



Cursus
Développer des applications d'IA
21 h
n8n s'est imposé comme un cadre populaire et puissant dans le domaine de l'intelligence artificielle. Il nous permet de créer des flux de travail automatisés sans avoir besoin d'un codage complexe.
Dans cet article, je vous expliquerai étape par étape comment tirer le meilleur parti de cette plateforme robuste pour automatiser deux processus distincts :
Nous tenons nos lecteurs informés des dernières nouveautés en matière d'IA en leur envoyant The Median, notre lettre d'information gratuite du vendredi qui analyse les principaux sujets de la semaine. Abonnez-vous et restez à la pointe de la technologie en quelques minutes par semaine :
n8n est un outil d'automatisation open-source qui nous aide à connecter diverses applications et services pour créer des flux de travail, à l'instar d'une chaîne de montage numérique. Il permet aux utilisateurs de concevoir visuellement ces flux de travail avec des nœuds, chacun représentant une étape différente du processus.
Avec n8n, nous pouvons automatiser des tâches, gérer des flux de données et même intégrer des API, le tout sans avoir besoin de compétences approfondies en programmation. Voici un exemple d'automatisation que nous construirons dans ce tutoriel :
Sans entrer dans les détails, voici une description de ce que fait cette automatisation :
Nous avons deux options pour utiliser n8n :
Les deux options vous permettent de suivre ce tutoriel gratuitement. Nous allons l'exécuter localement, mais si vous préférez utiliser l'interface web, les étapes sont les mêmes.
Le dépôt officiel de n8n explique comment installer n8n localement. La méthode la plus simple consiste à :
npx n8n.C'est tout ! Après avoir exécuté la commande, vous devriez voir ceci dans le terminal :
Pour ouvrir l'interface, appuyez sur "o" sur le clavier ou ouvrez l'URL localhost affichée dans le terminal - dans mon cas, http://localhost:5678.
Avant de construire notre première automatisation, il est bon de comprendre comment fonctionne n8n. Un flux de travail n8n consiste en une séquence de nœuds. Il commence par un nœud de déclenchement qui spécifie une condition d'exécution du flux de travail.
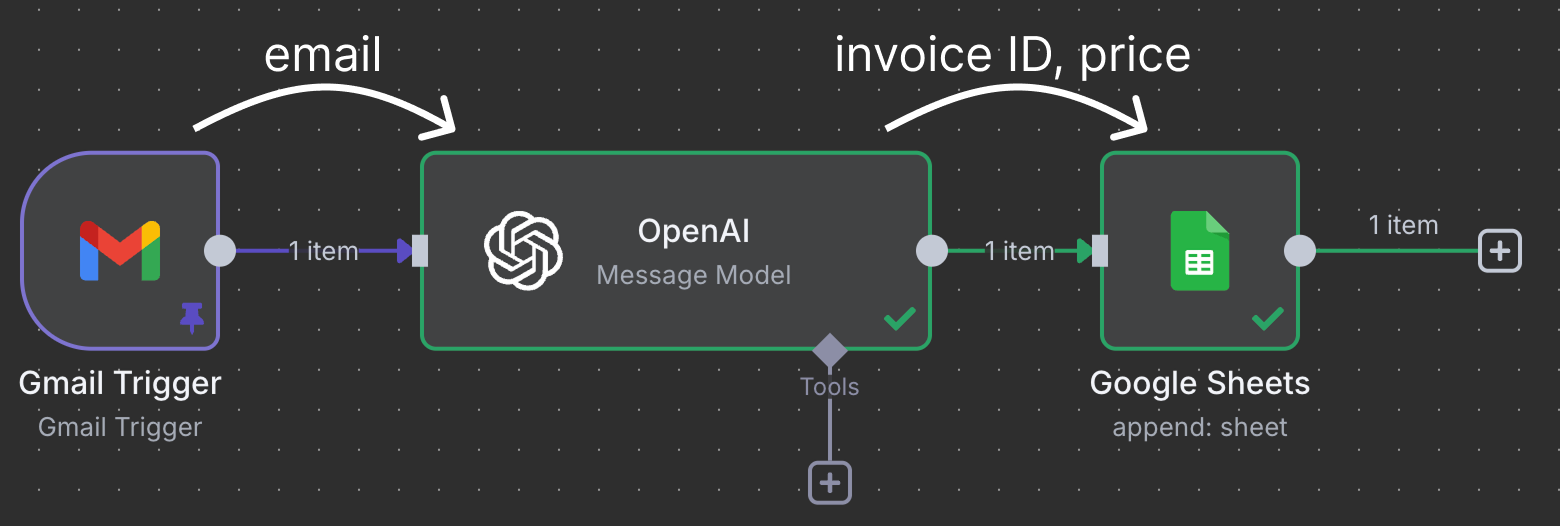
Les nœuds se connectent pour déplacer et traiter les données. Dans cet exemple, le nœud de déclenchement Gmail se connecte à un nœud OpenAI. Cela signifie que l'e-mail est transmis à ChatGPT pour traitement. Enfin, la sortie de ChatGPT est envoyée à un nœud Google Sheet, qui se connecte à une Google Sheet dans notre Google Drive et écrit une nouvelle ligne dans une feuille de calcul.
Ce flux de travail particulier utilise le ChatGPT pour identifier les factures qui doivent être payées et assigne une ligne dans la feuille avec l'ID de la facture et le prix.
Les flux de travail de n8n peuvent être beaucoup plus complexes. n8n prend en charge plus de 1 047 intégrations, nous ne pouvons donc pas toutes les couvrir dans un tutoriel. Je m'efforcerai plutôt de vous donner une idée générale de son fonctionnement et de vous fournir le contexte nécessaire pour l'explorer par vous-même. S'il existe un outil que vous utilisez régulièrement, il y a de fortes chances que n8n le prenne en charge ou que vous puissiez l'intégrer manuellement.
Dans cette section, nous apprenons à construire le flux de travail ci-dessus.
Il s'agit d'un cas d'utilisation réel que j'utilise pour gérer mes factures de location. J'ai une maison avec quelques chambres que je loue. Les factures sont réparties à parts égales entre tous les locataires. Chaque fois que je reçois une facture, je dois ajouter le total à une feuille de calcul qui est partagée avec mes locataires.
J'ai une adresse électronique spécifique à laquelle sont envoyées les factures relatives aux factures domestiques. De cette façon, je sais que tous les courriels de cette boîte aux lettres correspondent à une facture. J'envoie le contenu de l'e-mail au ChatGPT pour identifier l'identifiant de la facture et le montant total à payer. Ces informations sont ensuite ajoutées à une nouvelle ligne de la feuille de calcul partagée.
Pour démarrer un nouveau flux de travail, nous devons cliquer sur le bouton "Ajouter une première étape...".
Comme il s'agit du premier nœud, il doit s'agir d'un déclencheur, ce qui nous permet de sélectionner un nœud déclencheur. Un nœud de déclenchement définit les conditions d'exécution du flux de travail.
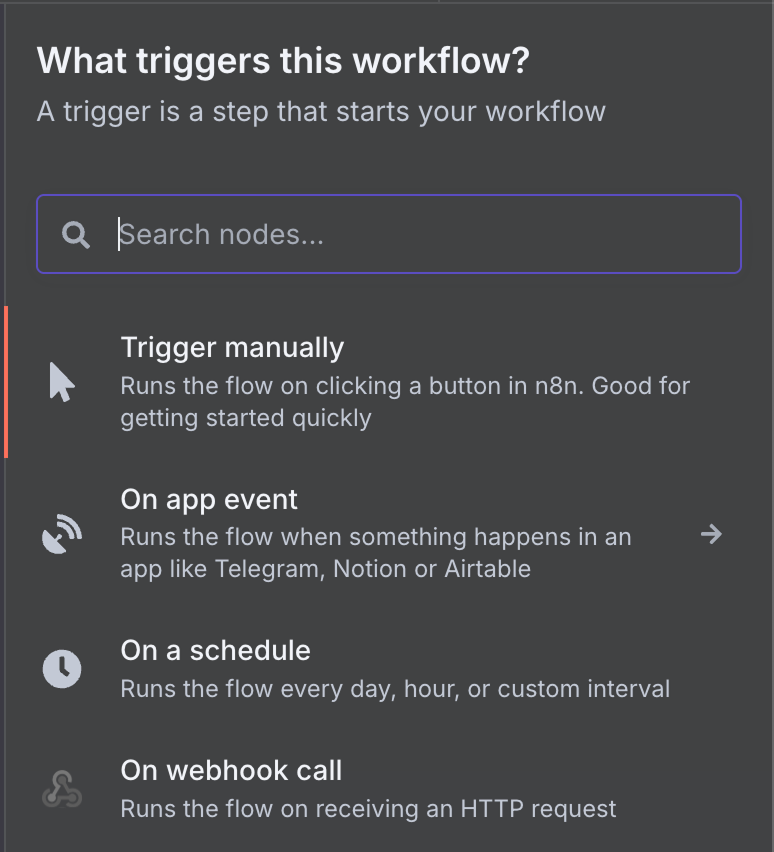
Il existe un large éventail de nœuds de déclenchement possibles. Sélectionnons un nœud déclencheur Gmail en tapant "gmail" dans la zone de recherche et en cliquant sur le nœud Gmail.
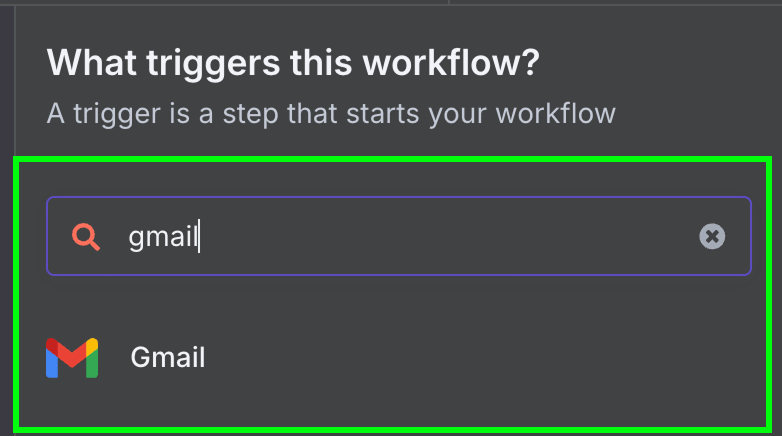
Ensuite, nous choisissons le seul déclencheur disponible pour Gmail : "Sur message reçu".

Cela ouvrira le panneau de configuration du nœud, dans lequel nous devons configurer nos informations d'identification Gmail pour permettre au flux de travail n8n d'accéder à notre compte Gmail. Pour ce faire, cliquez sur "New credential". La fenêtre suivante s'ouvre :
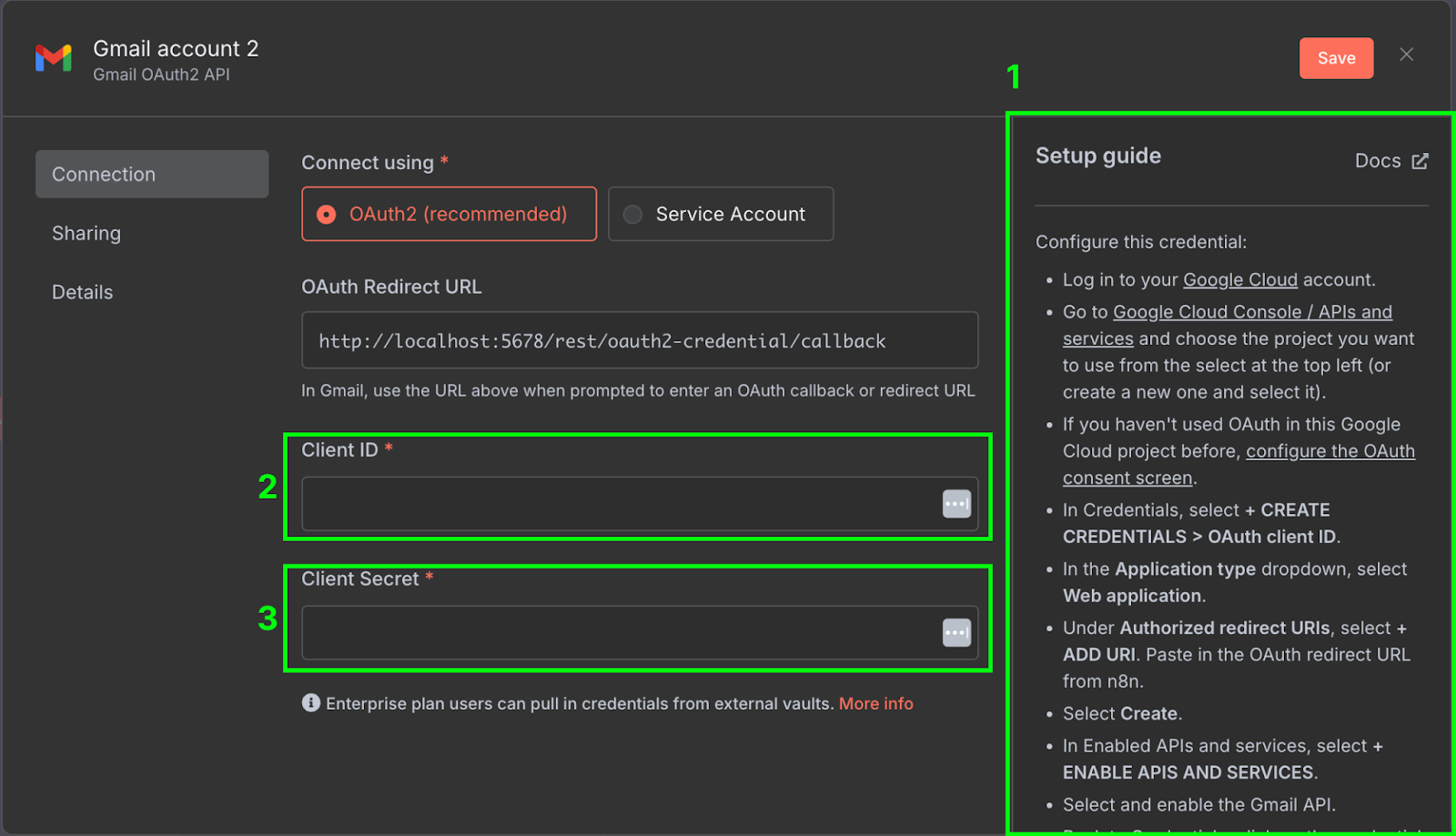
Sur le côté droit (1), vous trouverez un guide d'installation expliquant les étapes nécessaires pour configurer les informations d'identification sur Google Cloud. Les guides fournis par n8n sont très complets, nous ne répéterons donc pas les étapes ici. Veillez également à activer l'API Gmail dans la Google Cloud Console.
Une fois qu'il est configuré, nous devons copier l'ID client (2) et le secret client (3) de Google Cloud dans la configuration des informations d'identification de n8n.
Pour nous assurer que tout est correctement configuré, nous pouvons tester le nœud en cliquant sur "Fetch Test Event".
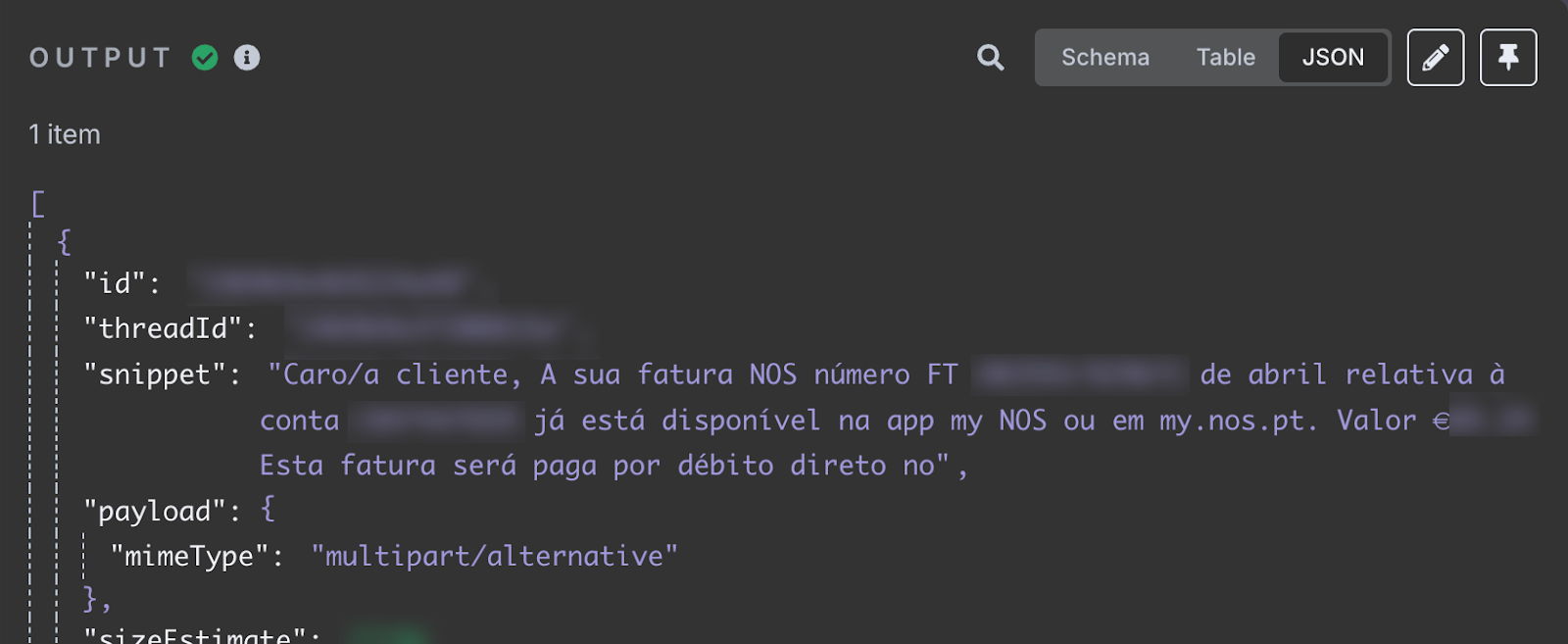
Après le test, nous devrions voir le dernier courriel que nous avons reçu dans notre boîte de réception dans la section de sortie. Le contenu de l'e-mail est le champ snippet.
Le champ snippet stocke le contenu de l'e-mail. Il est indiqué que ma facture internet d'avril est disponible. Il fournit l'identifiant de la facture et le montant total à payer. Il s'agit des informations que nous voulons ajouter à la feuille de calcul.
À des fins de test, je vous recommande d'épingler la sortie en cliquant sur le bouton d'épinglage dans le coin supérieur droit :
Cela verrouillera le résultat sur le déclencheur, ce qui signifie qu'à chaque fois que nous exécuterons ce flux de travail, ce même résultat sera utilisé, ce qui facilitera le test du flux de travail car les résultats ne seront pas affectés par les nouveaux courriers électroniques que nous pourrions recevoir. Nous le désépinglerons une fois que le flux de travail aura été correctement mis en place.
À ce stade, notre flux de travail doit comporter un seul nœud de déclenchement (nous pouvons voir qu'il s'agit d'un nœud de déclenchement grâce au petit marqueur en forme d'éclair sur la gauche).
Notez que, comme vous n'aurez probablement pas de facture par courrier électronique dans votre boîte aux lettres, le ChatGPT vous donnera probablement plus tard une réponse qui n'a pas de sens. Si vous souhaitez tester ce flux de travail précis, vous pouvez vous envoyer un e-mail de test avec le contenu suivant (ou quelque chose de similaire) :
Dear customer,
Your internet invoice number FT 2025**/****** for April is now available in the attachment.
Amount
€**.**
This invoice must be paid by 19/05/2025.Après l'envoi, vous devez supprimer le résultat, réexécuter le nœud Gmail et épingler le nouveau résultat.
L'étape suivante consiste à configurer le nœud OpenAI. Commencez par cliquer sur le bouton "+" à droite du nœud de déclenchement Gmail :

Tapez "OpenAI" et sélectionnez l'option correspondante dans la liste.
Ensuite, sous "Actions de texte", sélectionnez le nœud "Message a model". Ce nœud est utilisé pour envoyer des messages à un LLM.

Comme précédemment, nous devons créer un identifiant pour accéder à OpenAI. Notez qu'une fois qu'un titre est créé, il peut être réutilisé dans n'importe quel flux de travail. Il n'est pas nécessaire de le régler à chaque fois.
Pour l'identifiant OpenAI, tout ce dont nous avons besoin, c'est d'une clé API. Si vous n'en avez pas, vous pouvez en créer un ici. Si vous avez des difficultés à le faire, n8n fournit également un guide à cet effet.
En termes de configuration, nous devons sélectionner le modèle d'IA que nous voulons utiliser et le message que nous envoyons au modèle. Pour le modèle, nous pouvons utiliser GPT 4.1 :
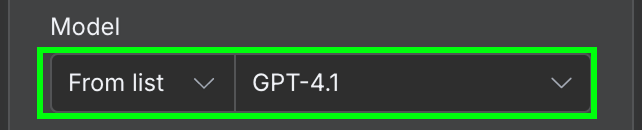
Dans le champ message, nous devons fournir l'invite. Pour cet exemple, nous donnons au modèle le contenu de l'e-mail et lui demandons d'identifier l'identifiant de la facture et le montant total à payer. Voici le texte que j'ai utilisé :
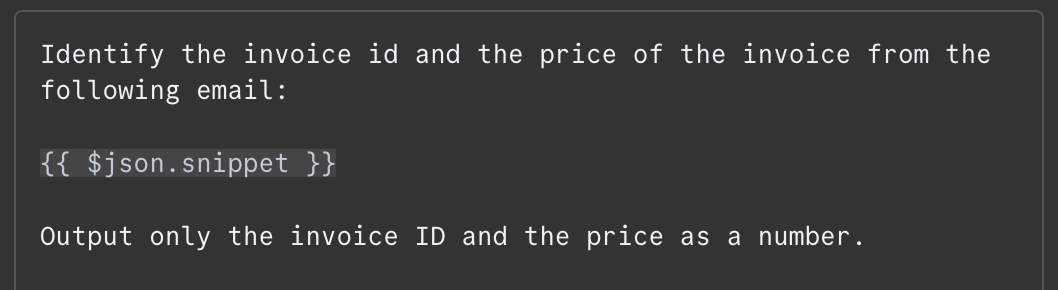
Le contenu du courriel est fourni à l'adresse suivante : {{ $json.snippet }}. Dans n8n, l'invite peut contenir des variables qui sont alimentées à partir de la sortie des nœuds précédents, le courrier électronique dans notre cas. La liste des champs disponibles est affichée à gauche. Nous pouvons saisir le champ manuellement ou le glisser-déposer dans l'invite.
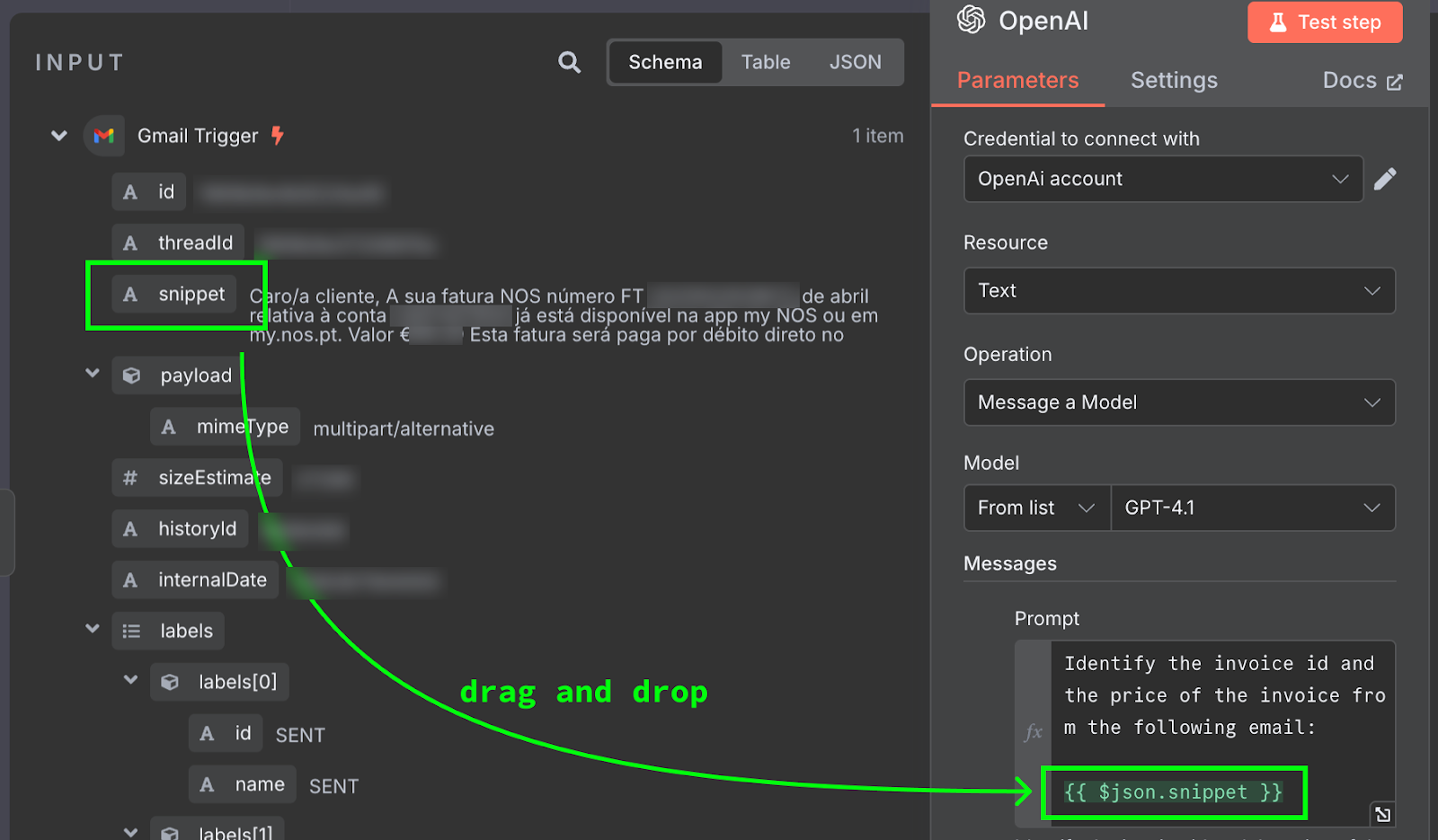
Pour tester cela, nous cliquons sur le bouton "Test Step" en haut du panneau de configuration. Le résultat est affiché à droite :
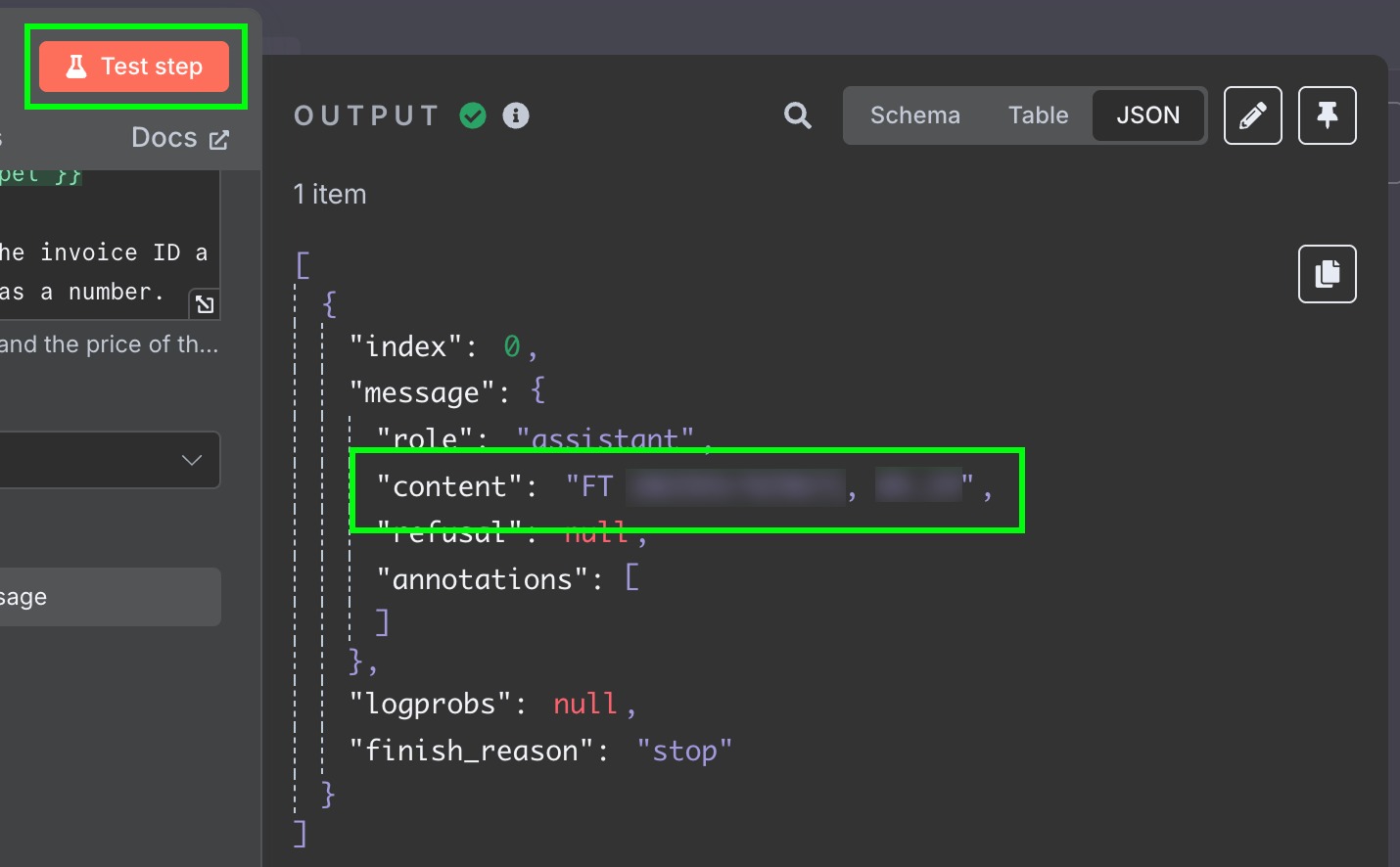
Le résultat est une chaîne de caractères contenant la réponse du modèle. Nous aimerions que les deux champs soient séparés, afin de ne pas avoir à traiter davantage le message. Nous pouvons y parvenir en changeant la sortie du LLM en JSON :

En testant à nouveau cette étape, nous obtenons les deux champs sous forme de données JSON :
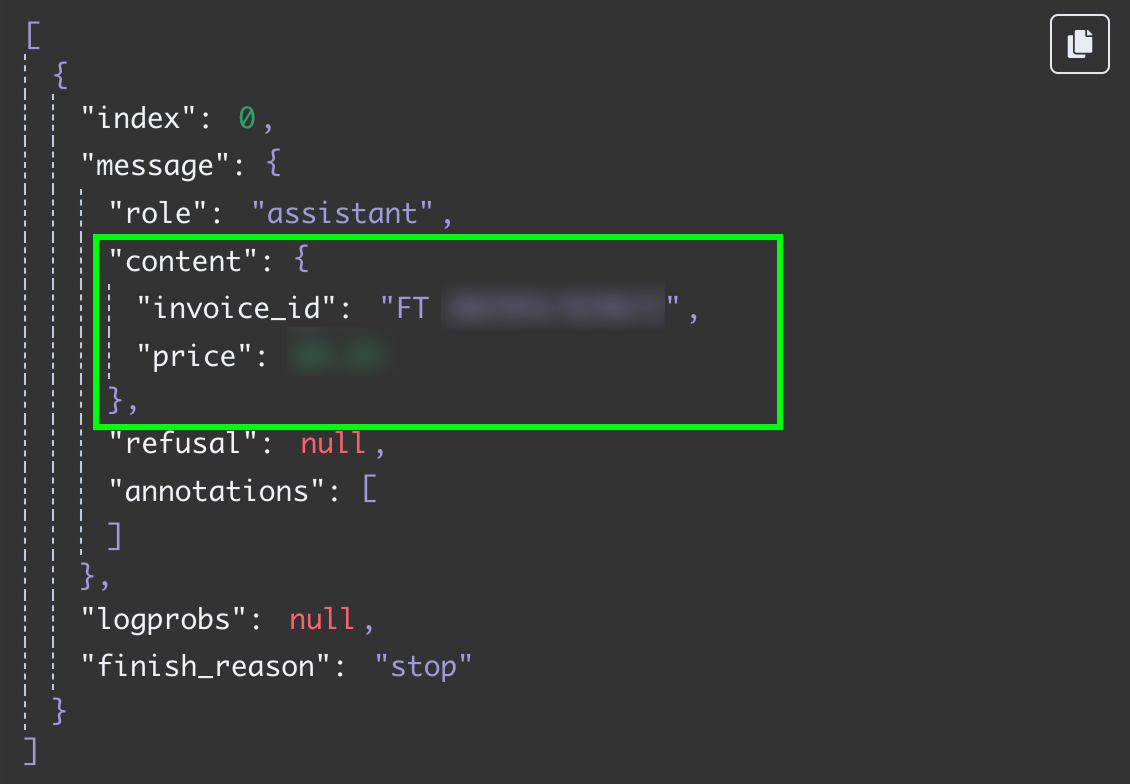
La dernière étape de ce flux de travail consiste à envoyer l'identifiant et le prix de la facture dans une nouvelle ligne d'une feuille Google. À ce stade, nous devons connecter la sortie du nœud OpenAI à Google Sheets. Nous procédons comme précédemment en cliquant sur le bouton "+" à gauche du nœud :
Ici, nous voulons taper Google Sheets et sélectionner le nœud "Append row in sheet" :
Nous pouvons utiliser les mêmes informations d'identification que celles utilisées pour l'accès à Gmail. Mais nous devons activer les API suivantes dans la Google Cloud Console:
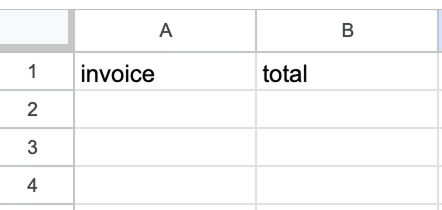
Pour configurer le nœud Google Sheets, nous devons sélectionner la feuille et les valeurs qui doivent remplir les champs. La feuille doit être créée manuellement avec deux colonnes, l'une pour l'identifiant de la facture et l'autre pour le total de la facture.
Ces valeurs sont tirées de la sortie du nœud OpenAI. Nous pouvons les glisser et les déposer dans les colonnes.
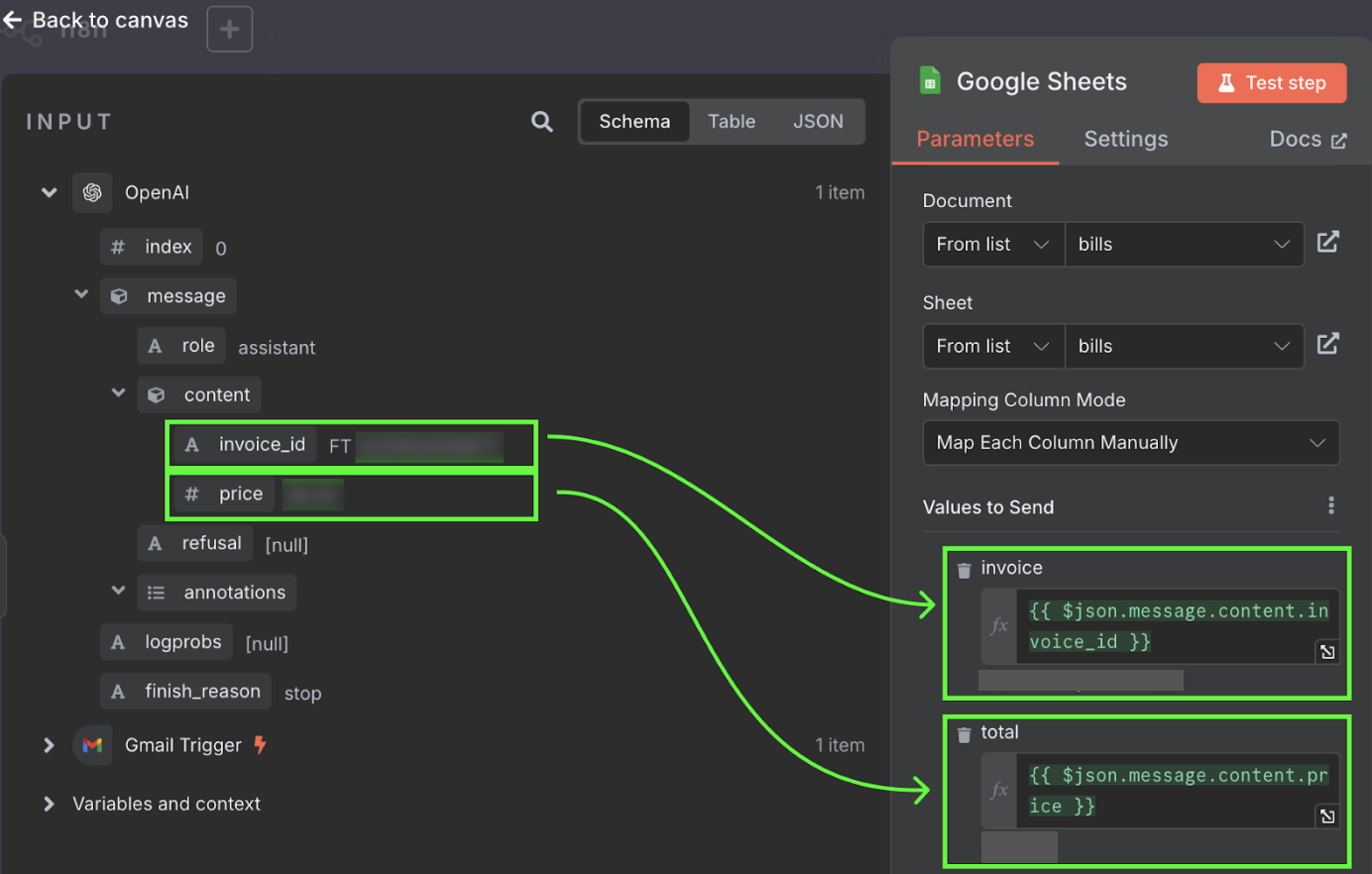
C'est tout ! Nous disposons d'un flux de travail qui traite automatiquement nos factures dans une feuille Google. Nous pouvons le tester en cliquant sur "Test workflow" en bas de page :
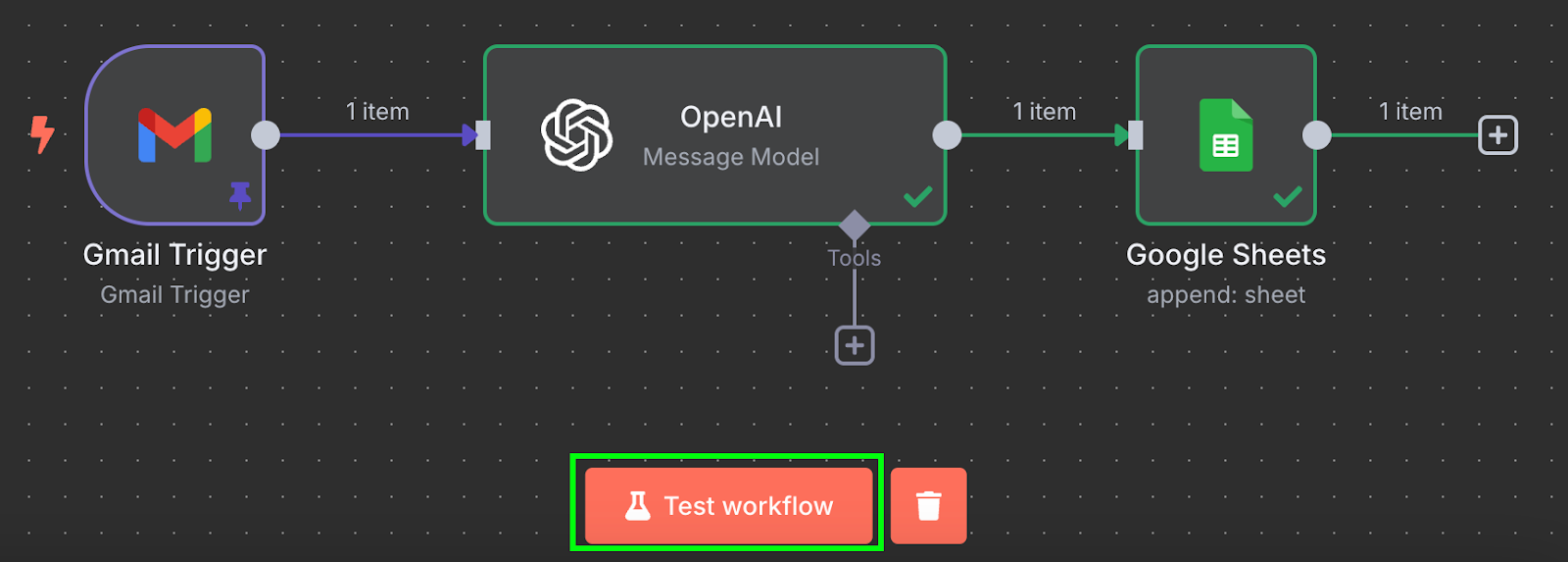
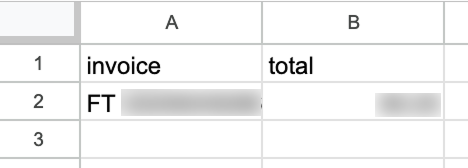
Après l'avoir exécuté, si nous allons dans notre feuille Google, nous verrons une nouvelle ligne avec les données :
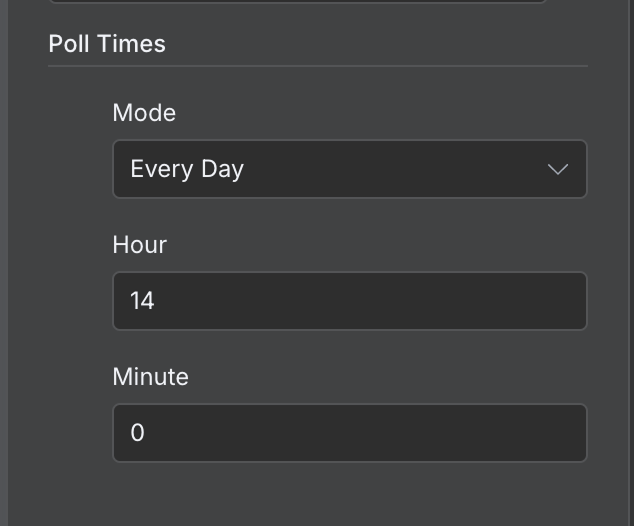
Par défaut, un flux de travail est exécuté toutes les minutes. En fonction du flux de travail, nous devons configurer une fréquence d'exécution appropriée. Dans cet exemple précis, une fois par minute est beaucoup trop fréquent. Une fois par jour est une fréquence plus appropriée.
Nous pouvons configurer cela en double-cliquant sur le nœud du déclencheur et en définissant une valeur différente dans le champ "Poll Times" :
Dans cette section, nous construisons un flux de travail plus complexe pour l'agent RAG. RAG est l'abréviation de "retrieval-augmented generation", une technique qui consiste à extraire des informations pertinentes d'une base de données ou d'un document, puis à utiliser un modèle linguistique pour générer des réponses basées sur les informations extraites.
Ceci est très utile lorsque nous disposons d'une base de connaissances spécifique, telle qu'un long document textuel, et que nous voulons construire un agent d'intelligence artificielle capable de répondre à des questions à ce sujet.
J'aime jouer à des jeux de société, mais mes amis et moi nous disputons souvent au sujet des règles et passons du temps à chercher les bonnes règles au lieu de jouer, ce qui peut être frustrant. La construction d'un agent RAG basé sur les règles du jeu est une bonne solution pour résoudre ce problème, car la prochaine fois que nous aurons une question, il nous suffira de la poser à l'agent.
Pour créer cet agent, nous allons suivre deux flux de travail :
Pinecone est un type de base de données qui gère les données sous forme de vecteurs. Une base de données vectorielle comme Pinecone est très utile à notre agent RAG car elle l'aide à rechercher et à comprendre rapidement les informations pertinentes, ce qui lui permet de fournir plus efficacement des réponses précises.
Comme nous ne devons exécuter ce flux de travail qu'une seule fois, nous pouvons utiliser un nœud de déclenchement manuel. Il s'agit d'un nœud de déclenchement utilisé pour exécuter manuellement un flux de travail.
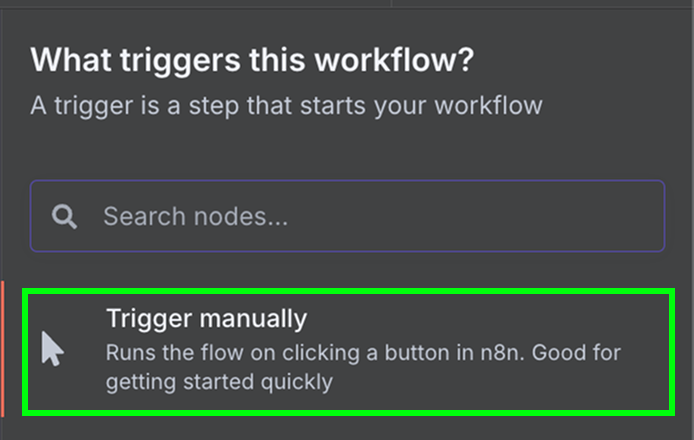
Connectez le nœud de déclenchement manuel à un nœud "Google Drive" pour télécharger les données depuis Google Drive.

Utilisez la configuration suivante :
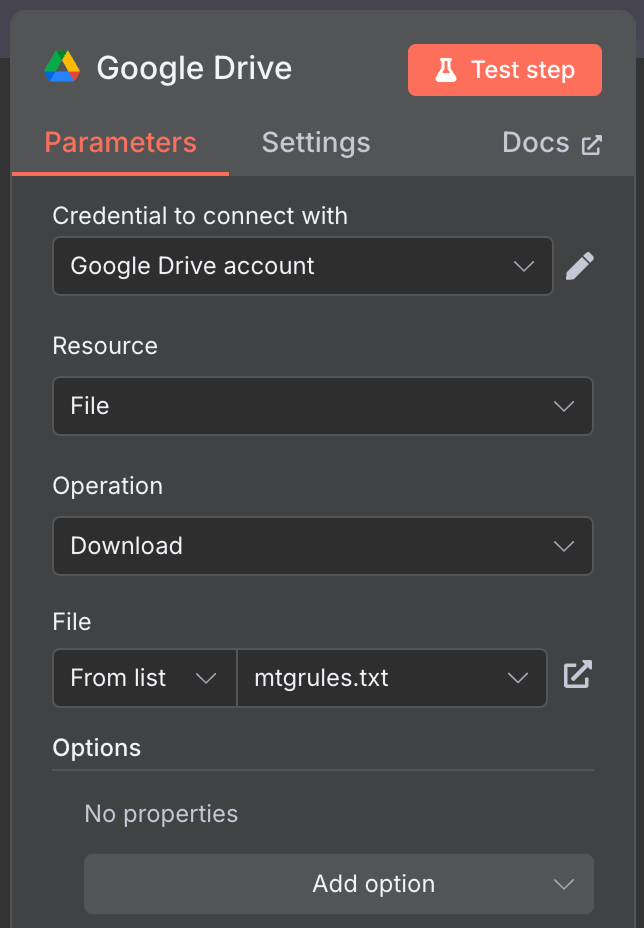
J'ai utilisé le fichier mtgrules.txt accessible au public et contenant les règles du jeu de cartes à collectionner Magic : The Gathering. Vous pouvez utiliser n'importe quel fichier sur lequel vous souhaitez poser des questions ; le processus est le même.
Pour configurer Pinecode, connectez-vous à Pineconecopiez la clé API et créez un index en cliquant sur le bouton "Créer un index". J'ai appelé mon index rules et j'ai sélectionné le modèle text-embedding-3-small.

De retour à n8n, connectez la sortie du nœud Google Drive à un nœud Pinecone Vector Store pour l'action "Add documents to vector store" :
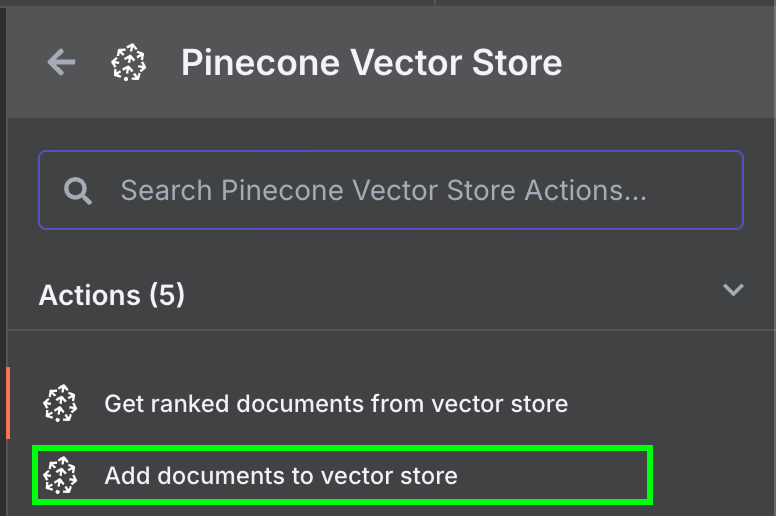
Pour configurer le nœud, nous devons créer un identifiant en collant la clé API et en sélectionnant l'index Pinecone que nous venons de créer. Sous le nœud Pinecone Vector Store, nous voyons deux choses que nous devons configurer : un modèle d'intégration et un chargeur de données.
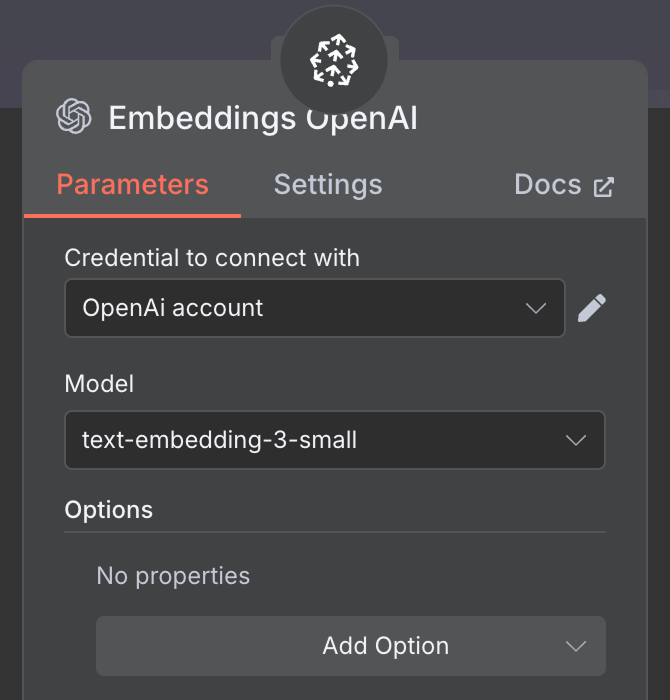
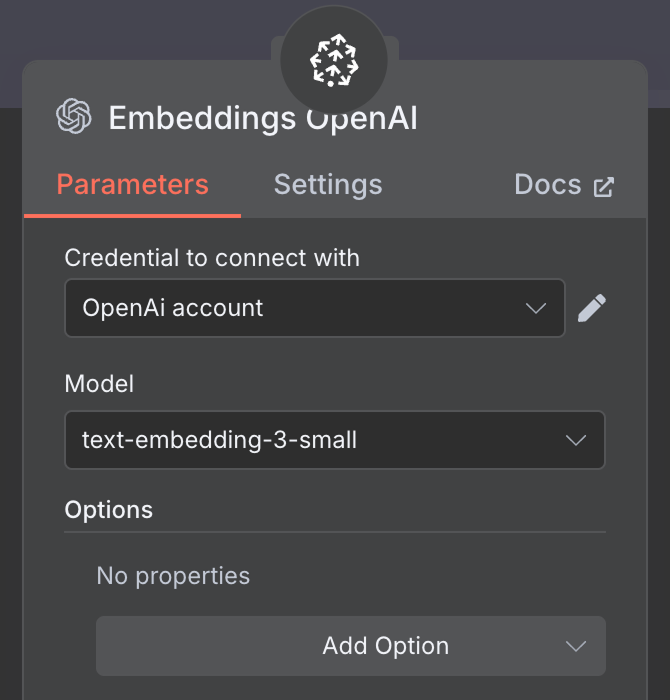
Pour l'intégration, créez un nœud OpenAI Embedding avec le modèle text-embedding-3-small:
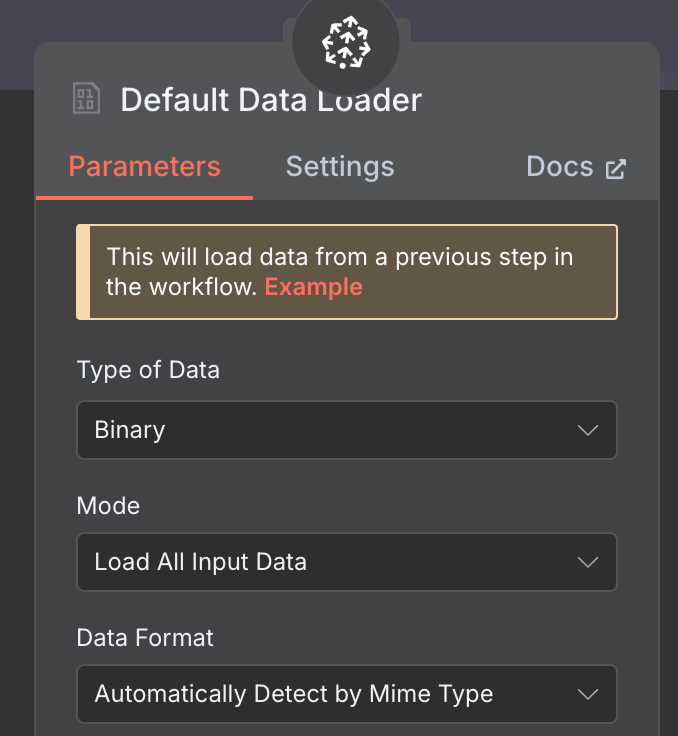
Pour le chargeur de données, nous créons un nœud Chargeur de données par défaut avec un type de données binaires :
Enfin, le chargeur de données nécessite un nœud Text Splitter, qui spécifie comment les données du fichier doivent être divisées lors de la création du magasin vectoriel. Nous utilisons le nœud Recursive Character Text Splitter, qui est le nœud recommandé pour la plupart des applications.
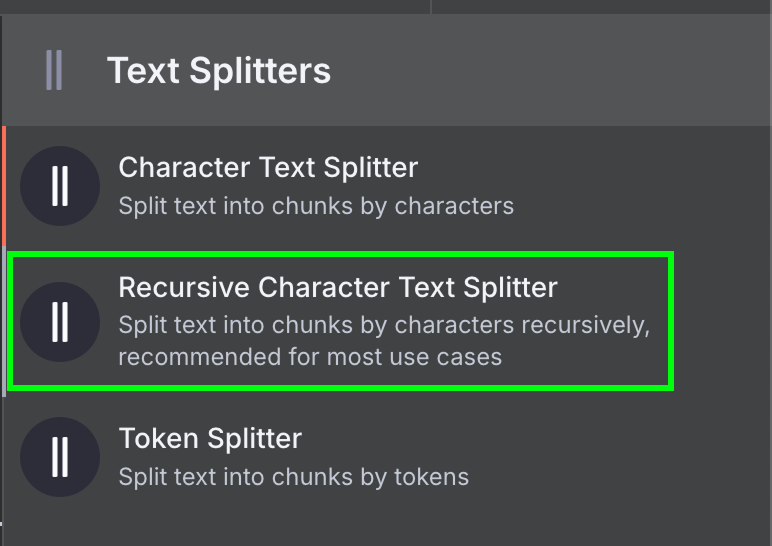
Nous le configurons pour qu'il utilise une taille de bloc de 1 000 et un chevauchement de bloc de 200 :
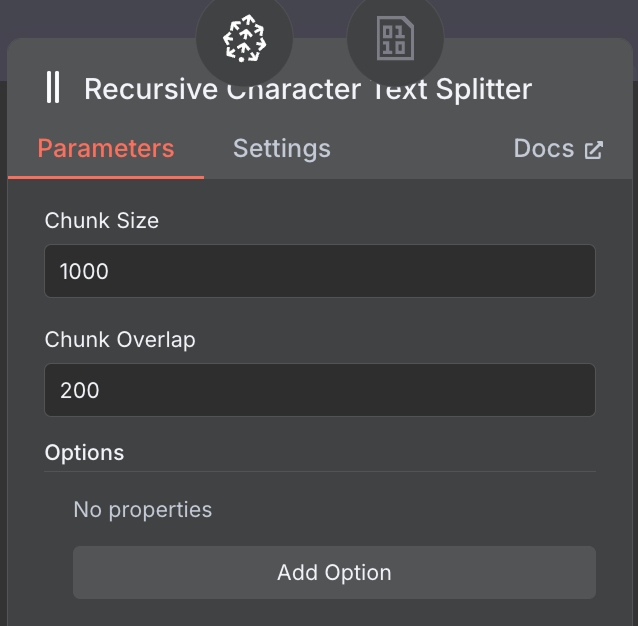
Lors du choix de la taille et du chevauchement des morceaux, envisagez d'utiliser une taille de morceau plus importante pour les documents longs afin de capturer le contenu adéquat et un chevauchement plus petit pour maintenir le contexte entre les segments sans redondance.
Voici à quoi ressemble le flux de travail final :
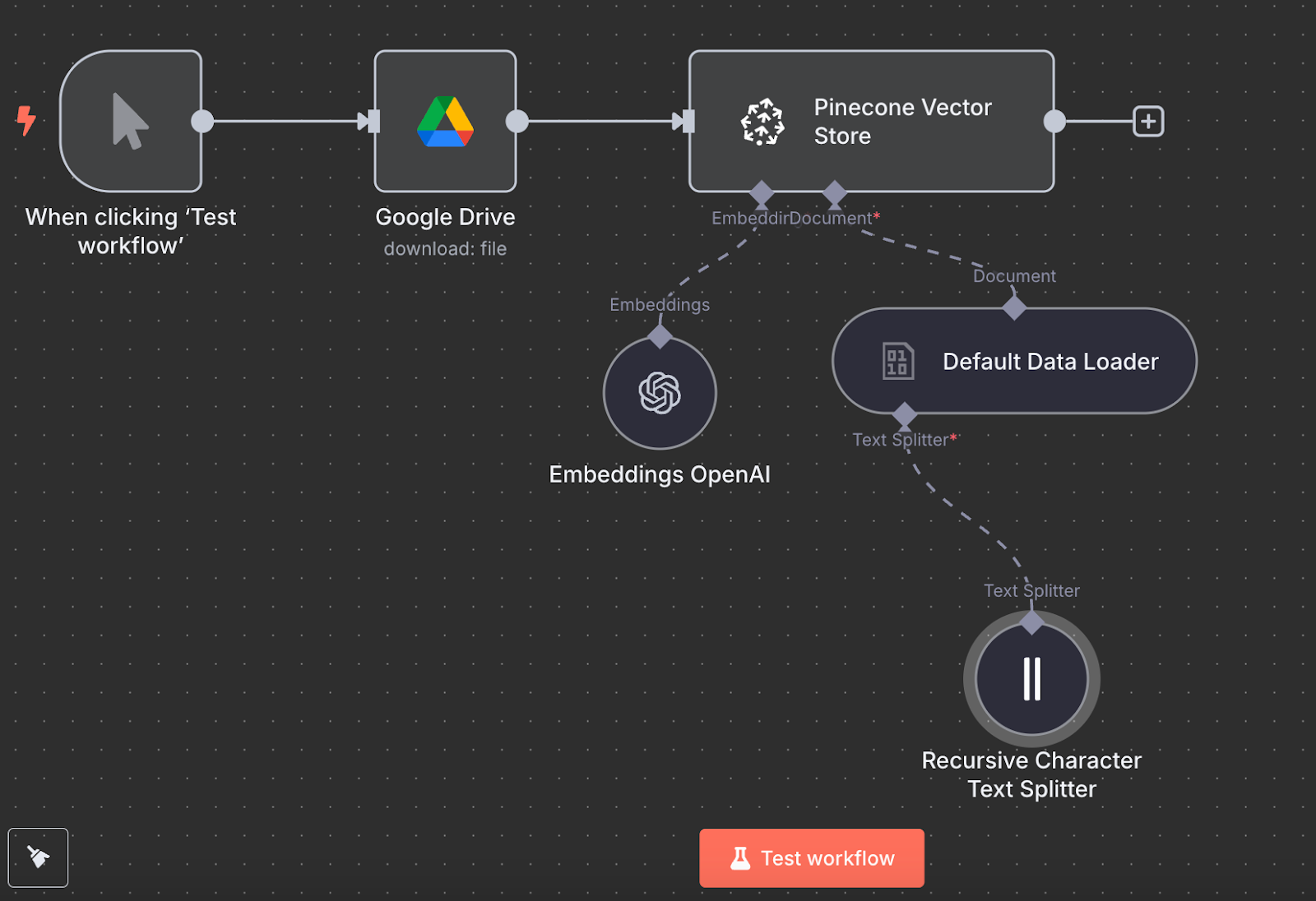
Nous pouvons l'exécuter en cliquant sur "Test workflow", et une fois que c'est fait, nous pouvons vérifier dans Pinecone que les données ont été chargées.
Voici le schéma final de l'agent RAG :
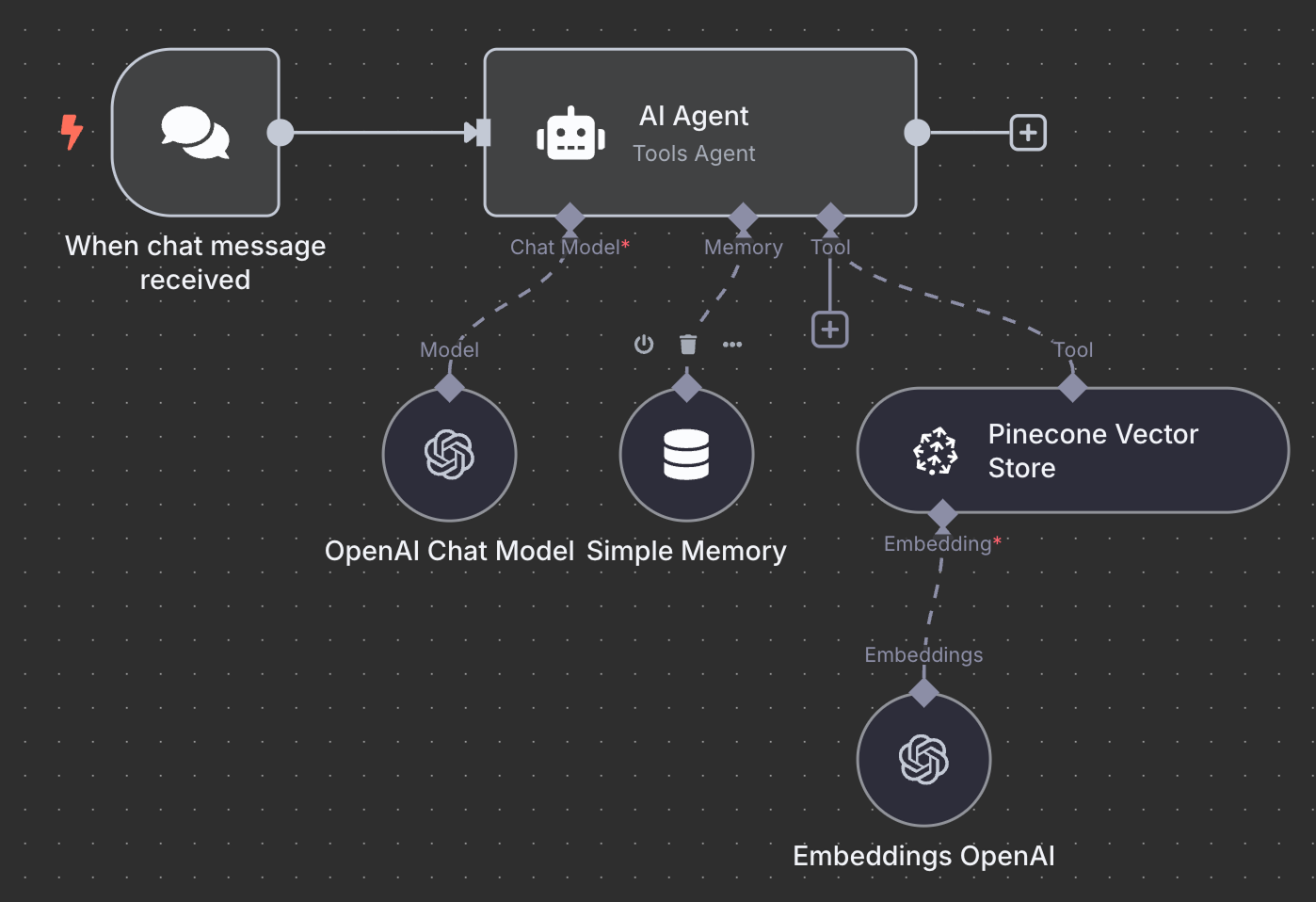
À titre d'exercice, je vous encourage à essayer de le comprendre et peut-être même de le recréer localement avant de poursuivre votre lecture.
Nous commençons par un nœud de déclenchement "Sur message de chat". Cette fonction est utilisée pour créer un flux de travail de chat.
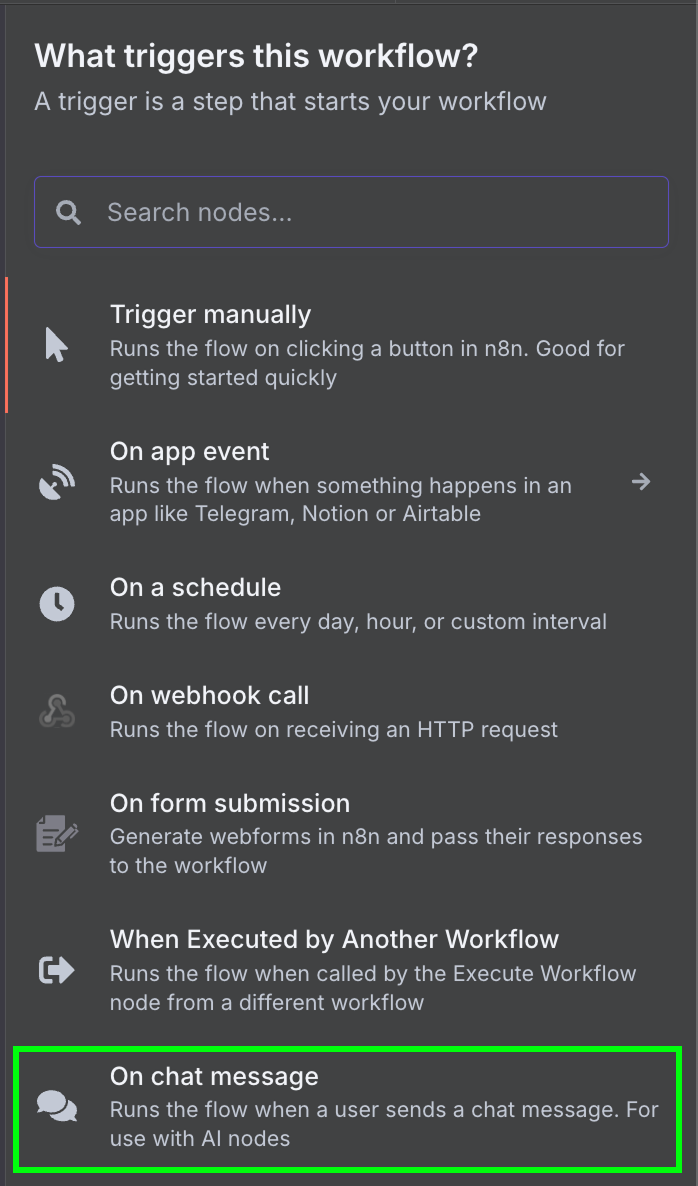
Ensuite, nous connectons le déclencheur de chat à un nœud "AI Agent" avec les options par défaut.
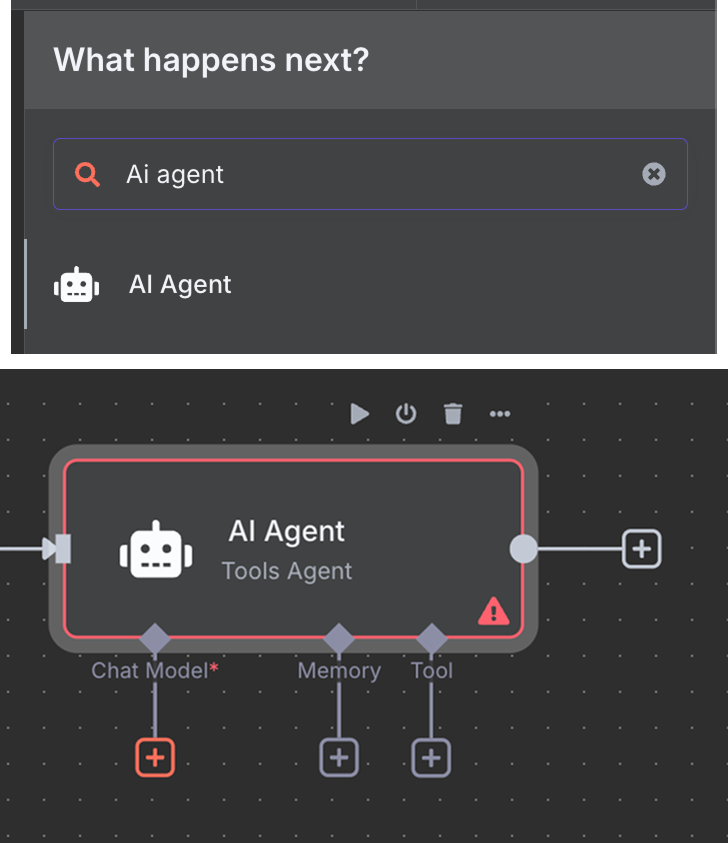
Sous l'agent AI, nous voyons que nous pouvons configurer trois choses :
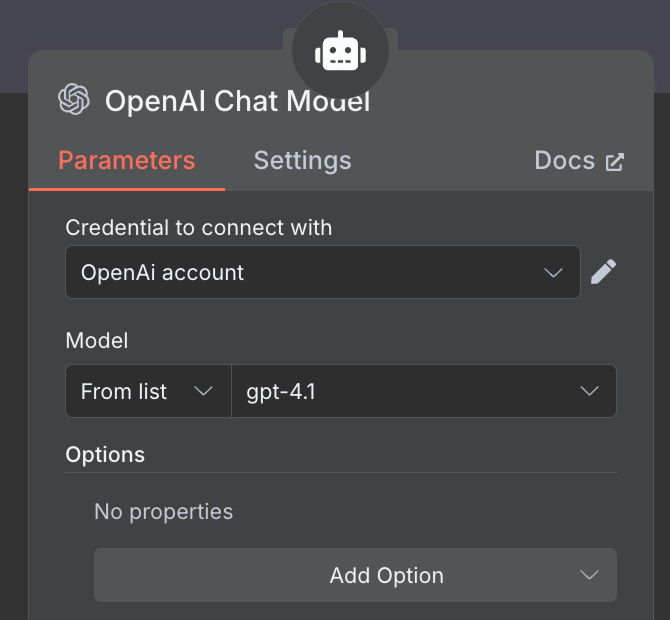
Pour le modèle d'IA, nous sélectionnons un nœud "OpenAI Chat Model" et utilisons le modèle gpt-4.1:
Pour la mémoire, nous utilisons un nœud "Simple Memory" avec une fenêtre contextuelle de longueur 5. Cela signifie que l'agent se souviendra et prendra en compte les cinq interactions précédentes lorsqu'il répondra.
Enfin, dans l'outil, nous ajoutons un nœud "Pinecone Vector Store" avec la configuration suivante :
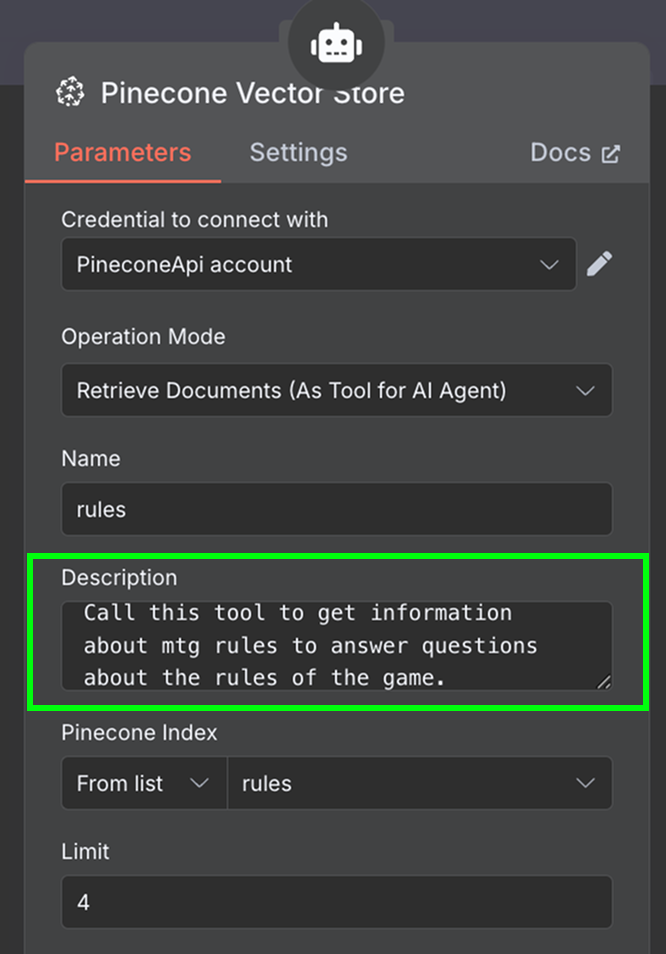
Dans le champ de description, il est important de préciser quand les outils doivent être utilisés. C'est ce que l'agent utilisera pour déterminer s'il doit appeler l'outil.
La dernière chose dont nous avons besoin est de configurer l'intégration utilisée par le magasin de vecteurs. Comme précédemment, nous utilisons un nœud OpenAI Embedding avec le modèle text-embedding-3-small:
Le flux de travail est terminé et nous pouvons discuter avec l'agent. En voici un exemple :
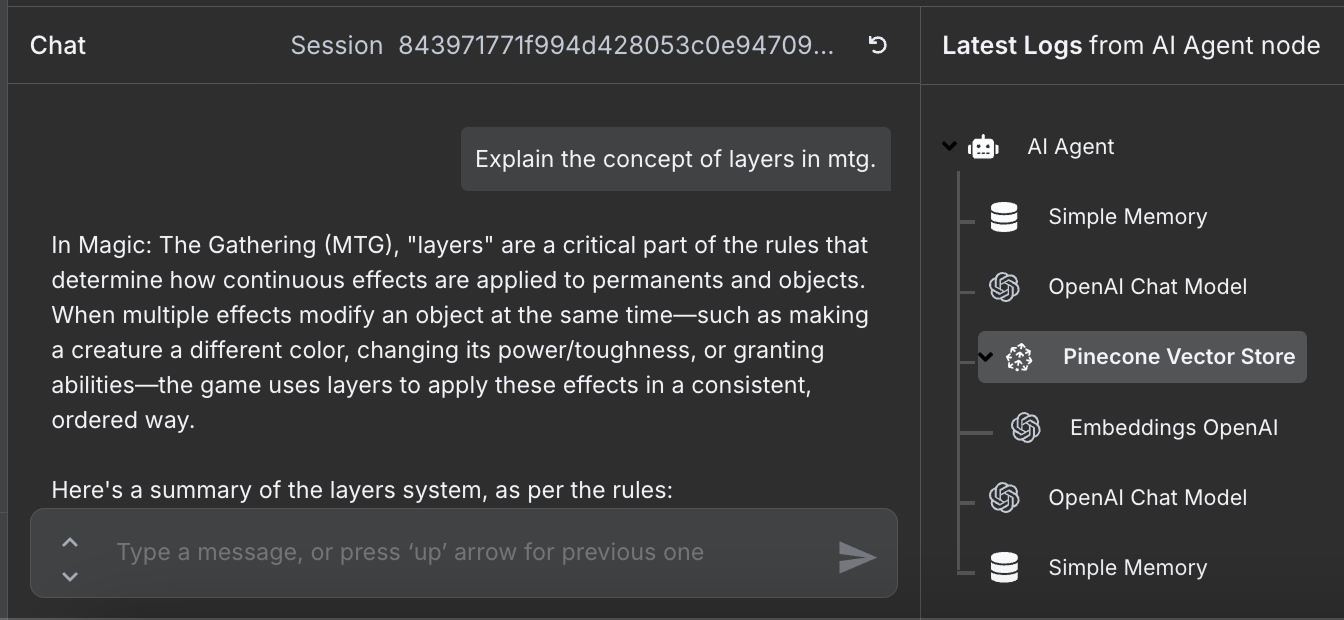
Nous pouvons voir sur la droite les étapes que l'agent a suivies pour répondre à notre question. En particulier, il accède à la base de données Pinecone pour récupérer les informations pertinentes sur les règles.
n8n offre une fonction utile qui peut accélérer de manière significative notre processus de création de flux de travail : la bibliothèque de modèles n8n.
Cette bibliothèque est une collection de flux de travail préconstruits, élaborés par la communauté et les experts n8n. Que nous cherchions à automatiser des tâches simples ou des processus plus complexes, il y a de fortes chances que quelqu'un ait déjà mis au point un flux de travail adapté à nos besoins.
L'importation d'un flux de travail dans notre installation n8n nous permet de ne pas toujours repartir de zéro. Au lieu de cela, nous pouvons tirer parti des solutions créatives développées par d'autres utilisateurs. Une fois que nous avons importé un flux de travail, il ne nous reste plus qu'à le configurer avec nos informations d'identification et à l'adapter à nos besoins exacts.
Pour toute tâche que nous souhaitons automatiser, du traitement des courriels à la gestion des médias sociaux, il est fort probable qu'il existe un modèle dans la bibliothèque.
n8n offre un vaste écosystème d'intégrations, nous permettant de connecter plus d'un millier de services et d'outils pour créer des agents d'intelligence artificielle. Nous n'avons fait qu'effleurer les possibilités de n8n dans ce tutoriel. En explorant la manière d'utiliser le n8n pour créer des agents d'intelligence artificielle afin d'automatiser les tâches quotidiennes, nous n'avons fait que commencer à exploiter son potentiel.
Apprenez l'IA avec ces cours !
Cursus
Cours
blog
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Moez Ali
