Introduction aux bases de données en Python
95.3K learners
Le langage de requête structuré (SQL) est le langage le plus couramment utilisé pour exécuter diverses tâches d'analyse de données. Il est également utilisé pour la maintenance d'une base de données relationnelle, par exemple : l'ajout de tableaux, la suppression de valeurs et l'optimisation de la base de données. Une base de données relationnelle simple se compose de plusieurs tableaux interconnectés, chaque tableau étant constitué de lignes et de colonnes.
En moyenne, une entreprise technologique génère des millions de points de données chaque jour. Une solution de stockage robuste et efficace est nécessaire pour pouvoir utiliser les données afin d'améliorer le système actuel ou de créer un nouveau produit. Les bases de données relationnelles telles que MySQL, PostgreSQL et SQLite résolvent ces problèmes en offrant une gestion robuste des bases de données, une sécurité et des performances élevées.
Fonctionnalités de base de SQL
Le langage SQL est une compétence très demandée qui vous aidera à décrocher n'importe quel emploi dans le secteur technologique. Des entreprises telles que Meta, Google et Netflix sont toujours à la recherche de professionnels des données capables d'extraire des informations des bases de données SQL et de proposer des solutions innovantes. Vous pouvez apprendre les bases de SQL en suivant le tutoriel Introduction à SQL sur DataCamp.
SQL peut nous aider à découvrir les performances de l'entreprise, à comprendre les comportements des clients et à contrôler les indicateurs de réussite des campagnes de marketing. La plupart des analystes de données peuvent effectuer la majorité des tâches de business intelligence en exécutant des requêtes SQL, alors pourquoi avons-nous besoin d'outils tels que Python, Python et R ? En utilisant des requêtes SQL, vous pouvez savoir ce qui s'est passé dans le passé, mais vous ne pouvez pas prédire les projections futures. Ces outils nous aident à mieux comprendre les performances actuelles et la croissance potentielle.
Python et R sont des langages polyvalents qui permettent aux professionnels d'exécuter des analyses statistiques avancées, de construire des modèles d'apprentissage automatique, de créer des API de données et, finalement, d'aider les entreprises à penser au-delà des KPI. Dans ce tutoriel, nous allons apprendre à connecter des bases de données SQL, à alimenter des bases de données et à exécuter des requêtes SQL à l'aide de Python et de R.
Note : Si vous êtes novice en SQL, suivez le cursus de compétences SQL pour comprendre les principes fondamentaux de l'écriture de requêtes SQL.
Le tutoriel Python couvrira les bases de la connexion avec différentes bases de données (MySQL et SQLite), la création de tableaux, l'ajout d'enregistrements, l'exécution de requêtes et l'apprentissage de la fonction Python read_sql.
Nous pouvons connecter la base de données à l'aide de SQLAlchemy, mais dans ce tutoriel, nous allons utiliser le paquetage Python intégré SQLite3 pour exécuter des requêtes sur la base de données. SQLAlchemy prend en charge tous les types de bases de données grâce à une API unifiée. Si vous souhaitez en savoir plus sur SQLAlchemy et sur la façon dont il fonctionne avec d'autres bases de données, consultez le cours Introduction aux bases de données en Python.
MySQL est le moteur de base de données le plus populaire au monde, et il est largement utilisé par des entreprises telles que Youtube, Paypal, LinkedIn et GitHub. Nous allons ici apprendre à connecter la base de données. Les autres étapes de l'utilisation de MySQL sont similaires à celles du paquetage SQLite3.
Tout d'abord, installez le paquet mysql en utilisant '!pip install mysql' et créez ensuite un moteur de base de données local en fournissant votre nom d'utilisateur, votre mot de passe et le nom de la base de données.
import mysql.connector as sql
conn = sql.connect(
host="localhost",
user="abid",
password="12345",
database="datacamp_python"
)
De même, nous pouvons créer ou charger une base de données SQLite en utilisant la fonction sqlite3.connect. SQLite est une bibliothèque qui met en œuvre un moteur de base de données autonome, sans configuration et sans serveur. Il est compatible avec DataLab, nous l'utiliserons donc dans notre projet pour éviter les erreurs liées à l'hôte local.
import sqlite3
import pandas as pd
conn= sqlite3.connect("datacamp_python.db")
Dans cette partie, nous allons apprendre à charger le jeu de données COVID-19's impact on airport traffic, sous licence CC BY-NC-SA 4.0, dans notre base de données SQLite. Nous apprendrons également à créer des tableaux à partir de zéro.

L'ensemble des données relatives au trafic aéroportuaire correspond à un pourcentage du volume de trafic pendant la période de référence allant du 1er février 2020 au 15 mars 2020. Nous chargerons un fichier CSV à l'aide de la fonction Pandas read_csv, puis nous utiliserons la fonction to_sql pour transférer le cadre de données dans notre tableau SQLite. La fonction to_sql nécessite un nom de tableau (String) et une connexion au moteur SQLite.
data = pd.read_csv("data/covid_impact_on_airport_traffic.csv")
data.to_sql(
'airport', # Name of the sql table
conn, # sqlite.Connection or sqlalchemy.engine.Engine
if_exists='replace'
)
Nous allons maintenant vérifier si nous avons réussi en exécutant une requête SQL rapide. Avant d'exécuter une requête, nous devons créer un curseur qui nous aidera à exécuter les requêtes, comme le montre le bloc de code ci-dessous. Vous pouvez avoir plusieurs curseurs sur la même base de données au sein d'une même connexion.
Dans notre cas, la requête SQL renvoie trois colonnes et cinq tableaux du tableau des aéroports. Pour afficher la première ligne, nous utiliserons cursor.fetchone().
cursor = conn.cursor()
cursor.execute("""SELECT Date, AirportName, PercentOfBaseline
FROM airport
LIMIT 5""")
cursor.fetchone()
>>> ('2020-04-03', 'Kingsford Smith', 64)
Pour afficher le reste des enregistrements, nous utiliserons cursor.fetchall(). Le jeu de données de l'aéroport est chargé avec succès dans la base de données en quelques lignes de code.
cursor.fetchall()
>>> [('2020-04-13', 'Kingsford Smith', 29),
('2020-07-10', 'Kingsford Smith', 54),
('2020-09-02', 'Kingsford Smith', 18),
('2020-10-31', 'Kingsford Smith', 22)]
Maintenant, apprenons à créer un tableau à partir de zéro et à l'alimenter en ajoutant des valeurs d'échantillonnage. Nous allons créer un tableau studentinfo avec l'identifiant (entier, clé primaire, auto-incrément), le nom (texte) et le sujet (texte).
Note : La syntaxe de SQLite est un peu différente. Il est recommandé de consulter l'aide-mémoire SQLite pour comprendre les requêtes SQL mentionnées dans ce tutoriel.
cursor.execute("""
CREATE TABLE studentinfo
(
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT,
subject TEXT
)
""")
Vérifions le nombre de tableaux que nous avons ajoutés à la base de données en exécutant une simple requête SQLite.
cursor.execute("""
SELECT name
FROM sqlite_master
WHERE type='table'
""")
cursor.fetchall()
>>> [('airport',), ('studentinfo',)]
Dans cette section, nous allons ajouter des valeurs au tableau " Informations sur les étudiants" et exécuter des requêtes SQL simples. En utilisant INSERT INTO, nous pouvons ajouter une seule ligne au tableau studentinfo.
Pour insérer des valeurs, nous devons fournir une requête et des arguments de valeur à la fonction execute. La fonction remplit les entrées " ?" avec les valeurs que nous avons fournies.
query = """
INSERT INTO studentinfo
(name, subject)
VALUES (?, ?)
"""
value = ("Marry", "Math")
cursor.execute(query,value)
Répétez la requête ci-dessus en ajoutant plusieurs enregistrements.
query = """
INSERT INTO studentinfo
(name, subject)
VALUES (?, ?)
"""
values = [("Abid", "Stat"),
("Carry", "Math"),
("Ali","Data Science"),
("Nisha","Data Science"),
("Matthew","Math"),
("Henry","Data Science")]
cursor.executemany(query,values)
Il est temps de vérifier le dossier. Pour ce faire, nous allons exécuter une simple requête SQL qui renverra les lignes dont le sujet est Data Science.
cursor.execute("""
SELECT *
FROM studentinfo
WHERE subject LIKE 'Data Science'
""")
cursor.fetchall()
>>> [(4, 'Ali', 'Data Science'),
(5, 'Nisha', 'Data Science'),
(7, 'Henry', 'Data Science')]
La commande DISTINCT subject est utilisée pour afficher les valeurs uniques présentes dans les colonnes sujet. Dans notre cas, il s'agit des mathématiques, des statistiques et de la science des données.
cursor.execute("SELECT DISTINCT subject from studentinfo")
cursor.fetchall()
>>> [('Math',), ('Stat',), ('Data Science',)]
Pour enregistrer toutes les modifications, nous utiliserons la fonction commit(). Sans validation, les données seront perdues après le redémarrage de la machine.
conn.commit()
Dans cette partie, nous allons apprendre à extraire les données de la base de données SQLite et à les convertir en un cadre de données Pandas en une seule ligne de code. read_sql offre bien plus que l'exécution de requêtes SQL. Nous pouvons l'utiliser pour définir des colonnes d'index, analyser la date et l'heure, ajouter des valeurs et filtrer les noms de colonnes. Apprenez-en plus sur l'importation de données en Python en suivant une courte formation DataCamp.
read_sql nécessite deux arguments : une requête SQL et une connexion au moteur SQLite. Le résultat contient les cinq premiers tableaux du tableau des aéroports où PercentOfBaseline est supérieur à 20.
data_sql_1 = pd.read_sql("""
SELECT Date,City,PercentOfBaseline
FROM airport
WHERE PercentOfBaseline > 20
ORDER BY Date DESC
""",
conn)
print(data_sql_1.head())
Date City PercentOfBaseline
0 2020-12-02 Sydney 27
1 2020-12-02 Santiago 48
2 2020-12-02 Calgary 99
3 2020-12-02 Leduc County 100
4 2020-12-02 Richmond 86
L'exécution d'analyses de données sur des bases de données relationnelles est devenue plus facile grâce à l'intégration de Pandas. Nous pouvons également utiliser ces données pour prévoir les valeurs et effectuer des analyses statistiques complexes.
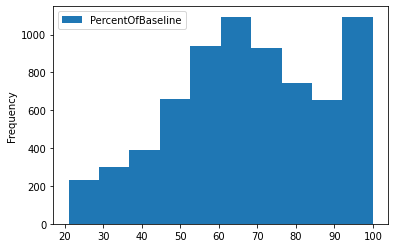
La fonction plot est utilisée pour visualiser l'histogramme de la colonne PercentOfBaseline.
data_sql_1.plot(y="PercentOfBaseline",kind="hist");
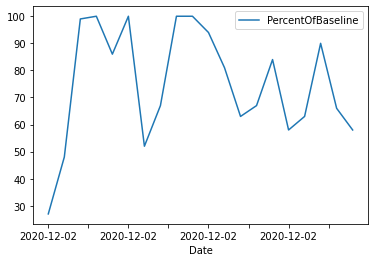
De même, nous pouvons limiter les valeurs aux 20 premières et afficher un graphique linéaire de la série chronologique.
data_sql_2 = pd.read_sql("""
SELECT Date,City,PercentOfBaseline
FROM airport
WHERE PercentOfBaseline > 20
ORDER BY Date DESC
LIMIT 20
""",
conn)
data_sql_2.plot(x="Date",y="PercentOfBaseline",kind="line");
Enfin, nous fermerons la connexion pour libérer des ressources. La plupart des logiciels le font automatiquement, mais il est préférable de fermer les connexions après avoir finalisé les modifications.
conn.close()
Nous allons reproduire toutes les tâches du tutoriel Python en utilisant R. Le tutoriel comprend la création de connexions, l'écriture de tableaux, l'ajout de lignes, l'exécution de requêtes et l'analyse de données avec Python.
Le paquet DBI est utilisé pour se connecter aux bases de données les plus populaires telles que MariaDB, Postgres, Duckdb et SQLite. Par exemple, installez le paquet RMySQL et créez une base de données en fournissant un nom d'utilisateur, un mot de passe, un nom de base de données et une adresse hôte.
install.packages("RMySQL")
library(RMySQL)
conn = dbConnect(
MySQL(),
user = 'abid',
password = '1234',
dbname = 'datacamp_R',
host = 'localhost'
)
Dans ce tutoriel, nous allons créer une base de données SQLite en fournissant un nom et la fonction SQLite.
library(RSQLite)
library(DBI)
library(tidyverse)
conn = dbConnect(SQLite(), dbname = 'datacamp_R.db')
En important la bibliothèque tidyverse, nous aurons accès aux ensembles de données dplyr, ggplot et defaults.
dbWriteTable prend data.frame et l'ajoute au tableau SQL. Elle prend trois arguments : la connexion à SQLite, le nom du tableau et le cadre de données. Avec dbReadTable, nous pouvons visualiser l'ensemble du tableau. Pour visualiser les 6 premières lignes, nous avons utilisé head.
dbWriteTable(conn, "cars", mtcars)
head(dbReadTable(conn, "cars"))
mpg cyl disp hp drat wt qsec vs am gear carb
1 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
2 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
3 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
4 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
5 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
6 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
dbExecute nous permet d'exécuter n'importe quelle requête SQLite, nous allons donc l'utiliser pour créer un tableau appelé idcard.
Pour afficher les noms des tableaux de la base de données, nous utiliserons dbListTables.
dbExecute(conn, 'CREATE TABLE idcard (id int, name text)')
dbListTables(conn)
>>> 'cars''idcard'
Ajoutons une seule ligne au tableau idcard et utilisons dbGetQuery pour afficher les résultats.
Remarque : dbGetQuery exécute une requête et renvoie les enregistrements, tandis que dbExecute exécute une requête SQL mais ne renvoie aucun enregistrement.
dbExecute(conn, "INSERT INTO idcard (id,name)\
VALUES(1,'love')")
dbGetQuery(conn,"SELECT * FROM idcard")
id name
1 love
Nous allons maintenant ajouter deux lignes supplémentaires et afficher les résultats en utilisant dbReadTable.
dbExecute(conn,"INSERT INTO idcard (id,name)\
VALUES(2,'Kill'),(3,'Game')
")
dbReadTable(conn,'idcard')
id name
1 love
2 Kill
3 Game
dbCreateTable nous permet de créer un tableau sans tracas. Elle requiert trois arguments : la connexion, le nom du tableau et un vecteur de caractères ou un data.frame. Le vecteur de caractères se compose de noms (noms de colonnes) et de valeurs (types). Dans notre cas, nous allons fournir un data.frame de population par défaut pour créer la structure initiale.
dbCreateTable(conn,'population',population)
dbReadTable(conn,'population')
country year population
Ensuite, nous allons utiliser dbAppendTable pour ajouter des valeurs dans le tableau de la population.
dbAppendTable(conn,'population',head(population))
dbReadTable(conn,'population')
country year population
Afghanistan 1995 17586073
Afghanistan 1996 18415307
Afghanistan 1997 19021226
Afghanistan 1998 19496836
Afghanistan 1999 19987071
Afghanistan 2000 20595360
Nous utiliserons dbGetQuery pour effectuer toutes nos tâches d'analyse de données. Essayons d'exécuter une requête simple avant d'en apprendre davantage sur les autres fonctions.
dbGetQuery(conn,"SELECT * FROM idcard")
id name
1 love
2 Kill
3 Game
Vous pouvez également exécuter une requête SQL complexe pour filtrer la puissance et afficher un nombre limité de lignes et de colonnes.
dbGetQuery(conn, "SELECT mpg,hp,gear\
FROM cars\
WHERE hp > 50\
LIMIT 5")
mpg hp gear
21.0 110 4
21.0 110 4
22.8 93 4
21.4 110 3
18.7 175 3
Pour supprimer des tableaux, utilisez dbRemoveTable. Comme nous pouvons le constater, nous avons réussi à supprimer le tableau idcard.
dbRemoveTable(conn,'idcard')
dbListTables(conn)
>>> 'cars''population'
Pour mieux comprendre les tableaux, nous utiliserons dbListFields qui affichera les noms des colonnes d'un tableau particulier.
dbListFields(conn, "cars")
>>> 'mpg''cyl''disp''hp''drat''wt''qsec''vs''am''gear''carb'
Dans cette section, nous utiliserons dplyr pour lire des tableaux, puis exécuter des requêtes à l'aide de filter, select et collect. Si vous ne voulez pas apprendre la syntaxe SQL et que vous souhaitez effectuer toutes les tâches en utilisant R, cette méthode est faite pour vous. Nous avons extrait le tableau des voitures, l'avons filtré en fonction des vitesses et du kilométrage, puis avons sélectionné trois colonnes comme indiqué ci-dessous.
cars_results <-
tbl(conn, "cars") %>%
filter(gear %in% c(4, 3),
mpg >= 14,
mpg <= 21) %>%
select(mpg, hp, gear) %>%
collect()
cars_results
mpg hp gear
21.0 110 4
21.0 110 4
18.7 175 3
18.1 105 3
14.3 245 3
... ... ...
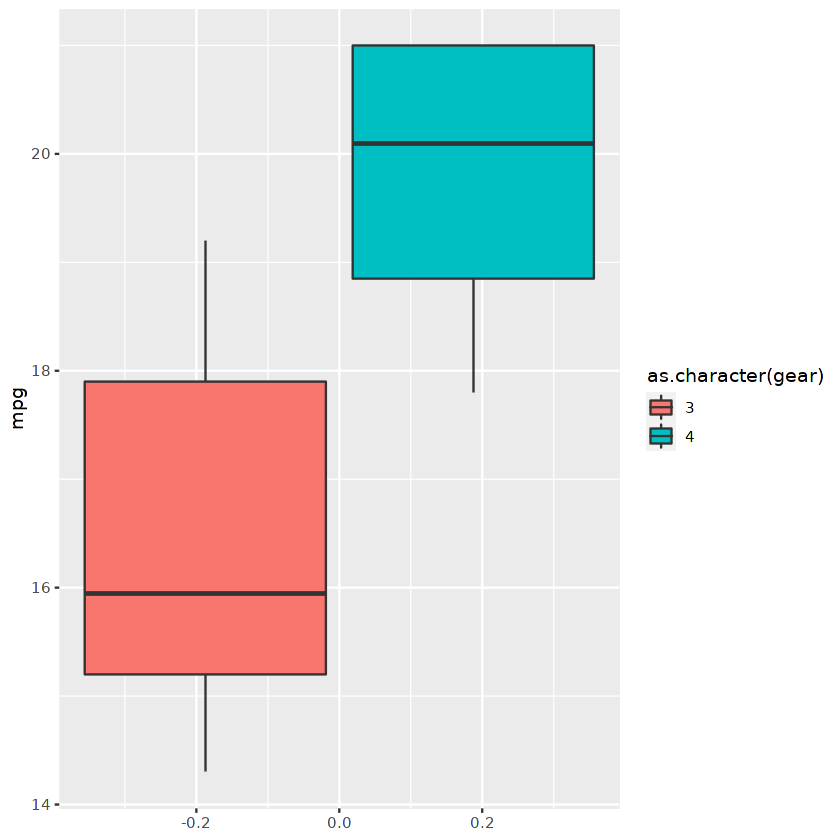
Nous pouvons utiliser la base de données filtrée pour afficher un graphique en boîte à l'aide de ggplot.
ggplot(cars_results,aes(fill=as.character(gear), y=mpg)) +
geom_boxplot()
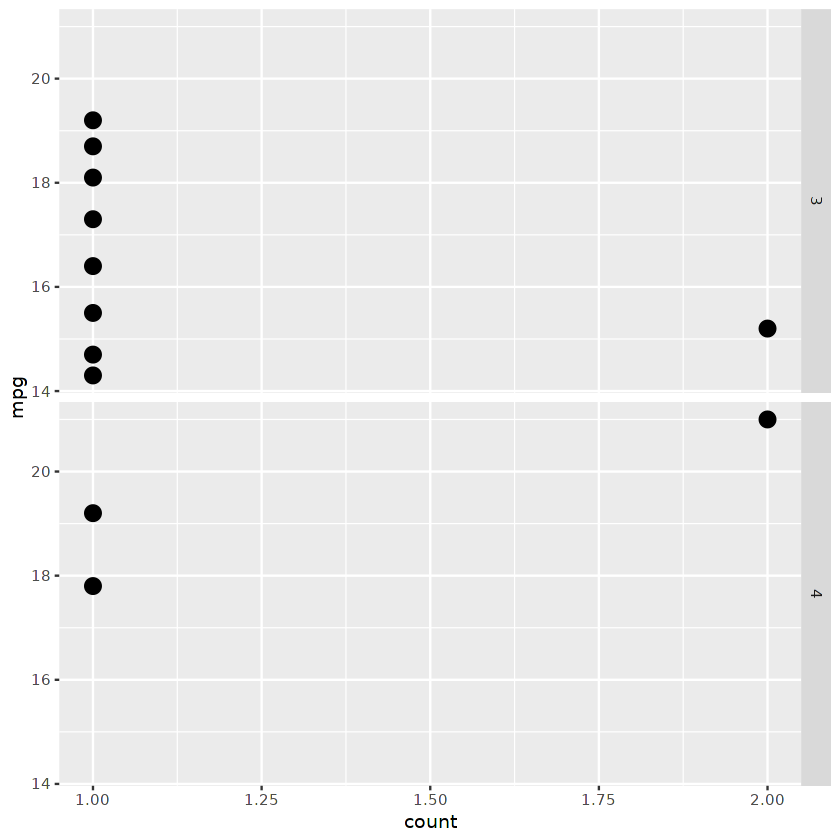
Nous pouvons également afficher un diagramme de points de facettes divisé par le nombre d'engrenages.
ggplot(cars_results,
aes(mpg, ..count.. ) ) +
geom_point(stat = "count", size = 4) +
coord_flip()+
facet_grid( as.character(gear) ~ . )
Dans ce tutoriel, nous avons appris l'importance de l'exécution de requêtes SQL avec Python et R, de la création de bases de données, de l'ajout de tableaux et de l'exécution d'analyses de données à l'aide de requêtes SQL. Nous avons également appris comment Pandas et dplyr nous aident à exécuter des requêtes avec une seule ligne de code.
Le langage SQL est une compétence indispensable pour tous les emplois liés à la technologie. Si vous commencez votre carrière en tant qu'analyste de données, nous vous recommandons de suivre le cursus Data Analyst with SQL Server dans un délai de deux mois. Ce cursus professionnel vous apprendra tout sur les requêtes SQL, les serveurs et la gestion des ressources.
Vous pouvez exécuter gratuitement tous les scripts utilisés dans ce tutoriel :
Cours connexes sur Python et SQL
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach