
Kurs
Einführung in GitHub-Konzepte
2 Std.
43.3K
Git ist ein echt starkes verteiltes Versionskontrollsystem, das den Änderungsverlauf von Dateien aufzeichnet und so Entwicklern eine effiziente teamübergreifende Zusammenarbeit ermöglicht.
Als jemand, der mit Code und Skripten arbeitet, ist einer der ersten Befehle, auf die du in Git stößt, „ git clone “. Mit diesem Befehl kannst du eine lokale Kopie eines Repositorys erstellen, an dem deine Kollegen gearbeitet haben. Damit legst du den Grundstein für die Mitarbeit an gemeinsamen Projekten oder die Offline-Verwaltung deiner Codebasis.
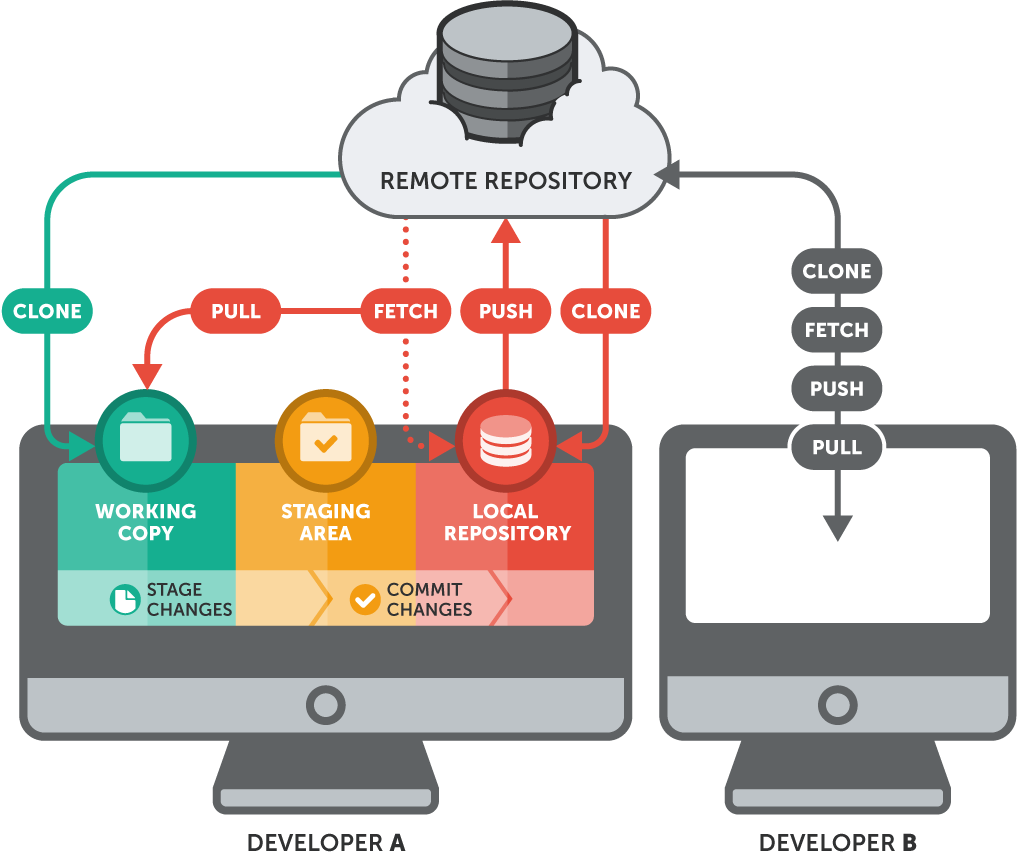 So funktioniert der Befehl „git clone“. Quelle: Git-Tower
So funktioniert der Befehl „git clone“. Quelle: Git-Tower
Wenn du mehr über Git erfahren möchtest, empfehle ich dir diesen Einführungskurs zu Git.
In der verteilten Architektur von Git hat jeder Entwickler eine komplette Kopie des Repositorys, einschließlich der Commit-Historie und der Branches. Das geht mit dem Befehl „ git clone “. So stellst du sicher, dass du nicht nur den aktuellen Stand eines Projekts herunterlädst, sondern auch die ganze Versionshistorie mitbekommst, was super wichtig sein kann, um zu verstehen, wie der Code so geworden ist, wie er jetzt ist.
In diesem Tutorial zeige ich dir, was „ git clone “ macht, wie du es in verschiedenen Situationen nutzen kannst und was hinter den Kulissen passiert, wenn du den Befehl ausführst. Egal, ob du gerade erst mit Git anfängst oder dein Wissen über Repository-Management vertiefen willst, dieser Leitfaden gibt dir praktische Tipps und das nötige Selbstvertrauen, um „ git clone “ effektiv zu nutzen.
Der Befehl „ git clone “ kopiert ein Repository in ein neues Verzeichnis auf deinem Rechner. Obwohl damit sowohl lokale als auch Remote-Repositorys geklont werden können, wird es am häufigsten zum Klonen eines Remote-Repositorys verwendet. Mit „ git clone “ werden alle Dateien, Branches, Commit-Verläufe und Konfigurationen aus einer Quelle (z. B. GitHub, GitLab oder Bitbucket) in ein neues Verzeichnis am Zielort kopiert, das sich auf Ihrem lokalen Rechner oder in einer CI/CD-Pipeline befinden kann.
Im Grunde ist „ git clone “ eine Abkürzung, die alles einrichtet, was du brauchst, um an einem bestehenden Projekt zu arbeiten. Wenn du zum Beispiel eine Kopie des Repositorys „aws-cli” von GitHub (einem Remote-Repository) auf deinen lokalen Rechner kopieren willst, kannst du den Befehl „ git clone ” ausführen, wie in der folgenden Abbildung gezeigt:
# Initializes a new Git repository in the “aws-cli” folder on your local
# The version of Git used throughout this tutorial is 2.39.5
git clone https://github.com/aws/aws-cli.git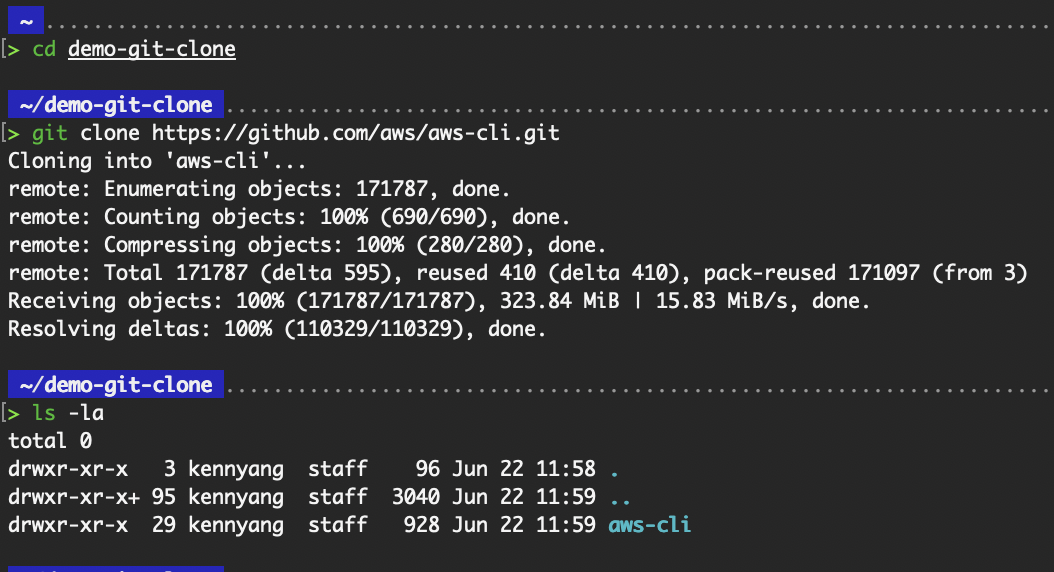
Ausgabe der grundlegenden Verwendung von git clone
Im Vergleich zu anderen Git-Befehlen ist „ git clone “ einzigartig, weil es normalerweise dein erster Kontakt mit einem Remote-Repository ist und in der Regel nur einmal ausgeführt wird. Zum Beispiel:
git init erstellt lokal ein brandneues Git-Repository von Grund auf, was auch nur einmal gemacht werden muss.git fetchgit pull und git push werden benutzt, nachdem ein Repository schon eingerichtet wurde.Im Gegensatz dazu richtet „ git clone “ deine ganze Git-Umgebung für ein bestehendes Projekt in einem einzigen Schritt ein – ganz ohne zusätzliche Konfiguration. Wenn du bei einem Projekt mitmachst oder zu einem Open-Source-Projekt beiträgst, ist git clone der richtige Startpunkt für dich.
Das Klonen eines Git-Repositorys ist viel mehr als nur das Herunterladen von Projektdateien. In diesem Abschnitt geht's darum, was beim Klonen passiert und wie das verteilte Modell von Git eine reibungslose Zusammenarbeit durch Peer-to-Peer-Interaktionen ermöglicht, anders als bei den üblichen zentralisierten Systemen.
Schauen wir mal, was im Hintergrund passiert, wenn der Befehl „ git clone “ ausgeführt wird.
.git “. In diesem Verzeichnis werden alle Metadaten, Konfigurationen und Versionshistorien gespeichert, die zum Verfolgen und Verwalten von Änderungen erforderlich sind.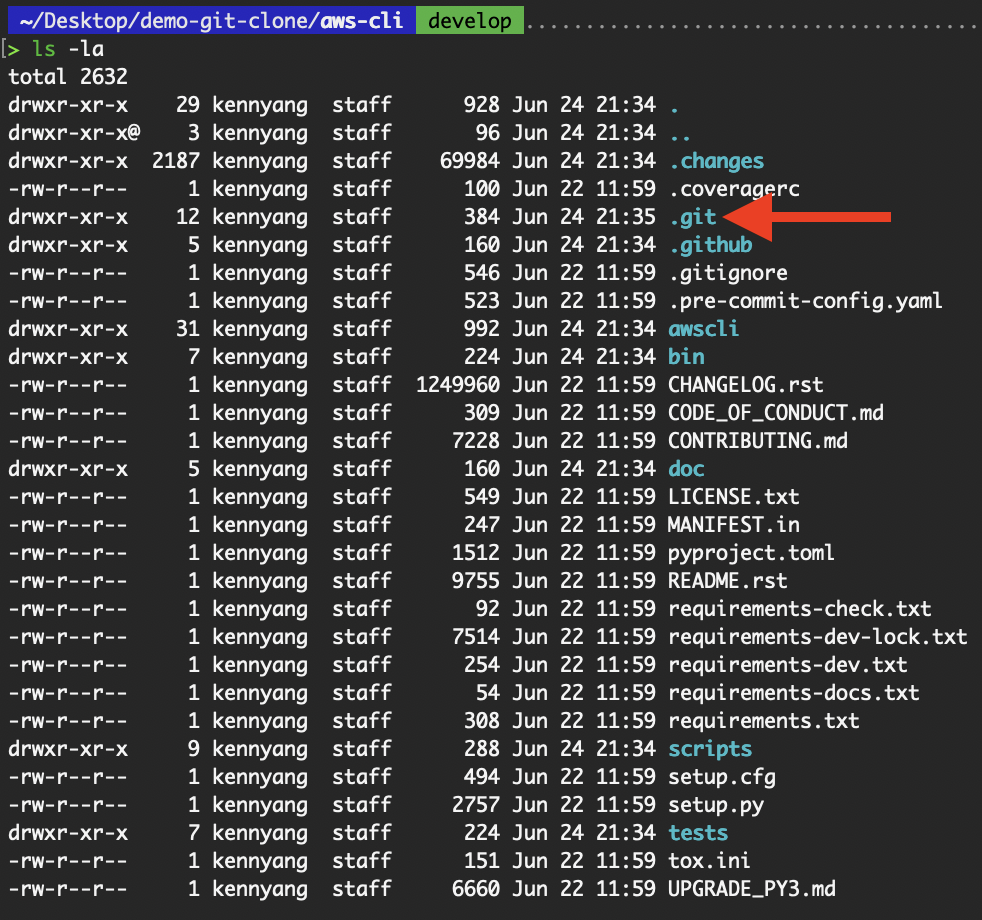 .git-Verzeichnis
.git-Verzeichnis
origin “, damit wir Änderungen einfach abrufen und übertragen können.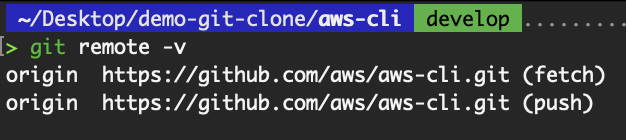 Remote-Repository anzeigen
Remote-Repository anzeigen
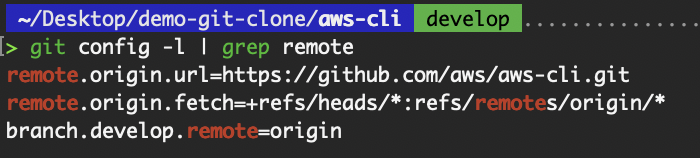
Konfigurationsvariablen anzeigen
main “ oder „ master “, und in diesem Branch fängst du nach dem Klonen mit der Arbeit an. Für das Repository „aws-cli“ ist der Standardzweig aber develop.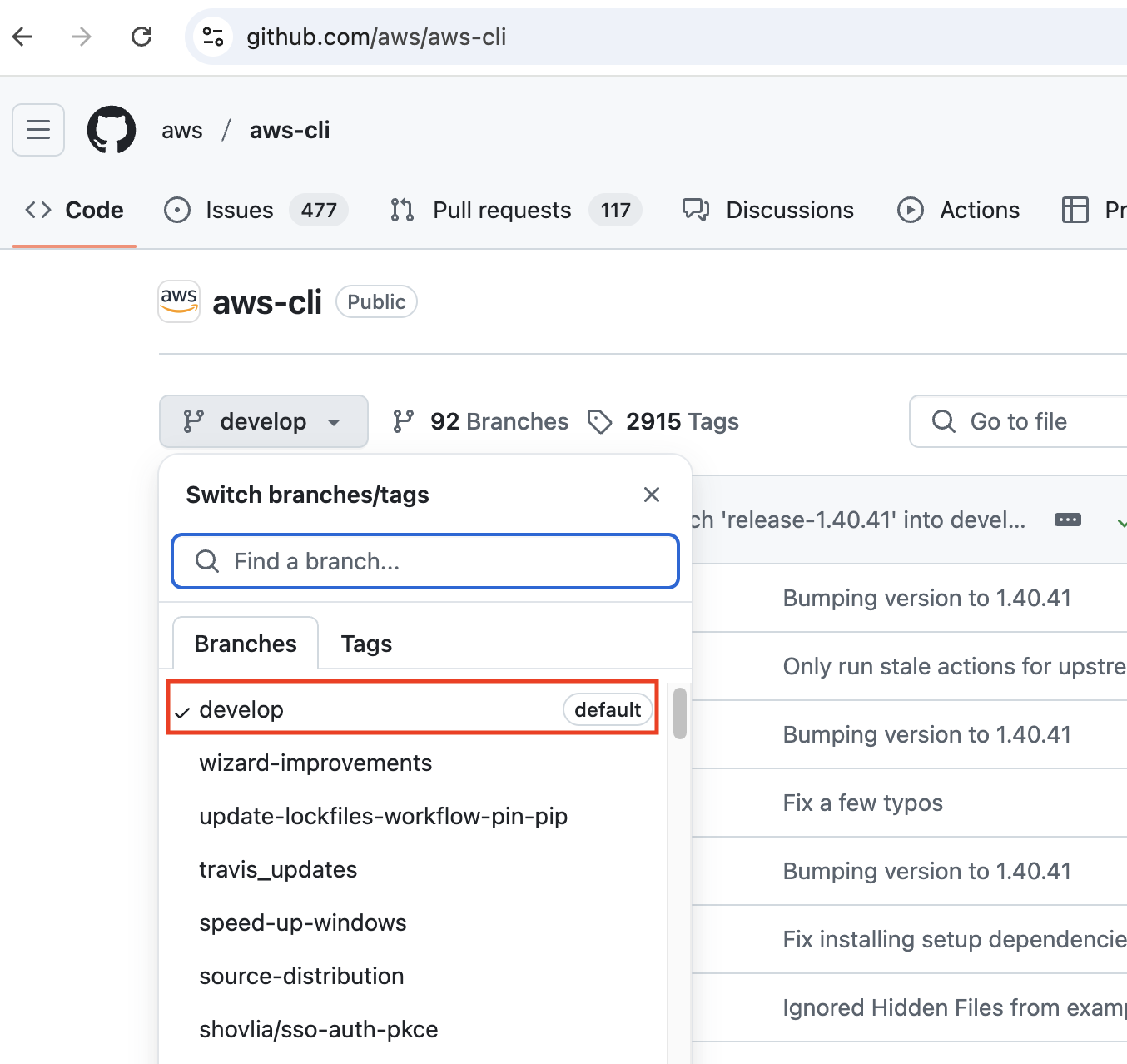 Der Standard-Zweig, wie er auf GitHub angezeigt wird
Der Standard-Zweig, wie er auf GitHub angezeigt wird
Dank dem Design und der Funktion von Git ist dein lokales Repository nach dem Klonen eine komplett unabhängige Kopie mit denselben Funktionen wie das Remote-Repository. Es kann Commits machen, Branches erstellen und sogar als Remote für andere dienen.
Dieses Modell unterscheidet sich deutlich von zentralisierten Versionskontrollsystemen (CVCS) wie Subversion (SVN), bei denen der Server als einzige Quelle für die Daten fungiert. In Git ist jeder Klon ein Peer, nicht nur ein Client. Alle Repositorys sind in Sachen Funktionalität gleich und Änderungen können in alle Richtungen geteilt werden.
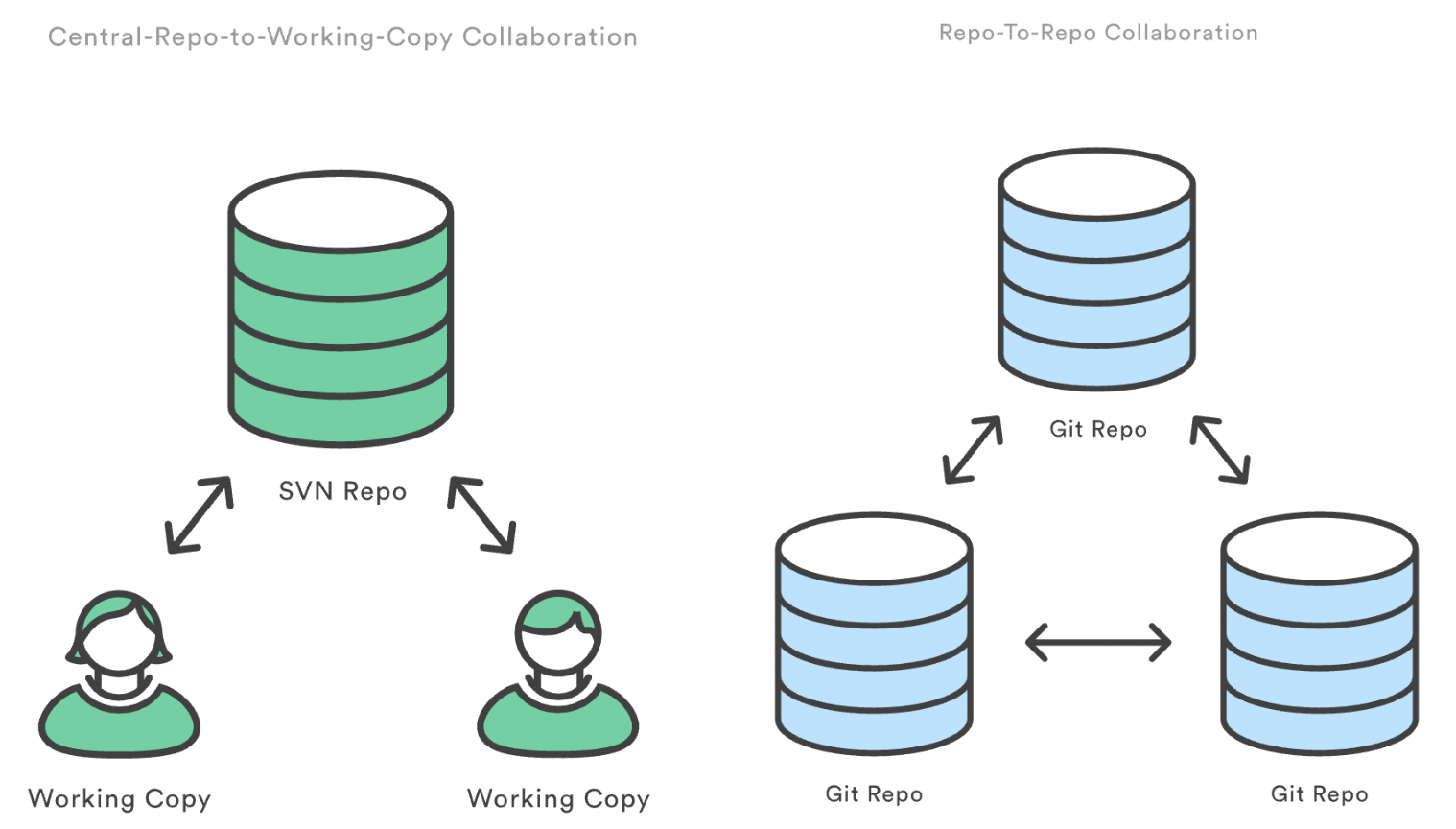
SVN-Repo vs. Git-Repo. Quelle: Atlassian
Jedes Mal, wenn wir ein Git-Repository klonen, erstellen wir nicht einfach eine Kopie, sondern ein neues, eigenständiges Git-Repository. Unser Klon hat die komplette Commit-Historie und Struktur des ursprünglichen Repositorys.
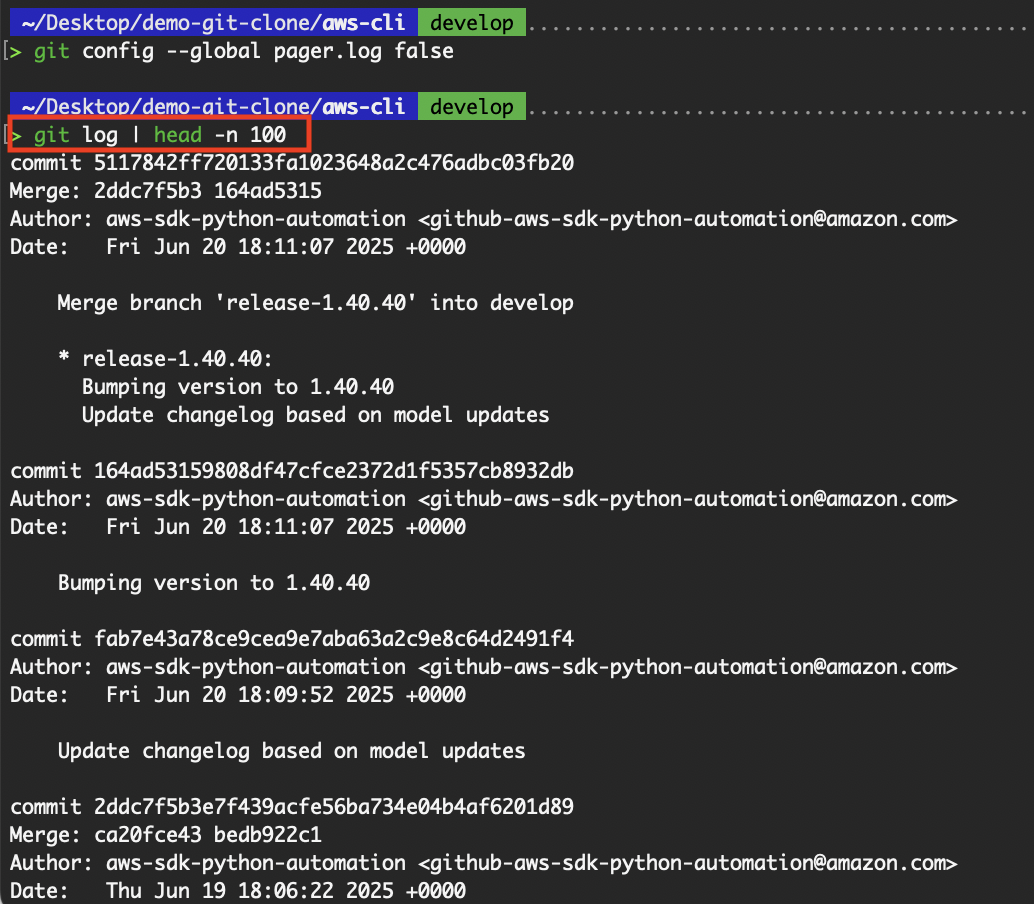
Zeig die ganze Commit-Historie aus dem geklonten Repo an.
Damit können wir offline arbeiten, Commits machen und eigenständig Branches erstellen. Unser lokales Repository kann auch als Basis für neue Features oder Experimente dienen.
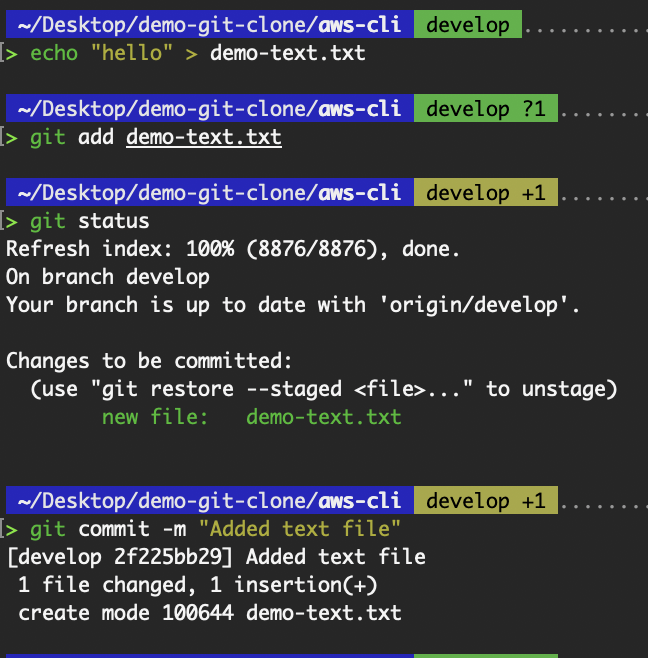
Füge einen Commit zum geklonten Repository hinzu
 Erstell einen lokalen Branch im geklonten Repository
Erstell einen lokalen Branch im geklonten Repository
Beim Klonen werden Lernpfade eingerichtet, vor allem mit dem Remote-Repository, das als „ origin “ bezeichnet wird. Diese Verbindung macht Folgendes möglich:
git fetch origingit pullgit push origin Auch wenn jeder seine eigene Repository-Kopie hat, sorgt Git für die Koordination durch gemeinsame Remotes und eine klare Verfolgung, welche Branches in den verschiedenen Repositories einander entsprechen. Deshalb wird Git in allen Unternehmen benutzt, um den Code zu verwalten.
Im Grunde ist das Klonen der Einstieg in das verteilte Modell der Zusammenarbeit bei Git, wo jeder, der was beiträgt, gleichberechtigt am Entwicklungszyklus teilnimmt.
Wie du am Beispiel vom Klonen des Repositorys „aws-cli“ sehen kannst, musst du beim Klonen eines Repositorys mit „ git clone “ den Speicherort des Remote-Repositorys angeben, und zwar über eine Git-URL.
Git kann mit verschiedenen Protokollen auf Remote-Repositorys zugreifen, die alle ihre eigene Struktur, ihr eigenes Sicherheitsmodell und ihre eigenen besten Anwendungsfälle haben. Wenn du die verschiedenen Arten von Git-URLs kennst und weißt, wann du sie verwenden musst, kannst du sicherer und effizienter arbeiten, vor allem bei der Zusammenarbeit mit anderen Teams oder beim Automatisieren von Bereitstellungen.
Beim Klonen eines Repositorys sagt die angegebene URL Git, wie es sich mit dem Remote-Server verbinden soll. Die gängigsten Git-URL-Typen sind:
Sicheres Hypertext-Übertragungsprotokoll (HTTPS). Meistens benutzt, um über einen Webbrowser auf Webseiten zuzugreifen. Dieser URL-Typ ist einfach zu verwenden und erfordert beim Klonen eines öffentlichen Repositorys keine Einrichtung. Hier sind ein paar Beispiele:
git clone https://github.com/<username>/<repo>.git
git clone https://github.com/aws/aws-cli.git
git clone https://gitlab.com/gitlab-org/gitlab.gitStrukturzerlegung:
https:// – Protokoll für die Kommunikation (sicher und Firewall-freundlich).github.com – Domain des Git-Hostingdienstes.username/repo.git – Pfad zum Repository:username ist der Besitzer (Benutzer oder Organisation)repo.git ist der Name des Git-RepositorysSecure Shell (SSH). Ein Netzwerkprotokoll, bei dem du dich beim Server anmelden musst, bevor du eine Verbindung aufbauen kannst. Dafür musst du ein SSH-Schlüsselpaar erstellen und den öffentlichen Schlüssel zu deinem Git-Anbieter (z. B. GitHub, GitLab) hinzufügen.
git clone git@github.com:<username>/<repo>.git
git clone git@github.com:aws/aws-cli.git
git clone git@gitlab.com:gitlab-org/gitlab.gitStrukturzerlegung:
git@ – Legt das SSH-Benutzerkonto fest (normalerweise einfach „git“).github.com: – Domain des Git-Servers, gefolgt von einem Doppelpunkt (:), nicht einem Schrägstrich (/).username/repo.git – Pfad zum Repository auf dem Server.Da ich in meinem GitHub-Konto keine SSH-Schlüssel eingerichtet habe, kommt die folgende Meldung, wenn ich versuche, die SSH-URL zu kopieren.
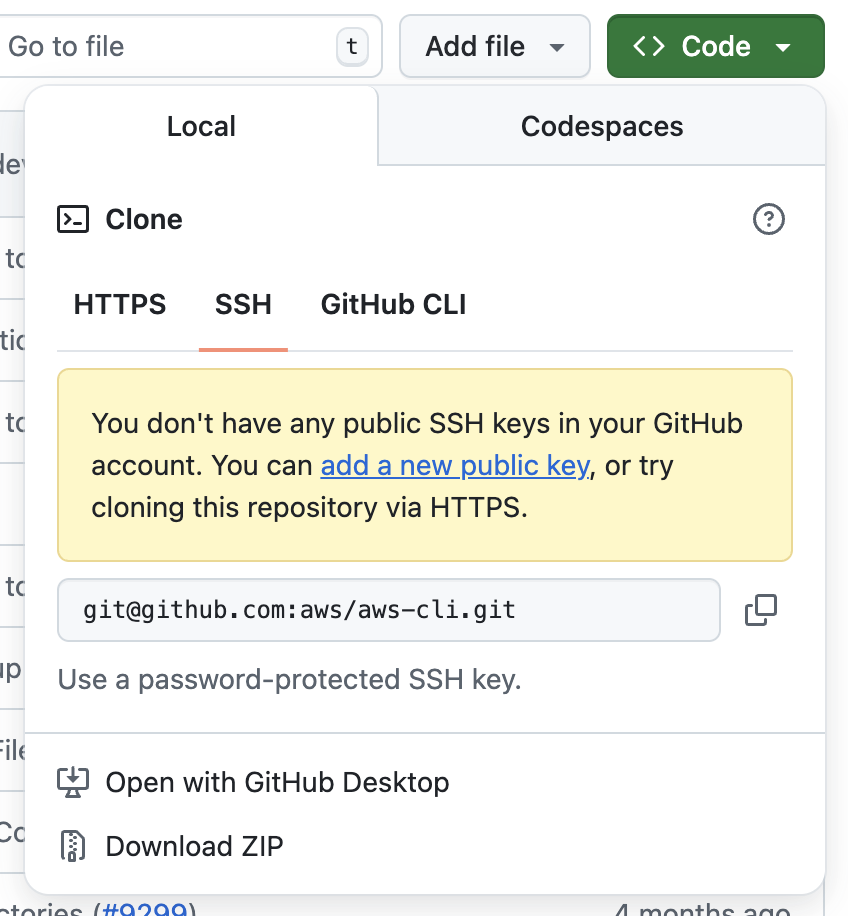
Kein SSH-Schlüssel eingerichtet
Im nächsten Abschnitt zeig ich dir, wie du SSH-Schlüssel einrichtest.
Ein leichtes, nicht authentifiziertes Protokoll für den Lesezugriff. Das ist ein Protokoll, das es nur bei Git gibt. Heutzutage wird es wegen Sicherheitsbedenken und der Ablehnung durch große Anbieter wie GitHub und GitLab kaum noch benutzt. Auf GitHub oder GitLab gibt's nicht mal die Option, mit dem Git-Protokoll zu klonen.
# Not recommended
git clone git://github.com/<username>/<repo>.gitStrukturzerlegung:
git// – Git-Protokoll (nur lesen, nicht authentifiziert).github.com: – Domain des Git-Servers.username/repo.git – Pfad zum Repository auf dem Server.Egal, welches Klonprotokoll du benutzt, kannst du die URL und das Protokoll mit den folgenden Befehlen checken:
git remote -v
git remote show originJedes Protokoll hat Vor- und Nachteile. In der folgenden Tabelle zeigen wir dir die Vor- und Nachteile der verschiedenen Protokolle für deinen Anwendungsfall.
|
Protokoll |
Anwendungsfall |
Pros |
Nachteile |
|
HTTPS |
Perfekt für Anfänger und CI-Tools |
Einfach zu bedienen, Firewall-freundlich |
Du musst deine Zugangsdaten eingeben oder einen persönlichen Zugriffstoken (PAT) einrichten. Das kann man mit Hilfe von Anmeldeinformationen umgehen. |
|
SSH |
Am besten für Leute, die oft was beitragen |
Sicher, keine wiederholten Anmeldungen |
Schlüssel einrichten und verwalten |
|
Git |
Archivierung oder öffentliches Klonen zum Lesen |
Schnell, leicht |
Unsicher, größtenteils veraltet |
Sobald du ein Git-URL-Protokoll ausgewählt hast, unterscheiden sich der eigentliche Klonvorgang und der Authentifizierungsablauf. Beide Methoden erreichen zwar letztendlich dasselbe Ziel (das Klonen eines Remote-Repositorys auf deinen lokalen Rechner), sind aber für unterschiedliche Sicherheitsanforderungen, Benutzerbedürfnisse und Komplexität der Einrichtung gedacht.
In diesem Abschnitt zeige ich dir, wie du ein Repository mit HTTPS und SSH klonen kannst, und gebe dir Tipps, wie du das am besten machst, was du einrichten musst und was du bei Problemen tun kannst, damit alles glatt läuft.
Das Klonen eines Git-Repositorys über HTTPS ist die einfachste Methode und damit super für Anfänger und eingeschränkte Umgebungen (wie Firmen-Firewalls oder eingeschränkte Netzwerke).
Um ein Repository zu klonen, geh einfach dorthin und kopier die HTTPS-URL. Das folgende Bild ist von GitHub. Das wird ähnlich wie bei deinem Git-Anbieter sein.
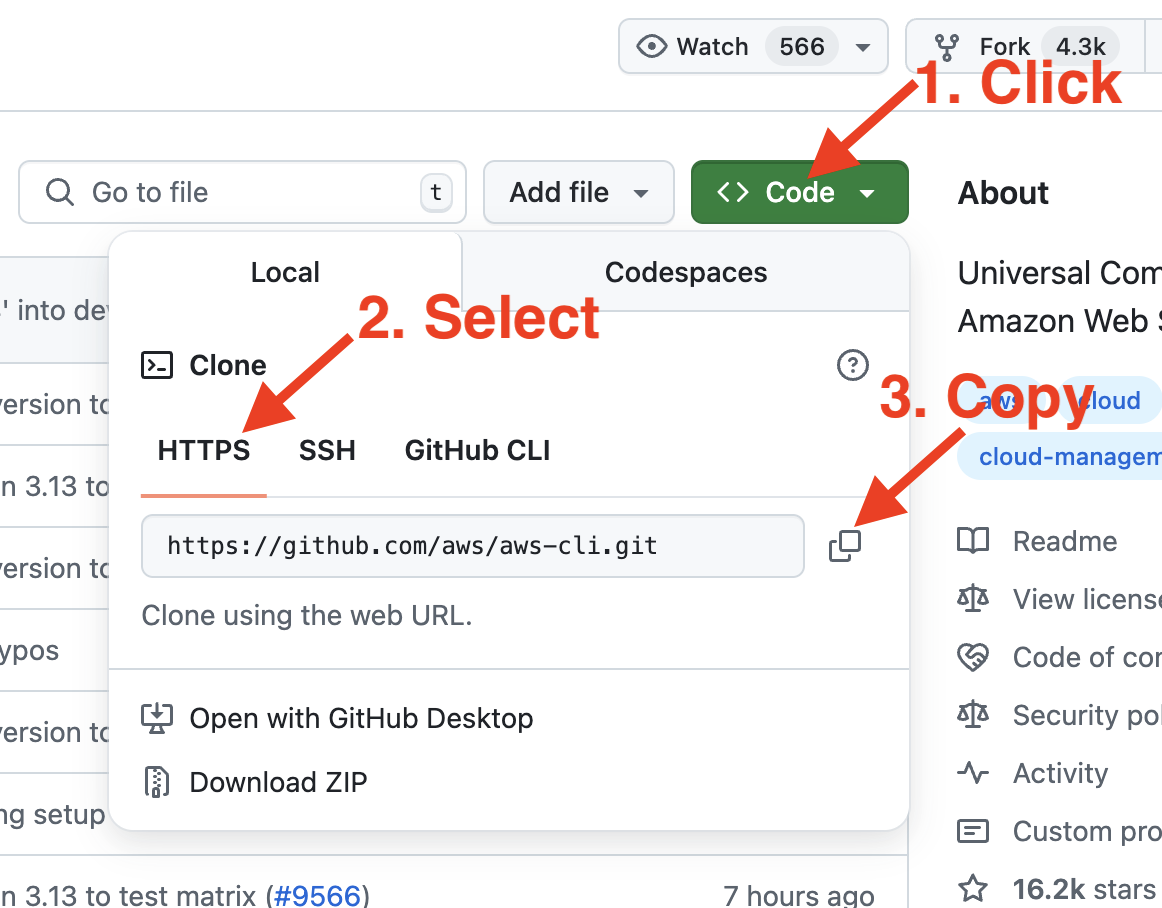
Hol dir die HTTPS-URL eines Repositorys auf GitHub
Führ dann den Befehl „ git clone “ auf dem Ziel (z. B. deinem Laptop oder einer CI/CD-Pipeline) aus, wo du das Repository klonen willst.
git clone https://github.com/aws/aws-cli.git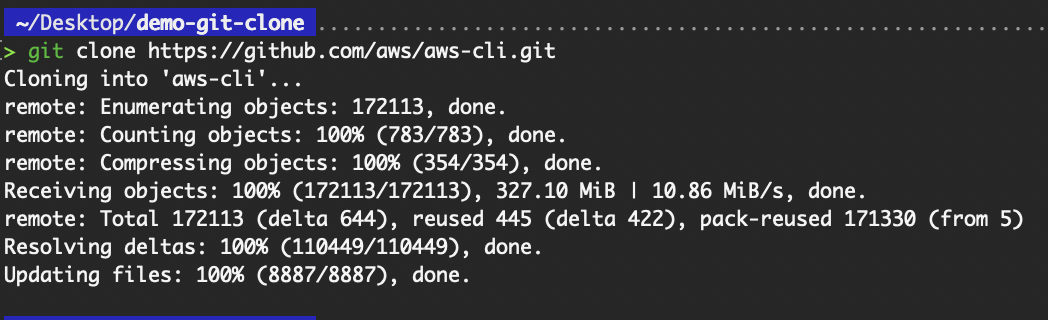
Grundlegender Befehl „git clone“
Zum Klonen eines öffentlichen Repositorys, wie wir es für das Repository „aws-cli“ gemacht haben, brauchst du keine Authentifizierung, da das Repository öffentlich ist. Solange du „ git “ auf deinem System installiert hast, kannst du das öffentliche Repo sofort und ohne weitere Konfiguration klonen.
Wenn du aber ein privates Repository klonst, musst du dich erst mal anmelden. Du kannst dich über folgende Wege anmelden:
Um die Authentifizierung über ein persönliches Zugriffstoken zu zeigen, hab ich einen Server in AWS EC2 hochgefahren und Git installiert. Wenn du den Befehl „ git clone “ in einem privaten Repository ausführst, musst du einen Benutzernamen und ein Passwort eingeben. Gib deinen GitHub-Benutzernamen als Benutzernamen und deinen persönlichen Zugriffstoken als Passwort ein.
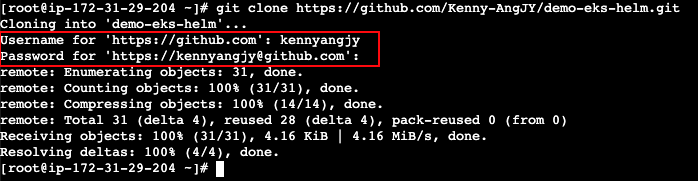
HTTPS-Authentifizierung mit Benutzername/Passwort
Wegen strengerer Sicherheitsregeln brauchen GitHub und andere Anbieter jetzt einen persönlichen Zugangstoken statt eines Passworts.
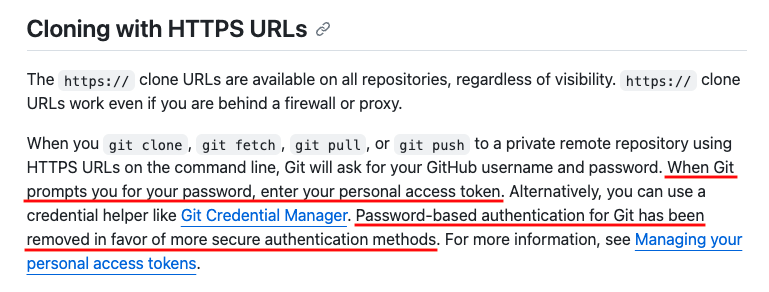
Klonen mit Anweisungen zum HTTPS-URL-Zugriffstoken. Quelle: GitHub
Wenn du deinen persönlichen Zugriffstoken nicht eingibst, bekommst du die folgende Fehlermeldung:
![]()
Die Unterstützung für die Passwortauthentifizierung wurde entfernt.
Um einen persönlichenZugriffstoken zu erstellen, geh auf „GitHub-Token erstellen“ und mach einfach die Anweisungen:
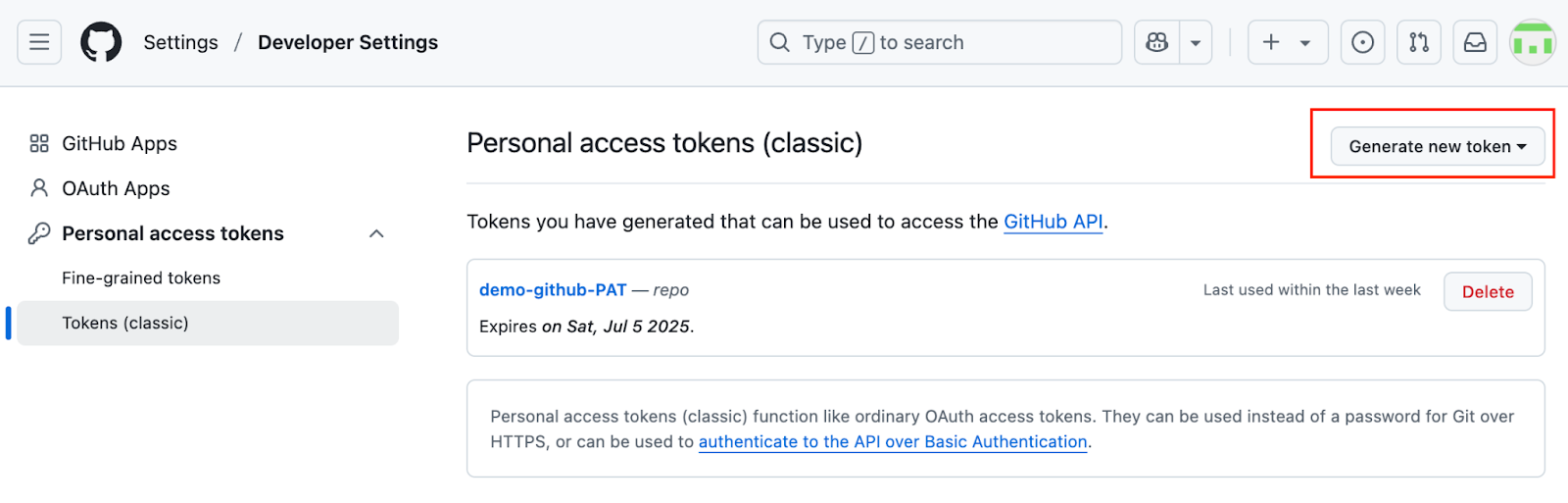
Erstell einen persönlichen Zugriffstoken auf GitHub
Damit du nicht jedes Mal deinen persönlichen Zugriffstoken eingeben musst, wenn Git eine Authentifizierung über HTTPS verlangt, kannst du einen Credential Helper verwenden, um deine Anmeldedaten sicher zwischenzuspeichern. Eine beliebte Option ist der Git Credential Manager.
Unter macOS ist Git nahtlos in den macOS-Schlüsselbund integriert, den ich persönlich zum Speichern meiner Anmeldedaten verwende. Ich benutze Passkeys aus dem Schlüsselbund, um mich anzumelden. Das ist sicher und funktioniert super.
Anmeldeinformationen anzeigen
Passkeys auf MacOS
Um einen Passkey einzurichten, geh zu den Passwort- und Authentifizierungseinstellungen von GitHubundmach einfach die Anweisungen.
Erstell einen Passkey auf GitHub
Mit GitHub kannst du zwar einen persönlichen Zugriffstoken ohne Ablaufdatum erstellen, aber die meisten Unternehmen haben Sicherheitsregeln, die ein Ablaufdatum für Tokens verlangen. Das heißt, wenn ein Token in automatisierten Umgebungen wie CI/CD-Pipelines verwendet wird und abläuft, schlägt die Pipeline wegen Authentifizierungsfehlern fehl. Es ist wichtig, das Token vor dem Ablauf proaktiv zu erneuern und seine Verwendung entsprechend anzupassen.
Ohne ordentliche Kontrollen können Entwickler versehentlich mehrere persönliche Zugriffstoken erstellen und verwenden, ohne dass dies klar dokumentiert oder über einen Lernpfad nachverfolgt wird. Das kann schnell zu Verwirrung darüber führen, welches Token wo verwendet wird, was die Wartung und Überprüfung erschwert. Für bessere Hygiene solltest du die Verwendung von Tokens auf ein Minimum beschränken, dokumentieren und an bestimmte Anwendungsfälle binden.
SSH bietet eine sichere und dauerhafte Authentifizierungsmethode, die besonders für regelmäßige Mitwirkende und fortgeschrittene Benutzer geeignet ist. Einmal eingerichtet, kannst du ganz einfach mit Repositorys arbeiten, ohne immer wieder deine Zugangsdaten eingeben zu müssen.
Um die SSH-Authentifizierung einzurichten, musst du erst mal ein SSH-Schlüsselpaar erstellen, das aus einem öffentlichen und einem privaten Schlüssel besteht.
# ed25519 specifies the key type
ssh-keygen -t ed25519 -C "your_email@google.com"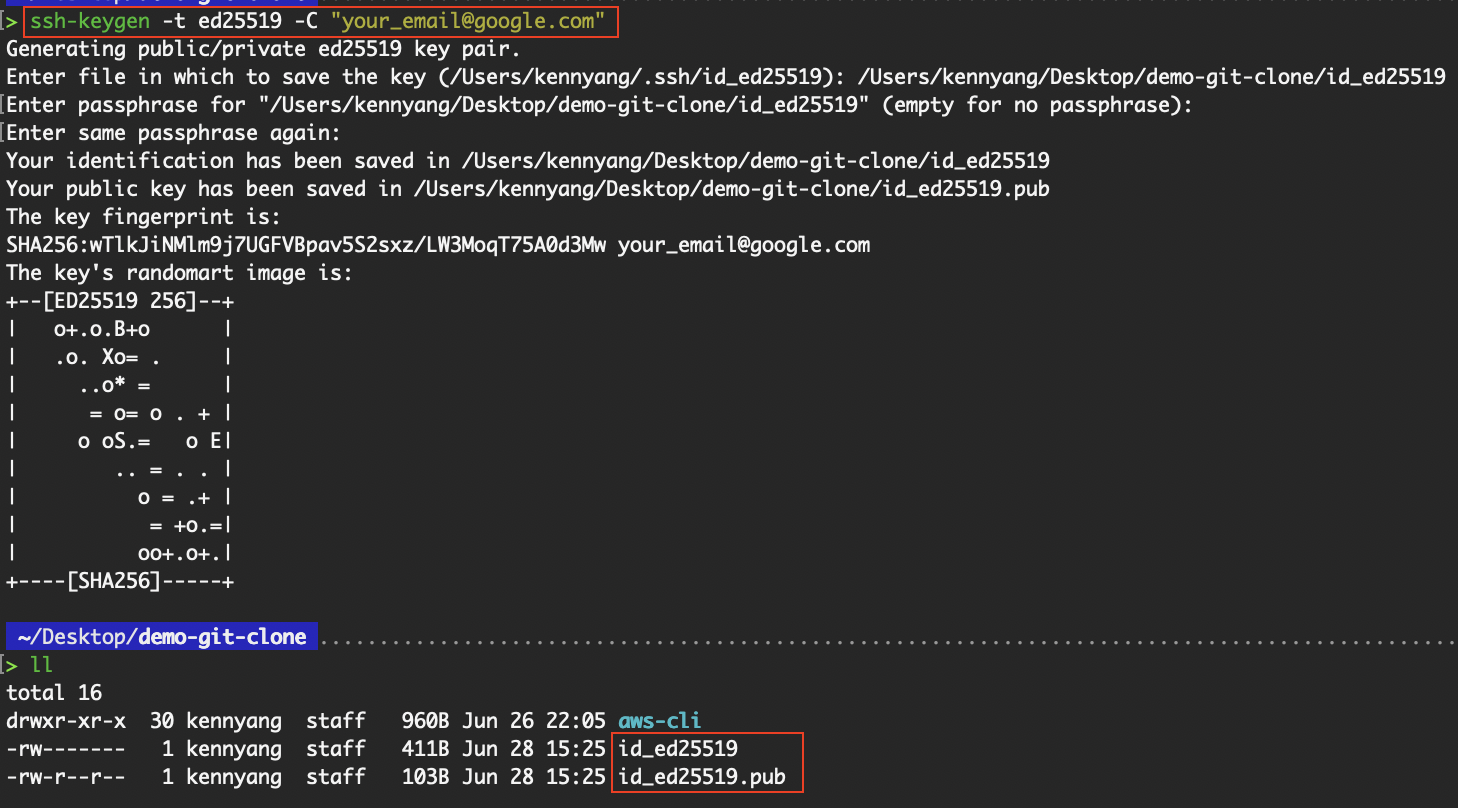
Erstell ein SSH-Schlüsselpaar
Da ich schon einen SSH-Schlüssel in „ ~/.ssh/id_ed25519 “ habe, habe ich das Standardverzeichnis überschrieben, in dem die Schlüssel gespeichert werden. Wenn du den SSH-Schlüssel zum ersten Mal auf deinem Gerät erstellst, nimm einfach das Standardverzeichnis.
Geh zu SSH und GPC-Schlüsseln in GitHub, um deinen SSH-Schlüssel einzurichten.
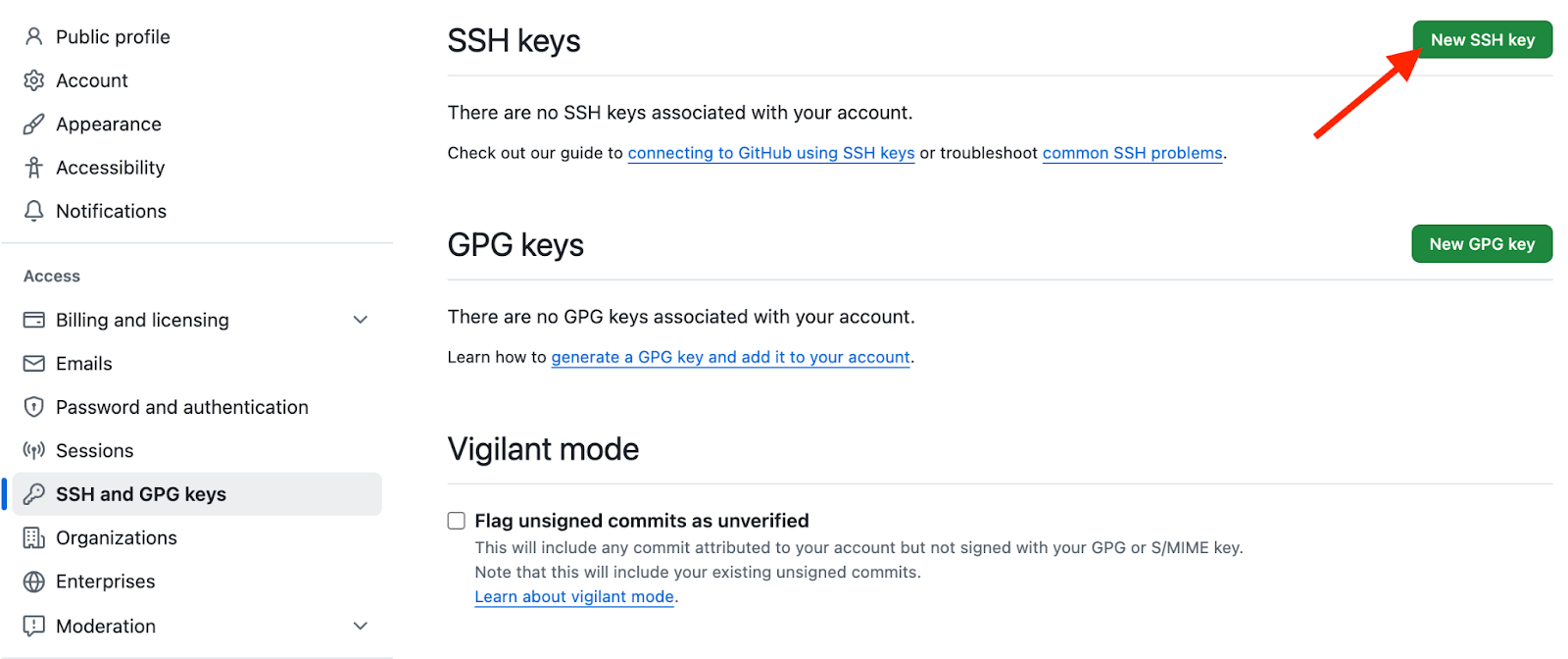
SSH-Schlüssel auf GitHub einrichten
Kopiere den Inhalt des öffentlichen Schlüssels im Abschnitt „Schlüssel“. Bei mir ist es der Inhalt von „ id_ed25519.pub “.
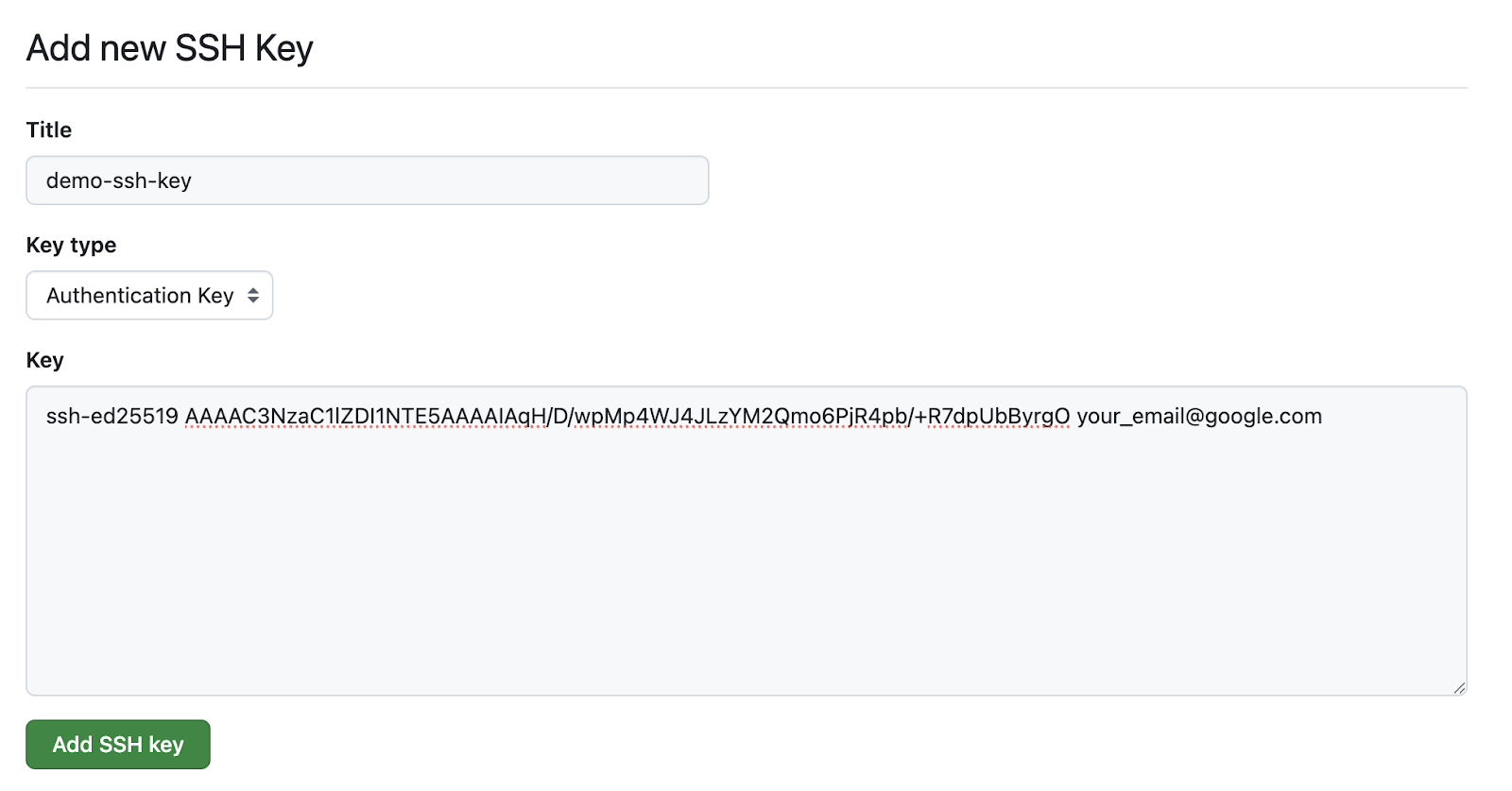
Kopiere den Inhalt von id_ed25519.pub und füge ihn hier ein.
SSH nutzt eine Verschlüsselung mit öffentlichen und privaten Schlüsseln. Bewahr deinen privaten Schlüssel sicher auf deinem Computer auf. Jetzt kannst du ein Repository, egal ob öffentlich oder privat, über SSH klonen.
Nachdem du SSH erfolgreich eingerichtet hast, wird beim Auswählen der SSH-URL die Warnmeldung nicht mehr angezeigt, wie oben im Abschnitt „Arten von Git-URLs“ gezeigt.
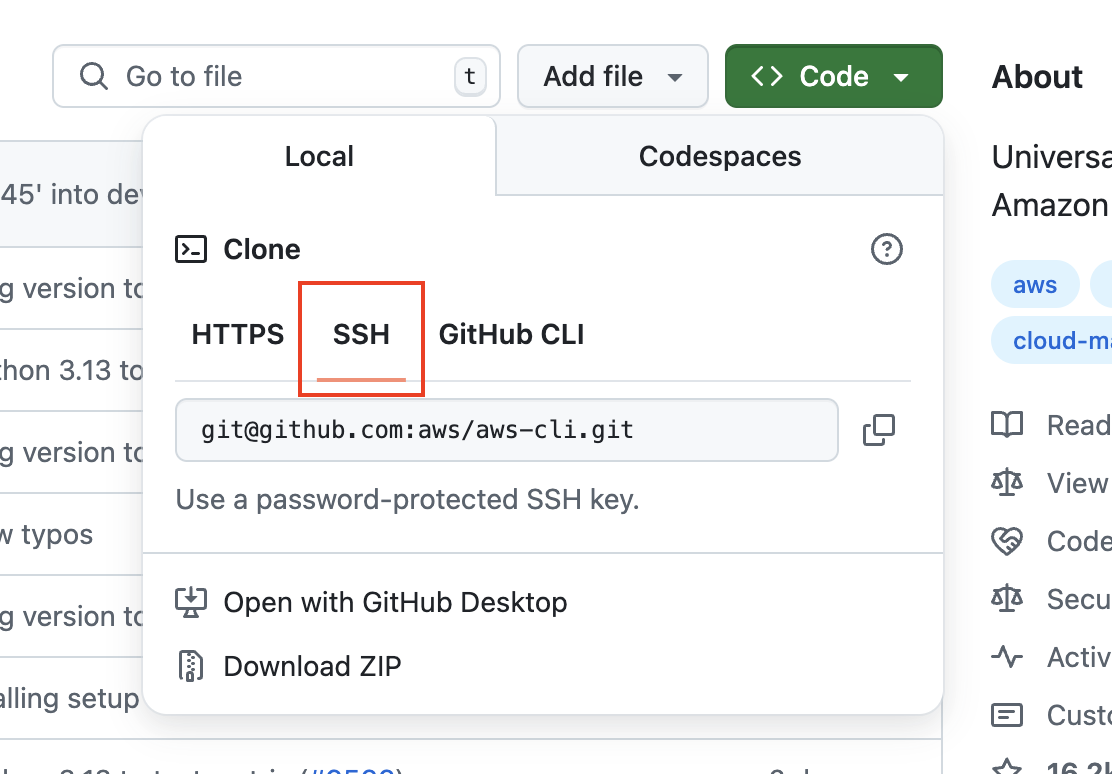
Hol dir die SSH-URL eines Repositorys auf GitHub
Da sich der private SSH-Schlüssel auf meinem lokalen Gerät befindet, zeige ich dir „ git clone “ mit SSH auf meinem lokalen Rechner statt auf dem EC2-Server.
git clone git@github.com:aws/aws-cli.git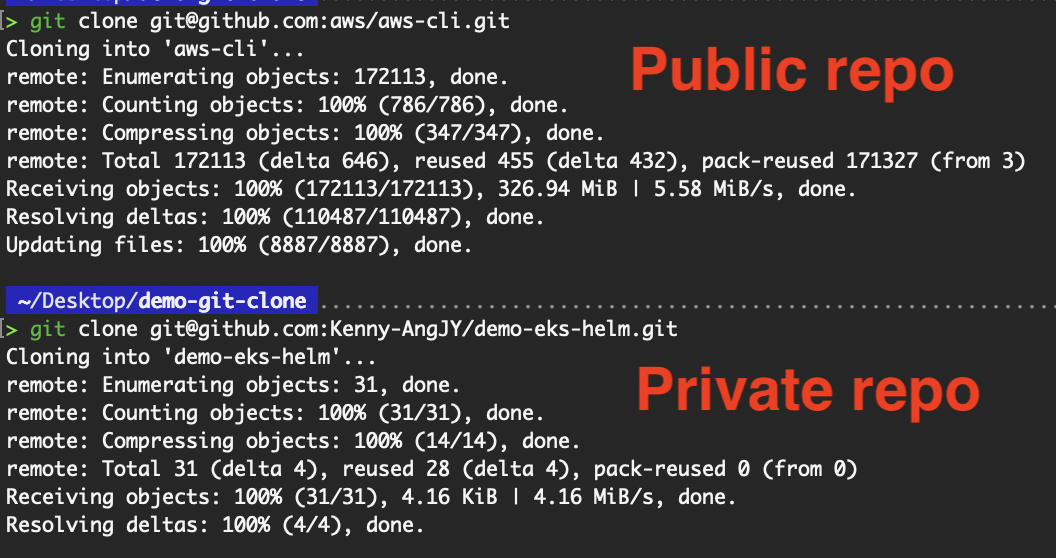
Klonieren von öffentlichen und privaten Repositorys mit SSH
Wir haben den Git-Klonvorgang mit SSH erfolgreich durchgeführt!
Zu den Vorteilen von SSH gehören die Sicherheit und die weite Verbreitung in Unternehmen, da es eine passwortlose Authentifizierung ermöglicht, was ideal für häufige Interaktionen ist. SSH-Verbindungen sind auch robust gegen Netzwerkunterbrechungen und oft schneller als HTTPS über große Entfernungen.
Allerdings haben Entwickler oft Probleme beim Einrichten des SSH-Schlüssels, weil sie den falschen öffentlichen Schlüssel zum Git-Anbieter kopieren. Wenn du mehrere private Schlüssel für verschiedene Zwecke hast, musst du in der Datei „ ~/.ssh/config “ festlegen, welcher Schlüssel pro Host verwendet werden soll. Sonst könnte bei der Anmeldung bei GitHub der private Schlüssel für Bitbucket verwendet werden, was zu einer fehlerhaften Anmeldung führt.
Host github.com
HostName github.com
User git
IdentityFile ~/.ssh/id_ed25519So checkst du die Verbindung und verifizierst den verwendeten Schlüssel:
![]()
SSH-Verbindung checken
Die bisherigen Beispiele für „ git clone “ zeigen die grundlegenden Funktionen des Befehls.
In diesem Abschnitt zeige ich dir die verschiedenen Optionen des Befehls, mit denen du den Klonvorgang eines Repositorys an deinen Rechner anpassen kannst. Egal, ob du mit bestimmten Zweigen arbeitest oder die Geschwindigkeit optimierst, wenn du diese Unterschiede verstehst, kannst du „ git clone “ besser nutzen.
Wie wir gesehen haben, ist die einfachste Verwendung von „ git clone “ das Klonen eines Remote-Repositorys auf deinen lokalen Rechner.
# HTTPS protocol
git clone https://github.com/aws/aws-cli.git
# SSH protocol
git clone git@github.com:aws/aws-cli.gitDiese Befehle erstellen einen Ordner namens „aws-cli“ und richten darin eine lokale Kopie des Repositorys ein, komplett mit Versionshistorie und Remote-Tracking-Einrichtung.
Standardmäßig erstellt „ git clone “ ein Verzeichnis, das nach dem Repo benannt ist. Um ein anderes Zielverzeichnis anzugeben, gib einfach den Namen als zweites Argument mit.
Damit wird der Inhalt von „ aws-cli.git “ in den lokalen Ordner „ my-project-folder “ kopiert:
git clone https://github.com/aws/aws-cli.git my-project-folder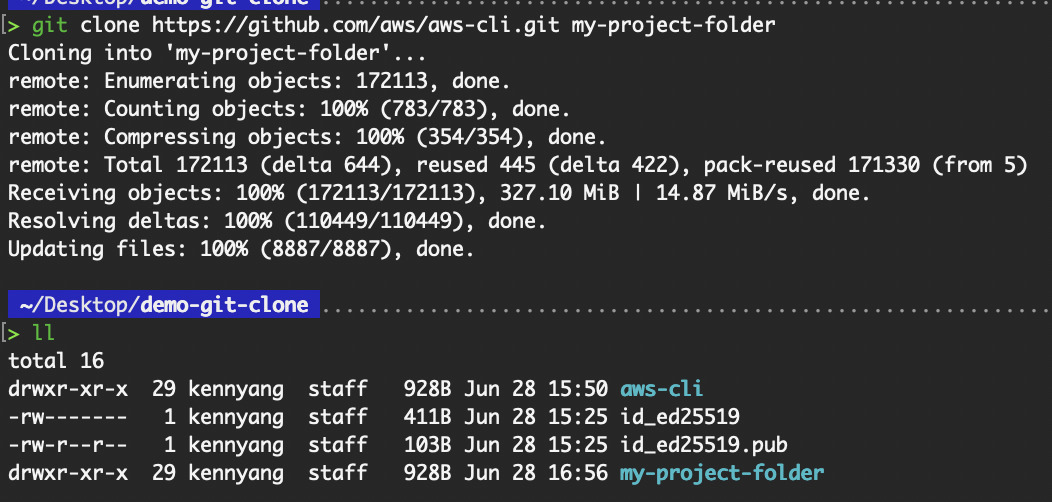
In einen bestimmten Ordner klonen
Verwende das Flag „ --branch “ (oder „ -b “), um nach dem Klonen aller Remote-Branches zum angegebenen Branch zu wechseln. Der angegebene Zweig wird zum ausgecheckten „HEAD“, während die anderen Zweige lokal zum Auschecken verfügbar bleiben.
In unserem Beispiel mit dem Repository „aws-cli“ ist der Standardzweig „ develop. “. Klonst du das Repository und wechselst zum Zweig „ master “.
# Clone a branch
git clone --branch master https://github.com/aws/aws-cli.git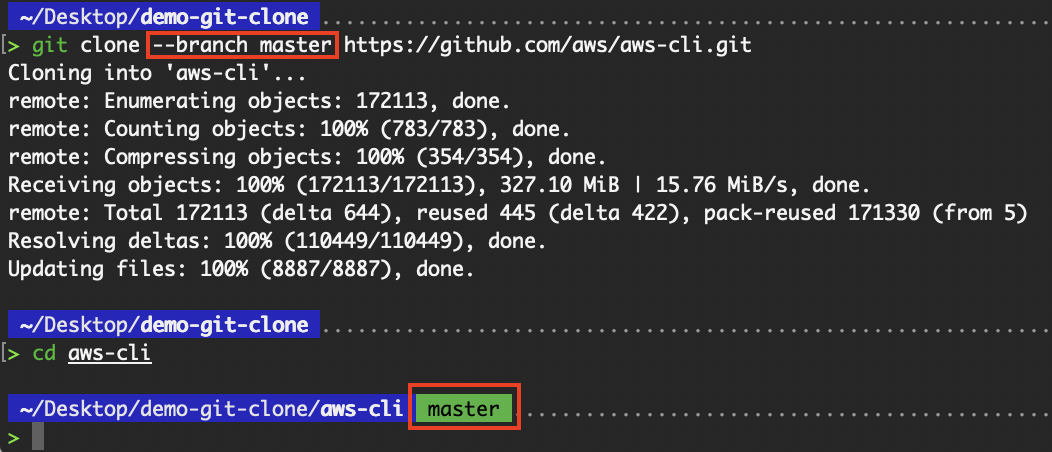
Einen bestimmten Zweig klonen
Wir können auch ein bestimmtes Tag klonen:
# Clone a tag (read-only snapshot)
git clone --branch 2.27.43 https://github.com/aws/aws-cli.git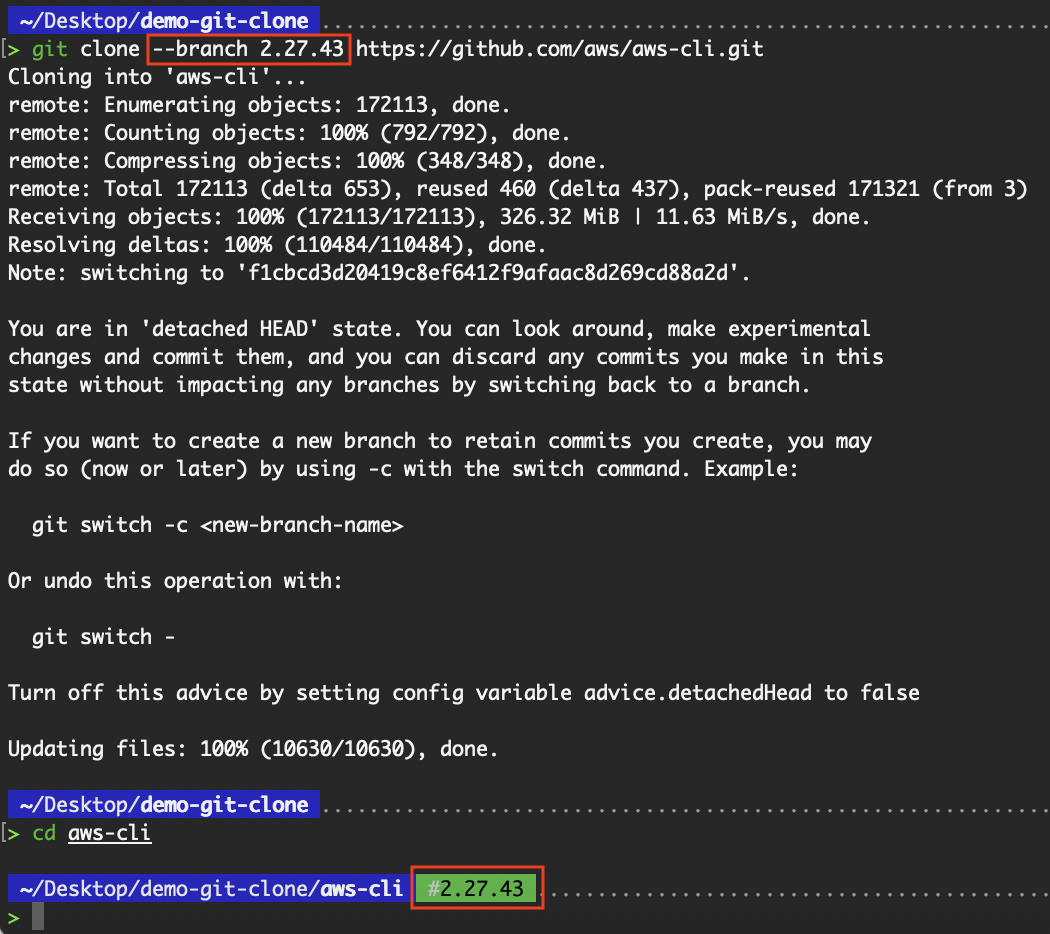
Kloning eines bestimmten Tags
Dieses Flag ist nützlich, wenn du an einer bestimmten Version oder einem bestimmten verzweigten Zweig arbeitest (z. B. staging, hotfix oder release).
Wenn du nur die neueste Version des Projekts ohne den kompletten Commit-Verlauf brauchst, benutze das Flag „ --depth “, um einen flachen Klon durchzuführen. Der Flag „ --depth “ sagt dir, wie viele Commits du klonen willst.
# Download only the latest commit history
git clone --depth 1 https://github.com/aws/aws-cli.git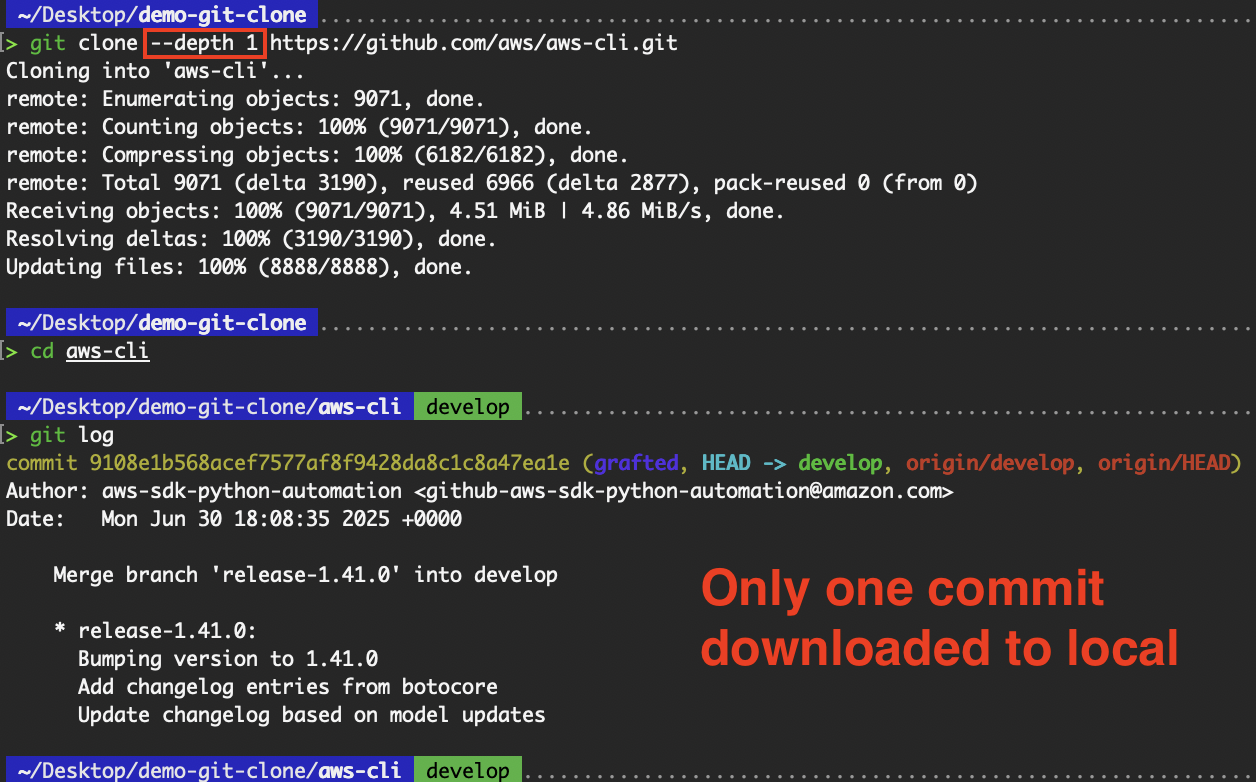 Flacher Klon
Flacher Klon
Das macht das Klonen schneller und spart Speicherplatz, was super für CI/CD-Pipelines ist oder wenn du dich nicht für den Commit-Verlauf interessierst. Das ist besonders praktisch für das Repository „aws-cli“, das wir gerade geklont haben. Da das Repository „aws-cli“ schon lange Commits hat, ist der Zeitunterschied beim Hinzufügen des Flags „ --depth “ ziemlich groß.
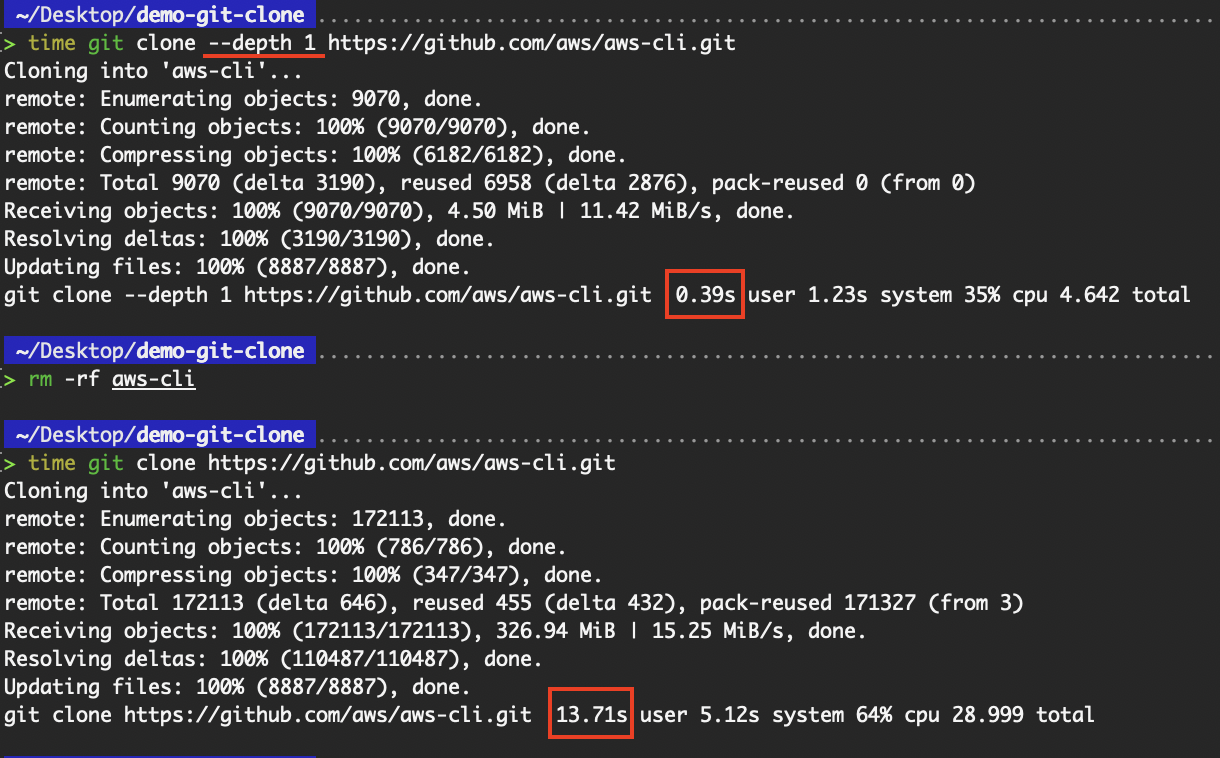 Zeitunterschied mit und ohne flachen Klon
Zeitunterschied mit und ohne flachen Klon
Durch das Weglassen der Commit-Historie bis auf den letzten Eintrag konnte die Menge der herunterzuladenden Daten reduziert und somit auch die benötigte Zeit verkürzt werden.
Der Befehl „ git clone “ wird meistens in seiner Grundform benutzt, aber Git hat noch ein paar coole Optionen, die dir mehr Kontrolle, Effizienz und Anpassungsmöglichkeiten beim Klonen geben.
Diese Funktionen sind besonders praktisch, wenn du mit großen Repositorys arbeitest, Repositorys auf Infrastrukturebene verwaltest oder bestimmte Entwicklungsabläufe optimieren willst.
In diesem Abschnitt schauen wir uns verzweigungsspezifische Vorgänge, flache und partielle Klone, Repository-Spezialisierungen und detaillierte Klonkonfigurationen an, die sowohl Entwicklern als auch DevOps-Ingenieuren das Leben erleichtern.
Standardmäßig holt „ git clone “ alle Branches und checkt den Standard-Branch aus. Wenn du aber mit großen Repositorys arbeitest oder an einer bestimmten Funktion mitmachst, ist es oft besser, nur einen Branch zu klonen. Das geht mit dem Flag „ --single-branch “.
git clone --branch <branch-name> --single-branch <repo-url>
git clone --branch feature/cliq --single-branch https://github.com/aws/aws-cli.git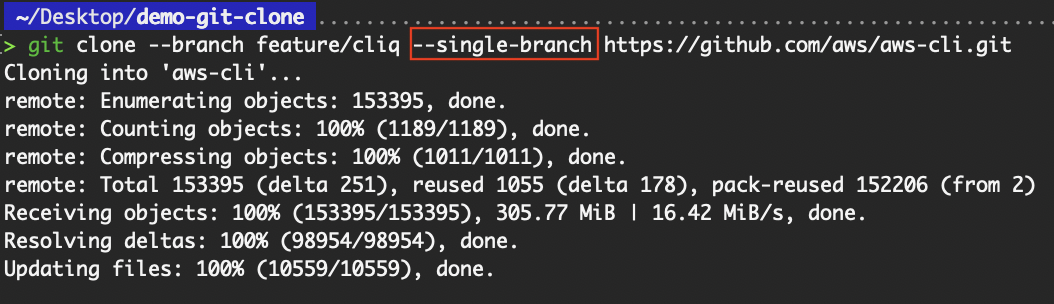 Einen bestimmten Zweig klonen
Einen bestimmten Zweig klonen
Die Vorteile sind unter anderem kleinere Downloads, weniger Zeit beim Herunterladen, schnelleres Einrichten für die Entwicklung bestimmter Funktionen und keine unnötigen Verzweigungen in der Versionshistorie.
Dieser Ansatz ist super, wenn du an einem Release-Zweig arbeiten oder nicht alle Zweige in aktiven CI/CD-Repositorys runterladen willst. Wenn der Name des Branches im Befehl nicht angegeben ist, klont Git nur den Standard-Branch.
Wenn du mehr über das Klonen eines bestimmten Branches erfahren möchtest, schau dir das Tutorial Git-Branch klonen an.
Wenn wir ein Repository klonen, werden zwei Teile kopiert: das Repository (Ordner „.git ”) und das Arbeitsverzeichnis. Das Arbeitsverzeichnis wird auch oft als Arbeitskopie, Arbeitsverzeichnis oder Arbeitsbereich bezeichnet.
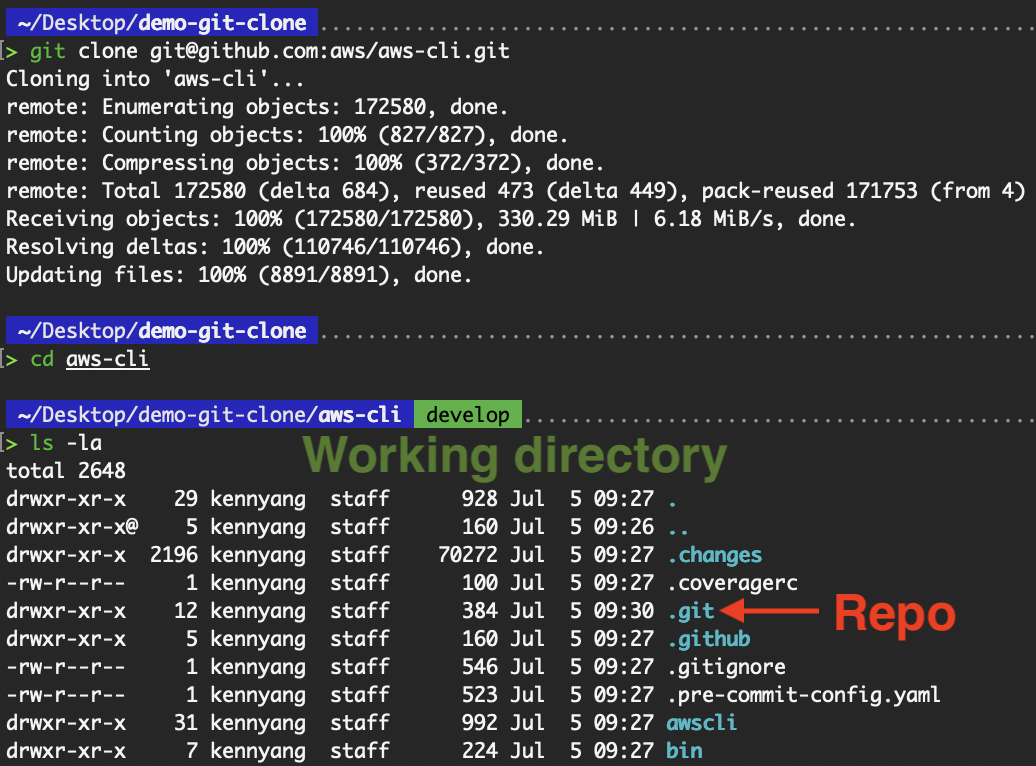
Unterschied zwischen Arbeitsverzeichnis und Repository
Der Ordner „ .git “ enthält folgende Dateien:
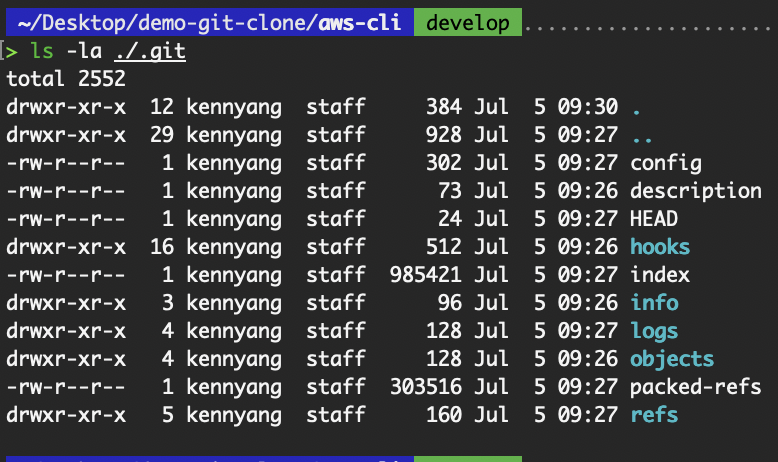
Inhalt des Ordners .git
Das bringt uns zum Thema „Bare Repository“.
Ein leeres Repository hat nur den Ordner „ .git “ und kein Arbeitsverzeichnis.
git clone --bare <repo-url>
git clone --bare https://github.com/aws/aws-cli.git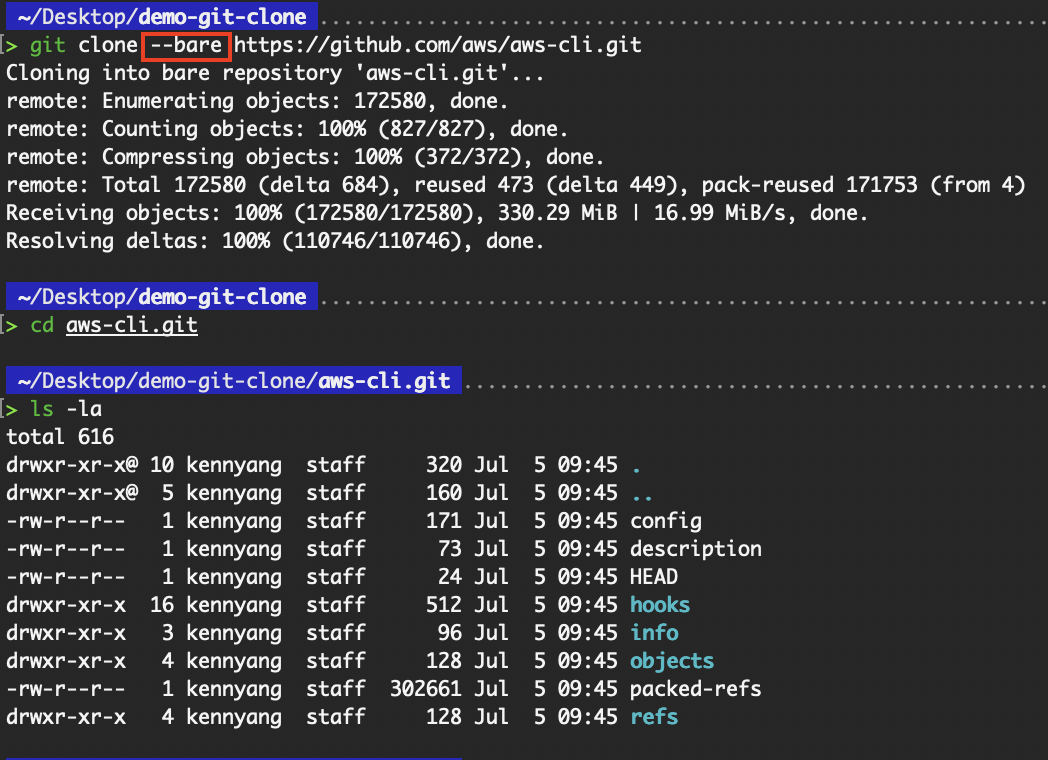
Ein leeres Repository klonen
Aus dem Vorherigen geht hervor, dass der Inhalt, der mit dem Flag „ --bare “ geklont wurde, einfach der Inhalt des Ordners „ .git “ des Nicht-Bare-Repositorys ist. Da es sich um ein leeres Repository handelt, gibt's kein Arbeitsverzeichnis, was bedeutet, dass wir die Git-Befehle nicht ausführen können, wie in der folgenden Abbildung gezeigt:
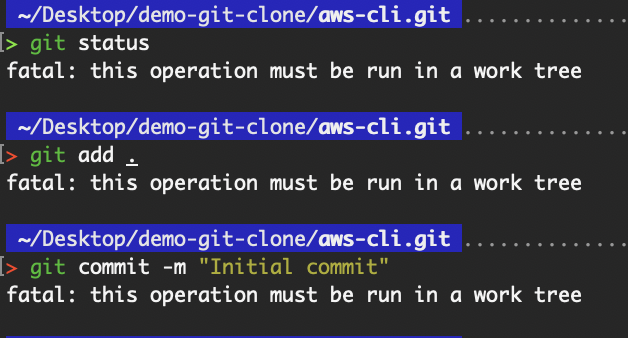 Der Vorgang muss in einem Arbeitsverzeichnis ausgeführt werden
Der Vorgang muss in einem Arbeitsverzeichnis ausgeführt werden
Bare Repositorys werden normalerweise als zentraler Speicher in einer gemeinsamen Umgebung für die Zusammenarbeit oder Spiegelung verwendet und nicht für die aktive Entwicklung. Um das Klonen aus dem Bare-Repository zu zeigen, nehme ich das Bare-Repository „aws-cli“, das ich auf meinem Rechner habe.

Aus meinem lokalen Bare-Repository klonen
Wir sehen, dass dieses Repository „aws-cli-non-bare” das Arbeitsverzeichnis enthält. Mach mal „ git remote -v “, um zu sehen, ob es auf das Bare-Repo verweist.
Der Befehl „ git clone --mirror “ richtet einen Spiegel des Quell-Repositorys ein. Das Flag „ --mirror “ bedeutet, dass „ --bare “ gesetzt ist, also dass das Spiegel-Repository kein Arbeitsverzeichnis enthält.
git clone --mirror <repo-url>
git clone --mirror https://github.com/aws/aws-cli.git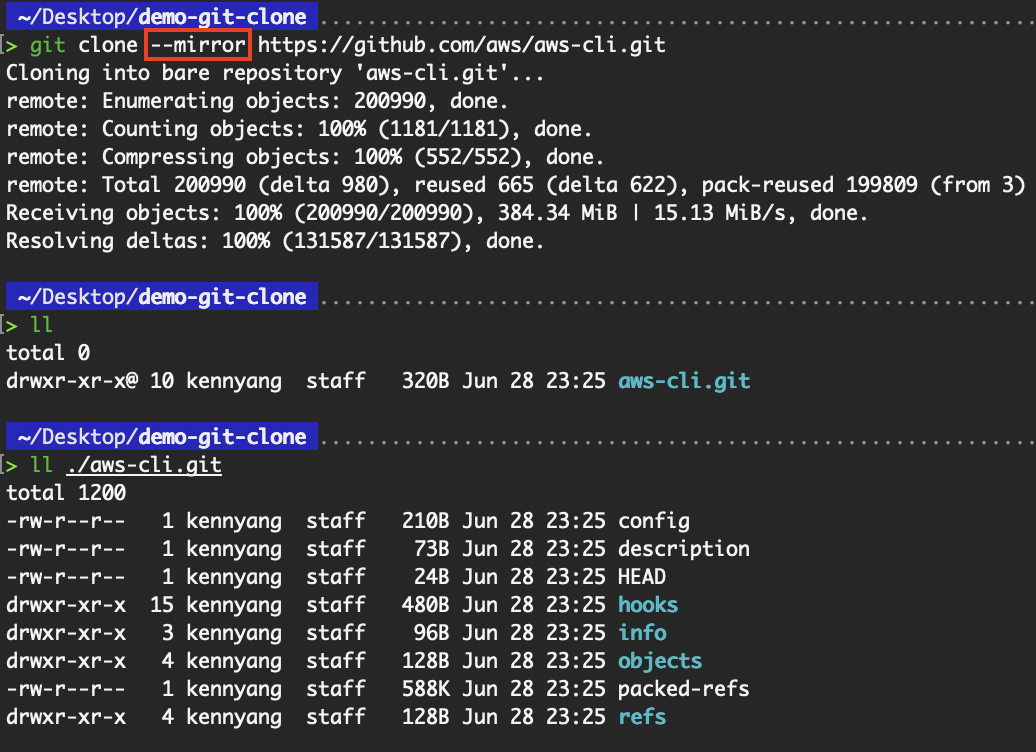
Klon ein (zentrales) Repository, um ein Spiegel-Repository zu erstellen.
Im Vergleich zu „ --bare “ ordnet „ --mirror “ aber nicht nur lokale Branches der Quelle lokalen Branches des Ziels zu, sondern ordnet auch alle Referenzen (einschließlich Remote-Tracking-Branches, Notizen usw.) zu und richtet eine Refspec-Konfiguration so ein, dass ein „ git remote update “ im Ziel-Repository alle diese Referenzen überschreibt. Dadurch erhalten wir eine umfassendere Kopie, die alle Referenzen (Verzweigungen, Tags usw.) enthält.
Die kompletten Schritte zum Spiegeln eines Repositorys findest du in der GitHub-Dokumentation.
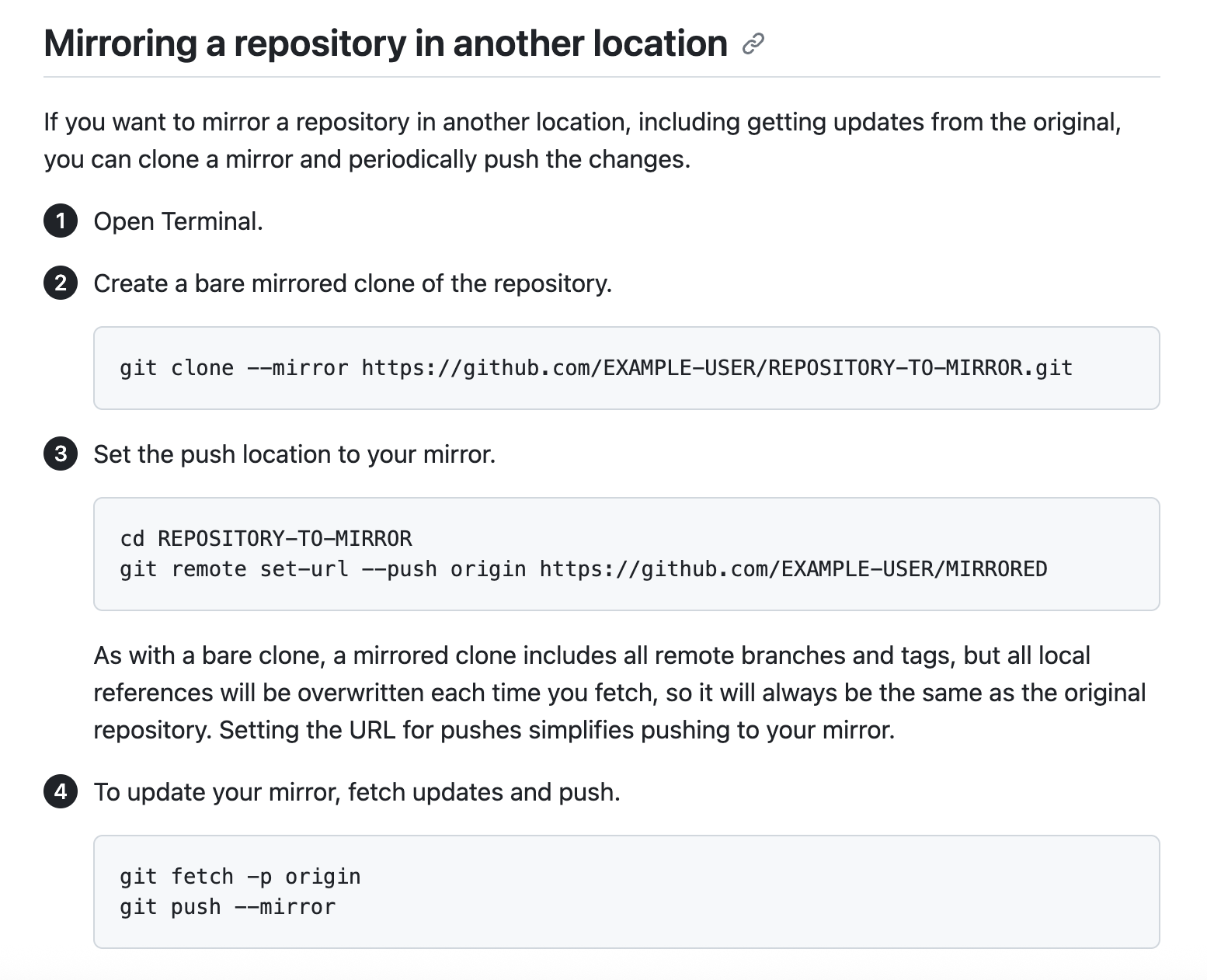
Ein Repository an einem anderen Ort spiegeln. Quelle: GitHub
Mit Teilklonen kannst du nur einen Teil der Repository-Objekte mit dem Flag „ --filter “ abrufen. Das ist super für Entwickler, die nur einen Teil einer Codebasis brauchen, vor allem in Umgebungen mit wenig Bandbreite oder Speicherplatz. Ein paar typische Beispiele für das Flag „ --filter “ sind:
--filter=blob:none: Dateiinhalt überspringen (Blobs)--filter=blob:limit=: Dateien ab einer bestimmten Größe ausschließen--filter=tree:: Lässt alle Blobs und Bäume weg, deren Tiefe vom Stammbaum aus größer oder gleich der festgelegten Tiefe ist.Das Flag „ --filter=blob:none “ wird verwendet, um Klonvorgänge zu optimieren, indem das sofortige Herunterladen von Dateiinhalten (Blobs) vermieden wird.
# Binary Large Objects (BLOB)
git clone --filter=blob:none <repo-url>
git clone --filter=blob:none https://github.com/aws/aws-cli.git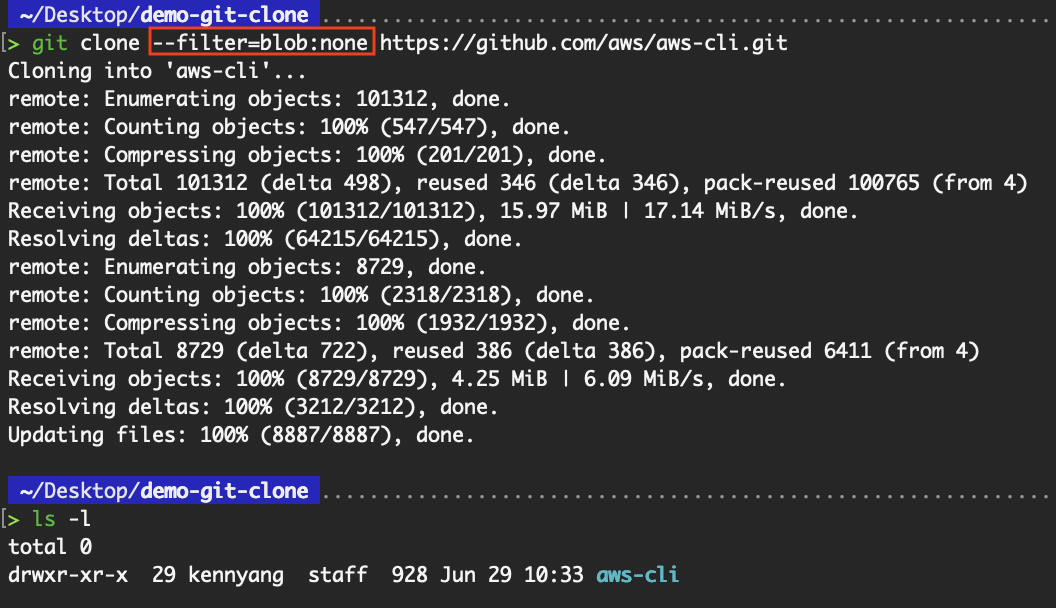
Klon mit Filter=blob:none
Das ist besonders praktisch bei großen Repositorys oder wenn nur ein Teil des Projekts gebraucht wird. In Monorepos brauchen zum Beispiel nicht alle Teams oder Entwickler den ganzen Code.
Ein Frontend-Entwickler, der nur mit „ frontend/ ” arbeitet, braucht keine Backend-Dienste oder gemeinsam genutzte Bibliotheken. Mit dem Flag „ --filter “ wird das Klonen schneller und der Speicherplatzbedarf reduziert, weil das Herunterladen von Blobs erst dann passiert, wenn sie gebraucht werden (z. B. wenn die Datei geöffnet wird). Das folgende Bild zeigt, was Git im Hintergrund macht, wenn ich eine Datei öffne, nämlich den Datei-Blob nach Bedarf runterzuladen.

Git lädt den Datei-Blob bei Bedarf runter.
Ein weiteres Beispiel wären CI/CD-Pipelines. Pipelines brauchen oft nicht den ganzen Repo-Verlauf oder jede Datei. Zusammen mit „sparse-checkout“ kann „ --filter=blob:none “ nur die Verzeichnisse klonen, die wirklich gebraucht werden (z. B. Bereitstellungsskripte).
Das Flag „ --filter=blob:limit= “ ist praktisch für Entwickler, die beim Klonen keine großen Dateien (Blobs) runterladen wollen, aber trotzdem kleinere Dateien sofort abrufen können. Das ist Teil der Teilklon-Funktion von Git und ist besonders praktisch, wenn du mit Repositorys arbeitest, die Inhalte unterschiedlicher Größe haben.
In manchen Projekten, vor allem bei Git LFS oder wenn Medien-Assets (z. B. Videos, große Datensätze, Spiel-Assets) verwendet werden, möchten Entwickler vielleicht große Dateien beim Klonen überspringen, um den ersten Klonvorgang zu beschleunigen und das Herunterladen großer Dateien aufzuschieben, bis sie wirklich gebraucht werden.
# Binary Large Objects (BLOB)
git clone --filter=blob:limit=<size> <repo-url>
# The suffixes k, m, and g can be used to name units in KiB, MiB, or GiB
git clone --filter=blob:limit=<n>[kmg] <repo-url>
git clone --filter=blob:limit=1m https://github.com/aws/aws-cli.git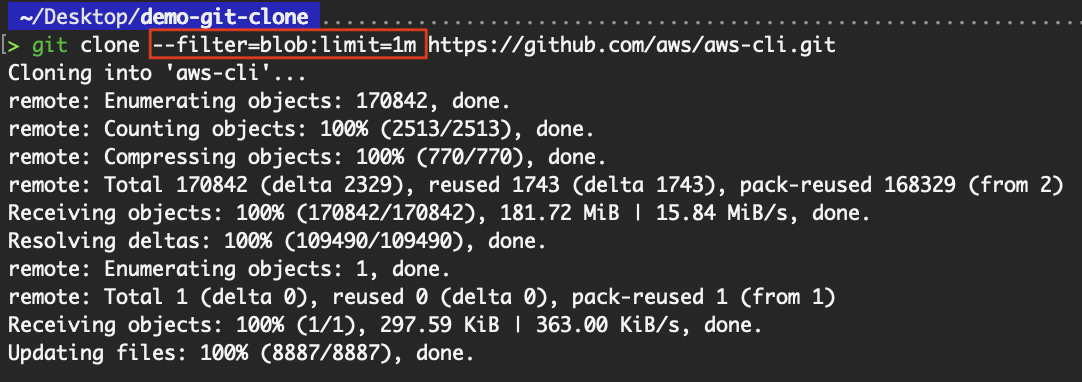
Klonen mit Filter=blob:limit
Das Flag „ --filter=tree: “ wird verwendet, um zu begrenzen, wie tief Git bei einem Klonen in die Verzeichnisstruktur vordringt, um die Datenübertragungsgröße zu reduzieren. Das ist besonders nützlich bei tief verschachtelten Projekten wie Monorepos. Wenn du zum Beispiel schnell eine große Monorepo-Struktur checken willst, zum Beispiel für Audits, Onboarding oder Reviews, ist das Herunterladen tiefer Verzeichnisse ziemlich nervig.
git clone --filter=tree:<depth> <repo-url>
git clone --filter=tree:0 https://github.com/aws/aws-cli.git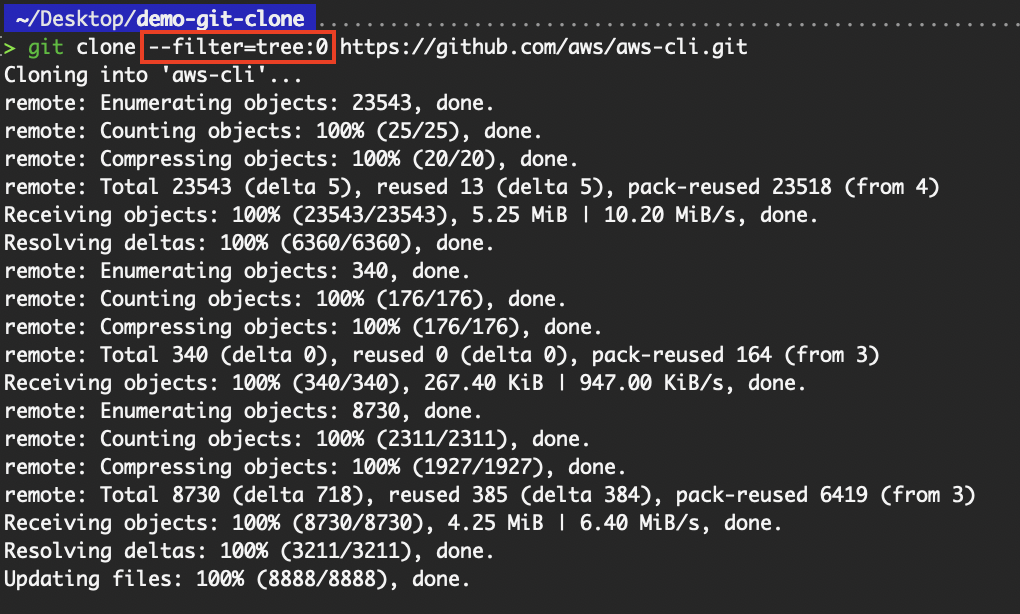
Klonen mit Filter=Baum
Beachte, dass der Git-Server, von dem du klonst (in diesem Fall GitHub), möglicherweise nur bestimmte Werte für die Baumfiltertiefe unterstützt.

Der Baumfilter erlaubt eine maximale Tiefe von 0.
Git hat ein paar Optionen, um das Verhalten beim Klonen anzupassen:
--origin : Legt einen eigenen Remote-Namen anstelle von „origin“ fest.--template .git “.--single-branch: verhindert das Abrufen anderer Zweige--recurse-submodules: initialisiert und klont Submodule automatischDiese Optionen sind praktisch, wenn du standardisierte Umgebungen einrichtest, mit modularen Repositorys arbeitest oder Tools für die Bereitstellung integrierst.
Mit dem Flag „ --origin “ können Entwickler den Namen des Remote-Speichers anpassen, von dem das Repository geklont wird. Standardmäßig nennt Git den Remote- origin, aber mit diesem Flag kannst du den Namen während des Klonvorgangs ändern.
git clone --origin <remote name> <repo-url>
# Name the remote as “upstream”
git clone --origin upstream https://github.com/aws/aws-cli.git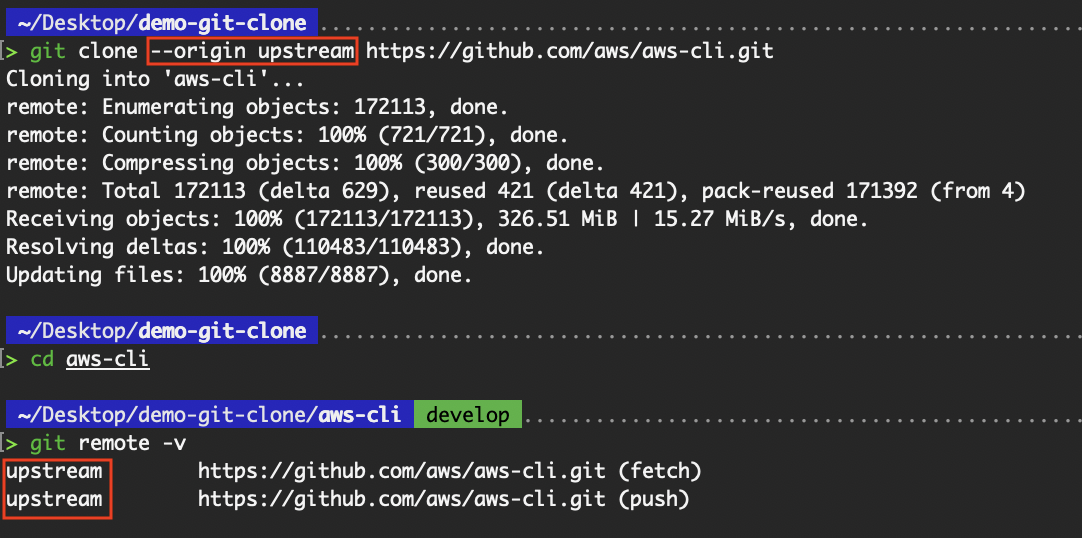
Benenne die Remote von „origin“ in „upstream“ um.
Entwickler müssen den Remote-Namen vielleicht ändern, um alles übersichtlicher zu halten, weil sie später vielleicht noch einen weiteren Remote hinzufügen müssen (z. B. Upstream vs. Forked Origin). Wenn du den Namen des ersten Remote-Geräts änderst, vermeidest du Verwirrung und Konflikte.
Mit dem Flag „ --template “ können Entwickler ein benutzerdefiniertes Vorlagenverzeichnis angeben, das Git beim Erstellen des Verzeichnisses „ .git “ im neu geklonten Repository verwendet. Mit Vorlagenverzeichnissen kannst du Hooks, Konfigurationsdateien oder Verzeichnisstrukturen vorab festlegen, die bei der Initialisierung automatisch auf das Repository angewendet werden.
# Specify the directory from which templates will be used
git clone --template=<template-directory> <repo>
git clone --template=./git-template https://github.com/aws/aws-cli.git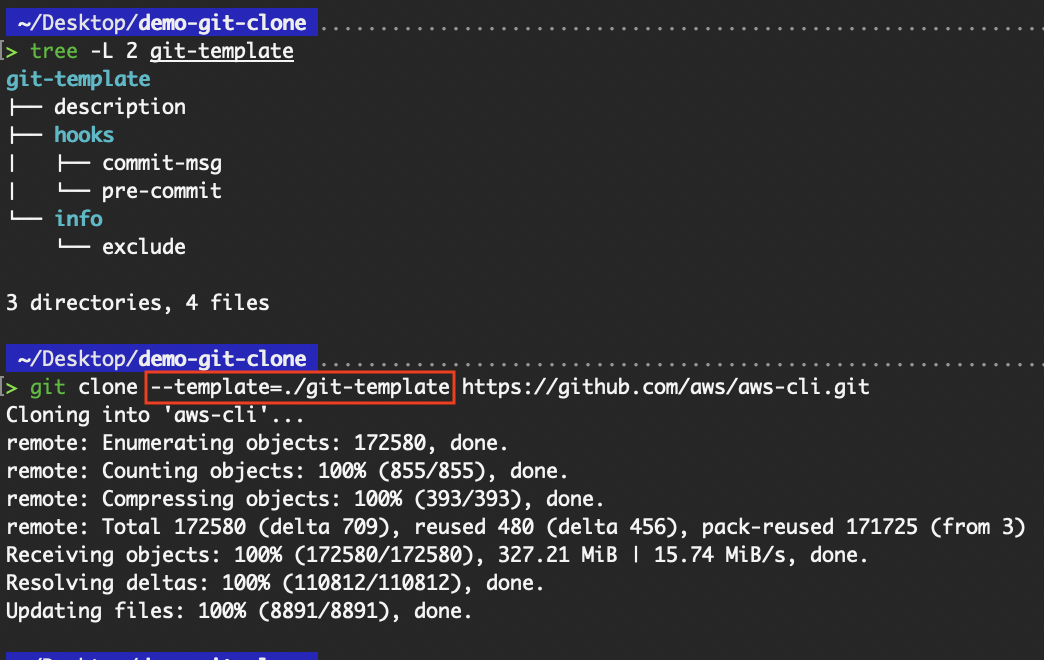
Verwendung des Flags --template
Ich werde das Template-Flag im Abschnitt „Anwendung des Template-Verzeichnisses“ näher erläutern.
Mit dem Flag „ --single-branch “ klonst du nur den Verlauf des angegebenen Branches, nicht den aller Branches im Remote-Repository. Das kann die Menge der geklonten Daten echt reduzieren, vor allem in Repos mit vielen langlebigen Branches oder einer umfangreichen Commit-Historie.
Wenn du an einer bestimmten Funktion oder einem Release-Zweig arbeiten sollst (z. B. feature/login-ui, release/v2.0), musst du nicht den Verlauf anderer Zweige klonen, die nichts damit zu tun haben.
git clone --branch feature/login-ui --single-branch <repo-url>
# If you do not specify a branch, Git will clone only the remote's default branch, usually main or master
git clone --single-branch <repo-url>
git clone --single-branch https://github.com/aws/aws-cli.gitEin typischer „ git clone “ verfolgt alle Remote-Zweige, wie in der folgenden Ausgabe von „ git branch -r “ gezeigt.
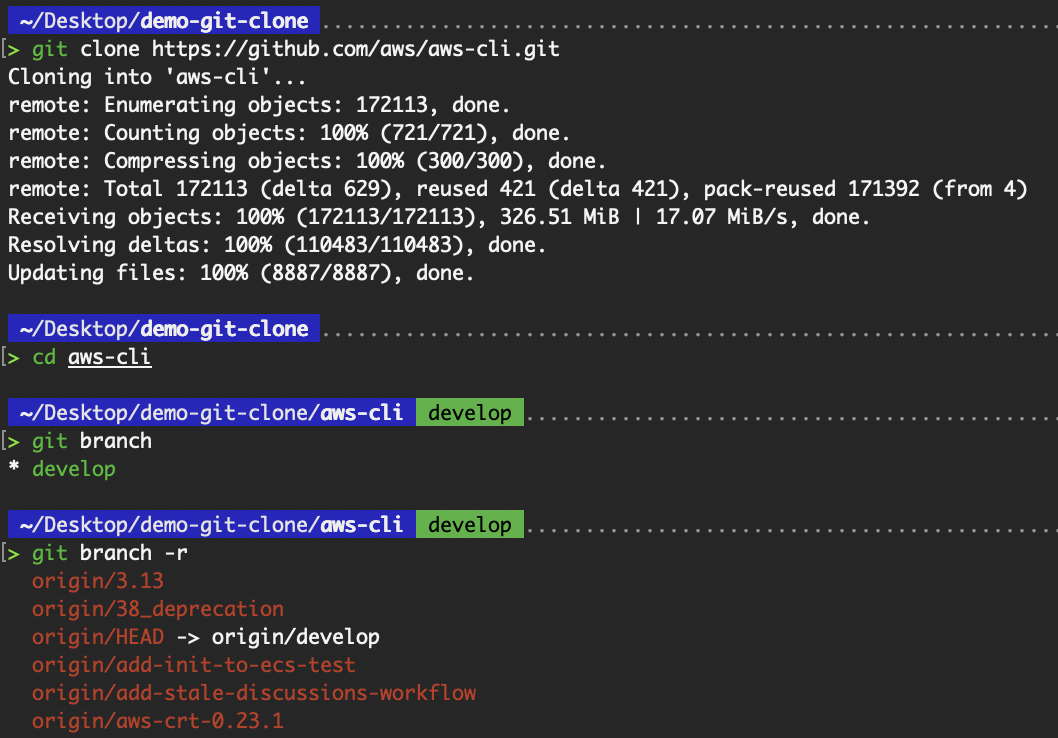
Alle Remote-Zweige werden verfolgt
Mit dem Befehl „ --single-branch “ wird nur die Historie des angegebenen Branches hinzugefügt.
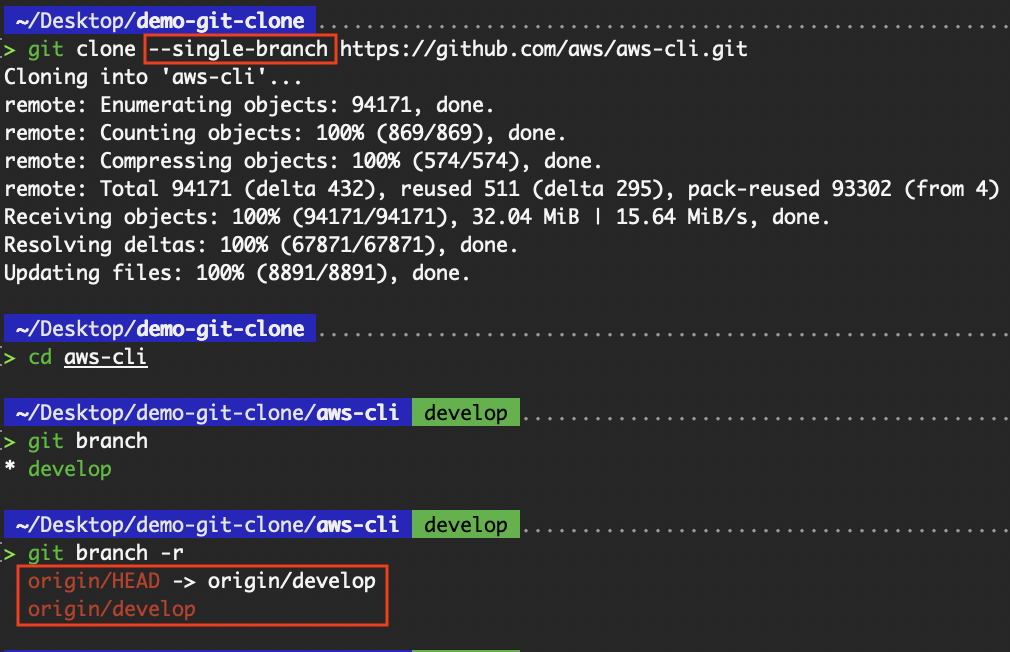
Nur der Standardzweig wird verfolgt.
Git-Submodule sind Verweise auf ein anderes Repository, die an einen bestimmten Commit gebunden sind. Damit kannst du das andere Git-Repository als Unterverzeichnis deines Git-Repositorys behalten, was oft genutzt wird, um Code von anderen, gemeinsam genutzte Bibliotheken oder herstellerspezifische Teile einzubinden.
Ich habein öffentliches GitHub-Repository erstellt, um dieses Konzept zu zeigen.
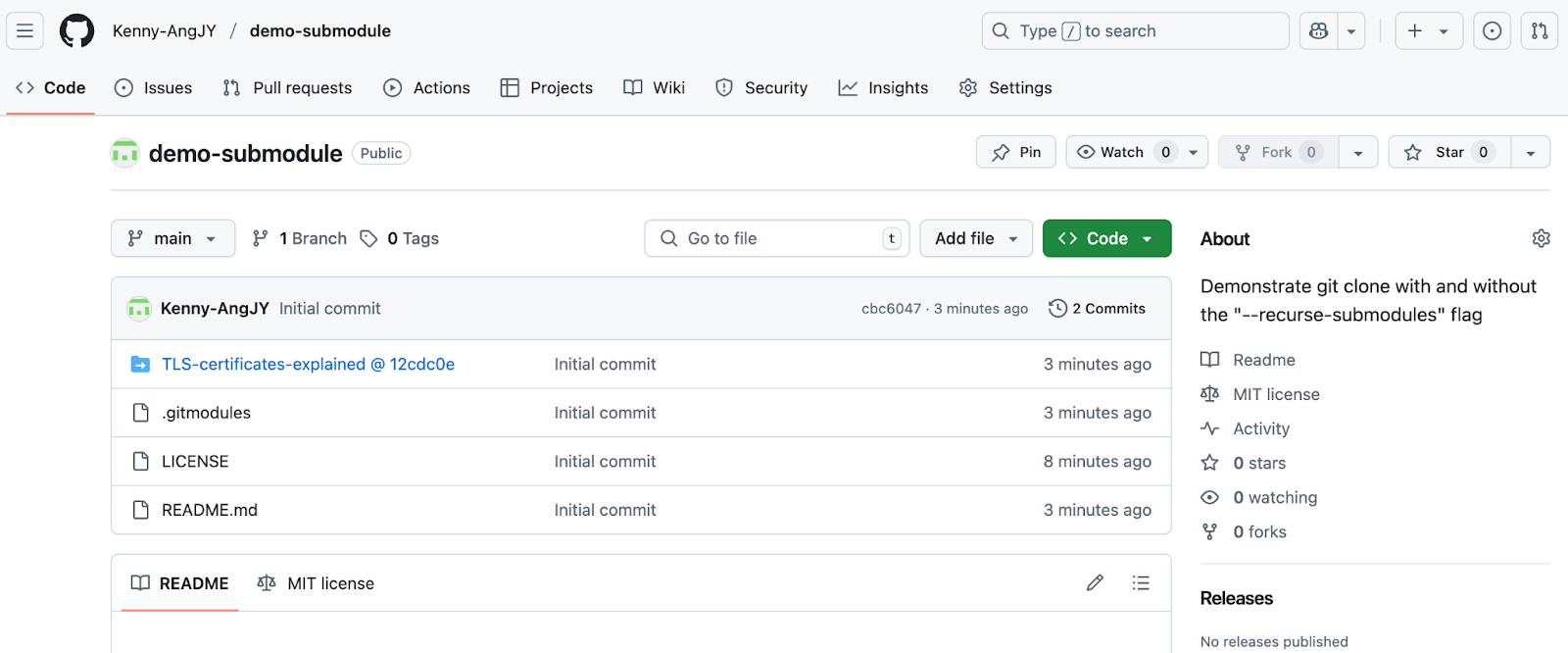
Submodule zeigen
Wenn wir ein Projekt mit einem Submodul klonen, kriegen wir standardmäßig die Verzeichnisse mit den Submodulen, aber nicht die Dateien darin.
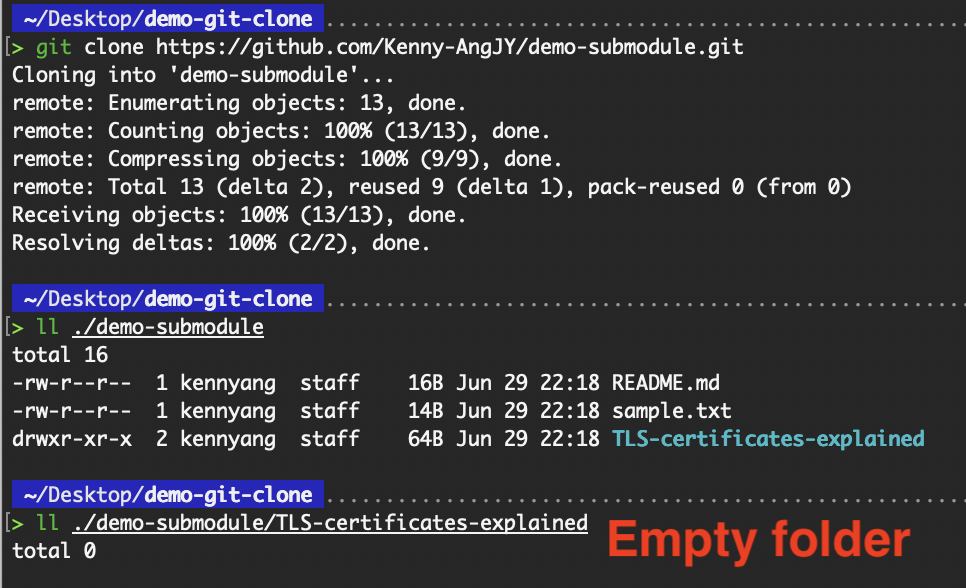
Leerer Submodul-Ordner
Anstatt „ git submodule init “ auszuführen, um deine lokale Konfigurationsdatei zu initialisieren, und „ git submodule update “, um alle Daten aus diesem Projekt abzurufen, können wir das Flag „ --recurse-submodules “ mit dem Befehl „ git clone “ verwenden, um alle in der Datei „ .gitmodules “ eines Repositorys definierten Submodule automatisch zu initialisieren und zu klonen.
git clone --recurse-submodules <repo-url>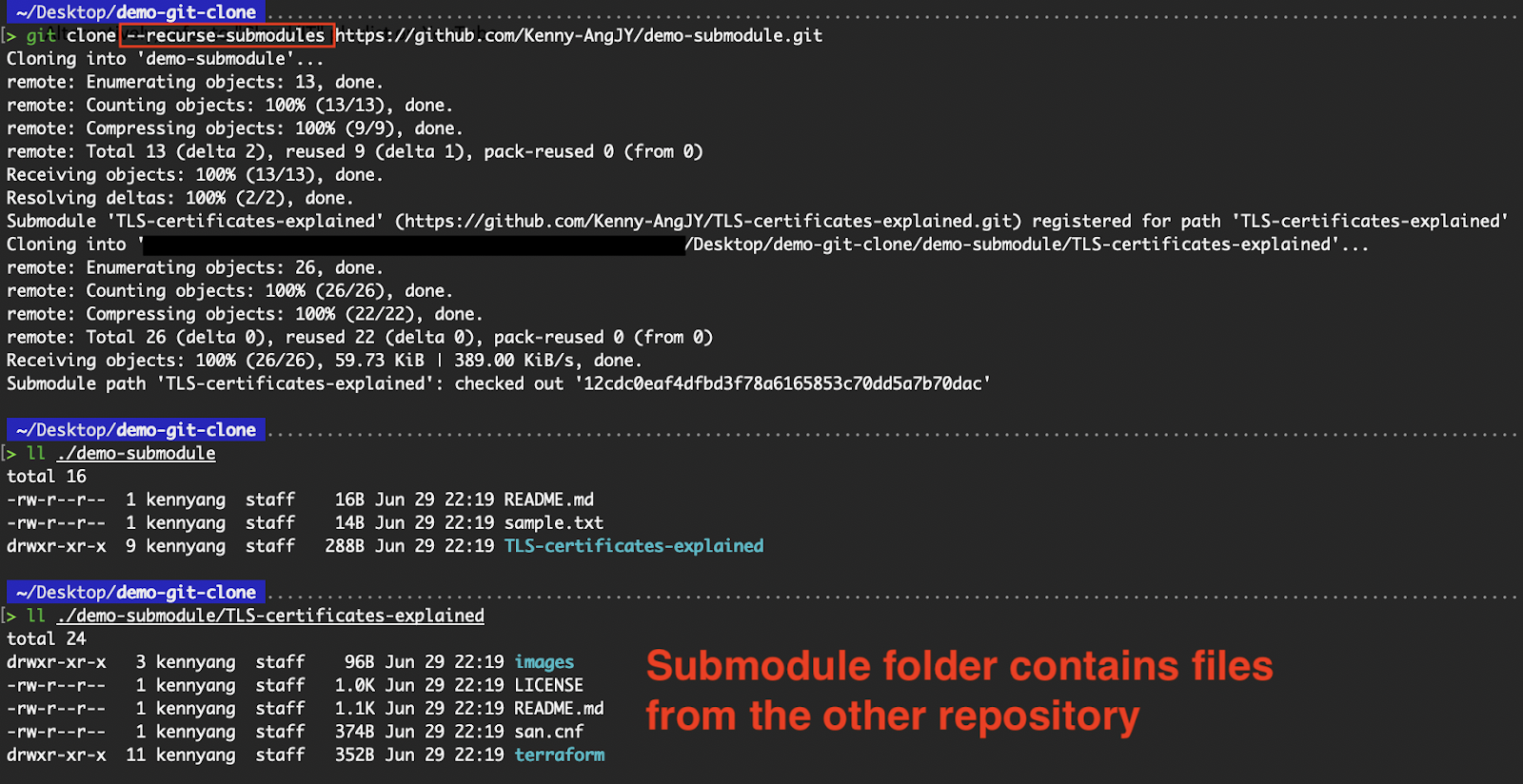
Klonieren von Dateien innerhalb des Submodul-Verzeichnisses
Mit Git kannst du Vorlagenverzeichnisse nutzen, um Standard-Hooks, Konfigurationen und andere Dateien beim Klonen oder beim Start eines Repositorys festzulegen:
Die Struktur des Vorlagenverzeichnisses kann so aussehen wie unten, wobei „ hooks/pre-commit “ ein Shell-Skript enthält, das Commits ohne JIRA-ID blockiert, und „ hooks/commit-msg “ die Vorlage für Commit-Meldungen enthält.
/home/devops/git-template/
├── config
├── description
├── hooks/
│ ├── pre-commit
│ └── commit-msg
├── info/
│ └── excludeNachdem du die benötigten Dateien im Vorlagenverzeichnis festgelegt hast, kannst du sie für deine Git-Klonvorgänge verwenden.
git clone --template=</path/to/template> <repo-url>
git clone --template=/home/devops/git-template https://github.com/aws/aws-cli.gitDas ist ideal für:
Vorlagenverzeichnisse machen die Teamarbeit einfacher und sorgen dafür, dass alles in geklonten Repositorys einheitlich bleibt.
Der Befehl „ git clone “ funktioniert im Grunde auf allen Plattformen gleich, aber je nach Betriebssystem kann es kleine Unterschiede geben.
Umgebungsspezifische Sachen wie Terminal-Tools, Dateipfadformate und die Handhabung von Berechtigungen können beeinflussen, wie Entwickler mit Git arbeiten. In diesem Abschnitt zeige ich dir, wie du das Klonen unter Windows, Linux/Ubuntu und macOS machst, damit du alle Feinheiten im Griff hast.
Unter Windows benutzen Entwickler normalerweise Git Bash, PowerShell oder die Eingabeaufforderung, um Git-Befehle auszuführen. Wir können Git von der Download-Seite installieren, die Git Bash mitbringt, eine Unix-ähnliche shell, die speziell für Git unter Windows angepasst wurde.
git clone in Git Bash
git clone in PowerShell
Ein paar Dinge, die du beachten solltest:
/c/Users/username/), während PowerShell und die Eingabeaufforderung das Windows-Format (C:\Users\username\) verwenden.Linux-Distributionen wie Ubuntu bieten über ihr eigenes Terminal eine super Git-Erfahrung. Für das folgende Beispiel habe ich eine Ubuntu-EC2-Instanz in AWS gestartet und mich über SSH damit verbunden.
Verbinde dich per SSH mit der Ubuntu EC2-Instanz.
Git ist schon installiert. Wenn es aber nicht da ist, mach einfach den Befehl „ sudo apt install git “.
Installiere Git auf Ubuntu
Geh zum gewünschten Verzeichnis und starte den Befehl „ git clone “.
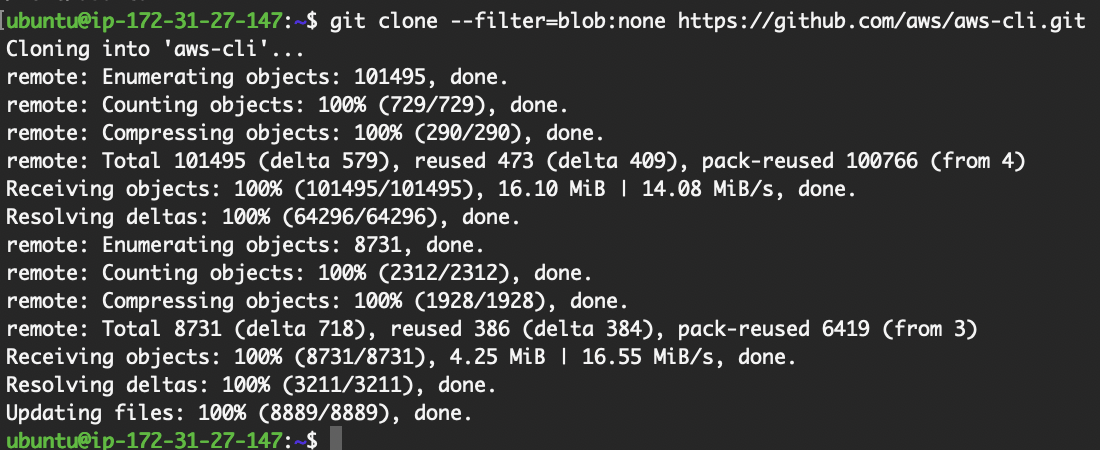
git clone in Ubuntu
Ein paar Dinge, die du beachten solltest:
~/.ssh/id_rsa).macOS hat eine Unix-basierte Umgebung, die Linux ziemlich ähnlich ist, sodass Git-Operationen ganz intuitiv funktionieren. Git ist oft schon installiert. Wenn nicht, kannst du Git mit der Installation der Xcode Command Line Tools (xcode-select --install) mitinstallieren.
Öffne das Terminal und gib den Befehl „ git clone “ ein.
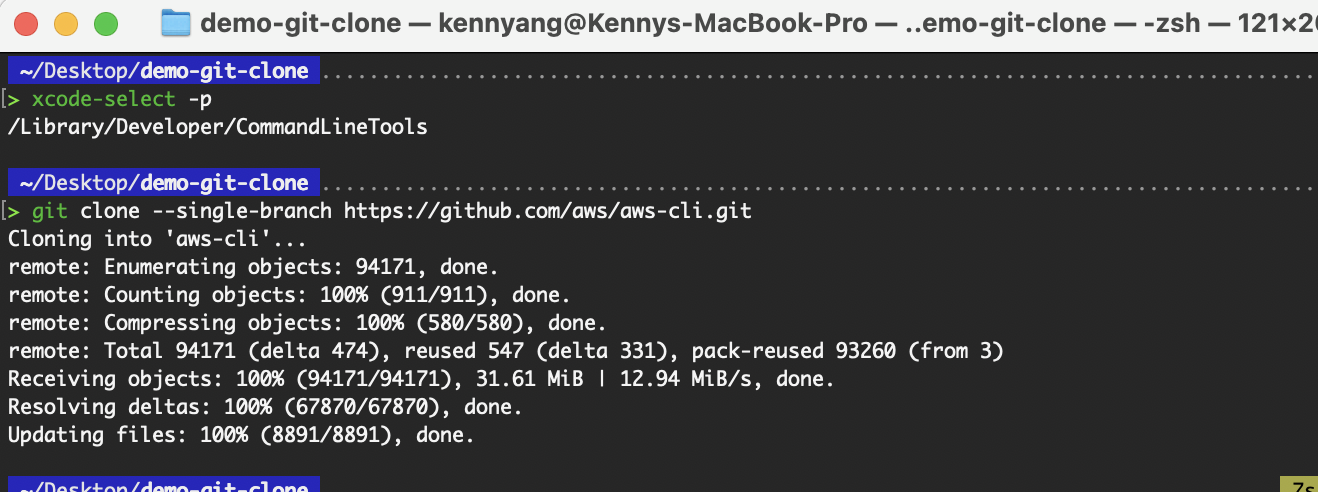 git clone auf Mac
git clone auf Mac
Ein paar Dinge, die du beachten solltest:
git clone wird zwar oft benutzt, um einfach eine Kopie eines Repositorys zu bekommen, aber in echten Engineering-Workflows kann man es für viel mehr nutzen.
In diesem Abschnitt schaue ich mir an, wie Klonstrategien in der Praxis eingesetzt werden können. Für jede Situation braucht man einen maßgeschneiderten Ansatz, um die Effizienz und Konsistenz zu maximieren.
In großen Unternehmen ist das effiziente Klonen von Repositorys super wichtig, um die Einarbeitung neuer Entwickler zu vereinfachen und die Projektkonfiguration zu standardisieren. Hier sind ein paar Strategien, die du anwenden kannst:
--depth=1). Wird oft benutzt, um die Einarbeitungszeit für neue Entwickler zu verkürzen, die nicht die ganze Commit-Historie brauchen.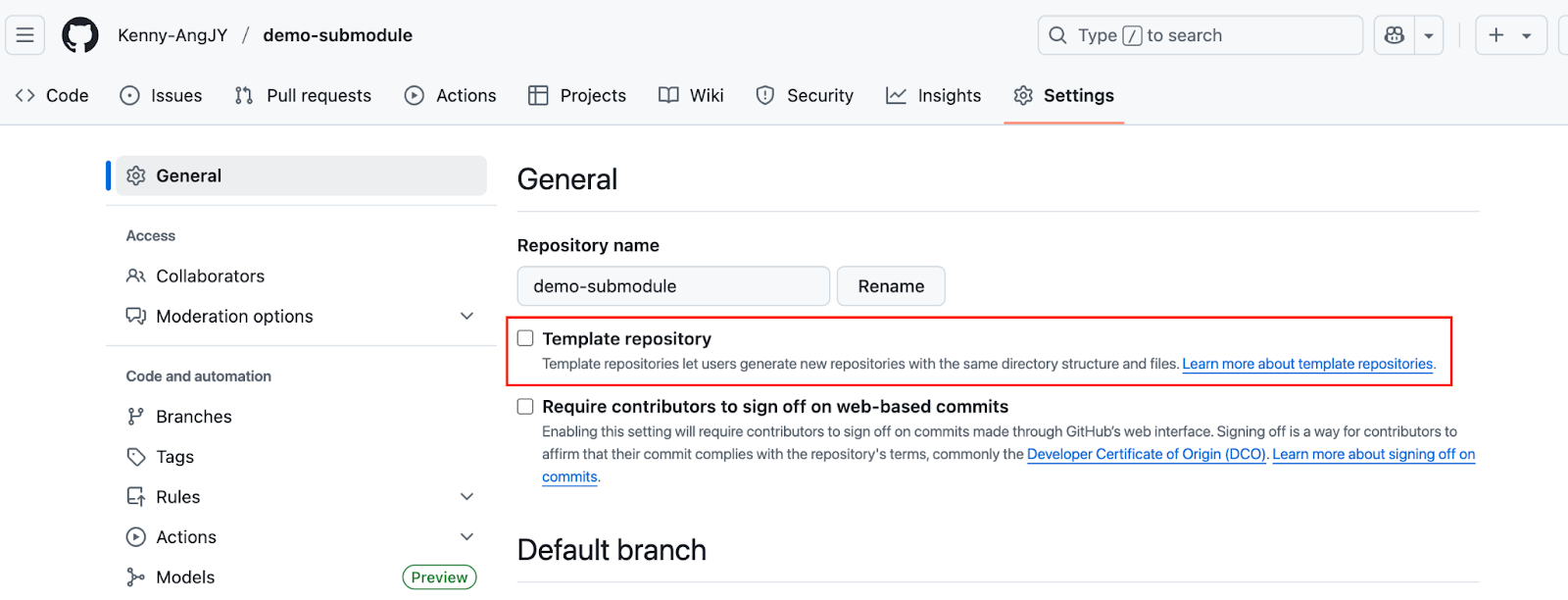
Einstellung für die Vorlagen-Datenbank
Nachdem du die Option aktiviert hast, findest du auf der Startseite deines Repositorys die Schaltfläche „Diese Vorlage verwenden“.
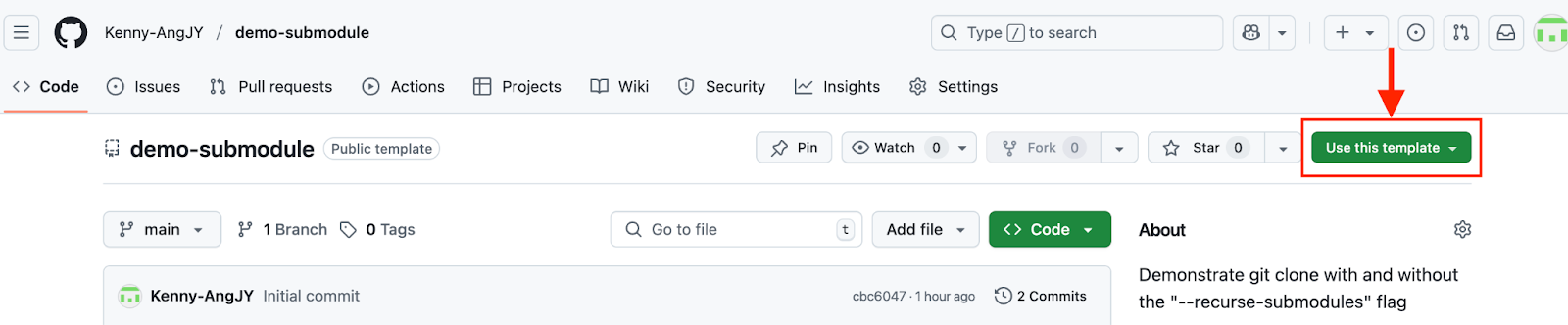
Das Repository als Vorlage verwenden
Unternehmen können aus verschiedenen Gründen, wie zum Beispiel aus Sicherheits-, Compliance- oder finanziellen Gründen, Repositorys zwischen Plattformen (z. B. von GitHub zu GitLab) migrieren. Für die Migration brauchst du einen Spiegelklon, damit alles komplett kopiert wird, also alle Zweige, Tags und die Commit-Historie.
Ein typischer Ablauf könnte so aussehen:
# --mirror flag clones all refs and configuration.
git clone --mirror https://source-url.com/your-repo.git
cd your-repo.git
git push --mirror https://target-url.com/your-new-repo.gitDiese Methode bewahrt Git-Metadaten besser als ein Standard-Klon mit anschließendem Push. Nach der Migration musst du die Remote-URLs aktualisieren und die Zugriffsberechtigungen checken.
In automatisierten Umgebungen spart die Optimierung von Klonvorgängen Zeit und reduziert den Ressourcenverbrauch, vor allem bei häufigen Bereitstellungen. Wir können die folgenden Best Practices befolgen, um einen effizienten Pipeline-Ablauf sicherzustellen:
--depth=1), um die Startzeiten der Jobs zu beschleunigen.git clone --depth 1 <repository-url>git clone --branch <branch-name> --single-branch <repo-url>git clone “-Operationen zu vermeiden. Anstatt das Repository in jeder Phase zu klonen, speicherst du das Arbeitsverzeichnis nach dem ersten Auschecken im Cache und gibst es als Artefakt oder freigegebenes Volume an die nächsten Phasen weiter. Dieser Ansatz reduziert überflüssige Vorgänge, beschleunigt die Pipeline-Ausführung und spart Rechen- und Netzwerkressourcen.
Obwohl „ git clone “ ein weit verbreiteter und unkomplizierter Befehl ist, können bei Entwicklern während des Klonvorgangs gelegentlich Probleme auftreten, insbesondere in Umgebungen mit strengen Authentifizierungskontrollen, benutzerdefinierten Repository-Konfigurationen oder eingeschränktem Netzwerkzugriff.
In diesem Abschnitt zeige ich dir die häufigsten Probleme beim Klonen und wie du sie schnell lösen kannst.
Authentifizierungsfehler treten normalerweise auf, wenn du auf private Repositorys zugreifst oder abgelaufene Anmeldedaten verwendest. Je nach Protokoll, HTTPS oder SSH, gibt's unterschiedliche Fehlermeldungen und Lösungen. In Umgebungen mit MFA solltest du immer SSH oder HTTPS mit PATs verwenden.
Bei HTTPS kommt es oft zu einem Fehler bei der Authentifizierung. Das kann passieren, wenn du einen abgelaufenen persönlichen Zugriffstoken benutzt. Wenn MFA aktiviert ist, könnte es auch daran liegen, dass das persönliche Zugriffstoken nicht als Passwort verwendet wurde.
 HTTPS-Authentifizierung hat nicht geklappt
HTTPS-Authentifizierung hat nicht geklappt
Bei SSH kommt oft der Fehler „Permission denied (publickey)“ vor. Das kann daran liegen, dass der öffentliche Schlüssel nicht zum Konto des Git-Anbieters hinzugefügt wurde oder dass der private Schlüssel auf deinem lokalen Gerät nicht im richtigen Verzeichnis gespeichert ist.
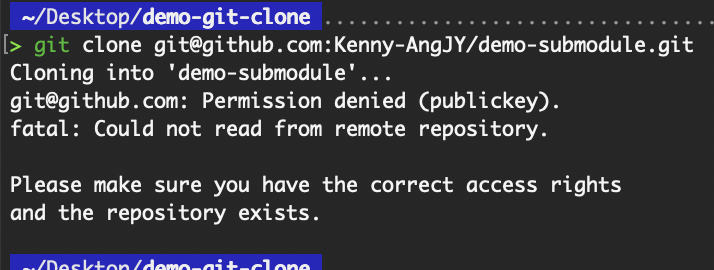 SSH-Authentifizierung fehlgeschlagen
SSH-Authentifizierung fehlgeschlagen
Du kannst die Verbindung so überprüfen:
ssh -T git@github.comIn seltenen Fällen kann es bei der Verwendung von Teilklonen ( Flags „--filter “ oder „ --depth “) vorkommen, dass Objekte fehlen (z. B. „Fehler: Objekt <sha> fehlt“), wenn Git versucht, auf Teile des Repositorys zuzugreifen, die ursprünglich nicht abgerufen wurden.
Ich hab so was noch nie erlebt. Trotzdem kann es zu Fehlern kommen, wenn du auf alte Commits, Branches oder Tags zugreifen willst. Wenn das in einer Pipeline ist, können Build-Tools oder Skripte abstürzen. Du kannst die fehlenden Daten ganz einfach so abrufen:
# Have Git refetch all objects from the remote, even if it thinks it already has them.
# For dealing with a broken or corrupted partial clone
git fetch --filter=blob:none --refetch
# Convert a shallow clone into a full clone. Retrieves the rest of the commit history that was omitted during the shallow clone.
git fetch --unshallow
# Obtain a deeper history of the branch
git fetch origin <branch> --depth=50
# Fetches 30 more commits from the current branch’s history. Repeat as needed.
git fetch --deepen=30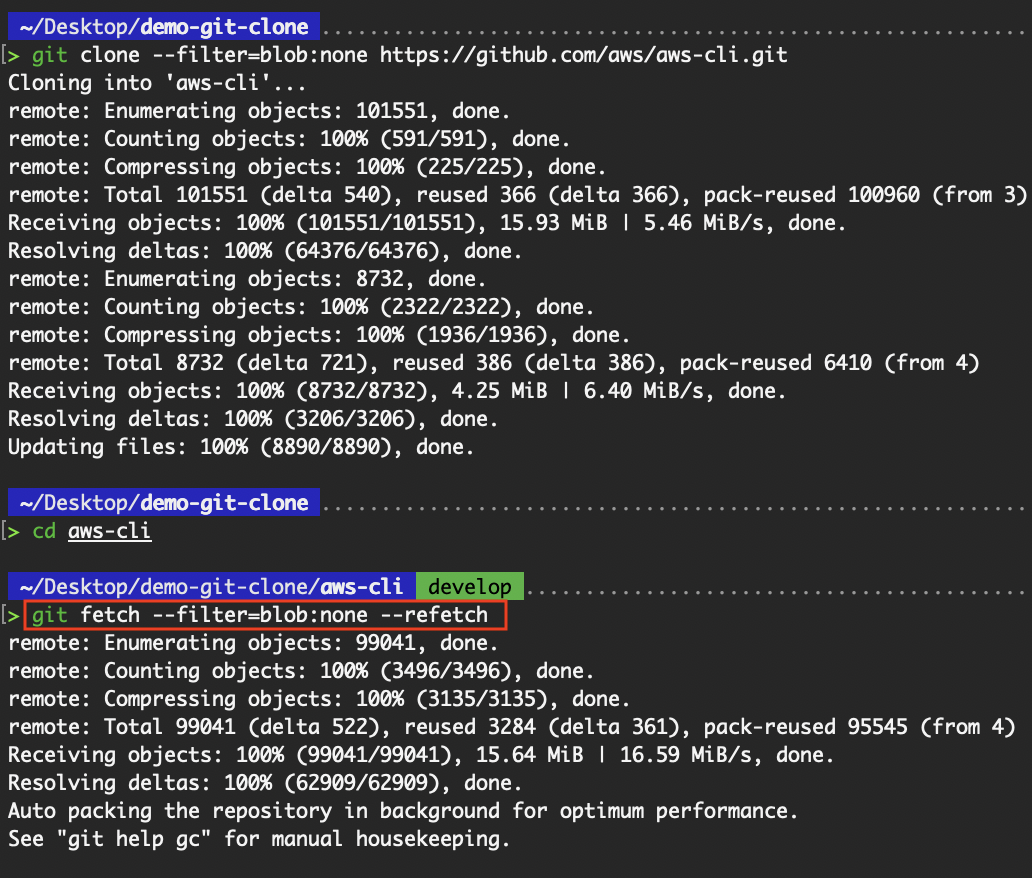
Lass Git alle Objekte vom Remote-Repository neu abrufen.
Neben den oben genannten Problemen, die bei der Ausführung von „ git clone “ auftreten können, sind in der folgenden Tabelle weitere häufige Fehler aufgeführt .
|
Fehlermeldung |
Ursache |
Fix |
|
Repository nicht gefunden. |
Falsche URL oder kein Zugriff |
Überprüfe die Repository-URL und stell sicher, dass du Leserechte hast. |
|
Fataler Fehler: Zugriff auf „...“ nicht möglich: Problem mit SSL-Zertifikat |
Problem mit der Zertifikatsvertrauenswürdigkeit |
Verwende eine gültige Zertifizierungsstelle oder deaktiviere die SSL-Überprüfung (nicht empfohlen): git config --global http.sslVerify false |
|
RPC ist abgestürzt; curl 56 |
Netzwerkprobleme oder große Repo |
Puffergröße erhöhen: git config --global http.postBuffer 524288000 |
Der Befehl „ git clone “ sieht auf den ersten Blick einfach aus, und für viele reicht die grundlegende Verwendung völlig aus. Wie dieser Artikel gezeigt hat, ist es aber ein grundlegendes Tool mit vielen Anwendungsmöglichkeiten.
Wir haben erklärt, wie „ git clone “ funktioniert, verschiedene URL-Typen und Protokolle angeschaut, fortgeschrittene Konfigurationen und betriebssystemspezifische Verhaltensweisen durchgegangen und reale Szenarien wie CI/CD, Unternehmens-Workflows und gängige Techniken zur Fehlerbehebung untersucht.
Wenn du „ git clone “ an deine Umgebung anpasst – egal ob für flache Klone in Pipelines, Repository-Migrationen oder große Zusammenarbeit – kannst du die Leistung und die Effizienz deines Teams echt steigern. Da moderne Entwicklungsumgebungen immer komplexer und verteilter werden, stellt die Beherrschung dieser Konfigurationen sicher, dass du Git nicht nur verwendest, sondern auch effektiv nutzt.
Für die Zukunft kann man die Klonmechanismen von Git noch verbessern, zum Beispiel mit smarteren Teilklonen, besserer Unterstützung für große Monorepos und einer intuitiveren Handhabung von Submodulen und Filtern. Mit der Weiterentwicklung von Git können Entwickler durch die Nutzung dieser Verbesserungen schneller und effizienter auf jedem System und in jeder Größenordnung arbeiten.
Um mehr über Git zu erfahren, empfehle ichdir den Kurs „Einführung in Git “. Wenn du deine Fähigkeiten auf die nächste Stufe bringen willst, dann ist der Kurs „Advanced Git“ genau das Richtige für dich!
Lerne mehr über Git mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
