.6 KB
"""Bu hücreyi çalıştırdıktan sonra şunları öğrenirsiniz:
Ayrıca veri kümesindeki her özellik için tanımlayıcı istatistikler elde etmek üzere DataFrame’imizde describe() metodunu da çağırabiliriz.
Örneğin:
wine_df.describe() 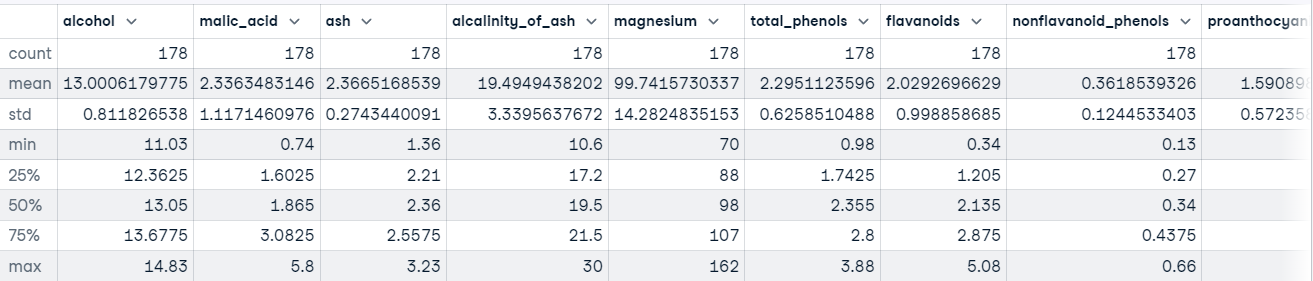
Ayrıca her özellikte hangi tür değerlerin tutulduğuna dair bir fikir sahibi olmak istersiniz. Bunu öğrenmenin en hızlı yolu, ilk beş veri satırını görüntülemek için head() metodunu veya son beş satırı görüntülemek için tail() metodunu kullanmaktır.
wine_df.tail()
Bu kodu çalıştırmak, özelliklerimizin farklı ölçeklerde olduğunu gösterir; bu durum, lojistik regresyon gibi Gradyan İnişi tabanlı algoritmalarla ve destek vektör makineleri gibi mesafe tabanlı algoritmalarla uğraşırken sorunlara yol açabilir. Bunun nedeni, bu algoritmaların veri noktalarının aralığına duyarlı olmalarıdır.
Normal bir makine öğrenmesi iş akışında bu süreç çok daha kapsamlı olacaktır, ancak bu eğitimin ana odağı olan Scikit-learn ile uyumlu kalmak için veri işlemeye geçeceğiz.
Pandas hakkında daha fazla bilgiyi Python Pandas Eğitimi: Yeni Başlayanlar için Kapsamlı Rehber’de edinebilirsiniz.
Verimizin nasıl göründüğüne dair fena olmayan bir anlayışa sahibiz. Bu noktaya ulaştığınızda genellikle, veriyi bir makine öğrenmesi modeline beslemek üzere hazırlamaya başlamaya hazırsınız demektir.
Veri işleme, makine öğrenmesi iş akışında hayati bir adımdır çünkü gerçek dünyadan gelen veri dağınıktır. Şunları içerebilir:
Veriyi bir makine öğrenmesi modeline beslemeden önce tüm bunlarla başa çıkmalısınız; aksi takdirde model bu hataları yaklaşım fonksiyonuna dahil eder – yeni örneklerde de hata yapmayı öğrenir. Bu durum, ünlü makine öğrenmesi sözünü doğurmuştur: “Çöp girerse, çöp çıkar.”
Bir diğer neden de makine öğrenmesi modellerinin genellikle sayısal veri gerektirmesidir.
İlk bakışta, verimizde farklı ölçeklerde olmaları dışında pek sorun görünmüyor. Bu sorunu gidermek için sklearn’ün StandardScaler sınıfını kullanarak özellikleri standartlaştıralım; bu, özellikleri ortalaması 0 ve standart sapması 1 olacak şekilde standartlaştıracaktır.
Kod şöyle:
from sklearn.preprocessing import StandardScaler
# Split data into features and label
X = wine_df[wine_data.feature_names].copy()
y = wine_df["target"].copy()
# Instantiate scaler and fit on features
scaler = StandardScaler()
scaler.fit(X)
# Transform features
X_scaled = scaler.transform(X.values)
# View first instance
print(X_scaled[0])
"""
[ 1.51861254 -0.5622498 0.23205254 -1.16959318 1.91390522 0.80899739
1.03481896 -0.65956311 1.22488398 0.25171685 0.36217728 1.84791957
1.01300893]
"""Modeli eğitmeye geçelim.
Bir makine öğrenmesi modeli tahmin yapmadan önce, bir yaklaşım fonksiyonunu öğrenmek için bir veri kümesi üzerinde eğitilmelidir.
Peki modelin daha önce görmediği veriler üzerinde iyi performans gösterip göstermediğini nasıl bileceğiz? Test etmedikçe bilemeyiz.
Bir makine öğrenmesi modelini, başkalarını etkilediği bir ortama yerleştirmeden önce test etmenin bir yolu, eğitim verilerini eğitim ve test seti olarak bölmek ve modelin öğrendiklerini değerlendirmek için test setini kullanmaktır; buna çevrimdışı değerlendirme denir.
Verileri eğitim ve test setlerine bölmenin birkaç yolu vardır, ancak scikit-learn’ün bunu bizim adımıza yapan yerleşik bir fonksiyonu vardır: train_test_split().
Bu fonksiyonu, verilerimizin %70’inin modeli eğitmek, %30’unun ise modelin görünmeyen örneklere genelleme becerisini değerlendirmek için kullanılacağı şekilde bölmek üzere kullanacağız.
from sklearn.model_selection import train_test_split
# Split data into train and test
X_train_scaled, X_test_scaled, y_train, y_test = train_test_split(X_scaled,
y,
train_size=.7,
random_state=25)
# Check the splits are correct
print(f"Train size: {round(len(X_train_scaled) / len(X) * 100)}% \n\
Test size: {round(len(X_test_scaled) / len(X) * 100)}%")
"""
Train size: 70%
Test size: 30%
Şimdi birkaç model oluşturalım.
sklearn sayesinde, bir makine öğrenmesi modeli oluşturmak son derece basittir.
Şarabın sınıfını tahmin etmek için üç model kuracağız:
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
# Instnatiating the models
logistic_regression = LogisticRegression()
svm = SVC()
tree = DecisionTreeClassifier()
# Training the models
logistic_regression.fit(X_train_scaled, y_train)
svm.fit(X_train_scaled, y_train)
tree.fit(X_train_scaled, y_train)
# Making predictions with each model
log_reg_preds = logistic_regression.predict(X_test_scaled)
svm_preds = svm.predict(X_test_scaled)
tree_preds = tree.predict(X_test_scaled)Bir sonraki adım, modellerin görünmeyen örneklere ne kadar iyi genelleme yaptığını değerlendirmektir.
Model değerlendirme, modelin görünmeyen örneklere ne kadar iyi genelleme yaptığını test etmek için yapılır. Scikit-learn, eğitilmiş bir modelin performansını değerlendirmek için bir dizi sınıflandırma ve regresyon metriği sağlar.
Bizim kullanım durumumuz için, classification_report() fonksiyonunu metrics modülünden kullanarak precision, recall, f1_score, accuracy vb. gibi başlıca sınıflandırma metriklerini gösteren metin tabanlı bir rapor oluşturacağız.
Koddaki görünümü şöyle:
from sklearn.metrics import classification_report
# Store model predictions in a dictionary
# this makes it easier to iterate through each model
# and print the results.
model_preds = {
"Logistic Regression": log_reg_preds,
"Support Vector Machine": svm_preds,
"Decision Tree": tree_preds
}
for model, preds in model_preds.items():
print(f"{model} Results:\n{classification_report(y_test, preds)}", sep="\n\n")
"""
Logistic Regression Results:
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 0.92 0.96 25
2 0.86 1.00 0.92 12
accuracy 0.96 54
macro avg 0.95 0.97 0.96 54
weighted avg 0.97 0.96 0.96 54
Support Vector Machine Results:
precision recall f1-score support
0 1.00 1.00 1.00 17
1 1.00 1.00 1.00 25
2 1.00 1.00 1.00 12
accuracy 1.00 54
macro avg 1.00 1.00 1.00 54
weighted avg 1.00 1.00 1.00 54
Decision Tree Results:
precision recall f1-score support
0 0.94 0.94 0.94 17
1 0.96 0.88 0.92 25
2 0.86 1.00 0.92 12
accuracy 0.93 54
macro avg 0.92 0.94 0.93 54
weighted avg 0.93 0.93 0.93 54
"""İlk bakışta, destek vektör makinesi en iyi model gibi görünüyor. Tipik bir iş akışında bu, modelle ilgili merak uyandırır – gerçekten göründüğü kadar iyi mi, yoksa bir yerde hata mı yaptık? Modelleriniz ve neler öğrendikleri hakkında daha fazla şey öğrenmeye hevesli olmalısınız; bu, güçlü ve zayıf yönleri hakkında size daha iyi içgörüler sağlayacaktır.
Bu bilgiyi bilmek, paydaşlar için son derece aydınlatıcıdır; çünkü modelin yetersiz kaldığı yerleri telafi etmek için çözümler bulmalarını sağlar.
scikit-learn kütüphanesi, makine öğrenmesi modellerinin uygulanmasını kolaylaştıran çeşitli modüllerden oluşur. Bu modüller, modelinizi bir makine öğrenmesi modeline beslemek üzere hazırlamanıza yardımcı olacak ön işleme araçlarından, verilerinizdeki desenleri bulmak için kullanabileceğiniz modellere ve modelinizin performansını değerlendirmek için kullanabileceğiniz metriklere kadar uzanır.
Bu eğitimde, sklearn’ün yeteneklerinin yalnızca yüzeyine değindik. Kütüphane ile neler yapabileceğinize daha derinlemesine dalmak için sizi yola çıkaracak birkaç kaynağımız var. Başlamak için bazıları şunlar:
Python ve Makine Öğrenmesi hakkında daha fazla bilgi edinin
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
