
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Um auf das Gemini 2.5 Pro Modell über die Google API zuzugreifen, befolge diese Schritte:
Installiere zunächst das google-genai Python-Paket. Führe den folgenden Befehl in deinem Terminal aus:
pip install google-genaiGehe zu Google AI Studio und generiere deinen API-Schlüssel. Setzen Sie dann den API-Schlüssel als eine Umgebungsvariable in deinem System.
Verwende den API-Schlüssel, um den Google GenAI-Client zu initialisieren. Dieser Client ermöglicht es dir, mit dem Gemini 2.5 Pro Modell zu interagieren.
import os
from google import genai
from google.genai import types
from IPython.display import Markdown, HTML, Image, display
API_KEY = os.environ.get("GEMINI_API_KEY")
client = genai.Client(api_key=API_KEY)Lade die Python-Datei, mit der du arbeiten willst, und erstelle eine Eingabeaufforderung für das Modell.
# Load the Python file as text
file_path = "secure_app.py"
with open(file_path, "r") as file:
doc_data = file.read()
prompt = "Please integrate user management into the FastAPI application."
contents = [
types.Part.from_bytes(
data=doc_data.encode("utf-8"),
mime_type="text/x-python",
),
prompt,
]Erstelle eine Chat-Instanz mit dem Gemini 2.5 Pro Modell (gemini-2.5-pro-exp-03-25) und versorge sie mit dem Inhalt der Datei und der Eingabeaufforderung. Das Modell analysiert den Code und erzeugt eine Antwort.
chat = client.aio.chats.create(
model="gemini-2.5-pro-exp-03-25",
config=types.GenerateContentConfig(
tools=[types.Tool(code_execution=types.ToolCodeExecution)]
),
)
response = await chat.send_message(contents)
Markdown(response.text)Innerhalb von Sekunden wurde die kontextabhängige Antwort erstellt.
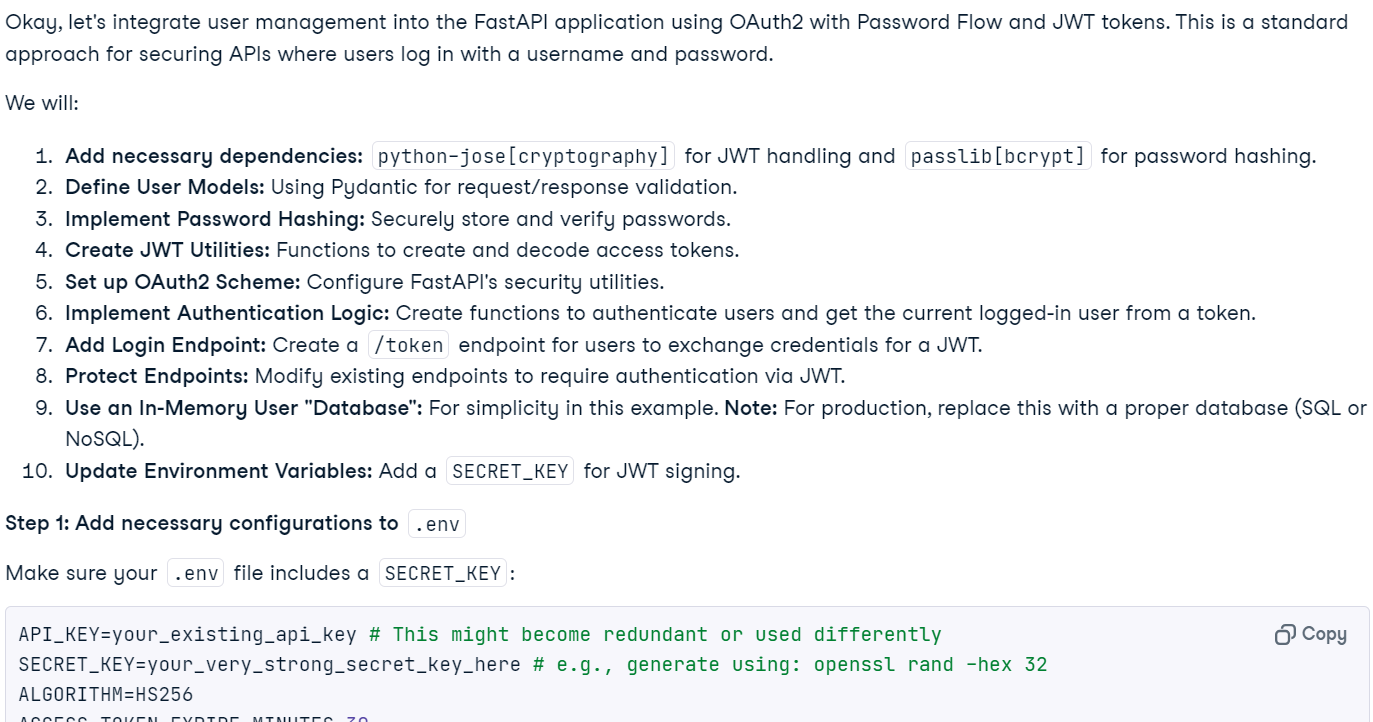
Hinweis: Der freie Zugang zum Modell ist derzeit aufgrund der hohen Auslastung möglicherweise nicht möglich. Warte einfach ein paar Minuten und versuche es erneut.
Du kannst das Modell auch auffordern, den Code auszuführen.
response = await chat.send_message('Please run the code to ensure that everything is functioning properly.')
Markdown(response.text)Beachte, dass diese Funktion experimentell ist und Einschränkungen hat. Das Modell kann zum Beispiel keine Webserver betreiben, nicht auf das Dateisystem zugreifen und keine Netzwerkoperationen durchführen.

Hinweis: Das Modell Gemini 2.5 Pro bietet erweiterte "denkende" Fähigkeiten. Diese sind zwar in Google AI Studio sichtbar, werden aber in der API-Ausgabe nicht berücksichtigt.
Mit dieser Anwendung können Nutzer/innen Dateien, auch mehrere Dateien oder sogar ein ZIP-Archiv, das ein ganzes Projekt enthält, in eine chatbasierte Oberfläche hochladen. Die Nutzer können Fragen zu ihrem Projekt stellen, Probleme beheben oder ihre Codebasis verbessern. Im Gegensatz zu herkömmlichen KI-Code-Editoren, die aufgrund ihrer Beschränkungen mit großen Kontexten zu kämpfen haben, kann Gemini 2.5 Pro mit seinem langen Kontextfenster effektiv Probleme in einem ganzen Projekt analysieren und lösen.
Installiere gradio für die Erstellung der Benutzeroberfläche und zipfile36 für den Umgang mit ZIP-Dateien.
pip install gradio==5.14.0
pip install zipfile36==0.1.3Importiere die notwendigen Python-Pakete, definiere globale Variablen, initialisiere den GenAI-Client, richte UI-Konstanten ein und erstelle eine Liste der unterstützten Dateierweiterungen.
import os
import zipfile
from typing import Dict, List, Optional, Union
import gradio as gr
from google import genai
from google.genai import types
# Retrieve API key for Google GenAI from the environment variables.
GOOGLE_API_KEY = os.environ.get("GOOGLE_API_KEY")
# Initialize the client so that it can be reused across functions.
CLIENT = genai.Client(api_key=GOOGLE_API_KEY)
# Global variables
EXTRACTED_FILES = {}
# Store chat sessions
CHAT_SESSIONS = {}
TITLE = """<h1 align="center">✨ Gemini Code Analysis</h1>"""
AVATAR_IMAGES = (None, "https://media.roboflow.com/spaces/gemini-icon.png")
# List of supported text extensions (alphabetically sorted)
TEXT_EXTENSIONS = [
".bat",
".c",
".cfg",
".conf",
".cpp",
".cs",
".css",
".go",
".h",
".html",
".ini",
".java",
".js",
".json",
".jsx",
".md",
".php",
".ps1",
".py",
".rb",
".rs",
".sh",
".toml",
".ts",
".tsx",
".txt",
".xml",
".yaml",
".yml",
]Die Funktion extract_text_from_zip() extrahiert Textinhalte aus Dateien in einem ZIP-Archiv und gibt sie als Wörterbuch zurück.
def extract_text_from_zip(zip_file_path: str) -> Dict[str, str]:
text_contents = {}
with zipfile.ZipFile(zip_file_path, "r") as zip_ref:
for file_info in zip_ref.infolist():
# Skip directories
if file_info.filename.endswith("/"):
continue
# Skip binary files and focus on text files
file_ext = os.path.splitext(file_info.filename)[1].lower()
if file_ext in TEXT_EXTENSIONS:
try:
with zip_ref.open(file_info) as file:
content = file.read().decode("utf-8", errors="replace")
text_contents[file_info.filename] = content
except Exception as e:
text_contents[file_info.filename] = (
f"Error extracting file: {str(e)}"
)
return text_contentsDie Funktion extract_text_from_single_file() extrahiert Textinhalte aus einer einzelnen Datei und gibt sie als Wörterbuch zurück.
def extract_text_from_single_file(file_path: str) -> Dict[str, str]:
text_contents = {}
filename = os.path.basename(file_path)
file_ext = os.path.splitext(filename)[1].lower()
if file_ext in TEXT_EXTENSIONS:
try:
with open(file_path, "r", encoding="utf-8", errors="replace") as file:
content = file.read()
text_contents[filename] = content
except Exception as e:
text_contents[filename] = f"Error reading file: {str(e)}"
return text_contentsDie Funktion upload_zip() verarbeitet hochgeladene Dateien, entweder im ZIP-Format oder Textdateien, extrahiert den Textinhalt und fügt eine Nachricht an den Chat an.
def upload_zip(files: Optional[List[str]], chatbot: List[Union[dict, gr.ChatMessage]]):
global EXTRACTED_FILES
# Handle multiple file uploads
if len(files) > 1:
total_files_processed = 0
total_files_extracted = 0
file_types = set()
# Process each file
for file in files:
filename = os.path.basename(file)
file_ext = os.path.splitext(filename)[1].lower()
# Process based on file type
if file_ext == ".zip":
extracted_files = extract_text_from_zip(file)
file_types.add("zip")
else:
extracted_files = extract_text_from_single_file(file)
file_types.add("text")
if extracted_files:
total_files_extracted += len(extracted_files)
# Store the extracted content in the global variable
EXTRACTED_FILES[filename] = extracted_files
total_files_processed += 1
# Create a summary message for multiple files
file_types_str = (
"files"
if len(file_types) > 1
else ("ZIP files" if "zip" in file_types else "text files")
)
# Create a list of uploaded file names
file_list = "\n".join([f"- {os.path.basename(file)}" for file in files])
chatbot.append(
gr.ChatMessage(
role="user",
content=f"<p>📚 Multiple {file_types_str} uploaded ({total_files_processed} files)</p><p>Extracted {total_files_extracted} text file(s) in total</p><p>Uploaded files:</p><pre>{file_list}</pre>",
)
)
# Handle single file upload (original behavior)
elif len(files) == 1:
file = files[0]
filename = os.path.basename(file)
file_ext = os.path.splitext(filename)[1].lower()
# Process based on file type
if file_ext == ".zip":
extracted_files = extract_text_from_zip(file)
file_type_msg = "📦 ZIP file"
else:
extracted_files = extract_text_from_single_file(file)
file_type_msg = "📄 File"
if not extracted_files:
chatbot.append(
gr.ChatMessage(
role="user",
content=f"<p>{file_type_msg} uploaded: {filename}, but no text content was found or the file format is not supported.</p>",
)
)
else:
file_list = "\n".join([f"- {name}" for name in extracted_files.keys()])
chatbot.append(
gr.ChatMessage(
role="user",
content=f"<p>{file_type_msg} uploaded: {filename}</p><p>Extracted {len(extracted_files)} text file(s):</p><pre>{file_list}</pre>",
)
)
# Store the extracted content in the global variable
EXTRACTED_FILES[filename] = extracted_files
return chatbotDie Funktion user() fügt die Texteingabe eines Nutzers an den Chatbot-Konversationsverlauf an.
def user(text_prompt: str, chatbot: List[gr.ChatMessage]):
if text_prompt:
chatbot.append(gr.ChatMessage(role="user", content=text_prompt))
return "", chatbotDie Funktion get_message_content() ruft den Inhalt einer Nachricht ab, die entweder ein Wörterbuch oder eine Gradio-Chat-Nachricht sein kann.
def get_message_content(msg):
if isinstance(msg, dict):
return msg.get("content", "")
return msg.contentDie Funktion send_to_gemini() sendet die Eingabeaufforderung des Nutzers an Gemini AI und streamt die Antwort zurück an den Chatbot. Wenn Codedateien hochgeladen werden, werden sie in den Kontext aufgenommen.
def send_to_gemini(chatbot: List[Union[dict, gr.ChatMessage]]):
global EXTRACTED_FILES, CHAT_SESSIONS
if len(chatbot) == 0:
chatbot.append(
gr.ChatMessage(
role="assistant",
content="Please enter a message to start the conversation.",
)
)
return chatbot
# Get the last user message as the prompt
user_messages = [
msg
for msg in chatbot
if (isinstance(msg, dict) and msg.get("role") == "user")
or (hasattr(msg, "role") and msg.role == "user")
]
if not user_messages:
chatbot.append(
gr.ChatMessage(
role="assistant",
content="Please enter a message to start the conversation.",
)
)
return chatbot
last_user_msg = user_messages[-1]
prompt = get_message_content(last_user_msg)
# Skip if the last message was about uploading a file (ZIP, single file, or multiple files)
if (
"📦 ZIP file uploaded:" in prompt
or "📄 File uploaded:" in prompt
or "📚 Multiple files uploaded" in prompt
):
chatbot.append(
gr.ChatMessage(
role="assistant",
content="What would you like to know about the code in this ZIP file?",
)
)
return chatbot
# Generate a unique session ID based on the extracted files or use a default key for no files
if EXTRACTED_FILES:
session_key = ",".join(sorted(EXTRACTED_FILES.keys()))
else:
session_key = "no_files"
# Create a new chat session if one doesn't exist for this set of files
if session_key not in CHAT_SESSIONS:
# Configure Gemini with code execution capability
CHAT_SESSIONS[session_key] = CLIENT.chats.create(
model="gemini-2.5-pro-exp-03-25",
)
# Send all extracted files to the chat session first
initial_contents = []
for zip_name, files in EXTRACTED_FILES.items():
for filename, content in files.items():
file_ext = os.path.splitext(filename)[1].lower()
mime_type = "text/plain"
# Set appropriate mime type based on file extension
if file_ext == ".py":
mime_type = "text/x-python"
elif file_ext in [".js", ".jsx"]:
mime_type = "text/javascript"
elif file_ext in [".ts", ".tsx"]:
mime_type = "text/typescript"
elif file_ext == ".html":
mime_type = "text/html"
elif file_ext == ".css":
mime_type = "text/css"
elif file_ext in [".json", ".jsonl"]:
mime_type = "application/json"
elif file_ext in [".xml", ".svg"]:
mime_type = "application/xml"
# Create a header with the filename to preserve original file identity
file_header = f"File: {filename}\n\n"
file_content = file_header + content
initial_contents.append(
types.Part.from_bytes(
data=file_content.encode("utf-8"),
mime_type=mime_type,
)
)
# Initialize the chat context with files if available
if initial_contents:
initial_contents.append(
"I've uploaded these code files for you to analyze. I'll ask questions about them next."
)
# Use synchronous API instead of async
CHAT_SESSIONS[session_key].send_message(initial_contents)
# For sessions without files, we don't need to send an initial message
# Append a placeholder for the assistant's response
chatbot.append(gr.ChatMessage(role="assistant", content=""))
# Send the user's prompt to the existing chat session using streaming API
response = CHAT_SESSIONS[session_key].send_message_stream(prompt)
# Process the response stream - text only (no images)
output_text = ""
for chunk in response:
if chunk.candidates and chunk.candidates[0].content.parts:
for part in chunk.candidates[0].content.parts:
if part.text is not None:
# Append the new chunk of text
output_text += part.text
# Update the last assistant message with the current accumulated response
if isinstance(chatbot[-1], dict):
chatbot[-1]["content"] = output_text
else:
chatbot[-1].content = output_text
# Yield the updated chatbot to show streaming updates in the UI
yield chatbot
# Return the final chatbot state
return chatbotDie Funktion rest_app() setzt die Anwendung zurück, indem sie den Chatverlauf und alle hochgeladenen Dateien löscht.
def reset_app(chatbot):
global EXTRACTED_FILES, CHAT_SESSIONS
# Clear the global variables
EXTRACTED_FILES = {}
CHAT_SESSIONS = {}
# Reset the chatbot with a welcome message
return [
gr.ChatMessage(
role="assistant",
content="App has been reset. You can start a new conversation or upload new files.",
)
]Definieren wir die Gradio-Komponenten: Chatbot, Texteingabe, Upload-Button und Steuerungsschaltflächen.
# Define the Gradio UI components
chatbot_component = gr.Chatbot(
label="Gemini 2.5 Pro",
type="messages",
bubble_full_width=False,
avatar_images=AVATAR_IMAGES,
scale=2,
height=350,
)
text_prompt_component = gr.Textbox(
placeholder="Ask a question or upload code files to analyze...",
show_label=False,
autofocus=True,
scale=28,
)
upload_zip_button_component = gr.UploadButton(
label="Upload",
file_count="multiple",
file_types=[".zip"] + TEXT_EXTENSIONS,
scale=1,
min_width=80,
)
send_button_component = gr.Button(
value="Send", variant="primary", scale=1, min_width=80
)
reset_button_component = gr.Button(
value="Reset", variant="stop", scale=1, min_width=80
)
# Define input lists for button chaining
user_inputs = [text_prompt_component, chatbot_component]Wir strukturieren die Gradio-Oberfläche mit Zeilen und Spalten, um ein klares Layout zu erhalten.
with gr.Blocks(theme=gr.themes.Ocean()) as demo:
gr.HTML(TITLE)
with gr.Column():
chatbot_component.render()
with gr.Row(equal_height=True):
text_prompt_component.render()
send_button_component.render()
upload_zip_button_component.render()
reset_button_component.render()
# When the Send button is clicked, first process the user text then send to Gemini
send_button_component.click(
fn=user,
inputs=user_inputs,
outputs=[text_prompt_component, chatbot_component],
queue=False,
).then(
fn=send_to_gemini,
inputs=[chatbot_component],
outputs=[chatbot_component],
api_name="send_to_gemini",
)
# Allow submission using the Enter key
text_prompt_component.submit(
fn=user,
inputs=user_inputs,
outputs=[text_prompt_component, chatbot_component],
queue=False,
).then(
fn=send_to_gemini,
inputs=[chatbot_component],
outputs=[chatbot_component],
api_name="send_to_gemini_submit",
)
# Handle ZIP file uploads
upload_zip_button_component.upload(
fn=upload_zip,
inputs=[upload_zip_button_component, chatbot_component],
outputs=[chatbot_component],
queue=False,
)
# Handle Reset button clicks
reset_button_component.click(
fn=reset_app,
inputs=[chatbot_component],
outputs=[chatbot_component],
queue=False,
)Starten wir die Gradio-Anwendung lokal mit aktivierter Warteschlange, um mehrere Anfragen zu bearbeiten.
# Launch the demo interface
demo.queue(max_size=99, api_open=False).launch(
debug=False,
show_error=True,
server_port=9595,
server_name="localhost",
)Um die Webanwendung zu starten, kombiniere alle oben genannten Codequellen in der Datei main.py (die ich auf GitHub hochgeladen habe, damit du sie leichter kopieren kannst). Führe es mit dem folgenden Befehl aus:
python main.pyDie Webanwendung ist unter folgender URL verfügbar: http://localhost:9595/
Du kannst die URL kopieren und in deinen Webbrowser einfügen.
Wie wir sehen können, verfügt die Webanwendung über eine Chatbot-Schnittstelle. Wir können es genau wie ChatGPT verwenden.
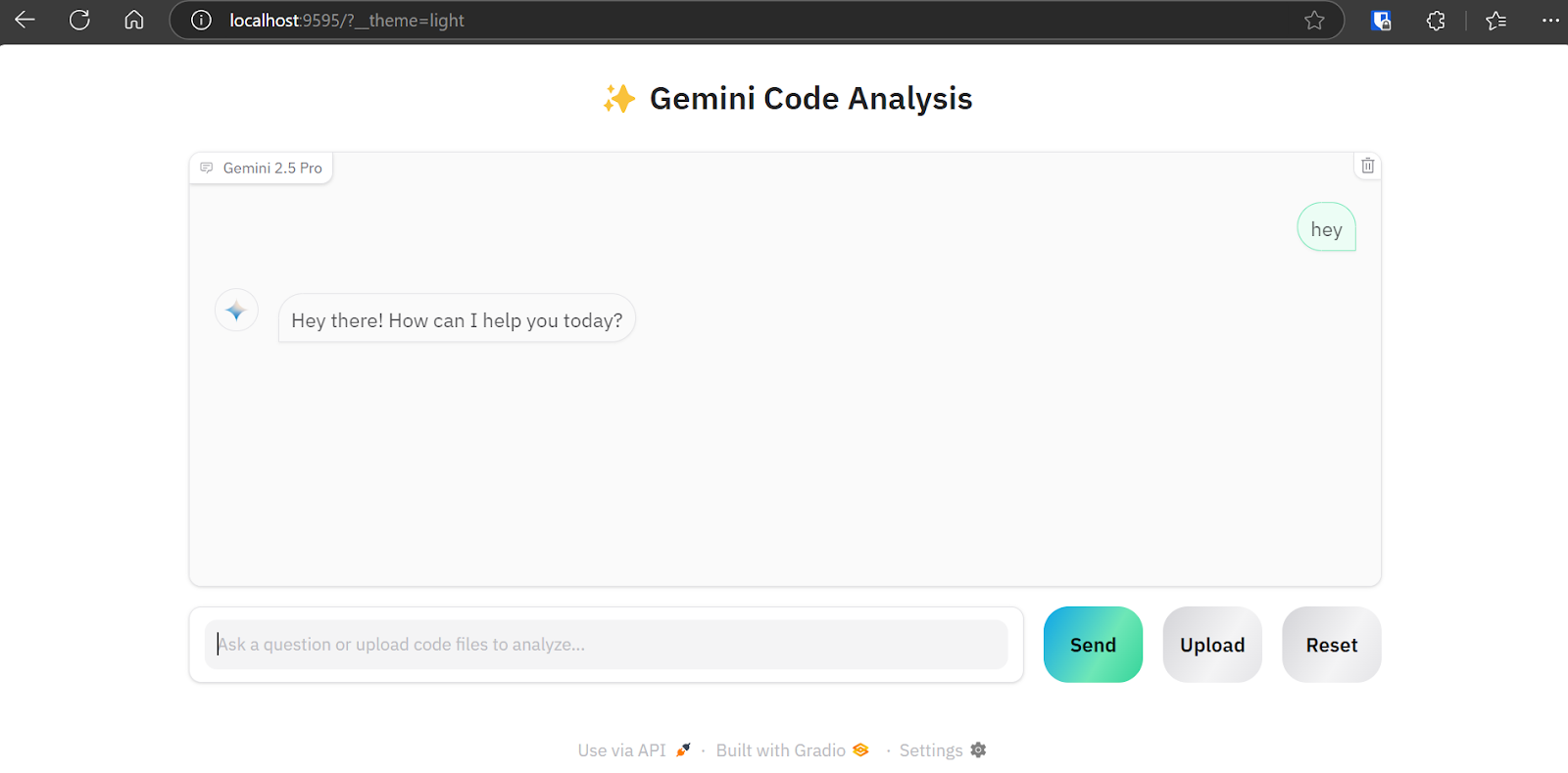
Die Schaltfläche "Hochladen" unterstützt das Hochladen von einzelnen und mehreren Dateien sowie von Zip-Dateien für dein Projekt. Mach dir also keine Sorgen, wenn dein Projekt mehr als 20 Dateien enthält; die Code-Analyse-App kann sie verarbeiten und an die Gemini 2.5 Pro API senden.

Lass uns mehrere Dateien hochladen und Gemini 2.5 Pro bitten, unser Projekt zu verbessern.
Wie wir sehen können, liefert das Modell richtige Vorschläge für Verbesserungen.
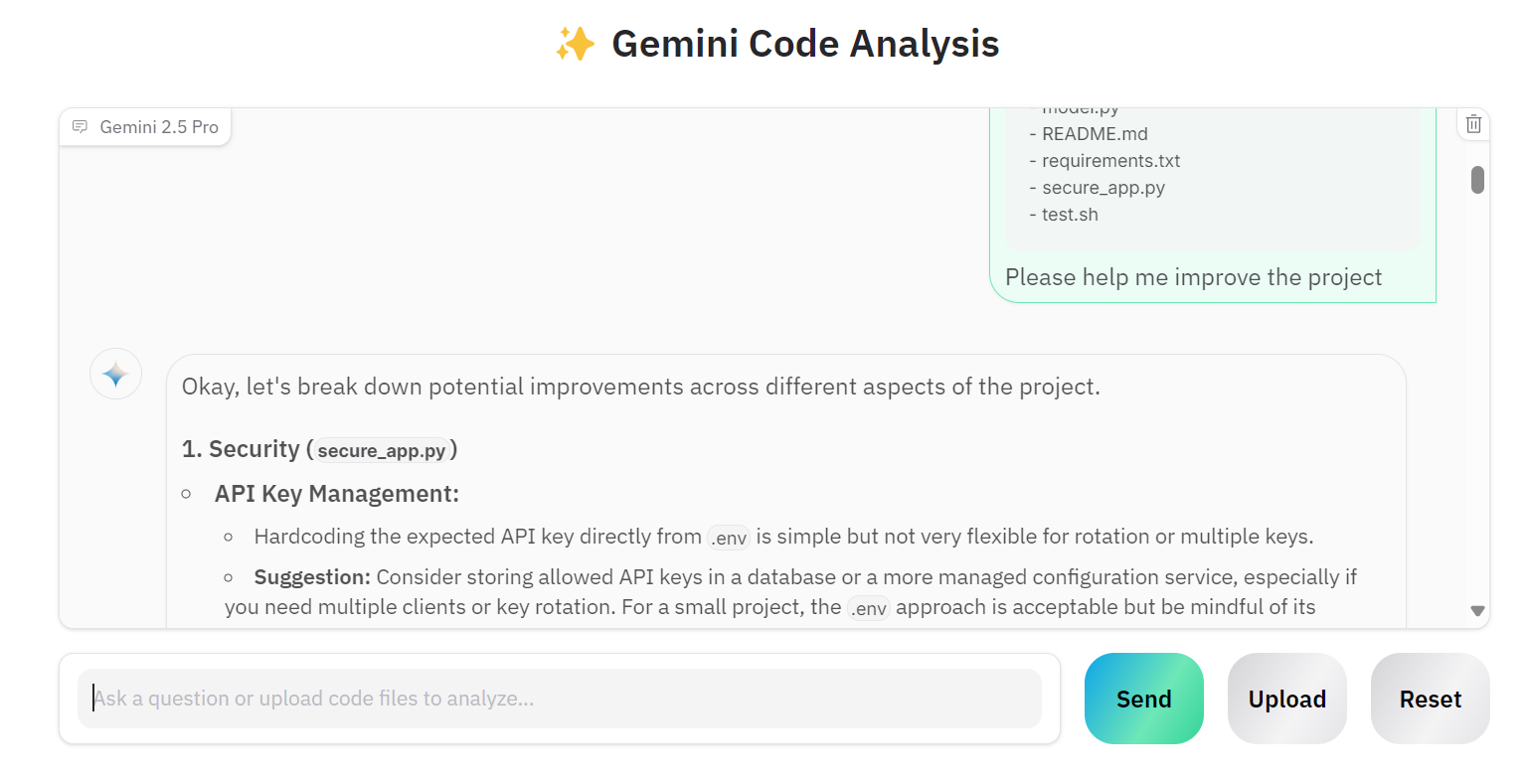
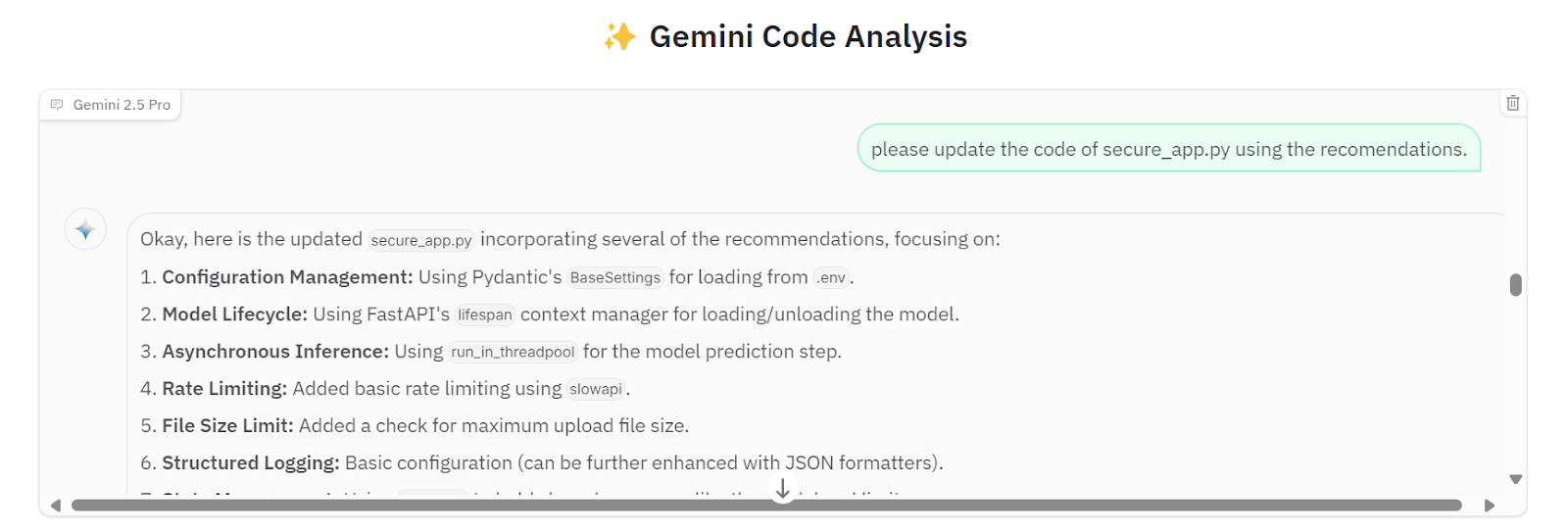
Wir können ihn bitten, alle Vorschläge in die secure_app.py Datei zu implementieren.
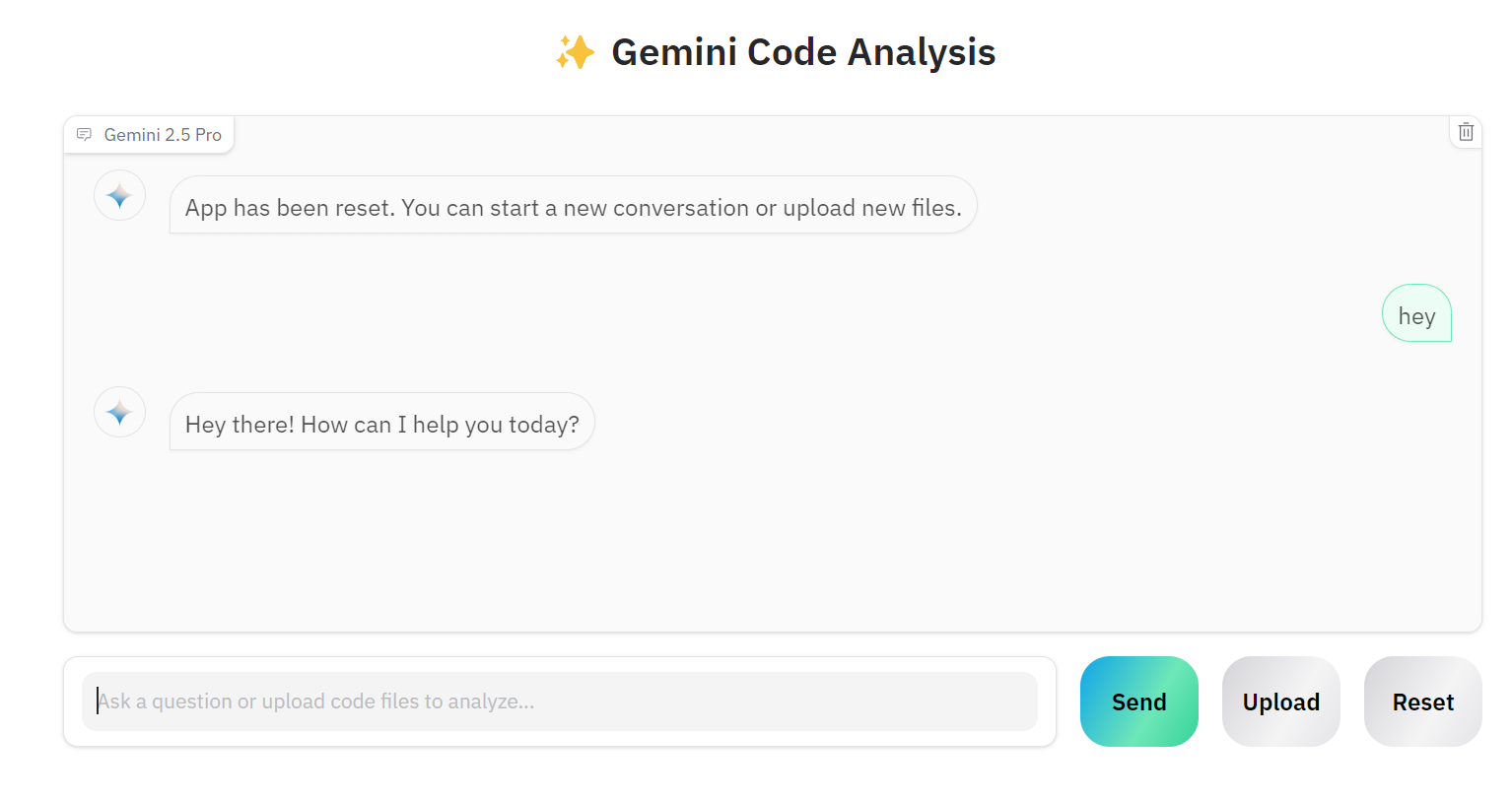
Wenn du an einem anderen Projekt arbeiten möchtest, kannst du auf die Schaltfläche "Zurücksetzen" klicken und mit dem Chatten über das neue Projekt beginnen.
Der Quellcode und die Konfigurationen sind im GitHub-Repository verfügbar: kingabzpro/Gemini-2.5-Pro-Coding-App.
Der Aufbau einer richtigen KI-Anwendung ist deutlich einfacher geworden. Anstatt komplexe Anwendungen mit Tools wie LangChain zu erstellen, Vektorspeicher zu integrieren, Prompts zu optimieren oder Gedankenketten hinzuzufügen, können wir den Gemini 2.5 Pro Client einfach über die Google API initialisieren. Die Gemini 2.5 Pro Chat-API kann verschiedene Dateitypen direkt verarbeiten, erlaubt Folgefragen und liefert äußerst präzise Antworten.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Lernpfad
Tutorial
Laiba Siddiqui
Tutorial
Moez Ali
Tutorial
Matt Crabtree
Tutorial
DataCamp Team
