Große Sprachmodelle (Large Language Models, LLMs) sind wichtige Bestandteile moderner Anwendungen der künstlichen Intelligenz, insbesondere bei der Verarbeitung natürlicher Sprache. Sie haben das Potenzial, menschliche Sprache effizient zu verarbeiten und zu verstehen. Die Anwendungen reichen von virtuellen Assistenten und maschineller Übersetzung bis hin zu Textzusammenfassungen und der Beantwortung von Fragen.
Bibliotheken wie LangChain erleichtern die Implementierung von End-to-End-KI-Anwendungen wie den oben genannten. Unser Tutorial Einführung in LangChain für Data Engineering & Datenanwendungen gibt einen Überblick darüber, was du mit Langchain machen kannst, einschließlich der Probleme, die LangChain löst, sowie Beispiele für Datenanwendungsfälle.
In diesem Artikel wird der gesamte Prozess des Trainings eines großen Sprachmodells erklärt, von der Einrichtung des Arbeitsbereichs bis zur endgültigen Implementierung mit Pytorch 2.0.1, einem dynamischen und flexiblen Deep-Learning-Framework, das eine einfache und klare Modellimplementierung ermöglicht.
Voraussetzungen
Um das meiste aus diesem Inhalt herauszuholen, ist es wichtig, dass du dich mit der Python-Programmierung auskennst, ein grundlegendes Verständnis von Deep Learning-Konzepten und Transformatoren hast und mit dem Pytorch-Framework vertraut bist. Der vollständige Quellcode wird auf GitHub verfügbar sein.
Bevor wir uns mit der Kernimplementierung beschäftigen, müssen wir die relevanten Bibliotheken installieren und importieren. Außerdem ist es wichtig zu wissen, dass das Trainingsskript von diesem Repository von Hugging Face inspiriert wurde.
Installation der Bibliothek
Der Installationsprozess wird im Folgenden beschrieben:
Zunächst verwenden wir die Anweisung %%bash, um die Installationsbefehle in einer einzigen Zelle als Bash-Befehl im Jupyter Notebook auszuführen.
- Trl: zum Trainieren von Transformer-Sprachmodellen mit Reinforcement Learning.
- Peft nutzt die Methode der parameter-effizienten Feinabstimmung (PEFT), um eine effiziente Anpassung des vortrainierten Modells zu ermöglichen.
- Torch: eine weit verbreitete Open-Source-Bibliothek für maschinelles Lernen.
- Datensätze: Sie helfen beim Herunterladen und Laden vieler gängiger Datensätze für maschinelles Lernen.
Transformers: eine von Hugging Face entwickelte Bibliothek mit Tausenden von vortrainierten Modellen für eine Vielzahl von textbasierten Aufgaben wie Klassifizierung, Zusammenfassung und Übersetzung.
%%bash
pip -q install trl
pip -q install peft
pip -q install torch
pip -q install datasets
pip -q install transformers
Jetzt können diese Module wie folgt importiert werden:
import torch
from trl import SFTTrainer
from datasets import load_dataset
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArgumentsLaden und Aufbereiten von Daten
Zur Veranschaulichung wird der Alpaka-Datensatz verwendet, der auf Hugging Face frei verfügbar ist. Der Datensatz hat drei Hauptspalten: Anweisungen, Eingabe und Ausgabe. Diese Spalten werden kombiniert, um eine endgültige Textspalte zu erstellen.
Die Anweisung zum Laden des Datensatzes wird unten gegeben, indem der Name des gewünschten Datensatzes angegeben wird, nämlich tatsu-lab/alpaca:
train_dataset = load_dataset("tatsu-lab/alpaca", split="train")
print(train_dataset)Wir können sehen, dass die resultierenden Daten in einem Wörterbuch mit zwei Schlüsseln stehen:
- Merkmale: enthält die Hauptspalten der Daten
- Num_rows: entspricht der Gesamtzahl der Zeilen in den Daten

Struktur des train_dataset
Die ersten fünf Zeilen können mit der folgenden Anweisung angezeigt werden. Konvertiere das Wörterbuch zunächst in einen Pandas DataFrame und zeige dann die Zeilen an.
pandas_format = train_dataset.to_pandas()
display(pandas_format.head())
Die ersten fünf Zeilen des train_dataset
Zur besseren Veranschaulichung drucken wir die Informationen über die ersten drei Zeilen, aber vorher müssen wir die Bibliothek textwrap installieren, um die maximale Anzahl der Wörter pro Zeile auf 50 zu setzen. Die erste Druckanweisung trennt jeden Block durch 15 Bindestriche.
import textwrap
for index in range(3):
print("---"*15)
print("Instruction:
{}".format(textwrap.fill(pandas_format.iloc[index]["instruction"],
width=50)))
print("Output:
{}".format(textwrap.fill(pandas_format.iloc[index]["output"],
width=50)))
print("Text:
{}".format(textwrap.fill(pandas_format.iloc[index]["text"],
width=50)))
Details zu den ersten drei Reihen
Model Ausbildung
Bevor wir mit dem Training des Modells beginnen, müssen wir einige Voraussetzungen schaffen:
- Vorgeprüftes Modell: Wir verwenden das vortrainierte Modell Salesforce/xgen-7b-8k-base, das auf Hugging Face verfügbar ist. Salesforce trainierte diese Serie von 7B LLMs namens XGen-7B mit standardmäßiger dichter Aufmerksamkeit auf bis zu 8K Sequenzen für bis zu 1,5T Token.
- Tokenizer: Dies wird für die Tokenisierung der Trainingsdaten benötigt. Der Code zum Laden des vortrainierten Modells und des Tokenizers lautet wie folgt:
pretrained_model_name = "Salesforce/xgen-7b-8k-base"
model = AutoModelForCausalLM.from_pretrained(pretrained_model_name, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name, trust_remote_code=True)Konfiguration der Ausbildung
Für das Training sind einige Trainingsargumente und Konfigurationen erforderlich. Die beiden wichtigsten Konfigurationsobjekte sind im Folgenden definiert: eine Instanz des TrainingArguments, eine Instanz des LoraConfig-Modells und schließlich das SFTTrainer-Modell.
AusbildungArgumente
Damit werden die Parameter für das Modelltraining festgelegt.
In diesem speziellen Szenario legen wir zunächst das Ziel fest, an dem das trainierte Modell gespeichert werden soll, indem wir das Attribut output_dir verwenden, bevor wir weitere Hyperparameter wie die Optimierungsmethode, die learning rate, die number of epochs und weitere festlegen.
model_training_args = TrainingArguments(
output_dir="xgen-7b-8k-base-fine-tuned",
per_device_train_batch_size=4,
optim="adamw_torch",
logging_steps=80,
learning_rate=2e-4,
warmup_ratio=0.1,
lr_scheduler_type="linear",
num_train_epochs=1,
save_strategy="epoch"
)LoRAConfig
Die wichtigsten Argumente für dieses Szenario sind der Rang der Low-Rank-Transformationsmatrix in LoRA, der auf 16 gesetzt wird. Dann wird der Skalierungsfaktor für die zusätzlichen Parameter in LoRA auf 32 gesetzt.
Außerdem beträgt die Dropout-Quote 0,05, was bedeutet, dass 5% der Eingabeeinheiten beim Training ignoriert werden. Da wir es mit einer kausalen Sprachmodellierung zu tun haben, wird die Aufgabe mit dem Attribut CAUSAL_LM initialisiert.
SFTTrainer
Ziel ist es, das Modell anhand der Trainingsdaten, des Tokenizers und zusätzlicher Informationen wie den oben genannten Modellen zu trainieren.
Da wir das Textfeld aus den Trainingsdaten verwenden, ist es wichtig, einen Blick auf die Verteilung zu werfen, um die maximale Anzahl von Token in einer bestimmten Sequenz festzulegen.
import matplotlib.pyplot as plt
pandas_format['text_length'] = pandas_format['text'].apply(len)
plt.figure(figsize=(10,6))
plt.hist(pandas_format['text_length'], bins=50, alpha=0.5, color='g')
plt.title('Distribution of Length of Text')
plt.xlabel('Length of Text')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()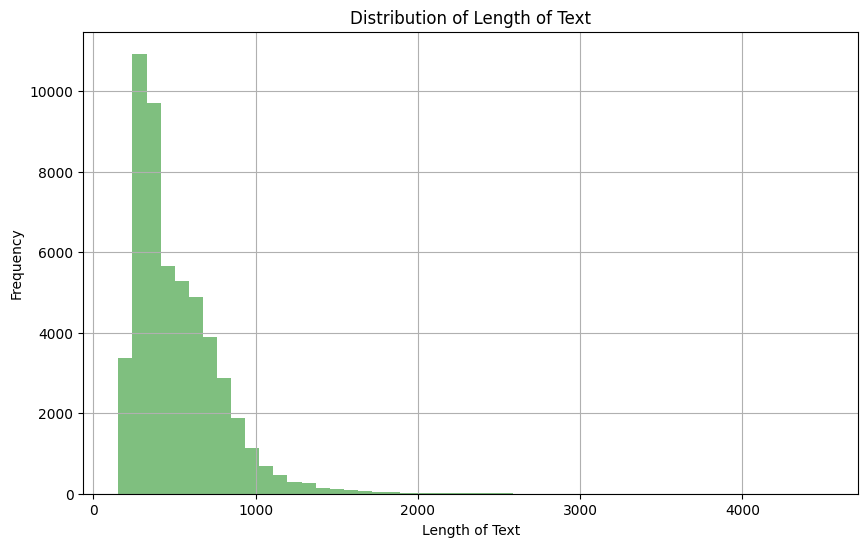
Verteilung der Länge der Textspalte
Anhand der obigen Beobachtung können wir sehen, dass die Mehrheit der Texte eine Länge zwischen 0 und 1000 hat. Außerdem können wir unten sehen, dass nur 4,5% der Textdokumente eine Länge von mehr als 1024 haben.
mask = pandas_format['text_length'] > 1024
percentage = (mask.sum() / pandas_format['text_length'].count()) * 100
print(f"The percentage of text documents with a length greater than 1024 is: {percentage}%")

Dann setzen wir die maximale Anzahl von Token in der Sequenz auf 1024, damit jeder Text, der länger ist, abgeschnitten wird.
SFT_trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
dataset_text_field="text",
max_seq_length=1024,
tokenizer=tokenizer,
args=model_training_args,
packing=True,
peft_config=lora_peft_config,
)Ausführung der Ausbildung
Wenn alle Voraussetzungen gegeben sind, können wir den Trainingsprozess des Modells wie folgt durchführen:
tokenizer.pad_token = tokenizer.eos_token
model.resize_token_embeddings(len(tokenizer))
model = prepare_model_for_int8_training(model)
model = get_peft_model(model, lora_peft_config)
training_args = model_training_args
trainer = SFT_trainer
trainer.train()Es ist wichtig zu erwähnen, dass dieses Training in einer Cloud-Umgebung mit einer GPU durchgeführt wird, was den gesamten Trainingsprozess beschleunigt. Die Ausbildung an einem lokalen Computer würde jedoch mehr Zeit in Anspruch nehmen.
Unser Blog, Pro und Contra der Verwendung von LLMs in der Cloud gegenüber der lokalen Ausführung von LLMs, enthält wichtige Überlegungen zur Auswahl der optimalen Bereitstellungsstrategie für LLMs
Lass uns verstehen, was in dem obigen Codeschnipsel passiert:
- tokenizer.pad_token = tokenizer.eos_token: Legt fest, dass das Auffüllungs-Token mit dem Satzende-Token übereinstimmt.
- model.resize_token_embeddings(len(tokenizer)): Ändert die Größe der Token-Einbettungsschicht des Modells, um sie an die Länge des Tokenizer-Vokabulars anzupassen.
- model = prepare_model_for_int8_training(model): Bereitet das Modell für das Training mit INT8-Genauigkeit vor und führt wahrscheinlich eine Quantisierung durch.
- model = get_peft_model(model, lora_peft_config): Passt das angegebene Modell entsprechend der PEFT-Konfiguration an.
- training_args = model_training_args: Weist den training_args vordefinierte Trainingsargumente zu.
- trainer = SFT_trainer: Weist die SFTTrainer-Instanz der Variablen trainer zu.
- trainer.train(): Löst den Trainingsprozess des Modells gemäß den angegebenen Spezifikationen aus.
Fazit
Dieser Artikel bietet eine klare Anleitung zum Training eines großen Sprachmodells mit PyTorch. Beginnend mit der Vorbereitung des Datensatzes wurden die Schritte zur Vorbereitung der Voraussetzungen, zur Einrichtung des Trainers und schließlich zur Durchführung des Trainings durchlaufen.
Obwohl ein spezieller Datensatz und ein vorab trainiertes Modell verwendet wurden, sollte der Prozess für alle anderen kompatiblen Optionen weitgehend identisch sein. Jetzt, wo du weißt, wie man ein LLM trainiert, kannst du dieses Wissen nutzen, um andere anspruchsvolle Modelle für verschiedene NLP-Aufgaben zu trainieren.
In unserem Leitfaden zur Erstellung von LLM-Anwendungen mit LangChain erfährst du mehr über die Leistungsfähigkeit von großen Sprachmodellen. Wenn du dich noch mit den Konzepten der großen Sprachmodelle beschäftigen musst, kannst du dich in unserem Kurs weiterbilden.
