Einführung in Datenbanken in Python
95.3K learners
Die Structured Query Language (SQL) ist die gebräuchlichste Sprache für die Durchführung verschiedener Datenanalyseaufgaben. Sie wird auch für die Pflege einer relationalen Datenbank verwendet, z.B. um Tabellen hinzuzufügen, Werte zu entfernen und die Datenbank zu optimieren. Eine einfache relationale Datenbank besteht aus mehreren Tabellen, die miteinander verbunden sind, und jede Tabelle besteht aus Zeilen und Spalten.
Im Durchschnitt erzeugt ein Technologieunternehmen jeden Tag Millionen von Datenpunkten. Es wird eine robuste und effektive Speicherlösung benötigt, damit sie die Daten nutzen können, um das aktuelle System zu verbessern oder ein neues Produkt zu entwickeln. Eine relationale Datenbank wie MySQL, PostgreSQL und SQLite löst diese Probleme, indem sie eine robuste Datenbankverwaltung, Sicherheit und hohe Leistung bietet.
Kernfunktionalitäten von SQL
SQL ist eine gefragte Fähigkeit, mit der du jeden Job in der Tech-Branche bekommen kannst. Unternehmen wie Meta, Google und Netflix sind immer auf der Suche nach Datenexperten, die Informationen aus SQL-Datenbanken extrahieren und innovative Lösungen entwickeln können. Die Grundlagen von SQL kannst du mit dem Tutorial Einführung in SQL auf DataCamp erlernen.
SQL kann uns helfen, die Leistung des Unternehmens zu ermitteln, das Kundenverhalten zu verstehen und die Erfolgskennzahlen von Marketingkampagnen zu überwachen. Die meisten Datenanalysten können die meisten Business-Intelligence-Aufgaben mit SQL-Abfragen erledigen. Warum brauchen wir dann Tools wie PoweBI, Python und R? Mithilfe von SQL-Abfragen kannst du feststellen, was in der Vergangenheit passiert ist, aber du kannst keine Prognosen für die Zukunft erstellen. Diese Instrumente helfen uns, mehr über die aktuelle Leistung und das potenzielle Wachstum zu erfahren.
Python und R sind Mehrzwecksprachen, die es Fachleuten ermöglichen, fortgeschrittene statistische Analysen durchzuführen, Modelle für maschinelles Lernen zu erstellen, Daten-APIs zu entwickeln und Unternehmen dabei zu helfen, über KPIs hinaus zu denken. In diesem Lernprogramm lernen wir, SQL-Datenbanken zu verbinden, Datenbanken zu füllen und SQL-Abfragen mit Python und R auszuführen.
Hinweis: Wenn du neu in SQL bist, solltest du den Lernpfad SQL besuchen, um die Grundlagen des Schreibens von SQL-Abfragen zu verstehen.
Das Python-Tutorial behandelt die Grundlagen der Verbindung mit verschiedenen Datenbanken (MySQL und SQLite), das Erstellen von Tabellen, das Hinzufügen von Datensätzen, das Ausführen von Abfragen und das Kennenlernen der Pandas-Funktion read_sql.
Wir können die Datenbank mit SQLAlchemy verbinden, aber in diesem Lehrgang werden wir das integrierte Python-Paket SQLite3 verwenden, um Abfragen an die Datenbank zu stellen. SQLAlchemy bietet Unterstützung für alle Arten von Datenbanken durch eine einheitliche API. Wenn du mehr über SQLAlchemy erfahren möchtest und wie es mit anderen Datenbanken zusammenarbeitet, dann schau dir den Kurs Einführung in Datenbanken in Python an.
MySQL ist die beliebteste Datenbank-Engine der Welt und wird von Unternehmen wie Youtube, Paypal, LinkedIn und GitHub eingesetzt. Hier lernen wir, wie man die Datenbank verbindet. Der Rest der Schritte zur Verwendung von MySQL ist ähnlich wie beim SQLite3-Paket.
Installiere zunächst das mysql-Paket mit '!pip install mysql' und erstelle dann eine lokale Datenbank-Engine, indem du deinen Benutzernamen, dein Passwort und den Datenbanknamen angibst.
import mysql.connector as sql
conn = sql.connect(
host="localhost",
user="abid",
password="12345",
database="datacamp_python"
)
Auf ähnliche Weise können wir eine SQLite-Datenbank mit der Funktion sqlite3.connect erstellen oder laden. SQLite ist eine Bibliothek, die eine in sich geschlossene, konfigurationsfreie und serverlose Datenbank-Engine implementiert. Es ist DataLab-freundlich, also werden wir es in unserem Projekt verwenden, um lokale Hostfehler zu vermeiden.
import sqlite3
import pandas as pd
conn= sqlite3.connect("datacamp_python.db")
In diesem Teil erfahren wir, wie wir den COVID-19-Datensatz über die Auswirkungen auf den Flughafenverkehr unter der CC BY-NC-SA 4.0-Lizenz in unsere SQLite-Datenbank laden. Wir werden auch lernen, wie man Tabellen von Grund auf neu erstellt.

Der Datensatz für den Flughafenverkehr besteht aus einem Prozentsatz des Verkehrsaufkommens während des Basiszeitraums vom 1. Februar 2020 bis zum 15. März 2020. Wir werden eine CSV-Datei mit der Pandas-Funktion read_csv laden und dann die Funktion to_sql verwenden, um den DataFrame in unsere SQLite-Tabelle zu übertragen. Die Funktion to_sql benötigt einen Tabellennamen (String) und eine Verbindung zur SQLite-Engine.
data = pd.read_csv("data/covid_impact_on_airport_traffic.csv")
data.to_sql(
'airport', # Name of the sql table
conn, # sqlite.Connection or sqlalchemy.engine.Engine
if_exists='replace'
)
Wir werden nun testen, ob wir erfolgreich waren, indem wir eine kurze SQL-Abfrage durchführen. Bevor wir eine Abfrage ausführen, müssen wir einen Cursor erstellen, der uns bei der Ausführung von Abfragen hilft, wie im folgenden Codeblock gezeigt. Du kannst mehrere Cursors auf dieselbe Datenbank innerhalb einer einzigen Verbindung haben.
In unserem Fall lieferte die SQL-Abfrage drei Spalten und fünf Zeilen aus der Tabelle " Flughafen". Um die erste Zeile anzuzeigen, verwenden wir cursor.fetchone().
cursor = conn.cursor()
cursor.execute("""SELECT Date, AirportName, PercentOfBaseline
FROM airport
LIMIT 5""")
cursor.fetchone()
>>> ('2020-04-03', 'Kingsford Smith', 64)
Um den Rest der Datensätze anzuzeigen, verwenden wir cursor.fetchall(). Der Flughafen-Datensatz wird mit ein paar Zeilen Code erfolgreich in die Datenbank geladen.
cursor.fetchall()
>>> [('2020-04-13', 'Kingsford Smith', 29),
('2020-07-10', 'Kingsford Smith', 54),
('2020-09-02', 'Kingsford Smith', 18),
('2020-10-31', 'Kingsford Smith', 22)]
Jetzt wollen wir lernen, wie man eine Tabelle von Grund auf erstellt und sie mit Beispielwerten füllt. Wir erstellen eine Tabelle studentinfo mit id (Integer, Primärschlüssel, Auto-Inkrement), Name (Text) und Betreff (Text).
Hinweis: Die SQLite-Syntax ist ein wenig anders. Es wird empfohlen, sich den SQLite-Spickzettel anzusehen, um die in diesem Lernprogramm erwähnten SQL-Abfragen zu verstehen.
cursor.execute("""
CREATE TABLE studentinfo
(
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
subject TEXT
)
""")
Überprüfen wir, wie viele Tabellen wir der Datenbank hinzugefügt haben, indem wir eine einfache SQLite-Abfrage ausführen.
cursor.execute("""
SELECT name
FROM sqlite_master
WHERE type='table'
""")
cursor.fetchall()
>>> [('airport',), ('studentinfo',)]
In diesem Abschnitt fügen wir der Tabelle studentinfo Werte hinzu und führen einfache SQL-Abfragen durch. Mit INSERT INTO können wir eine einzelne Zeile zur Tabelle " Schülerinfo" hinzufügen.
Um Werte einzufügen, müssen wir der Funktion execute eine Abfrage und Wertargumente übergeben. Die Funktion füllt die "?"-Eingänge mit den Werten, die wir angegeben haben.
query = """
INSERT INTO studentinfo
(name, subject)
VALUES (?, ?)
"""
value = ("Marry", "Math")
cursor.execute(query,value)
Wiederhole die obige Abfrage, indem du mehrere Datensätze hinzufügst.
query = """
INSERT INTO studentinfo
(name, subject)
VALUES (?, ?)
"""
values = [("Abid", "Stat"),
("Carry", "Math"),
("Ali","Data Science"),
("Nisha","Data Science"),
("Matthew","Math"),
("Henry","Data Science")]
cursor.executemany(query,values)
Es ist an der Zeit, den Rekord zu überprüfen. Dazu führen wir eine einfache SQL-Abfrage aus, die Zeilen zurückgibt, deren Betreff Data Science ist.
cursor.execute("""
SELECT *
FROM studentinfo
WHERE subject LIKE 'Data Science'
""")
cursor.fetchall()
>>> [(4, 'Ali', 'Data Science'),
(5, 'Nisha', 'Data Science'),
(7, 'Henry', 'Data Science')]
Der Befehl DISTINCT subject wird verwendet, um eindeutige Werte in Betreffspalten anzuzeigen. In unserem Fall sind es Mathe, Statistik und Datenwissenschaft.
cursor.execute("SELECT DISTINCT subject from studentinfo")
cursor.fetchall()
>>> [('Math',), ('Stat',), ('Data Science',)]
Um alle Änderungen zu speichern, verwenden wir die Funktion commit(). Ohne einen Commit sind die Daten nach dem Neustart des Rechners verloren.
conn.commit()
In diesem Teil lernen wir, wie wir die Daten aus der SQLite-Datenbank extrahieren und mit einer Zeile Code in einen Pandas-DataFrame umwandeln. read_sql bietet mehr als nur die Ausführung von SQL-Abfragen. Wir können sie verwenden, um Indexspalten zu setzen, Datum und Uhrzeit zu analysieren, Werte hinzuzufügen und Spaltennamen herauszufiltern. In einem kurzen DataCamp-Kurs erfährst du mehr über den Import von Daten in Python.
read_sql benötigt zwei Argumente: eine SQL-Abfrage und eine Verbindung zur SQLite-Engine. Die Ausgabe enthält die obersten fünf Zeilen der Flughafentabelle, in denen PercentOfBaseline größer als 20 ist.
data_sql_1 = pd.read_sql("""
SELECT Date,City,PercentOfBaseline
FROM airport
WHERE PercentOfBaseline > 20
ORDER BY Date DESC
""",
conn)
print(data_sql_1.head())
Date City PercentOfBaseline
0 2020-12-02 Sydney 27
1 2020-12-02 Santiago 48
2 2020-12-02 Calgary 99
3 2020-12-02 Leduc County 100
4 2020-12-02 Richmond 86
Die Datenanalyse in relationalen Datenbanken ist mit der Integration von Pandas einfacher geworden. Wir können diese Daten auch für Prognosen nutzen und komplexe statistische Analysen durchführen.
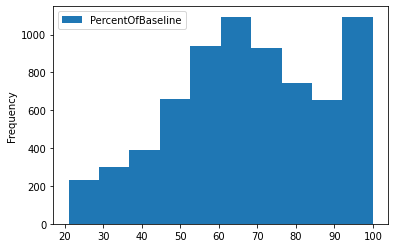
Die Funktion plot wird verwendet, um das Histogramm der Spalte PercentOfBaseline zu visualisieren.
data_sql_1.plot(y="PercentOfBaseline",kind="hist");
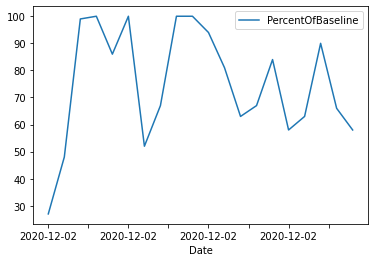
Genauso können wir die Werte auf die ersten 20 beschränken und ein Zeitreihen-Diagramm anzeigen.
data_sql_2 = pd.read_sql("""
SELECT Date,City,PercentOfBaseline
FROM airport
WHERE PercentOfBaseline > 20
ORDER BY Date DESC
LIMIT 20
""",
conn)
data_sql_2.plot(x="Date",y="PercentOfBaseline",kind="line");
Schließlich schließen wir die Verbindung, um Ressourcen freizugeben. Die meisten Pakete tun dies automatisch, aber es ist besser, die Verbindungen zu schließen, nachdem du die Änderungen abgeschlossen hast.
conn.close()
Wir werden alle Aufgaben aus dem Python-Tutorial mit R wiederholen. Das Tutorial beinhaltet das Erstellen von Verbindungen, das Schreiben von Tabellen, das Anhängen von Zeilen, das Ausführen von Abfragen und die Datenanalyse mit dplyr.
Das DBI-Paket wird für die Verbindung mit den gängigsten Datenbanken wie MariaDB, Postgres, Duckdb und SQLite verwendet. Installiere zum Beispiel das Paket RMySQL und erstelle eine Datenbank, indem du einen Benutzernamen, ein Passwort, einen Datenbanknamen und eine Hostadresse angibst.
install.packages("RMySQL")
library(RMySQL)
conn = dbConnect(
MySQL(),
user = 'abid',
password = '1234',
dbname = 'datacamp_R',
host = 'localhost'
)
In diesem Lernprogramm werden wir eine SQLite-Datenbank erstellen, indem wir einen Namen und die SQLite-Funktion angeben.
library(RSQLite)
library(DBI)
library(tidyverse)
conn = dbConnect(SQLite(), dbname = 'datacamp_R.db')
Indem wir die tidyverse-Bibliothek importieren, haben wir Zugriff auf die Datensätze dplyr, ggplot und defaults.
dbWriteTable Funktion nimmt data.frame und fügt es in die SQL-Tabelle ein. Sie benötigt drei Argumente: die Verbindung zu SQLite, den Namen der Tabelle und den Datenrahmen. Mit dbReadTable können wir die gesamte Tabelle einsehen. Um die obersten 6 Zeilen anzuzeigen, haben wir head verwendet.
dbWriteTable(conn, "cars", mtcars)
head(dbReadTable(conn, "cars"))
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
4 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
5 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
6 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
dbExecute können wir jede beliebige SQLite-Abfrage ausführen, also werden wir sie benutzen, um eine Tabelle namens idcard zu erstellen.
Um die Namen der Tabellen in der Datenbank anzuzeigen, verwenden wir dbListTables.
dbExecute(conn, 'CREATE TABLE idcard (id int, name text)')
dbListTables(conn)
>>> 'cars''idcard'
Fügen wir der Tabelle idcard eine einzelne Zeile hinzu und verwenden dbGetQuery, um die Ergebnisse anzuzeigen.
Hinweis: dbGetQuery führt eine Abfrage aus und gibt die Datensätze zurück, während dbExecute eine SQL-Abfrage ausführt, aber keine Datensätze zurückgibt.
dbExecute(conn, "INSERT INTO idcard (id,name)\
VALUES(1,'love')")
dbGetQuery(conn,"SELECT * FROM idcard")
id name
1 love
Wir werden nun zwei weitere Zeilen hinzufügen und die Ergebnisse mit dbReadTable anzeigen.
dbExecute(conn,"INSERT INTO idcard (id,name)\
VALUES(2,'Kill'),(3,'Game')
")
dbReadTable(conn,'idcard')
id name
1 love
2 Kill
3 Game
dbCreateTable können wir eine problemlose Tabelle erstellen. Sie benötigt drei Argumente: Verbindung, Name der Tabelle und entweder einen Zeichenvektor oder einen data.frame. Der Zeichenvektor besteht aus Namen (Spaltennamen) und Werten (Typen). In unserem Fall werden wir einen Standard-Bevölkerungsdatenrahmen verwenden, um die Ausgangsstruktur zu erstellen.
dbCreateTable(conn,'population',population)
dbReadTable(conn,'population')
country year population
Dann verwenden wir dbAppendTable, um die Werte in der Tabelle der Bevölkerung zu addieren.
dbAppendTable(conn,'population',head(population))
dbReadTable(conn,'population')
country year population
Afghanistan 1995 17586073
Afghanistan 1996 18415307
Afghanistan 1997 19021226
Afghanistan 1998 19496836
Afghanistan 1999 19987071
Afghanistan 2000 20595360
Wir verwenden dbGetQuery, um alle unsere Datenanalyseaufgaben zu erledigen. Versuchen wir, eine einfache Abfrage auszuführen und dann mehr über andere Funktionen zu erfahren.
dbGetQuery(conn,"SELECT * FROM idcard")
id name
1 love
2 Kill
3 Game
Du kannst auch eine komplexe SQL-Abfrage ausführen, um die Pferdestärken zu filtern und begrenzte Zeilen und Spalten anzuzeigen.
dbGetQuery(conn, "SELECT mpg,hp,gear\
FROM cars\
WHERE hp > 50\
LIMIT 5")
mpg hp gear
21.0 110 4
21.0 110 4
22.8 93 4
21.4 110 3
18.7 175 3
Um Tabellen zu entfernen, verwende dbRemoveTable. Wie wir jetzt sehen können, haben wir die Tabelle idcard erfolgreich entfernt.
dbRemoveTable(conn,'idcard')
dbListTables(conn)
>>> 'cars''population'
Um mehr über Tabellen zu erfahren, verwenden wir dbListFields, das die Spaltennamen in einer bestimmten Tabelle anzeigt.
dbListFields(conn, "cars")
>>> 'mpg''cyl''disp''hp''drat''wt''qsec''vs''am''gear''carb'
In diesem Abschnitt werden wir dplyr verwenden, um Tabellen zu lesen und dann Abfragen mit filter, select und collect durchzuführen. Wenn du keine SQL-Syntax lernen willst und alle Aufgaben mit reinem R erledigen willst, dann ist diese Methode genau das Richtige für dich. Wir haben die Tabelle mit den Autos herangezogen, sie nach Gängen und Benzinverbrauch gefiltert und dann drei Spalten ausgewählt, wie unten gezeigt.
cars_results <-
tbl(conn, "cars") %>%
filter(gear %in% c(4, 3),
mpg >= 14,
mpg <= 21) %>%
select(mpg, hp, gear) %>%
collect()
cars_results
mpg hp gear
21.0 110 4
21.0 110 4
18.7 175 3
18.1 105 3
14.3 245 3
... ... ...
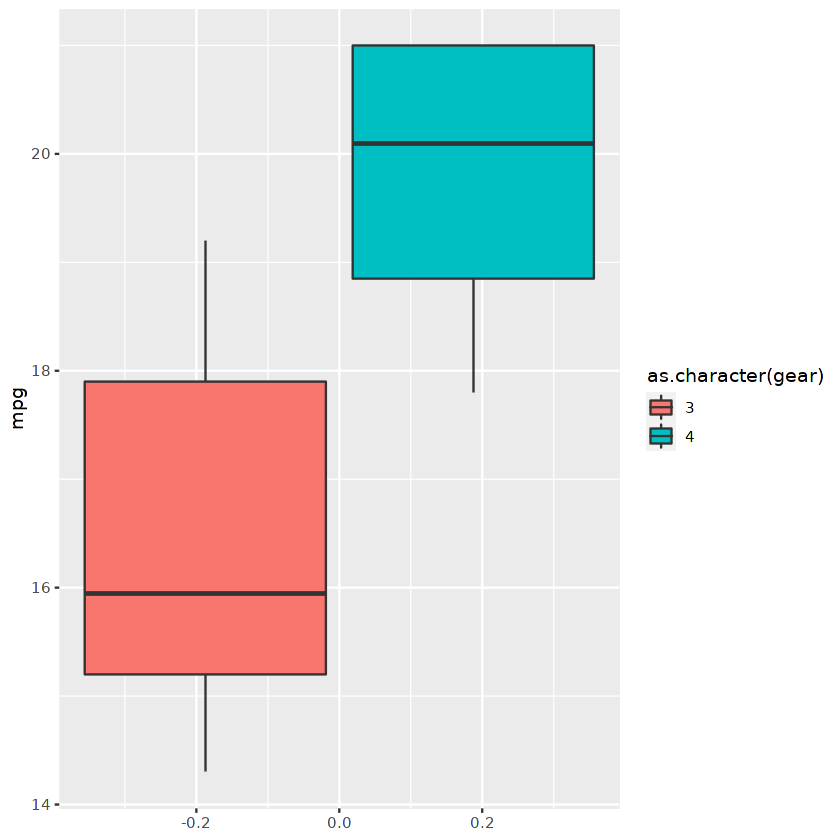
Wir können den gefilterten Datenrahmen verwenden, um ein Boxplot-Diagramm mit ggplot anzuzeigen.
ggplot(cars_results,aes(fill=as.character(gear), y=mpg)) +
geom_boxplot()
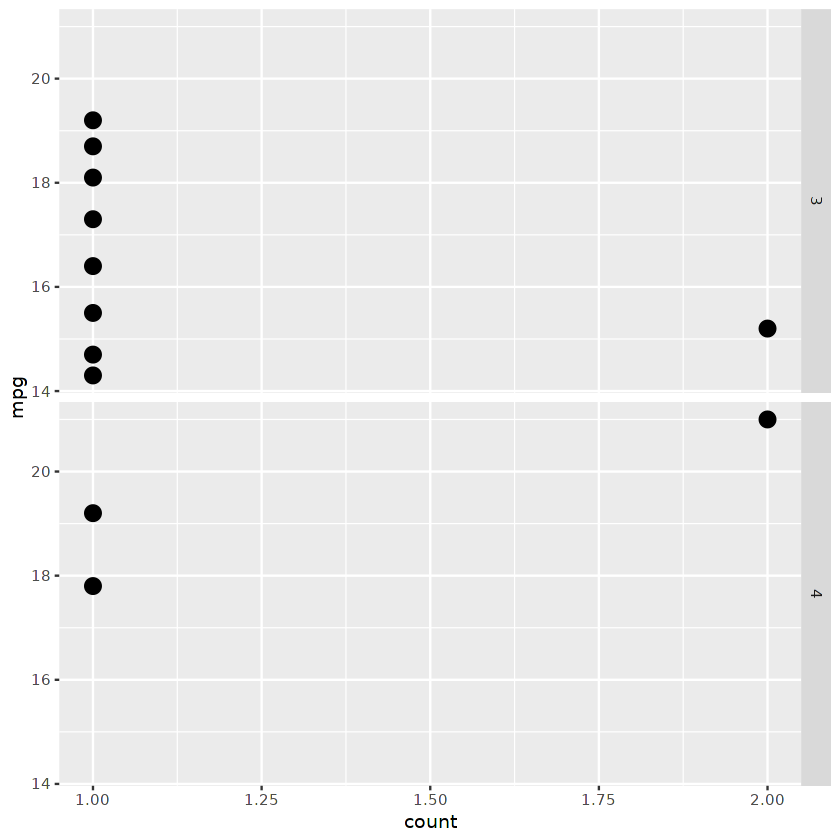
Oder wir können ein Facettenpunktdiagramm, geteilt durch die Anzahl der Gänge, anzeigen.
ggplot(cars_results,
aes(mpg, ..count.. ) ) +
geom_point(stat = "count", size = 4) +
coord_flip()+
facet_grid( as.character(gear) ~ . )
In diesem Tutorium haben wir gelernt, wie wichtig es ist, SQL-Abfragen mit Python und R auszuführen, Datenbanken zu erstellen, Tabellen hinzuzufügen und Datenanalysen mit SQL-Abfragen durchzuführen. Wir haben auch gelernt, wie Pandas und dplyr uns helfen, Abfragen mit einer einzigen Zeile Code auszuführen.
SQL ist ein Muss für alle Berufe im technischen Bereich. Wenn du deine Karriere als Datenanalyst/in beginnst, empfehlen wir dir, den Lernpfad Data Analyst with SQL Server innerhalb von zwei Monaten zu absolvieren. Auf diesem Lernpfad lernst du alles über SQL-Abfragen, Server und die Verwaltung von Ressourcen.
Du kannst alle Skripte, die in diesem Lernprogramm verwendet werden, kostenlos ausführen:
Verwandte Python- und SQL-Kurse
Kurs
Kurs