
Programa
Desenvolvimento de aplicativos de IA
21 h
n8n vem se consolidando como um framework popular e poderoso em IA agentiva. Ele permite criar fluxos de trabalho automatizados sem precisar de código complexo.
Neste artigo, vou explicar passo a passo como aproveitar ao máximo essa plataforma robusta para automatizar dois processos distintos:
Mantemos nossos leitores atualizados sobre o que há de novo em IA com a The Median, nossa newsletter gratuita de sexta-feira que resume as principais notícias da semana. Assine e fique por dentro em poucos minutos por semana:
n8n é uma ferramenta de automação open source que ajuda a conectar diversos apps e serviços para criar fluxos, como uma linha de montagem digital. Você pode desenhar esses fluxos visualmente com nós (nodes), cada um representando uma etapa do processo.
Com o n8n, dá para automatizar tarefas, orquestrar o fluxo de dados e até integrar APIs, sem precisar de grandes conhecimentos de programação. Aqui vai um exemplo de automação que vamos construir neste tutorial:
Sem entrar nos detalhes, aqui vai o que essa automação faz:
Temos duas opções para usar o n8n:
As duas opções permitem seguir este tutorial sem custo. Vamos rodar localmente, mas se preferir a interface web, os passos são os mesmos.
Observação: o n8n 2.0 foi lançado no fim de 2025 e introduziu um sistema de rascunho/publicação de workflows, salvamento automático (janeiro de 2026), um painel de foco atualizado para editar nós sem perder o contexto do canvas e Task Runners que isolam a execução do workflow para mais segurança.
Os workflows abaixo rodam na versão 2.x — se você estiver na 1.x, considere atualizar antes de seguir.
O repositório oficial do n8n explica como configurar o n8n localmente. A forma mais simples é:
Baixar e instalar o Node.js pelo site oficial.
Abrir um terminal e rodar o comando npx n8n.
Pronto! Depois de rodar o comando, você deve ver isto no terminal:
Para abrir a interface, pressione "o" no teclado ou acesse o URL do localhost mostrado no terminal — no meu caso, http://localhost:5678.
Antes de construir nossa primeira automação, vale entender como o n8n funciona. Um workflow no n8n é composto por uma sequência de nós. Ele começa com um nó de disparo (trigger) que define a condição para executar o fluxo.
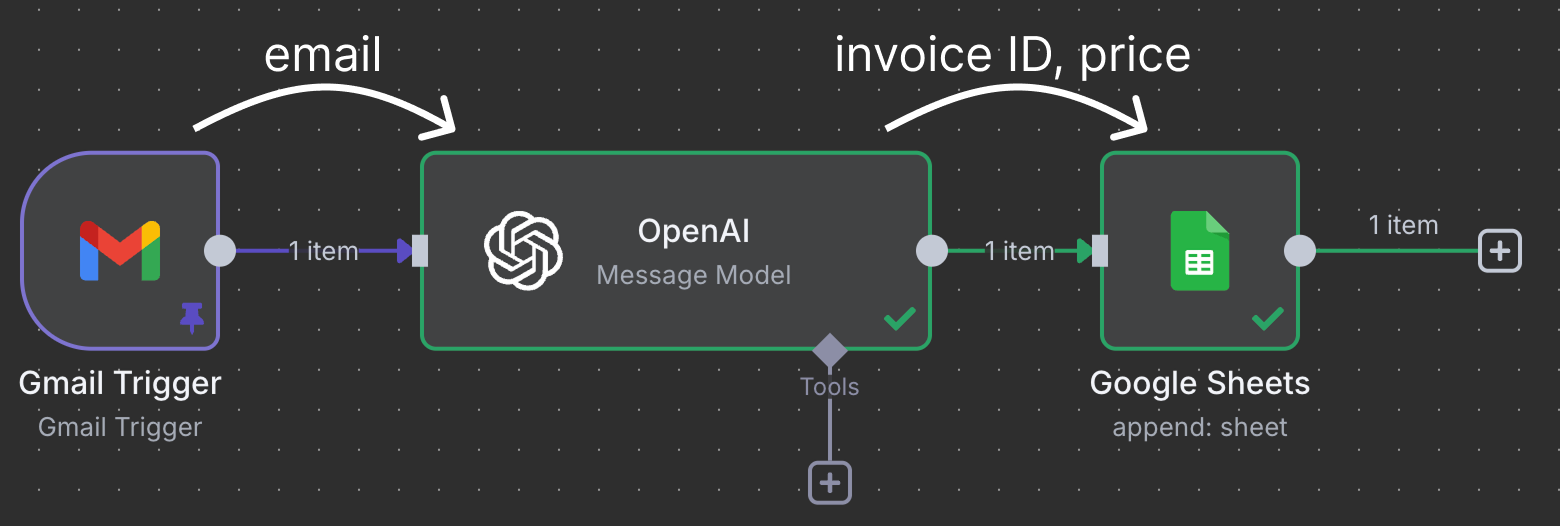
Os nós se conectam para mover e processar dados. Neste exemplo, o nó de trigger do Gmail conecta a um nó da OpenAI. Isso significa que o e-mail é enviado ao ChatGPT para processamento. Por fim, a saída do ChatGPT vai para um nó do Google Sheets, que se conecta a uma planilha no nosso Google Drive e escreve uma nova linha na planilha.
Este workflow usa o ChatGPT para identificar faturas que precisam ser pagas e registra na planilha o ID da fatura e o valor.
Workflows no n8n podem ser bem mais complexos. O n8n tem mais de 400 integrações oficiais (nós core), mais 600+ nós criados pela comunidade e conexões personalizadas via nó HTTP Request — então não dá para cobrir tudo em um único tutorial.
Em vez disso, vou te dar uma visão geral de como funciona e a base necessária para você explorar por conta própria. Se existe uma ferramenta que você usa no dia a dia, é bem provável que o n8n já ofereça suporte ou que você consiga integrá-la manualmente.
Nesta seção, vamos construir o workflow acima.
É um caso real que uso para gerenciar as faturas do meu aluguel. Tenho uma casa com alguns quartos que eu alugo. As contas são divididas igualmente entre todos os inquilinos. Toda vez que recebo uma fatura, preciso adicionar o total em uma planilha compartilhada com eles.
Tenho um endereço de e-mail específico para o qual encaminho as faturas das contas da casa. Assim, sei que todos os e-mails nessa caixa correspondem a uma fatura. Eu envio o conteúdo do e-mail para o ChatGPT identificar o ID da fatura e o valor total a pagar. Em seguida, essa informação é adicionada a uma nova linha na planilha compartilhada.
Para iniciar um novo workflow, clique no botão "Add first step...".

Como é o primeiro nó, ele precisa ser um trigger, então aparece um painel para escolher o nó de disparo. Um trigger define as condições para executar o workflow.
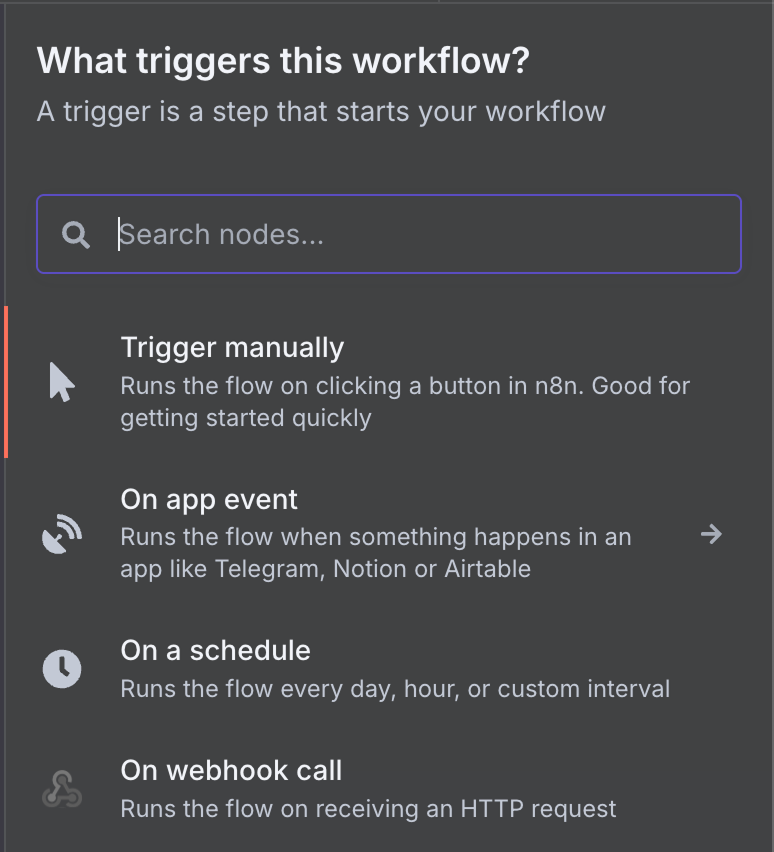
Há uma variedade grande de triggers possíveis. Vamos selecionar um trigger do Gmail digitando "gmail" na busca e clicando no nó do Gmail.
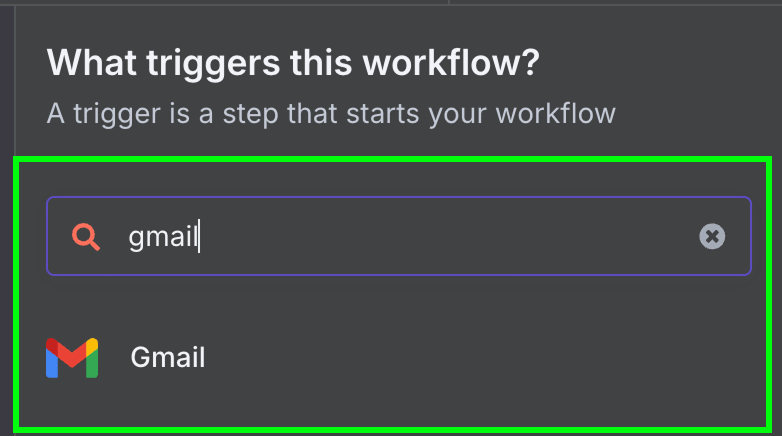
Em seguida, escolhemos o único trigger disponível para Gmail: "On message received".

Isso abre o painel de configuração do nó, onde precisamos configurar as credenciais do Gmail para permitir que o workflow do n8n acesse nossa conta. Para isso, clique em "New credential". A janela a seguir será aberta:
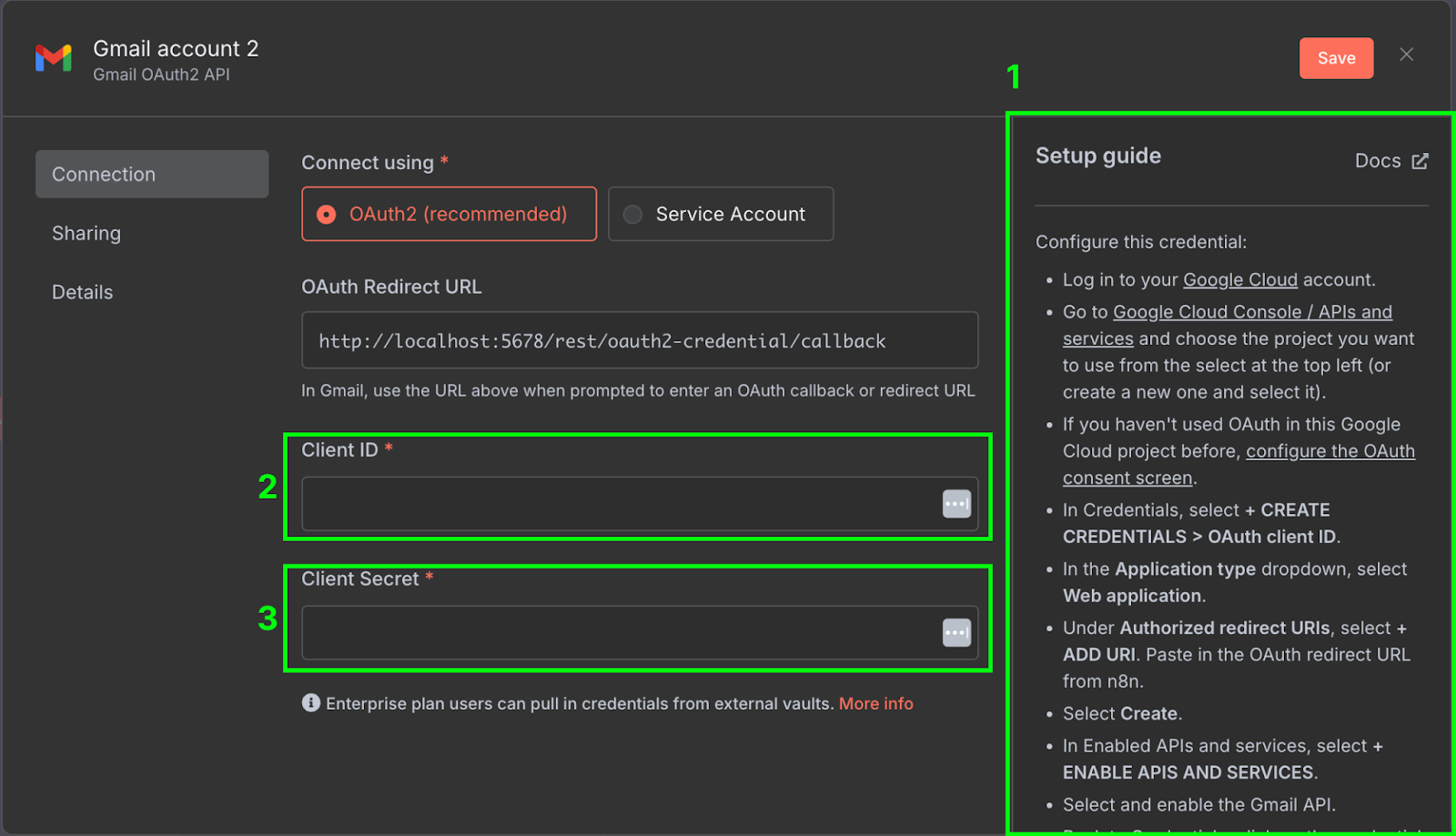
À direita (1), há um guia com os passos para configurar as credenciais no Google Cloud. Os guias do n8n são bem completos, então não vamos repetir os passos aqui. Lembre-se de habilitar também a Gmail API no Google Cloud Console.
Depois de configurar, copie o client ID (2) e o client secret (3) do Google Cloud para a configuração de credencial no n8n.
Para confirmar que está tudo certo, podemos testar o nó clicando em "Fetch Test Event".

Após o teste, devemos ver na saída o e-mail mais recente recebido na caixa de entrada. O conteúdo do e-mail está no campo snippet.
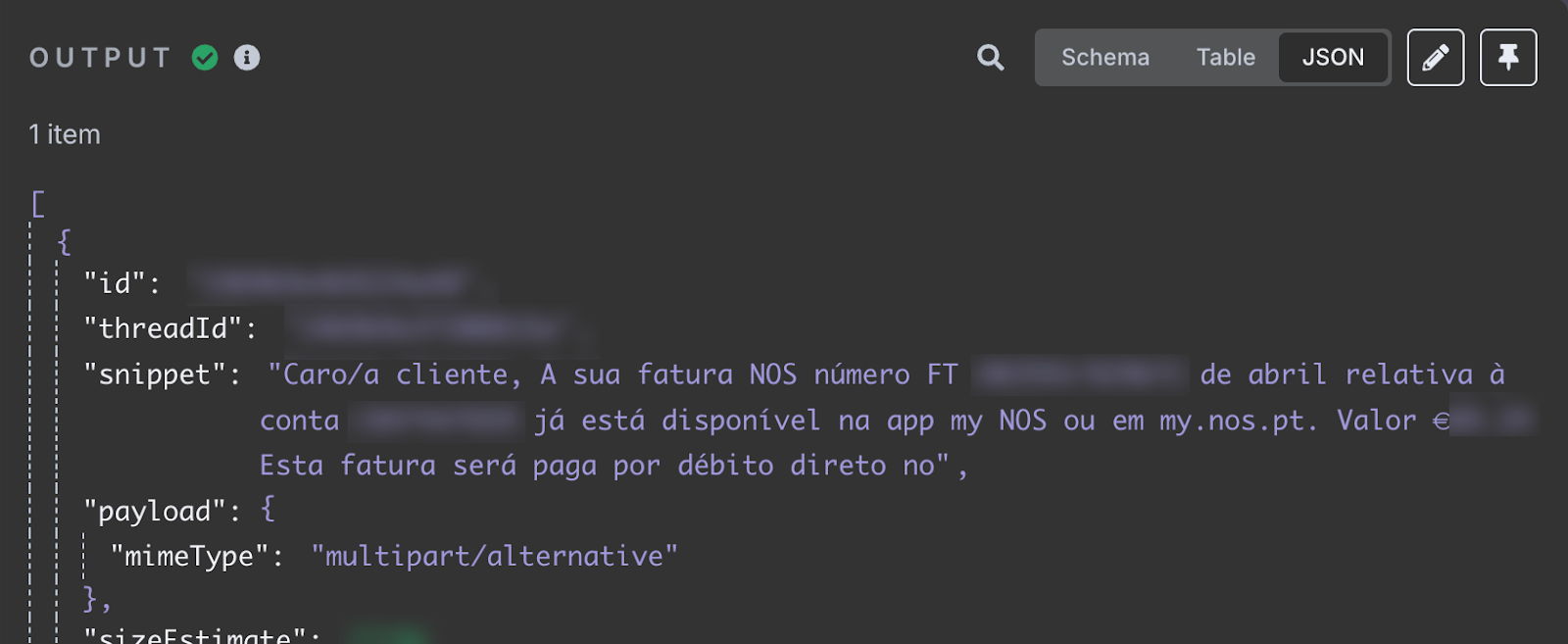
O campo snippet armazena o conteúdo do e-mail. Ele diz que minha fatura de internet de abril está disponível, informando o ID e o valor total a pagar. É isso que queremos adicionar à planilha.
Para testes, recomendo fixar a saída clicando no ícone de alfinete no canto superior direito:
Isso trava o resultado no trigger, ou seja, sempre que rodarmos o workflow, será usada a mesma saída, facilitando os testes porque novos e-mails não vão afetar o resultado. Vamos desfixar quando tudo estiver configurado.
Neste ponto, nosso workflow deve ter apenas um nó de trigger (identificado pelo pequeno raio à esquerda).

Note que, como você provavelmente não tem uma fatura de e-mail na caixa, mais adiante o ChatGPT pode gerar uma resposta sem sentido. Se quiser testar exatamente este fluxo, envie para si mesmo um e-mail de teste com o conteúdo abaixo (ou algo parecido):
Dear customer,
Your internet invoice number FT 2025**/****** for April is now available in the attachment.
Amount
€**.**
This invoice must be paid by 19/05/2025.Depois de enviar, desfixe o resultado, rode novamente o nó do Gmail e fixe a nova saída.
O próximo passo é configurar o nó da OpenAI. Comece clicando no botão "+" à direita do nó de trigger do Gmail:

Digite "OpenAI" e selecione a opção correspondente na lista.
Em "Text Actions", selecione o nó "Message a model". Esse nó serve para enviar mensagens a um LLM.

Como antes, precisamos criar uma credencial para acessar a OpenAI. Lembre que, depois de criada, a credencial pode ser reutilizada em qualquer workflow. Não é necessário configurar toda vez.
Para a credencial da OpenAI, tudo o que precisamos é uma chave de API. Se você não tiver, crie uma aqui. Se tiver dificuldade, o n8n também fornece um guia.
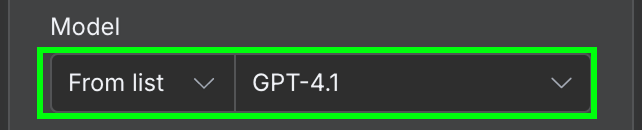
Na configuração, precisamos selecionar o modelo de IA e a mensagem que enviaremos ao modelo.
Para o modelo, usaremos o GPT-4.1. A OpenAI já lançou a família GPT-5 (5.4, 5.4-mini, 5.5) e aposentou o 4.1 no ChatGPT, mas ele ainda está disponível via API e é mais do que suficiente para uma extração simples como esta.
No campo da mensagem, precisamos fornecer o prompt. Neste exemplo, passamos ao modelo o conteúdo do e-mail e pedimos para identificar o ID da fatura e o valor total a pagar. Este foi o prompt que usei:
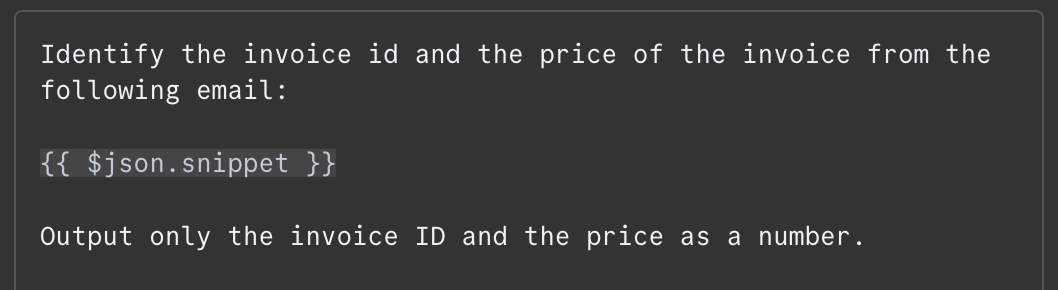
O conteúdo do e-mail é fornecido como {{ $json.snippet }}. No n8n, o prompt pode conter variáveis populadas a partir da saída de nós anteriores — no nosso caso, o e-mail. A lista de campos disponíveis aparece à esquerda. Você pode digitar o campo manualmente ou arrastar e soltar no prompt.
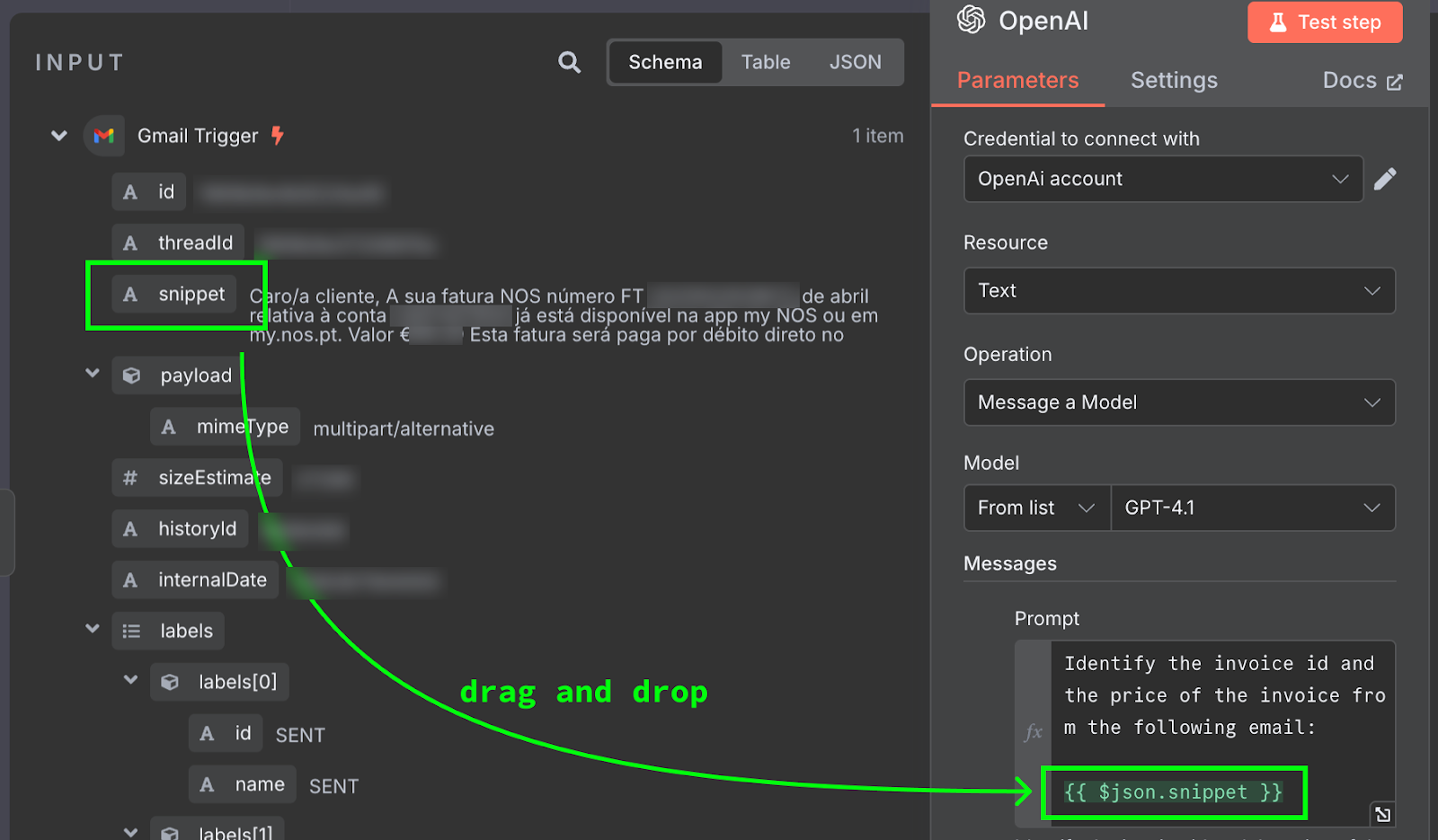
Para testar, clique em "Test Step" no topo do painel de configuração. O resultado aparece à direita:
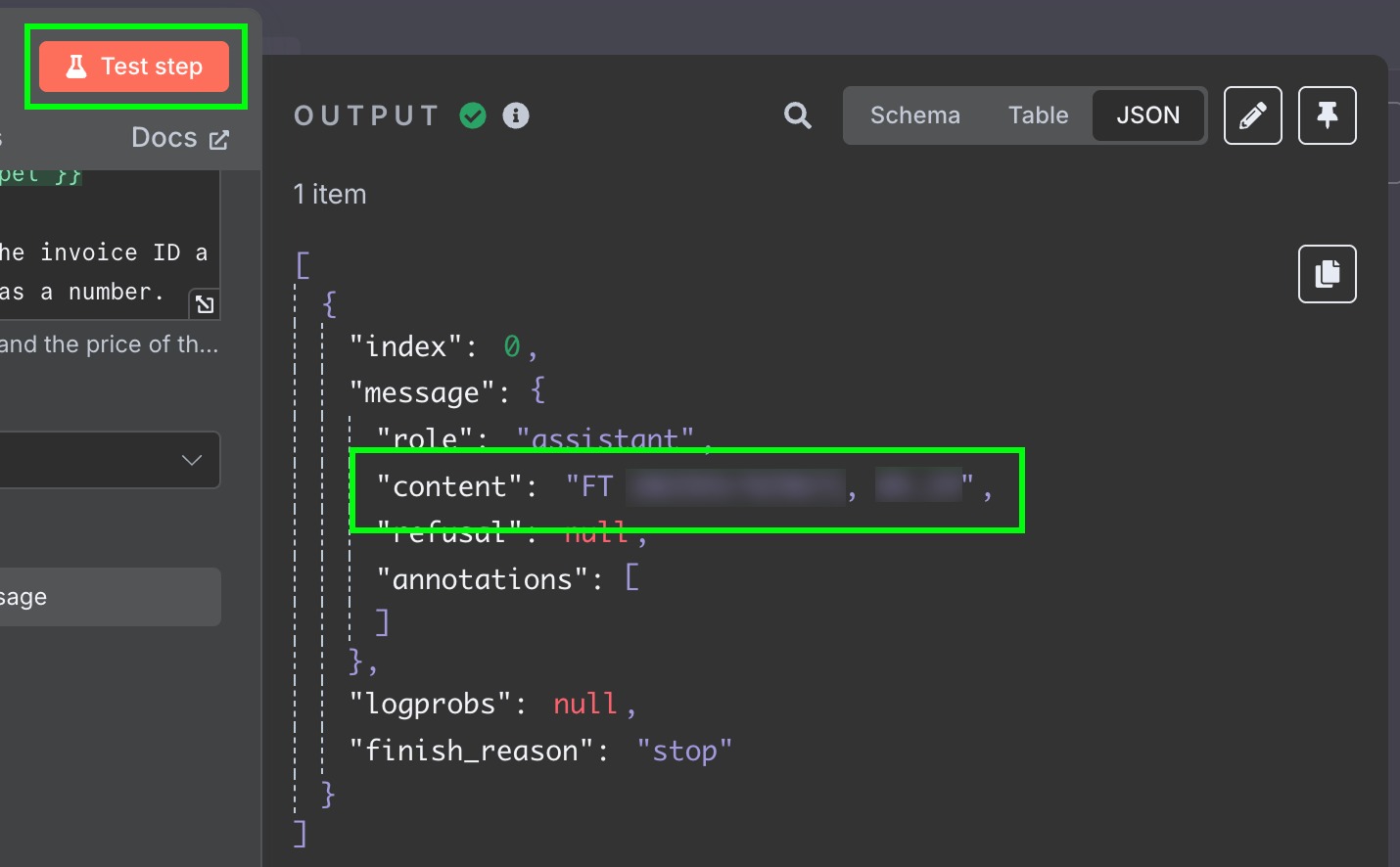
A saída é uma string com a resposta do modelo. Queremos ter os dois campos separados para não precisar processar a mensagem depois. Podemos fazer isso mudando a saída do LLM para JSON:

Testando novamente, obtemos os dois campos como dados JSON:
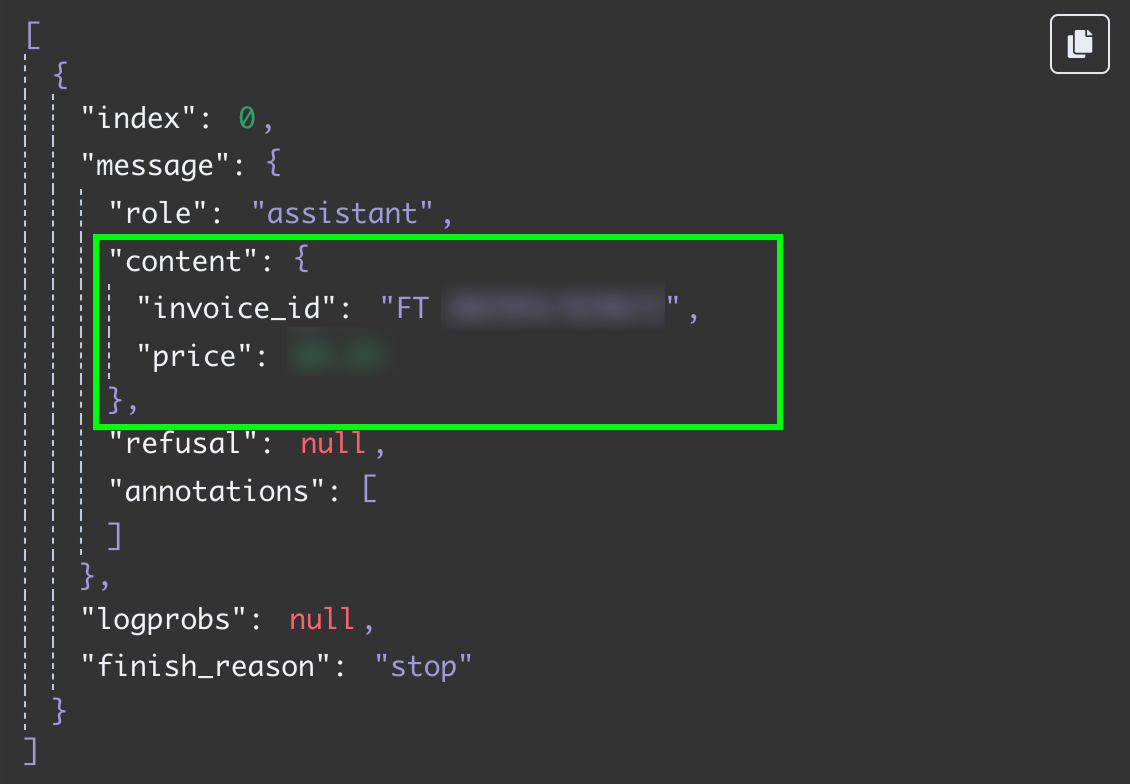
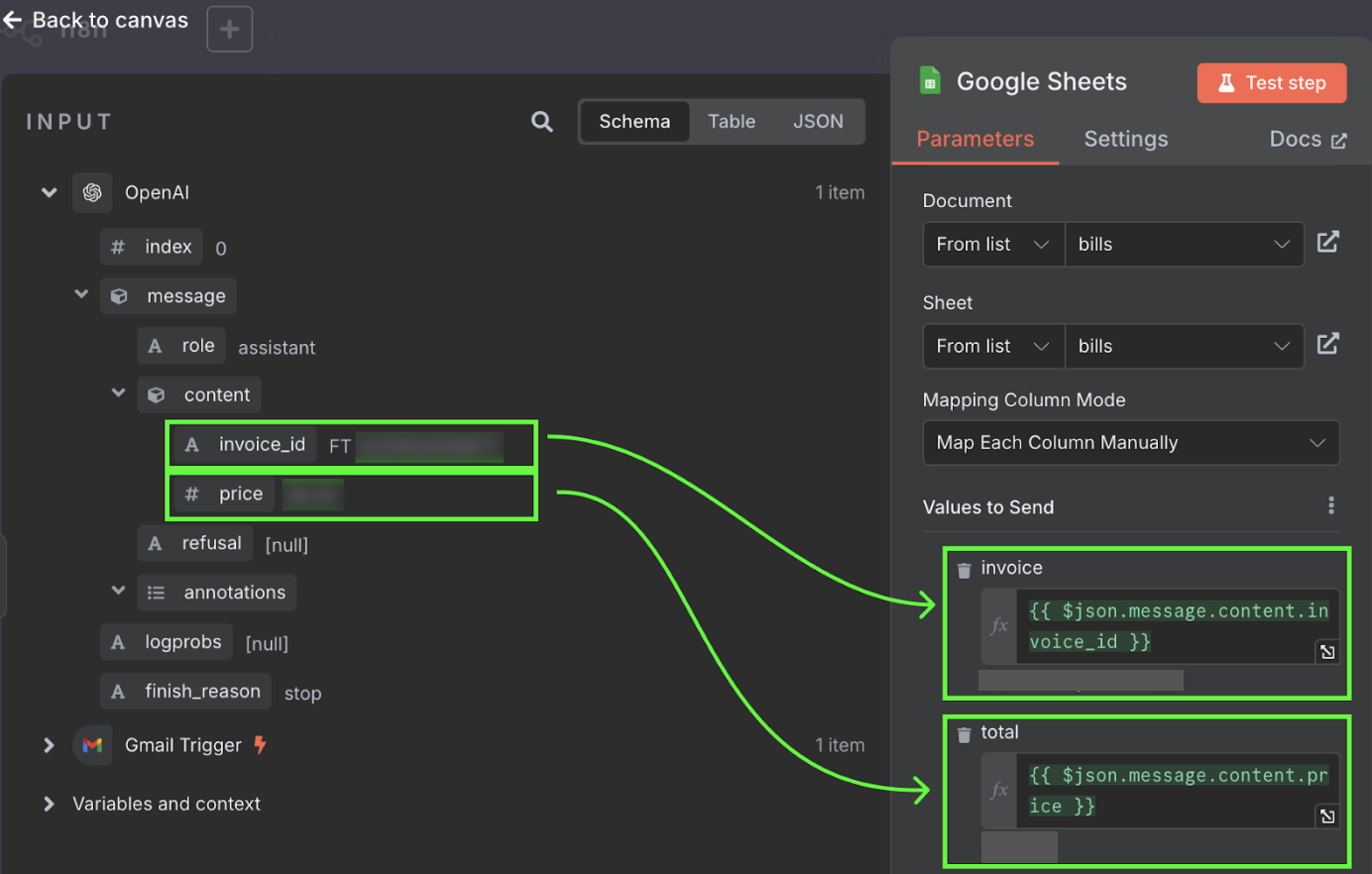
O passo final desse fluxo é enviar o ID da fatura e o valor para uma nova linha em uma planilha do Google. Agora, conectamos a saída do nó da OpenAI ao Google Sheets. Fazemos isso como antes, clicando no botão "+" à esquerda do nó:
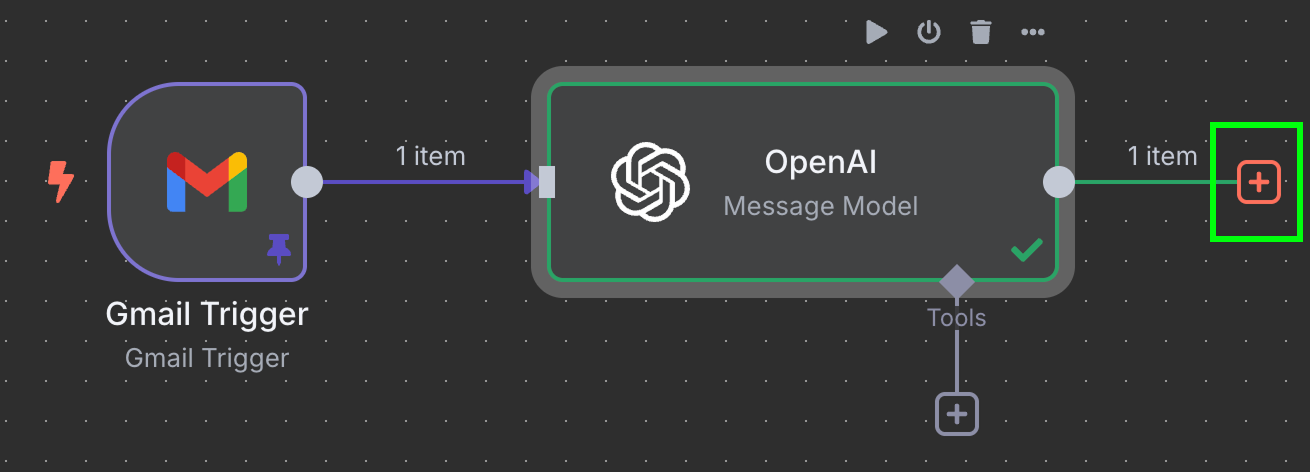
Digite Google Sheets e selecione o nó "Append row in sheet":
Podemos usar as mesmas credenciais usadas para o acesso ao Gmail. Mas é preciso habilitar estas APIs no Google Cloud Console:
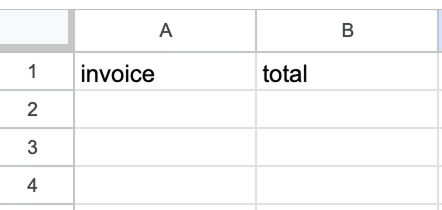
Para configurar o nó do Google Sheets, selecione a planilha e os valores que vão preencher os campos. A planilha deve ser criada manualmente com duas colunas: uma para o ID da fatura e outra para o total.
Esses valores vêm da saída do nó da OpenAI. Podemos arrastar e soltar para as colunas.
Pronto! Temos um fluxo que processa automaticamente nossas faturas em uma planilha do Google. Podemos testar clicando em "Test workflow" no rodapé:
Depois de rodar, ao abrir a planilha veremos uma nova linha com os dados:
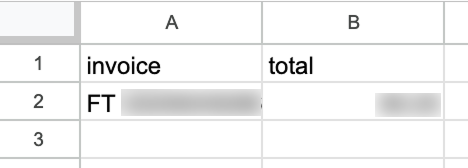
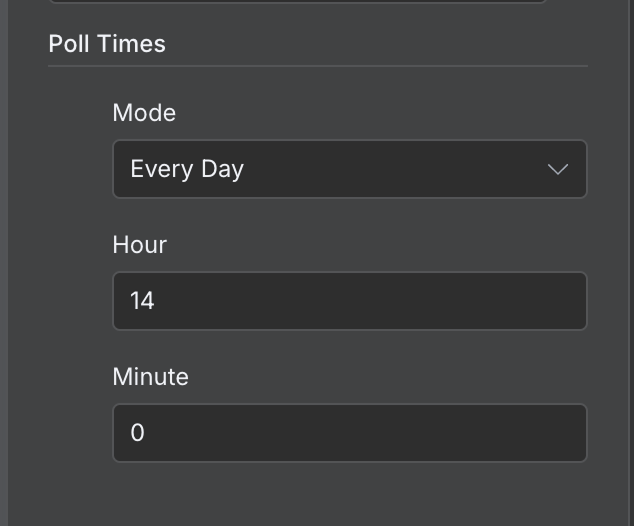
Por padrão, um workflow roda a cada minuto. Dependendo do fluxo, vale ajustar uma frequência mais adequada. Neste exemplo, a cada minuto é demais; uma vez por dia é mais apropriado.
Podemos configurar isso dando um duplo clique no nó de trigger e ajustando o campo "Poll Times":
Nesta seção, vamos criar um workflow de RAG mais complexo. RAG significa retrieval-augmented generation, uma técnica que combina a recuperação de informações relevantes de um banco de dados ou documento com o uso de um modelo de linguagem para gerar respostas baseadas no que foi recuperado.
Isso é muito útil quando temos uma base de conhecimento específica, como um documento longo, e queremos criar um agente de IA capaz de responder dúvidas sobre ele.
Eu gosto de jogos de tabuleiro, mas meus amigos e eu frequentemente discutimos as regras e perdemos tempo procurando a resposta em vez de jogar — o que é frustrante. Construir um agente RAG com as regras do jogo resolve esse problema, porque da próxima vez basta perguntar ao agente.
Para construir esse agente, faremos dois workflows:
Pinecone é um tipo de banco de dados que gerencia dados na forma de vetores. Um banco vetorial como o Pinecone é ótimo para nosso agente RAG porque ajuda a consultar e entender rapidamente informações relevantes, aumentando a precisão das respostas.
Como precisamos rodar esse fluxo só uma vez, podemos usar um nó de trigger manual. Ele serve para executar um workflow manualmente.
Conecte o trigger manual a um nó "Google Drive" para baixar os dados do Drive.

Use a configuração a seguir:
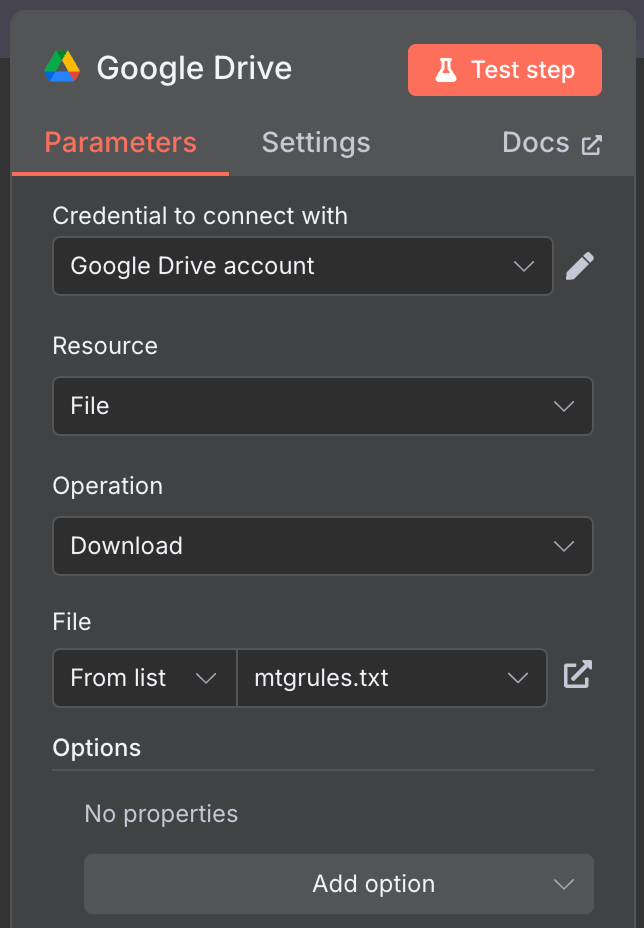
Usei o arquivo público mtgrules.txt com as regras do jogo de cartas Magic: The Gathering. Você pode usar qualquer arquivo sobre o qual queira fazer perguntas; o fluxo é o mesmo.
Para configurar o Pinecone, acesse o Pinecone, copie a chave de API e crie um índice clicando em "Create index". Chamei meu índice de rules e selecionei o modelo text-embedding-3-small.

De volta ao n8n, conecte a saída do nó do Google Drive a um nó Pinecone Vector Store com a ação "Add documents to vector store":
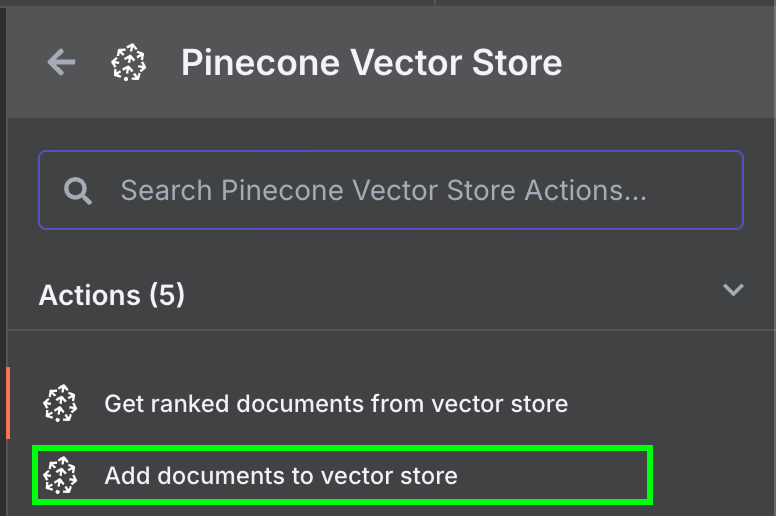
Para configurar o nó, crie uma credencial colando a chave de API e selecione o índice do Pinecone recém-criado. Abaixo do Pinecone Vector Store, vemos duas coisas a configurar: um modelo de embedding e um data loader.
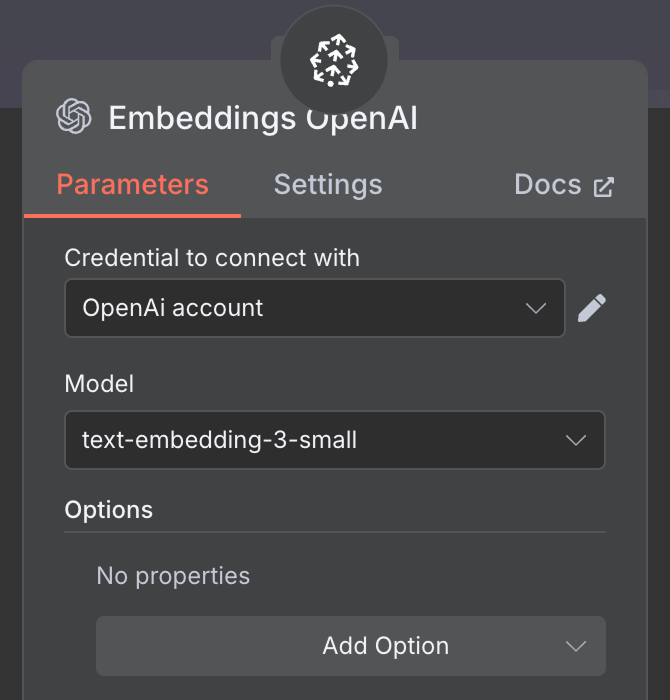
Para o embedding, crie um nó OpenAI Embedding com o modelo text-embedding-3-small:
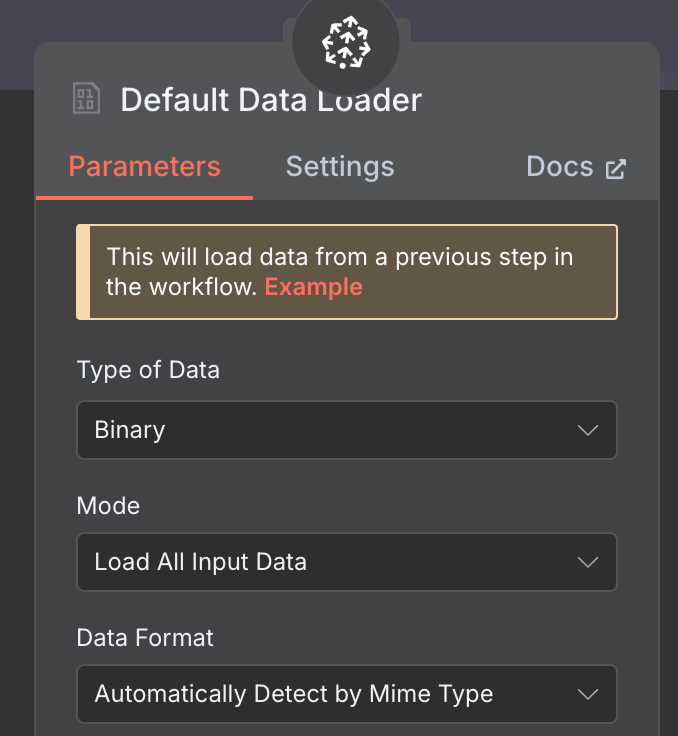
Para o data loader, crie um nó Default Data Loader com tipo de dados binário:
Por fim, o data loader requer um Text Splitter, que define como o arquivo será dividido ao criar o vetor. Usamos o nó Recursive Character Text Splitter, recomendado para a maioria dos casos.
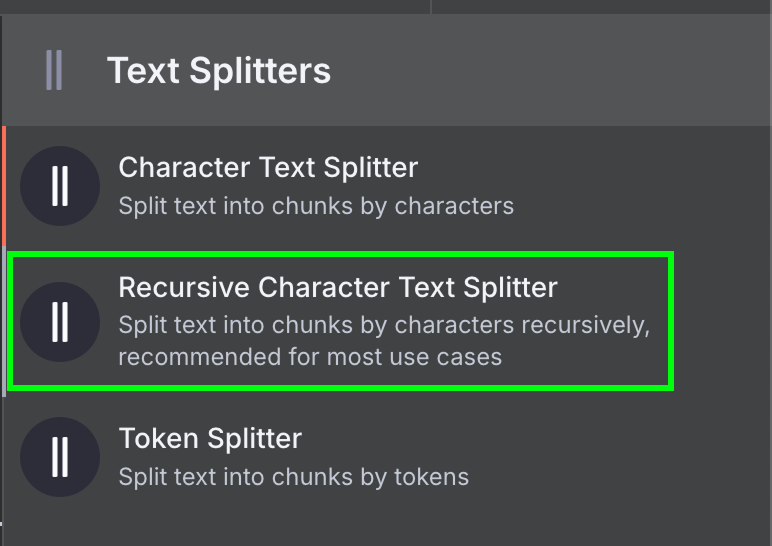
Configure com chunk size de 1.000 e chunk overlap de 200:
Ao escolher chunk size e overlap, considere usar um chunk maior para documentos longos, para capturar conteúdo suficiente, e um overlap menor para manter o contexto entre os trechos sem redundância.
Veja como fica o workflow final:
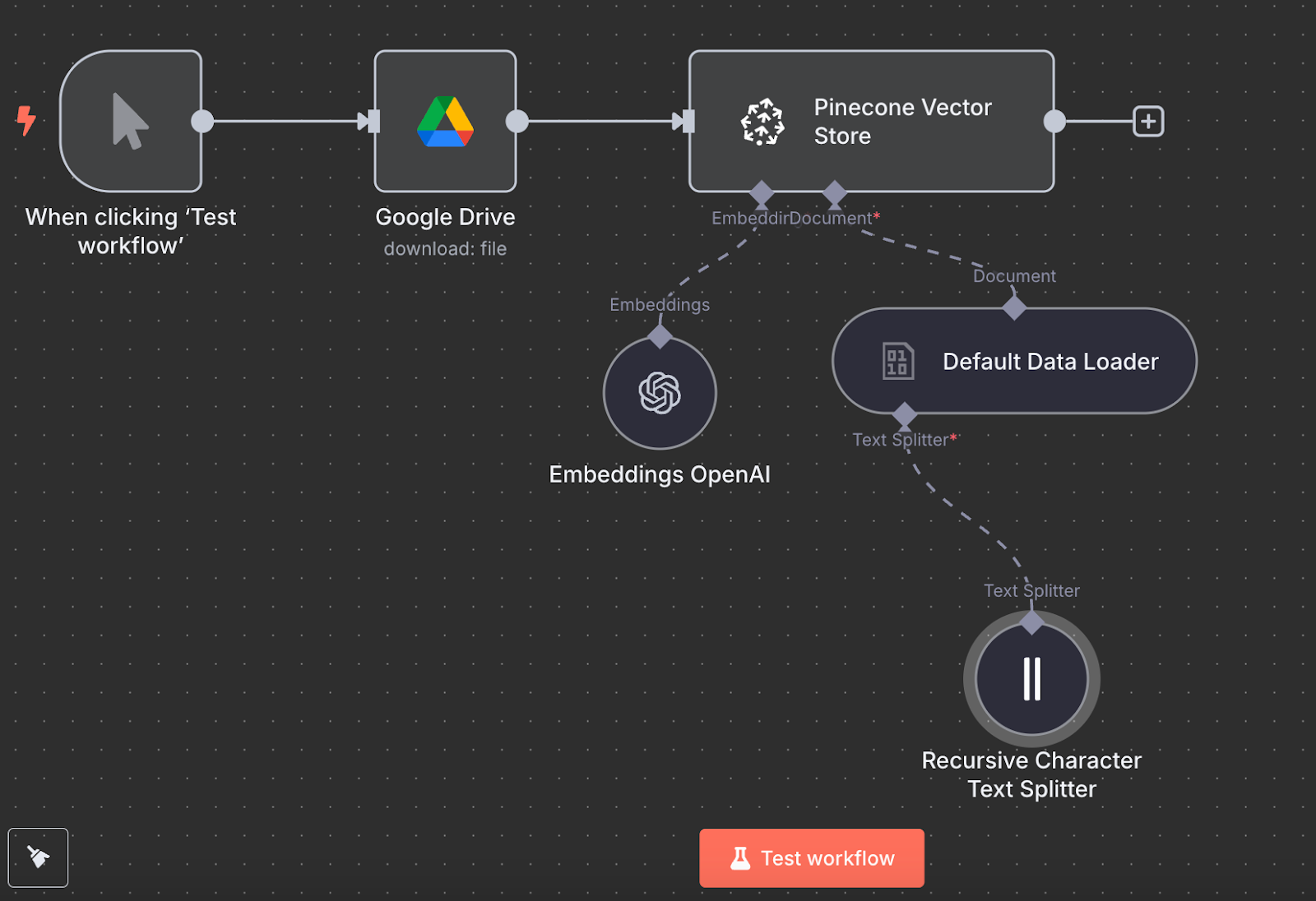
Execute clicando em "Test workflow" e, quando terminar, verifique no Pinecone se os dados foram carregados.
Aqui está o esquema final do agente RAG:
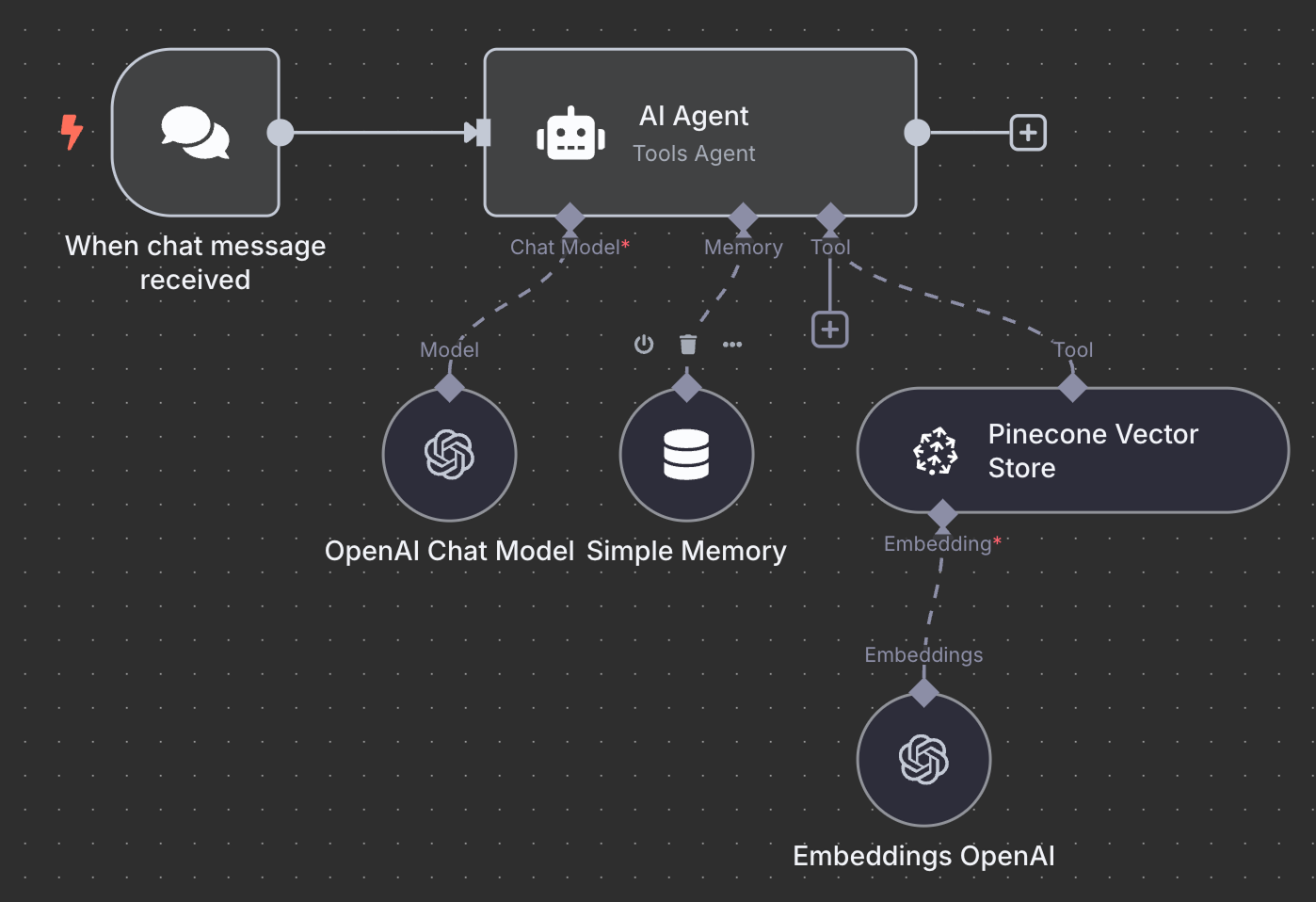
Como exercício, tente entendê-lo e até recriá-lo localmente antes de continuar a leitura.
Começamos com o trigger "On chat message". Ele é usado para criar um fluxo de chat.
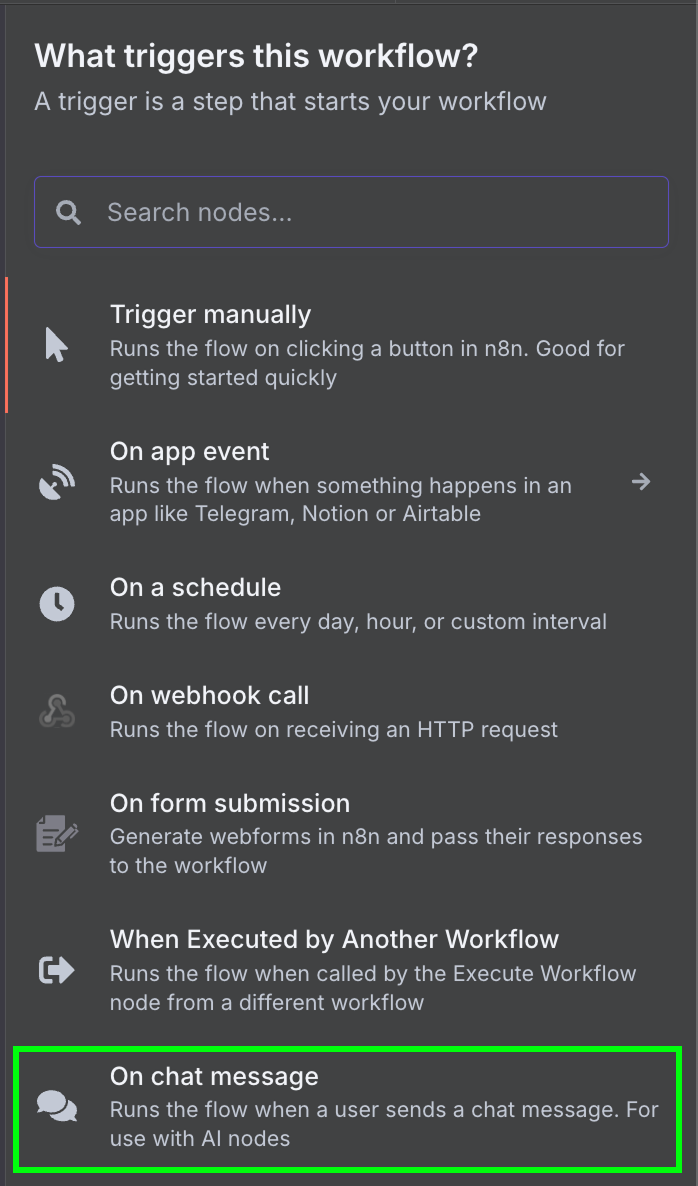
Depois, conectamos o trigger de chat a um nó "AI Agent" com as opções padrão.
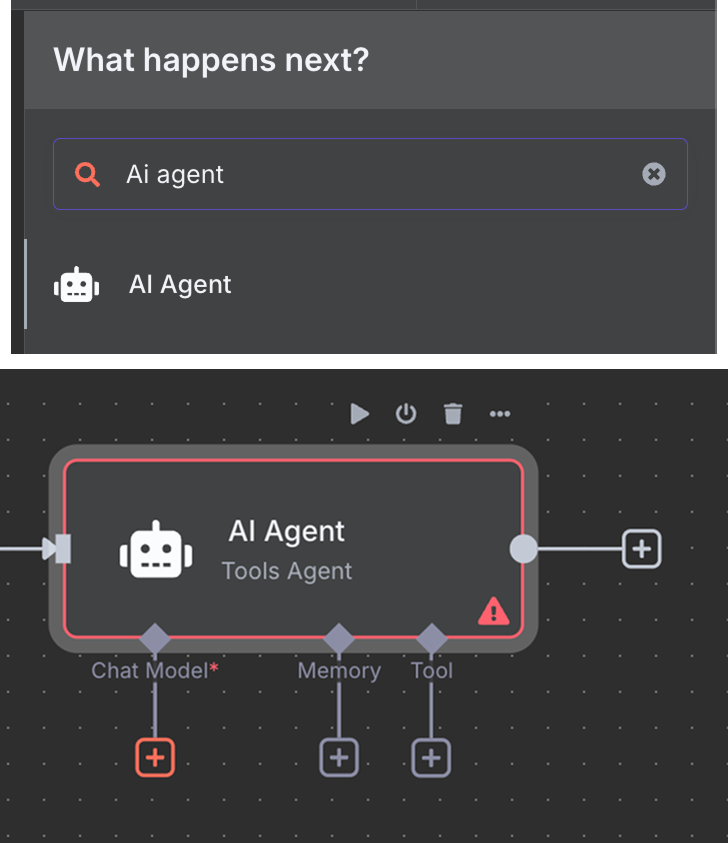
Abaixo do AI Agent, podemos configurar três coisas:
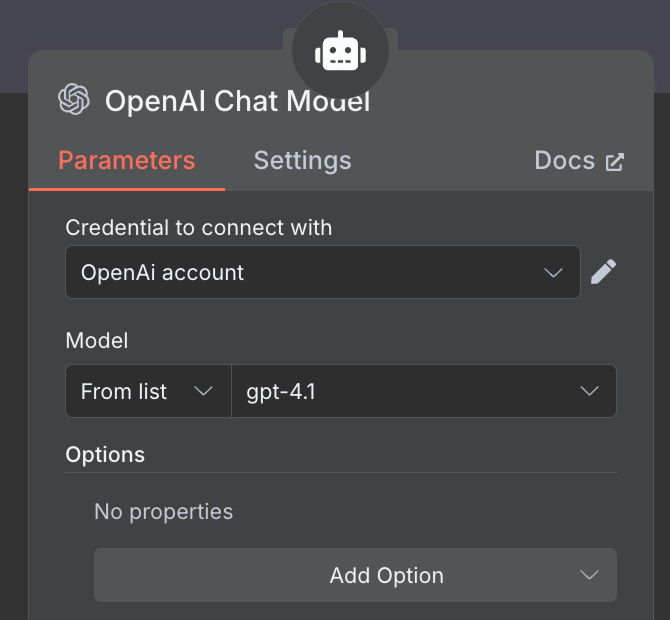
Para o modelo de IA, selecione um nó "OpenAI Chat Model" e use o GPT-4.1, como antes. A família GPT-5 é a atual da OpenAI, mas o 4.1 tem janela de contexto de 1M tokens e funciona muito bem com RAG.
Para a memória, use um nó "Simple Memory" com janela de contexto de 5. Isso significa que o agente vai considerar as cinco interações anteriores ao responder.
Por fim, na ferramenta, adicione um nó "Pinecone Vector Store" com a seguinte configuração:
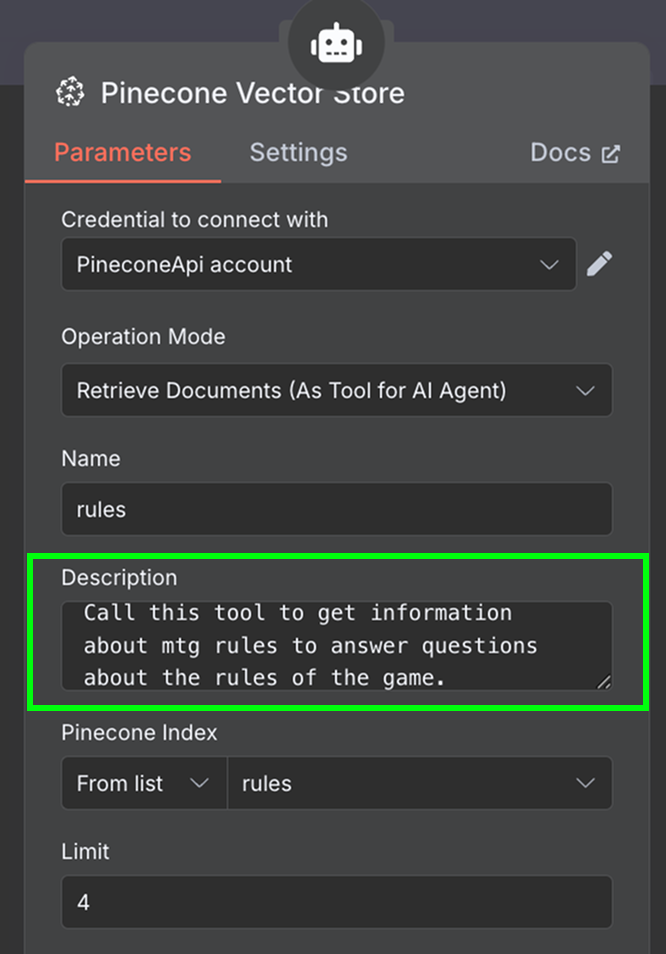
No campo de descrição, é importante especificar quando a ferramenta deve ser usada. É com base nisso que o agente decide chamar a ferramenta.
O último passo é configurar o embedding usado pela vector store. Como antes, use um nó OpenAI Embedding com o modelo text-embedding-3-small:
Workflow pronto — já dá para conversar com o agente. Veja um exemplo:
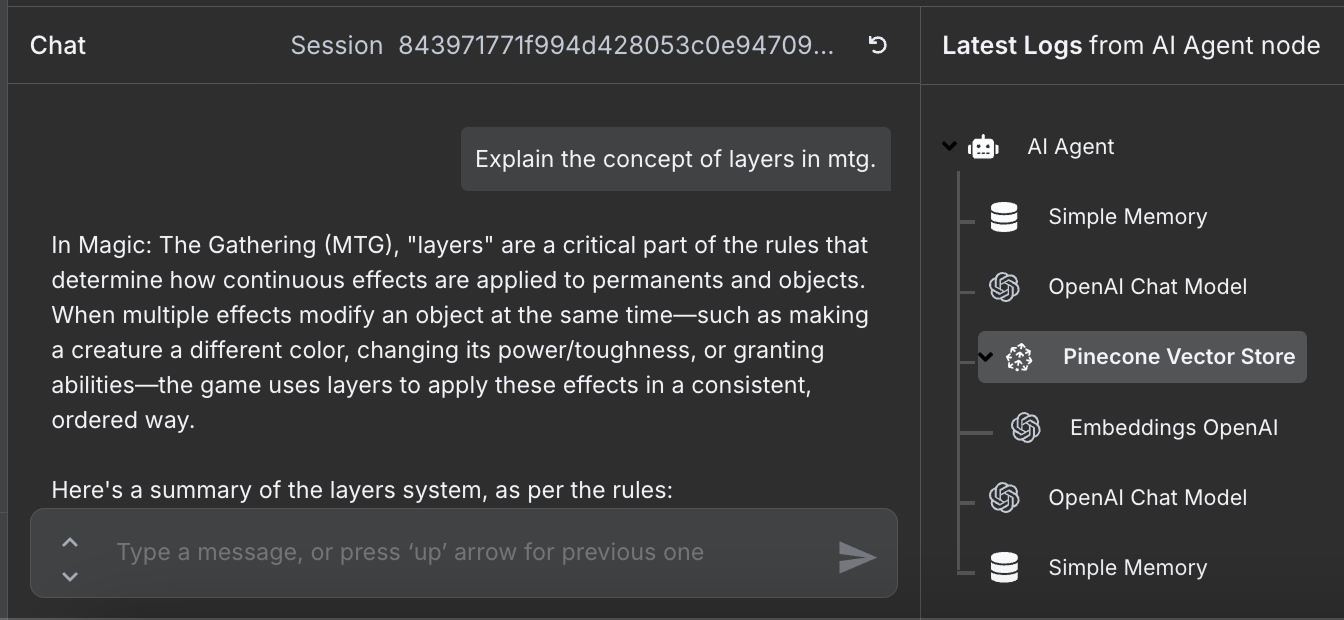
À direita, vemos as etapas que o agente seguiu para responder. Em especial, ele acessou o Pinecone para buscar as regras relevantes.
O n8n oferece um recurso que pode acelerar muito a criação de fluxos: a biblioteca de templates do n8n.
Essa biblioteca reúne workflows prontos, criados pela comunidade e por especialistas do n8n. Seja para automatizar tarefas simples ou processos mais complexos, é bem provável que alguém já tenha construído um fluxo parecido com o que você precisa.
Importar um workflow para sua instância do n8n significa que você nem sempre precisa começar do zero. Em vez disso, dá para aproveitar soluções já testadas por outros usuários. Depois de importar, basta configurar suas credenciais e ajustar aos seus requisitos.
Para praticamente qualquer tarefa que você queira automatizar, de processamento de e-mails a gestão de redes sociais, é bem provável que já exista um template na biblioteca.
O n8n oferece um ecossistema vasto de integrações, permitindo conectar mais de mil serviços e ferramentas para criar agentes de IA. Neste tutorial, só arranhamos a superfície do que o n8n consegue fazer. Ao explorar como usar o n8n para construir agentes que automatizam tarefas do dia a dia, começamos a liberar seu verdadeiro potencial.
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Matt Crabtree
11 min
blog
Laiba Siddiqui
13 min
blog
Nahla Davies
15 min
Tutorial
Moez Ali
Tutorial
Tutorial
Zoumana Keita




