
Kurs
Einführung in Docker
4 Std.
48.3K
Als ich anfing, als Machine Learning Engineer zu arbeiten, merkte ich schnell, dass das Erstellen von Modellen nicht die größte Herausforderung ist. Sie auf zuverlässige und skalierbare Weise einzusetzen war.
Damals lernte ich Kubernetes kennen, das Container-Orchestrierungstool, das in der Branche in aller Munde zu sein schien.
Am Anfang hatte ich Schwierigkeiten, die komplexe Architektur zu verstehen. Ich habe versucht, mehr zu lernen, indem ich Dokumentationen und Anleitungen zu Kubernetes gelesen habe, in denen die Grundlagen erklärt werden. Aber trotzdem war es für mich schwer zu verstehen.
Aber das änderte sich, als ich anfing, die Konzepte selbst umzusetzen. Indem ich meinen eigenen Kubernetes-Cluster einrichtete, mit verschiedenen Konfigurationen experimentierte und kleine Anwendungen einsetzte, begann ich langsam, die Zusammenhänge zu erkennen. Die praktische Erfahrung half mir, Vertrauen zu gewinnen, und ich verstand endlich, wie Kubernetes das Anwendungsmanagement im großen Maßstab vereinfachen kann.
Dieses Tutorial soll dir die gleiche praktische Erfahrung vermitteln. Egal, ob du ein Anfänger bist oder die Grundlagen vertiefen willst, dieser Leitfaden führt dich durch die Einrichtung eines lokalen Kubernetes-Clusters, die Bereitstellung von Anwendungen und die effiziente Verwaltung von Ressourcen.
Am Ende wirst du ein solides Verständnis der Kubernetes-Grundlagen haben und bereit sein, diese Fähigkeiten in realen Anwendungen anzuwenden!
Hier sind einige Voraussetzungen und Hilfsmittel, die du brauchst, um diesen Leitfaden durchzuarbeiten.
cd und ls und grundlegende Textbearbeitung mit nano oder vim.Willst du wissen, wie Kubernetes und Docker im Vergleich aussehen? Schau dir diese ausführliche Kubernetes vs. Kubernetes an. Docker-Vergleich um ihre Rolle in containerisierten Umgebungen zu verstehen.
Lass uns jetzt konkret werden und deinen lokalen Kubernetes-Cluster einrichten!
Aber was ist ein Kubernetes-Cluster? Ein Kubernetes-Cluster ist eine Sammlung von Knotenpunkten, die zusammenarbeiten, um deine Anwendungen auszuführen. Sie besteht aus zwei Komponenten:
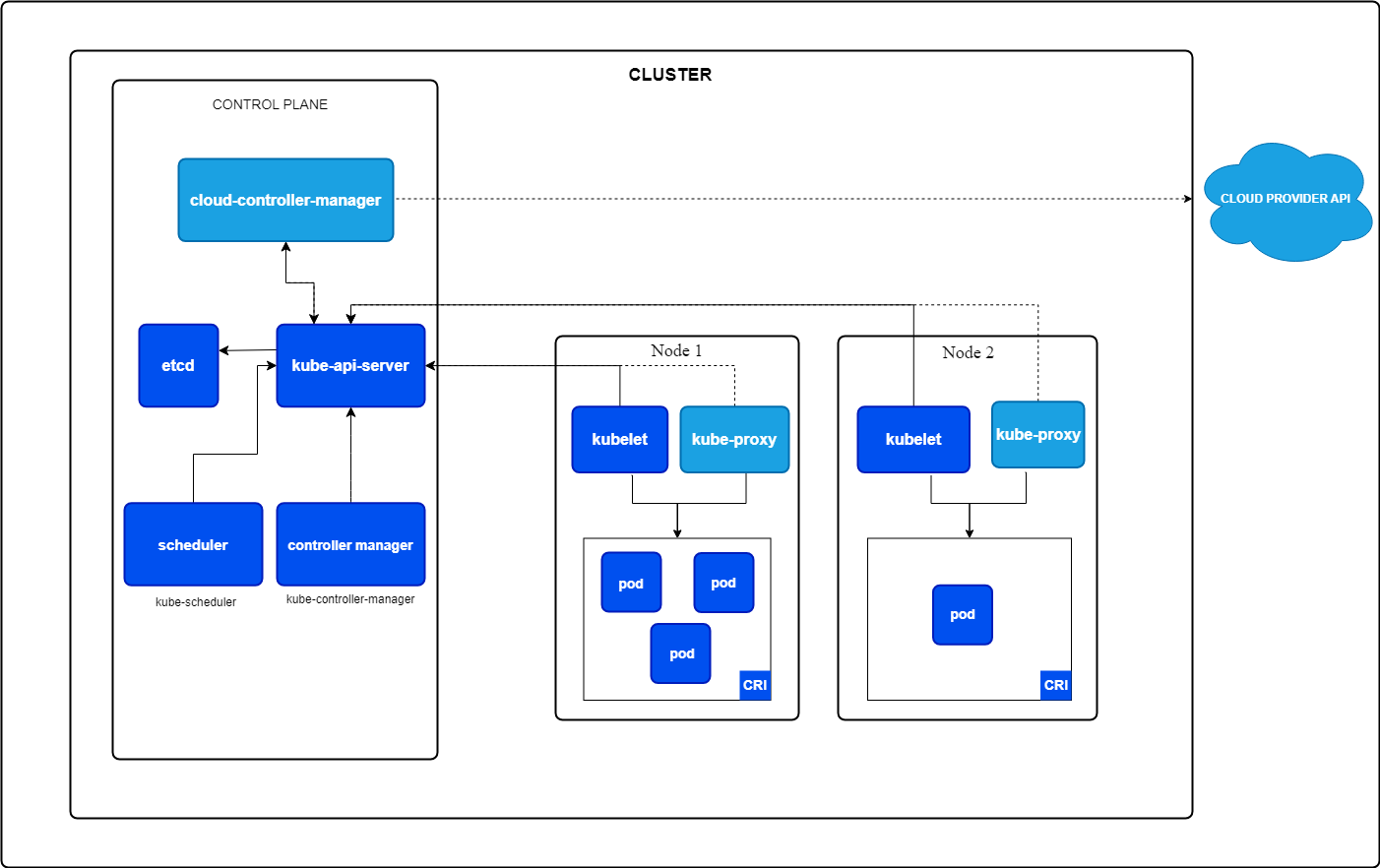
Kernkomponenten von Kubernetes. Bild von Kubernetes.io
Minikube kann auf Windows, Linux und MacOS installiert werden. Bitte befolge die Anweisungen im Abschnitt " Erste Schritte" in der offiziellen Minikube-Dokumentation.
Ich arbeite unter Windows, benutze aber WSL2, weil ich die Linux-Oberfläche bevorzuge. Wenn du WSL2 für deinen Windows-Rechner einrichten möchtest, lies bitte die Microsoft Installationsanleitung.
kubectl ist die Kommandozeilen-Schnittstelle zu deinen Kubernetes-Ressourcen. Du kannst es installieren, indem du der offiziellen Kubernetes-Dokumentation folgst oder die integrierte Installation in minikube nutzt.
Ich empfehle, die Installation mit Hilfe der offiziellen Kubernetes-Dokumentation durchzuführen, mit der du kubectl als eigenständigen Befehl verwenden kannst. Mit minikube musst du Befehle mit dem Präfix minikube ausführen.
Nachdem wir minikube installiert haben, können wir mit folgendem Befehl einen Cluster von einem Terminal mit Administratorrechten starten:
minikube startDieser Befehl zieht automatisch die benötigten Kubernetes-Binärdateien und startet einen Single-Node-Cluster für dich.
Wir können jetzt den Status des Clusters überprüfen, um zu sehen, ob alles wie erwartet läuft:
minikube statusDas Ergebnis sollte in etwa so aussehen:
minikube
type: Control Plane
host: Running
kubelet: Running
apiserver: Running
kubeconfig: ConfiguredJetzt können wir noch einen Schritt weiter gehen und mit kubectl alle Knoten unseres Clusters abrufen, von denen es nur einen geben sollte:
kubectl get nodes Der obige Befehl sollte etwas Ähnliches wie das Folgende ergeben:
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane 10m v1.32.0Wenn du den Cluster stoppen möchtest, um Ressourcen freizugeben, wenn er nicht benötigt wird, kannst du diesen Befehl ausführen:
bash
minikube stopStarte sie einfach wieder, wenn du das nächste Mal mit Kubernetes weiterarbeiten willst.
Wenn du deinen Minikube-Cluster und alle zu ihm hinzugefügten Ressourcen vollständig löschen möchtest, kannst du diesen Befehl ausführen:
minikube deleteNachdem wir nun einen Cluster eingerichtet und überprüft haben, dass alles funktioniert, ist es an der Zeit, unsere erste Anwendung zu erstellen.
Doch bevor du die erste Anwendung erstellst, musst du die Grundlagen von Kubernetes verstehen. Wenn du eine tiefer gehende Einführung in Kubernetes möchtest, empfehle ich dir den Kurs Einführung in Kubernetes .
Die grundlegendsten Konzepte in Kubernetes sind Pods, Deployments und Services. Die Kenntnis dieser drei Ressourcentypen kann dir helfen, leistungsfähige Anwendungen zu erstellen. Deshalb wollen wir sie genauer unter die Lupe nehmen.
Ein Pod ist die kleinste einsatzfähige Einheit in Kubernetes. Er betreibt einen oder mehrere eng gekoppelte Container mit demselben Speicher, Netzwerk und Namespace. Ein Pod wird immer auf einem Kubernetes-Knoten geplant.
Du kannst festlegen, wie viele Ressourcen dein Pod erhalten soll (z. B. CPU und Speicher).
Eine Beispielanwendung mit zwei Containern könnte dein Anwendungscontainer und ein Hilfscontainer sein, der die Logs sammelt und sie irgendwo hinschickt.
Merkmale eines Pods:
Beispiel YAML für die Erstellung eines Pods:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: nginx-container
image: nginx:1.21
ports:
- containerPort: 80Du kannst den Pod dann mit kubectl installieren:
kubectl apply -f pod.yamlDies würde einen Pod namens my-pod starten, der einen nginx Webserver für dich betreibt.
Ein Deployment ist ein übergeordnetes Kubernetes-Objekt, das für die Verwaltung des Lebenszyklus von Pods verwendet wird. Er stellt sicher, dass die gewünschte Anzahl von Pod-Replikaten läuft und kümmert sich um Updates und Rollbacks.
Merkmale eines Einsatzes:
Schauen wir uns an, wie eine Deployment YAML-Datei aussehen würde, die wieder einen nginx-Webserver erstellt, aber diesmal mit drei Repliken:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80Du kannst dieses Deployment mit kubectl installieren:
kubectl apply -f deployment.yamlDamit wird ein Deployment mit dem Namen nginx-deployment erstellt, das drei Pods erzeugt, auf denen jeweils der nginx-Container läuft.
Jetzt kommen wir zum letzten Teil: Die Dienstleistungen.
Ein Dienst ist eine Abstraktion, die einen stabilen Netzwerkzugang zu Pods bietet, auch wenn sich ihre IP-Adressen ändern. Sie fungiert als Brücke zwischen deinen Anwendungen und externen Clients.
Aber warum ist das notwendig? Jeder Pod hat eine eigene IP-Adresse. Warum können wir diese IP-Adresse also nicht direkt verwenden?
Wir können! Aber das sollten wir nicht. Und warum?
Da ein Pod kurzlebig ist, wird er durch das Deployment getötet und ein neuer Pod wird hochgezogen, wenn dein Pod ungesund ist. Dieser neue Pod hat dann eine andere IP-Adresse. Das würde bedeuten, dass der Client, der deine Anwendung nutzen möchte, die IP-Adresse permanent ändern müsste, wenn ein Pod abstürzt, was häufig vorkommen kann.
Hier kommt ein Dienst ins Spiel: Er sucht nach allen Pods, die einem bestimmten Label entsprechen, und leitet den Datenverkehr automatisch an sie weiter. Wenn ein Pod ungesund wird, hört der Dienst auf, Verkehr an diesen Pod zu senden. Und wenn ein neuer Pod auftaucht, wird der Verkehr an den neuen Pod weitergeleitet.
Der Dienst verteilt außerdem den Datenverkehr auf alle Replikate deines Deployments. Das ist fantastisch, denn das bedeutet, dass du mehr Instanzen deiner Anwendung erstellen kannst, um den Datenverkehr zu verteilen, ohne dass du das über deine Anwendungslogik steuern musst.
Arten von Dienstleistungen:
Beispiel YAML, um unseren nginx Webserver außerhalb des Clusters zu zeigen:
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: NodePortDu kannst diesen Dienst wieder mit kubectl erstellen:
kubectl apply -f service.yamlDieser Dienst würde nun den eingehenden Verkehr an alle Pods mit dem Label app=nginx auf Port 80 verteilen.
Wenn du einen describe Befehl für deinen neu erstellten Dienst ausführst, solltest du sehen, dass es jetzt drei Endpunkte gibt, wobei jeder Endpunkt die IP-Adresse des Pods darstellt, der gerade läuft:
kubectl describe service nginx-serviceDer obige Befehl sollte etwas ähnliches zurückgeben wie:
Name: nginx-service
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=nginx
Type: NodePort
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.104.53.131
IPs: 10.104.53.131
Port: <unset> 80/TCP
TargetPort: 80/TCP
NodePort: <unset> 32256/TCP
Endpoints: 10.244.0.5:80,10.244.0.6:80,10.244.0.7:80
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>Also, um es kurz zusammenzufassen:
Mit Namespaces in Kubernetes kannst du Ressourcen innerhalb eines Clusters organisieren und isolieren. Du kannst sie dir als virtuelle Cluster innerhalb desselben physischen Clusters vorstellen.
Vorteile der Verwendung von Namespaces:
Standardmäßig verfügt Kubernetes über einige eingebaute Namespaces:
Du kannst einen Namespace mit einer YAML-Datei erstellen:
apiVersion: v1
kind: Namespace
metadata:
name: my-namespaceSpeichere sie in einer Datei namens namespace.yaml und wende sie mit an:
kubectl apply -f namespace.yamlWenn du den unten stehenden Befehl ausführst, solltest du eine Liste aller aufgelisteten Standard-Namespaces und des neu erstellten Namespaces sehen:
kubectl get namespacesDu kannst dann Ressourcen in diesem Namespace erstellen, indem du den Namespace einfach im Metadatenbereich deiner Ressource angibst.
Unser nginx Deployment würde wie folgt aussehen, wenn wir es in deinem neu erstellten Namespace erstellen wollen:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: my-namespace
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80Jetzt musst du explizit angeben, dass du Ressourcen aus deinem neu erstellten Namespace abrufen willst, indem du dasArgument -n verwendest:
kubectl get deployment -n my-namespaceOk, jetzt, wo du mit den grundlegenden Konzepten von Kubernetes vertraut bist, ist es an der Zeit, unsere erste Webanwendung in Kubernetes zu implementieren und zu versuchen, darauf zuzugreifen.
In diesem Kapitel werden wir einen nginx-Webserver erstellen, diesen Webserver über einen Dienst der Außenwelt zur Verfügung stellen, die Anwendung skalieren, um ein hohes Verkehrsaufkommen zu simulieren, und die Anwendung mit einem Rolling Update auf eine neuere Version aktualisieren.
Also, lass uns anfangen, lustige Sachen zu machen!
Der erste Schritt besteht darin, ein Deployment für unseren Webserver zu erstellen, das einen Container mit dem Nginx-Image erzeugt.
Kopiere den folgenden Code und speichere ihn in einer Datei namens nginx-deployment.yaml.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80Dann wendest du dieses Deployment mit dem folgenden Befehl auf deinen Cluster an:
kubectl apply -f nginx-deployment.yamlDu kannst dann überprüfen, ob der Pod läuft:
kubectl get podsWir müssen den nginx-Webserver über einen Dienst nach außen hin sichtbar machen. Hierfür erstellen wir einen Dienst vom Typ NodePort, da wir von unserem lokalen Rechner außerhalb des Kubernetes-Clusters auf den nginx-Webserver zugreifen wollen.
Erstelle also eine Datei namens nginx-service.yaml und füge den folgenden Inhalt hinzu:
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: NodePortDu kannst den Dienst dann mit dem folgenden Befehl anwenden:
kubectl apply -f nginx-service.yamlZu guter Letzt kannst du minikube verwenden, um die URL zu deinem nginx-Webserver zu erhalten:
minikube service nginx-service --urlÖffne diese URL in deinem Browser und du solltest die Willkommensseite deines nginx-Webservers sehen.
Screenshot der Willkommensseite eines nginx-Webservers in einem lokalen Browser.
Wir haben also einen Pod in Betrieb. Aber es kann sein, dass eine große Anzahl von Nutzern unsere Webseite besucht. Deshalb kannst du in Kubernetes deine Anwendung schnell skalieren, um mehr Pods in Betrieb zu haben.
Der Dienst erkennt automatisch alle Pods, die zu diesem Einsatz gehören, und verteilt dann die eingehenden Anfragen auf alle Pods, auf denen der nginx-Webserver läuft. Das hilft, die Gesamtleistung unserer Webseite zu verbessern, wenn viel Traffic hereinkommt.
Skalieren wir also unsere Anwendung mit dem folgenden Befehl auf 3 Replikate:
kubectl scale deployment nginx-deployment --replicas=3Du kannst jetzt wieder alle laufenden Pods bekommen, das sollten drei sein:
kubectl get podsDu kannst auch den folgenden Befehl verwenden, um alle Endpunkte abzurufen, mit denen unsere nginx-service verbunden ist. Dies sollte drei Endpunkte zurückgeben, wobei jeder Endpunkt eine eigene interne Cluster-IP-Adresse hat:
kubectl get endpoints nginx-serviceJetzt haben wir einen weiteren großen Vorteil von Kubernetes: Laufende Updates.
Ein Rolling Update zielt darauf ab, jegliche Ausfallzeiten deiner Webanwendung zu vermeiden. Stell dir nur den finanziellen Verlust für Unternehmen wie Amazon vor, wenn ihre Webseite jedes Mal, wenn Amazon eine neue Version herausbringt, nicht erreichbar wäre.
Bei einem Rolling Update skaliert Kubernetes einen neuen Pod hoch, prüft, ob dieser gesund ist, und skaliert dann den alten Pod herunter.
Standardmäßig stellt Kubernetes sicher, dass mindestens 75 % der gewünschten Anzahl von Pods einsatzbereit sind, wobei 25 % die maximale Zahl der nicht verfügbaren Pods ist. Das bedeutet, dass Kubernetes in unserem Fall, in dem wir drei Replikate in Betrieb haben, jeweils nur einen neuen Pod hinzufügt, prüft, ob dieser gesund ist, und wenn ja, einen anderen Pod herunterskaliert. Dieser Vorgang wird wiederholt, bis alle Pods auf die neue Version aktualisiert sind.
Ändern wir also die Version unseres nginx-Images von latest auf 1.23:
kubectl set image deployment/nginx-deployment nginx=nginx:1.23Du kannst dann den Status des Rollouts mit überwachen:
kubectl rollout status deployment/nginx-deploymentDie Ausgabe sollte ungefähr so aussehen:
Waiting for deployment "nginx-deployment" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "nginx-deployment" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "nginx-deployment" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "nginx-deployment" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "nginx-deployment" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "nginx-deployment" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "nginx-deployment" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "nginx-deployment" rollout to finish: 1 old replicas are pending termination...
deployment "nginx-deployment" successfully rolled outUnd während der Rollout läuft, ist deine Webseite die ganze Zeit über zugänglich, ohne dass es zu Ausfallzeiten kommt!
Ist das nicht toll?
Kubernetes bietet leistungsstarke Werkzeuge, um Ressourcen aller Art zu prüfen, zu ändern und zu löschen. Wenn du weißt, wie du Ressourcen effektiv verwalten kannst, kannst du die Fehlerbehebung, die Ressourcenzuweisung und die Wartung des Clusters insgesamt verbessern.
In diesem Abschnitt gehen wir auf weitere wichtige Befehle ein, die dir helfen, deine Ressourcen effektiv zu verwalten und Probleme zu beheben.
Bevor du eine Ressource änderst, ist es wichtig, dass du dir die aktuell laufenden Ressourcen in deinem Cluster ansiehst und überprüfst.
Du kannst z.B. alle laufenden Pods, Dienste und Einsätze auflisten, um zu sehen, was in deinem Cluster vor sich geht:
# list running Pods
kubectl get pods
# list running Services
kubectl get services
# list running Deployments
kubectl get deploymentsWenn du tiefer in eine bestimmte Ressource eindringen willst, kannst du denBefehl describe verwenden:
kubectl describe deployment nginx-deploymentHier werden weitere Informationen angezeigt, z. B. rollierende Aktualisierungen, Skalierung oder Bildzugriffsereignisse. Das ist die erste Anlaufstelle, die du aufsuchen kannst, wenn etwas schief läuft.
Du kannst auch die Logs eines laufenden Pods überprüfen, um zu sehen, was in diesem Pod vor sich geht, indem du den folgenden Befehl verwendest:
kubectl logs <pod-name>Es ist auch wichtig, Ressourcen zu bereinigen, wenn sie nicht mehr gebraucht werden, um Cluster-Ressourcen für neue Anwendungen freizugeben.
Du kannst einen Pod mit löschen:
kubectl delete pod <pod-name>Wir können dies für einen unserer Nginx-Pods tun. Ein neuer Pod sollte jedoch sofort hochskaliert werden, da er über ein Deployment verwaltet wird, das immer versucht, drei Replikate in Betrieb zu nehmen.
Hier müssten wir also die nginx-deployment löschen:
kubectl delete deployment nginx-deploymentNachdem du diesen Befehl ausgeführt hast, sollten alle laufenden nginx Pods gelöscht werden.
Wir können auch alle Ressourcen in einem Namespace löschen. Der folgende Befehl würde alle unsere Ressourcen löschen, diestandardmäßig im default Namespace erstellt wurden:
kubectl delete all --allHerzlichen Glückwunsch! Du hast das Ende erreicht und erfolgreich deine ersten Schritte in Kubernetes gemacht.
In diesem Tutorial hast du gelernt, wie man:
Kubernetes kann anfangs sehr komplex erscheinen (zumindest war das bei mir so). Aber wenn man es in grundlegende Konzepte zerlegt, ist es leichter zugänglich.
Experimentiere weiter und setze mehr Anwendungen ein.
Kubernetes lernt man am besten, indem man etwas tut, also fang an zu bauen!
Um deine Kubernetes-Kenntnisse weiter zu verbessern, solltest du dich mit dem Thema beschäftigen:
Der Lernpfad "Containerisierung und Virtualisierung mit Docker und Kubernetes " auf dem DataCamp ist eine hervorragende Ressource, um mit Docker und Kubernetes zu üben.
Lerne in diesen Kursen mehr über Docker und Kubernetes!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
