Os modelos de linguagem grande (LLMs) são os principais componentes dos aplicativos modernos de inteligência artificial, especialmente para o processamento de linguagem natural. Eles têm o potencial de processar e compreender com eficiência a linguagem humana, com aplicações que vão desde assistentes virtuais e tradução automática até resumos de textos e respostas a perguntas.
Bibliotecas como a LangChain facilitam a implementação de aplicativos de IA de ponta a ponta, como os mencionados acima. Nosso tutorial Introdução ao LangChain para engenharia de dados e aplicativos de dados fornece uma visão geral do que você pode fazer com o Langchain, incluindo os problemas que o LangChain resolve, juntamente com exemplos de casos de uso de dados.
Este artigo explicará todo o processo de treinamento de um modelo de linguagem grande, desde a configuração do espaço de trabalho até a implementação final usando o Pytorch 2.0.1, uma estrutura de aprendizagem profunda dinâmica e flexível que permite uma implementação fácil e clara do modelo.
Pré-requisitos
Para aproveitar ao máximo este conteúdo, é importante estar familiarizado com a programação em Python, ter uma compreensão básica dos conceitos e transformadores de aprendizagem profunda e estar familiarizado com a estrutura do Pytorch. O código-fonte completo estará disponível no GitHub.
Antes de mergulhar na implementação do núcleo, precisamos instalar e importar as bibliotecas relevantes. Além disso, é importante observar que o script de treinamento é inspirado nesse repositório do Hugging Face.
Instalação da biblioteca
O processo de instalação está detalhado abaixo:
Em primeiro lugar, usamos a instrução %%bash para executar os comandos de instalação em uma única célula como um comando bash no Jupyter Notebook.
- Trl: usado para treinar modelos de linguagem de transformador com aprendizado por reforço.
- O Peft usa os métodos de ajuste fino com eficiência de parâmetros (PEFT) para permitir a adaptação eficiente do modelo pré-treinado.
- Torch: uma biblioteca de aprendizado de máquina de código aberto amplamente utilizada.
- Datasets: usado para auxiliar no download e no carregamento de muitos conjuntos de dados comuns de aprendizado de máquina.
Transformers: uma biblioteca desenvolvida pela Hugging Face e que vem com milhares de modelos pré-treinados para uma variedade de tarefas baseadas em texto, como classificação, resumo e tradução.
%%bash
pip -q install trl
pip -q install peft
pip -q install torch
pip -q install datasets
pip -q install transformers
Agora, esses módulos podem ser importados da seguinte forma:
import torch
from trl import SFTTrainer
from datasets import load_dataset
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArgumentsCarregamento e preparação de dados
O conjunto de dados de alpaca, disponível gratuitamente no Hugging Face, será usado para esta ilustração. O conjunto de dados tem três colunas principais: instruções, entrada e saída. Essas colunas são combinadas para gerar uma coluna de texto final.
A instrução para carregar o conjunto de dados é dada abaixo, fornecendo o nome do conjunto de dados de interesse, que é tatsu-lab/alpaca:
train_dataset = load_dataset("tatsu-lab/alpaca", split="train")
print(train_dataset)Podemos ver que os dados resultantes estão em um dicionário de duas chaves:
- Features: contém as colunas principais dos dados
- Num_rows: correspondente ao número total de linhas nos dados

Estrutura do train_dataset
As primeiras cinco linhas podem ser exibidas com a seguinte instrução. Primeiro, converta o dicionário em um dataframe do pandas e, em seguida, exiba as linhas.
pandas_format = train_dataset.to_pandas()
display(pandas_format.head())
Primeiras cinco linhas do train_dataset
Para melhor visualização, vamos imprimir as informações sobre as três primeiras linhas, mas, antes disso, precisamos instalar a biblioteca textwrap para definir o número máximo de palavras por linha como 50. A primeira instrução de impressão separa cada bloco por 15 traços.
import textwrap
for index in range(3):
print("---"*15)
print("Instruction:
{}".format(textwrap.fill(pandas_format.iloc[index]["instruction"],
width=50)))
print("Output:
{}".format(textwrap.fill(pandas_format.iloc[index]["output"],
width=50)))
print("Text:
{}".format(textwrap.fill(pandas_format.iloc[index]["text"],
width=50)))
Detalhes das três primeiras linhas
Treinamento de modelos
Antes de prosseguir com o treinamento do modelo, precisamos definir alguns pré-requisitos:
- Modelo pré-treinado: Usaremos o modelo pré-treinado Salesforce/xgen-7b-8k-base, que está disponível no Hugging Face. A Salesforce treinou essa série de LLMs 7B denominada XGen-7B com atenção densa padrão em até 8K sequências para até 1,5T tokens.
- Tokenizador: Isso é necessário para tarefas de tokenização nos dados de treinamento. O código para carregar o modelo pré-treinado e o tokenizador é o seguinte:
pretrained_model_name = "Salesforce/xgen-7b-8k-base"
model = AutoModelForCausalLM.from_pretrained(pretrained_model_name, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name, trust_remote_code=True)Configuração do treinamento
O treinamento requer alguns argumentos e configurações de treinamento, e os dois objetos de configuração importantes são definidos abaixo, uma instância do TrainingArguments, uma instância do modelo LoraConfig e, por fim, o modelo SFTTrainer.
TrainingArguments
Isso é usado para definir os parâmetros para o treinamento do modelo.
Nesse cenário específico, começamos definindo o destino em que o modelo treinado será armazenado usando o atributo output_dir antes de definir hiperparâmetros adicionais, como o método de otimização, o learning rate, o number of epochs, entre outros.
model_training_args = TrainingArguments(
output_dir="xgen-7b-8k-base-fine-tuned",
per_device_train_batch_size=4,
optim="adamw_torch",
logging_steps=80,
learning_rate=2e-4,
warmup_ratio=0.1,
lr_scheduler_type="linear",
num_train_epochs=1,
save_strategy="epoch"
)LoRAConfig
Os principais argumentos usados para esse cenário são a classificação da matriz de transformação de baixa classificação no LoRA, que é definida como 16. Em seguida, o fator de escala para os parâmetros adicionais no LoRA é definido como 32.
Além disso, a taxa de desistência é de 0,05, o que significa que 5% das unidades de entrada serão ignoradas durante o treinamento. Por fim, como estamos lidando com uma modelagem de linguagem causal, a tarefa é, portanto, inicializada com o atributo CAUSAL_LM.
SFTTrainer
O objetivo é treinar o modelo usando os dados de treinamento, o tokenizador e informações adicionais, como os modelos acima.
Como estamos usando o campo de texto dos dados de treinamento, é importante dar uma olhada na distribuição para ajudar a definir o número máximo de tokens em uma determinada sequência.
import matplotlib.pyplot as plt
pandas_format['text_length'] = pandas_format['text'].apply(len)
plt.figure(figsize=(10,6))
plt.hist(pandas_format['text_length'], bins=50, alpha=0.5, color='g')
plt.title('Distribution of Length of Text')
plt.xlabel('Length of Text')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()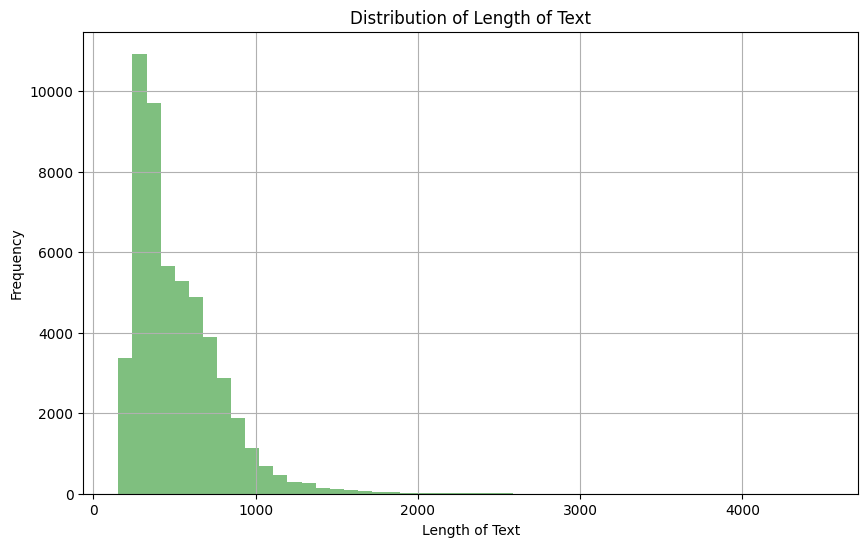
Distribuição do comprimento da coluna de texto
Com base na observação acima, podemos ver que a maior parte do texto tem um comprimento entre 0 e 1000. Além disso, podemos ver abaixo que apenas 4,5% dos documentos de texto têm um comprimento maior que 1024.
mask = pandas_format['text_length'] > 1024
percentage = (mask.sum() / pandas_format['text_length'].count()) * 100
print(f"The percentage of text documents with a length greater than 1024 is: {percentage}%")

Em seguida, definimos o número máximo de tokens na sequência como 1024, de modo que qualquer texto maior do que isso seja truncado.
SFT_trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
dataset_text_field="text",
max_seq_length=1024,
tokenizer=tokenizer,
args=model_training_args,
packing=True,
peft_config=lora_peft_config,
)Execução do treinamento
Com todos os pré-requisitos em vigor, podemos agora executar o processo de treinamento do modelo da seguinte forma:
tokenizer.pad_token = tokenizer.eos_token
model.resize_token_embeddings(len(tokenizer))
model = prepare_model_for_int8_training(model)
model = get_peft_model(model, lora_peft_config)
training_args = model_training_args
trainer = SFT_trainer
trainer.train()É importante mencionar que esse treinamento está sendo realizado em um ambiente de nuvem com uma GPU, o que torna o processo geral de treinamento mais rápido. No entanto, o treinamento em um computador local exigiria mais tempo para ser concluído.
Nosso blog, Pros and Cons of Using LLMs in the Cloud Versus Running LLMs Locally (Prós e contras do uso de LLMs na nuvem versus a execução de LLMs localmente), fornece considerações importantes para selecionar a estratégia de implementação ideal para LLMs
Vamos entender o que está acontecendo no trecho de código acima:
- tokenizer.pad_token = tokenizer.eos_token: Define o token de preenchimento como sendo o mesmo que o token de fim de frase.
- model.resize_token_embeddings(len(tokenizer)): Redimensiona a camada de incorporação de tokens do modelo para corresponder ao comprimento do vocabulário do tokenizador.
- model = prepare_model_for_int8_training(model): Prepara o modelo para treinamento com precisão INT8, provavelmente realizando a quantização.
- model = get_peft_model(model, lora_peft_config): Ajusta o modelo fornecido de acordo com a configuração do PEFT.
- training_args = model_training_args: Atribui argumentos de treinamento predefinidos a training_args.
- trainer = SFT_trainer: Atribui a instância do SFTTrainer à variável trainer.
- trainer.train(): Aciona o processo de treinamento do modelo de acordo com as especificações fornecidas.
Conclusão
Este artigo forneceu um guia claro sobre o treinamento de um modelo de linguagem grande usando o PyTorch. Começando com a preparação do conjunto de dados, ele percorreu as etapas de preparação dos pré-requisitos, configuração do instrutor e, por fim, execução do processo de treinamento.
Embora tenha usado um conjunto de dados específico e um modelo pré-treinado, o processo deve ser basicamente o mesmo para quaisquer outras opções compatíveis. Agora que você sabe como treinar um LLM, pode aproveitar esse conhecimento para treinar outros modelos sofisticados para várias tarefas de PNL.
Confira nosso guia sobre como criar aplicativos LLM com o LangChain para explorar ainda mais o poder dos grandes modelos de linguagem. Ou, se você ainda precisa explorar conceitos de modelos de linguagem grandes, confira nosso curso para aprofundar seu aprendizado.
