Kurs
Python für Fortgeschrittene
4 Std.
1.4M
Ein Graph ist eine Art Datenstruktur, die Knoten und Kanten enthält. Ein Knoten kann eine Person, ein Ort oder eine Sache sein, und die Kanten definieren die Beziehung zwischen den Knoten. Die Kanten können aufgrund von Richtungsabhängigkeiten gerichtet und ungerichtet sein.
In dem Beispiel unten sind die blauen Kreise Knoten und die Pfeile sind Kanten. Die Richtung der Kanten definiert Abhängigkeiten zwischen zwei Knotenpunkten.
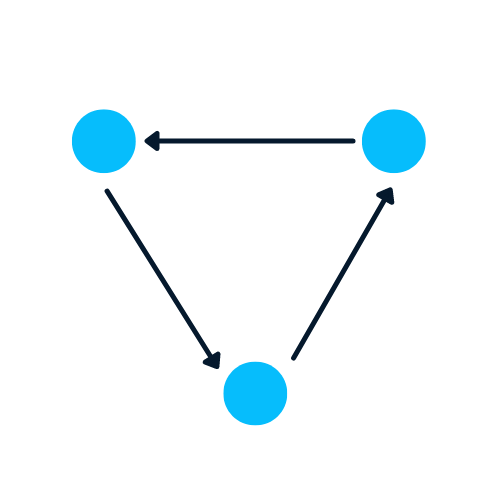
Bild vom Autor
Lernen wir den komplexen Graph-Datensatz kennen: Jazz Musicians Network. Sie enthält 198 Knoten und 2742 Kanten. Im folgenden Community-Diagramm stehen die verschiedenfarbigen Knoten für verschiedene Gemeinschaften von Jazzmusikern und die Kanten, die sie verbinden. Es gibt ein Netz der Zusammenarbeit, in dem ein einzelner Musiker Beziehungen innerhalb und außerhalb der Gemeinschaft hat.
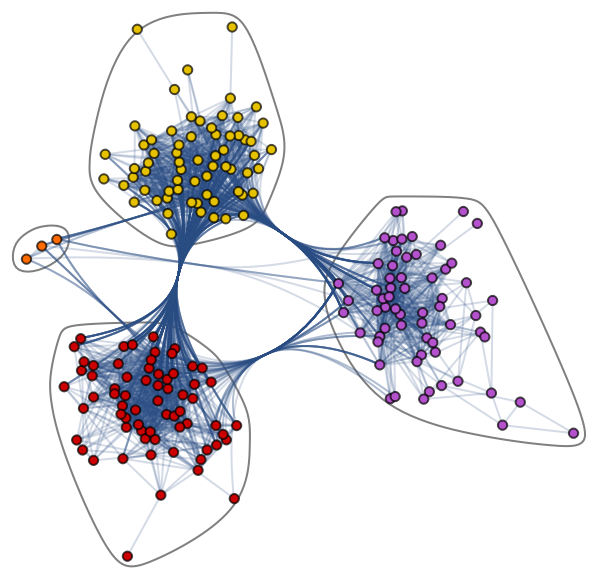
Community Graph Plot von Jazz Musicians Network
Diagramme eignen sich hervorragend, um komplexe Probleme mit Beziehungen und Wechselwirkungen zu behandeln. Sie werden in der Mustererkennung, der Analyse sozialer Netzwerke, in Empfehlungssystemen und der semantischen Analyse eingesetzt. Das Erstellen von graphenbasierten Lösungen ist ein ganz neues Feld, das reiche Einblicke in komplexe und vernetzte Datensätze bietet.
In diesem Abschnitt lernen wir, wie man mit NetworkX einen Graphen erstellt.
Der folgende Code wurde von Daniel Holmbergs Blog über Graph Neural Networks in Python beeinflusst.
import networkx as nx
H = nx.DiGraph()
#adding nodes
H.add_nodes_from([
(0, {"color": "blue", "size": 250}),
(1, {"color": "yellow", "size": 400}),
(2, {"color": "orange", "size": 150}),
(3, {"color": "red", "size": 600})
])
#adding edges
H.add_edges_from([
(0, 1),
(1, 2),
(1, 0),
(1, 3),
(2, 3),
(3,0)
])
node_colors = nx.get_node_attributes(H, "color").values()
colors = list(node_colors)
node_sizes = nx.get_node_attributes(H, "size").values()
sizes = list(node_sizes)
#Plotting Graph
nx.draw(H, with_labels=True, node_color=colors, node_size=sizes)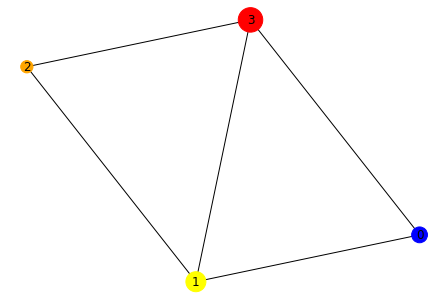
Im nächsten Schritt werden wir die Datenstruktur mit der Funktion to_undirected() von einem gerichteten in einen ungerichteten Graphen umwandeln.
#converting to undirected graph
G = H.to_undirected()
nx.draw(G, with_labels=True, node_color=colors, node_size=sizes)Graphenbasierte Datenstrukturen haben Nachteile, und Datenwissenschaftler müssen sie verstehen, bevor sie graphenbasierte Lösungen entwickeln.
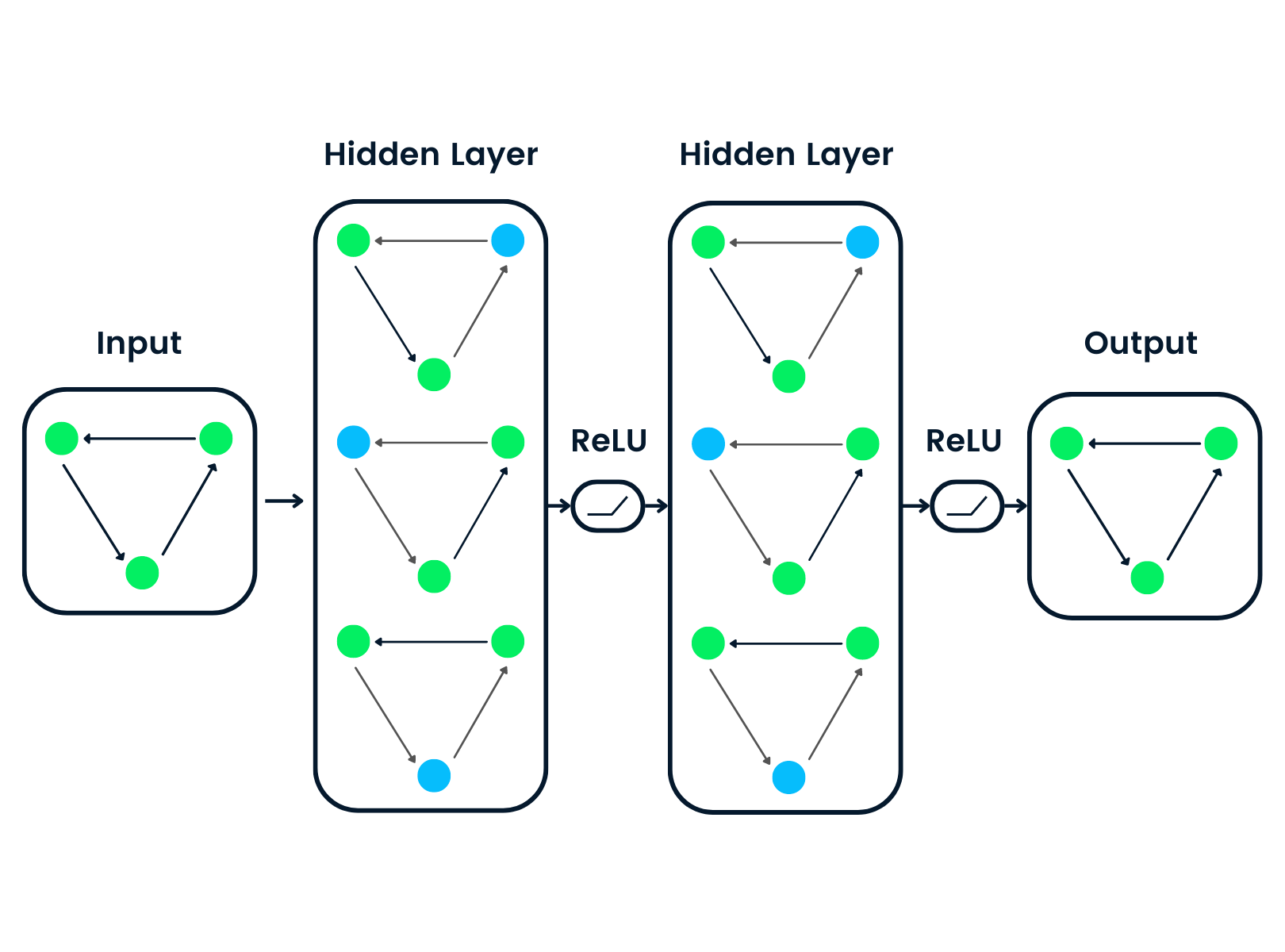
Graphenneuronale Netze sind spezielle Arten von neuronalen Netzen, die mit einer Graphen-Datenstruktur arbeiten können. Sie werden stark von Convolutional Neural Networks (CNNs) und Graph Embedding beeinflusst. GNNs werden bei der Vorhersage von Knoten, Kanten und graphenbasierten Aufgaben eingesetzt.
GNNs wurden eingeführt, als Convolutional Neural Networks aufgrund der willkürlichen Größe des Graphen und der komplexen Struktur keine optimalen Ergebnisse erzielen konnten.
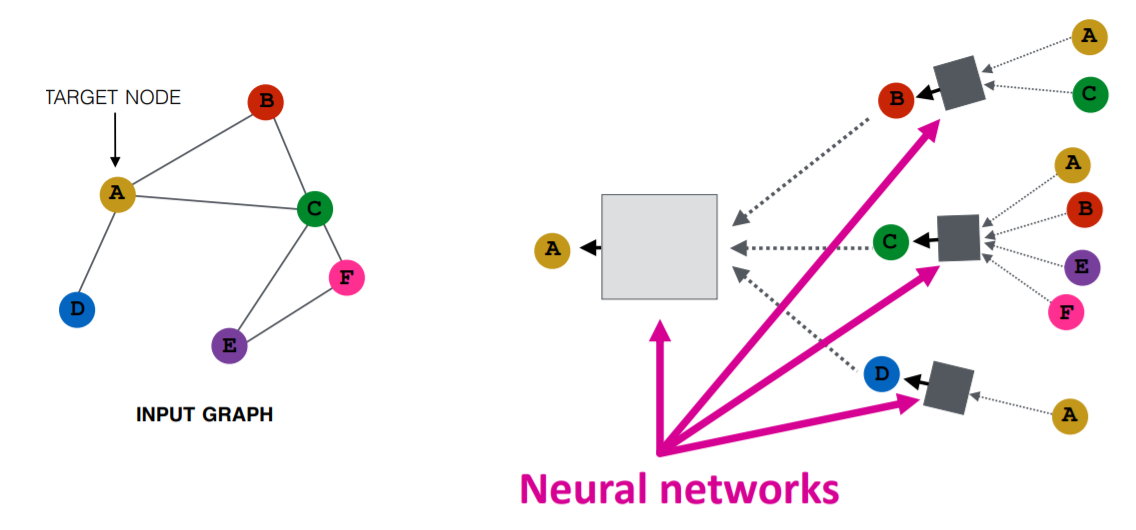
Bild von Purvanshi Mehta
Der Eingangsgraph wird durch eine Reihe von neuronalen Netzen geleitet. Die eingegebene Graphenstruktur wird in eine Grapheneinbettung umgewandelt, die es uns ermöglicht, Informationen über Knoten, Kanten und den globalen Kontext zu erhalten.
Dann wird der Merkmalsvektor der Knoten A und C durch die Schicht des neuronalen Netzes geleitet. Sie fasst diese Merkmale zusammen und gibt sie an die nächste Ebene weiter - neptune.ai.
Lies unser Deep Learning-Tutorial oder besuche unseren Kurs Einführung in Deep Learning, um mehr über Deep Learning-Algorithmen und -Anwendungen zu erfahren.
Es gibt verschiedene Arten von neuronalen Netzen, und die meisten von ihnen haben eine Variante von Convolutional Neural Networks. In diesem Abschnitt werden wir uns mit den beliebtesten GNNs beschäftigen.
Wenn du mehr über rekurrente neuronale Netze (RNNs) erfahren möchtest, schau dir den Kurs von DataCamp an. Es wird dich in verschiedene RNN-Modellarchitekturen, Keras-Frameworks und RNN-Anwendungen einführen.
Im Folgenden haben wir einige Arten von GNN-Aufgaben mit Beispielen beschrieben:
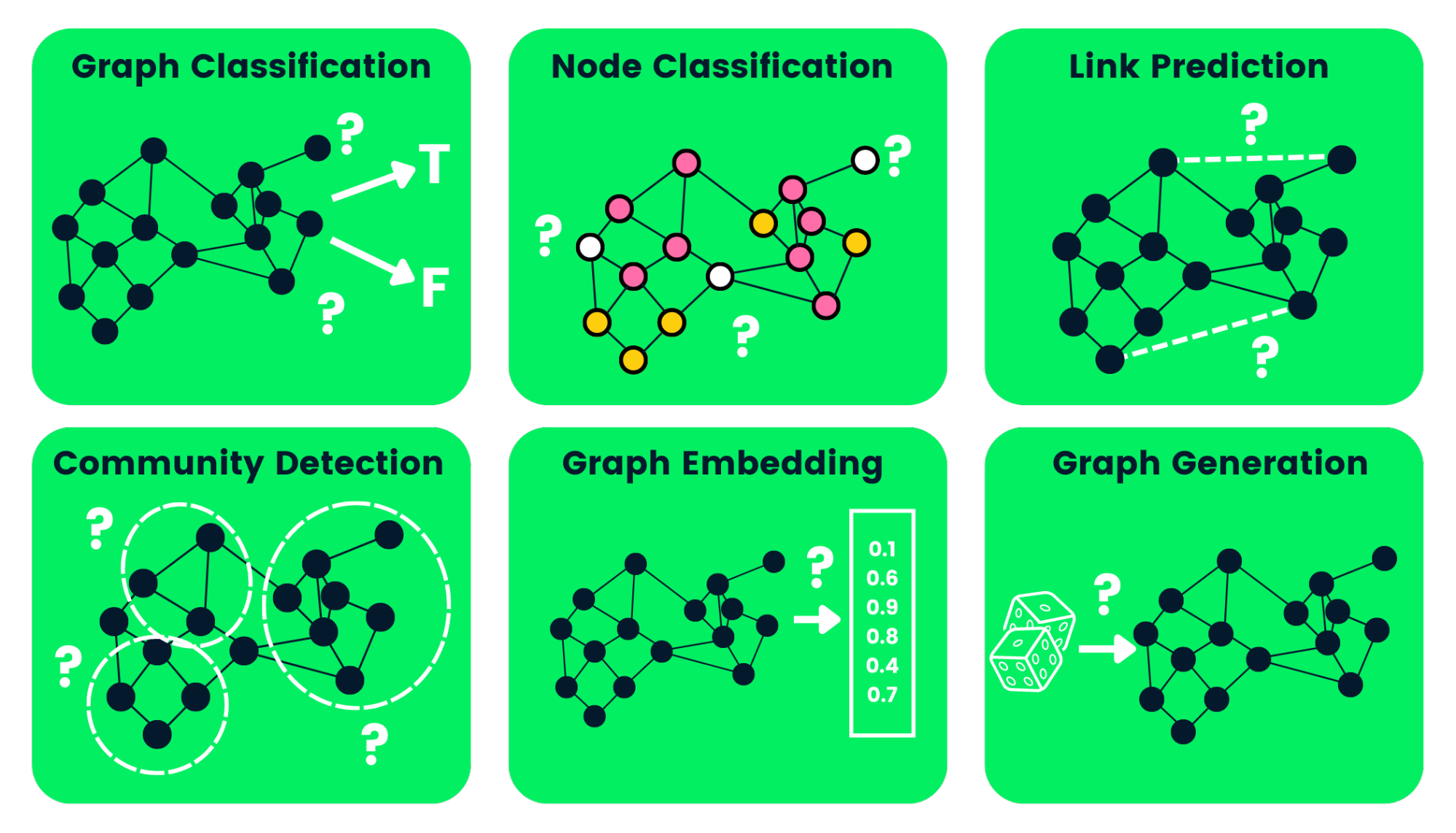
Bild vom Autor
Die Verwendung von GNNs hat ein paar Nachteile. Wenn wir sie verstehen, können wir entscheiden, wann wir GNNa einsetzen und wie wir die Leistung unserer maschinellen Lernmodelle optimieren können.
Die meisten GNNs sind Graph Convolutional Networks, und es ist wichtig, etwas über sie zu erfahren, bevor du dich in ein Tutorial zur Knotenklassifizierung stürzt.
Die Faltung in GCN ist dasselbe wie die Faltung in faltigen neuronalen Netzen. Es multipliziert Neuronen mit Gewichten (Filtern), um aus Datenmerkmalen zu lernen.
Sie fungiert als gleitende Fenster auf ganzen Bildern, um Merkmale aus benachbarten Zellen zu lernen. Der Filter nutzt Weight Sharing, um verschiedene Gesichtsmerkmale in Bilderkennungssystemen zu lernen - Towards Data Science.
Übertrage nun die gleiche Funktionalität auf Graph Convolutional Networks, bei denen ein Modell die Merkmale von benachbarten Knoten lernt. Der Hauptunterschied zwischen GCN und CNN besteht darin, dass es für nicht-euklidische Datenstrukturen entwickelt wurde, bei denen die Reihenfolge der Knoten und Kanten variieren kann.
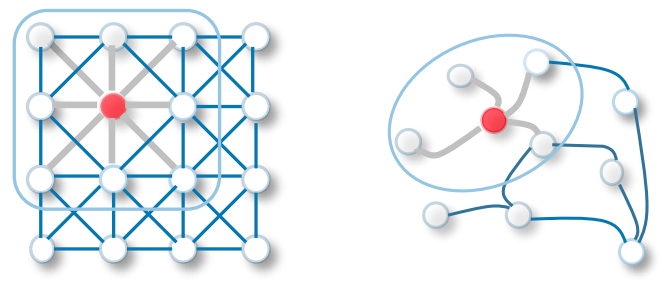
CNN vs. GCN | Bildquelle
Erfahre mehr über grundlegende CNNs, indem du dem TensorFlow-Tutorial zu Convolutional Neural Networks (CNN) folgst.
Es gibt zwei Arten von GCNs:
Wir werden die Spektrale Graphenfaltung für ein Knotenklassifizierungsmodell aufbauen und trainieren. Der Quellcode ist in dieser DataLab-Arbeitsmappe verfügbar, damit du dein erstes graphbasiertes maschinelles Lernmodell ausprobieren und ausführen kannst.
Die Kodierungsbeispiele sind von der geometrischen Dokumentation von Pytorch beeinflusst.
Wir werden das Pytorch-Paket installieren, da pytorch_geometric darauf aufbaut.
!pip install -q torchDann werden wir die torch-Version verwenden, um torch-scatter und torch-sparse zu installieren. Danach installieren wir die neueste Version von pytorch_geometricvon GitHub.
%%capture
import os
import torch
os.environ['TORCH'] = torch.__version__
os.environ['PYTHONWARNINGS'] = "ignore"
!pip install torch-scatter -f https://data.pyg.org/whl/torch-${TORCH}.html
!pip install torch-sparse -f https://data.pyg.org/whl/torch-${TORCH}.html
!pip install git+https://github.com/pyg-team/pytorch_geometric.gitPlanetoid ist ein Zitationsnetzwerk-Datensatz aus Cora, CiteSeer und PubMed. Die Knoten sind Dokumente mit 1433-dimensionalen Bag-of-Words-Merkmalsvektoren, und die Kanten sind Zitierlinks zwischen Forschungsarbeiten. Es gibt 7 Klassen und wir werden das Modell trainieren, um fehlende Bezeichnungen vorherzusagen.
Wir nehmen den Planetoid Cora-Datensatz auf und normalisieren die Bag of Words-Eingangsmerkmale in Zeilen. Danach werden wir den Datensatz und das erste Diagrammobjekt analysieren.
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures
dataset = Planetoid(root='data/Planetoid', name='Cora', transform=NormalizeFeatures())
print(f'Dataset: {dataset}:')
print('======================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')
data = dataset[0] # Get the first graph object.
print(data)Der Cora-Datensatz hat 2708 Knoten, 10.556 Kanten, 1433 Merkmale und 7 Klassen. Das erste Objekt hat 2708 Trainings-, Validierungs- und Testmasken. Wir werden diese Masken verwenden, um das Modell zu trainieren und zu bewerten.
Dataset: Cora():
======================
Number of graphs: 1
Number of features: 1433
Number of classes: 7
Data(x=[2708, 1433], edge_index=[2, 10556], y=[2708], train_mask=[2708], val_mask=[2708], test_mask=[2708])Wir erstellen eine GCN-Modellstruktur, die zwei GCNConv-Schichten mit einer relu Aktivierung und einer Dropout-Rate von 0,5 enthält. Das Modell besteht aus 16 versteckten Kanälen.
GCN-Schicht:
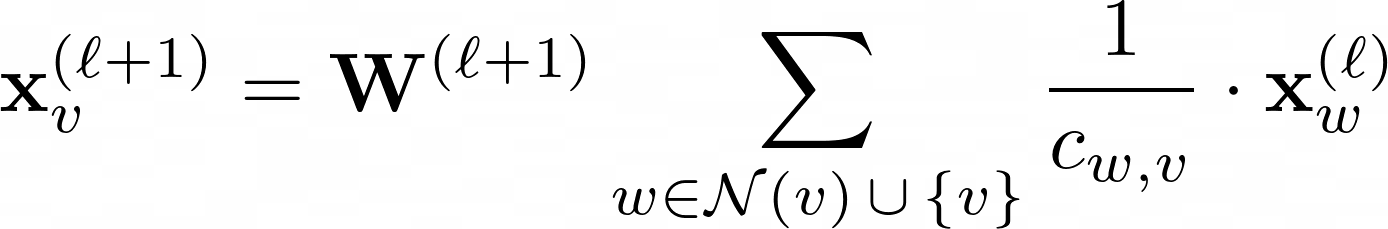
W(ℓ+1) ist in der obigen Gleichung eine übertragbare Gewichtsmatrix und Cw,v gibt einen festen Normalisierungskoeffizienten für jede Kante vor.
from torch_geometric.nn import GCNConv
import torch.nn.functional as F
class GCN(torch.nn.Module):
def __init__(self, hidden_channels):
super().__init__()
torch.manual_seed(1234567)
self.conv1 = GCNConv(dataset.num_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
return x
model = GCN(hidden_channels=16)
print(model)
>>> GCN(
(conv1): GCNConv(1433, 16)
(conv2): GCNConv(16, 7)
)Lass uns die Knoteneinbettungen von untrainierten GCN-Netzwerken mit sklearn.manifold.TSNE und matplotlib.pyplot visualisieren. Es wird ein 7-dimensionaler Knoten gezeichnet, der ein 2D-Streudiagramm einbettet.
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
def visualize(h, color):
z = TSNE(n_components=2).fit_transform(h.detach().cpu().numpy())
plt.figure(figsize=(10,10))
plt.xticks([])
plt.yticks([])
plt.scatter(z[:, 0], z[:, 1], s=70, c=color, cmap="Set2")
plt.show()Wir werten das Modell aus und fügen dem untrainierten Modell Trainingsdaten hinzu, um verschiedene Knoten und Kategorien zu visualisieren.
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)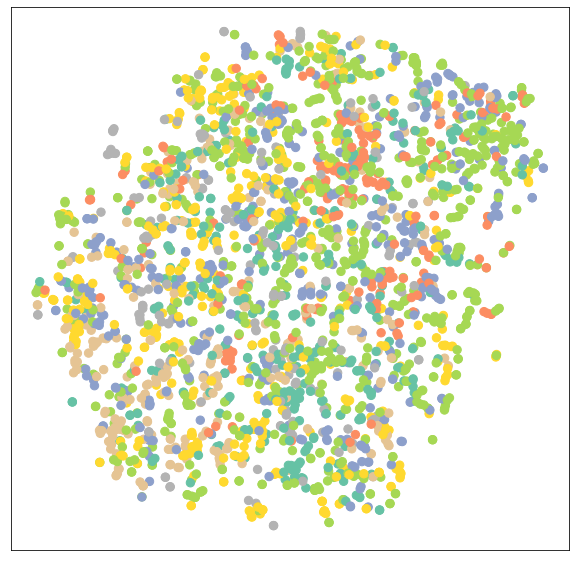
Wir werden unser Modell anhand von 100 Epochen mit der Adam-Optimierung und der Cross-Entropy Loss-Funktion trainieren.
In der Zugfunktion haben wir:
In der Testfunktion haben wir:
model = GCN(hidden_channels=16)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1)
test_correct = pred[data.test_mask] == data.y[data.test_mask]
test_acc = int(test_correct.sum()) / int(data.test_mask.sum())
return test_acc
for epoch in range(1, 101):
loss = train()
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
GAT(
(conv1): GATConv(1433, 8, heads=8)
(conv2): GATConv(64, 7, heads=8)
)
.. .. .. ..
.. .. .. ..
Epoch: 098, Loss: 0.5989
Epoch: 099, Loss: 0.6021
Epoch: 100, Loss: 0.5799Wir werden das Modell nun an einem ungesehenen Datensatz mit der Testfunktion testen. Wie du siehst, haben wir mit 81,5 % Genauigkeit ziemlich gute Ergebnisse erzielt.
test_acc = test()
print(f'Test Accuracy: {test_acc:.4f}')
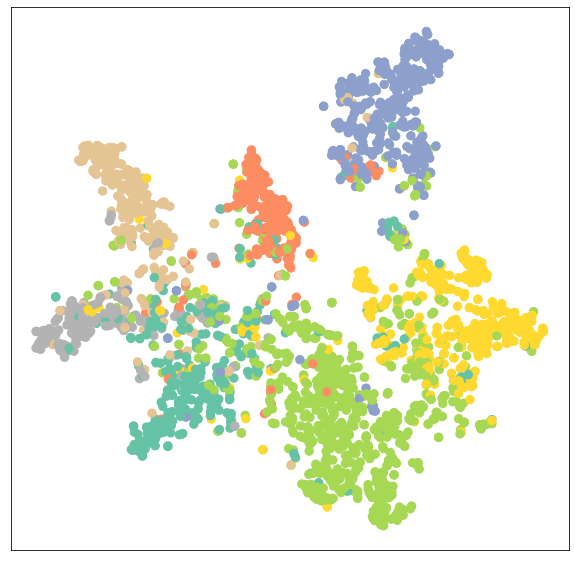
>>> Test Accuracy: 0.8150Um die Ergebnisse zu überprüfen, werden wir nun das Output Embedding eines trainierten Modells visualisieren.
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)Wie wir sehen können, hat das trainierte Modell eine bessere Clusterung der Knoten für dieselbe Kategorie ergeben.
Im zweiten Schritt werden wir GCNConv durch GATConv-Schichten ersetzen. Das Graph Attention Networks verwendet maskierte Selbstbeobachtungsschichten, um die Nachteile von GCNConv zu beheben und modernste Ergebnisse zu erzielen.
Du kannst auch andere GNN-Schichten ausprobieren und mit Optimierungen, Aussetzern und der Anzahl versteckter Kanäle herumspielen, um eine bessere Leistung zu erzielen.
Im folgenden Code haben wir gerade GCNConv durch GATConv mit 8 Aufmerksamkeitsköpfen in der ersten Schicht und 1 in der zweiten Schicht ersetzt.
Wir werden auch einstellen:
Wir haben die Testfunktion geändert, um die Genauigkeit einer bestimmten Maske (valid, test) zu ermitteln. Sie hilft uns, die Validierungs- und Testergebnisse während des Modelltrainings auszudrucken. Außerdem speichern wir die Validierungs- und Testergebnisse später in einem Liniendiagramm.
from torch_geometric.nn import GATConv
class GAT(torch.nn.Module):
def __init__(self, hidden_channels, heads):
super().__init__()
torch.manual_seed(1234567)
self.conv1 = GATConv(dataset.num_features, hidden_channels,heads)
self.conv2 = GATConv(heads*hidden_channels, dataset.num_classes,heads)
def forward(self, x, edge_index):
x = F.dropout(x, p=0.6, training=self.training)
x = self.conv1(x, edge_index)
x = F.elu(x)
x = F.dropout(x, p=0.6, training=self.training)
x = self.conv2(x, edge_index)
return x
model = GAT(hidden_channels=8, heads=8)
print(model)
optimizer = torch.optim.Adam(model.parameters(), lr=0.005, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss
def test(mask):
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1)
correct = pred[mask] == data.y[mask]
acc = int(correct.sum()) / int(mask.sum())
return acc
val_acc_all = []
test_acc_all = []
for epoch in range(1, 101):
loss = train()
val_acc = test(data.val_mask)
test_acc = test(data.test_mask)
val_acc_all.append(val_acc)
test_acc_all.append(test_acc)
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}, Val: {val_acc:.4f}, Test: {test_acc:.4f}')
.. .. .. ..
.. .. .. ..
Epoch: 098, Loss: 1.1283, Val: 0.7960, Test: 0.8030
Epoch: 099, Loss: 1.1352, Val: 0.7940, Test: 0.8050
Epoch: 100, Loss: 1.1053, Val: 0.7960, Test: 0.8040Wie wir feststellen können, hat unser Modell nicht besser abgeschnitten als GCNConv. Es erfordert eine Optimierung der Hyperparameter oder mehr Epochen, um die besten Ergebnisse zu erzielen.
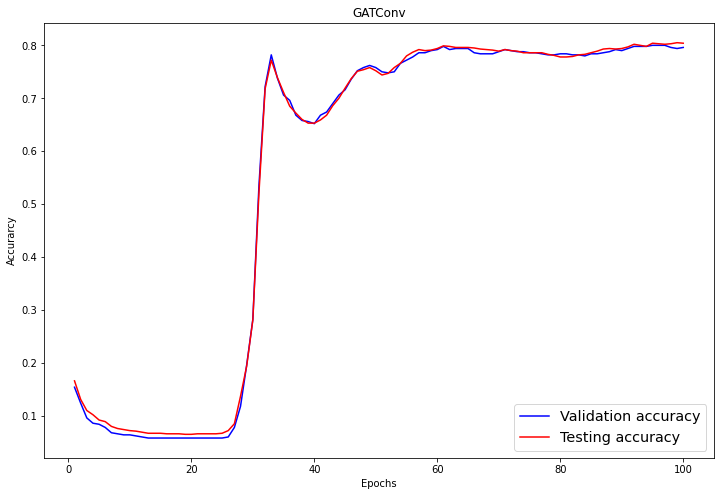
Im Auswertungsteil visualisieren wir die Validierungs- und Testergebnisse mit dem Liniendiagramm von matplotlib.pyplot .
import numpy as np
plt.figure(figsize=(12,8))
plt.plot(np.arange(1, len(val_acc_all) + 1), val_acc_all, label='Validation accuracy', c='blue')
plt.plot(np.arange(1, len(test_acc_all) + 1), test_acc_all, label='Testing accuracy', c='red')
plt.xlabel('Epochs')
plt.ylabel('Accurarcy')
plt.title('GATConv')
plt.legend(loc='lower right', fontsize='x-large')
plt.savefig('gat_loss.png')
plt.show()Nach 60 Epochen hat die Validierungs- und Prüfgenauigkeit einen stabilen Wert von 0,8+/-0,02 erreicht.
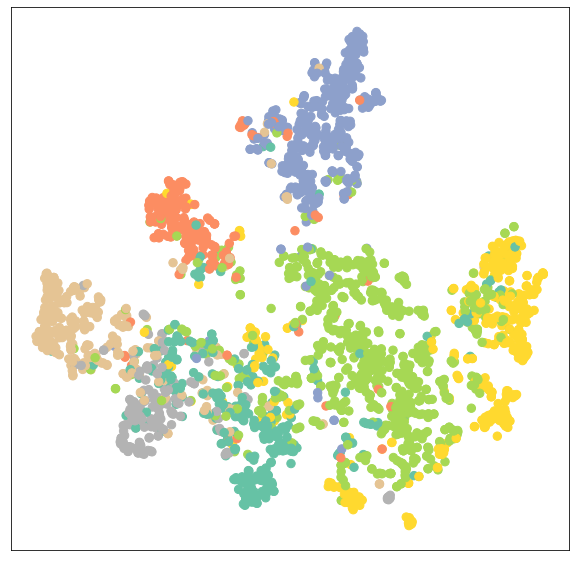
Lass uns noch einmal das Knoten-Cluster des GATConv-Modells veranschaulichen.
model.eval()
out = model(data.x, data.edge_index)
visualize(out, color=data.y)Wie wir sehen können, hat die GATConv-Schicht die gleichen Ergebnisse bei der Clusterbildung für dieselbe Kategorie von Knotenpunkten erzielt.
Wir können die Überanpassung reduzieren, indem wir einen zweiten Validierungsdatensatz hinzufügen und die Modellleistung verbessern, indem wir mit verschiedenen GCN-Schichten aus pytoch_geometric experimentieren.
Der Quellcode des Tutorials ist in dieser DataLab-Arbeitsmappe verfügbar. Erstelle eine Kopie der Arbeitsmappe, die du ausführen kannst.
Füge deinem Lebenslauf Deep Learning-Fähigkeiten hinzu, indem du den Lernpfad Deep Learning in Python belegst. Er führt dich in Deep-Learning-Algorithmen, Keras, Pytorch und das Tensorflow-Framework ein.
Python-Kurse
Kurs
Kurs
Blog
Tutorial
Sejal Jaiswal
Tutorial
Javier Canales Luna
Tutorial
Laiba Siddiqui
Tutorial
DataCamp Team
Tutorial
Matt Crabtree

