Curso
Machine Learning para dados de séries temporais em Python
4 h
53.3K
Quando eu tinha 14 anos, fiz minha primeira aposta de futebol no vencedor da Copa do Mundo da FIFA 2010. Baseando-me apenas na intuição, adivinhei cada partida e apostei nos dois finalistas do meu plano de torneio: Holanda e Espanha. No final, essas duas equipes chegaram à final - fiquei muito feliz por minhas previsões terem se concretizado.
Passados 14 anos, procurei um projeto para aprofundar minhas habilidades em Python e machine learning, o que me levou a um projeto de previsão para a EURO 2024. Meu principal objetivo era prever os resultados das partidas (vitória, empate ou derrota) e o número de gols marcados por cada equipe.
Neste artigo, apresento uma visão geral do meu projeto de previsão da EURO 2024, destacando as principais etapas que tomei, os desafios que encontrei e os insights que obtive. Para se aprofundar nos detalhes técnicos, incluindo a implementação do código, consulte o projeto de notebook que o acompanha-Você precisará de uma conta do DataLab para acessar todos os arquivos.
A previsão de resultados no futebol é notoriamente desafiadora devido a vários fatores. No futebol, a distribuição estatística dos gols é bastante variável. Ao mesmo tempo, há relativamente poucas oportunidades de gol por partida em comparação com outros esportes coletivos com bola, o que leva a resultados imprevisíveis.
Veja o handebol, por exemplo: suas frequentes chances de gol tendem a produzir resultados mais previsíveis, pois o número de gols tem mais probabilidade de refletir a criação e a prevenção de chances, já que o número de tentativas de gol é calculado ao longo do jogo. No entanto, no futebol, às vezes pode ser suficiente "estacionar o ônibus" na frente do seu gol e jogar um contra-ataque determinado para virar a partida de cabeça para baixo.
Além disso, os jogos de futebol são caracterizados por umaalta dependência do caminho, o que significa que a dinâmica e o resultado do jogo geralmente dependem muito do primeiro gol. Ações pequenas, mas significativas, podem levar a um gol ou cartão vermelho e mudar drasticamente o curso de uma partida, tornando as previsões ainda mais difíceis.
A introdução do VAR (Video Assistant Referee, árbitro assistente de vídeo) nos últimos anos aumentou a imprevisibilidade, pois pode anular decisões cruciais em campo. E não vamos nos esquecer da elusiva "forma do dia", um fator sobre o qual eu poderia escrever um livro como torcedor do notoriamente imprevisível Eintracht Frankfurt (apropriadamente apelidado de "diva mal-humorada").

Além dos fatores discutidos, meu modelo de previsão também enfrenta várias limitações de dados adicionais que preciso abordar.
Para enfrentar os desafios com os dados utilizados, foram usadas várias estratégias:
Sempre que possível, preenchi os pontos de dados ausentes para garantir que o conjunto de dados permanecesse abrangente - por exemplo, adicionando formações táticas para as partidas a serem previstas.
Como a maioria das equipes mantém a mesma formação, depois de treiná-la e testá-la, presumi que cada equipe jogaria na formação que usou com mais frequência nas últimas cinco partidas. Isso nos permite prever partidas antes que a escalação se torne pública, o que só acontece uma hora antes do início da partida.
Quando nem a imputação nem a remoção eram práticas, eu excluía ou substituía determinados recursos para não comprometer a precisão do modelo.
Originalmente, por exemplo, eu queria fazer uma previsão de dois níveis que usasse os recursos primários para prever recursos secundários, como posse de bola e gols esperados, para prever o resultado com base nesses recursos secundários também. Para simplificar, optei por não usar esse procedimento e, em vez disso, atribuí a cada equipe dois recursos com base nas estatísticas médias das partidas para representar seu estilo de jogo.
Quando a imputação não era viável, removi os dados ausentes para manter a integridade do conjunto de dados. Felizmente, houve apenas uma pequena perda de observações, de modo que o conjunto de dados ainda continha mais de 3.000 correspondências para a criação de modelos.
Depois de abordar as dificuldades e limitações, vamos examinar o processo de transformação de dados brutos em previsões perspicazes. O pipeline de dadosO pipeline de dados, a espinha dorsal do projeto, envolveu a coleta, o pré-processamento e a preparação dos dados para modelagem, aproveitando vários recursos táticos, psicológicos e históricos.
A etapa inicial envolveu a coleta de dados históricos de partidas de várias fontes, incluindo Transfermarktpara reunir informações abrangentes sobre partidas anteriores.
Uma linha no DataFrame resultante corresponde a uma partida da perspectiva de uma das equipes envolvidas. Esses dados foram combinados com o FootyStats para incluir recursos de estilo de jogo, como posse média de bola e métricas de eficiência.
Para obter mais detalhes, consulte o notebook sobre raspagem de dados aqui.
Em seguida, os dados brutos foram transformados em recursos significativos que poderiam ser usados pelos modelos de machine learning. Isso envolveu a extração de valores, a transformação de variáveis e o cálculo de médias.
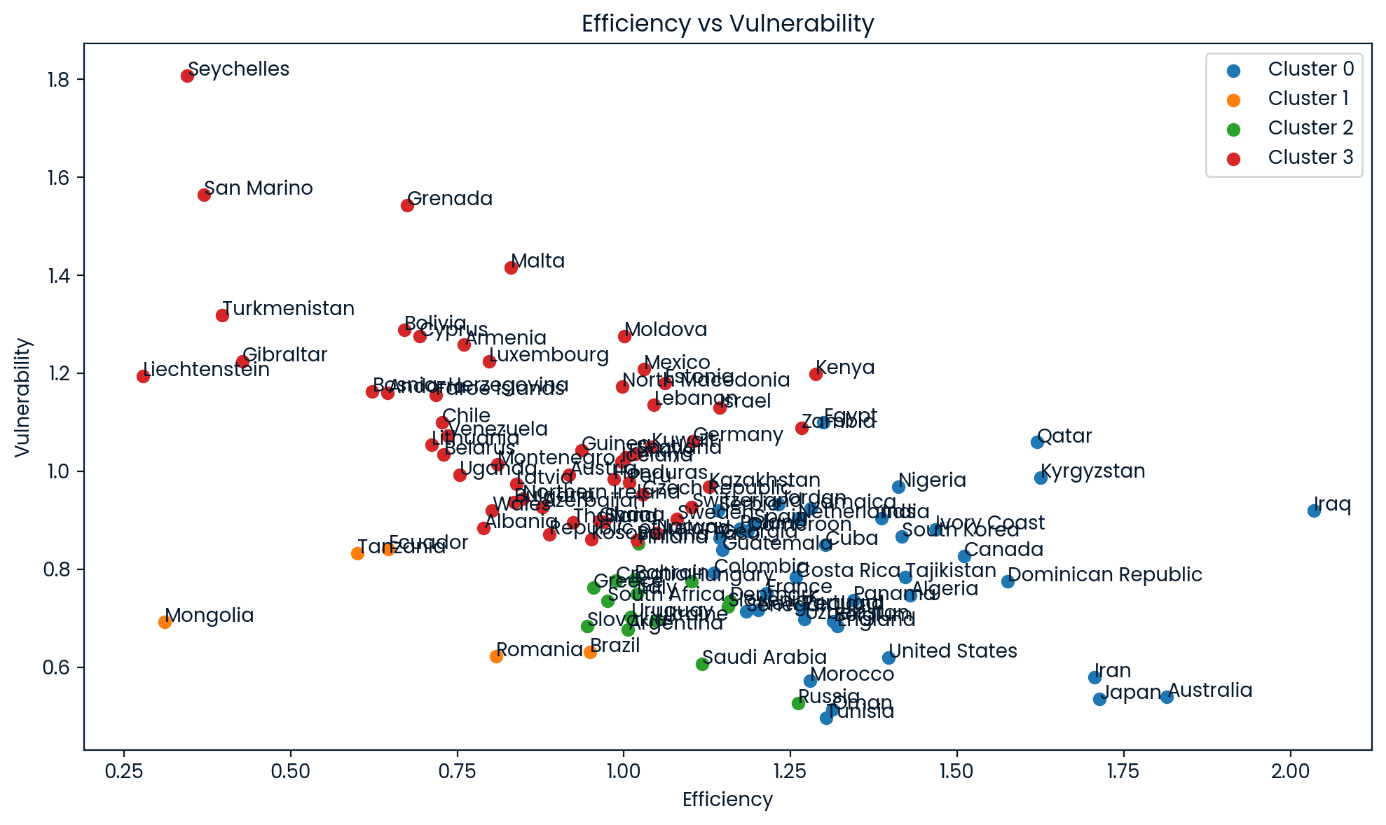
Grupos de eficiência versus vulnerabilidade de todas as equipes no conjunto de dados
Vários recursos importantes foram identificados e usados nos modelos para aumentar a precisão das previsões. Esses recursos incluem:
Antes de criar os modelos de machine learning, o conjunto de dados é dividido em partidas jogadas e não jogadas para distinguir entre dados rotulados e não rotulados. Além disso, pegamos o logaritmo dos recursos de forma altamente distorcidos para a direita e aplicamos a normalização e a codificação de um único disparo para garantir que os dados estejam em um formato adequado.
As variáveis de equipe, incluindo a tendência de longo prazo, devem ser dimensionadas usando o MinMaxScaler para evitar que os zeros que representam partidas sem a respectiva equipe influenciem sua escala. Todos os outros recursos numéricos são normalizados usando o StandardScaler.
Para identificar os modelos mais eficazes para prever os resultados do futebol, comecei com uma ampla seleção de modelos de machine learning. Adotando uma abordagem de "caixa preta", explorei vários modelos para entender seus pontos fortes e fracos no tratamento dos dados. Para cada modelo, usei a versão de classificação para prever os resultados das partidas e a versão de regressão para prever o número de gols marcados por ambas as equipes. Os modelos que testei incluem:
Primeiro, estabeleci uma semente (meu antigo número de camisa, nove) para reprodutibilidade. A definição de rótulos e alvos e a criação de modelos envolveram várias etapas importantes, que incluíram a comparação dos desempenhos dos modelos usando a validação cruzada:
Por fim, selecionei os modelos de melhor desempenho com base em sua precisão na previsão dos resultados das partidas (vitória/derrota) e na raiz do erro quadrático médio (RMSE) na previsão do número de gols.
Escolhi dois modelos para os resultados das partidas: um para prever vitórias e derrotas e outro especificamente para empates. Essa distinção foi necessária porque os padrões e fatores que influenciam os empates diferem significativamente daqueles que afetam as vitórias e derrotas. Para garantir que as probabilidades finais de todos os três resultados (vitória, empate, perda) somem 100%, os resultados da aplicação do modelo foram normalizados posteriormente.
Usando os modelos escolhidos com seus hiperparâmetros e recursos selecionados, prevejo todos os rótulos para cada linha. Como há duas linhas para cada partida a ser prevista, obtemos duas probabilidades para cada resultado da partida e dois números flutuantes como gols previstos para cada equipe.
Esses valores não devem diferir muito uns dos outros e, na maioria dos casos, não diferem. No entanto, se diferirem, marcamos a correspondência para indicar que a previsão deve ser considerada com um pouco de cautela. Para reduzi-los a apenas um valor para cada rótulo, eu pego a média dos dois valores previstos.
Para os resultados das partidas, normalizei as probabilidades de vitória, empate e derrota para garantir que a soma fosse 100%. Também criei colunas adicionais para capturar opções de apostas populares, como "chance dupla". Com base no número flutuante de gols previstos por equipe, instancio uma distribuição de Poisson e obtenho probabilidades para cada número de gols de cada equipe e para saber se a soma de todos os gols da partida está acima ou abaixo de 1,5, 2,5, 3,5, 4,5 e 5,5, que são bastante populares para se apostar.
Para minhas previsões de gorjeta, escolhi o resultado com a maior probabilidade. Se as probabilidades de vitória de ambas as equipes estivessem dentro de 0,05 uma da outra, eu interpretava isso como um empate. Para as previsões de gols, selecionei o número mais provável de gols para cada equipe, ajustando os números conforme necessário para garantir que estivessem alinhados com o resultado previsto.
Para prever futuras partidas da EURO, atualizei os dados brutos das partidas com os resultados iniciais previstos. Ao incorporar essas previsões ao conjunto de dados e reaplicar a engenharia de recursos, eu poderia prever a próxima rodada de partidas com base no cenário do torneio em evolução.
Entender a diferença entre exatidão e precisão é fundamental no contexto das previsões de futebol, principalmente quando se considera a aplicação dessas previsões. Usando apostas versus gorjetas como exemplo, você pode ilustrar a importância dessas métricas:
O objetivo é encontrar apostas em que o retorno esperado seja positivo. Isso significa que você precisa identificar os resultados prováveis e considerar as probabilidades oferecidas pelas casas de apostas para encontrar apostas de valor.
A precisão é crucial aqui, pois se concentra na exatidão das previsões positivas (por exemplo, prever uma vitória). A alta precisão ajuda a identificar consistentemente apostas subvalorizadas pelas casas de apostas, afetando diretamente a lucratividade.
Lembre-se de que as empresas de apostas têm equipes inteiras para criar e manter modelos preditivos muito sofisticados que provavelmente superarão um modelo mais simples como o meu na maioria dos casos.
O objetivo é adivinhar com precisão o resultado de cada partida. Os participantes ganham pontos para cada previsão correta, com o objetivo de acumular o maior número de pontos em uma série de partidas. A precisão geral é mais importante nesse cenário porque mede a frequência com que suas previsões estão corretas, afetando sua pontuação total.
A previsão de empates é outro exemplo perfeito da possível discrepância entre as duas medições. Apenas cerca de 20% das partidas nos dados de treinamento terminaram em empate, levando a maioria dos modelos a subestimar a chance de empate e, às vezes, até mesmo a nunca prever um empate.
Isso resulta em uma alta taxa de precisão de cerca de 80%, já que todos os não sorteios são rotulados corretamente, mas uma precisão de 0 para sorteios porque nenhum dos sorteios foi previsto como tal.
O desempenho dos modelos variou de acordo com o tipo de previsão:
Como são usados modelos diferentes, há casos em que as previsões de resultados e metas não coincidem. Embora seja difícil comparar pontuações categóricas e numéricas, acho que é justo dizer que as previsões de resultados geralmente funcionam melhor do que as de metas, e é por isso que as últimas são ajustadas às primeiras em caso de incompatibilidade.
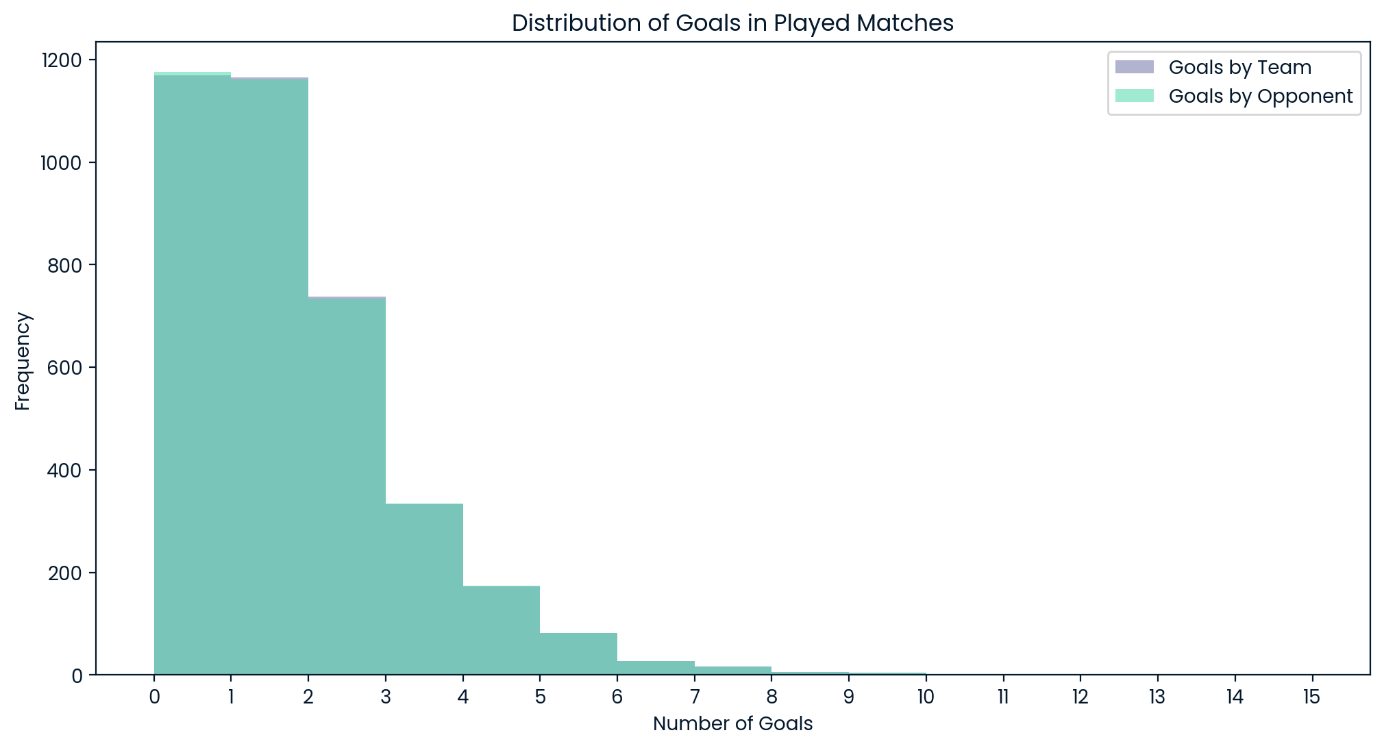
Distribuição de gols em todas as partidas disputadas
É notável que o modelo recorra exclusivamente a pontuações de zero, um e dois como o número de gols mais provável para qualquer equipe em qualquer partida. Considerando a distribuição geral de gols nos dados de teste, isso não é nenhuma surpresa, mas é preciso ter em mente que o modelo nunca esperará uma partida com muitos gols como resultado provável.
A aplicação dos modelos às primeiras partidas da EURO gerou resultados interessantes!
Em três quartos dos casos, o modelo previu que o vencedor seria a equipe favorita, enquanto no quarto restante, o resultado previsto não refletia os favoritos das casas de apostas.
À primeira vista, essa proporção parecia uma boa aposta, pois é justo supor que há um certo número de resultados surpreendentes. Mas agora chegamos à parte complicada, que é uma questão geral nas previsões de futebol, independentemente de você usar seu instinto ou um modelo de machine learning: Quando faz sentido apostar no azarão?
Uma estratégia para lidar com isso é apostar apenas e sempre no favorito. Isso significa que você errará em algumas surpresas, mas, no geral, sua precisão será muito boa. Tentar adivinhar os resultados inesperados também é a única chance de otimizar a precisão das suas apostas, mas é obviamente a estratégia mais difícil e arriscada.
Supondo que a proporção de surpresas seja aproximadamente constante, cada erro conta em dobro - para cada surpresa adivinhada que não se concretizou, você está perdendo uma ao apostar no favorito.
Escolhi a abordagem mais arriscada, mas ela não trouxe grandes benefícios até agora. Meu modelo foi bastante azarado em relação a possíveis surpresas, levando a uma precisão bastante decepcionante de 50% para a primeira rodada.
Por exemplo, o modelo previu que a Sérvia e a Geórgia, os dois azarões, empatariam com a Inglaterra e, respectivamente, venceriam a Turquia. No entanto, os favoritos venceram em ambos os casos. Por outro lado, o modelo não previu surpresas reais, como a vitória da Eslováquia contra a Bélgica, a impressionante vitória da Romênia por 3 a 0 contra a Ucrânia e o empate da Dinamarca com a Eslovênia.
As previsões a seguir foram feitas após a segunda rodada, faltando uma partida da fase de grupos para cada equipe. O resultado mais surpreendente é o do grupo mais interessante, mesmo no grupo E, onde todas as equipes compartilham o mesmo número de pontos (3) a uma partida do fim.
Usando o modelo, a previsão é de que a Eslováquia vença o grupo depois de uma vitória de 1 x 0 sobre a Romênia, já que eles venceram a Bélgica. Assim, a Eslováquia rebaixaria o grande favorito do grupo para o segundo lugar. O modelo prevê até mesmo que a Eslováquia será a maior surpresa do torneio, prevendo que ela vencerá a Áustria e passará para as quartas de final.
A previsão para todo o percurso do torneio foi particularmente desafiadora devido ao formato, no qual as equipes melhores colocadas em terceiro lugar também se classificam para a fase eliminatória. Isso introduziu vários confrontos possíveis, aumentando ainda mais a complexidade dependendo de quais grupos as quatro melhores equipes terceiras colocadas se originam. Portanto, considere as previsões a seguir com cautela - os confrontos podem mudar completamente, mesmo que o saldo de gols de uma equipe mude em apenas um gol.
As partidas do K.O. são geralmente previstas como muito disputadas, com uma vitória espanhola por 2 a 0 na possível partida de 1/8 de final contra a Romênia como a única com uma diferença de gols prevista maior que um.
As partidas da Itália levam a proximidade ao extremo, com empates sendo os resultados previstos para as duas primeiras partidas do K.O.. Como as disputas de pênaltis são raras e não há dados suficientes para prever seus vencedores, recorri às minhas lembranças do bom histórico italiano de pênaltis e esperava que a Itália vencesse as duas disputas de pênaltis contra a Suíça e a Inglaterra.
No final, o modelo prevê que Espanha, Portugal, Holanda e Itália chegarão às semifinais.
A Holanda e a Espanha formam a minha previsão de final, assim como em 2010 - será que a história se repete?
Esse projeto proporcionou vários aprendizados importantes:
Para melhorar as previsões e expandir o escopo do projeto, você pode tomar várias medidas:
Para obter informações e códigos mais detalhados, visite o notebook do projeto.
Esta postagem do blog oferece uma visão geral dos desafios e metodologias envolvidos na previsão de resultados de futebol, destacando a jornada e os aprendizados do projeto de previsão da EURO 2024.
A integração da ciência de dados e da análise esportiva oferece oportunidades interessantes para entusiastas e profissionais da área. À medida que o projeto continua a evoluir, o objetivo continua sendo refinar os modelos e expandir sua aplicação para outros torneios, contribuindo para o crescente campo da análise esportiva.
Se você quiser saber mais sobre análise esportiva, aqui estão alguns recursos que você pode experimentar:
Aprenda machine learning com estes cursos!
Curso
Curso
Curso
blog
Kurtis Pykes
13 min
blog
Javier Canales Luna
14 min