Curso
Machine Learning para datos de series temporales en Python
4 h
53.3K
Cuando tenía 14 años, hice mi primera apuesta futbolística al ganador de la Copa Mundial de la FIFA 2010. Confiando sólo en mi intuición, adiviné cada partido y aposté por los dos finalistas de mi plan de torneo: Holanda y España. Al final, esos dos equipos llegaron a la final; estaba encantado de que mis predicciones se hubieran cumplido.
Avanzando 14 años, busqué un proyecto para profundizar en mis conocimientos de Python y aprendizaje automático, lo que me llevó a un proyecto de predicción para la EURO 2024. Mi objetivo principal era predecir los resultados de los partidos (victoria, empate o derrota) y el número de goles marcados por cada equipo.
En este artículo, ofrezco una visión general de mi proyecto de predicción de la Eurocopa 2024, destacando los pasos clave que di, los retos que encontré y los conocimientos que obtuve. Para profundizar en los detalles técnicos, incluida la implementación del código, consulta el proyecto de cuaderno adjunto-necesitarás una cuenta DataLab para acceder a todos los archivos.
Predecir los resultados del fútbol es un reto notorio debido a varios factores. En el fútbol, la distribución estadística de los goles es muy variable. Al mismo tiempo, hay relativamente pocas oportunidades de gol por partido en comparación con otros deportes de pelota en equipo, lo que da lugar a resultados impredecibles.
Tomemos el balonmano, por ejemplo: sus frecuentes ocasiones de gol tienden a producir resultados más predecibles, porque es más probable que el número de goles refleje la creación y la prevención de ocasiones, ya que el número de intentos de gol se promedia a lo largo del partido. En el fútbol, sin embargo, a veces puede bastar con "aparcar el autobús" delante de tu portería y jugar un contraataque decidido para dar la vuelta al partido.
Además, los partidos de fútbol se caracterizan por una alta dependencia de la trayectoria, lo que significa que el impulso y el resultado del partido suelen depender en gran medida del primer gol. Acciones pequeñas pero significativas pueden provocar un gol o una tarjeta roja y cambiar drásticamente el curso de un partido, lo que dificulta aún más las predicciones.
La introducción del VAR (Árbitro Asistente de Vídeo) en los últimos años ha aumentado la imprevisibilidad, ya que puede anular decisiones cruciales sobre el terreno de juego. Y no olvidemos la elusiva "forma de la jornada", un factor sobre el que podría escribir un libro como seguidor del notoriamente impredecible Eintracht de Frankfurt (apodado acertadamente la "diva malhumorada").

Además de los factores comentados, mi modelo de predicción también se enfrenta a varias limitaciones de datos adicionales que debo abordar.
Para hacer frente a los problemas con los datos utilizados, se utilizaron varias estrategias:
Rellené los puntos de datos que faltaban siempre que fue posible para garantizar que el conjunto de datos siguiera siendo completo; por ejemplo, añadiendo formaciones tácticas para los partidos que había que predecir.
Como la mayoría de los equipos se ciñen a la misma formación, una vez que la han entrenado y probado, he supuesto que cada equipo jugará con la formación que haya utilizado más a menudo en los últimos cinco partidos. Esto nos permite predecir los partidos antes de que se haga pública la alineación, lo que sólo ocurre una hora antes de que empiece el partido.
Cuando ni la imputación ni la eliminación resultaban prácticas, excluía o sustituía ciertos rasgos para no comprometer la precisión del modelo.
Originalmente, por ejemplo, quería hacer una predicción de dos niveles que tomara las características primarias para predecir características secundarias como la posesión del balón y los goles esperados, para predecir también el resultado basándome en esas características secundarias. En aras de la simplicidad, decidí no seguir este procedimiento y, en su lugar, asigné a cada equipo dos características basadas en las estadísticas medias de los partidos para representar su estilo de juego.
Cuando la imputación no era factible, eliminé los datos que faltaban para mantener la integridad del conjunto de datos. Afortunadamente, sólo hubo una pequeña pérdida de observaciones, por lo que el conjunto de datos seguía conteniendo más de 3.000 coincidencias para la construcción del modelo.
Una vez abordadas las dificultades y limitaciones, examinemos el proceso de convertir los datos brutos en predicciones perspicaces. El sitio canalización de datosla columna vertebral del proyecto, consistió en recopilar, preprocesar y preparar los datos para el modelado, aprovechando diversas características tácticas, psicológicas e históricas.
El paso inicial consistió en extraer datos históricos de partidos de varias fuentes, entre ellas Transfermarktpara recopilar información exhaustiva sobre partidos anteriores.
Una fila del DataFrame resultante corresponde a un partido desde la perspectiva de uno de los equipos implicados. Estos datos se combinaron con FootyStats para incluir características de estilo de juego como la posesión media del balón y métricas de eficacia.
Para más detalles, consulta el cuaderno de raspado de datos aquí.
A continuación, los datos brutos se transformaron en características significativas que pudieran ser utilizadas por los modelos de aprendizaje automático. Esto implicaba extraer valores, transformar variables y calcular medias.
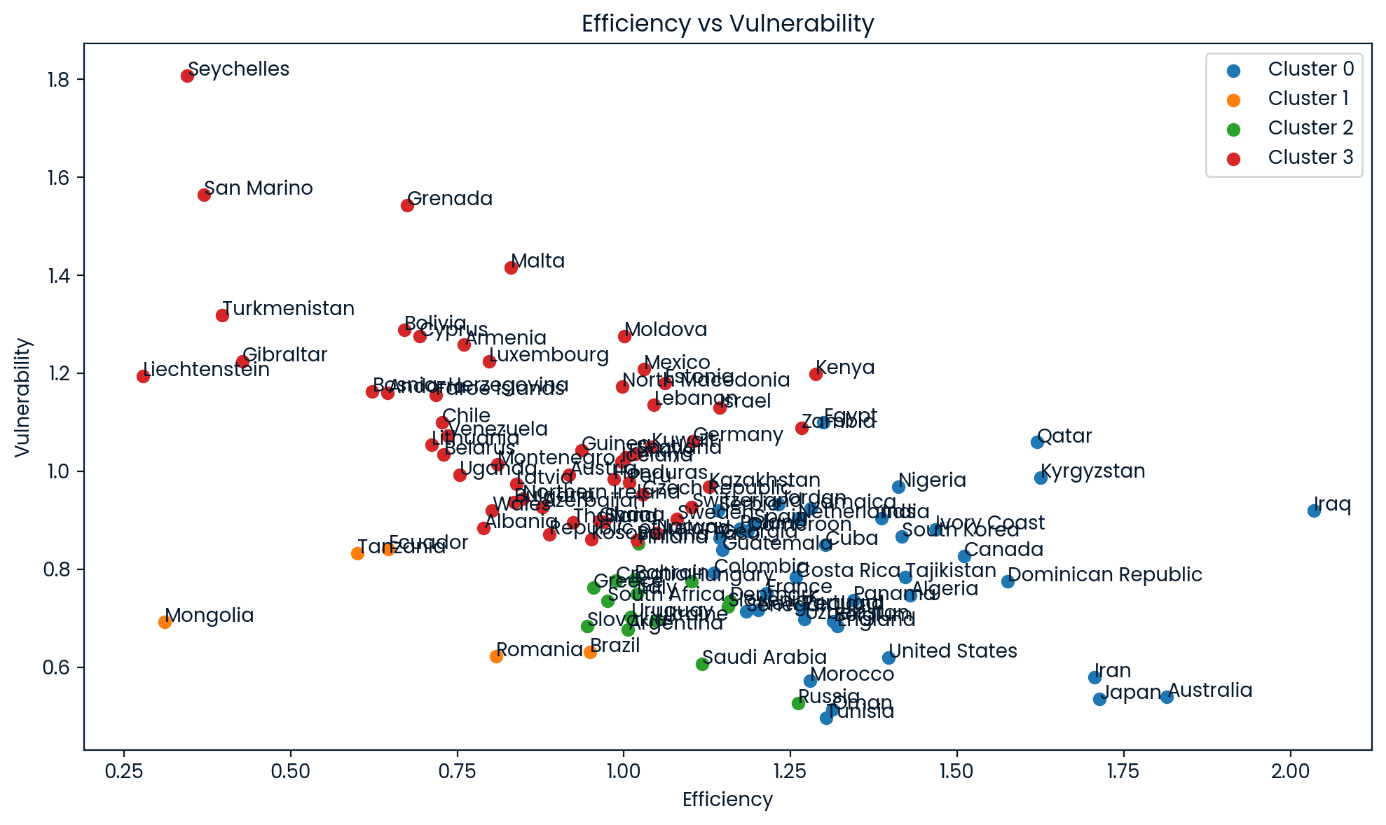
Grupos de eficiencia frente a vulnerabilidad de todos los equipos del conjunto de datos
Se identificaron varias características clave y se utilizaron en los modelos para mejorar la precisión de las predicciones. Estas características incluían:
Antes de construir los modelos de aprendizaje automático, el conjunto de datos se divide en partidos jugados y no jugados para distinguir entre datos etiquetados y no etiquetados. Además, tomamos el logaritmo de las características de forma muy sesgada a la derecha y aplicamos la normalización y la codificación de un solo golpe para asegurarnos de que los datos tienen un formato adecuado.
Las variables de equipo, incluida la tendencia a largo plazo, deben escalarse utilizando MinMaxScaler para evitar que los ceros que representan partidos sin el equipo respectivo influyan en su escala. Todas las demás características numéricas se normalizan utilizando el Escalador estándar.
Para identificar los modelos más eficaces para predecir los resultados del fútbol, empecé con una amplia selección de modelos de aprendizaje automático. Adoptando un enfoque de "caja negra", exploré varios modelos para comprender sus puntos fuertes y débiles en el tratamiento de los datos. Para cada modelo, utilicé la versión de clasificación para predecir los resultados de los partidos y la versión de regresión para predecir el número de goles marcados por ambos equipos. Los modelos que probé incluían
Primero fijé una semilla (mi antiguo número de camiseta, el nueve) para la reproducibilidad. La definición de etiquetas y objetivos y la construcción del modelo implicaron varios pasos clave, todos los cuales incluían la comparación del rendimiento del modelo mediante validación cruzada:
Por último, seleccioné los modelos con mejores resultados basándome en su precisión a la hora de predecir los resultados de los partidos (victorias/derrotas) y el error cuadrático medio (RMSE) a la hora de predecir el número de goles.
Elegí dos modelos para los resultados de los partidos: uno para predecir las victorias y las derrotas, y otro específicamente para los empates. Esta distinción era necesaria porque los patrones y factores que influyen en los empates difieren significativamente de los que afectan a las victorias y derrotas. Para garantizar que las probabilidades finales de los tres resultados (victoria, empate, derrota) suman 100%, los resultados de la aplicación del modelo se normalizaron posteriormente.
Utilizando los modelos elegidos con sus hiperparámetros y características seleccionadas, predigo todas las etiquetas de cada fila. Como hay dos filas para cada partido a predecir, obtenemos dos probabilidades para cada resultado del partido y dos números flotantes como goles previstos para cada equipo.
Estos valores no deberían diferir demasiado entre sí y, en la mayoría de los casos, no lo hacen; sin embargo, si lo hacen, marcamos la coincidencia para indicar que la predicción debe considerarse con cierto recelo. Para reducirlos a un solo valor para cada etiqueta, tomo la media de ambos valores predichos.
Para los resultados de los partidos, normalicé las probabilidades de victoria, empate y derrota para asegurarme de que sumaban 100%. También creé columnas adicionales para capturar opciones de apuesta populares como "doble oportunidad". Basándome en el número flotante de goles pronosticados por equipo, instancio una distribución de Poisson y obtengo probabilidades para cada número de goles de cada equipo y para saber si la suma de todos los goles del partido es superior o inferior a 1,5, 2,5, 3,5, 4,5 y 5,5, que son apuestas bastante populares.
Para mis pronósticos de propina, elegí el resultado con mayor probabilidad. Si las probabilidades de victoria de ambos equipos estaban dentro de un margen de 0,05 entre sí, lo interpretaba como un empate. Para las predicciones de goles, seleccioné el número de goles más probable para cada equipo, ajustando los números según fuera necesario para asegurarme de que coincidían con el resultado previsto.
Para predecir futuros partidos de la Eurocopa, actualicé los datos brutos de los partidos con los resultados iniciales predichos. Al incorporar estas predicciones al conjunto de datos y volver a aplicar la ingeniería de características, pude predecir la siguiente ronda de partidos basándome en la evolución del panorama del torneo.
Entender la diferencia entre exactitud y precisión es crucial en el contexto de las predicciones futbolísticas, sobre todo cuando se considera la aplicación de estas predicciones. Utilizar como ejemplo las apuestas frente a las propinas puede ilustrar la importancia de estas métricas:
El objetivo es encontrar apuestas en las que el rendimiento esperado sea positivo. Esto significa que tienes que identificar los resultados probables y considerar las cuotas que ofrecen las casas de apuestas para encontrar apuestas de valor.
La precisión es crucial aquí, ya que se centra en la exactitud de las predicciones positivas (por ejemplo, predecir una victoria). La alta precisión ayuda a identificar sistemáticamente las apuestas infravaloradas por las casas de apuestas, lo que afecta directamente a la rentabilidad.
Ten en cuenta que las empresas de apuestas tienen equipos enteros para construir y mantener modelos predictivos muy sofisticados que probablemente vencerán a uno más simple como el mío en la mayoría de los casos.
El objetivo es acertar el resultado de cada partido. Los participantes ganan puntos por cada pronóstico correcto, con el objetivo de acumular el mayor número de puntos en una serie de partidos. La precisión global es más importante en este escenario porque mide la frecuencia con la que tus predicciones son correctas, lo que influye en tu puntuación total.
La predicción de empates es otro ejemplo perfecto de la posible discrepancia entre las dos mediciones. Sólo un 20% de los partidos de los datos de entrenamiento acabaron en empate, lo que lleva a la mayoría de los modelos a subestimar la probabilidad de empate y, a veces, incluso a no predecirlo nunca.
Esto conduce a un alto índice de precisión de aproximadamente el 80%, ya que todos los no sorteos se etiquetan correctamente, pero a una precisión de 0 para los sorteos, porque ninguno de los sorteos se predijo como tal.
El rendimiento de los modelos varió en función del tipo de predicción:
Como se utilizan modelos diferentes, hay casos en los que las predicciones de resultados y objetivos no coinciden. Aunque es difícil comparar las puntuaciones categóricas y las numéricas, creo que es justo decir que las predicciones de resultados suelen funcionar mejor que las de objetivos, razón por la cual las segundas se ajustan a las primeras en caso de desajuste.
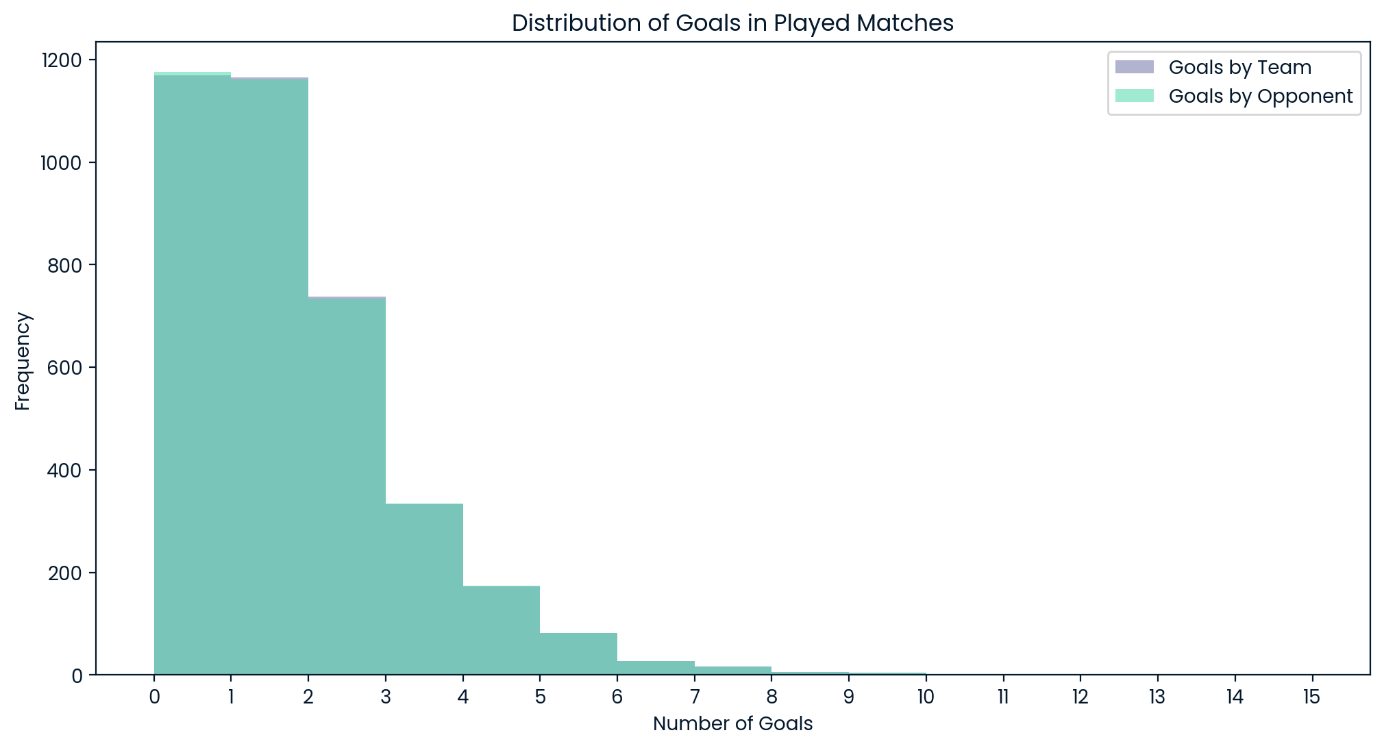
Distribución de goles en todos los partidos jugados
Llama la atención que el modelo recurra exclusivamente a las puntuaciones de cero, uno y dos como el número de goles más probable para cualquier equipo en cualquier partido. Dada la distribución general de goles en los datos de las pruebas, esto no es ninguna sorpresa, pero hay que tener en cuenta que el modelo nunca esperará un partido con muchos goles como resultado probable.
¡La aplicación de los modelos a los primeros partidos de la EURO generó resultados interesantes!
En tres cuartas partes de los casos, el modelo predijo que el ganador sería el equipo favorito, mientras que en la cuarta parte restante, el resultado predicho no reflejaba los favoritos de las casas de apuestas.
A primera vista, esta proporción parecía una buena apuesta, ya que es justo suponer que hay un cierto número de resultados sorprendentes. Pero ahora llega la parte complicada, que es una cuestión general en las predicciones futbolísticas, independientemente de si utilizas tu instinto o un modelo de aprendizaje automático: ¿Cuándo tiene sentido apostar por el perdedor?
Una estrategia para hacer frente a esto es apostar sólo y siempre por el favorito. Esto significa que te equivocarás en una parte de las sorpresas, pero en general, tu precisión será bastante buena. Intentar adivinar también los resultados inesperados es la única posibilidad de optimizar la precisión de tus apuestas, pero obviamente es la estrategia más difícil y arriesgada.
Suponiendo que la proporción de sorpresas sea más o menos constante, cada error cuenta el doble: por cada sorpresa adivinada que no se hizo realidad, te estás perdiendo una al apostar por el favorito.
Elegí el enfoque más arriesgado, pero hasta ahora no me ha reportado grandes beneficios. Mi modelo tuvo bastante mala suerte en cuanto a posibles sorpresas, lo que me llevó a una precisión bastante decepcionante del 50% en la primera jornada.
Por ejemplo, el modelo predijo que Serbia y Georgia, los dos tapados, empatarían contra Inglaterra y, respectivamente, ganarían a Turquía. Sin embargo, los favoritos ganaron en ambos casos. Por otra parte, el modelo no predijo sorpresas reales como la victoria de Eslovaquia contra Bélgica, la sorprendente victoria de Rumania por 3:0 contra Ucrania y el empate de Dinamarca contra Eslovenia.
Los siguientes pronósticos se realizaron tras la segunda jornada, a falta de un partido de la liguilla para cada equipo. El resultado más sorprendente es el del grupo más interesante, incluso en el grupo E, donde todos los equipos comparten el mismo número de puntos (3) a falta de un partido.
Utilizando el modelo, se predice que Eslovaquia ganará el grupo tras una victoria por 1:0 sobre Rumanía, ya que ganó a Bélgica. Así, Eslovaquia relegaría a la gran favorita del grupo al segundo puesto. El modelo prevé incluso que Eslovaquia sea la mayor sorpresa del torneo, pronosticando que ganará a Austria y pasará a cuartos de final.
La predicción para todo el recorrido del torneo fue especialmente difícil debido al formato, en el que los mejores terceros también se clasifican para la fase eliminatoria. Esto introdujo varios emparejamientos posibles, añadiendo más complejidad según de qué grupos procedan los cuatro mejores terceros. Por tanto, tómate las siguientes predicciones con cautela: los emparejamientos podrían cambiar por completo, aunque la diferencia de goles de un equipo sólo cambie en un gol.
En general, los partidos del K.O. se prevén muy ajustados, con una victoria española por 2:0 en su posible partido de 1/8 de final contra Rumanía como el único con una diferencia de goles esperada superior a uno.
Los partidos italianos llevan la cercanía al extremo, siendo los empates los resultados previstos para sus dos primeros partidos de K.O. Como las tandas de penaltis son poco frecuentes y no hay datos suficientes para predecir sus ganadores, recurrí a mis recuerdos del buen historial de penaltis italiano y esperaba que Italia ganara las dos tandas de penaltis contra Suiza e Inglaterra.
Al final, el modelo predice que España, Portugal, Holanda e Italia llegarán a semifinales.
Holanda y España conforman mi final prevista, al igual que en 2010; ¿será que la historia se repite?
Este proyecto proporcionó varios aprendizajes clave:
Para mejorar las predicciones y ampliar el alcance del proyecto, se pueden dar varios pasos:
Para obtener información más detallada y código, visita el cuaderno del proyecto.
Esta entrada de blog ofrece una visión general de los retos y metodologías que implica la predicción de resultados futbolísticos, destacando el recorrido y los aprendizajes del proyecto de predicción de la Eurocopa 2024.
La integración de la ciencia de datos y la analítica deportiva ofrece oportunidades apasionantes para los aficionados y los profesionales del sector. A medida que el proyecto sigue evolucionando, el objetivo sigue siendo perfeccionar los modelos y ampliar su aplicación a otros torneos, contribuyendo así al creciente campo de la analítica deportiva.
Si quieres aprender más sobre analítica deportiva, aquí tienes algunos recursos que puedes probar:
Aprende aprendizaje automático con estos cursos
Curso
Curso
Curso
blog
Kurtis Pykes
13 min
blog
Kevin Babitz
10 min