Les grands modèles de langage (LLM) sont des composants majeurs des applications modernes d'intelligence artificielle, en particulier pour le traitement du langage naturel. Ils ont le potentiel de traiter et de comprendre efficacement le langage humain, avec des applications allant des assistants virtuels à la traduction automatique, en passant par le résumé de texte et la réponse aux questions.
Des bibliothèques comme LangChain facilitent la mise en œuvre d'applications d'IA de bout en bout telles que celles mentionnées ci-dessus. Notre tutoriel Introduction à LangChain pour l'ingénierie des données et les applications de données donne un aperçu de ce que vous pouvez faire avec Langchain, y compris les problèmes que LangChain résout, ainsi que des exemples de cas d'utilisation des données.
Cet article explique tout le processus de formation d'un grand modèle de langage, de la configuration de l'espace de travail à l'implémentation finale en utilisant Pytorch 2.0.1, un cadre d'apprentissage profond dynamique et flexible qui permet une implémentation simple et claire du modèle.
Conditions préalables
Pour tirer le meilleur parti de ce contenu, il est important d'être à l'aise avec la programmation Python, d'avoir une compréhension de base des concepts d'apprentissage profond et des transformateurs, et d'être familier avec le framework Pytorch. Le code source complet sera disponible sur GitHub.
Avant de nous plonger dans l'implémentation de base, nous devons installer et importer les bibliothèques appropriées. De plus, il est important de noter que le script de formation est inspiré de ce dépôt de Hugging Face.
Installation de la bibliothèque
La procédure d'installation est détaillée ci-dessous :
Tout d'abord, nous utilisons l'instruction %%bash pour exécuter les commandes d'installation dans une seule cellule en tant que commande bash dans le carnet Jupyter.
- Trl: utilisé pour former des modèles de langage de transformateur avec l'apprentissage par renforcement.
- Peft utilise les méthodes PEFT (parameter-efficient fine-tuning) pour permettre une adaptation efficace du modèle pré-entraîné.
- Torch: une bibliothèque d'apprentissage automatique à code source ouvert largement utilisée.
- Datasets (ensembles de données) : permet de télécharger et de charger de nombreux ensembles de données d'apprentissage automatique.
Transformers : une bibliothèque développée par Hugging Face et livrée avec des milliers de modèles pré-entraînés pour une variété de tâches basées sur le texte telles que la classification, le résumé et la traduction.
%%bash
pip -q install trl
pip -q install peft
pip -q install torch
pip -q install datasets
pip -q install transformers
Ces modules peuvent maintenant être importés comme suit :
import torch
from trl import SFTTrainer
from datasets import load_dataset
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArgumentsChargement et préparation des données
Le jeu de données sur les alpagas, disponible gratuitement sur Hugging Face, sera utilisé pour cette illustration. L'ensemble de données comporte trois colonnes principales : instructions, entrées et sorties. Ces colonnes sont combinées pour générer une colonne de texte finale.
L'instruction de chargement de l'ensemble de données est donnée ci-dessous en indiquant le nom de l'ensemble de données qui nous intéresse, à savoir tatsu-lab/alpaca:
train_dataset = load_dataset("tatsu-lab/alpaca", split="train")
print(train_dataset)Nous pouvons constater que les données résultantes se trouvent dans un dictionnaire à deux clés :
- Caractéristiques: contient les principales colonnes des données
- Num_rows: correspond au nombre total de lignes dans les données

Structure de l'ensemble de données de formation
Les cinq premières lignes peuvent être affichées avec l'instruction suivante. Commencez par convertir le dictionnaire en un DataFrame pandas, puis affichez les lignes.
pandas_format = train_dataset.to_pandas()
display(pandas_format.head())
Cinq premières lignes de l'ensemble de données train_dataset
Pour une meilleure visualisation, nous allons imprimer les informations concernant les trois premières lignes, mais avant cela, nous devons installer la bibliothèque textwrap pour fixer le nombre maximum de mots par ligne à 50. La première instruction d'impression sépare chaque bloc par 15 tirets.
import textwrap
for index in range(3):
print("---"*15)
print("Instruction:
{}".format(textwrap.fill(pandas_format.iloc[index]["instruction"],
width=50)))
print("Output:
{}".format(textwrap.fill(pandas_format.iloc[index]["output"],
width=50)))
print("Text:
{}".format(textwrap.fill(pandas_format.iloc[index]["text"],
width=50)))
Détails des trois premières lignes
Modèle de formation
Avant de procéder à l'entraînement du modèle, nous devons mettre en place certaines conditions préalables :
- Modèle pré-entraîné : Nous utiliserons le modèle pré-entraîné Salesforce/xgen-7b-8k-base, disponible sur Hugging Face. Salesforce a formé cette série de LLM 7B nommée XGen-7B avec une attention dense standard sur jusqu'à 8K séquences pour jusqu'à 1,5T tokens.
- Tokenizer : Cela est nécessaire pour les tâches de symbolisation sur les données d'apprentissage. Le code pour charger le modèle pré-entraîné et le tokenizer est le suivant :
pretrained_model_name = "Salesforce/xgen-7b-8k-base"
model = AutoModelForCausalLM.from_pretrained(pretrained_model_name, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name, trust_remote_code=True)Configuration de la formation
L'entraînement nécessite quelques arguments et configurations d'entraînement, et les deux objets de configuration importants sont définis ci-dessous, une instance de TrainingArguments, une instance du modèle LoraConfig, et enfin le modèle SFTTrainer.
Arguments de formation
Il est utilisé pour définir les paramètres de l'apprentissage du modèle.
Dans ce scénario spécifique, nous commençons par définir la destination où le modèle formé sera stocké à l'aide de l'attribut output_dir avant de définir des hyperparamètres supplémentaires, tels que la méthode d'optimisation, learning rate, number of epochs, etc.
model_training_args = TrainingArguments(
output_dir="xgen-7b-8k-base-fine-tuned",
per_device_train_batch_size=4,
optim="adamw_torch",
logging_steps=80,
learning_rate=2e-4,
warmup_ratio=0.1,
lr_scheduler_type="linear",
num_train_epochs=1,
save_strategy="epoch"
)LoRAConfig
Les principaux arguments utilisés pour ce scénario sont le rang de la matrice de transformation de bas rang dans LoRA, qui est fixé à 16. Ensuite, le facteur d'échelle pour les paramètres supplémentaires dans LoRA est fixé à 32.
En outre, le taux d'abandon est de 0,05, ce qui signifie que 5 % des unités d'entrée seront ignorées au cours de la formation. Enfin, comme il s'agit d'une modélisation causale du langage, la tâche est donc initialisée avec l'attribut CAUSAL_LM.
SFTTrainer
Il s'agit de former le modèle à l'aide des données d'apprentissage, du tokenizer et d'informations supplémentaires telles que les modèles susmentionnés.
Étant donné que nous utilisons le champ de texte des données d'apprentissage, il est important d'examiner la distribution afin de déterminer le nombre maximal de tokens dans une séquence donnée.
import matplotlib.pyplot as plt
pandas_format['text_length'] = pandas_format['text'].apply(len)
plt.figure(figsize=(10,6))
plt.hist(pandas_format['text_length'], bins=50, alpha=0.5, color='g')
plt.title('Distribution of Length of Text')
plt.xlabel('Length of Text')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()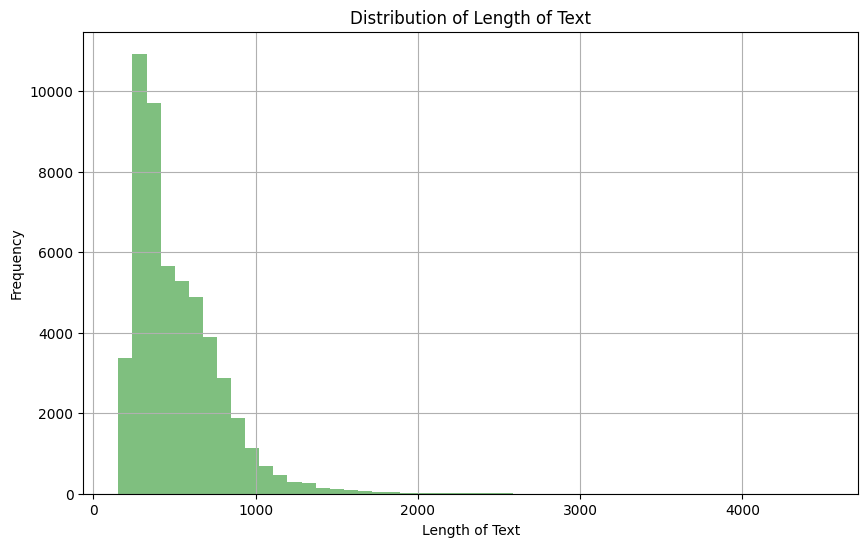
Distribution de la longueur de la colonne de texte
Sur la base de l'observation ci-dessus, nous pouvons constater que la majorité des textes ont une longueur comprise entre 0 et 1000. De même, nous pouvons voir ci-dessous que seulement 4,5 % des documents textuels ont une longueur supérieure à 1024.
mask = pandas_format['text_length'] > 1024
percentage = (mask.sum() / pandas_format['text_length'].count()) * 100
print(f"The percentage of text documents with a length greater than 1024 is: {percentage}%")

Nous fixons ensuite le nombre maximal de tokens dans la séquence à 1024, de sorte que tout texte plus long soit tronqué.
SFT_trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
dataset_text_field="text",
max_seq_length=1024,
tokenizer=tokenizer,
args=model_training_args,
packing=True,
peft_config=lora_peft_config,
)Exécution de la formation
Toutes les conditions préalables étant réunies, nous pouvons maintenant exécuter le processus de formation du modèle comme suit :
tokenizer.pad_token = tokenizer.eos_token
model.resize_token_embeddings(len(tokenizer))
model = prepare_model_for_int8_training(model)
model = get_peft_model(model, lora_peft_config)
training_args = model_training_args
trainer = SFT_trainer
trainer.train()Il est important de mentionner que cette formation est réalisée sur un environnement cloud avec un GPU, ce qui rend le processus de formation global plus rapide. Cependant, la formation sur un ordinateur local prendrait plus de temps.
Notre blog, Avantages et inconvénients de l'utilisation des LLM dans le cloud par rapport à l'exécution locale des LLM, fournit des considérations clés pour sélectionner la stratégie de déploiement optimale pour les LLM.
Comprenons ce qui se passe dans l'extrait de code ci-dessus :
- tokenizer.pad_token = tokenizer.eos_token: Définit le jeton de remplissage comme étant le même que le jeton de fin de phrase.
- model.resize_token_embeddings(len(tokenizer)): Redimensionne la couche d'intégration de jetons du modèle pour qu'elle corresponde à la longueur du vocabulaire du tokenizer.
- model = prepare_model_for_int8_training(model): Prépare le modèle pour l'entraînement avec une précision INT8, en effectuant probablement une quantification.
- model = get_peft_model(model, lora_peft_config): Ajuste le modèle donné en fonction de la configuration PEFT.
- training_args = model_training_args: Affecte des arguments de formation prédéfinis à training_args.
- trainer = SFT_trainer: Affecte l'instance SFTTrainer à la variable trainer.
- trainer.train(): Déclenche le processus de formation du modèle selon les spécifications fournies.
Conclusion
Cet article fournit un guide clair sur la formation d'un grand modèle de langage à l'aide de PyTorch. En commençant par la préparation de l'ensemble de données, il a parcouru les étapes de la préparation des conditions préalables, de la mise en place de l'unité didactique et, enfin, de l'exécution du processus de formation.
Bien qu'il utilise un ensemble de données spécifique et un modèle pré-entraîné, le processus devrait être largement le même pour toutes les autres options compatibles. Maintenant que vous savez comment former un LLM, vous pouvez exploiter ces connaissances pour former d'autres modèles sophistiqués pour diverses tâches de NLP.
Consultez notre guide sur la création d'applications LLM avec LangChain pour explorer davantage la puissance des grands modèles de langage. Ou, si vous avez encore besoin d'explorer les concepts de modèles de langage de grande taille, consultez notre cours pour approfondir votre apprentissage.
