
Lernpfad
Dateningenieur in Python
40 Std.
Redis in Kombination mit Python ist eine leistungsstarke Kombination für Dateningenieure, die leistungsstarke, skalierbare und wartbare Systeme aufbauen wollen. Egal, ob du Caching-Schichten optimierst, Echtzeit-Ereignisströme verwaltest oder verteiltes Sperren implementierst, Redis bietet eine flexible und effiziente Lösung.
In diesem Leitfaden erklären wir dir die Grundlagen der Verwendung von Redis mit Python, damit du es nahtlos in deine Data-Engineering-Workflows integrieren kannst.

Redis ist ein quelloffener In-Memory-Datenspeicher, der als Datenbank, Cache und Message Broker eingesetzt wird. Es steht für Remote Dictionary Server und wurde ursprünglich als Key-Value-Speichersystem mit schnellen Zugriffszeiten entwickelt.
Es unterstützt verschiedene Datenstrukturen wie z.B. Strings, Hashes, Listen, Mengen und sortierte Mengen mit Bereichsabfragen. Redis bietet außerdem erweiterte Funktionen wie Transaktionen, Pub/Sub-Messaging, Lua-Skripting und integrierte Replikations- und Clustering-Funktionen für bessere Verfügbarkeit und Skalierbarkeit.
Die möglichen Anwendungsfälle für Redis sind vielfältig.
Einige der häufigsten Anwendungsfälle in der Datentechnik sind:
Redis wird auch häufig in Kombination mit anderen Technologien wie Webservern (z. B. NGINX), Datenbanken (z. B. MySQL) und Messaging-Systemen (z. B. Kafka) eingesetzt, um die Leistung und Skalierbarkeit zu optimieren.
Python ist aufgrund seiner Flexibilität, seines umfangreichen Ökosystems und seiner einfachen Integration in Big-Data-Technologien eine der dominierenden Sprachen im Data Engineering.
Die Kombination mit Redis kann viele Vorteile für deine Anwendungen bringen:
Redis-py ist die offizielle Redis-Client-Bibliothek für Python. Sie bietet eine benutzerfreundliche Schnittstelle für die Kommunikation mit Redis in deinem Python-Code.
Einige der wichtigsten Funktionen sind:
Schauen wir uns an, wie wir Redis mit Python einrichten können.

![]()
Es gibt drei Möglichkeiten, Redis zum Laufen zu bringen:
Wenn du Docker verwendest, musst du erstens den Docker-Desktop auf deinem Rechner installiert haben. Diese kann von der DockerHub Website.
Sobald Docker installiert ist, öffnest du deine Eingabeaufforderung und gibst den folgenden Befehl ein.
docker pull redis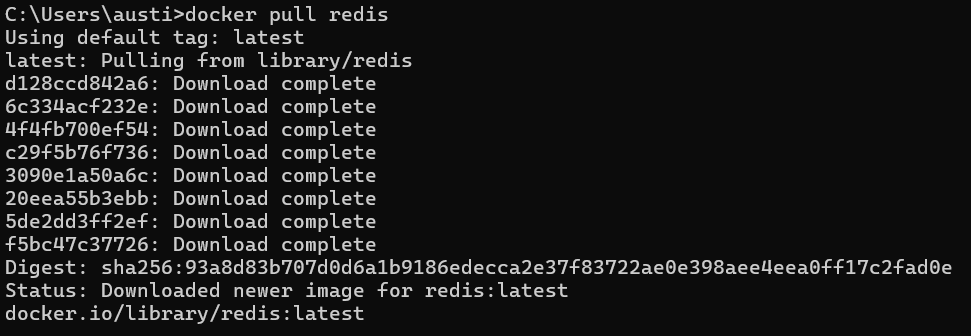
Als nächstes starten wir einen neuen Container.
docker run --name my-redis -p 6379:6379 -d redisdocker pull redis lädt das neueste offizielle Redis-Image herunter. docker run --name my-redis -p 6379:6379 -d redis startet einen neuen Container namens my-redis. Der Parameter -p 6379:6379 ordnet den Port 6379 deines lokalen Rechners dem Port 6379 des Containers zu, sodass du dich über localhost:6379 mit Redis verbinden kannst. Das -d Flag lässt den Container im Hintergrund laufen (detached mode).
Um das zu überprüfen, führe aus:
docker exec -it my-redis redis-cli ping
Es sollte mit PONG antworten.
Bei Windows-Rechnern ist es auch möglich, das Windows Subsystem für die Installation zu verwenden. Dabei wird Linux für die Installation verwendet.
wsl --installDieser Befehl installiert und konfiguriert die Standard-Ubuntu-Distribution innerhalb der WSL. Starte neu, falls erforderlich.
Öffne dann dein Ubuntu-Terminal (aus dem Microsoft Store oder durch Eingabe von wsl in der PowerShell) und führe es aus:
sudo apt-get update
sudo apt-get install redis-serverAls Nächstes startest du deinen Redis-Server.
sudo service redis-server startLass uns einen Test machen, um zu sehen, ob der Server läuft und funktioniert.
redis-cli pingHier ist eine detaillierte Beschreibung der Befehle, die wir oben verwendet haben:
sudo apt-get update holt sich die neuesten Paketdefinitionen.sudo apt-get install redis-server installiert Redis in der Ubuntu-Umgebung.sudo service redis-server start startet sofort den Redis-Dienst.redis-cli ping testet die Verbindung zum lokalen Redis-Server und gibt bei Erfolg PONG zurück.Diese Lösungen bieten native Windows-Binärdateien. Nach dem Herunterladen und Installieren oder Entpacken führst du aus:
redis-server.exeNach dem Start sollte redis-server.exe Protokolle ausgeben, die zeigen, dass es auf 127.0.0.1:6379 lauscht.
Du kannst dies mit der mitgelieferten CLI bestätigen (falls vorhanden):
redis-cli.exe pingWenn du erfolgreich bist, solltest du ein PONG Ergebnis erwarten.
Als Nächstes musst du die Bibliothek redis-py installieren, damit du mit Python auf die Datenbank zugreifen kannst. Bevor du die Bibliothek installierst, musst du sicherstellen, dass du sowohl Python als auch Redis separat installiert hast.
pip install redisDieser Befehl lädt die Python Redis-Client-Bibliothek (redis-py) von PyPI herunter und installiert sie. Wenn du eine virtuelle Umgebung verwendest, stelle sicher, dass du sie aktivierst, bevor du diesen Befehl ausführst.
Überprüfe mit:
python -c "import redis; print(redis.__version__)"Dies sollte eine Versionsnummer ausgeben (z.B. 5.2.1).
Wenn du eine der oben genannten Methoden angewendet hast (Docker, WSL oder ein Build eines Drittanbieters), solltest du jetzt einen Redis-Server auf localhost:6379 laufen haben. Das reicht für die lokale Entwicklung unter Windows aus.
Im Folgenden findest du Python-Beispiele, die zeigen, wie du dich mit verschiedenen Redis-Datentypen verbinden und diese manipulieren kannst. Jeder Codeblock enthält erläuternde Kommentare, die erklären, wie die Methoden oder Befehle funktionieren.
import redis
# Instantiate a Redis client, connecting to localhost on port 6379
r = redis.Redis(
host='localhost',
port=6379,
db=0 # The default Redis database index
)
# 1. SET command: store a string under 'mykey'
r.set("mykey", "hello from Windows")
# 2. GET command: retrieve the value stored at 'mykey'
value = r.get("mykey")
print(value) # Output is b'hello from Windows', since redis-py returns bytes.
# 3. Convert bytes to string
print(value.decode()) # prints "hello from Windows"
# 4. DEL command: remove 'mykey' from Redis
r.delete("mykey")Wir erstellen ein Redis-Objekt, das sich mit dem lokalen Redis-Server verbindet.
r.set("mykey", "hello from Windows") speichert die Zeichenfolge "Hallo von Windows" unter dem Schlüssel "mykey".r.get("mykey") holt den in mykey gespeicherten Wert ab. Redis gibt Bytes zurück, also dekodieren wir sie für eine für Menschen lesbare Ausgabe.r.delete("mykey") löscht den Schlüssel mykey komplett.Hier ist ein Codebeispiel für die Verwaltung von Benutzersitzungen:
import uuid
def store_user_session(user_id):
"""
Generates a unique session token (UUID) for a user and stores it in Redis.
The session is stored under the key pattern: user:{user_id}:session
"""
session_key = f"user:{user_id}:session"
token = str(uuid.uuid4()) # Generate a random UUID as a session token
r.set(session_key, token) # Store token in Redis
return token
def get_user_session(user_id):
"""
Retrieves the stored session token for the given user_id.
Returns None if the session does not exist or is expired.
"""
session_key = f"user:{user_id}:session"
token = r.get(session_key)
return token.decode('utf-8') if token else None
def delete_user_session(user_id):
"""
Deletes the session entry from Redis for the specified user_id.
"""
session_key = f"user:{user_id}:session"
r.delete(session_key)
# Usage demonstration
session_token = store_user_session(1001)
print(f"Stored session token: {session_token}")
retrieved_token = get_user_session(1001)
print(f"Retrieved session token: {retrieved_token}")
delete_user_session(1001)
print(f"Session after delete: {get_user_session(1001)}") # Should be None or emptystore_user_session(user_id): Erzeugt eine global eindeutige ID über uuid.uuid4() und speichert sie unter einem benutzerspezifischen Schlüssel. get_user_session(user_id): Liest das Sitzungs-Token zurück. Wenn None, fehlt die Sitzung oder sie ist abgelaufen. delete_user_session(user_id): Entfernt den Sitzungsschlüssel aus Redis und meldet damit den Benutzer ab.
Redis-Listen sind geordnete Folgen von Zeichenketten. Sie erlauben Operationen an beiden Enden, was sie praktisch für Warteschlangen, Stapel oder Protokolle macht.
# LPUSH: Push an element to the head (left) of the list
r.lpush("task_queue", "task1")
# RPUSH: Push an element to the tail (right) of the list
r.rpush("task_queue", "task2")
r.rpush("task_queue", "task3")
# LPOP: Pop (remove and return) the element at the head
task = r.lpop("task_queue")
print(task) # b'task1'
# Optional: RPOP removes and returns the element at the tail
task = r.rpop("task_queue")
print(task) # b'task3'lpush("task_queue", "task1") fügt "task1" auf der linken Seite einer Liste namens "task_queue" hinzu. rpush("task_queue", "task2") und rpush("task_queue", "task3") fügen Aufgaben auf der rechten Seite hinzu. lpop("task_queue") and rpop("task_queue") entfernt und gibt Elemente von den jeweiligen Enden der Liste zurück.
def enqueue_task(queue_name, task):
"""
Appends a task to the end (right) of the Redis list named queue_name.
"""
r.rpush(queue_name, task)
def dequeue_task(queue_name):
"""
Removes a task from the front (left) of the Redis list named queue_name.
Returns the task as a string, or None if the queue is empty.
"""
task = r.lpop(queue_name)
return task.decode('utf-8') if task else None
# Example usage:
enqueue_task("my_queue", "send_email")
enqueue_task("my_queue", "generate_report")
while True:
task = dequeue_task("my_queue")
if not task:
print("No more tasks in queue.")
break
print(f"Processing task: {task}")enqueue_task fügt immer neue Aufgaben am Ende der Liste hinzu, was eine traditionelle FIFO-Warteschlange simuliert. dequeue_task entfernt Aufgaben von der Spitze. Wenn die Liste leer ist, gibt sie None zurück.
Die while-Schleife bearbeitet Aufgaben, bis die Warteschlange leer ist, und hält dann an.
Hashes sind ähnlich wie Python-Wörterbücher, werden aber in Redis gespeichert. Sie eignen sich am besten, um zusammengehörige Felder zu gruppieren (z. B. Benutzerdetails).
# HSET: Store 'name' and 'email' fields for a user hash key
r.hset("user:1001", "name", "Alice")
r.hset("user:1001", "email", "alice@example.com")
# HGET: Retrieve a single field from the hash
email = r.hget("user:1001", "email")
print(email.decode('utf-8')) # alice@example.com
# HDEL: Remove a field from the hash
r.hdel("user:1001", "email")hset("user:1001", "name", "Alice") setzt das Feld "name" auf den Wert "Alice" im Hash mit dem Schlüssel "user:1001". hget("user:1001", "email") holt das Feld "email" ab. hdel("user:1001", "email") löscht das Feld "email" aus diesem Hash.
def create_user_profile(user_id, name, email):
"""
Creates a user profile in Redis under the key 'user:{user_id}'.
'name' and 'email' are stored as separate fields in the hash.
"""
user_key = f"user:{user_id}"
r.hset(user_key, mapping={"name": name, "email": email})
def get_user_profile(user_id):
"""
Retrieves and returns all fields in the user profile hash
as a Python dictionary. Keys and values are decoded from bytes.
"""
user_key = f"user:{user_id}"
profile_data = r.hgetall(user_key)
return {k.decode('utf-8'): v.decode('utf-8') for k, v in profile_data.items()}
def delete_user_profile(user_id):
"""
Deletes the entire user profile key from Redis.
"""
user_key = f"user:{user_id}"
r.delete(user_key)
# Usage demonstration
create_user_profile(1002, "Bob", "bob@example.com")
print(get_user_profile(1002)) # e.g. {'name': 'Bob', 'email': 'bob@example.com'}
delete_user_profile(1002)Wir speichern den Namen und die E-Mail-Adresse eines Benutzers in einem Hash. mapping={"name": name, "email": email} nutzt die Fähigkeit von redis-py, mehrere Felder auf einmal zu setzen. r.hgetall(user_key) ruft alle Felder und Werte ab und gibt sie als Wörterbuch mit rohen Bytes zurück, die wir in Strings dekodieren. delete_user_profile löscht den gesamten Hash-Schlüssel.
Daten in Redis können mit Sets oder sortierten Sets verwaltet werden.
Mengen sind Sammlungen von eindeutigen Werten, während sortierte Mengen Sammlungen von Schlüssel-Wert-Paaren sind, denen jeweils ein Wert zugeordnet ist. Diese Datenstrukturen bieten effiziente Möglichkeiten, Daten zu speichern und abzurufen, was sie für Anwendungen nützlich macht, die schnelle Abfragen erfordern.
Eine Menge in Redis ähnelt einer mathematischen Menge - sie enthält eine Sammlung von eindeutigen Elementen, und es sind keine doppelten Elemente erlaubt. Mengen können verwendet werden, um Beziehungen zwischen verschiedenen Entitäten zu modellieren, z. B. zwischen Nutzern, die einen Beitrag in sozialen Medien geliked haben.
Hier ist eine Demonstration der Sets:
# SADD: Add multiple members to a set
r.sadd("tags:python", "redis", "windows", "backend")
# SMEMBERS: Retrieve all unique members in the set
tags = r.smembers("tags:python")
print(tags) # {b'redis', b'windows', b'backend'}Redis Sets stellen die Einzigartigkeit der Mitglieder sicher. Der Versuch, ein doppeltes Mitglied hinzuzufügen, hat keine Wirkung.
Das Ergebnis von smembers ist eine Python-Menge von Bytes.
Sortierte Mengen in Redis ähneln normalen Mengen, aber jedes Mitglied hat auch eine entsprechende Punktzahl. Dies ermöglicht effiziente Sortier- und Rangordnungsoperationen in der Menge.
Sortierte Sets werden oft für Bestenlisten verwendet, in denen die Punktzahl den Rang oder die Punkte eines Spielers darstellt.
Hier ist eine Demonstration der sortierten Sets:
# ZADD: Add members with scores
r.zadd("leaderboard", {"player1": 10, "player2": 20})
# ZRANGE: Retrieve members in ascending order of score
leaders = r.zrange("leaderboard", 0, -1, withscores=True)
print(leaders) # [(b'player1', 10.0), (b'player2', 20.0)]Sortierte Mengen speichern Mitglieder in einer bestimmten Reihenfolge, die durch ihre numerische Punktzahl bestimmt wird. zrange("leaderboard", 0, -1, withscores=True) gibt alle Mitglieder von Rang 0 bis zum Ende zurück, einschließlich ihrer Punktzahl.
Die Verwendung von sortierten Sets kann bei der Verwaltung von Tags oder der Erstellung von Ranglisten hilfreich sein.
def add_tag(post_id, tag):
"""
Adds a 'tag' to the set of tags belonging to a specific post.
Each post has its own set under 'post:{post_id}:tags'.
"""
r.sadd(f"post:{post_id}:tags", tag)
def get_tags(post_id):
"""
Retrieves all tags for a specific post, decoding the bytes into strings.
"""
raw_tags = r.smembers(f"post:{post_id}:tags")
return {tag.decode('utf-8') for tag in raw_tags}
def update_leaderboard(player, score):
"""
Updates or inserts a player's score in the 'game:leaderboard' sorted set.
A higher score indicates a better position if sorting descending.
"""
r.zadd("game:leaderboard", {player: score})
def get_leaderboard():
"""
Returns an ascending list of (player, score) tuples from the leaderboard.
To invert the sorting (highest first), you'd use ZREVRANGE.
"""
entries = r.zrange("game:leaderboard", 0, -1, withscores=True)
return [(player.decode('utf-8'), score) for player, score in entries]
# Usage demonstration
add_tag(123, "python")
add_tag(123, "redis")
print(get_tags(123))
update_leaderboard("Alice", 300)
update_leaderboard("Bob", 450)
print(get_leaderboard())add_tag und get_tags demonstrieren ein One-to-many-Tagging-System, bei dem Tags in einem Set gespeichert werden. update_leaderboard und get_leaderboard zeigen, wie du eine Spielrangliste implementieren kannst.
Redis hat mehrere Funktionen, die es zu einer beliebten Wahl für die Datenspeicherung in Python-Anwendungen machen: Queueing, Locking und Caching.
Nachfolgend sind ihre Implementierungen in Python aufgeführt:
Wir werden Redis als Warteschlange mit Blocking unter BLPOP verwenden.
BLPOP ist eine blockierende Operation, die wartet, bis ein Element in einer Liste verfügbar ist.
def blocking_consumer(queue_name):
"""
Continuously listens to the specified queue (Redis list) using BLPOP,
which blocks until new items are pushed. Once an item arrives,
it is removed from the queue and processed.
"""
print(f"Waiting on queue: {queue_name}")
while True:
result = r.blpop(queue_name)
if result:
list_name, task_bytes = result
task = task_bytes.decode('utf-8')
print(f"Received task: {task}")
else:
print("Queue is empty or an error occurred.")
break
def enqueue_task(queue_name, task):
"""
Pushes a task to the end of a Redis list (queue).
"""
r.rpush(queue_name, task)
# Example usage:
enqueue_task("blocking_queue", "task_block_1")
enqueue_task("blocking_queue", "task_block_2")
# In a real application, the consumer might run in a separate thread or process
blocking_consumer("blocking_queue")blocking_consumer verwendet blpop in einer Schleife. Wenn die Liste leer ist, wartet blpop so lange, bis ein anderer Eintrag gepusht wird.
Sobald ein Artikel eingegangen ist, wird er aus der Liste entfernt und gedruckt.
Dieser Ansatz ist ideal für Produzenten-Konsumenten-Muster, bei denen die Beschäftigten die Aufgaben nach ihrem Erscheinen erledigen.
Verteilte Sperren verhindern, dass mehrere Clients oder Prozesse gleichzeitig dieselbe Ressource verändern. Redis kann helfen, Race Conditions in einer verteilten Umgebung zu vermeiden.
import time
from redis.exceptions import LockError
def process_critical_section():
"""
Acquires a lock named 'resource_lock' with a timeout of 10 seconds.
The lock automatically expires after 10 seconds to prevent deadlocks.
"""
lock = r.lock("resource_lock", timeout=10)
try:
# Attempt to acquire the lock, wait for up to 5 seconds if another process holds it
acquired = lock.acquire(blocking=True, blocking_timeout=5)
if acquired:
print("Lock acquired; performing critical operation...")
time.sleep(3) # Simulate some operation
else:
print("Failed to acquire lock within 5 seconds.")
except LockError:
print("A LockError occurred, possibly releasing already released lock.")
finally:
# Always release the lock in a finally block to ensure cleanup
lock.release()
print("Lock released.")
# Usage demonstration
process_critical_section()Wir erstellen eine Sperre mit timeout=10. Wenn die Sperre nicht manuell freigegeben wird, entfernt Redis sie automatisch nach 10 Sekunden, um ein unendliches Blockieren (Deadlock) zu verhindern. lock.acquire(blocking=True, blocking_timeout=5) versucht 5 Sekunden lang, die Sperre zu erhalten, bevor es aufgibt. Nach Beendigung gibt lock.release() die Ressource für andere Prozesse frei.
Caching ist ein gängiges Anwendungsszenario: Häufig abgerufene Daten werden im Arbeitsspeicher gespeichert, um die Belastung von Datenbanken oder externen APIs zu verringern.
import requests
import json
def get_user_data(user_id):
"""
Retrieves user data from a hypothetical API endpoint.
If the data is found in Redis (cache), use that. Otherwise, call the API,
store the response in Redis with a 60-second expiration, and return it.
"""
cache_key = f"user_data:{user_id}"
cached_data = r.get(cache_key)
if cached_data:
print("Cache hit!")
return json.loads(cached_data)
print("Cache miss. Fetching from API...")
response = requests.get(f"https://api.example.com/users/{user_id}")
user_info = response.json()
# Store in Redis for 60 seconds
r.setex(cache_key, 60, json.dumps(user_info))
return user_info
# Usage
user = get_user_data(42) # First call => cache miss
user_again = get_user_data(42) # Subsequent call => cache hitWir prüfen, ob user_data:{user_id} in Redis existiert. Wenn ja, ist das ein Cache-Treffer, und wir überspringen den API-Aufruf. Wenn nicht, holen wir die Daten von der Remote-API, dann setex (set + expiration) für 60 Sekunden. Nachfolgende Aufrufe innerhalb dieses Zeitrahmens rufen die zwischengespeicherten Daten ab und verringern so die Latenzzeit.
Du denkst, du hast den Dreh mit Redis schon raus? Gehen wir einige fortgeschrittenere Themen durch.
Pub/Sub (Publish/Subscribe) ist ein beliebtes Messaging-Muster für die Echtzeitkommunikation. Verleger senden Nachrichten an einen Kanal, und alle Abonnenten dieses Kanals erhalten die Nachrichten.
import threading
def subscriber(r, channel_name):
"""
Subscribes to the given Redis channel and listens for messages.
When a new message is published on that channel, it is printed.
"""
pubsub = r.pubsub()
pubsub.subscribe(channel_name)
print(f"Subscribed to {channel_name}")
# pubsub.listen() yields messages from the subscribed channel(s) in real time
for message in pubsub.listen():
if message['type'] == 'message':
print(f"Received message: {message['data'].decode('utf-8')}")
def publisher(r, channel_name, message):
"""
Publishes a message to the specified Redis channel.
All subscribers to this channel immediately receive the message.
"""
r.publish(channel_name, message)
# Example usage
channel = "updates"
# Start subscriber in a separate thread to avoid blocking the main thread
sub_thread = threading.Thread(target=subscriber, args=(r, channel))
sub_thread.start()
# Publish messages
publisher(r, channel, "Hello from Windows!")
publisher(r, channel, "Another update!")pubsub = r.pubsub() erstellt ein PubSub-Objekt. pubsub.subscribe(channel_name) weist Redis an, Nachrichten aus diesem Kanal an das PubSub-Objekt zu senden. pubsub.listen() ist ein unendlicher Iterator, der Nachrichten nach und nach ausgibt. r.publish(channel_name, message) sendet eine Nachricht an alle Abonnenten von channel_name.
Redis unterstützt Time-to-Live (TTL). Dies ist wichtig für temporäre Daten wie Sitzungen oder kurzlebige Caches.
# EXPIRE: Set a 30-second expiration on a key
r.set("temp_key", "some value")
r.expire("temp_key", 30)
# SETEX: Combined set + expire in one command
r.setex("temp_key2", 60, "another value")r.expire("temp_key", 30) setzt eine TTL von 30 Sekunden. Nach 30 Sekunden wird temp_key automatisch gelöscht. r.setex("temp_key2", 60, "another value") ist eine Abkürzung, die gleichzeitig den Schlüssel und das Ablaufdatum festlegt.
Hier ist ein Beispiel dafür, wie du ablaufende Schlüssel verwenden kannst, um eine Sitzung nach einer bestimmten Zeitspanne ablaufen zu lassen.
def store_session_with_expiry(user_id, token, ttl=3600):
"""
Stores a session token for a specific user with a time-to-live (TTL).
By default, the session expires after 1 hour (3600 seconds).
"""
session_key = f"user:{user_id}:session"
r.setex(session_key, ttl, token)
def get_session_with_expiry(user_id):
"""
Retrieves the session token for the user. Returns None if the key doesn't exist
or if it has expired.
"""
session_key = f"user:{user_id}:session"
token = r.get(session_key)
return token.decode('utf-8') if token else None
# Usage
store_session_with_expiry(2001, "session_token_abc", 3600)
retrieved_token = get_session_with_expiry(2001)
print(f"Retrieved token: {retrieved_token}")store_session_with_expiry verwendet setex unter der Haube, um user:{user_id}:session mit einer bestimmten TTL zu speichern. Wenn du keine TTL angibst, kann der Schlüssel für unbestimmte Zeit erhalten bleiben.
Wenn die TTL abläuft, entfernt Redis den Schlüssel automatisch und macht es unmöglich, die Sitzung wiederherzustellen.
Der Umgang mit Redis erfordert einige Überlegungen und Best Practices, um eine optimale Leistung zu gewährleisten und häufige Fallstricke zu vermeiden.
Einige Tipps, die du dir merken solltest, sind:
Redis ist ein leistungsstarkes und vielseitiges Werkzeug für die Verwaltung von Daten in Python-Anwendungen. Die Verwendung von Python mit Redis kann viele Anwendungen und Anwendungsfälle mit sich bringen, vom Zwischenspeichern von Daten bis zur Verwaltung von Warteschlangen.
Willst du mehr über Redis erfahren? Unser Einführung in NoSQL Kurs kann dir helfen, den Umgang mit Key-Value-Daten zu lernen. Bist du stattdessen an Python interessiert? Dann ist unser Python Datengrundlagen Lernpfad der beste Startpunkt sein.
Top DataCamp Kurse
Lernpfad
Lernpfad
Kurs