
Was ist Streamlit?
Streamlit ist ein kostenloses und quelloffenes Framework, mit dem du schnell schöne Webanwendungen für maschinelles Lernen und Data Science erstellen und teilen kannst. Es ist eine Python-basierte Bibliothek, die speziell für Machine-Learning-Ingenieure entwickelt wurde. Datenwissenschaftler/innen oder Ingenieur/innen für maschinelles Lernen sind keine Webentwickler/innen und haben kein Interesse daran, wochenlang zu lernen, wie man diese Frameworks für die Entwicklung von Webanwendungen einsetzt. Stattdessen wollen sie ein Werkzeug, das einfacher zu erlernen und zu benutzen ist, solange es Daten anzeigen und die für die Modellierung benötigten Parameter erfassen kann. Mit Streamlit kannst du mit nur wenigen Zeilen Code eine atemberaubend aussehende Anwendung erstellen.
Verdiene eine Python-Zertifizierung
Warum sollten Datenwissenschaftler Streamlit nutzen?
Das Beste an Streamlit ist, dass du nicht einmal die Grundlagen der Webentwicklung kennen musst, um loszulegen oder deine erste Webanwendung zu erstellen. Wenn du dich also mit Data Science beschäftigst und deine Modelle einfach, schnell und mit nur wenigen Zeilen Code einsetzen willst, ist Streamlit eine gute Wahl.
Einer der wichtigsten Aspekte, um eine Anwendung erfolgreich zu machen, ist, sie mit einer effektiven und intuitiven Benutzeroberfläche auszustatten. Viele der modernen datenintensiven Apps stehen vor der Herausforderung, schnell eine effektive Benutzeroberfläche zu erstellen, ohne komplizierte Schritte zu unternehmen. Streamlit ist eine vielversprechende Open-Source-Python-Bibliothek, mit der Entwickler im Handumdrehen attraktive Benutzeroberflächen erstellen können.
Streamlit ist der einfachste Weg, vor allem für Leute ohne Front-End-Kenntnisse, ihren Code in eine Webanwendung einzubauen:
- Es sind keine Front-End-Kenntnisse (html, js, css) erforderlich.
- Du musst nicht Tage oder Monate damit verbringen, eine Web-App zu erstellen. Du kannst eine wirklich schöne Machine Learning- oder Data Science-App in nur wenigen Stunden oder sogar Minuten erstellen.
- Es ist mit den meisten Python-Bibliotheken kompatibel (z. B. Pandas, Matplotlib, Seaborn, Plotly, Keras, PyTorch, SymPy(latex)).
- Es wird weniger Code benötigt, um tolle Webanwendungen zu erstellen.
- Das Zwischenspeichern von Daten vereinfacht und beschleunigt die Berechnungspipelines.
Wie man Streamlit benutzt
Streamlit installieren
Unter Windows:
- Installiere Anaconda und erstelle deine Umgebung
- Öffne das Terminal
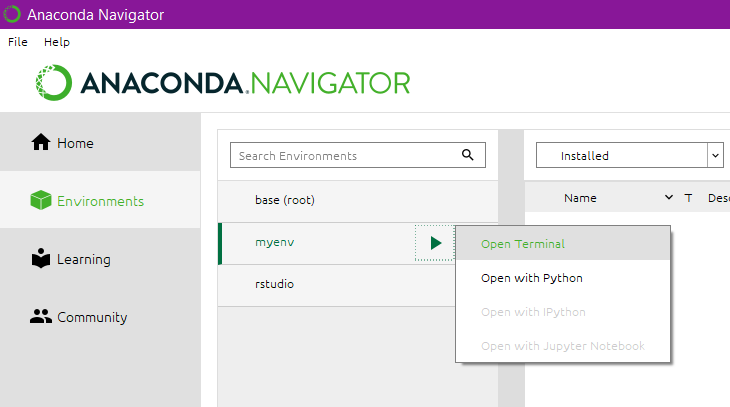
- Gib diesen Befehl in das Terminal ein, um Streamlit zu installieren:
pip install streamlit- Teste, ob die Installation funktioniert hat:
streamlit hello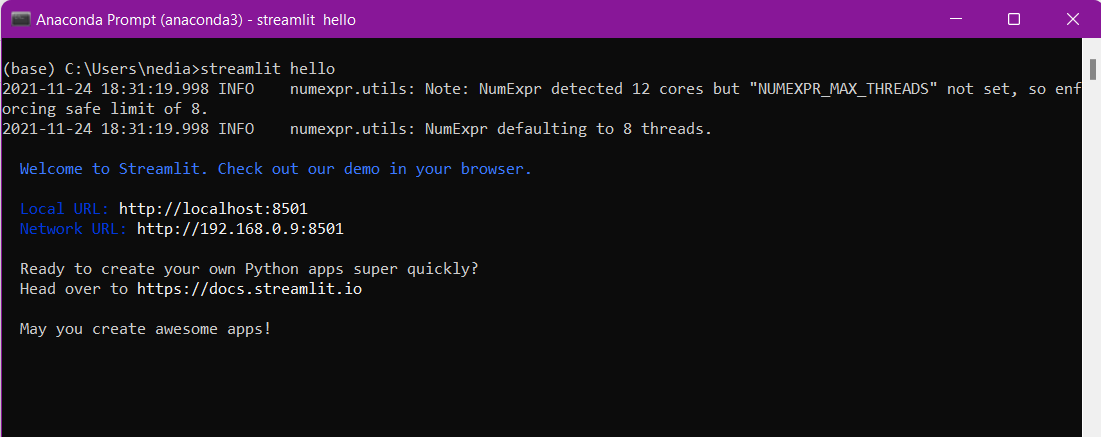
Wenn du diesen Befehl im Terminal eingibst, sollte sich die folgende Seite automatisch öffnen:
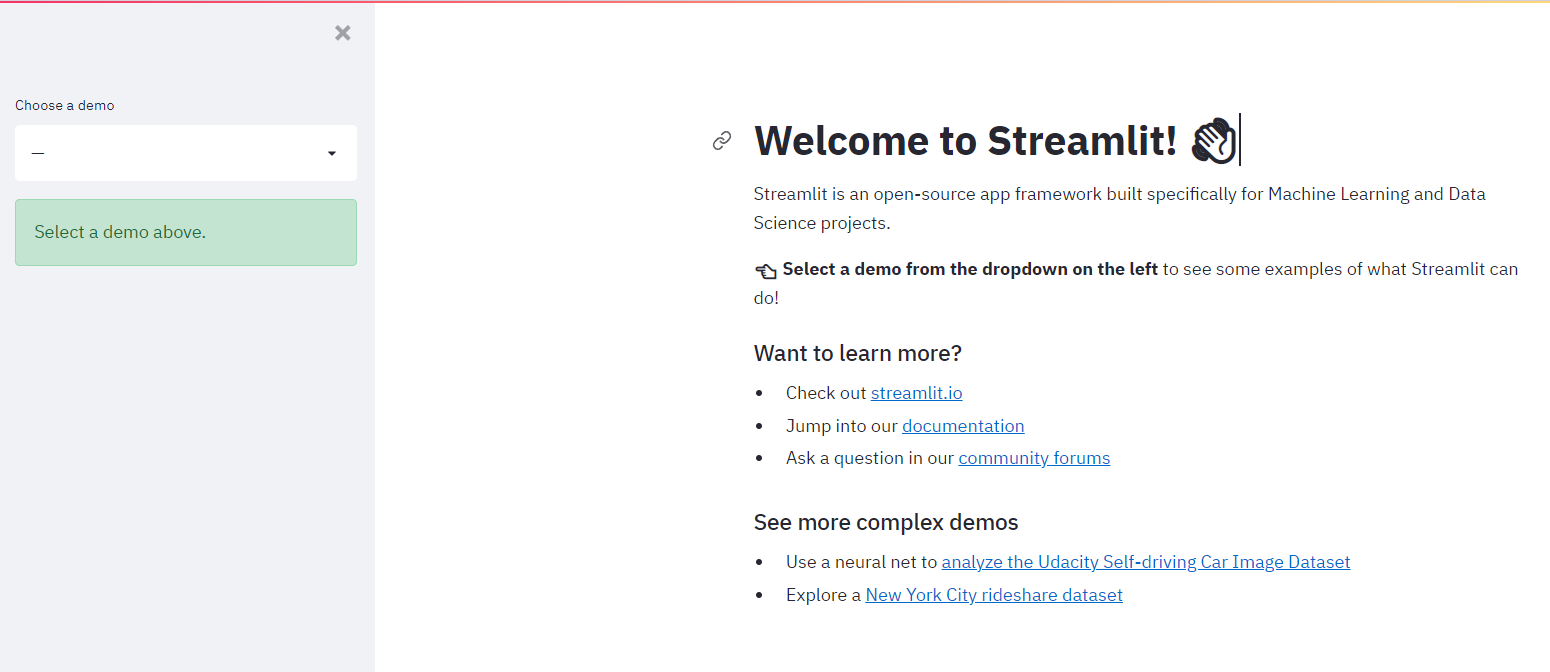
Unter macOS:
Installiere pip:
sudo easy_install pipInstalliere pipenv:
pip3 install pipenvSchaffe deine Umgebung. Öffne deinen Projektordner:
cd project_folder_name
Erstelle eine pipenv-Umgebung:
pipenv shell- Gib diesen Befehl ein, um Streamlit zu installieren:
pip install streamlit
Teste, ob die Installation funktioniert hat:
streamlit helloOn Linux:
Installiere pip:
sudo apt-get install python3-pipInstalliere pipenv:
pip3 install pipenvSchaffe deine Umgebung. Öffne deinen Projektordner:
cd project_folder_name
Erstelle eine pipenv-Umgebung:
pipenv shellGib diesen Befehl ein, um Streamlit zu installieren
pip install streamlitTeste, ob die Installation funktioniert hat:
streamlit hello
Wie du deinen Streamlit-Code ausführst
streamlit run file_name.py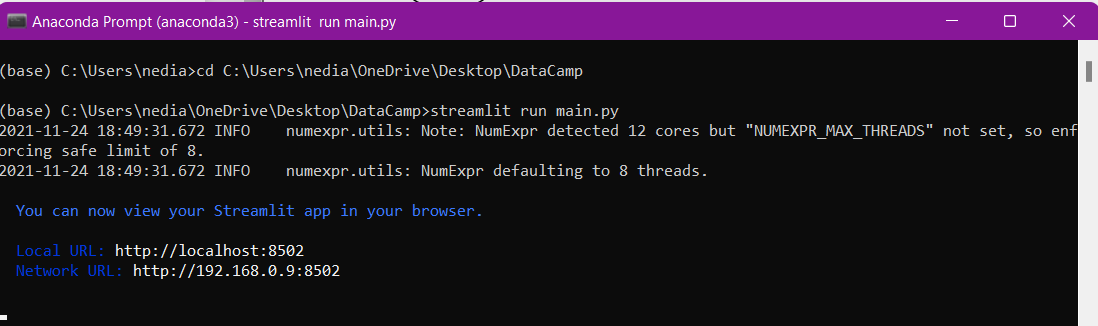
Streamlit-Befehle sind einfach zu schreiben und zu verstehen. Mit einem einfachen Befehl kannst du Texte, Medien, Widgets, Diagramme usw. anzeigen.
Texte mit Streamlit anzeigen
Zu Beginn werden wir sehen, wie du deiner Streamlit-App Text hinzufügst und welche verschiedenen Befehle es gibt, um Texte hinzuzufügen.
st.write(): Mit dieser Funktion kannst du alles zu einer Web-App hinzufügen, von formatierten Strings bis hin zu Diagrammen in matplotlib figure, Altair charts, plotly figure, data frame, Keras model und anderen.
import streamlit as stst.write("Hello ,let's learn how to build a streamlit app together")
st.title(): Mit dieser Funktion kannst du den Titel der App hinzufügen. st.header(): Diese Funktion wird verwendet, um die Überschrift eines Abschnitts zu setzen. st.markdown(): Diese Funktion wird verwendet, um eine Abschrift eines Abschnitts zu setzen. st.subheader(): Mit dieser Funktion kannst du die Zwischenüberschriften eines Abschnitts festlegen. st.caption(): Diese Funktion wird verwendet, um die Beschriftung zu schreiben. st.code(): Diese Funktion wird verwendet, um einen Code zu setzen. st.latex(): Mit dieser Funktion kannst du mathematische Ausdrücke als LaTeX formatiert anzeigen.
st.title ("this is the app title")st.header("this is the markdown")st.markdown("this is the header")st.subheader("this is the subheader")st.caption("this is the caption")st.code("x=2021")st.latex(r''' a+a r^1+a r^2+a r^3 ''')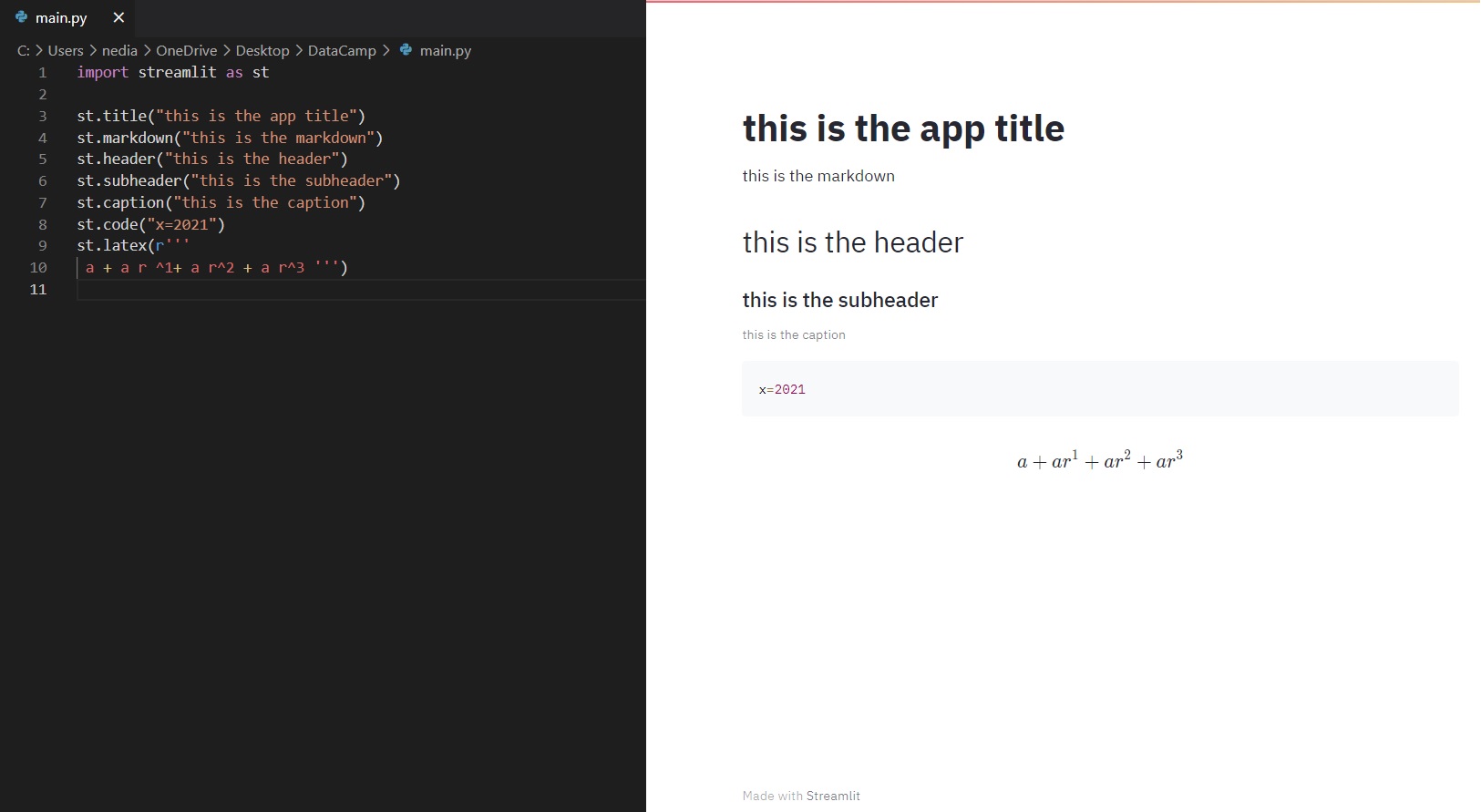
Zeige ein Bild, ein Video oder eine Audiodatei mit Streamlit an
So einfach wie die Streamlit-Funktionen kannst du Bilder, Videos und Audiodateien nicht anzeigen. Schauen wir uns an, wie man Medien mit Streamlit anzeigt!
st.image(): Diese Funktion wird verwendet, um ein Bild anzuzeigen. st.audio(): Diese Funktion wird verwendet, um ein Audio anzuzeigen. st.video(): Diese Funktion wird verwendet, um ein Video anzuzeigen.
st.image("kid.jpg")st.audio("Audio.mp3")st.video("video.mp4")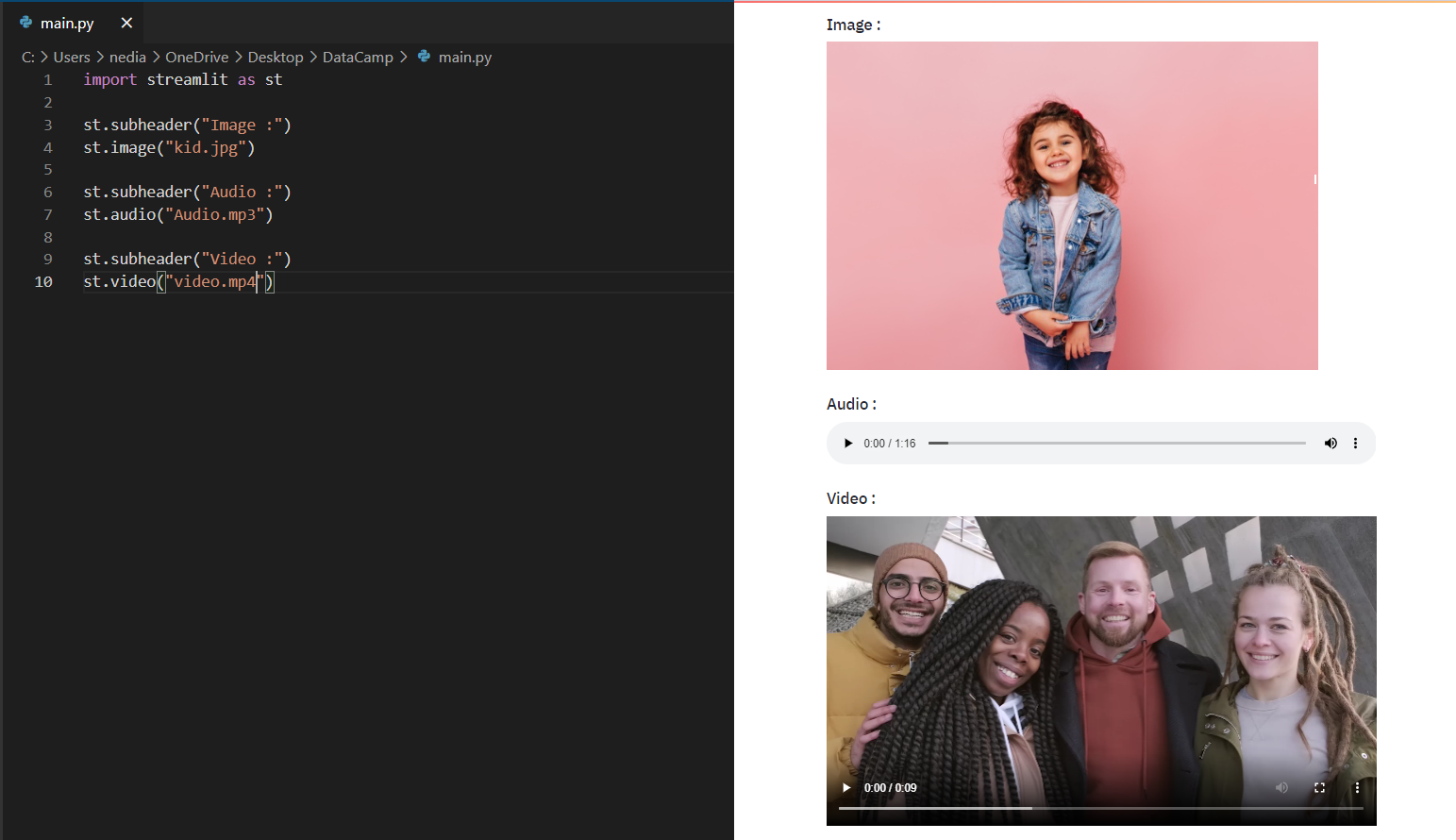
Eingabe-Widgets
Widgets sind die wichtigsten Komponenten der Benutzeroberfläche. Streamlit hat verschiedene Widgets, mit denen du Interaktivität mit Schaltflächen, Schiebereglern, Texteingaben und vielem mehr direkt in deine Apps einbauen kannst.
st.checkbox(): Diese Funktion gibt einen booleschen Wert zurück. Wenn das Kästchen angekreuzt ist, wird ein True-Wert zurückgegeben, andernfalls ein False-Wert. st.button(): Mit dieser Funktion kannst du ein Schaltflächen-Widget anzeigen. st.radio(): Diese Funktion wird verwendet, um ein Radiobutton-Widget anzuzeigen. st.selectbox(): Mit dieser Funktion kannst du ein Auswahl-Widget anzeigen. st.multiselect(): Diese Funktion wird verwendet, um ein Multiselect-Widget anzuzeigen. st.select_slider(): Diese Funktion wird verwendet, um ein Schieberegler-Widget anzuzeigen. st.slider(): Diese Funktion wird verwendet, um ein Slider-Widget anzuzeigen.
st.checkbox('yes')st.button('Click')st.radio('Pick your gender',['Male','Female'])st.selectbox('Pick your gender',['Male','Female'])st.multiselect('choose a planet',['Jupiter', 'Mars', 'neptune'])st.select_slider('Pick a mark', ['Bad', 'Good', 'Excellent'])st.slider('Pick a number', 0,50)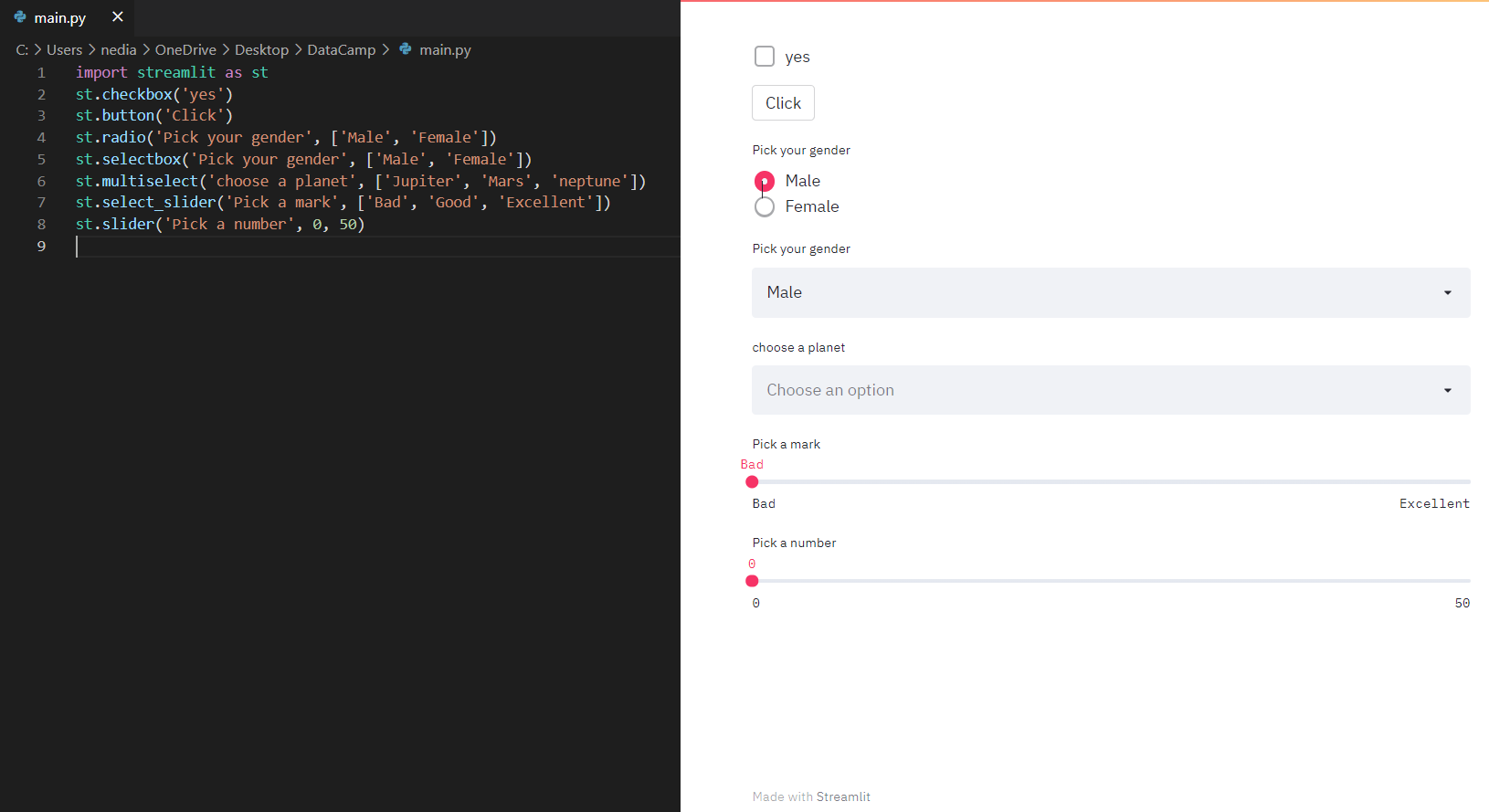
st.number_input(): Diese Funktion wird verwendet, um ein numerisches Eingabewidget anzuzeigen. st.text_input(): Diese Funktion wird verwendet, um ein Texteingabe-Widget anzuzeigen. st.date_input(): Mit dieser Funktion wird ein Datumseingabe-Widget zur Auswahl eines Datums angezeigt. st.time_input(): Mit dieser Funktion kannst du ein Zeit-Eingabe-Widget anzeigen lassen, um eine Zeit auszuwählen. st.text_area(): Diese Funktion wird verwendet, um ein Texteingabe-Widget mit mehr als einer Zeile Text anzuzeigen. st.file_uploader(): Diese Funktion wird verwendet, um ein Dateiuploader-Widget anzuzeigen. st.color_picker(): Mit dieser Funktion wird ein Farbauswahl-Widget angezeigt, mit dem du eine Farbe auswählen kannst.
st.number_input('Pick a number', 0,10)st.text_input('Email address')st.date_input('Travelling date')st.time_input('School time')st.text_area('Description')st.file_uploader('Upload a photo')st.color_picker('Choose your favorite color')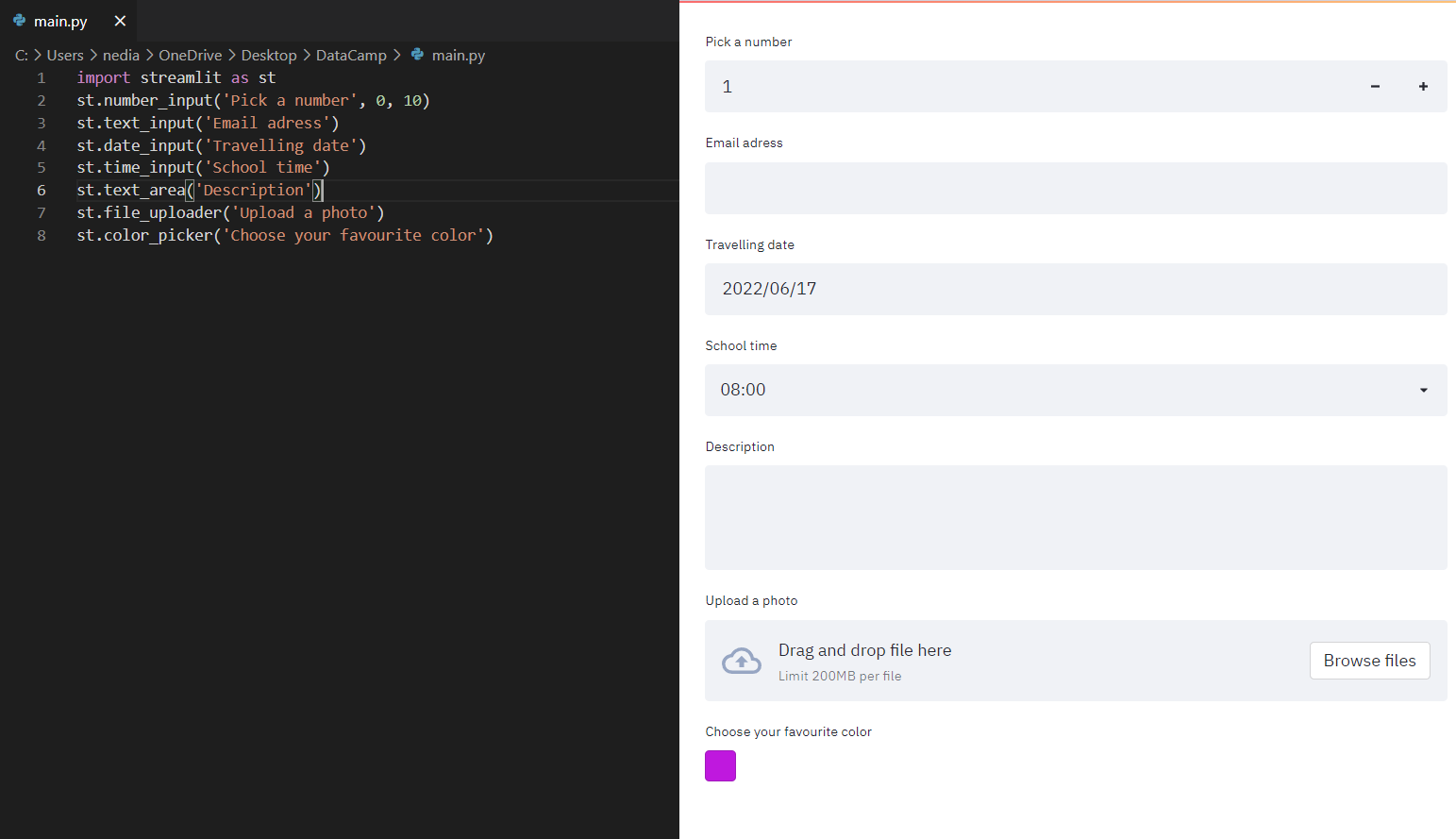
Fortschritt und Status mit Streamlit anzeigen
Jetzt werden wir sehen, wie wir einen Fortschrittsbalken und Statusmeldungen wie Fehler und Erfolg zu unserer App hinzufügen können.
st.balloons(): Diese Funktion wird verwendet, um Luftballons zur Feier anzuzeigen. st.progress(): Mit dieser Funktion kannst du einen Fortschrittsbalken anzeigen. st.spinner(): Diese Funktion wird verwendet, um während der Ausführung eine temporäre Wartemeldung anzuzeigen.
st.balloons()st.progress(10)with st.spinner('Wait for it...'): time.sleep(10)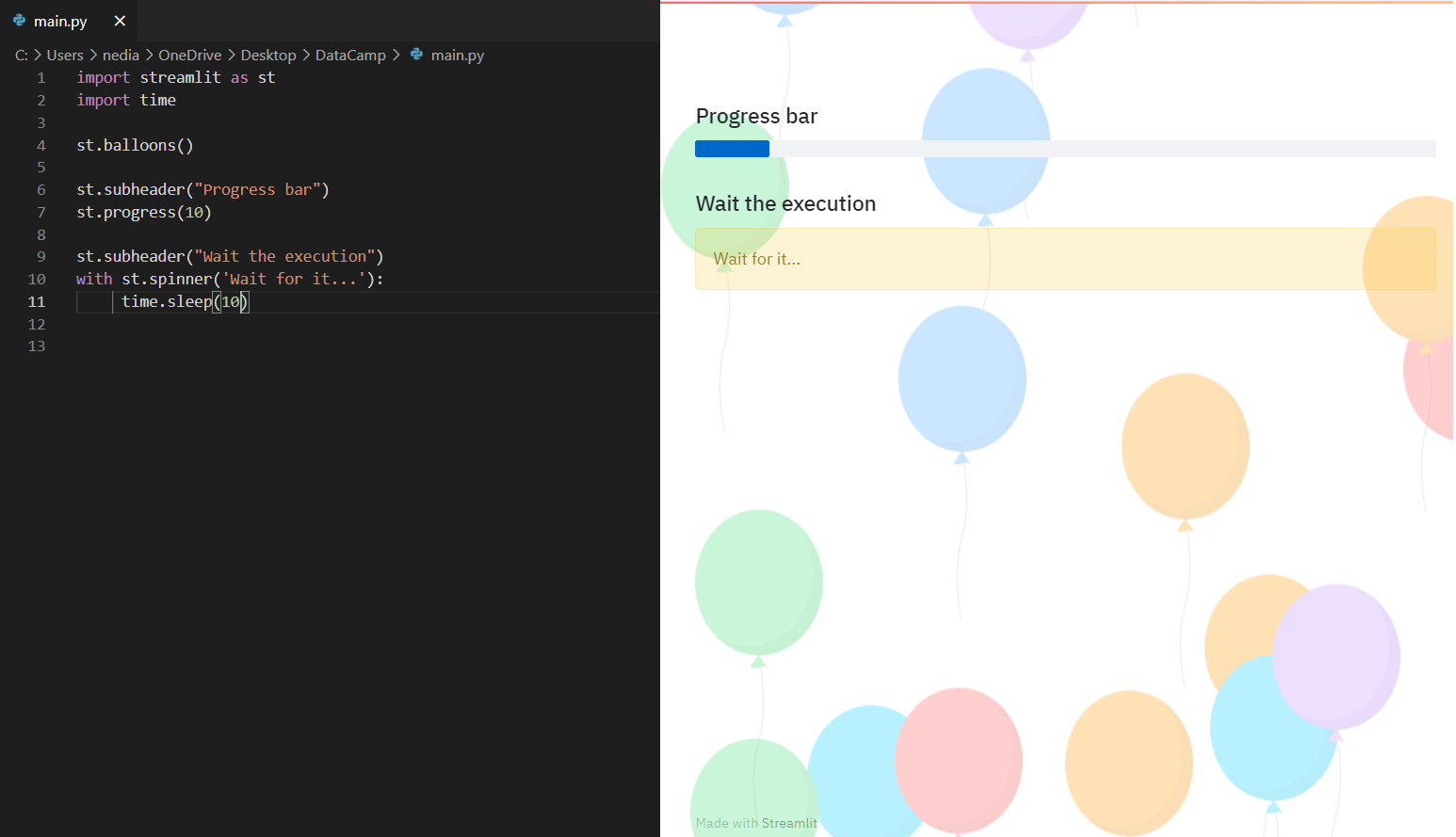
st.success(): Mit dieser Funktion kannst du eine Erfolgsmeldung anzeigen. st.error(): Diese Funktion wird verwendet, um eine Fehlermeldung anzuzeigen. st.warnig(): Diese Funktion wird verwendet, um eine Warnmeldung anzuzeigen. st.info(): Mit dieser Funktion kannst du eine Informationsmeldung anzeigen. st.exception(): Diese Funktion wird verwendet, um eine Ausnahmemeldung anzuzeigen.
st.success("You did it !")st.error("Error")st.warnig("Warning")st.info("It's easy to build a streamlit app")st.exception(RuntimeError("RuntimeError exception"))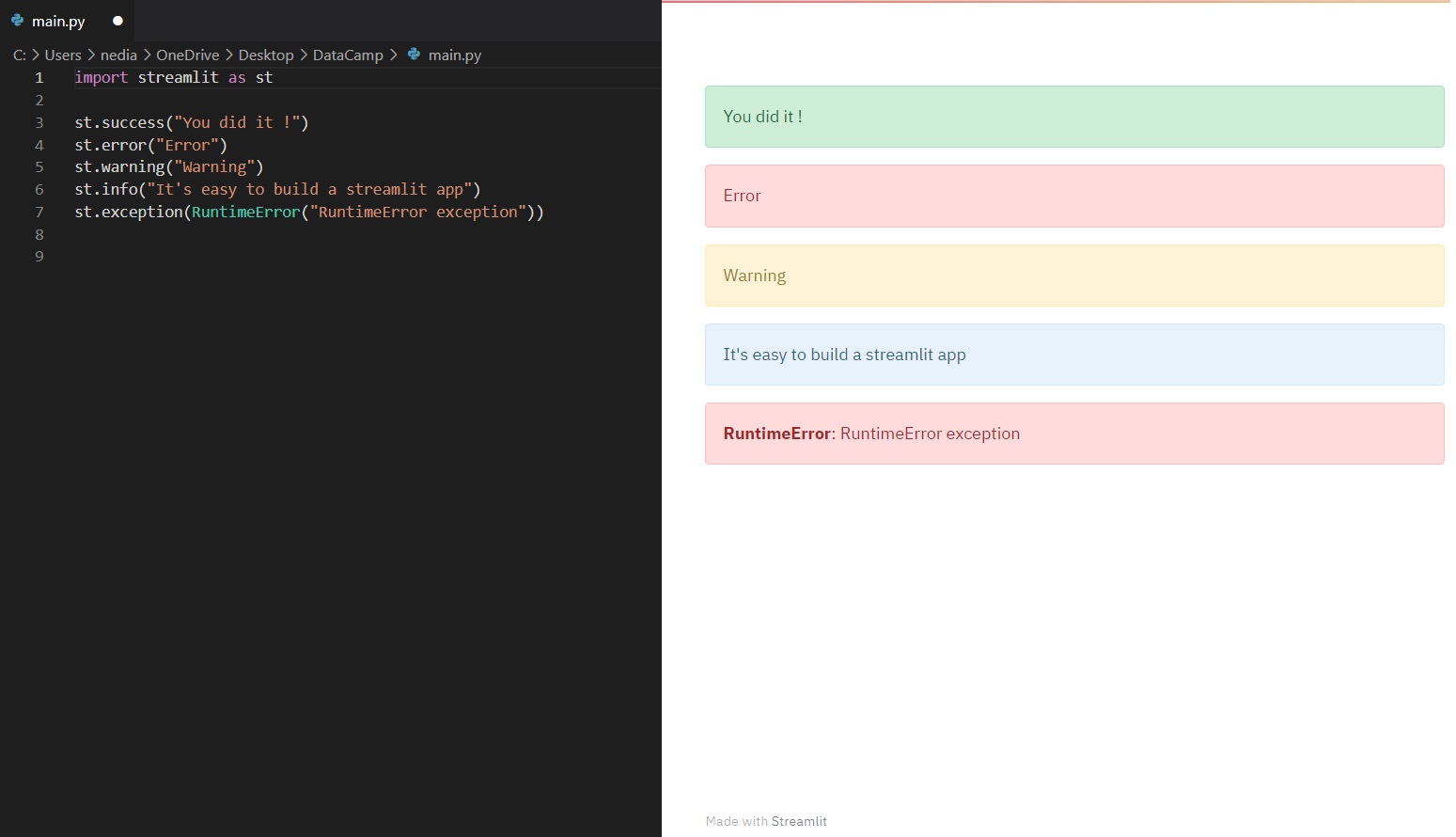
Seitenleiste und Container
Du kannst auch eine Seitenleiste oder einen Container auf deiner Seite einrichten, um deine App zu organisieren. Die Hierarchie und Anordnung der Seiten in deiner App kann einen großen Einfluss auf das Nutzererlebnis haben. Indem du deine Inhalte organisierst, ermöglichst du es den Besuchern, sich auf deiner Seite zurechtzufinden und zu navigieren. Das hilft ihnen, das zu finden, wonach sie suchen, und erhöht die Wahrscheinlichkeit, dass sie in Zukunft wiederkommen.
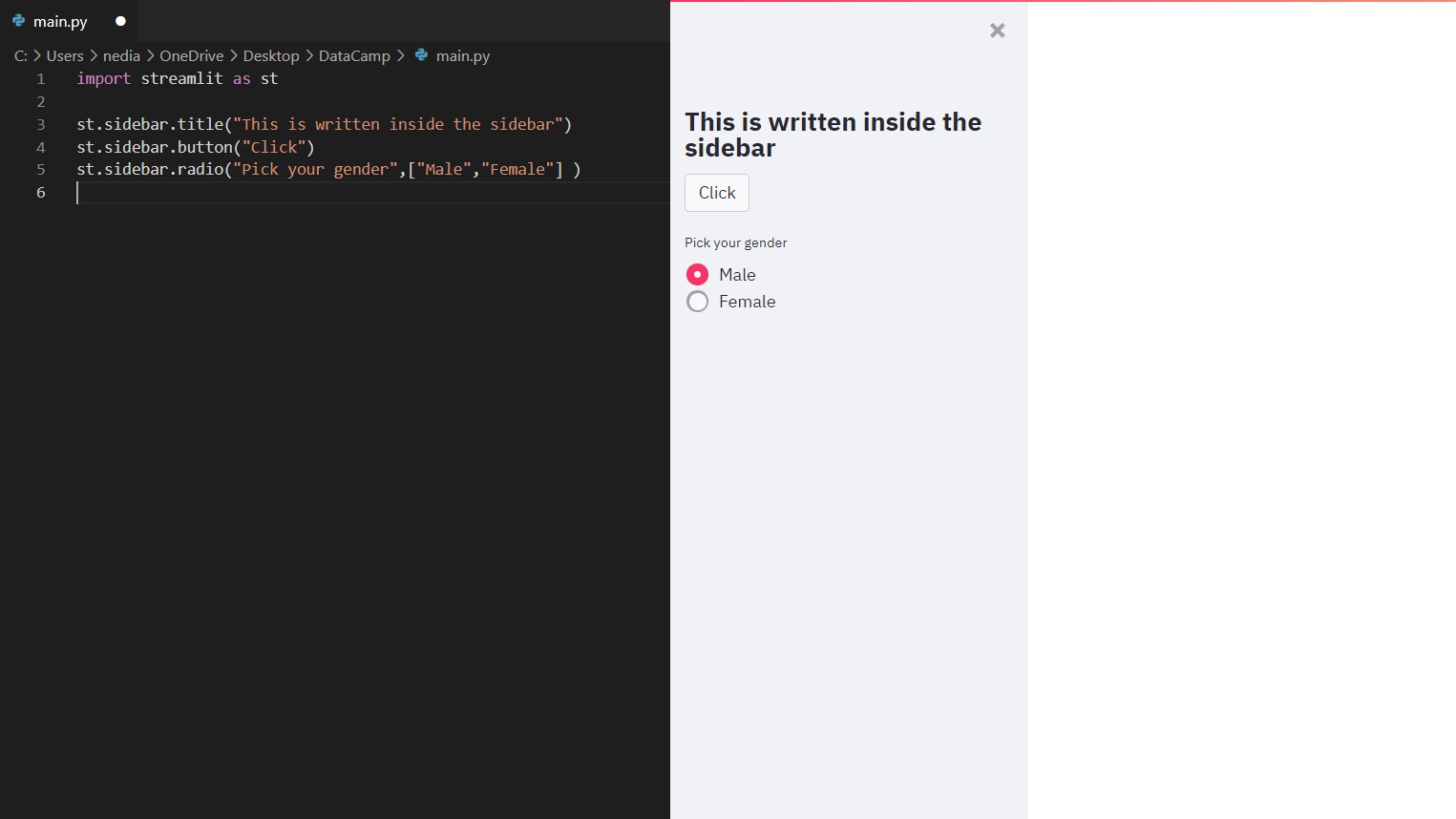
Seitenleiste
Wenn du ein Element an st.sidebar() übergibst, wird dieses Element auf der linken Seite angeheftet, damit sich die Nutzer auf den Inhalt deiner App konzentrieren können.
Aber st.spinner() und st.echo() werden von st.sidebar nicht unterstützt.
Wie du siehst, kannst du eine Seitenleiste in deiner App-Oberfläche erstellen und darin Elemente platzieren, die deine App übersichtlicher und verständlicher machen.
Container
st.container() wird verwendet, um einen unsichtbaren Container zu erstellen, in den du Elemente einfügen kannst, um eine sinnvolle Anordnung und Hierarchie zu schaffen.
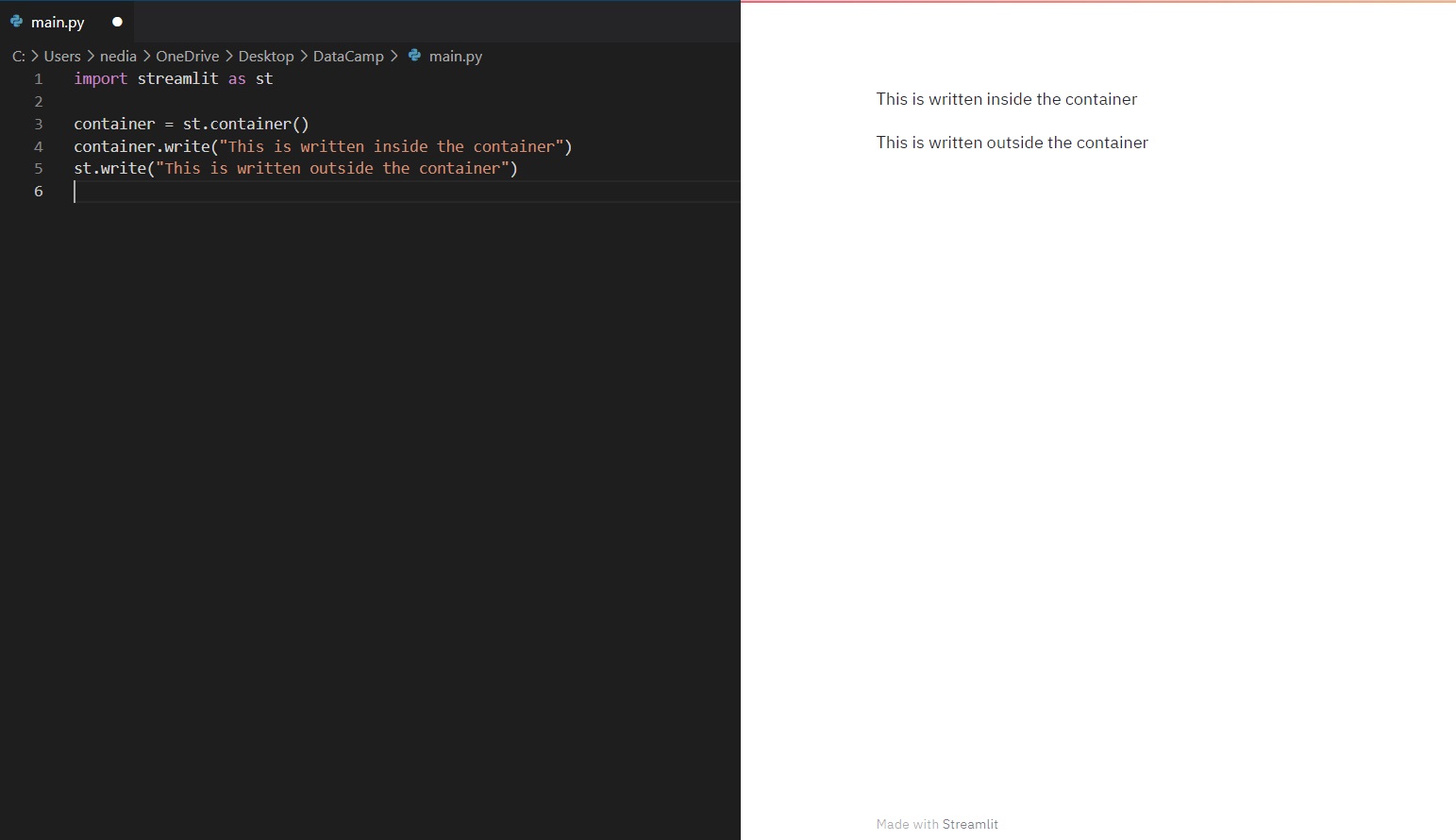
Diagramme anzeigen mit Streamlit
Warum brauchen wir Visualisierung?
Datenvisualisierung hilft dabei, Geschichten zu erzählen, indem sie Daten in ein Format bringt, das leichter zu verstehen ist und Trends und Ausreißer hervorhebt. Eine gute Visualisierung erzählt eine Geschichte, entfernt das Rauschen aus den Daten und hebt die nützlichen Informationen hervor. Es ist jedoch nicht so einfach, ein Diagramm aufzuhübschen oder den "Info"-Teil einer Infografik hinzuzufügen. Effektive Datenvisualisierung ist ein schwieriger Balanceakt zwischen Form und Funktion. Die schlichteste Grafik könnte zu langweilig sein, um Aufmerksamkeit zu erregen oder eine aussagekräftige Botschaft zu vermitteln, und die beeindruckendste Visualisierung könnte völlig versagen, wenn es darum geht, die richtige Botschaft zu vermitteln. Die Daten und das Bildmaterial müssen zusammenpassen, und es ist eine Kunst, gute Analysen mit gutem Storytelling zu verbinden.
Glaubst du, dass es machbar ist, dir die Daten von einer Million Punkten in einer Tabelle/Datenbank zu geben und von dir zu verlangen, dass du deine Schlüsse ziehst, indem du nur die Daten in dieser Tabelle siehst? Wenn du kein Supermensch bist, ist das nicht möglich. In diesem Fall nutzen wir die Datenvisualisierung - sie gibt uns eine klare Vorstellung davon, was die Informationen bedeuten, indem sie durch Karten oder Diagramme in einen visuellen Kontext gesetzt werden. Das ist die Macht der Streamlit-Visualisierung.
st.pyplot(): Diese Funktion wird verwendet, um eine matplotlib.pyplot-Grafik anzuzeigen.
import streamlit as stimport matplotlib.pyplot as pltimport numpy as nprand=np.random.normal(1, 2, size=20)fig, ax = plt.subplots()ax.hist(rand, bins=15)st.pyplot(fig)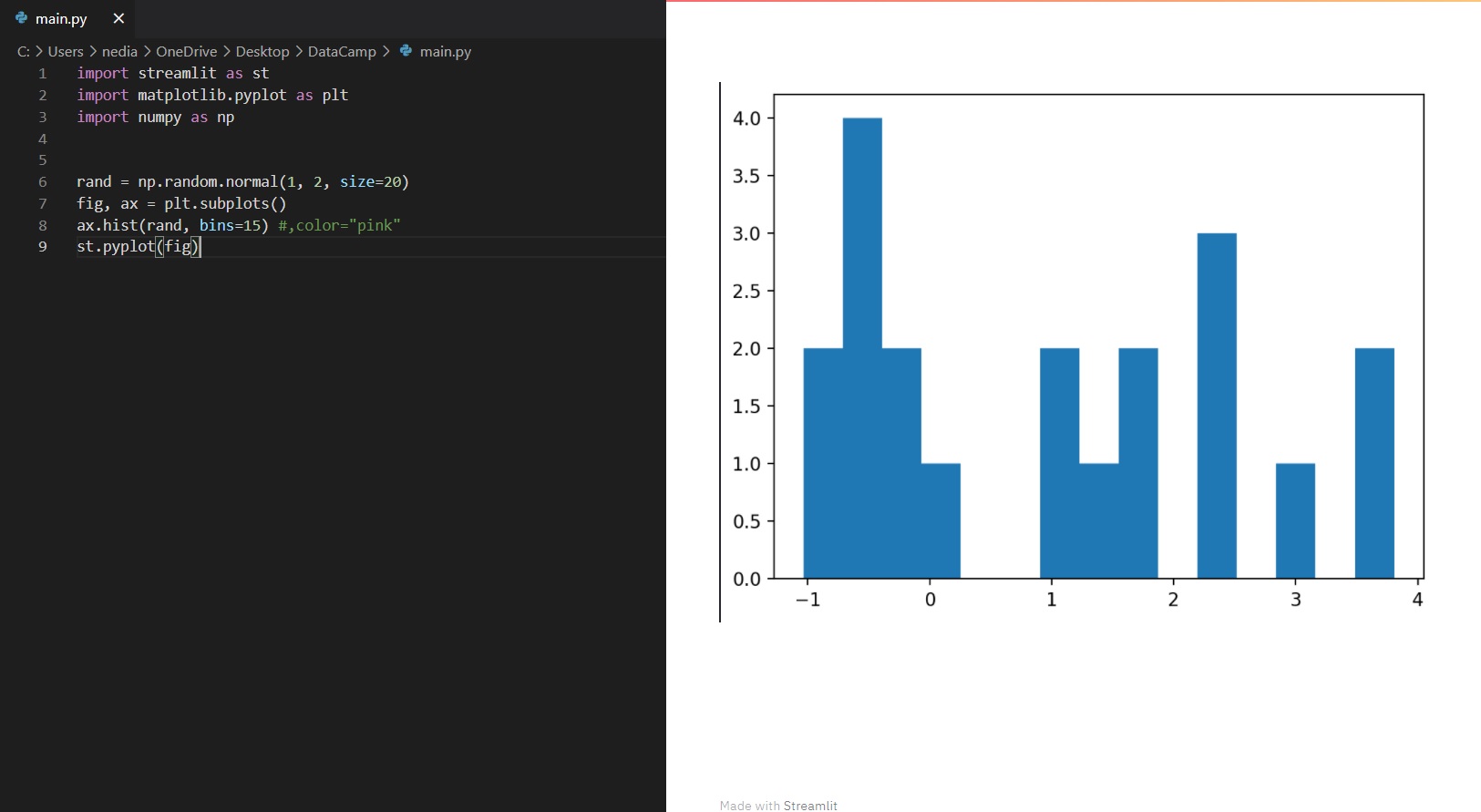
st.line_chart(): Diese Funktion wird verwendet, um ein Liniendiagramm anzuzeigen.
import streamlit as stimport pandas as pdimport numpy as npdf= pd.DataFrame( np.random.randn(10, 2), columns=['x', 'y'])st.line_chart(df)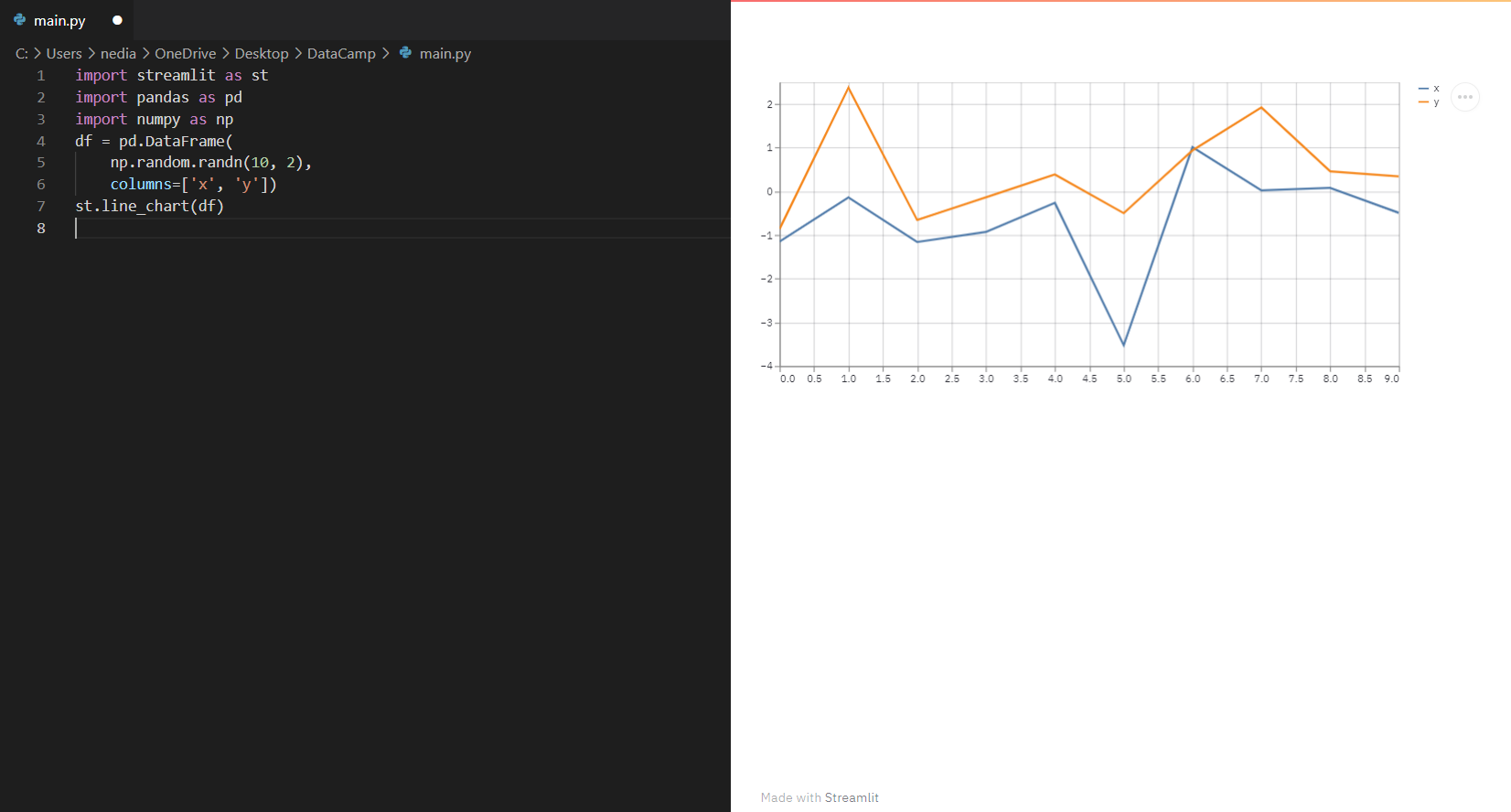
st.bar_chart(): Diese Funktion wird verwendet, um ein Balkendiagramm anzuzeigen.
import streamlit as stimport pandas as pdimport numpy as npdf= pd.DataFrame( np.random.randn(10, 2), columns=['x', 'y'])st.bar_chart(df)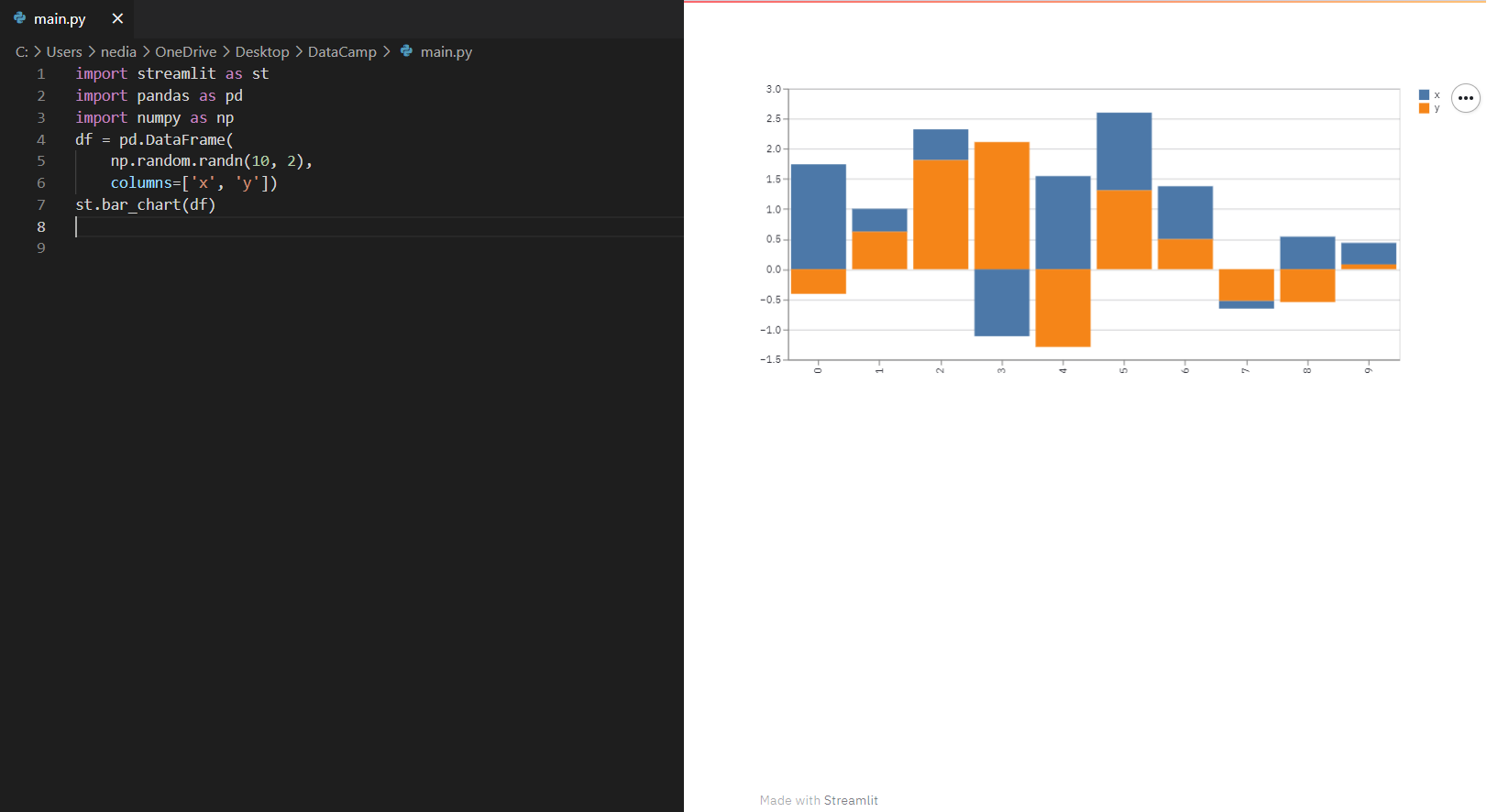
st.area_chart(): Diese Funktion wird verwendet, um ein Flächendiagramm anzuzeigen.
import streamlit as stimport pandas as pdimport numpy as npdf= pd.DataFrame( np.random.randn(10, 2), columns=['x', 'y'])st.area_chart(df)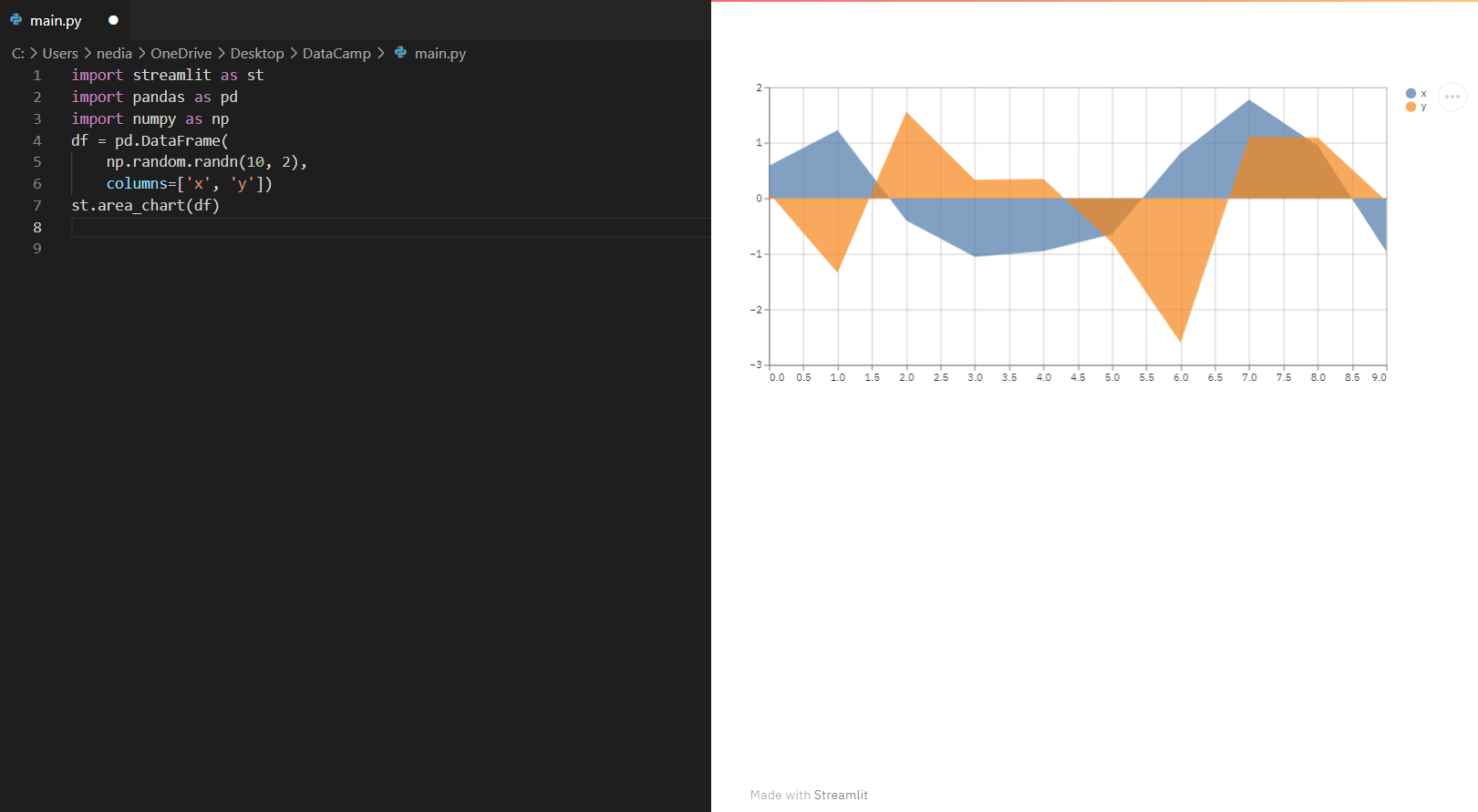
st.altair_chart(): Mit dieser Funktion kannst du ein Altair-Diagramm anzeigen.
import streamlit as stimport numpy as npimport pandas as pdimport altair as altdf = pd.DataFrame( np.random.randn(500, 3), columns=['x','y','z'])c = alt.Chart(df).mark_circle().encode( x='x' , 'y'=y , size='z', color='z', tooltip=['x', 'y', 'z'])st.altair_chart(c, use_container_width=True)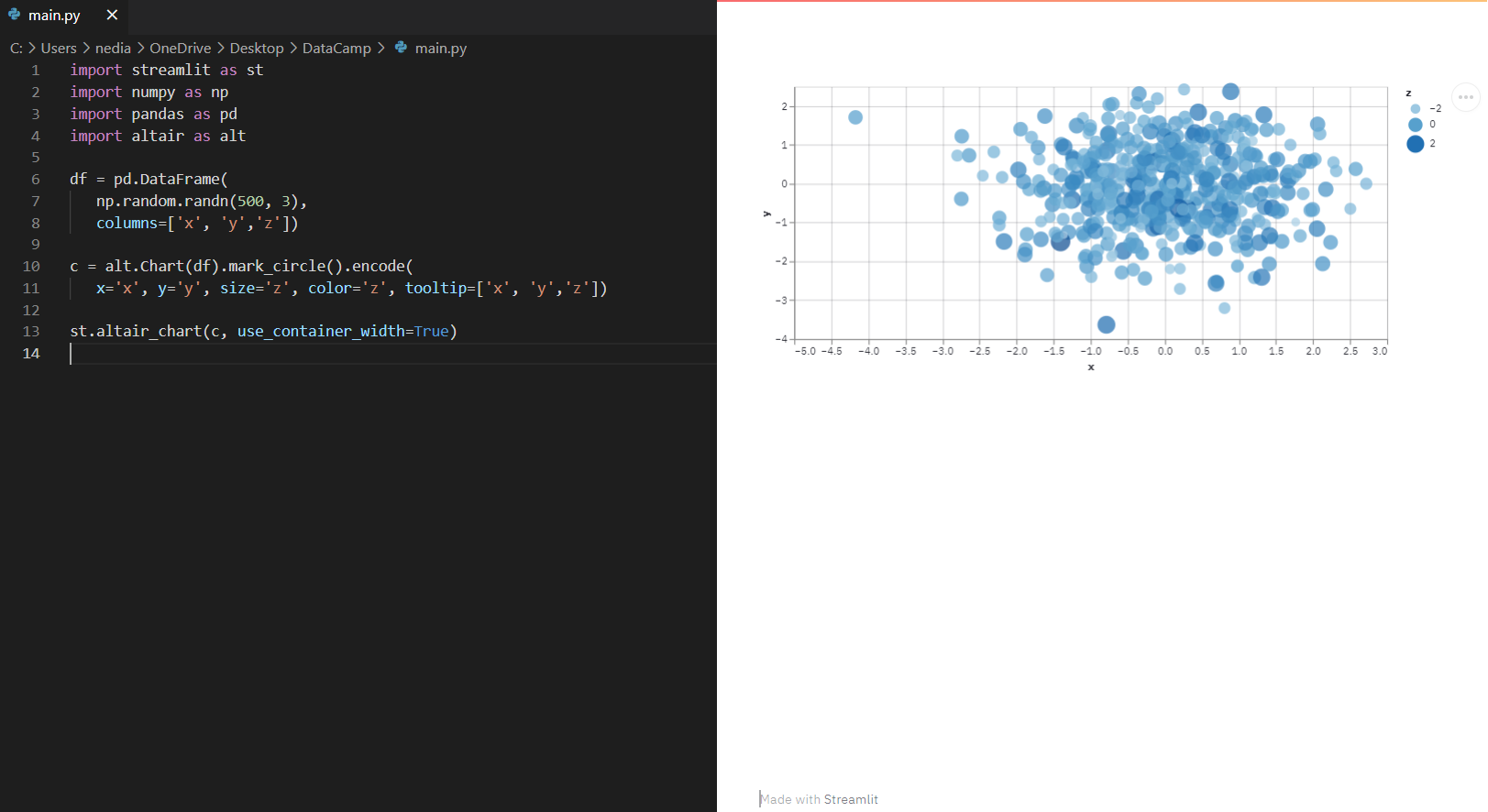
st.graphviz_chart(): Diese Funktion dient dazu, Graphenobjekte darzustellen, die mit verschiedenen Knoten und Kanten ergänzt werden können.
import streamlit as stimport graphviz as graphvizst.graphviz_chart(''' digraph { Big_shark -> Tuna Tuna -> Mackerel Mackerel -> Small_fishes Small_fishes -> Shrimp }''')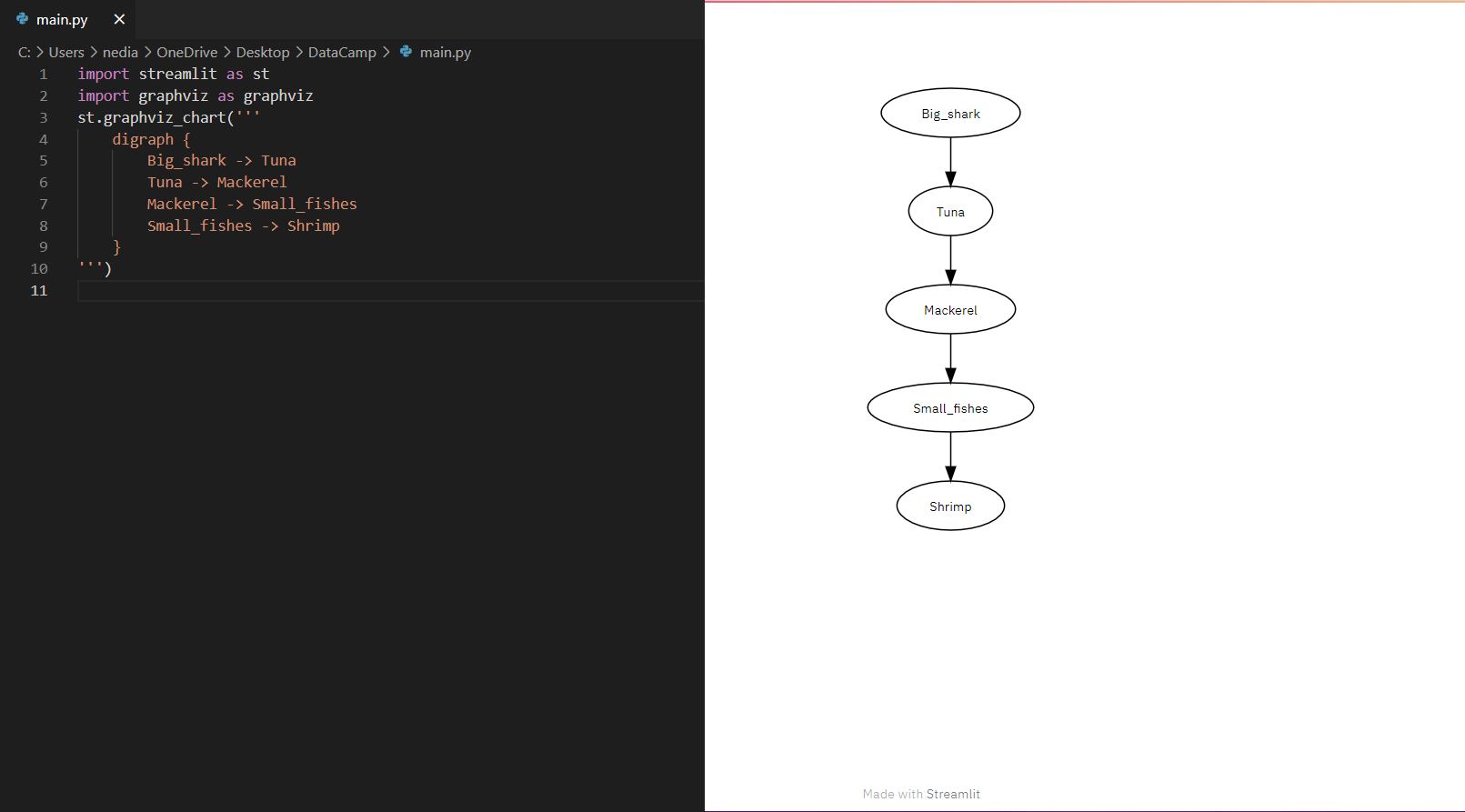
Karten mit Streamlit anzeigen
st.map(): Diese Funktion wird verwendet, um Karten in der App anzuzeigen. Allerdings werden die Werte für Breiten- und Längengrad benötigt, und diese Werte sollten nicht null/NA sein.
import pandas as pdimport numpy as npimport streamlit as stdf = pd.DataFrame(np.random.randn(500, 2) / [50, 50] + [37.76, -122.4],columns=['lat', 'lon'])st.map(df)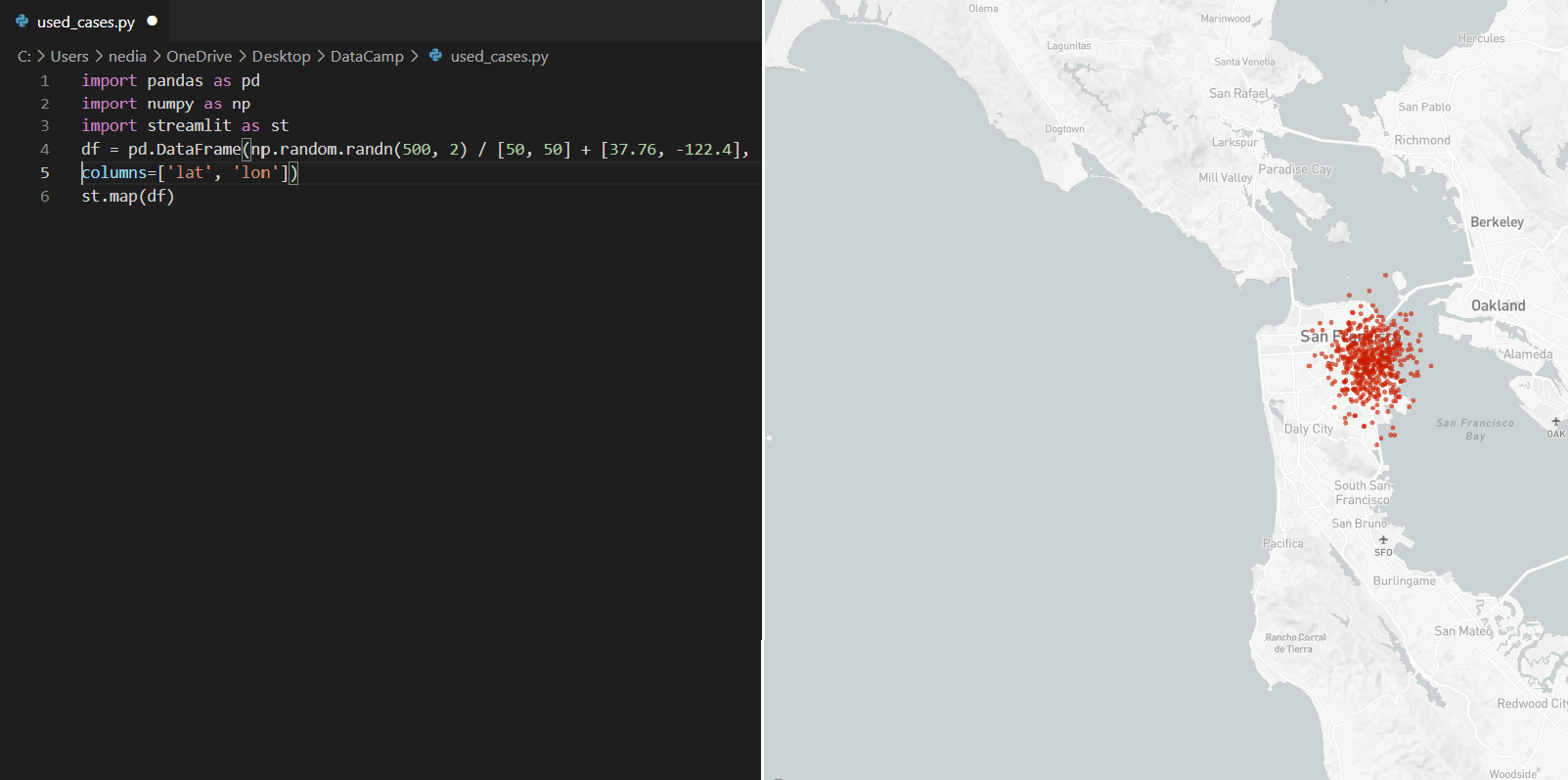
Themen
Du kannst auch ein Thema wählen, das deinen Stil widerspiegelt. Folge den Schritten im GIF unten:

Und wenn du mehr über Styling und Themes erfahren möchtest, kannst du einen Blick auf Theming werfen.
Jetzt ist es an der Zeit, gemeinsam eine App zu entwickeln!
Eine Anwendung für maschinelles Lernen erstellen
In diesem Abschnitt führe ich dich durch ein Projekt, das ich zum Thema Kreditprognose gemacht habe.
Der Hauptgewinn von Krediten stammt direkt aus den Kreditzinsen. Die Kreditunternehmen gewähren einen Kredit nach einem intensiven Prüfungs- und Validierungsprozess. Sie haben aber immer noch keine Gewissheit, ob der Antragsteller in der Lage ist, den Kredit ohne Schwierigkeiten zurückzuzahlen. In diesem Lernprogramm werden wir ein Vorhersagemodell (Random Forest Classifier) erstellen, um den Kreditstatus eines Antragstellers vorherzusagen. Unsere Aufgabe ist es, eine Web-App so vorzubereiten, dass sie in der Produktion verfügbar ist.
Wir beginnen damit, die notwendigen Bibliotheken für unsere App zu importieren:
import streamlit as stimport pandas as pdimport numpy as npimport pickle #to load a saved modelimport base64 #to open .gif files in streamlit appIn dieser App werden wir mehrere Widgets als Schieberegler verwenden: Selectbox und Radio im Sidebar-Menü, für die wir einige Python-Funktionen vorbereiten werden.Das Beispiel wird eine einfache Demo mit zwei Seiten sein. Auf der Startseite werden die von uns ausgewählten Daten angezeigt, während du auf der Seite "Exploration" Variablen in Diagrammen visualisieren kannst und auf der Seite "Prediction" (Vorhersage) Variablen mit einer Schaltfläche namens "Predict" (Vorhersage) findest, mit der du den Kreditstatus schätzen kannst. Mit dem folgenden Code erhältst du ein Auswahlfeld in der Seitenleiste, mit dem du eine Seite auswählen kannst. Die Daten werden zwischengespeichert, damit sie nicht ständig neu geladen werden müssen.
@st.cache ist ein Caching-Mechanismus, mit dem deine App auch dann performant bleibt, wenn du Daten aus dem Web lädst, große Datensätze bearbeitest oder teure Berechnungen durchführst.
@st.cache(suppress_st_warning=True)def get_fvalue(val): feature_dict = {"No":1,"Yes":2} for key,value in feature_dict.items(): if val == key: return valuedef get_value(val,my_dict): for key,value in my_dict.items(): if val == key: return valueapp_mode = st.sidebar.selectbox('Select Page',['Home','Prediction']) #two pages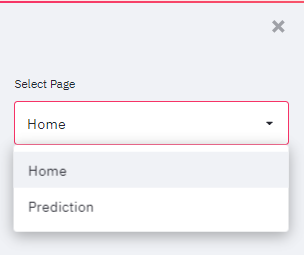
Auf der Startseite visualisieren wir: das Präsentationsbild / den Datensatz / das Histogramm des Einkommens des Antragstellers und des Kreditbetrags.
Hinweis: Wir werden if/elif/else verwenden, um zwischen den Seiten zu wechseln.
Wir laden die Datei loan_dataset.csv in variable Daten, die es uns ermöglichen, ein paar Zeilen davon auf der Startseite anzuzeigen.
if app_mode=='Home': st.title('LOAN PREDICTION :') st.image('loan_image.jpg') st.markdown('Dataset :') data=pd.read_csv('loan_dataset.csv') st.write(data.head()) st.markdown('Applicant Income VS Loan Amount ') st.bar_chart(data[['ApplicantIncome','LoanAmount']].head(20))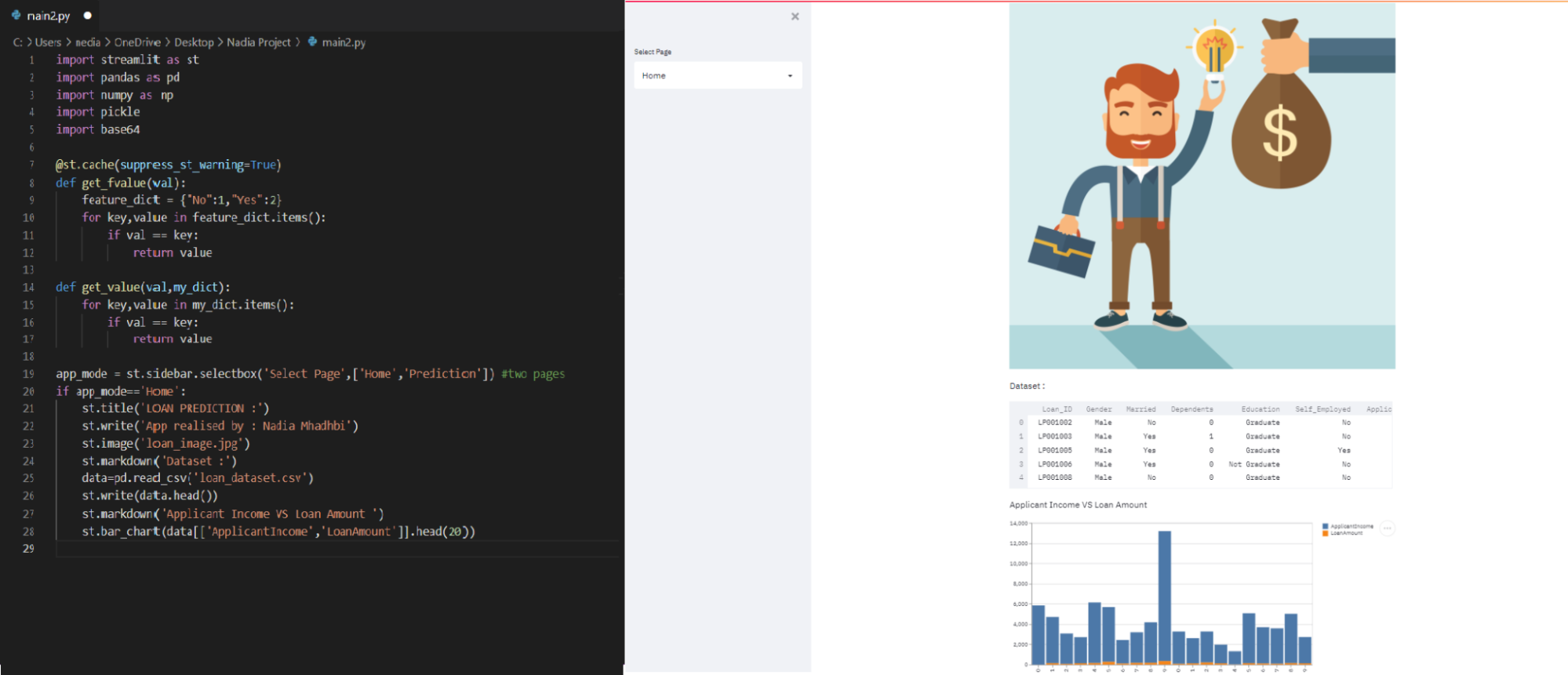
Dann auf der Seite "Vorhersage":
elif app_mode == 'Prediction': st.image('slider-short-3.jpg') st.subheader('Sir/Mme , YOU need to fill all necessary informations in order to get a reply to your loan request !') st.sidebar.header("Informations about the client :") gender_dict = {"Male":1,"Female":2} feature_dict = {"No":1,"Yes":2} edu={'Graduate':1,'Not Graduate':2} prop={'Rural':1,'Urban':2,'Semiurban':3} ApplicantIncome=st.sidebar.slider('ApplicantIncome',0,10000,0,) CoapplicantIncome=st.sidebar.slider('CoapplicantIncome',0,10000,0,) LoanAmount=st.sidebar.slider('LoanAmount in K$',9.0,700.0,200.0) Loan_Amount_Term=st.sidebar.selectbox('Loan_Amount_Term',(12.0,36.0,60.0,84.0,120.0,180.0,240.0,300.0,360.0)) Credit_History=st.sidebar.radio('Credit_History',(0.0,1.0)) Gender=st.sidebar.radio('Gender',tuple(gender_dict.keys())) Married=st.sidebar.radio('Married',tuple(feature_dict.keys())) Self_Employed=st.sidebar.radio('Self Employed',tuple(feature_dict.keys())) Dependents=st.sidebar.radio('Dependents',options=['0','1' , '2' , '3+']) Education=st.sidebar.radio('Education',tuple(edu.keys())) Property_Area=st.sidebar.radio('Property_Area',tuple(prop.keys())) class_0 , class_3 , class_1,class_2 = 0,0,0,0 if Dependents == '0': class_0 = 1 elif Dependents == '1': class_1 = 1 elif Dependents == '2' : class_2 = 1 else: class_3= 1 Rural,Urban,Semiurban=0,0,0 if Property_Area == 'Urban' : Urban = 1 elif Property_Area == 'Semiurban' : Semiurban = 1 else : Rural=1Wir haben zwei Funktionen get_value(val,my_dict) und get_fvalue(val) und Wörterbücher als feature_dict geschrieben, um st.sidebar.radio() mit nicht-numerischen Variablen zu manipulieren. Das ist optional, du kannst so etwas einfach machen:

Mal sehen, warum wir das getan haben.
Hinweis: Algorithmen für maschinelles Lernen können keine kategorischen Variablen verarbeiten. Im Datensatz habe ich etwas Feature Engineering betrieben. Die Spalte "Verheiratet" hat zum Beispiel zwei Variablen "Ja" und "Nein" und ich habe eine Label-Kodierung vorgenommen (sieh dir das an, um es besser zu verstehen), sodass "Nein" gleich 1 und "Ja" gleich 2 ist. Die Funktion get_fvalue(val) wird einfach den Wert (1/2) zurückgeben, je nachdem, was der Kunde gewählt hat. Dasselbe gilt für die Funktion get_value(val,my_dict) . Der Unterschied zwischen den beiden Funktionen ist, dass die erste für Ja/Nein-Merkmale funktioniert und die zweite für den allgemeinen Fall, dass wir mehrere Variablen haben (Beispiel: Geschlecht ).
Wie wir sehen können, hat die Variable Dependents vier Kategorien: 0, 1, 2 und 3+, und wir können so etwas nicht in eine numerische Variable umwandeln, und wir haben "+3", was bedeutet, dass Dependents 3, 4, 5 ... haben kann. Wir haben ein One Hot Enconding durchgeführt (sieh es dir an, um es besser zu verstehen). So haben wir ein Sidebar-Radio erstellt, das die vier Elemente enthält und jedes hat eine binäre Variable.
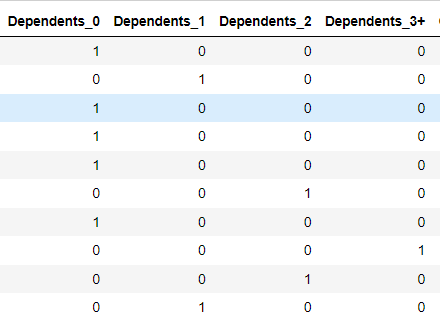
Außerdem haben wir eine Hot-Codierung für Property_Area vorgenommen und deshalb 3 Variablen erstellt (Rural, Urban, Semiurban). Wenn Rural den Wert 1 annimmt, sind die anderen Variablen gleich 0.
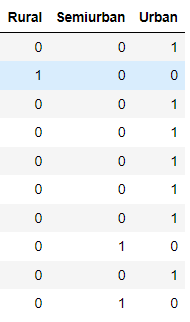
Wir haben also beides gesehen - wenn wir unsere Features beschriften oder eine heiße Kodierung und wie man damit umgeht, um erfolgreich eine funktionierende Streamlit-App zu erstellen.
data1={ 'Gender':Gender, 'Married':Married, 'Dependents':[class_0,class_1,class_2,class_3], 'Education':Education, 'ApplicantIncome':ApplicantIncome, 'CoapplicantIncome':CoapplicantIncome, 'Self Employed':Self_Employed, 'LoanAmount':LoanAmount, 'Loan_Amount_Term':Loan_Amount_Term, 'Credit_History':Credit_History, 'Property_Area':[Rural,Urban,Semiurban], } feature_list=[ApplicantIncome,CoapplicantIncome,LoanAmount,Loan_Amount_Term,Credit_History,get_value(Gender,gender_dict),get_fvalue(Married),data1['Dependents'][0],data1['Dependents'][1],data1['Dependents'][2],data1['Dependents'][3],get_value(Education,edu),get_fvalue(Self_Employed),data1['Property_Area'][0],data1['Property_Area'][1],data1['Property_Area'][2]] single_sample = np.array(feature_list).reshape(1,-1)Jetzt werden wir unsere Variablen in einem Wörterbuch speichern, denn wir haben get_value(val,my_dict) und get_fvalue(val) geschrieben, um mit Wörterbüchern umzugehen. Danach werden die Eingaben - die der Client in unserer Streamlit-App als Eingaben auswählen wird - in einer Liste namens feature_list und dann in einer Numpy-Variablen namens single_sample angeordnet.
Hinweis: Die Eingaben der Merkmale müssen in der gleichen Reihenfolge wie die Spalten des Datensatzes angeordnet sein (z. B. kann Married nicht die Eingabe von Gender übernehmen).
if st.button("Predict"): file_ = open("6m-rain.gif", "rb") contents = file_.read() data_url = base64.b64encode(contents).decode("utf-8") file_.close() file = open("green-cola-no.gif", "rb") contents = file.read() data_url_no = base64.b64encode(contents).decode("utf-8") file.close() loaded_model = pickle.load(open('Random_Forest.sav', 'rb')) prediction = loaded_model.predict(single_sample) if prediction[0] == 0 : st.error( 'According to our Calculations, you will not get the loan from Bank' ) st.markdown( f'<img src="data:image/gif;base64,{data_url_no}" alt="cat gif">', unsafe_allow_html=True,) elif prediction[0] == 1 : st.success( 'Congratulations!! you will get the loan from Bank' ) st.markdown( f'<img src="data:image/gif;base64,{data_url}" alt="cat gif">', unsafe_allow_html=True, )Schließlich laden wir unser gespeichertes RandomForestClassifier-Modell in loaded_model und seine Vorhersage, die 0 oder 1 ist (Klassifizierungsproblem) in prediction. Die .gif-Dateien werden in file und file_ gespeichert. Je nach dem Wert von prediction gibt es zwei Fälle: "Erfolgreich" oder "Gescheitert", um einen Kredit von der Bank zu bekommen.
Dies ist unsere Vorhersage-Seite:
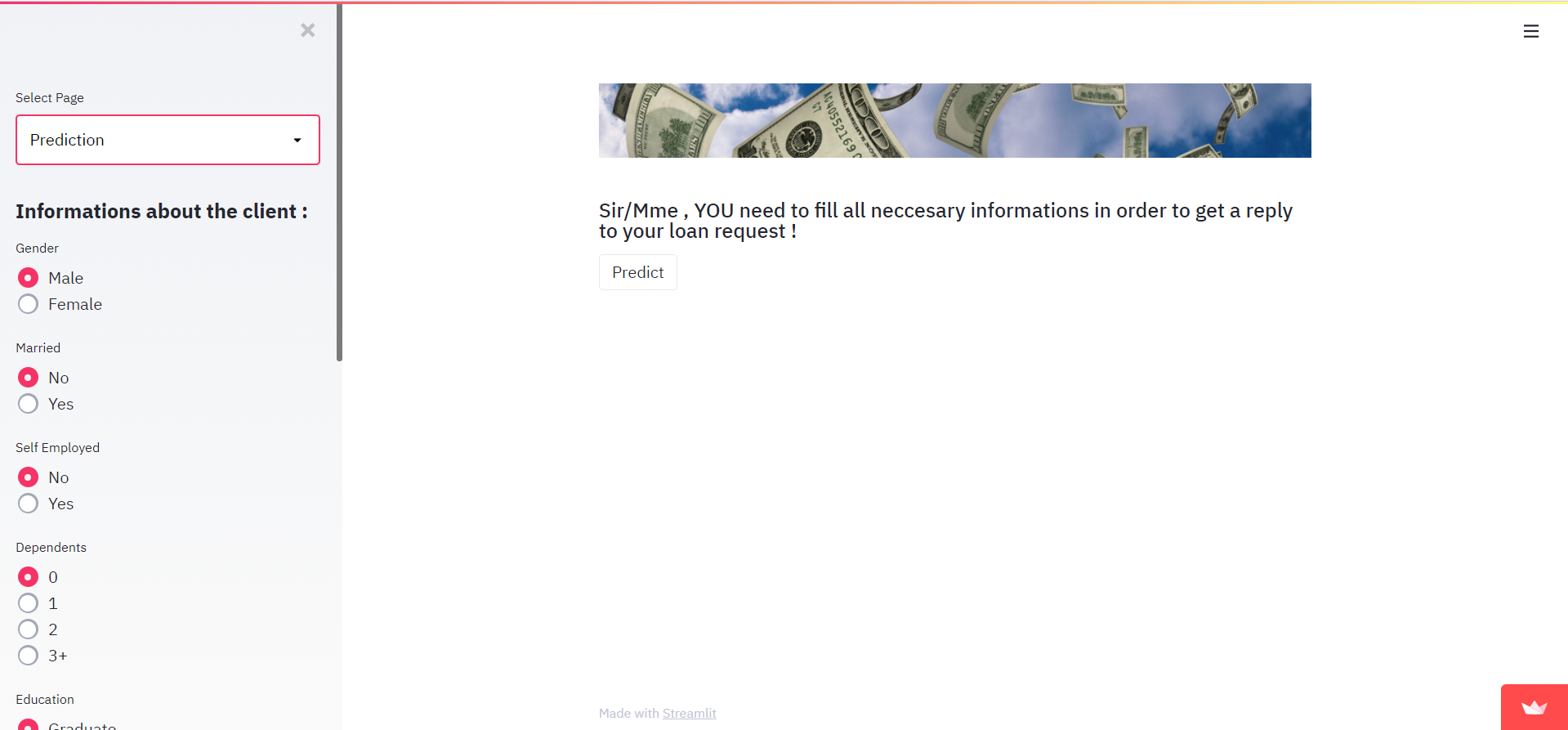
Im Fall von FAILURE sieht die Ausgabe wie folgt aus:
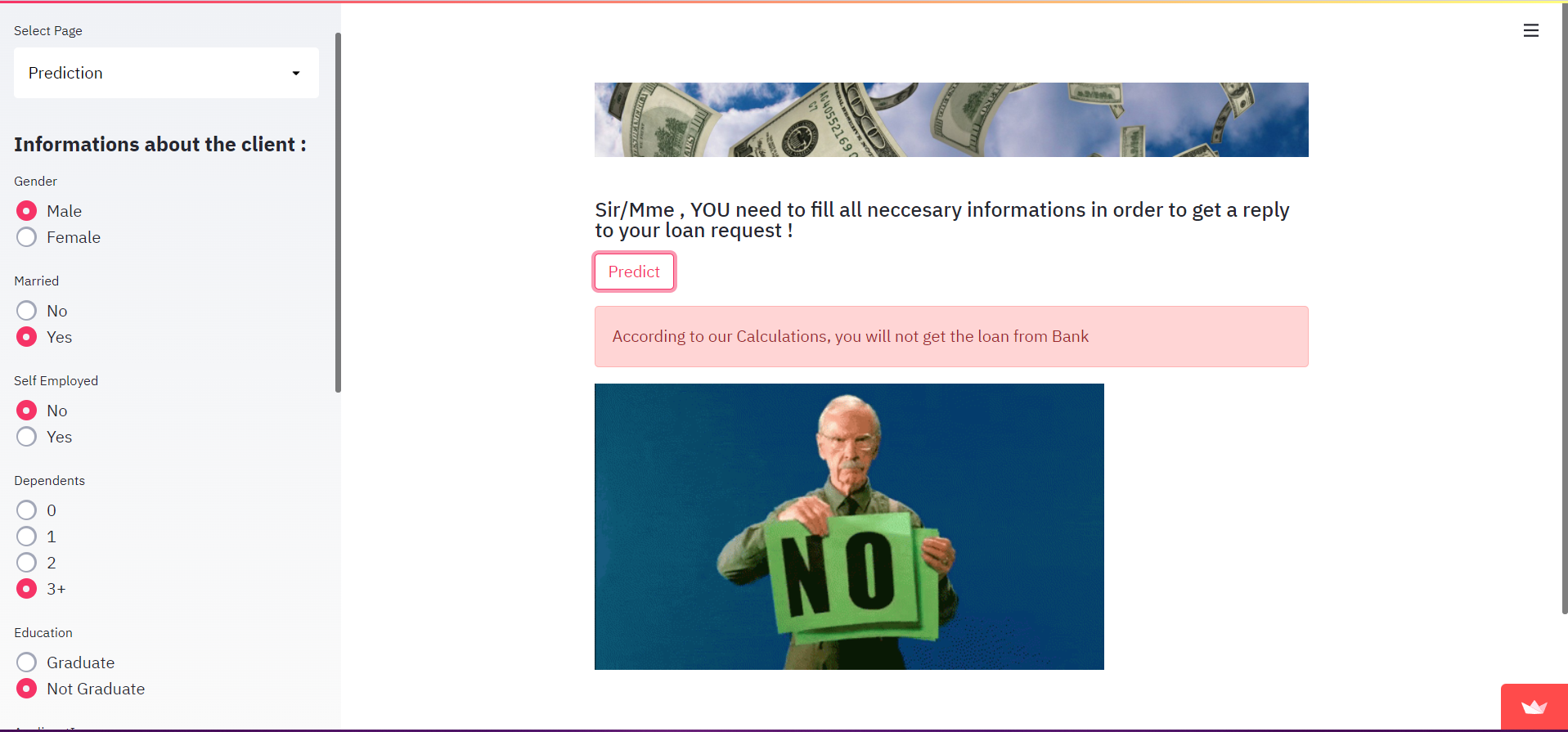
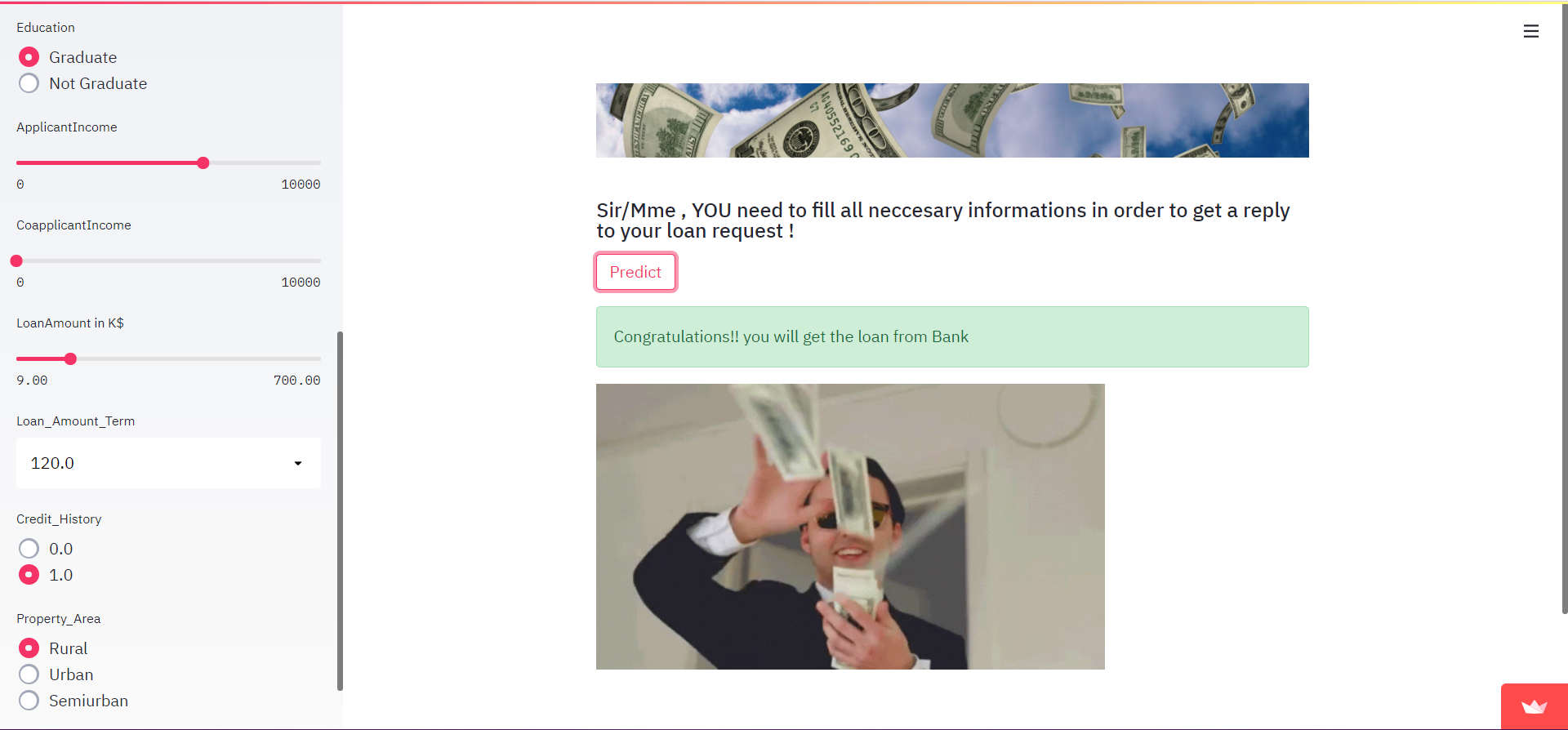
Im Falle von SUCCESS sieht die Ausgabe wie folgt aus:
5. Wie man eine Streamlit-App einsetzt
Die Bereitstellung ist der Mechanismus, über den die Anwendungen von den Entwicklern an die Nutzer geliefert werden.
Die Bereitstellung einer Anwendung ist der Prozess des Kopierens, Konfigurierens und Aktivierens einer bestimmten Anwendung auf einer bestimmten Basis-URL. Sobald der Bereitstellungsprozess abgeschlossen ist, wird die Anwendung unter der Basis-URL öffentlich zugänglich. Der Server führt diesen zweistufigen Prozess durch, indem er die Anwendung zunächst bereitstellt und sie dann nach erfolgreicher Bereitstellung aktiviert.
Hier erfährst du, wie du eine Streamlit-App einrichten kannst!
Bevor du deine App bereitstellst, musst du ein neues Repository auf GitHub erstellen, in dem du deinen App-Code und die Abhängigkeiten ablegen musst.
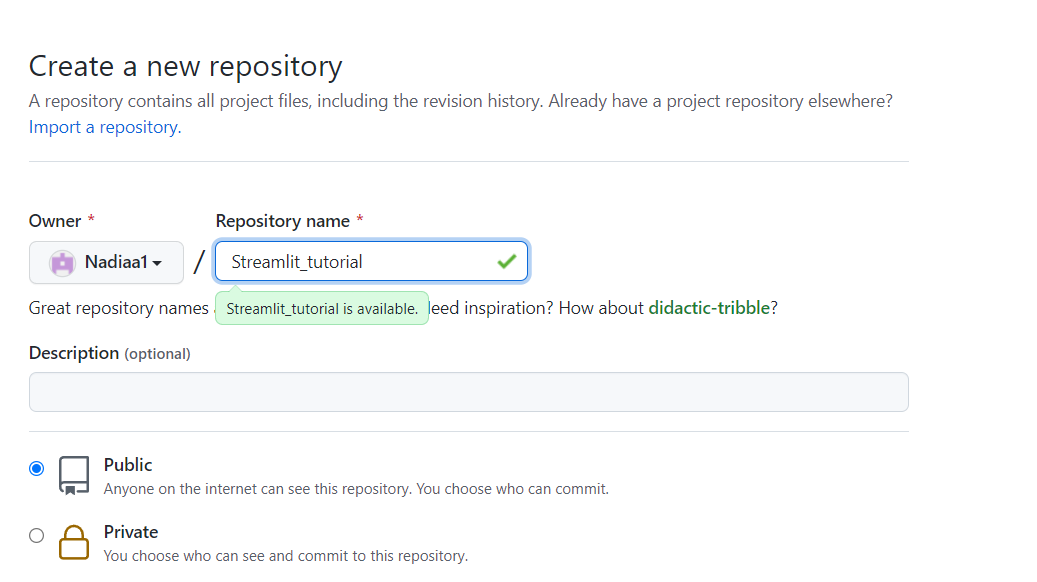
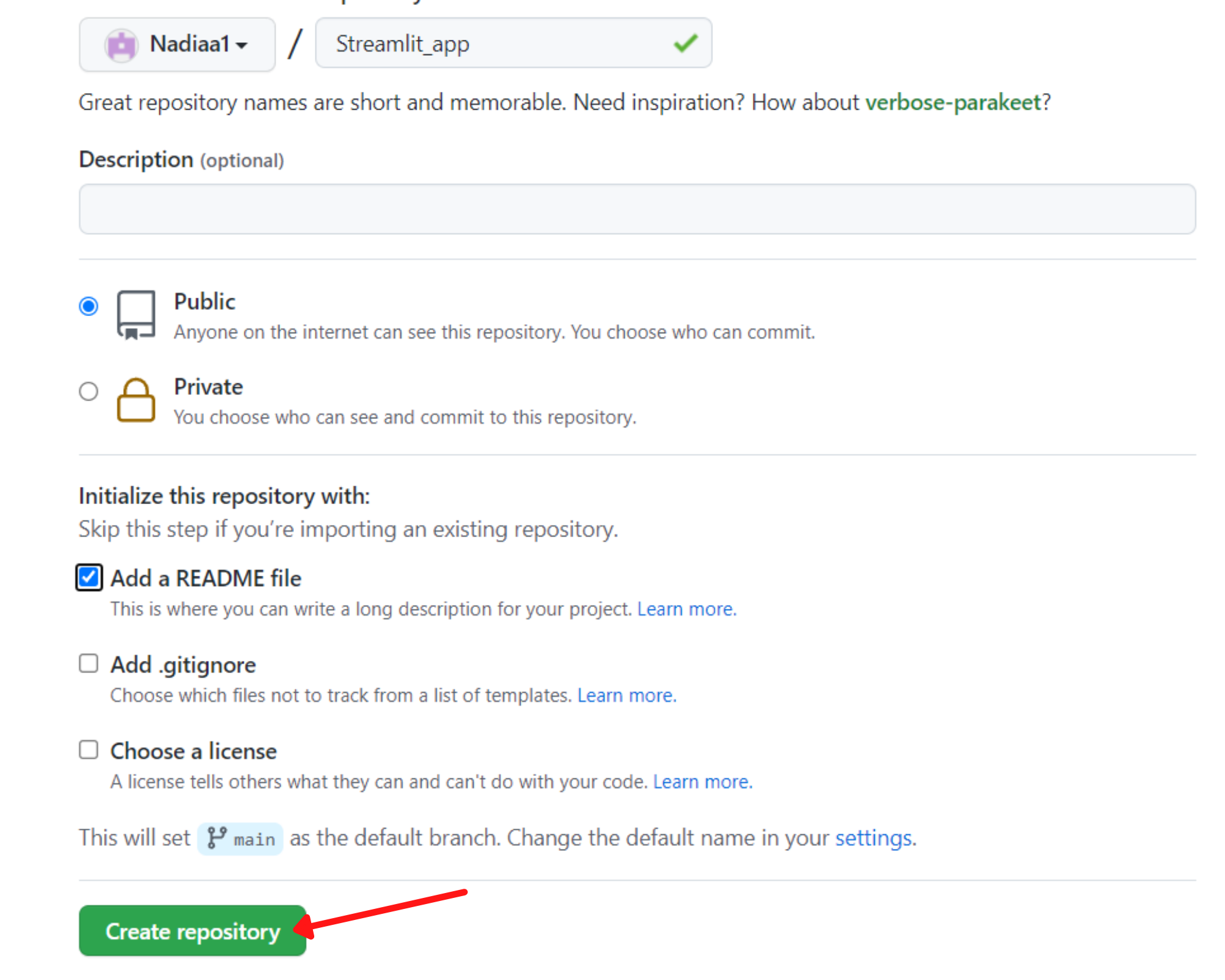
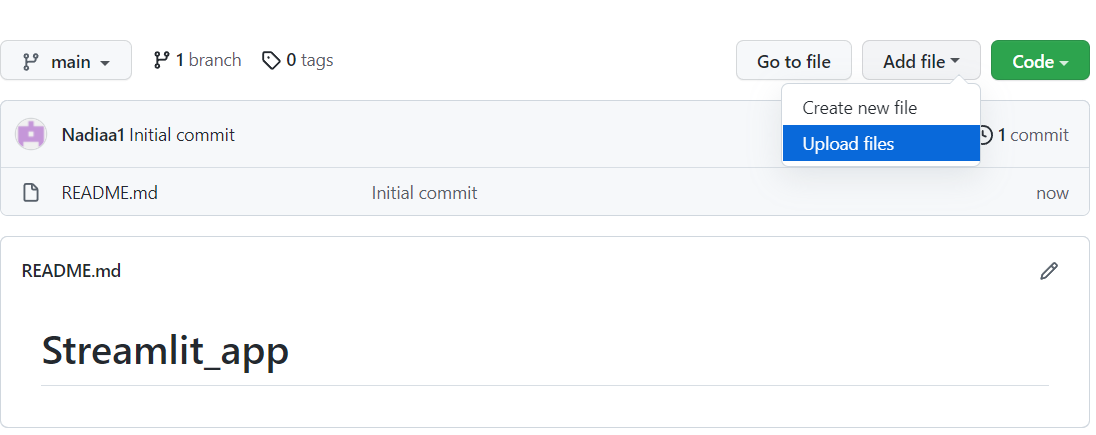
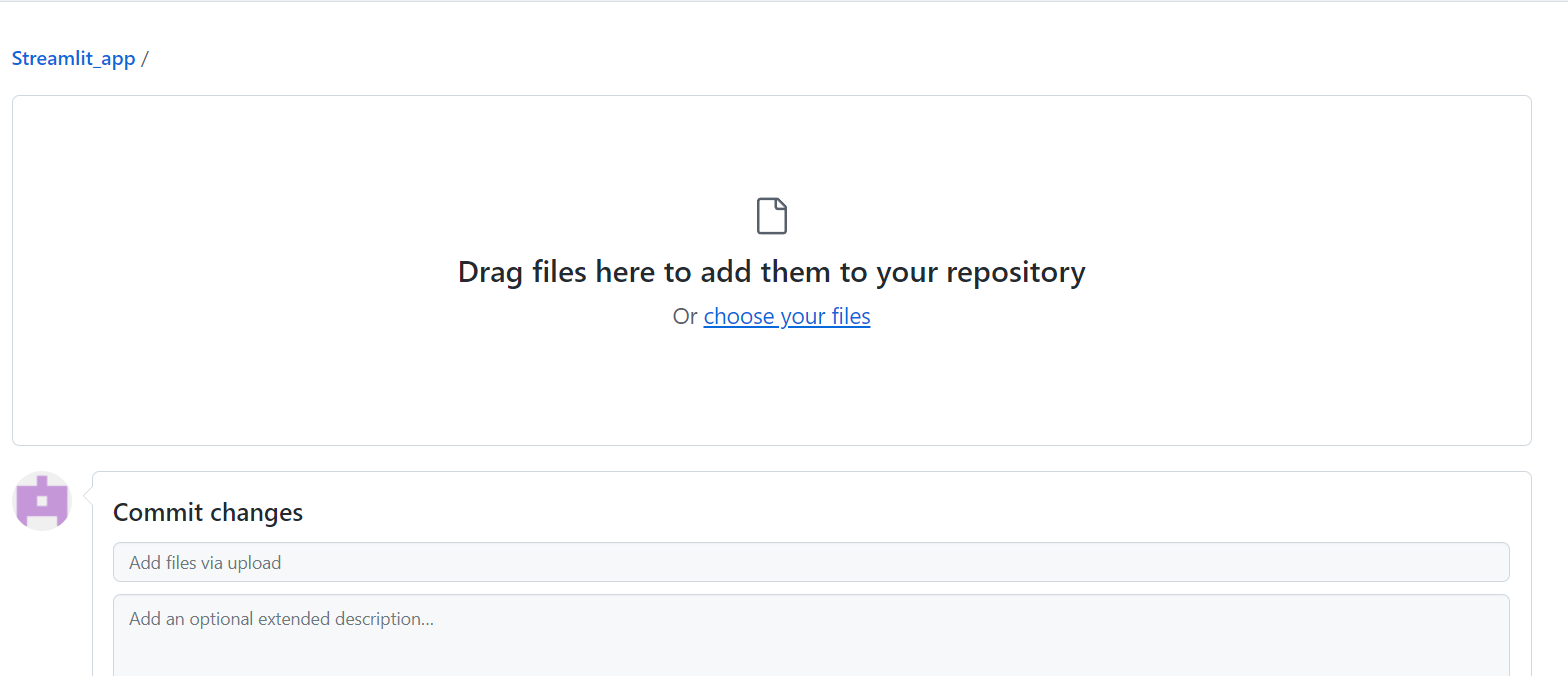
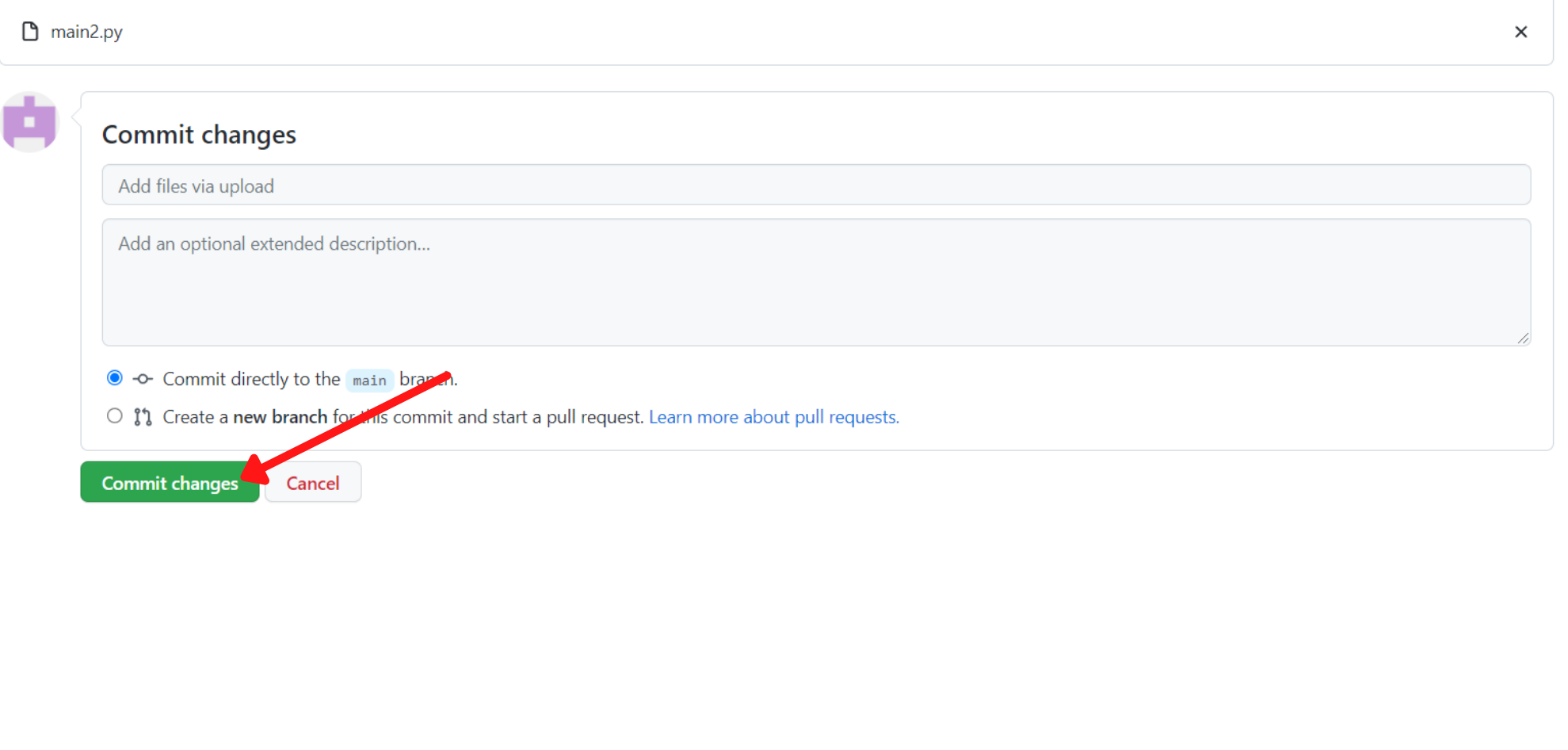
Klicke dann auf "Änderungen übertragen", um sie zu speichern:
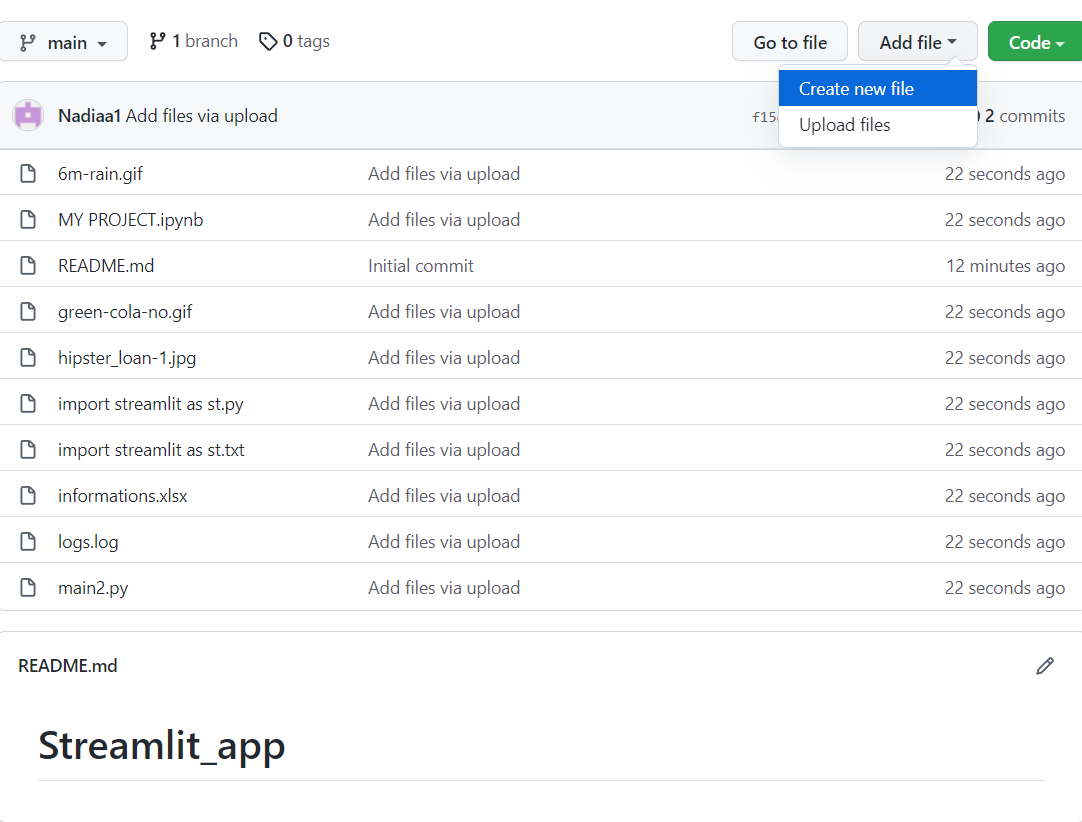
Nachdem du ein Repository erstellt und Dateien hochgeladen hast, musst du eine neue Datei mit dem Namen Requirements erstellen, in der du die Bibliotheken, die du in deiner App verwendest, ablegen musst.
Klicke zunächst auf "Neue Datei erstellen".
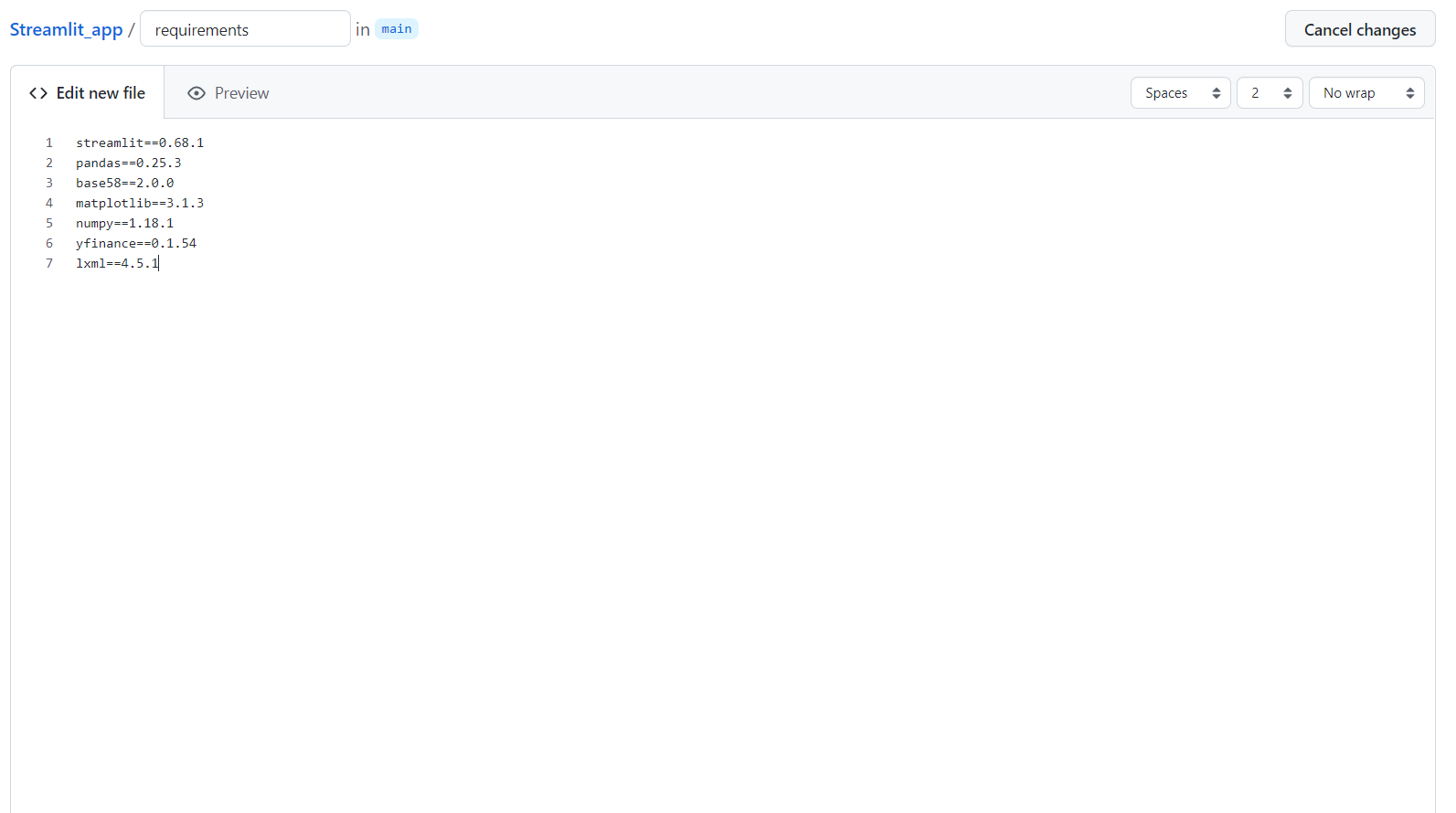
Jetzt bist du kurz davor, deine App bereitzustellen. Du musst nur noch diesen Link besuchen.
Dann befolge diese Schritte:
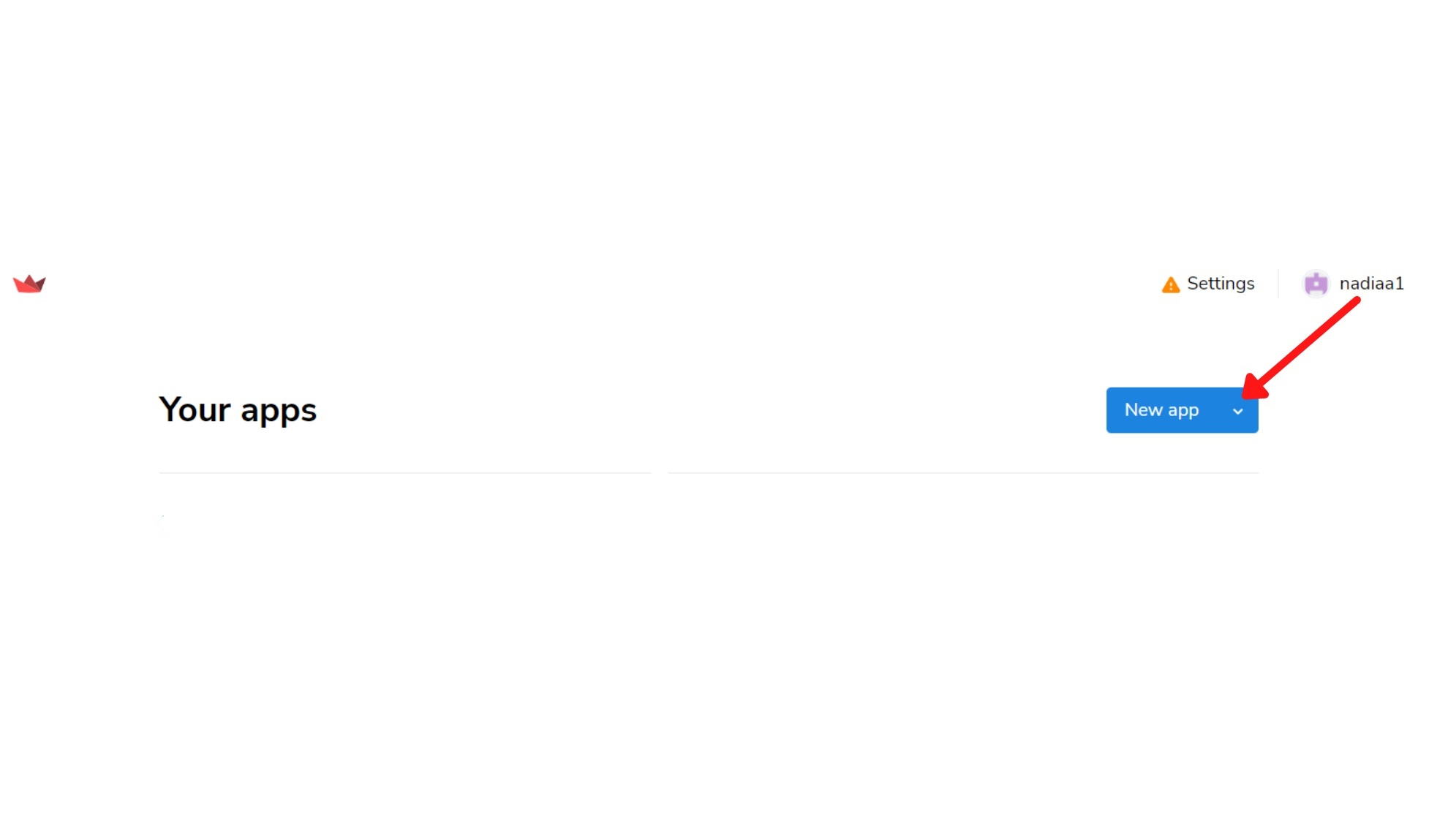
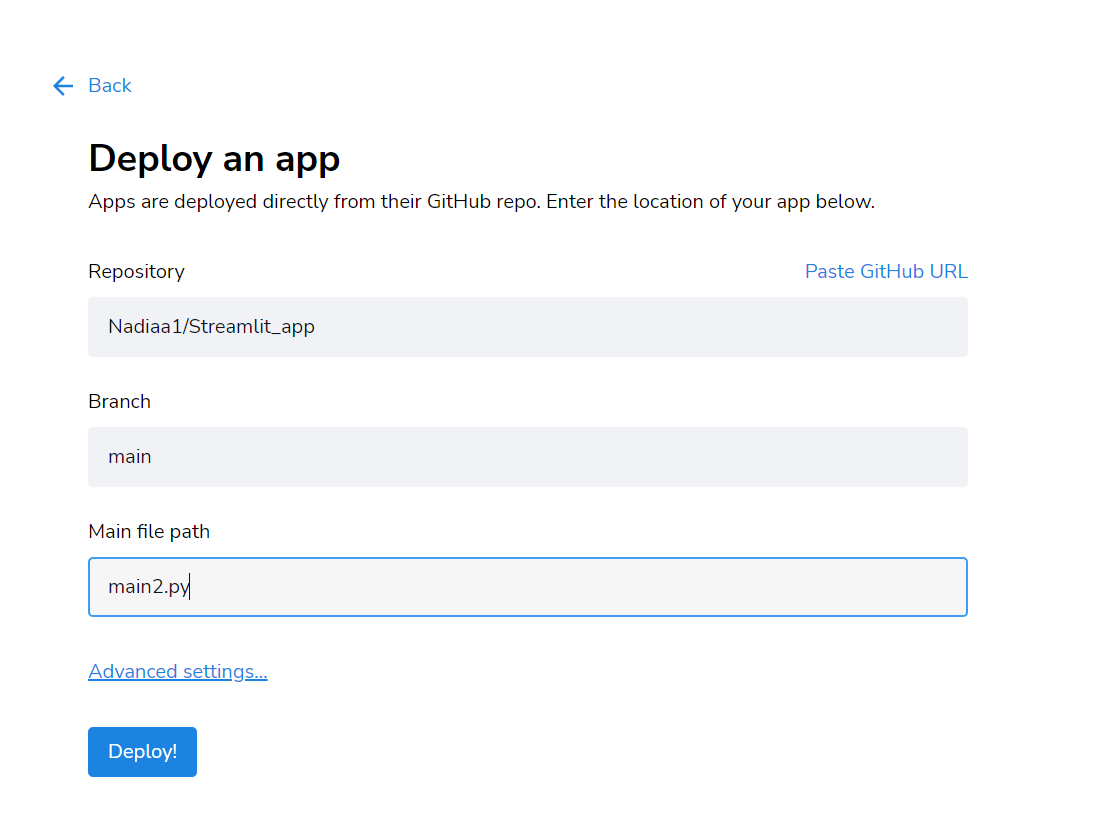
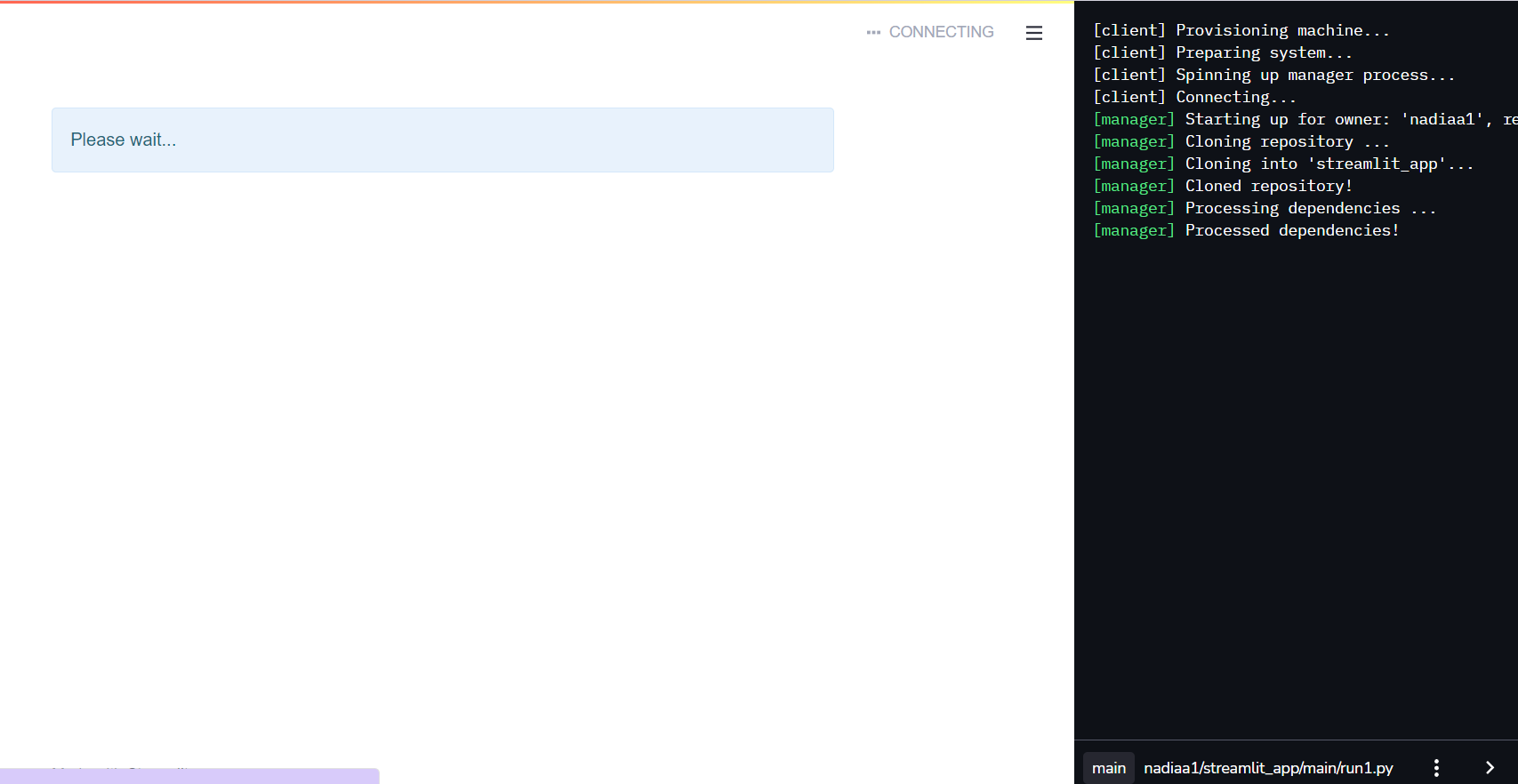
Klicke auf Bereitstellen und warte einen Moment!
Eine Seite wird automatisch in deinem Browser geöffnet! Diese Seite ist deine Projekt-App, die du mit Streamlit realisiert hast.
Herzlichen Glückwunsch, du hast deine App erfolgreich implementiert! Klicke hier, um die eingesetzte App zu überprüfen.
Weitere Dokumentation findest du unter folgendem Link: docs.streamlit.io
