
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
n8n hat sich in der agentischen KI als beliebtes, leistungsstarkes Framework etabliert. Damit lassen sich automatisierte Workflows ohne komplexes Coding aufsetzen.
In diesem Artikel zeige ich dir Schritt für Schritt, wie du diese robuste Plattform optimal nutzt, um zwei unterschiedliche Prozesse zu automatisieren:
Wir halten unsere Leser mit The Median auf dem Laufenden: Unser kostenloser Freitags-Newsletter ordnet die wichtigsten KI-News der Woche ein. Abonniere ihn und bleib in wenigen Minuten pro Woche auf dem Laufenden:
n8n ist ein Open-Source-Automatisierungstool, das verschiedene Apps und Services verbindet, um Workflows zu erstellen – wie ein digitales Fließband. User können diese Workflows visuell mit Nodes entwerfen, die jeweils einen Prozessschritt abbilden.
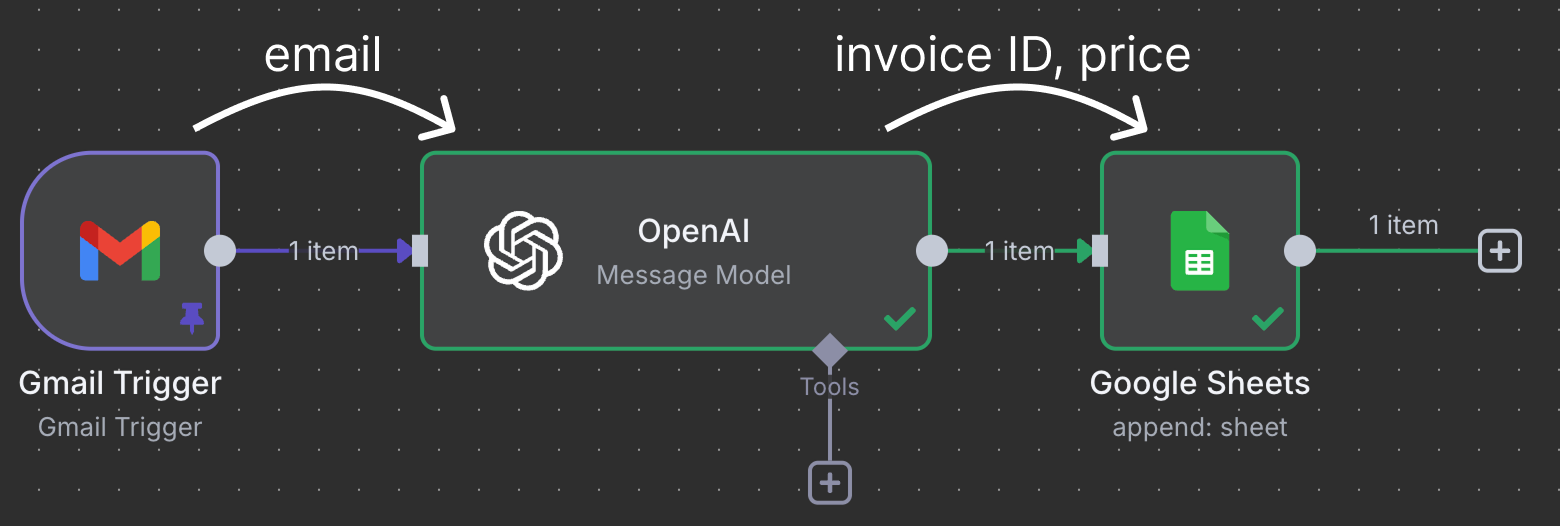
Mit n8n lassen sich Aufgaben automatisieren, Datenflüsse steuern und sogar APIs integrieren – ohne umfangreiche Programmierkenntnisse. Hier ein Beispiel für eine Automation, die wir in diesem Tutorial bauen:
Ohne ins Detail zu gehen, macht diese Automation Folgendes:
Es gibt zwei Wege, n8n zu nutzen:
Mit beiden Optionen kannst du diesem Tutorial kostenlos folgen. Wir nutzen die lokale Variante, aber die Schritte sind in der Weboberfläche identisch.
Hinweis: n8n 2.0 erschien Ende 2025 und brachte ein Draft/Publish-Workflowsystem, Autosave (Januar 2026), ein überarbeitetes Focus Panel zum Bearbeiten von Nodes ohne Canvas-Kontextverlust sowie Task Runners, die die Workflow-Ausführung zur besseren Sicherheit isolieren.
Die folgenden Workflows laufen auf 2.x — wenn du noch 1.x nutzt, solltest du vorab ein Upgrade in Betracht ziehen.
Das offizielle n8n-Repository erklärt, wie du n8n lokal aufsetzt. Am einfachsten geht es so:
Lade Node.js von der offiziellen Website herunter und installiere es.
Öffne ein Terminal und führe den Befehl npx n8n aus.
Das war’s! Nach dem Befehl solltest du im Terminal Folgendes sehen:
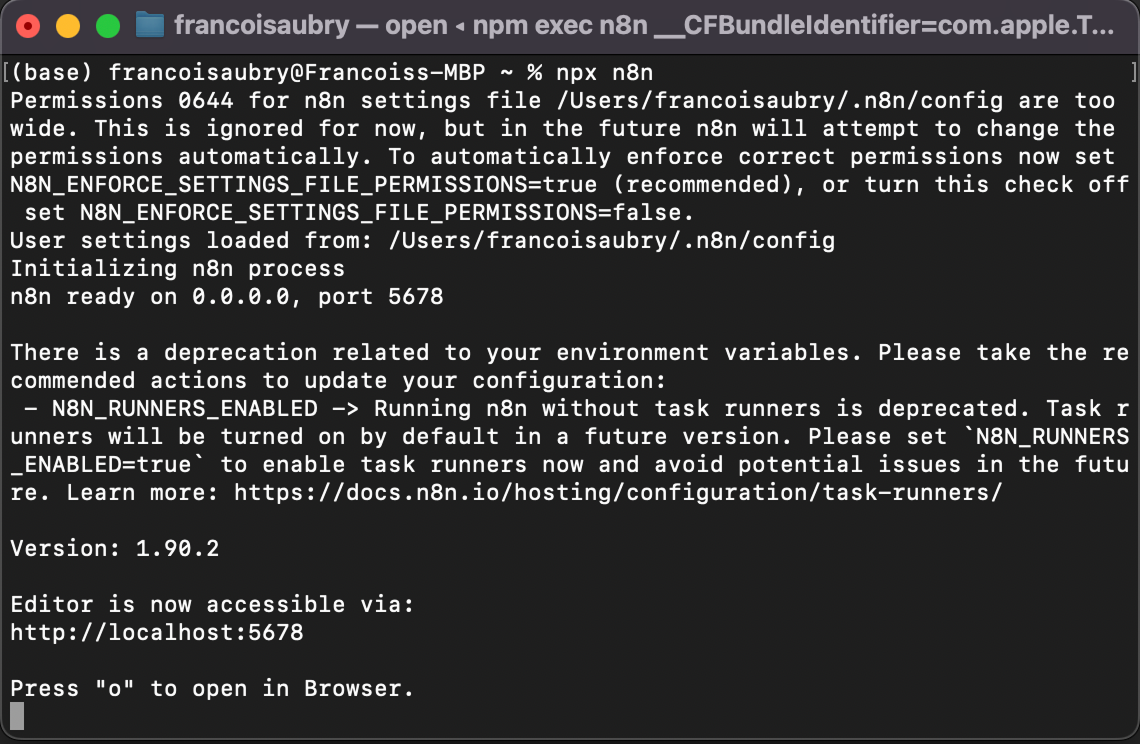
Zum Öffnen der Oberfläche drücke entweder die Taste "o" oder öffne die im Terminal angezeigte Localhost-URL — in meinem Fall http://localhost:5678.
Bevor wir die erste Automation bauen, ist es hilfreich zu verstehen, wie n8n funktioniert. Ein n8n-Workflow besteht aus einer Abfolge von Nodes. Er beginnt mit einem Trigger-Node, der die Bedingung für die Ausführung des Workflows festlegt.
Nodes werden verbunden, um Daten zu bewegen und zu verarbeiten. In diesem Beispiel verbindet sich der Gmail-Trigger-Node mit einem OpenAI-Node. Das bedeutet: Die E-Mail wird zur Verarbeitung an ChatGPT übergeben. Abschließend wird die Ausgabe von ChatGPT an einen Google-Sheet-Node gesendet, der sich mit einem Google Sheet in unserem Google Drive verbindet und eine neue Zeile in die Tabelle schreibt.
Dieser Workflow nutzt ChatGPT, um Rechnungen zu identifizieren, die bezahlt werden müssen, und trägt die Rechnungs-ID sowie den Betrag in die Tabelle ein.
n8n-Workflows können deutlich komplexer werden. n8n unterstützt über 400 offizielle Integrationen (Core Nodes), dazu 600+ Community-Nodes sowie eigene Anbindungen über den HTTP-Request-Node — das sprengt den Rahmen eines Tutorials.
Stattdessen bekommst du ein generelles Verständnis und genug Hintergrund, um selbst weiter zu erkunden. Wenn du ein Tool regelmäßig nutzt, stehen die Chancen gut, dass n8n es bereits unterstützt oder du es manuell integrieren kannst.
In diesem Abschnitt bauen wir den oben gezeigten Workflow.
Das ist ein echtes Use Case, mit dem ich meine Mietnebenkosten-Rechnungen verwalte. Ich habe ein Haus mit einigen Zimmern, die ich vermiete. Die Kosten werden gleichmäßig auf alle Mieter aufgeteilt. Jedes Mal, wenn ich eine Rechnung erhalte, muss ich den Gesamtbetrag in eine geteilte Tabelle eintragen.
Dafür nutze ich eine spezielle E-Mail-Adresse, an die Rechnungen rund um Hauskosten weitergeleitet werden. So weiß ich: Alle Mails in diesem Postfach sind Rechnungen. Den Inhalt der E-Mail schicke ich an ChatGPT, um die Rechnungs-ID und den Gesamtbetrag zu erkennen. Anschließend wird diese Information als neue Zeile in der geteilten Tabelle gespeichert.
Um einen neuen Workflow zu starten, klicken wir auf die Schaltfläche "Add first step...".

Weil es der erste Node ist, muss es ein Trigger sein. Daher erscheint ein Panel zur Auswahl eines Trigger-Nodes. Ein Trigger-Node definiert die Bedingungen, unter denen der Workflow ausgeführt wird.
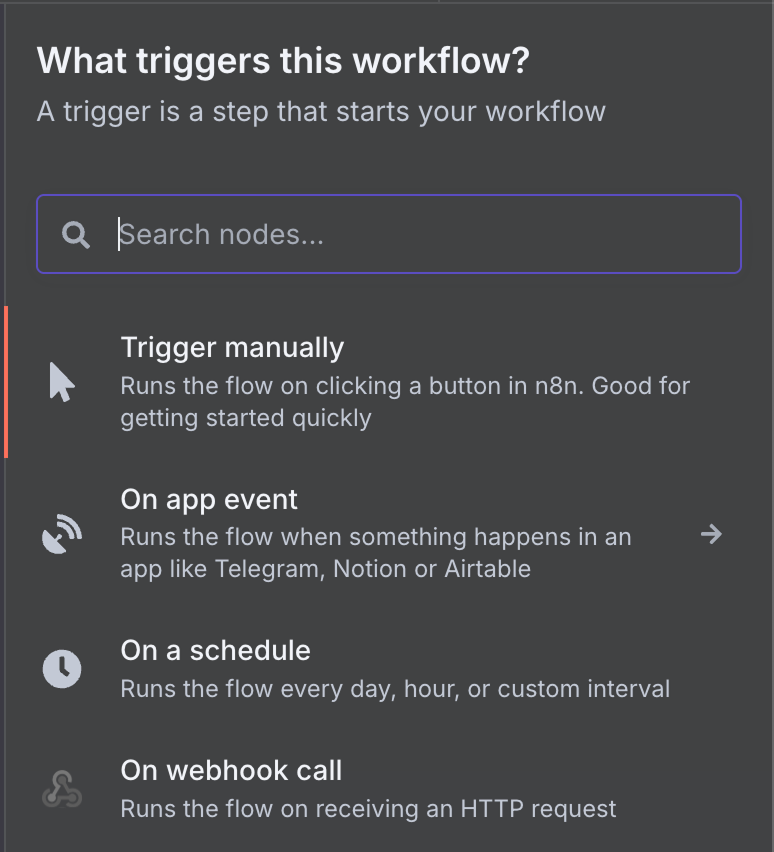
Es gibt eine große Auswahl an Trigger-Nodes. Wähle den Gmail-Trigger, indem du "gmail" in die Suche eingibst und auf den Gmail-Node klickst.
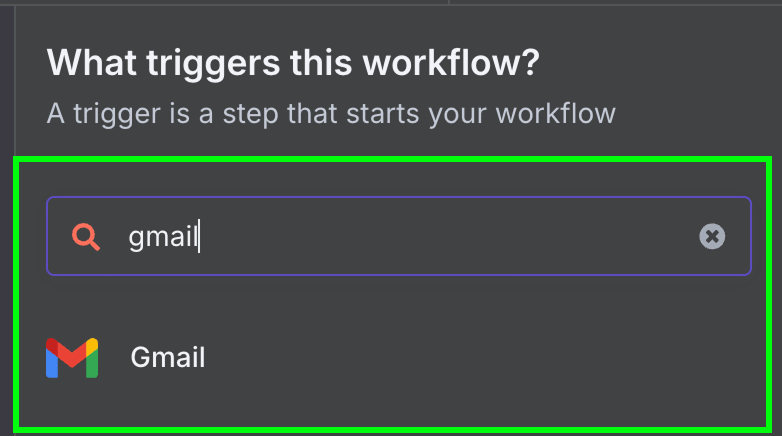
Dann wählen wir den einzigen verfügbaren Gmail-Trigger: "On message received".

Daraufhin öffnet sich das Konfigurationspanel des Nodes. Hier müssen wir unsere Gmail-Zugangsdaten hinterlegen, damit der n8n-Workflow auf unser Gmail-Konto zugreifen kann. Klicke dazu auf "New credential". Es öffnet sich folgendes Fenster:
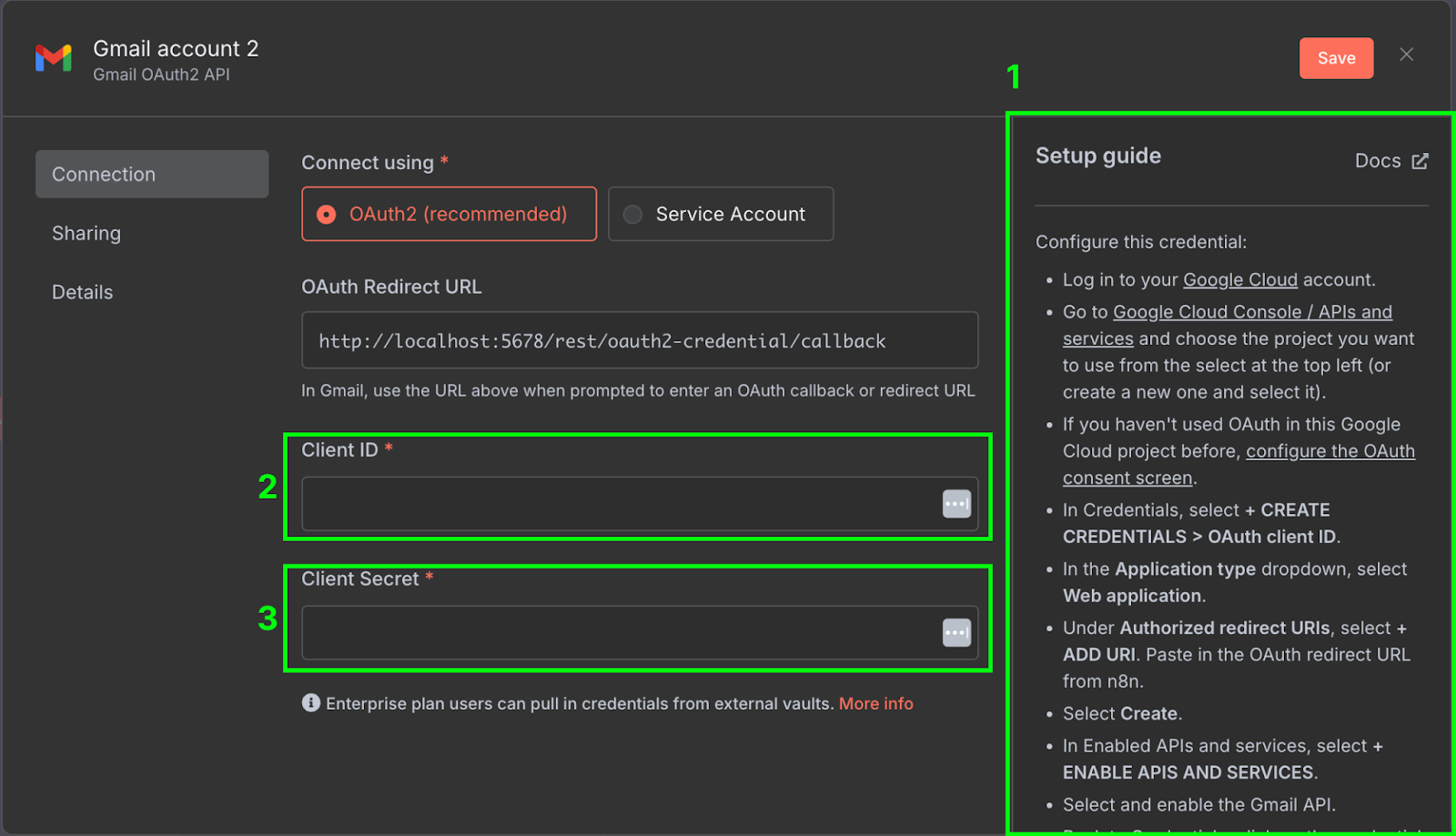
Rechts (1) gibt es eine Anleitung mit den nötigen Schritten zur Einrichtung der Credentials in der Google Cloud. Die n8n-Guides sind sehr ausführlich, daher wiederholen wir sie hier nicht. Aktiviere außerdem die Gmail API in der Google Cloud Console.
Sobald alles eingerichtet ist, kopieren wir die Client-ID (2) und das Client-Secret (3) aus der Google Cloud in die Credential-Konfiguration von n8n.
Um zu prüfen, ob alles korrekt konfiguriert ist, testen wir den Node mit "Fetch Test Event".

Nach dem Test sollten wir im Output die zuletzt empfangene E-Mail aus unserem Posteingang sehen. Der Inhalt der E-Mail steht im Feld snippet.
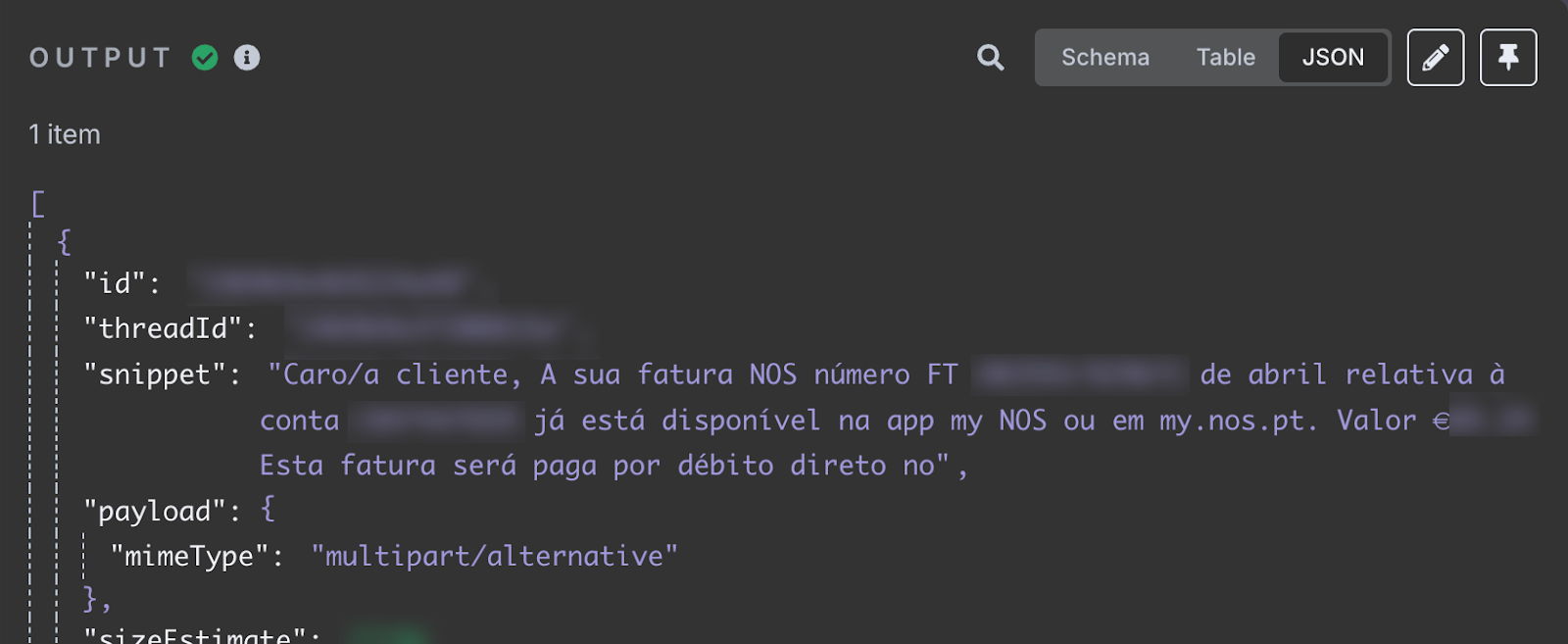
Das Feld snippet enthält den E-Mail-Text. Hier steht, dass meine Internetrechnung für April vorliegt – inklusive Rechnungs-ID und Gesamtbetrag. Genau diese Infos wollen wir in die Tabelle übernehmen.
Zum Testen empfehle ich, das Ergebnis zu pinnen – über die Pinnnadel oben rechts:
Damit wird dieses Trigger-Ergebnis fixiert. Bei jedem Lauf wird also derselbe Output genutzt, was das Testen erleichtert, da neue E-Mails das Ergebnis nicht verändern. Wir lösen das Pinning wieder, sobald der Workflow sauber steht.
An diesem Punkt hat unser Workflow nur einen Trigger-Node (zu erkennen am kleinen Blitzsymbol links).

Beachte: Da du wahrscheinlich keine echte Rechnungs-Mail im Postfach hast, liefert ChatGPT später womöglich unpassende Antworten. Wenn du exakt diesen Workflow testen willst, schicke dir selbst eine Testmail mit folgendem Inhalt (oder ähnlich):
Dear customer,
Your internet invoice number FT 2025**/****** for April is now available in the attachment.
Amount
€**.**
This invoice must be paid by 19/05/2025.Danach musst du das Ergebnis entpinnen, den Gmail-Node erneut ausführen und das neue Ergebnis pinnen.
Als Nächstes konfigurieren wir den OpenAI-Node. Klicke auf das "+" rechts neben dem Gmail-Trigger-Node:

Gib "OpenAI" ein und wähle die entsprechende Option aus der Liste.
Wähle unter "Text Actions" den Node "Message a model". Damit sendest du Nachrichten an ein LLM.

Wie zuvor brauchen wir ein Credential für den Zugriff auf OpenAI. Einmal erstellt, kann es in jedem Workflow wiederverwendet werden.
Für das OpenAI-Credential benötigen wir nur einen API-Schlüssel. Falls du noch keinen hast, kannst du ihn hier erstellen. Bei Problemen stellt n8n dazu ebenfalls eine Anleitung bereit.
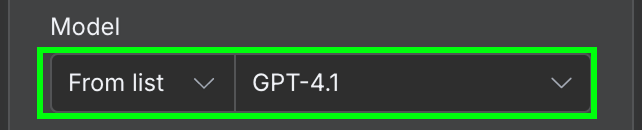
In der Konfiguration wählen wir das KI-Modell und die Nachricht, die wir an das Modell senden.
Als Modell verwenden wir GPT-4.1. OpenAI hat inzwischen die GPT-5-Familie (5.4, 5.4-mini, 5.5) veröffentlicht und 4.1 aus ChatGPT entfernt, aber über die API ist es weiterhin verfügbar und für einfache Extraktion wie hier völlig ausreichend.
Im Nachrichtenfeld formulieren wir den Prompt. Für dieses Beispiel geben wir dem Modell den E-Mail-Inhalt und bitten es, Rechnungs-ID und Gesamtbetrag zu identifizieren. Das ist der Prompt, den ich genutzt habe:
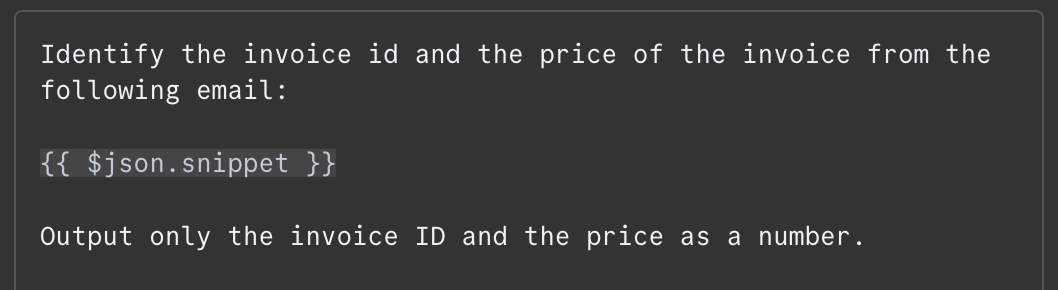
Der E-Mail-Inhalt wird als {{ $json.snippet }} übergeben. In n8n können Prompts Variablen enthalten, die aus dem Output vorheriger Nodes befüllt werden – hier aus der E-Mail. Die verfügbaren Felder siehst du links. Du kannst sie eintippen oder per Drag-and-drop in den Prompt ziehen.
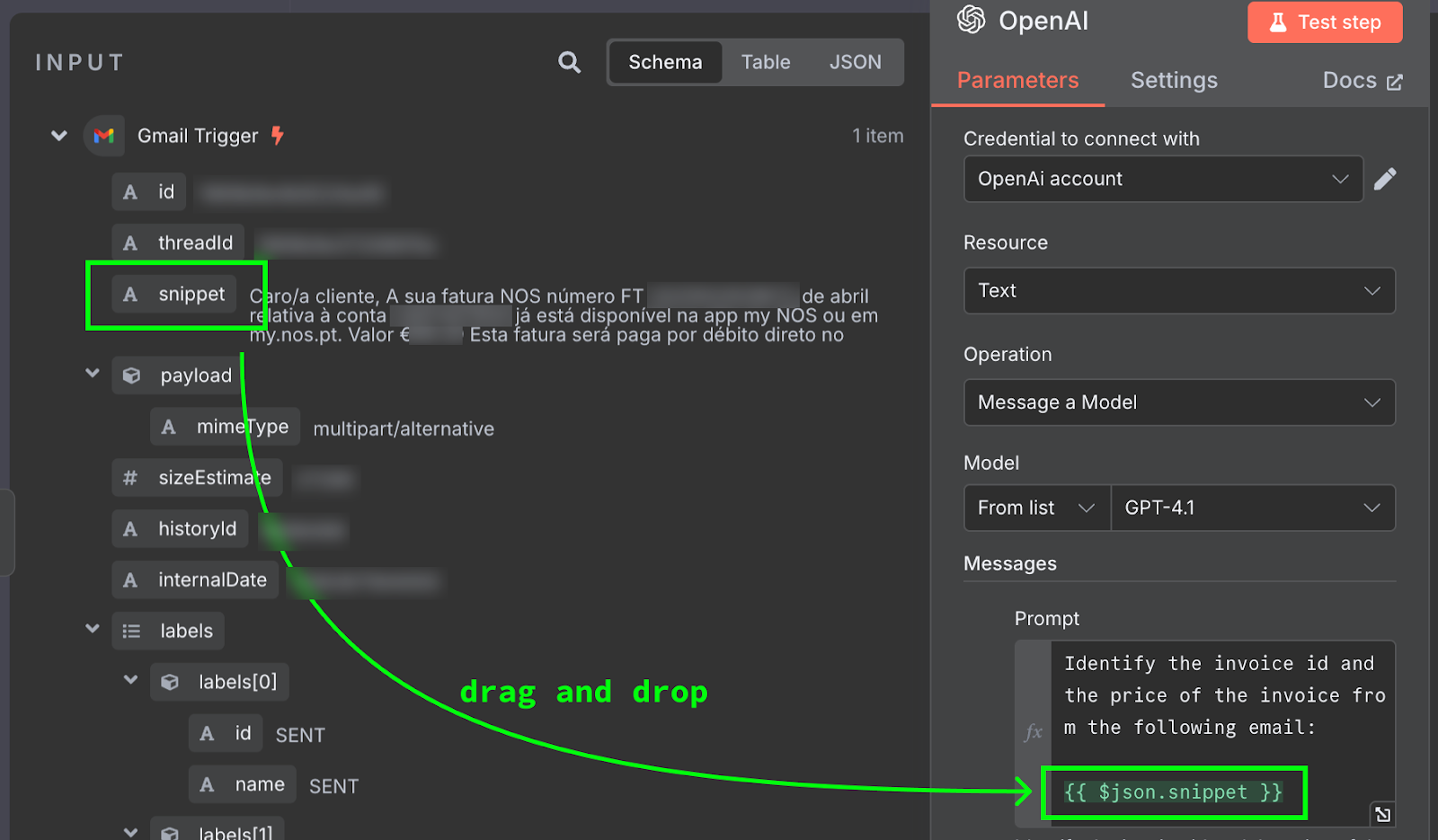
Zum Testen klicken wir oben im Konfigurationspanel auf "Test Step". Das Ergebnis erscheint rechts:
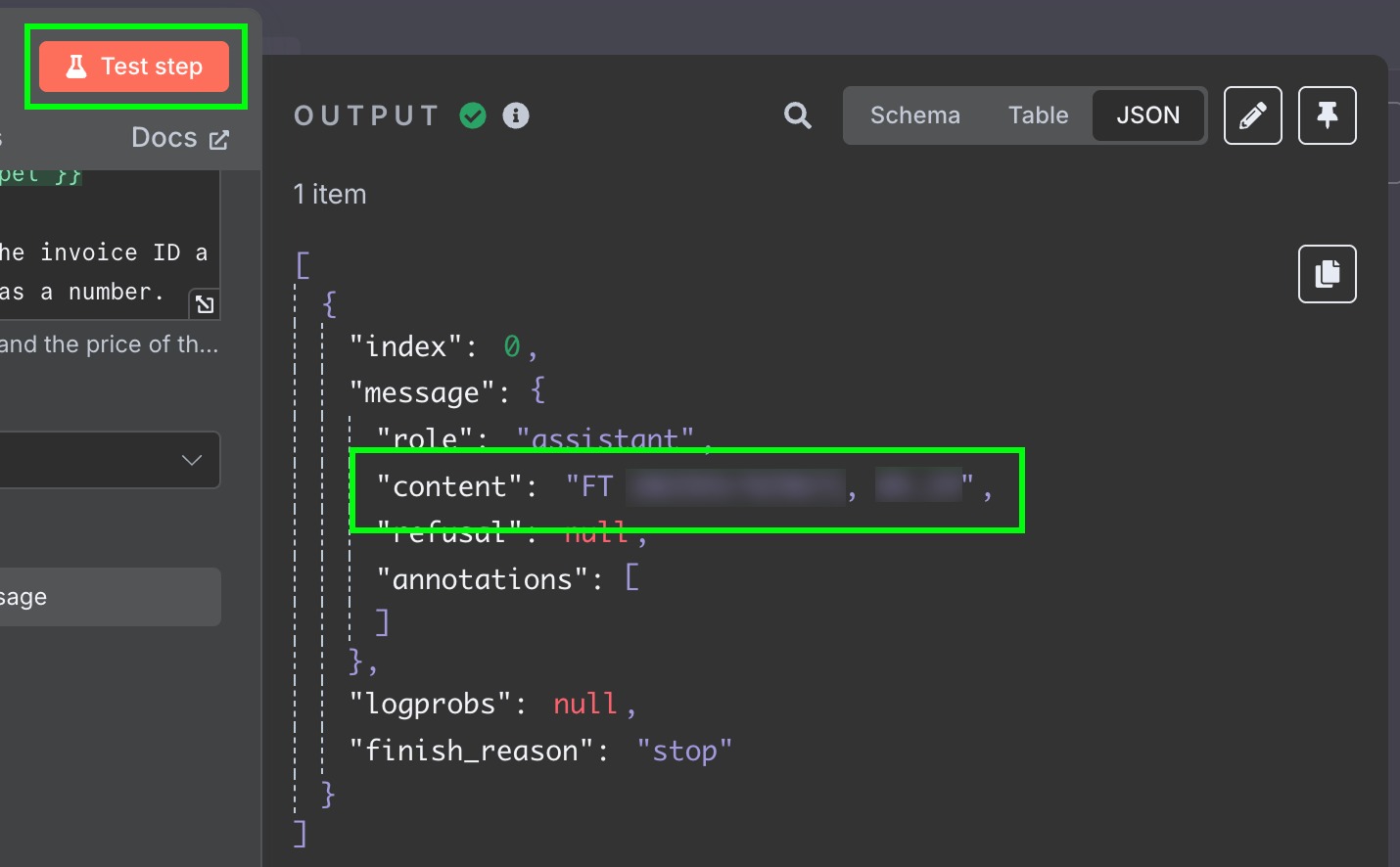
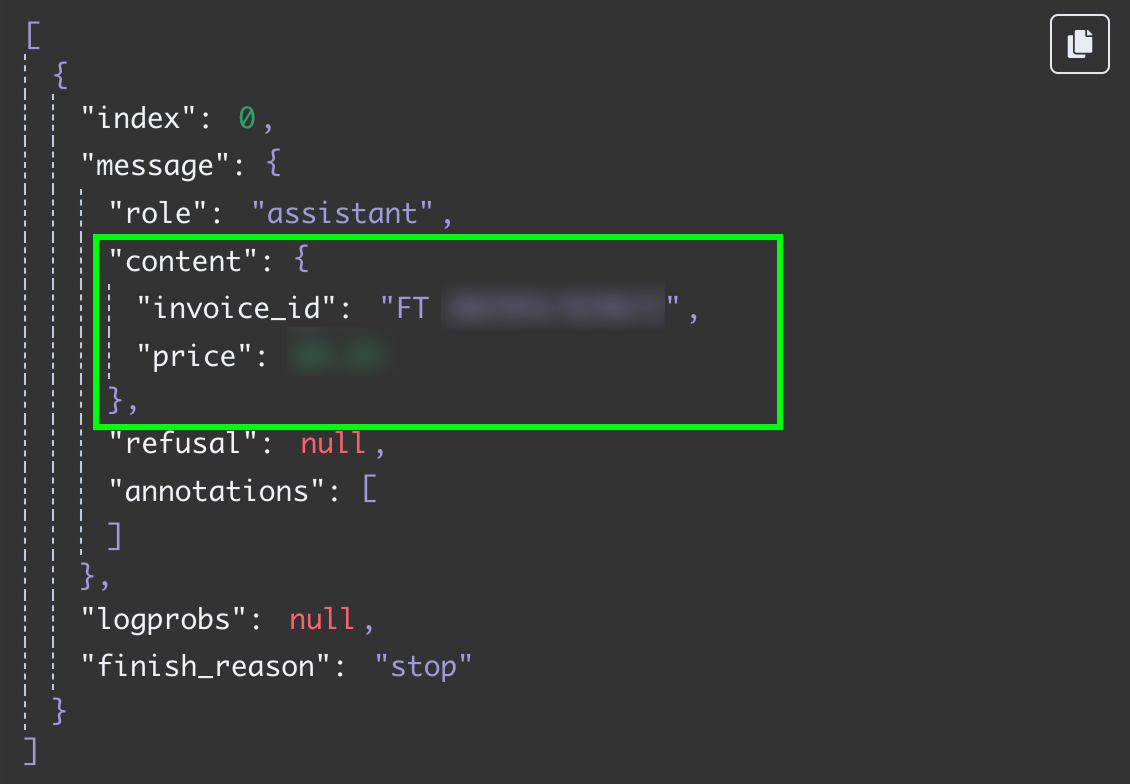
Das Resultat ist ein String mit der Antwort des Modells. Wir möchten die zwei Felder jedoch separat haben, damit wir die Nachricht nicht weiterverarbeiten müssen. Das erreichen wir, indem wir das LLM-Output auf JSON umstellen:

Testen wir diesen Schritt erneut, erhalten wir beide Felder als JSON-Daten:
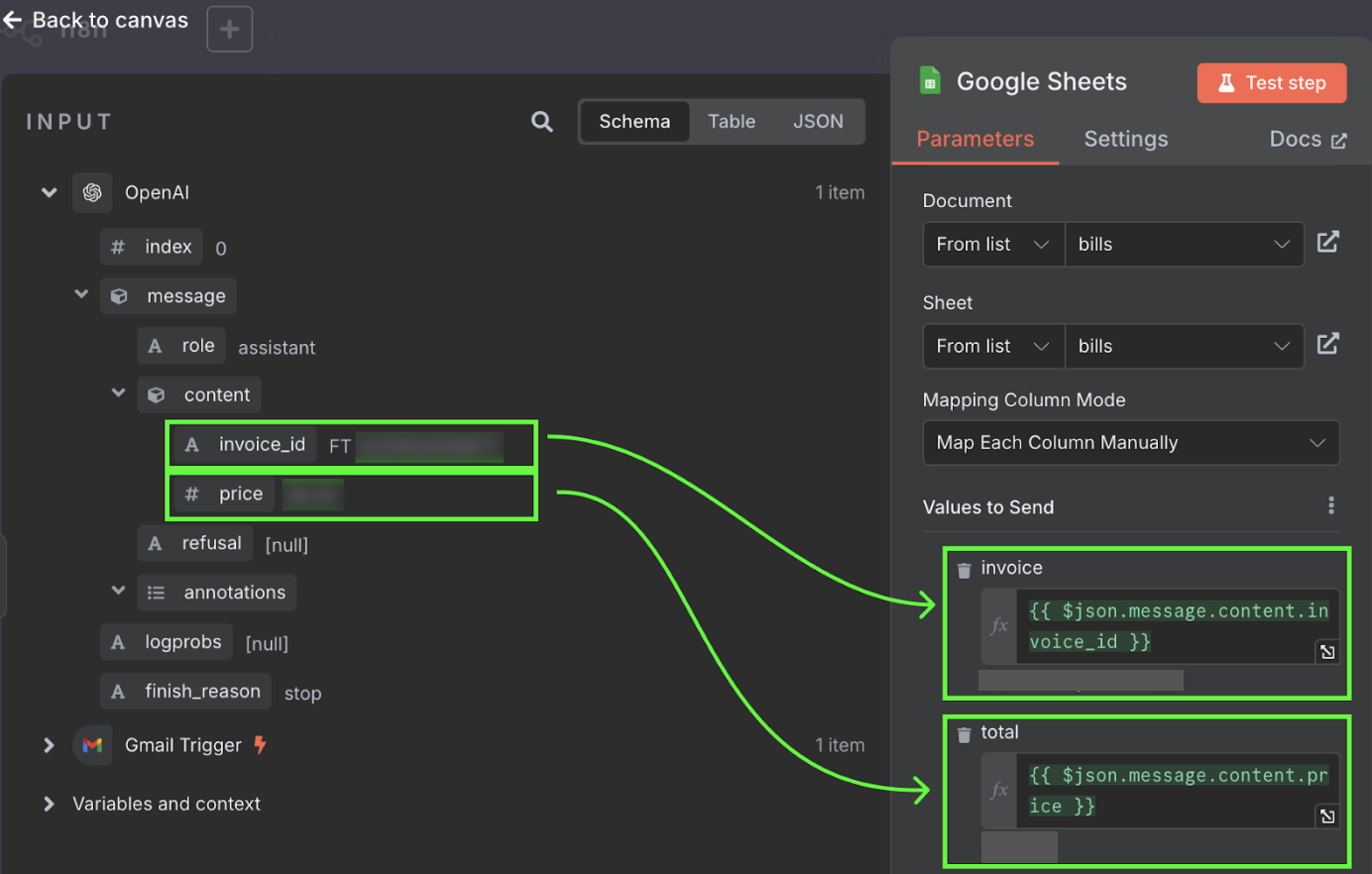
Der letzte Schritt dieses Workflows schreibt Rechnungs-ID und Betrag als neue Zeile in ein Google Sheet. Dazu verbinden wir den Output des OpenAI-Nodes mit Google Sheets – wie zuvor über das "+" links am Node:
Suche nach Google Sheets und wähle den Node "Append row in sheet":
Wir können dieselben Credentials wie für Gmail verwenden. Allerdings müssen in der Google Cloud Console folgende APIs aktiviert sein:
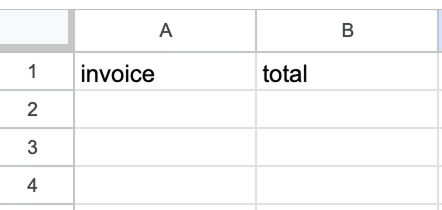
Für den Google-Sheets-Node wählen wir die Tabelle und legen fest, welche Werte in welche Spalten geschrieben werden. Das Sheet sollte manuell mit zwei Spalten angelegt sein – eine für die Rechnungs-ID und eine für den Gesamtbetrag.
Diese Werte stammen aus dem Output des OpenAI-Nodes. Du kannst sie per Drag-and-drop in die Spalten ziehen.
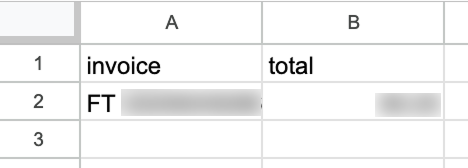
Fertig! Wir haben einen Workflow, der Rechnungen automatisch in ein Google Sheet überträgt. Teste ihn über "Test workflow" unten:
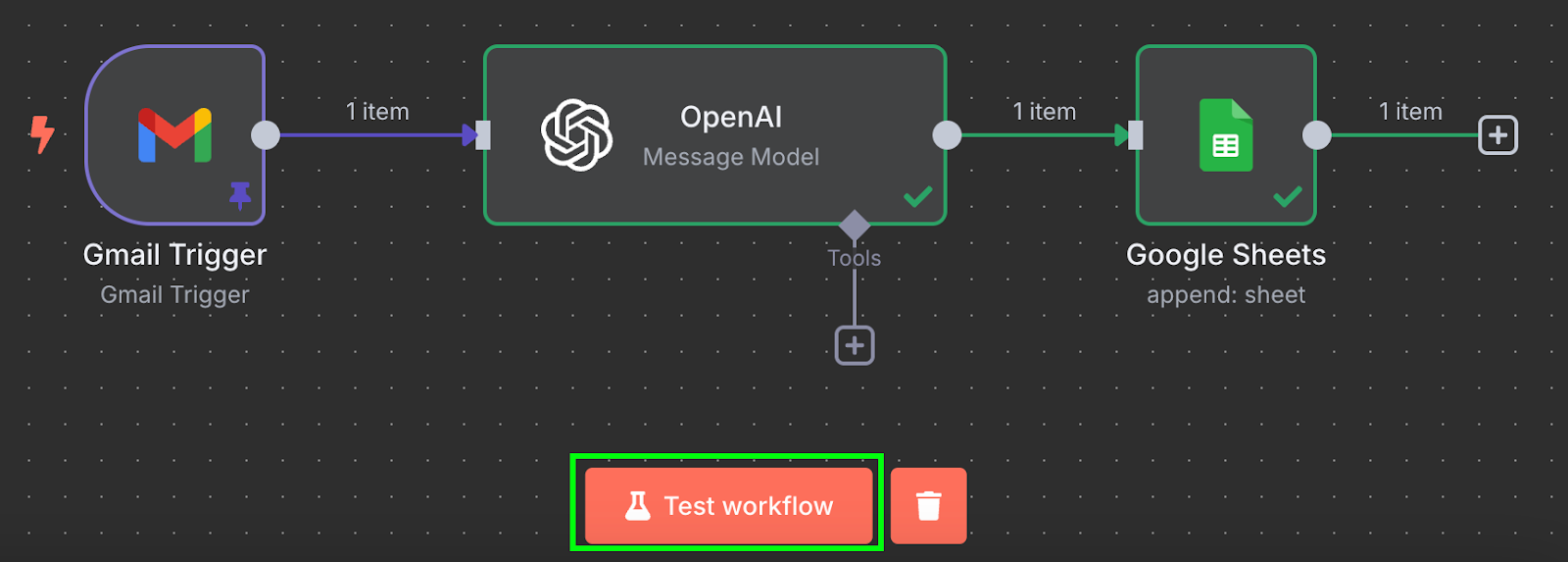
Nach dem Lauf siehst du im Google Sheet eine neue Zeile mit den Daten:
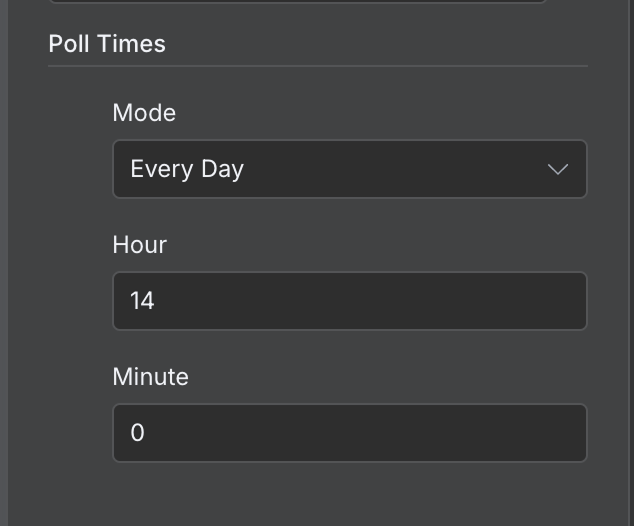
Standardmäßig läuft ein Workflow jede Minute. Je nach Anwendungsfall solltest du eine passende Frequenz einstellen. In diesem Beispiel ist jede Minute viel zu oft; einmal täglich ist sinnvoller.
Das stellst du ein, indem du auf den Trigger-Node doppelklickst und im Feld "Poll Times" einen anderen Wert setzt:
In diesem Abschnitt bauen wir einen komplexeren RAG-Agenten-Workflow. RAG steht für Retrieval-augmented Generation: Eine Technik, bei der zunächst relevante Informationen aus einer Datenbank oder einem Dokument abgerufen und darauf basierend mit einem Sprachmodell Antworten generiert werden.
Das ist besonders nützlich, wenn wir eine spezifische Wissensbasis haben, z. B. ein langes Textdokument, und einen KI-Agenten bauen möchten, der Fragen dazu beantworten kann.
Ich spiele gern Brettspiele, aber meine Freunde und ich diskutieren häufig über Regeln und suchen dann ewig nach der korrekten Stelle – frustrierend. Ein RAG-Agent auf Basis der Spielregeln ist eine gute Lösung: Beim nächsten Mal fragen wir einfach den Agenten.
Dafür bauen wir zwei Workflows:
Pinecone ist eine Datenbank, die Daten als Vektoren verwaltet. Eine Vektordatenbank wie Pinecone ist ideal für unseren RAG-Agenten, da sie relevante Informationen schnell auffindet und einordnet – das verbessert Genauigkeit und Effizienz der Antworten.
Da dieser Workflow nur einmal ausgeführt werden muss, nutzen wir einen Manual-Trigger-Node. Damit lässt sich ein Workflow manuell starten.
Verbinde den Manual-Trigger-Node mit einem "Google Drive"-Node, um die Daten aus Google Drive herunterzuladen.

Nutze folgende Konfiguration:
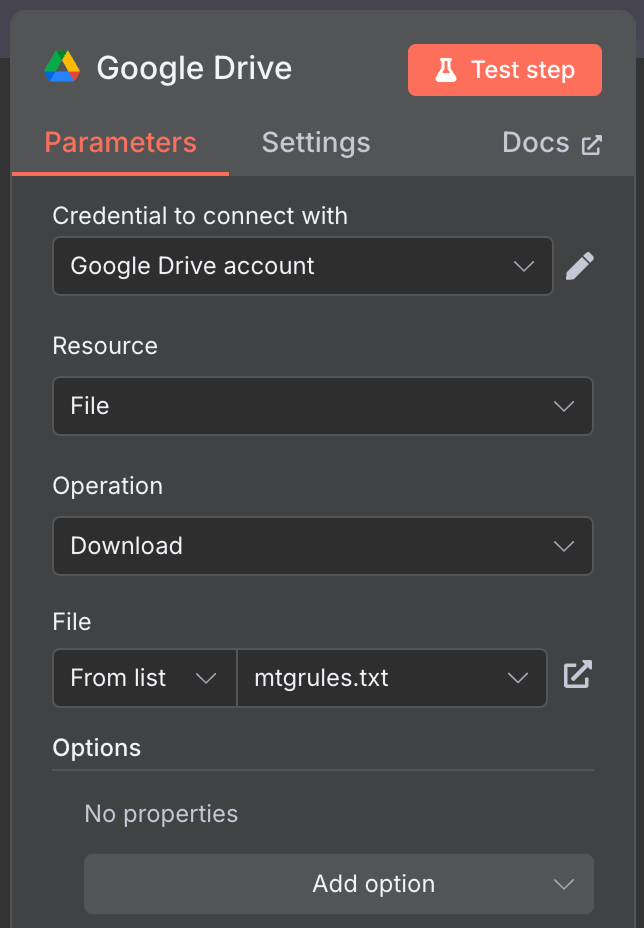
Ich habe die öffentlich verfügbare Datei mtgrules.txt mit den Regeln des Trading-Card-Games Magic: The Gathering verwendet. Du kannst jede beliebige Datei nehmen, zu der du Fragen stellen willst – der Workflow bleibt gleich.
Zur Einrichtung von Pinecone loggst du dich in Pinecone ein, kopierst den API-Key und erstellst über "Create index" einen Index. Meinen Index habe ich rules genannt und das Modell text-embedding-3-small gewählt.

Zurück in n8n verbindest du den Output des Google-Drive-Nodes mit einem Pinecone Vector Store-Node mit der Aktion "Add documents to vector store":
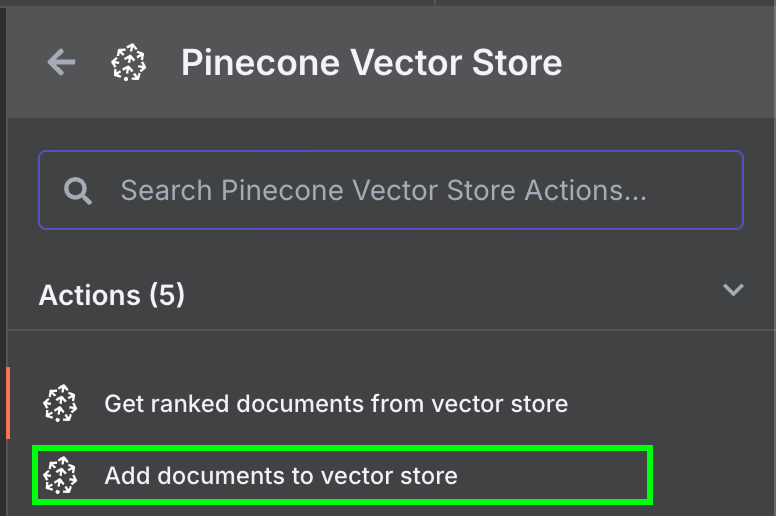
Für die Konfiguration legst du ein Credential an (API-Key einfügen) und wählst den eben erstellten Pinecone-Index. Unter dem Pinecone Vector Store-Node siehst du zwei weitere Komponenten: ein Embedding-Modell und einen Data Loader.
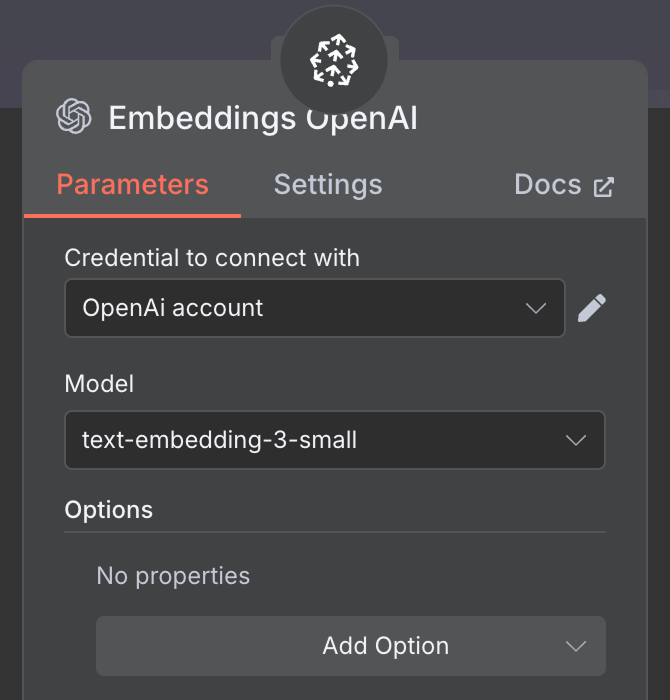
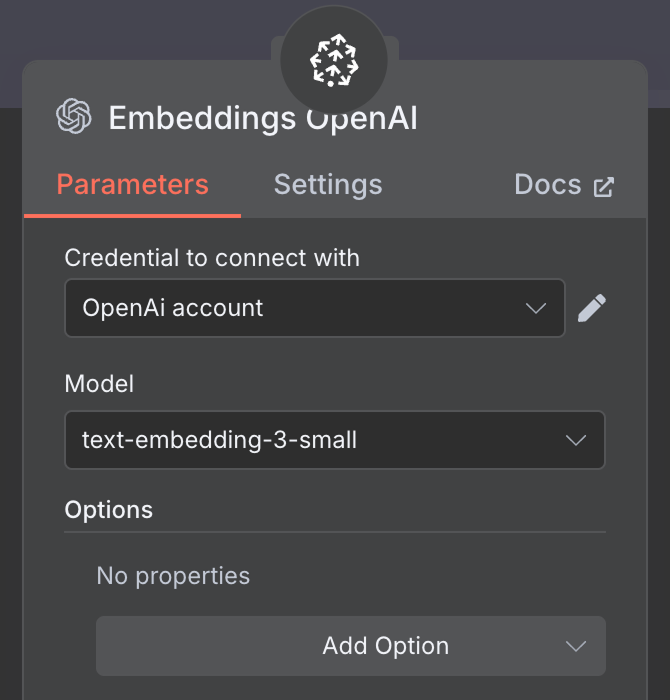
Für das Embedding erstellst du einen OpenAI Embedding-Node mit dem Modell text-embedding-3-small:
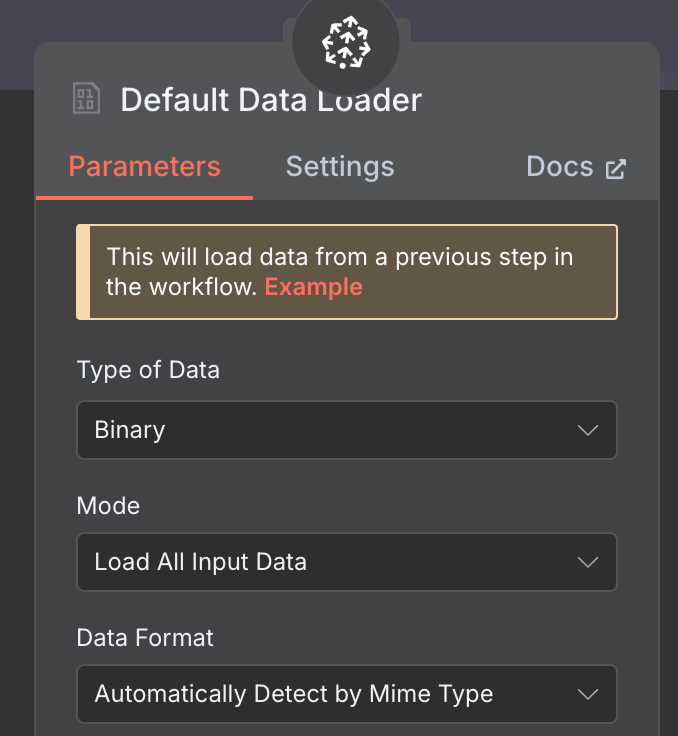
Als Data Loader nutzen wir einen Default Data Loader-Node mit "Binary" als Datentyp:
Abschließend benötigt der Data Loader einen Text Splitter-Node, der festlegt, wie die Datei beim Erstellen des Vector Stores in Abschnitte aufgeteilt wird. Wir nutzen den Recursive Character Text Splitter-Node – die Standardempfehlung für die meisten Anwendungen.
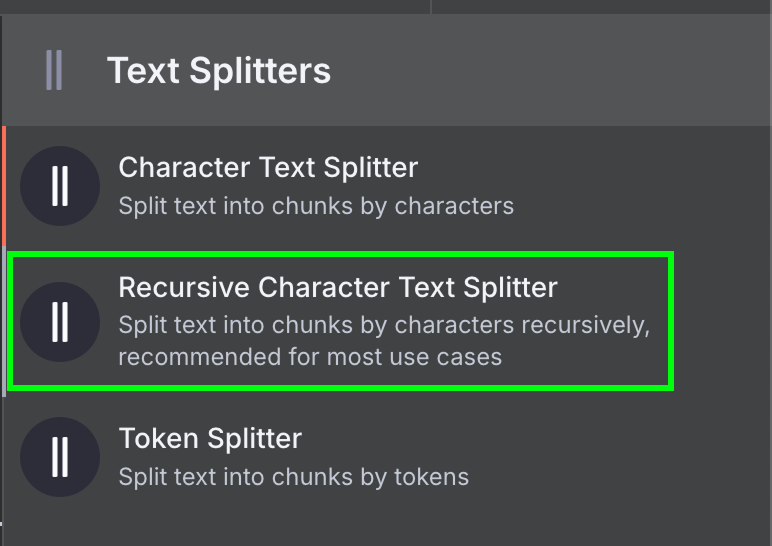
Wir konfigurieren Chunk Size 1.000 und Chunk Overlap 200:
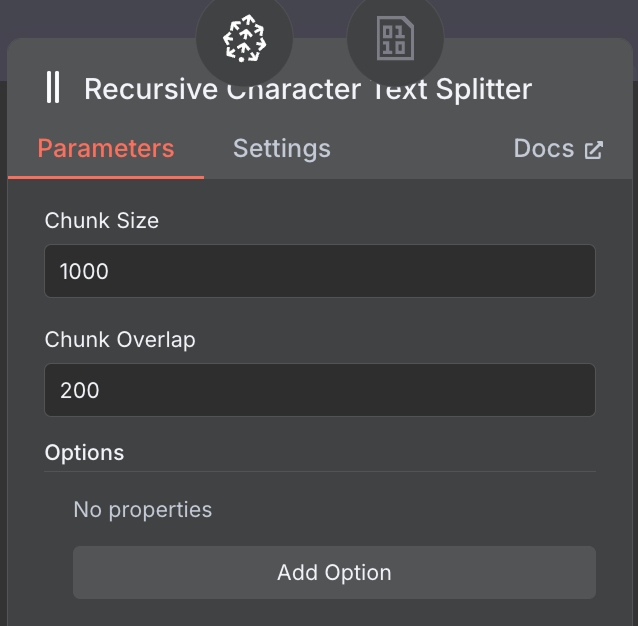
Bei der Wahl von Chunk Size und Overlap gilt: Für lange Dokumente eher größere Chunks, dazu eine kleinere Überlappung – so bleibt genug Kontext erhalten, ohne zu viel Redundanz.
So sieht der finale Workflow aus:
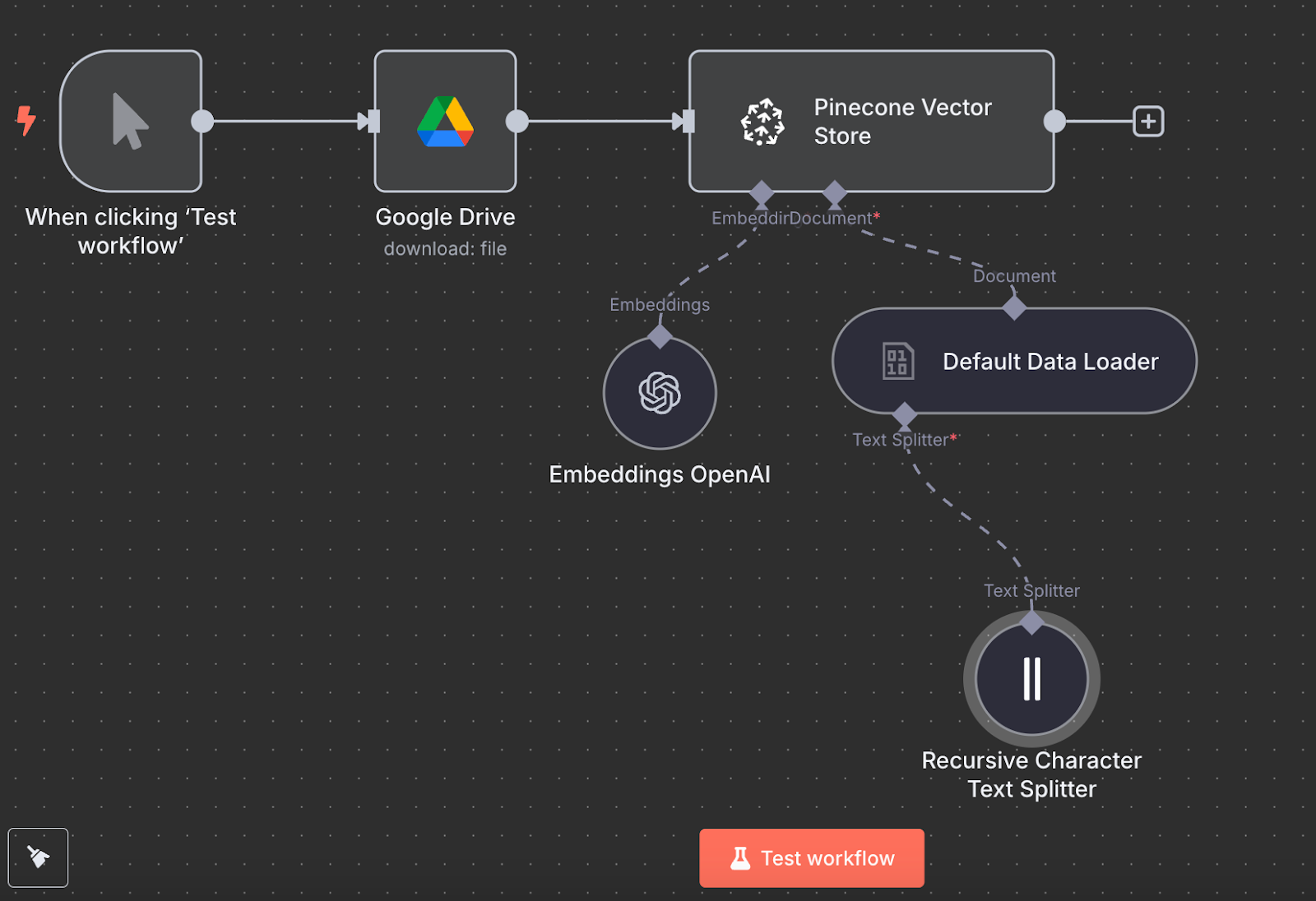
Starte ihn mit "Test workflow". Nach Abschluss kannst du in Pinecone prüfen, ob die Daten geladen wurden.
So sieht das finale Schema für den RAG-Agenten aus:
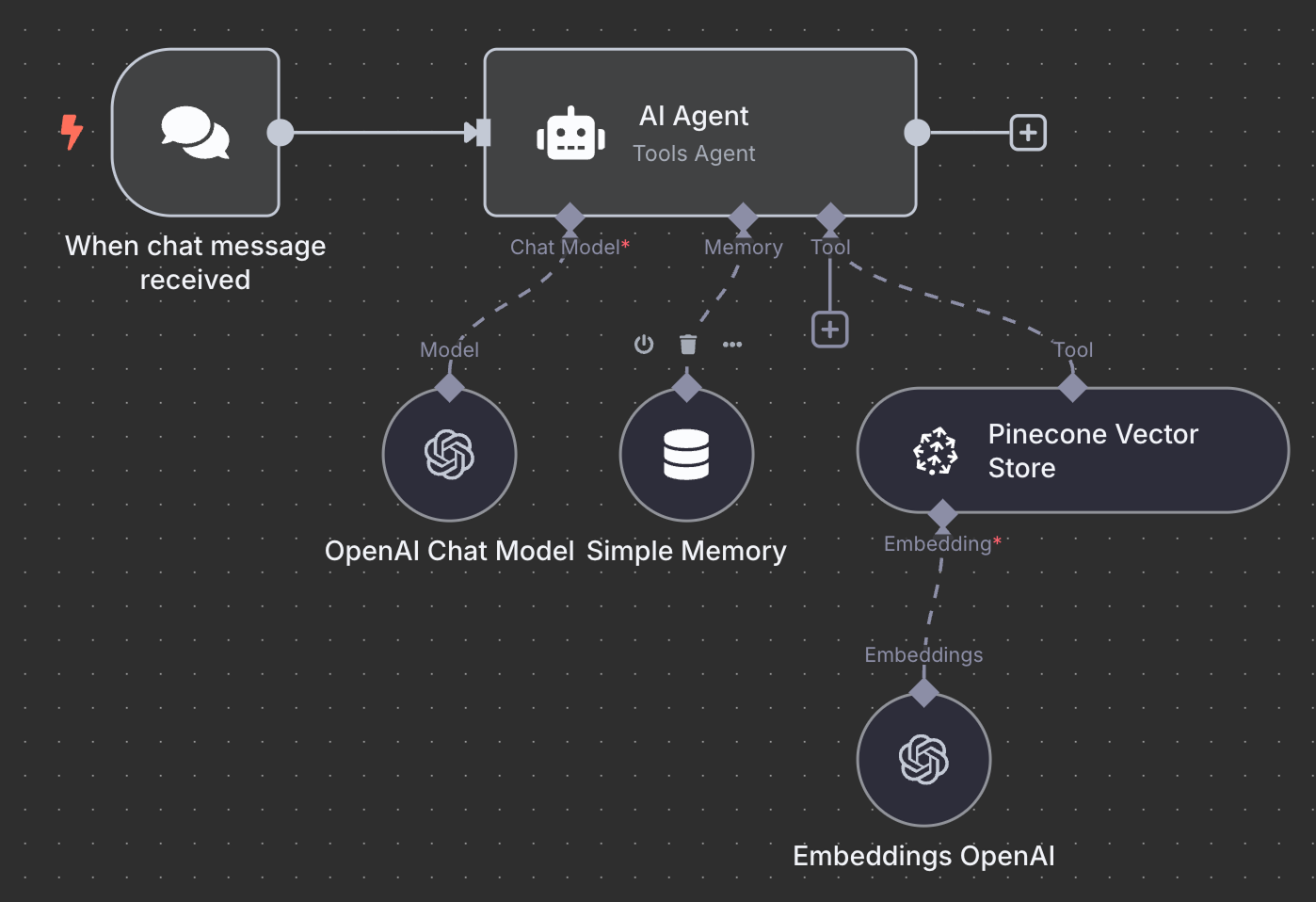
Als Übung: Versuche, den Ablauf zu verstehen und ihn lokal nachzubauen, bevor du weiterliest.
Wir starten mit einem "On chat message"-Trigger-Node. Er wird für Chat-Workflows verwendet.
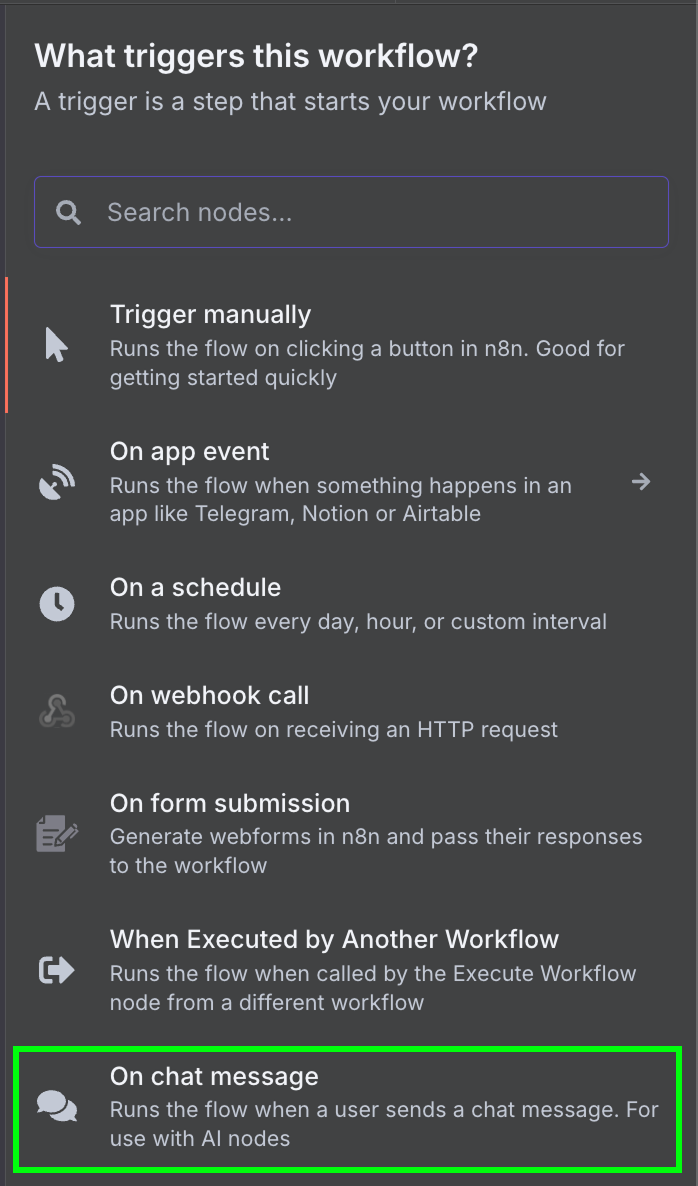
Als Nächstes verbinden wir den Chat-Trigger mit einem "AI Agent"-Node mit den Standardeinstellungen.
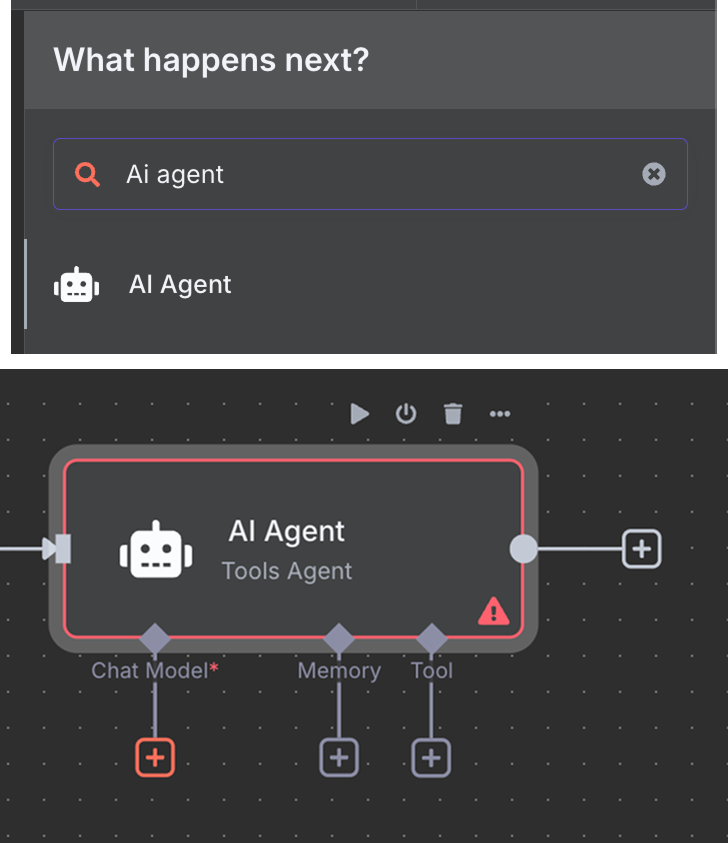
Unter dem AI Agent können wir drei Dinge konfigurieren:
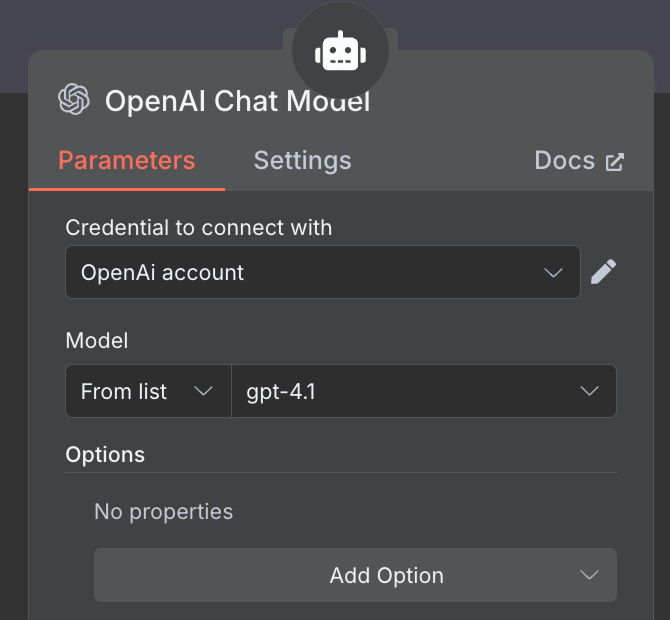
Als KI-Modell wählen wir einen "OpenAI Chat Model"-Node und nutzen GPT-4.1, wie zuvor. Die GPT-5-Familie ist aktuell, aber 4.1 hat ein 1M-Token-Kontextfenster und eignet sich gut für RAG.
Als Memory nutzen wir einen "Simple Memory"-Node mit einer Kontextlänge von 5. Der Agent berücksichtigt also die letzten fünf Interaktionen.
Als Tool fügen wir einen "Pinecone Vector Store"-Node mit folgender Konfiguration hinzu:
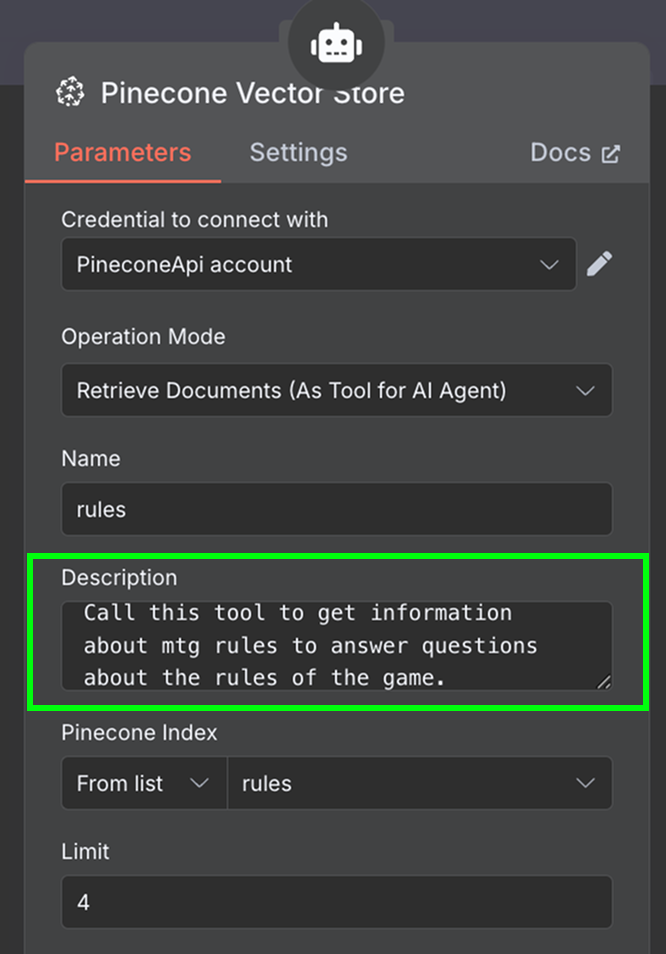
Im Beschreibungsfeld ist wichtig festzuhalten, wann das Tool genutzt werden soll. Daran orientiert sich der Agent, ob er das Tool aufruft.
Zuletzt konfigurieren wir das Embedding für den Vector Store. Wie zuvor nutzen wir einen OpenAI Embedding-Node mit dem Modell text-embedding-3-small:
Der Workflow ist fertig – wir können mit dem Agenten chatten. So kann das aussehen:
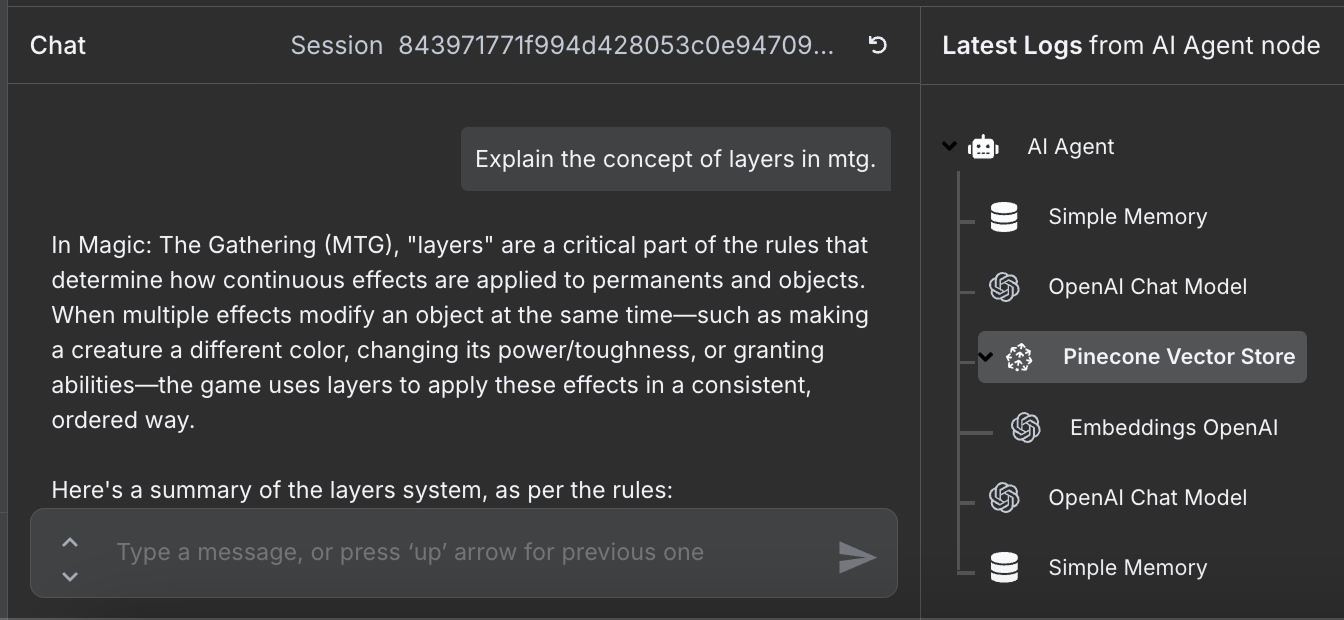
Rechts siehst du die Schritte, die der Agent zur Beantwortung unternommen hat. Insbesondere hat er die Pinecone-Datenbank genutzt, um die relevanten Regelstellen abzurufen.
n8n bietet ein nützliches Feature, das unseren Aufbau von Workflows erheblich beschleunigt: die n8n-Template-Bibliothek.
Diese Sammlung enthält vorgefertigte Workflows aus der Community und von n8n-Expertinnen und -Experten. Ob einfache Aufgaben oder komplexe Prozesse – mit hoher Wahrscheinlichkeit gibt es bereits ein passendes Template.
Importierst du einen Workflow in deine n8n-Instanz, musst du nicht bei null starten. Du profitierst von Lösungen anderer Nutzer. Nach dem Import musst du nur noch deine Credentials hinterlegen und den Workflow an deine Anforderungen anpassen.
Für nahezu jede Automatisierungsaufgabe – von E-Mail-Verarbeitung bis Social-Media-Management – findest du wahrscheinlich ein Template in der Bibliothek.
n8n bietet ein riesiges Integrationsökosystem und verbindet über tausend Services und Tools, um KI-Agenten zu bauen. In diesem Tutorial haben wir nur an der Oberfläche gekratzt. Indem du n8n nutzt, um KI-Agenten für Alltagsaufgaben zu erstellen, beginnst du erst, sein Potenzial wirklich zu erschließen.
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Mark Pedigo
Tutorial
Moez Ali
Tutorial
DataCamp Team
Tutorial
Matt Crabtree