
Was ist Deep Learning?
Deep Learning ist eine Art des maschinellen Lernens, bei dem Computer lernen, Aufgaben zu erfüllen, indem sie aus Beispielen lernen, ähnlich wie Menschen es tun. Stell dir vor, du bringst einem Computer bei, Katzen zu erkennen: Anstatt ihm zu sagen, dass er nach Schnurrhaaren, Ohren und einem Schwanz suchen soll, zeigst du ihm Tausende von Katzenbildern. Der Computer findet die gemeinsamen Muster ganz von selbst und lernt, wie man eine Katze identifiziert. Das ist die Essenz des Deep Learning.
Technisch gesehen verwendet Deep Learning so genannte "neuronale Netze", die dem menschlichen Gehirn nachempfunden sind. Diese Netzwerke bestehen aus Schichten miteinander verbundener Knotenpunkte, die Informationen verarbeiten. Je mehr Schichten, desto "tiefer" ist das Netz, so dass es komplexere Merkmale lernen und anspruchsvollere Aufgaben erfüllen kann.
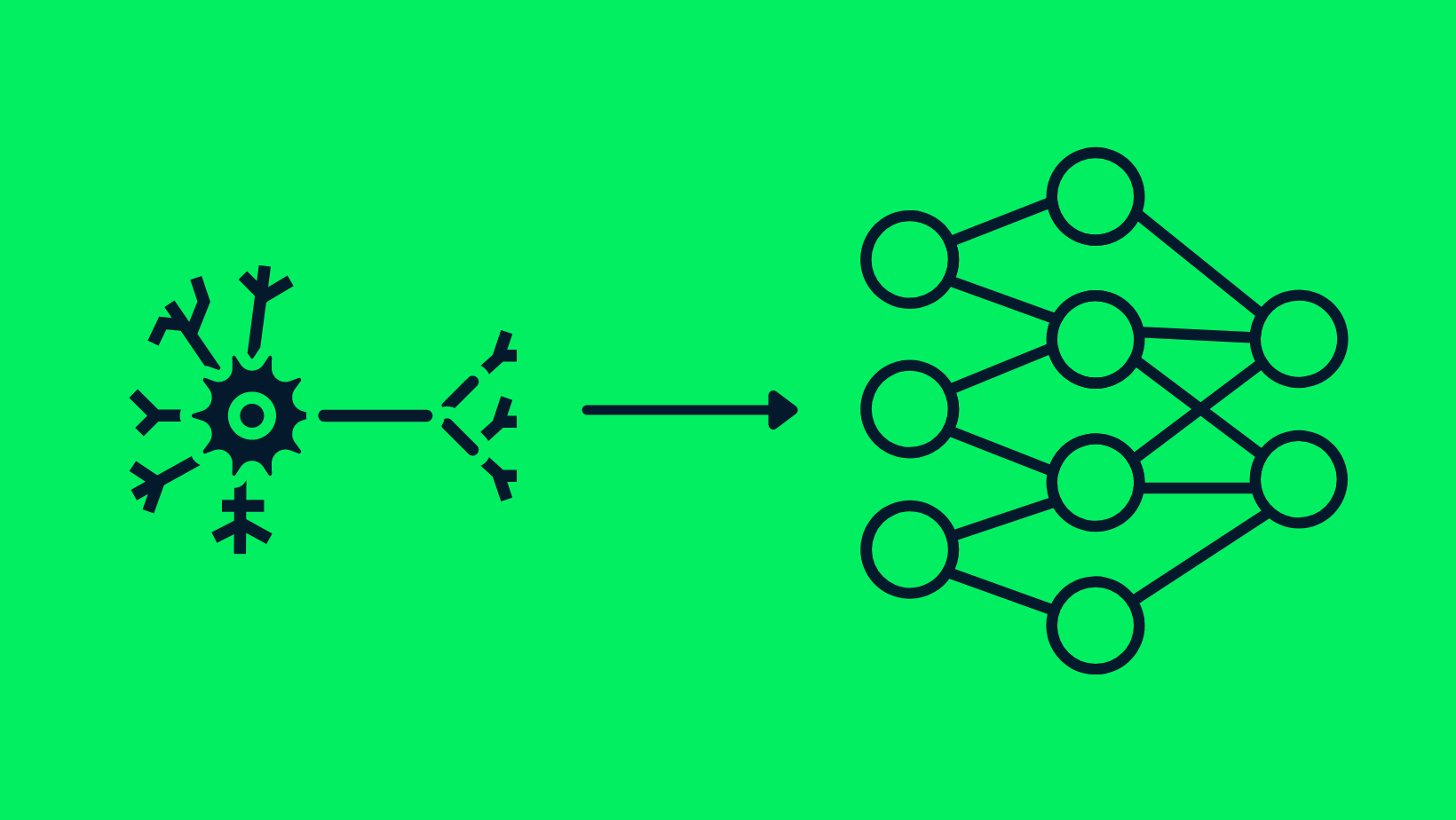
Die Ähnlichkeit zwischen Neuronen und neuronalen Netzen
Die Entwicklung von Machine Learning zu Deep Learning
Was ist maschinelles Lernen?
Maschinelles Lernen ist ein Teilbereich der künstlichen Intelligenz (KI), der es Computern ermöglicht, aus Daten zu lernen und Entscheidungen ohne explizite Programmierung zu treffen. Sie umfasst verschiedene Techniken und Algorithmen, die es Systemen ermöglichen, Muster zu erkennen, Vorhersagen zu treffen und die Leistung im Laufe der Zeit zu verbessern. Den Unterschied zwischen maschinellem Lernen und KI kannst du in einem separaten Artikel nachlesen.
Wie sich Deep Learning vom traditionellen maschinellen Lernen unterscheidet
Während das maschinelle Lernen an sich schon eine transformative Technologie ist, geht Deep Learning noch einen Schritt weiter, indem es viele Aufgaben automatisiert, die normalerweise menschliches Fachwissen erfordern.
Deep Learning ist im Wesentlichen eine spezialisierte Untergruppe des maschinellen Lernens, die sich durch die Verwendung von neuronalen Netzen mit drei oder mehr Schichten auszeichnet. Diese neuronalen Netze versuchen, das Verhalten des menschlichen Gehirns zu simulieren - auch wenn sie weit davon entfernt sind, dessen Fähigkeit zu erreichen -, um aus großen Datenmengen zu "lernen". Du kannst das maschinelle Lernen im Vergleich zum Deep Learning in einem anderen Beitrag genauer untersuchen.
Die Bedeutung von Feature Engineering
Beim Feature-Engineering werden aus den Rohdaten die relevantesten Variablen, die sogenannten "Features", ausgewählt, umgewandelt oder erstellt, um sie in Machine-Learning-Modellen zu verwenden.
Wenn du zum Beispiel ein Wettervorhersagemodell erstellst, können die Rohdaten Temperatur, Luftfeuchtigkeit, Windgeschwindigkeit und Luftdruck enthalten. Beim Feature-Engineering geht es darum, herauszufinden, welche dieser Variablen für die Wettervorhersage am wichtigsten sind, und sie möglicherweise umzuwandeln (z. B. die Temperatur von Fahrenheit in Celsius umzurechnen), um sie für das Modell nützlicher zu machen.
Beim traditionellen maschinellen Lernen ist das Feature Engineering oft ein manueller und zeitaufwändiger Prozess, der Fachwissen erfordert. Einer der Vorteile von Deep Learning ist jedoch, dass es automatisch relevante Merkmale aus den Rohdaten lernen kann, sodass weniger manuelle Eingriffe nötig sind.
Warum ist Deep Learning wichtig?
Die Gründe, warum Deep Learning zum Industriestandard geworden ist:
- Umgang mit unstrukturierten Daten: Modelle, die auf strukturierten Daten trainiert wurden, können leicht von unstrukturierten Daten lernen, was den Zeit- und Ressourcenaufwand für die Standardisierung von Datensätzen reduziert.
- Umgang mit großen Daten: Dank der Einführung von Grafikprozessoren (GPUs) können Deep Learning-Modelle große Datenmengen blitzschnell verarbeiten.
- Hohe Genauigkeit: Deep Learning-Modelle liefern die genauesten Ergebnisse in den Bereichen Computervision, natürliche Sprachverarbeitung (NLP) und Audioverarbeitung.
- Mustererkennung: Die meisten Modelle erfordern den Eingriff eines Ingenieurs für maschinelles Lernen, aber Deep-Learning-Modelle können alle Arten von Mustern automatisch erkennen.
In diesem Tutorial tauchen wir in die Welt des Deep Learning ein und lernen alle wichtigen Konzepte kennen, die du brauchst, um eine Karriere im Bereich der künstlichen Intelligenz (KI) zu starten. Wenn du mit praktischen Übungen lernen möchtest, schau dir unseren Kurs " Einführung in Deep Learning in Python" an.
Kernkonzepte des Deep Learning
Bevor du in die Feinheiten der Deep Learning Algorithmen und ihrer Anwendungen eintauchst, ist es wichtig, die grundlegenden Konzepte zu verstehen, die diese Technologie so revolutionär machen. In diesem Abschnitt lernst du die Bausteine des Deep Learning kennen: neuronale Netze, tiefe neuronale Netze und Aktivierungsfunktionen.
Neuronale Netze
Das Herzstück des Deep Learning sind neuronale Netze, also Rechenmodelle, die vom menschlichen Gehirn inspiriert sind. Diese Netzwerke bestehen aus miteinander verbundenen Knotenpunkten oder "Neuronen", die zusammenarbeiten, um Informationen zu verarbeiten und Entscheidungen zu treffen. So wie unser Gehirn verschiedene Regionen für verschiedene Aufgaben hat, hat auch ein neuronales Netz Schichten für bestimmte Funktionen.
In unserem Leitfaden " Was sind neuronale Netze?" gehen wir auf die wichtigsten Punkte näher ein.
Tiefe neuronale Netze
Was ein neuronales Netzwerk "tief" macht, ist die Anzahl der Schichten, die es zwischen Eingang und Ausgang hat. Ein tiefes neuronales Netzwerk hat mehrere Schichten, wodurch es komplexere Merkmale lernen und genauere Vorhersagen treffen kann. Die "Tiefe" dieser Netze ist das, was dem Deep Learning seinen Namen gibt und seine Fähigkeit, komplizierte Probleme zu lösen.
Unsere Einführung in tiefe neuronale Netze behandelt die Bedeutung von DNNs für Deep Learning und künstliche Intelligenz.
Aktivierungsfunktionen
In einem neuronalen Netz sind die Aktivierungsfunktionen wie die Entscheidungsträger. Sie legen fest, welche Informationen an die nächste Schicht weitergegeben werden sollen. Diese Funktionen erhöhen die Komplexität und ermöglichen es dem Netzwerk, aus den Daten zu lernen und differenzierte Entscheidungen zu treffen.
Wie Deep Learning funktioniert
Deep Learning nutzt die Merkmalsextraktion, um ähnliche Merkmale desselben Labels zu erkennen, und verwendet dann Entscheidungsgrenzen, um zu bestimmen, welche Merkmale jedes Label genau repräsentieren. Bei der Klassifizierung von Katzen und Hunden extrahieren die Deep Learning-Modelle Informationen wie Augen, Gesicht und Körperform der Tiere und teilen sie in zwei Klassen ein.
Das Deep Learning-Modell besteht aus tiefen neuronalen Netzen. Das einfache neuronale Netz besteht aus einer Eingabeschicht, einer verborgenen Schicht und einer Ausgabeschicht. Deep-Learning-Modelle bestehen aus mehreren versteckten Schichten, wobei zusätzliche Schichten die Genauigkeit des Modells verbessern.
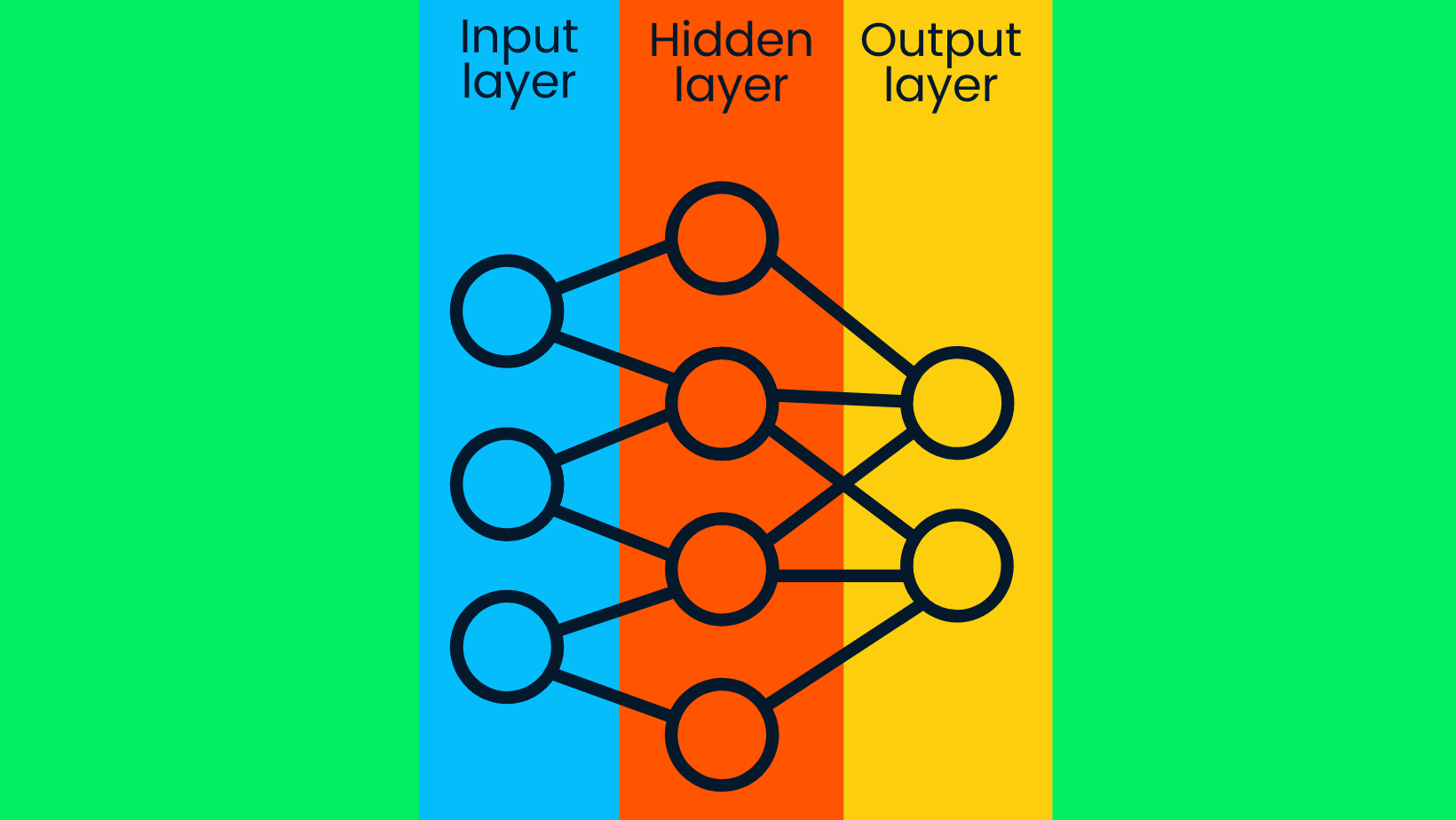 Einfaches neuronales Netzwerk
Einfaches neuronales Netzwerk
Die Eingabeschichten enthalten Rohdaten und übertragen die Daten an die Knoten der verborgenen Schichten. Die Knoten der verborgenen Schichten klassifizieren die Datenpunkte auf der Grundlage der breiteren Zielinformationen, und mit jeder weiteren Schicht wird der Umfang des Zielwerts enger gefasst, um genaue Annahmen zu treffen. Die Ausgabeschicht nutzt die Informationen der versteckten Schicht, um das wahrscheinlichste Label auszuwählen. In unserem Fall geht es darum, das Bild eines Hundes genau vorherzusagen und nicht das einer Katze.
Künstliche Intelligenz vs. Deep Learning
Lass uns eine der am häufigsten gestellten Fragen im Internet beantworten: "Ist Deep Learning künstliche Intelligenz?". Die kurze Antwort lautet: Ja. Deep Learning ist ein Teilbereich des maschinellen Lernens, und maschinelles Lernen ist ein Teilbereich der KI.
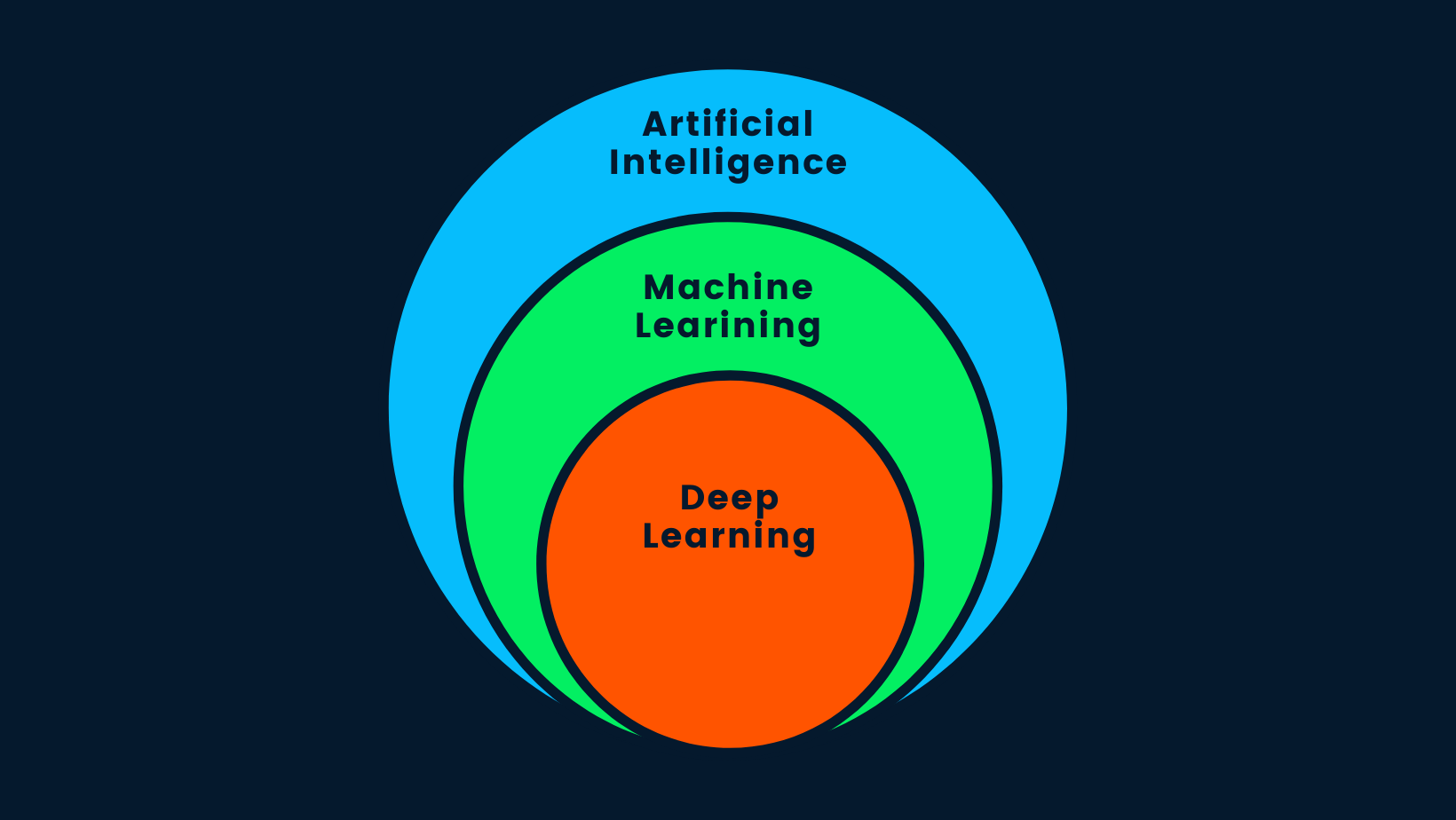 AI vs. ML vs. DL
AI vs. ML vs. DL
Künstliche Intelligenz ist das Konzept, dass intelligente Maschinen gebaut werden können, die das menschliche Verhalten nachahmen oder die menschliche Intelligenz übertreffen. KI nutzt Methoden des maschinellen Lernens und des Deep Learning, um menschliche Aufgaben zu erledigen. Kurz gesagt: KI ist Deep Learning, denn es ist der fortschrittlichste Algorithmus, der intelligente Entscheidungen treffen kann.
Wofür wird Deep Learning eingesetzt?
In der letzten Zeit hat die Welt der Technologie einen Anstieg von Anwendungen der künstlichen Intelligenz erlebt, die alle auf Deep-Learning-Modellen beruhen. Die Anwendungen reichen von Filmempfehlungen auf Netflix bis hin zu Amazon-Lagerverwaltungssystemen.
In diesem Abschnitt werden wir einige der berühmtesten Anwendungen kennenlernen, die mit Deep Learning entwickelt wurden. So kannst du das volle Potenzial von tiefen neuronalen Netzen ausschöpfen.
Computer Vision
Computer Vision (CV) wird in selbstfahrenden Autos eingesetzt, um Objekte zu erkennen und Kollisionen zu vermeiden. Sie wird auch zur Gesichtserkennung, Posenschätzung, Bildklassifizierung und Erkennung von Anomalien eingesetzt.
 Gesichtserkennung
Gesichtserkennung
Automatische Spracherkennungssysteme
Automatische Spracherkennung (ASR ) wird von Milliarden von Menschen weltweit genutzt. Sie befindet sich in unseren Telefonen und wird in der Regel aktiviert, indem wir "Hey, Google" oder "Hi, Siri" sagen. Solche Audioanwendungen werden auch für Text-to-Speech, die Audioklassifizierung und die Erkennung von Sprachaktivitäten verwendet.
 Erkennung von Sprachmustern
Erkennung von Sprachmustern
Generative KI
Generative KI hat einen Nachfrageschub erlebt, denn CryptoPunk NFT wurde gerade für 1 Million Dollar verkauft. CryptoPunk ist eine generative Kunstsammlung, die mit Deep-Learning-Modellen erstellt wurde. Die Einführung des GPT-4-Modells durch OpenAI hat den Bereich der Texterstellung mit dem leistungsstarken ChatGPT-Tool revolutioniert; jetzt kannst du Modellen beibringen, einen ganzen Roman zu schreiben oder sogar Code für deine Data-Science-Projekte zu schreiben.
 Generative Kunst
Generative Kunst
Übersetzung
Die Deep Learning-Übersetzung ist nicht auf die Sprachübersetzung beschränkt, da wir jetzt in der Lage sind, Fotos mit Hilfe von OCR in Text zu übersetzen oder Text mit Hilfe von NVIDIA GauGAN2 in Bilder zu übersetzen.
 Sprachübersetzung
Sprachübersetzung
Zeitreihenvorhersage
Zeitreihenprognosen werden für die Vorhersage von Börsencrashs, Aktienkursen und Wetterveränderungen verwendet. Der Finanzsektor lebt von Spekulationen und Zukunftsprognosen. Deep Learning und Zeitreihenmodelle sind besser als der Mensch, wenn es darum geht, Muster zu erkennen, und sind daher in dieser und ähnlichen Branchen ein wichtiges Instrument.
 Zeitreihenprognose
Zeitreihenprognose
Automatisierung
Deep Learning wird für die Automatisierung von Aufgaben eingesetzt, zum Beispiel für das Training von Robotern für die Lagerverwaltung. Die beliebteste Anwendung ist das Spielen von Videospielen und das bessere Lösen von Rätseln. Kürzlich schlug die Dota-KI von OpenAI das Profiteam OG, was die Welt schockierte, denn die Leute hatten nicht erwartet, dass alle fünf Bots die Weltmeister überlisten würden.
 Roboterarm mit Hilfe von Reinforcement Learning
Roboterarm mit Hilfe von Reinforcement Learning
Kundenfeedback
Deep Learning wird für die Bearbeitung von Kundenfeedback und Beschwerden eingesetzt. Sie wird in jeder Chatbot-Anwendung verwendet, um nahtlosen Kundenservice zu bieten.
 Kundenfeedback
Kundenfeedback
Biomedizinische
Dieser Bereich hat am meisten von der Einführung des Deep Learning profitiert. DL wird in der Biomedizin zur Erkennung von Krebs, zum Aufbau stabiler Medizin, zur Erkennung von Anomalien bei Röntgenaufnahmen der Brust und zur Unterstützung medizinischer Geräte eingesetzt.
 Analyse von DNA-Sequenzen
Analyse von DNA-Sequenzen
Deep Learning Modelle
Lernen wir die verschiedenen Arten von Deep Learning-Modellen kennen und wie sie funktionieren.
Überwachtes Lernen
Beim überwachten Lernen wird ein markierter Datensatz verwendet, um Modelle zu trainieren, die entweder Daten klassifizieren oder Werte vorhersagen. Der Datensatz enthält Merkmale und Zielkennzeichnungen, die es dem Algorithmus ermöglichen, im Laufe der Zeit zu lernen, indem er den Verlust zwischen vorhergesagten und tatsächlichen Kennzeichnungen minimiert. Überwachtes Lernen kann in Klassifizierungs- und Regressionsprobleme unterteilt werden.
Klassifizierung
Der Klassifizierungsalgorithmus unterteilt den Datensatz anhand von Merkmalsextraktionen in verschiedene Kategorien. Die beliebtesten Deep Learning-Modelle sind ResNet50 für die Bildklassifizierung und BERT (Sprachmodell) für die Textklassifizierung.
 Klassifizierung
Klassifizierung
Regression
Anstatt den Datensatz in Kategorien einzuteilen, lernt das Regressionsmodell die Beziehung zwischen Input- und Outputvariablen, um das Ergebnis vorherzusagen. Regressionsmodelle werden häufig für prädiktive Analysen, Wettervorhersagen und die Vorhersage der Börsenentwicklung verwendet. LSTM und RNN sind beliebte Deep-Learning-Regressionsmodelle.
 Lineare Regression
Lineare Regression
Unüberwachtes Lernen
Unüberwachte Lernalgorithmen lernen die Muster in einem unbeschrifteten Datensatz und bilden Cluster. Deep-Learning-Modelle können verborgene Muster ohne menschliches Zutun erlernen, und diese Modelle werden oft in Empfehlungsmaschinen eingesetzt.
Unüberwachtes Lernen wird für die Gruppierung verschiedener Arten, die medizinische Bildgebung und die Marktforschung verwendet. Das gängigste Deep-Learning-Modell für das Clustering ist der Deep-Embedded-Clustering-Algorithmus.
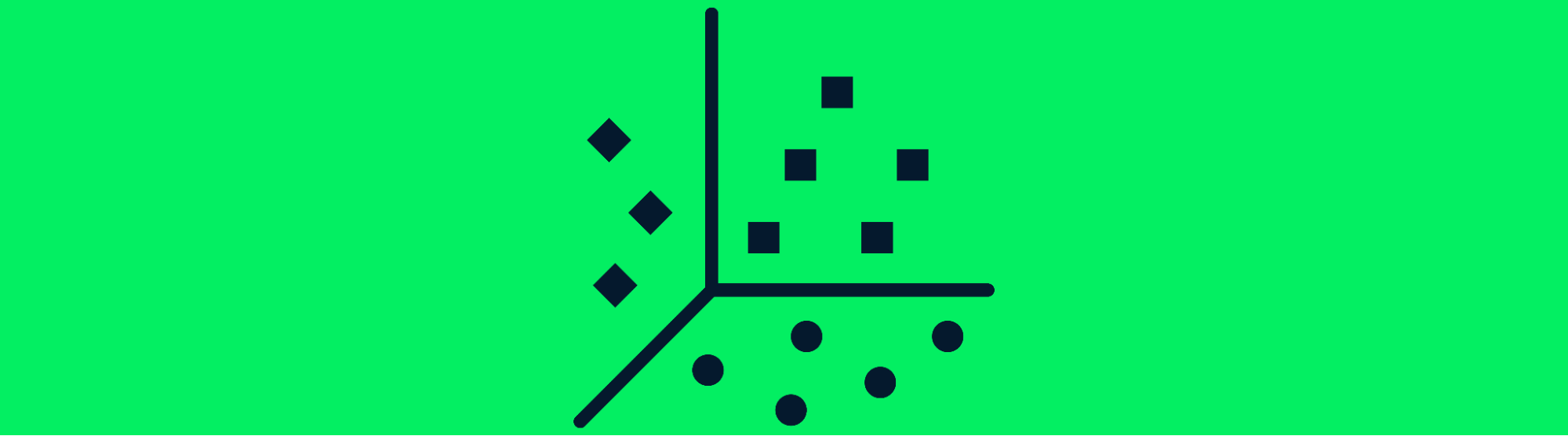 Clustering von Daten
Clustering von Daten
Reinforcement Learning
Reinforcement Learning (RL) ist eine Methode des maschinellen Lernens, bei der Agenten verschiedene Verhaltensweisen aus der Umwelt lernen. Dieser Agent führt zufällige Aktionen aus und erhält Belohnungen. Der Agent lernt, seine Ziele durch Versuch und Irrtum in einer komplexen Umgebung ohne menschliches Eingreifen zu erreichen.
So wie ein Baby durch die Ermutigung seiner Eltern das Laufen lernt, lernt die KI, bestimmte Aufgaben auszuführen, indem sie die Belohnungen maximiert, und der Designer legt die Belohnungspolitik fest. In letzter Zeit hat RL durch die Fortschritte in der Robotik, selbstfahrende Autos, das Besiegen von Profispielern in Spielen und die Landung von Raketen auf der Erde hohe Anforderungen an die Automatisierung gestellt.
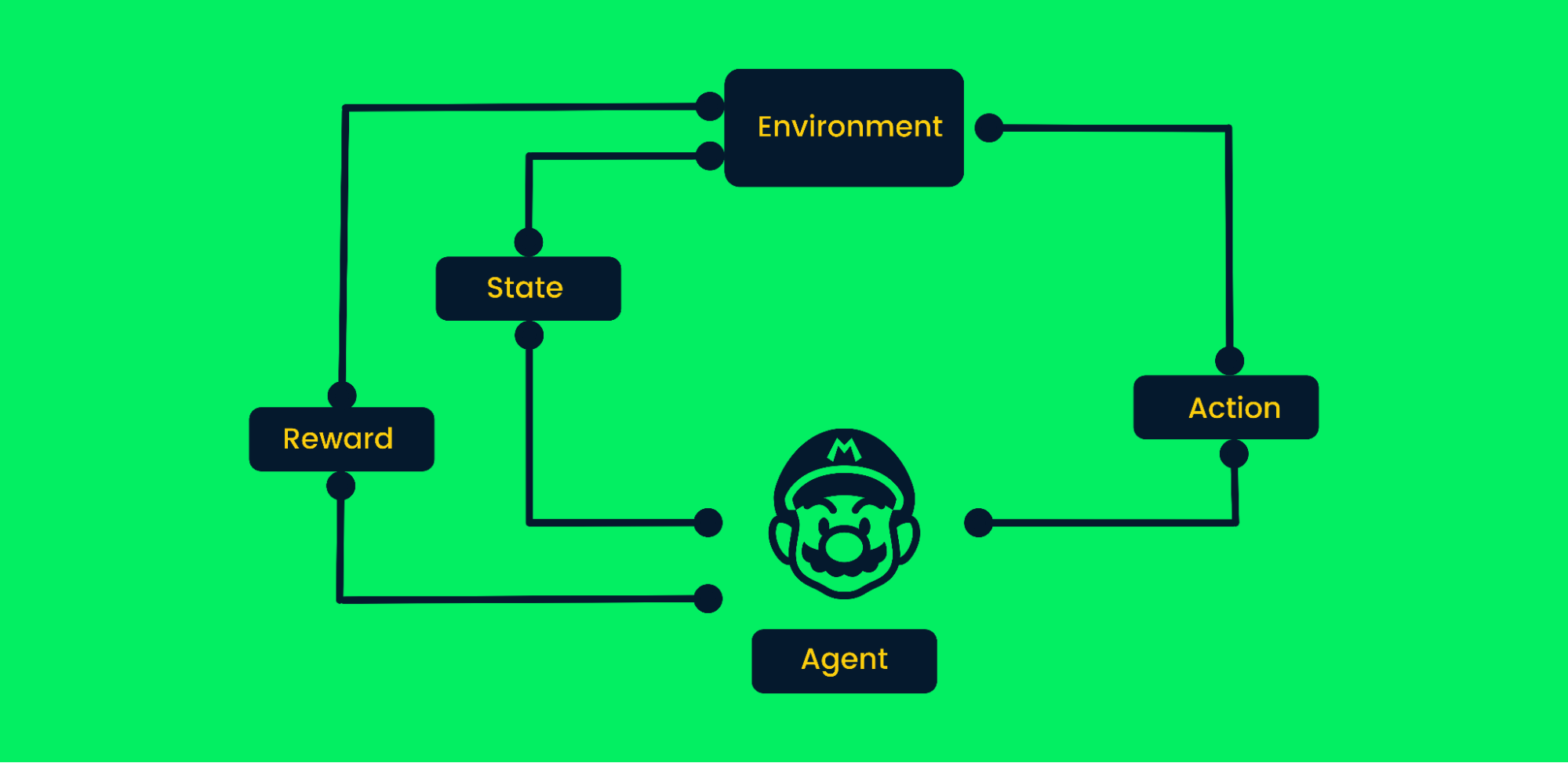 Reinforcement Learning Rahmenwerk
Reinforcement Learning Rahmenwerk
Nehmen wir das Mario-Videospiel als Beispiel:
- Zu Beginn erhält der Agent (Marios Figur) den Zustand Null von der Umgebung.
- Basierend auf dem Zustand wird ein Agent eine Aktion ausführen, in unserem Fall hat Mario sich nach rechts bewegt.
- Jetzt hat sich der Zustand geändert und die Figur befindet sich in einem neuen Rahmen.
- Der Agent erhält eine Belohnung, denn durch die Bewegung nach rechts ist die Figur nicht tot. Unser Hauptziel ist es, die Belohnungen zu maximieren.
Der Agent setzt die Schleife der Aktionen und der Maximierung der Belohnungen fort, bis er das Ende der Phase erreicht oder stirbt. Erfahre mehr unter An Introduction to Reinforcement Learning.
Generative adversarische Netze
Generative adversarische Netzwerke (GANs) verwenden zwei neuronale Netze, die zusammen synthetische Instanzen von Originaldaten erzeugen. GANs haben in den letzten Jahren viel an Popularität gewonnen, da sie in der Lage sind, einige der großen Künstler zu imitieren und Meisterwerke zu schaffen. Sie werden häufig für die Erstellung von synthetischer Kunst, Videos, Musik und Texten verwendet. Erfahre mehr über Anwendungen in der Praxis unter Generative Adversarial Networks Tutorial.
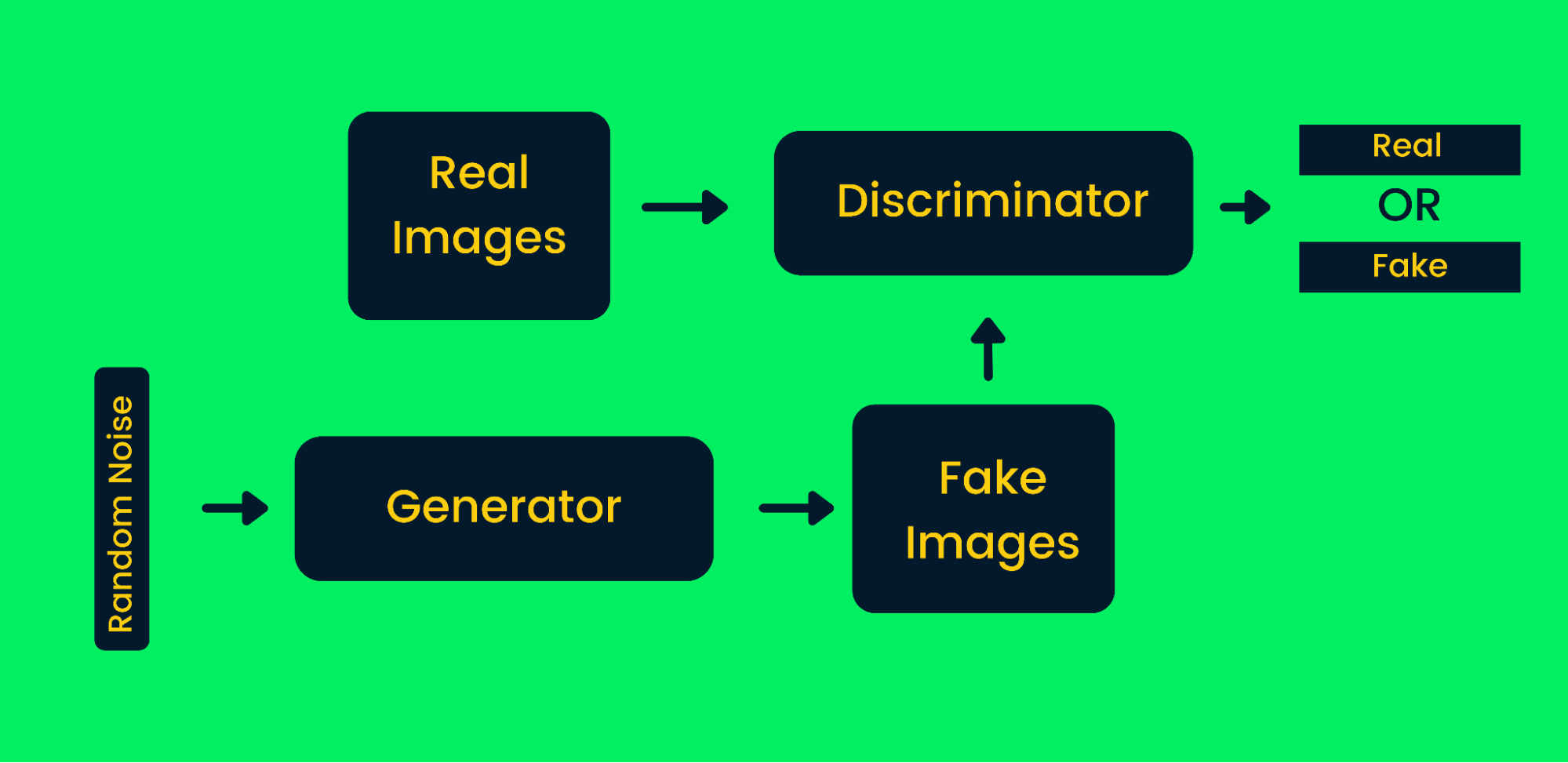 Generatives adversariales Netzwerk-Framework
Generatives adversariales Netzwerk-Framework
Wie GANs bei der Erzeugung synthetischer Bilder funktionieren:
- Zuerst nehmen die Generator-Netzwerke Zufallsrauschen als Input und erzeugen gefälschte Bilder.
- Die erzeugten und die echten Bilder werden in den Diskriminator eingespeist.
- Der Diskriminator entscheidet, ob das erzeugte Bild echt ist oder nicht. Sie liefert Wahrscheinlichkeiten von null bis eins, wobei null für ein gefälschtes Bild und eins für ein echtes Bild steht. Die Architektur der GANs enthält zwei Feedback-Schleifen. Der Diskriminator befindet sich in einer Rückkopplungsschleife mit echten Bildern, während der Generator in einer Rückkopplungsschleife mit einem Diskriminator steht. Sie arbeiten zusammen, um authentischere Bilder zu produzieren.
Graph Neuronales Netzwerk
Ein Graph ist eine Datenstruktur, die aus Kanten und Eckpunkten besteht. Die Kanten können gerichtet sein, wenn es Richtungsabhängigkeiten zwischen denKnoten gibt, auch bekannt als gerichtete Graphen. Die grünen Kreise im Diagramm unten sind die Knotenpunkte und die Pfeile stellen die Kanten dar.
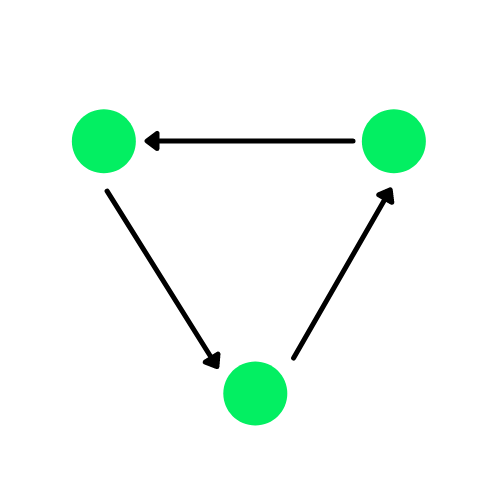
Ein gerichteter Graph
Ein Graph Neural Network (GNN) ist eine Art von Deep Learning-Architektur, die direkt auf Graphenstrukturen arbeitet. GNNs werden bei der Analyse großer Datenmengen, bei Empfehlungssystemen und bei Computervisionen eingesetzt.
 Ein Graphennetzwerk
Ein Graphennetzwerk
Sie werden auch für die Klassifizierung von Knoten, die Vorhersage von Verbindungen und das Clustering verwendet. In einigen Fällen haben Graphneuronale Netze besser abgeschnitten als Faltungsneuronale Netze, zum Beispiel bei der Erkennung von Objekten und der Vorhersage semantischer Beziehungen.
Natürliche Sprachverarbeitung
Natürliche Sprachverarbeitung (NLP) nutzt Deep-Learning-Technologien, um Computern zu helfen, eine natürliche menschliche Sprache zu lernen. NLP nutzt Deep Learning, um menschliche Sprache zu lesen, zu entschlüsseln und zu verstehen. Sie wird häufig für die Verarbeitung von Sprache, Text und Bildern eingesetzt. Die Einführung des Transfer-Lernens hat NLP auf die nächste Stufe gehoben, da wir in der Lage sind, das Modell mit wenigen Stichproben zu verfeinern und eine Spitzenleistung zu erzielen.
 Unterkategorien von NLP
Unterkategorien von NLP
NLP kann in mehrere Bereiche unterteilt werden:
- Übersetzung: Übersetzen von Sprachen, Molekularstrukturen und mathematischen Gleichungen
- Zusammenfassen: Große Textabschnitte in wenigen Zeilen zusammenfassen und dabei die wichtigsten Informationen beibehalten.
- Klassifizierung: Unterteilung des Textes in verschiedene Kategorien.
- Generierung: Text-zu-Text-Generierung; damit kannst du ganze Aufsätze mit einer einzigen Textzeile erstellen.
- Konversation: Virtueller Assistent, der das Wissen aus früheren Gesprächen behält und menschliche Gespräche nachahmt.
- Beantworte Fragen: KI beantwortet Fragen mit Hilfe von Q&A-Daten.
- Merkmalsextraktion: um Muster im Text zu erkennen oder Informationen zu extrahieren, wie z.B. "name entity recognition" und "part of speech".
- Satzähnlichkeiten: Ähnlichkeiten zwischen verschiedenen Texten bewerten.
- Text to Speech: Umwandlung von Text in hörbare Sprache.
- Automatische Spracherkennung: verschiedene Laute verstehen und in Text umwandeln.
- Optische Zeichenerkennung: Extraktion von Textdaten aus Bildern.
Wenn du die verschiedenen Anwendungsmöglichkeiten von NLP testen willst, probiere Hugging Face Spaces aus. Die Spaces beherbergen alle Arten von Webanwendungen, mit denen du herumspielen kannst, um Inspiration für dein NLP-Projekt zu bekommen.
Ein tieferer Blick auf Deep Learning-Konzepte
Aktivierungsfunktionen
In neuronalen Netzen erzeugt die Aktivierungsfunktion Entscheidungsgrenzen für die Ausgabe und wird verwendet, um die Leistung des Modells zu verbessern. Die Aktivierungsfunktion ist ein mathematischer Ausdruck, der auf der Grundlage seiner Bedeutung entscheidet, ob die Eingabe ein Neuron durchlaufen soll oder nicht. Außerdem verleiht sie den Netzwerken Nicht-Linearität. Ohne Aktivierungsfunktion wird das neuronale Netz zu einem einfachen linearen Regressionsmodell.
Es gibt verschiedene Arten von Aktivierungsfunktionen:
- Tanh
- ReLU
- Sigmoid
- Linear
- Softmax
- Swish
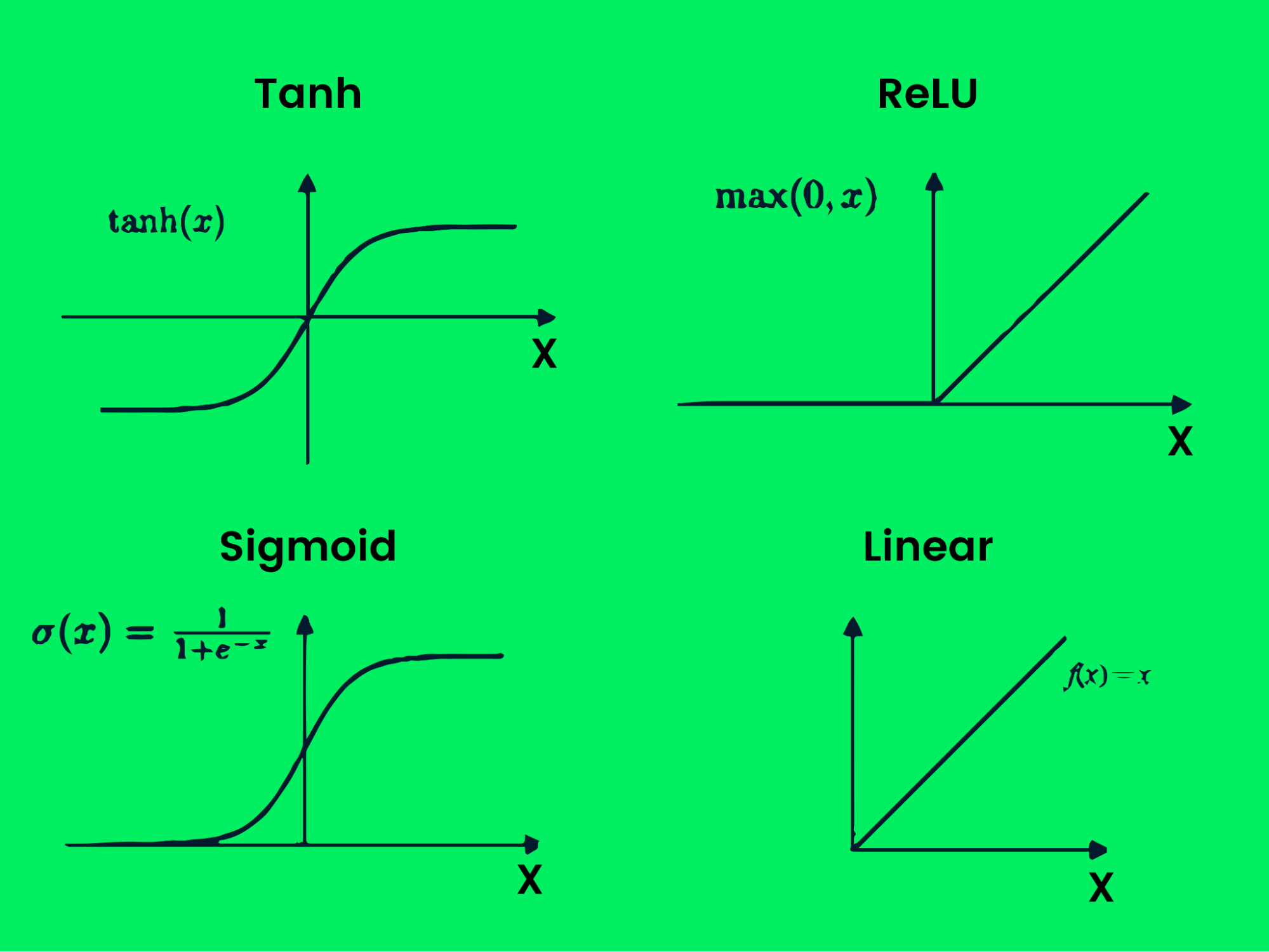 Aktivierung Funktion
Aktivierung Funktion
Diese Funktionen erzeugen verschiedene Ausgabegrenzen, wie in der Abbildung oben zu sehen ist. Mit mehreren Schichten und Aktivierungsfunktionen kannst du jedes komplexe Problem lösen. Erfahre mehr darüber, was Aktivierungsfunktionen beim Deep Learning sind.
Verlustfunktion
Die Verlustfunktion ist die Differenz zwischen den tatsächlichen und den vorhergesagten Werten. So können neuronale Netze die Gesamtleistung des Modells verfolgen. Je nach Problemstellung haben wir uns für eine bestimmte Art von Funktion entschieden, zum Beispiel für den mittleren quadratischen Fehler.
Verlust = Summe (vorhergesagt - tatsächlich)²
Die am häufigsten verwendeten Verlustfunktionen beim Deep Learning sind:
- Binäre Kreuzentropie
- Kategorisches Scharnier
- Mittlerer quadratischer Fehler
- Huber
- Spärliche kategoriale Kreuzentropie
Backpropagation
Bei der Forwarding Propagation initialisieren wir unser neuronales Netz mit zufälligen Eingaben, um eine ebenfalls zufällige Ausgabe zu erzeugen. Um die Leistung unseres Modells zu verbessern, passen wir die Gewichte mithilfe von Backpropagation zufällig an. Um die Leistung des Modells zu verfolgen, brauchen wir eine Verlustfunktion, die globale Minima findet, um die Genauigkeit des Modells zu maximieren.
Stochastischer Gradientenabstieg
Der Gradientenabstieg wird verwendet, um die Verlustfunktion zu optimieren, indem die Gewichte kontrolliert verändert werden, um den Verlust zu minimieren. Jetzt haben wir ein Ziel, aber wir brauchen Hinweise, ob wir die Gewichte erhöhen oder verringern sollen, um eine bessere Leistung zu erzielen. Die Ableitung der Verlustfunktion gibt uns die Richtung vor und wir können sie nutzen, um die Gewichte des Netzes zu aktualisieren.
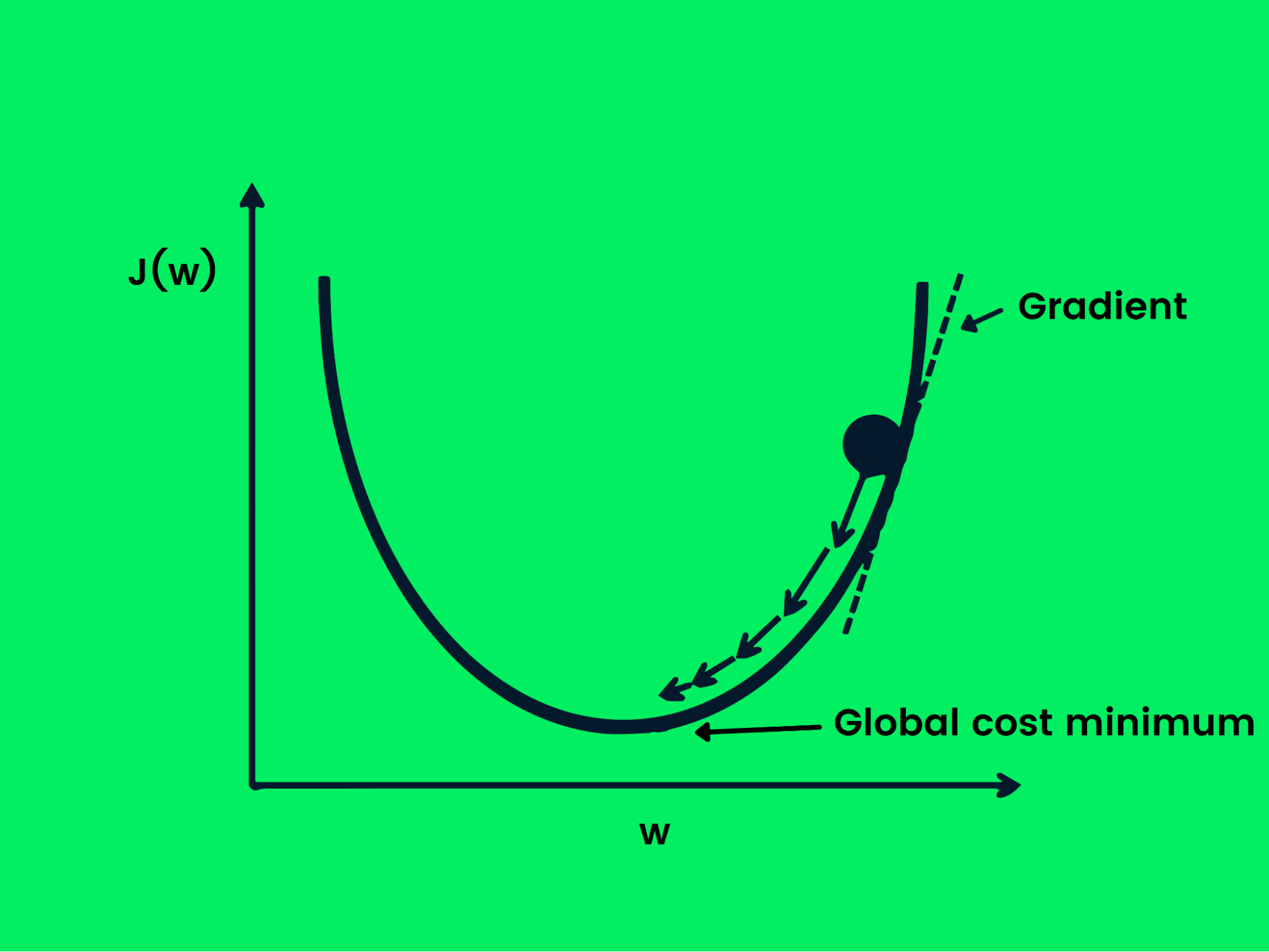 Gradientenabstieg
Gradientenabstieg
Die folgende Gleichung zeigt, wie die Gewichte mithilfe des Gradientenabstiegs aktualisiert werden.
w = w -Jw
Beim stochastischen Gradientenabstieg werden die Stichproben in Stapel aufgeteilt, anstatt den gesamten Datensatz zur Optimierung des Gradientenabstiegs zu verwenden. Das ist nützlich, wenn du den minimalen Verlust schneller erreichen und die Rechenleistung optimieren willst.
Hyperparameter
Hyperparameter sind die einstellbaren Parameter, die vor dem Trainingsprozess angepasst werden. Diese Parameter wirken sich direkt auf die Leistung des Modells aus und helfen dir, schneller globale Minima zu erreichen.
Liste der am häufigsten verwendeten Hyperparameter:
- Lernrate: Schrittgröße jeder Iteration, die von 0,1 bis 0,0001 eingestellt werden kann. Kurz gesagt, sie bestimmt die Geschwindigkeit, mit der das Modell lernt.
- Stapelgröße: Anzahl der Proben, die gleichzeitig durch ein neuronales Netz laufen.
- Anzahl der Epochen: eine Iteration, die angibt, wie oft das Modell die Gewichte ändert. Zu viele Epochen können zu einer Überanpassung der Modelle führen und zu wenige zu einer Unteranpassung, daher müssen wir eine mittlere Anzahl wählen.
Mehr darüber, wie diese Komponenten zusammenarbeiten, erfährst du im Keras Tutorial: Deep Learning in Python.
Beliebte Algorithmen
Convolutional Neural Networks
Das Convolutional Neural Network (CNN) ist ein neuronales Netzwerk mit Vorwärtskopplung, das eine strukturierte Reihe von Daten verarbeiten kann. Sie wird häufig für Computer-Vision-Anwendungen wie die Bildklassifizierung verwendet.
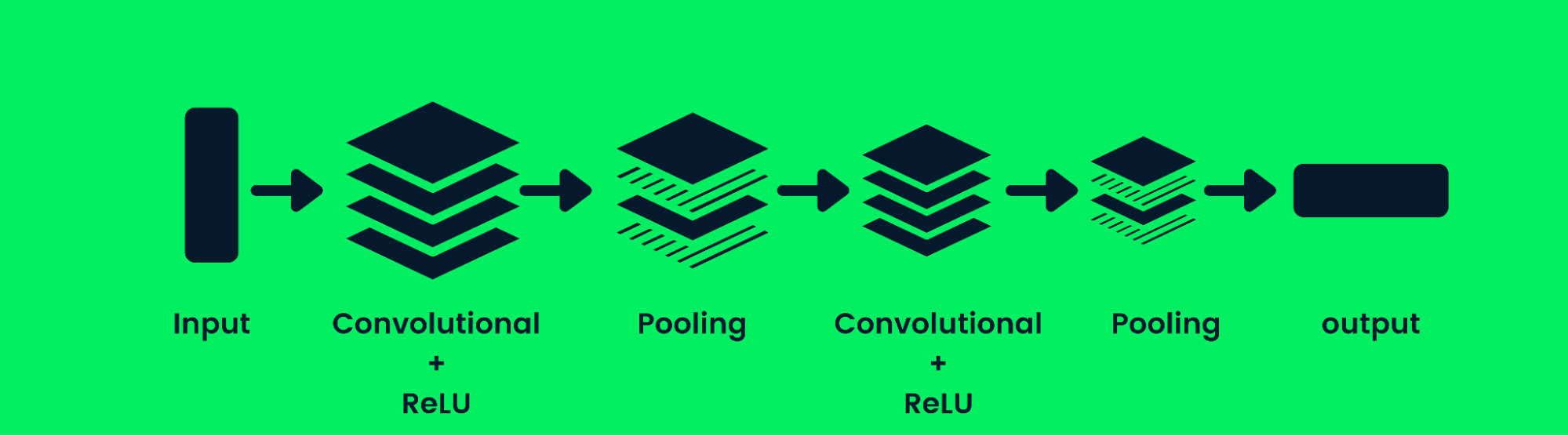 Architektur des neuronalen Faltungsnetzwerks
Architektur des neuronalen Faltungsnetzwerks
CNNs sind gut darin, Muster, Linien und Formen zu erkennen. Das CNN besteht aus einer Faltungsschicht, einer Pooling-Schicht und einer Ausgabeschicht (fully connected layers). Die Modelle zur Bildklassifizierung enthalten in der Regel mehrere Faltungsschichten, gefolgt von Pooling-Schichten, da zusätzliche Schichten die Genauigkeit des Modells erhöhen. Hier erfährst du mehr über Faltungsschichten: Convolutional Neural Networks in Python.
Rekurrente neuronale Netze
Rekurrente neuronale Netze (RNN) unterscheiden sich von Feed-Forward-Netzen, da die Ausgabe der Schicht in die Eingabe zurückgeführt wird, um die Ausgabe der Schicht vorherzusagen. Das hilft ihm, bei sequentiellen Daten besser abzuschneiden, da es die Informationen früherer Proben speichern kann, um zukünftige Proben vorherzusagen. Erfahre mehr unter Recurrent Neural Network (RNN) Tutorial: Arten und Beispiele.
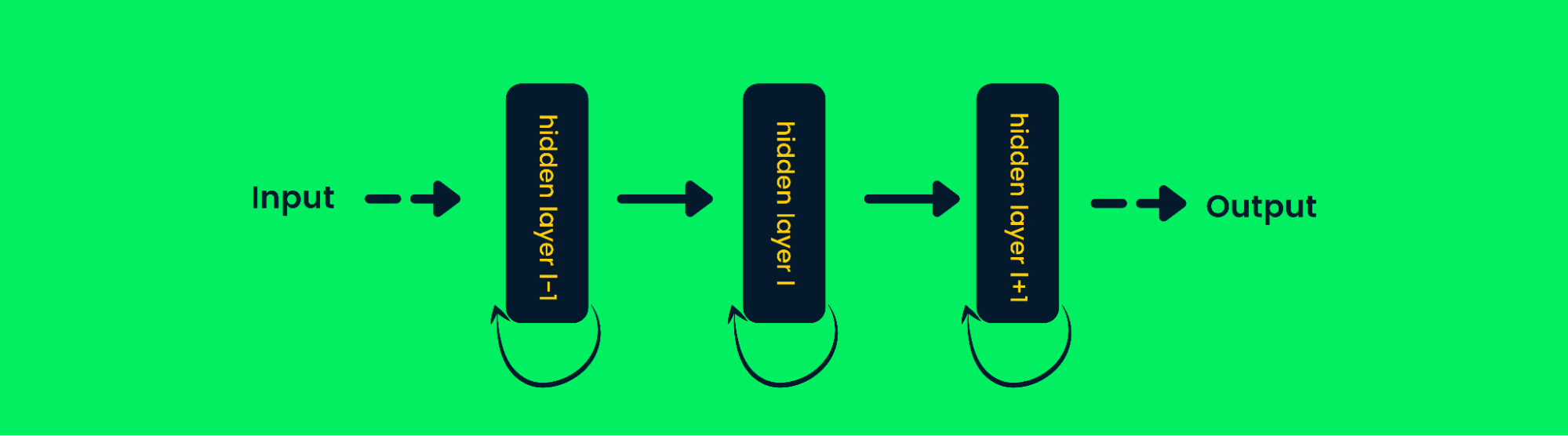 Rekurrente neuronale Netzwerkarchitektur
Rekurrente neuronale Netzwerkarchitektur
In herkömmlichen neuronalen Netzen wird die Ausgabe der Schichten auf der Grundlage der aktuellen Eingabewerte berechnet, aber in RNN wird die Ausgabe auch auf der Grundlage früherer Eingaben berechnet. Das macht sie ziemlich gut darin, das nächste Wort vorauszusagen, Aktienkurse zu prognostizieren, in KI-Chatbots zu arbeiten und Anomalien zu erkennen.
Netzwerke des Kurzzeitgedächtnisses
Netze mit langem Kurzzeitgedächtnis (LSTM) sind fortschrittliche Arten von rekurrenten neuronalen Netzen, die mehr Informationen über vergangene Werte speichern können. Sie löst das Problem der verschwindenden Steigung, das bei einfachen RNN auftritt.
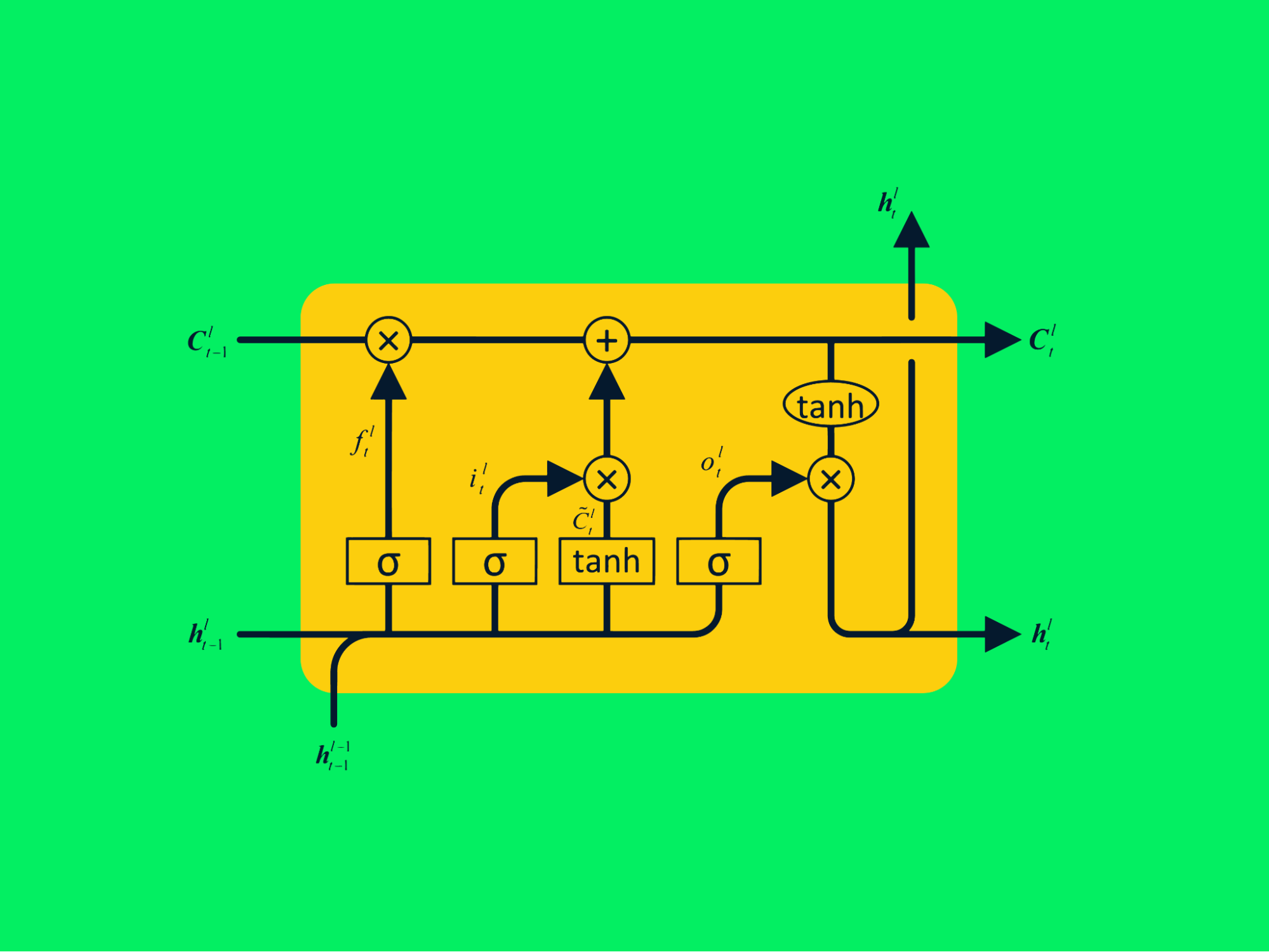 LSTM-Architektur
LSTM-Architektur
Das typische RNN besteht aus sich wiederholenden neuronalen Netzen mit einer einzigen Tanh-Schicht, während das LSTM aus vier interaktiven Schichten besteht, die miteinander kommunizieren, um große Datenfolgen zu verarbeiten.
Praktische Erfahrungen kannst du mit dem folgenden Tutorial sammeln: LSTM für Aktienprognosen oder den Kurs Advanced Deep Learning with Keras, wenn du mehr über Deep Learning-Modelle erfahren möchtest.
Deep Learning Frameworks
Es gibt mehrere Deep-Learning-Frameworks wie MxNet, CNTK und Caffe2, aber wir werden uns mit den beliebtesten Frameworks beschäftigen.
Tensorflow
Tensorflow (TF) ist eine Open-Source-Bibliothek, die für die Erstellung von Deep-Learning-Anwendungen verwendet wird. Es enthält alle notwendigen Werkzeuge, um zu experimentieren und kommerzielle KI-Produkte zu entwickeln. Es unterstützt sowohl CPU, GPU als auch TPU für das Training komplexer Modelle. TF wurde ursprünglich vom Google-KI-Team für den internen Gebrauch entwickelt und ist jetzt für die Öffentlichkeit zugänglich.
Die Tensorflow-API ist für browserbasierte Anwendungen und mobile Geräte verfügbar, und TensorFlow Extended ist ideal für die Produktion. TF ist mittlerweile zum Industriestandard geworden und wird sowohl für die akademische Forschung als auch für den Einsatz von Deep Learning-Modellen in der Produktion verwendet.
TF wird auch mit Tensorboard geliefert , einem Dashboard, mit dem du deine Machine Learning Experimente analysieren kannst. Vor kurzem haben die Tensorflow-Entwickler Keras in ihr Framework integriert, das für die Entwicklung tiefer neuronaler Netze beliebt ist. Erfahre mehr im Kurs Einführung in TensorFlow in Python.
Keras
Keras ist ein Framework für neuronale Netze, das in Python geschrieben wurde und auf mehreren Frameworks wie Tensorflow und Theano laufen kann. Keras ist eine Open-Source-Bibliothek, die entwickelt wurde, um schnelles Experimentieren im Bereich Deep Learning zu ermöglichen, damit du deine Konzepte leicht in funktionierende KI-Anwendungen umsetzen kannst.
Die Dokumentation ist leicht verständlich und die API ähnelt der von Numpy, so dass du sie leicht in jedes Data Science-Projekt integrieren kannst. Genau wie TF kann auch Keras auf CPU, GPU und TPU laufen, je nach verfügbarer Hardware. Erfahre mehr unter Einführung in Deep Learning mit Keras.
PyTorch
PyTorch ist das beliebteste und einfachste Deep Learning Framework. Es verwendet Tensoren anstelle von Numpy-Arrays, um schnelle numerische Berechnungen mit Hilfe der GPU durchzuführen. PyTorch wird hauptsächlich für Deep Learning und die Entwicklung komplexer maschineller Lernmodelle verwendet.
Akademische Forscher bevorzugen PyTorch wegen seiner Flexibilität und Benutzerfreundlichkeit. Es ist in C++ und Python geschrieben und verfügt über GPUs und TPUs zur Beschleunigung. Es ist zu einer Komplettlösung für alle Deep-Learning-Probleme geworden. Wenn du mehr über PyTorch erfahren möchtest, solltest du den Kurs Einführung in Deep Learning mit PyTorch besuchen.
Fazit
In diesem Tutorium haben wir uns damit beschäftigt, was Deep Learning ist, welche Grundlagen es hat, wie es funktioniert und welche Anwendungen es gibt. Wir haben auch gelernt, wie tiefe neuronale Netze funktionieren und welche verschiedenen Arten von Deep-Learning-Modellen es gibt. Schließlich hast du einige beliebte Deep-Learning-Frameworks kennengelernt.
In diesem Tutorial hast du alle wichtigen Informationen erhalten, die du für den Einstieg in das Thema Deep Learning brauchst. Der Lernpfad Deep Learning in Python bereitet dich auf die Arbeit an realen Projekten vor. Du kannst auch Deep Learning mit Keras in R ausprobieren, wenn du mit der Programmiersprache R vertraut bist.
