
programa
Profesional de AWS Cloud (CLF-C02)
10 h
Tras haber utilizado Amazon Aurora durante un tiempo en varias empresas, he comprobado de primera mano cómo destaca como motor de base de datos relacional totalmente gestionado, ofreciendo un alto rendimiento, escalabilidad y fiabilidad.
Como solución nativa en la nube compatible con MySQL y PostgreSQL, Aurora es una opción excelente para las empresas que requieren alta disponibilidad y escalado automático. Dado que AWS administra las copias de seguridad, la conmutación por error y la replicación automáticamente, el uso de Aurora te permite aumentar la eficiencia de la base de datos al tiempo que reduces los costes de mantenimiento.
En este tutorial, te guiaré a través de la configuración de una instancia de Aurora, su gestión eficiente, la optimización del rendimiento y la garantía de seguridad y rentabilidad.
Amazon Aurora es una base de datos relacional basada en la nube que supera a las tradicionales MySQL y PostgreSQL escalando dinámicamente los recursos de almacenamiento y computación.
Según AWS, Aurora puede ofrecer hasta cinco veces elrendimiento de MySQL estándar y tres veces el de PostgreSQL estándar, gracias a su arquitectura distribuida y de alta disponibilidad.
Aurora está construida con funciones como copias de seguridad automatizadas, réplicas de lectura para escalado horizontal y mecanismos de conmutación por error que garantizan un tiempo de inactividad mínimo.
La capa de almacenamiento de Aurora está diseñada para tolerar fallos y autorrepararse.
Además, los datos se replican automáticamente en varias Zonas de Disponibilidad (AZ) para garantizar su durabilidad.
La imagen siguiente proporciona una visión general de alto nivel de la arquitectura y las características clave de Amazon Aurora.
La relación entre el volumen del clúster, la instancia DB escritora y las instancias DB lectoras en un clúster Aurora. Así queurce: Documentos AWS
El motor de la base de datos supervisa continuamente las consultas y optimiza los planes de ejecución, lo que se traduce en importantes mejoras de eficiencia.
Una de las principales ventajas de Aurora es su compatibilidad con las bases de datosMySQLy PostgreSQLexistentes, lo que facilita a las empresas la migración sin necesidad de modificar mucho sus aplicaciones.
La estructura de costes de Aurora también es atractiva. Cobra en función del uso real de los recursos informáticos y de almacenamiento. Este modelo de costes elimina la necesidad de sobreaprovisionar infraestructura, lo que a su vez ahorra dinero.
> Si estás interesado en una comprensión más amplia de las opciones de almacenamiento de AWS, checha un vistazo a este tutorial sobre almacenamiento de AWS.
Configurar AWS Aurora implica crear un clúster de base de datos, configurar los ajustes de seguridad y garantizar un acceso adecuado a la red. ¡Hagámoslo en esta sección!
> Si eres nuevo en AWS, considera repasar los temas básicos con tl curso Introducción a AWS antes de sumergirte en Aurora.
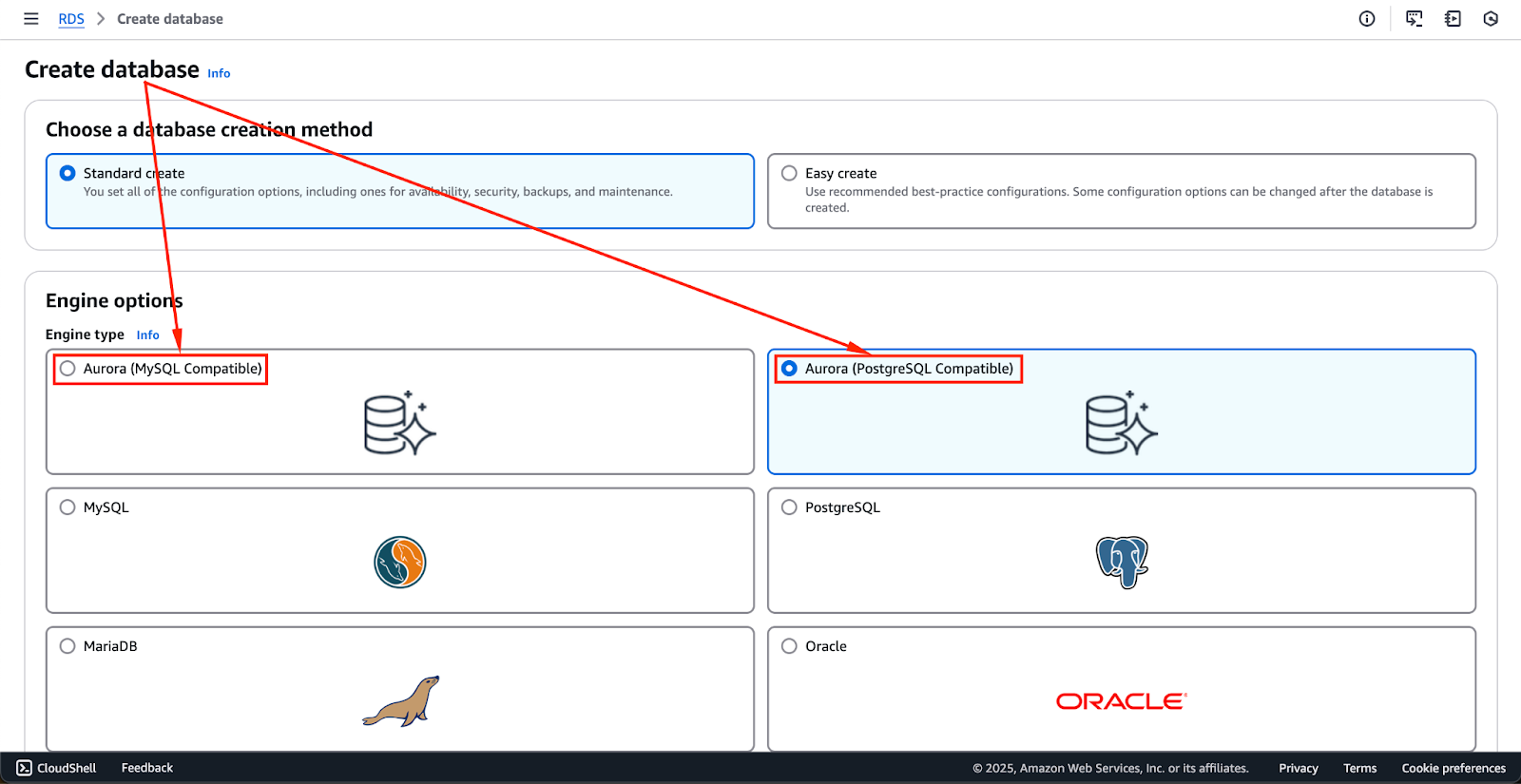
Configurar un clúster de base de datos Aurora requiere unos cuantos pasos clave, como seleccionar el motor de base de datos adecuado, configurar los ajustes de seguridad y definir las especificaciones de las instancias.
La imagen siguiente muestra las opciones de motor disponibles actualmente. Éstas podrían cambiar en el futuro, pero las dos primeras opciones -Aurora (Compatible con MySQL) y Aurora (Compatible con PostgreSQL)- son los motores Aurora.
La imagen siguiente destaca la "Disponibilidad y durabilidad" donde puedes configurar estos parámetros.
La imagen de abajo resalta la "Conectividad donde puedes establecer y personalizar estas configuraciones.
Después de revisar todas las configuraciones, puedes proceder a crear el cluster Aurora. La imagen siguiente muestra el botón"Crear base de datos" de que puedes pulsar para iniciar el proceso de creación.
El proceso de aprovisionamiento puede tardar varios minutos, dependiendo del tamaño de instancia seleccionado y de la configuración de la red.
> Si eres nuevo en los servicios de AWS, revisa tel curso Tecnología y servicios en la nube de AWS puede ayudarte a entender los conceptos clave de AWS relevantes para la configuración de Aurora.
La seguridad es fundamental para administrar una base de datos Aurora, y AWS proporciona múltiples herramientas para imponer fuertes controles de acceso.
> Para profundizar en la seguridad de los entornos de AWS, echa un vistazo aal curso de Gestión de Costes y Seguridad de AWS. Si quieres saber más sobre cómo funciona IAM y cómo implementarlo eficazmente, echa un vistazo a esta guía sobre AWS Identity and Access Management (IAM).
Conectarse a AWS Aurora es esencial para interactuar con la base de datos. Puedes hacerlo mediante herramientas cliente o aplicaciones. ¡Veamos cómo en esta sección!
Una vez que la base de datos Aurora esté en funcionamiento, tendrás que establecer una conexión para empezar a interactuar con la base de datos.
Para Aurora MySQL, se pueden utilizar clientes de bases de datos comunes como MySQL Workbench y HeidiSQL para conectarse. Como alternativa, puedes utilizar interfaces de línea de comandos.
La conexión requiere especificar el punto final de la base de datos, que puedes encontrar en la consola de administración de AWS.
Utilizando la CLI de MySQL, la conexión puede establecerse con el siguiente comando:
mysql -h your-cluster-endpoint -u admin -pTras introducir la contraseña maestra, deberías poder ejecutar consultas SQL, crear tablas y gestionar datos.
Para Aurora PostgreSQL, puedes conectarte utilizando herramientas como pgAdmin o la interfaz de línea de comandos de PostgreSQL (psql).
El comando de conexión en psql sigue este formato:
psql -h your-cluster-endpoint -U admin -d yourdatabasenameAl igual que con MySQL, hay que introducir las credenciales correctas para acceder a la base de datos.
Una vez que hayas obtenido acceso, deberías poder ejecutar consultas SQL, crear tablas y gestionar datos.
Las aplicaciones que necesiten interactuar con Aurora deben configurarse con las cadenas de conexión a la base de datos adecuadas. Normalmente, estas cadenas de conexión consisten en el nombre de usuario, la contraseña, el número de puerto y el punto final.
Se recomienda que utilices la agrupación de conexiones para optimizar el rendimiento y reducir la sobrecarga de establecer nuevas conexiones para cada solicitud.
Librerías populares como SQLAlchemy para Python o JDBC para Java proporcionan formas eficaces de gestionar las conexiones en un entorno de aplicación.
Administrar eficazmente AWS Aurora implica garantizar la protección de los datos, monitorizar el rendimiento y escalar los recursos según sea necesario. En esta sección, revisaremos estas prácticas.
AWS Aurora ofrece backups automatizados que capturan y almacenan continuamente los cambios de la base de datos en Amazon S3. Estas copias de seguridad se conservan en función de los ajustes definidos por el usuario, lo que permite restaurarlas en cualquier punto del periodo de conservación.
Además de las copias de seguridad automatizadas, también puedes crear instantáneas manuales que persistan más allá de la ventana de retención. Las instantáneas manuales son especialmente útiles para archivar a largo plazo o antes de realizar actualizaciones importantes de la base de datos.
Cuando trabajaba en un proyecto con una aplicación crítica, programábamos copias de seguridad automáticas cada dos horas. Sin embargo, antes de realizar cambios o actualizaciones en la aplicación, creábamos manualmente una copia de seguridad para asegurarnos de que podíamos volver atrás en caso necesario. Esto demuestra cómo las copias de seguridad automatizadas y manuales pueden utilizarse juntas de forma eficaz.
La imagen siguiente muestra cómo se puede utilizar AWS Backup para la recuperación de desastres con Amazon Aurora.
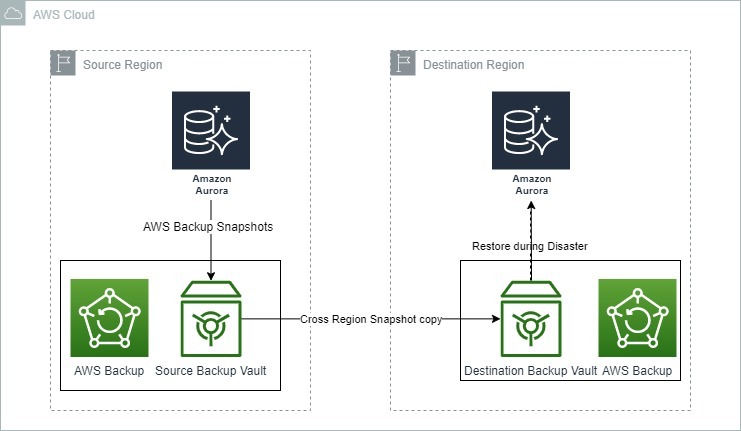
Opciones de copia de seguridad y recuperación para Amazon Aurora. Fuente: Blogs de AWS
La supervisión del rendimiento es esencial para mantener una base de datos saludable.
AWS CloudWatch proporciona métricas en tiempo real que rastrean la utilización de la CPU, el uso de la memoria, la E/S del disco y el tráfico de red.
Configurar las Alarmas de CloudWatch puede ayudar a los administradores a recibir notificaciones cuando se superen los umbrales de rendimiento, lo que permite una gestión proactiva de la base de datos.
Además, AWS Performance Insights ofrece un análisis detallado de las consultas para identificar y optimizar las que funcionan con lentitud.
La imagen siguiente muestra cómo AWS Performance Insights proporciona información sobre el rendimiento de la base de datos.
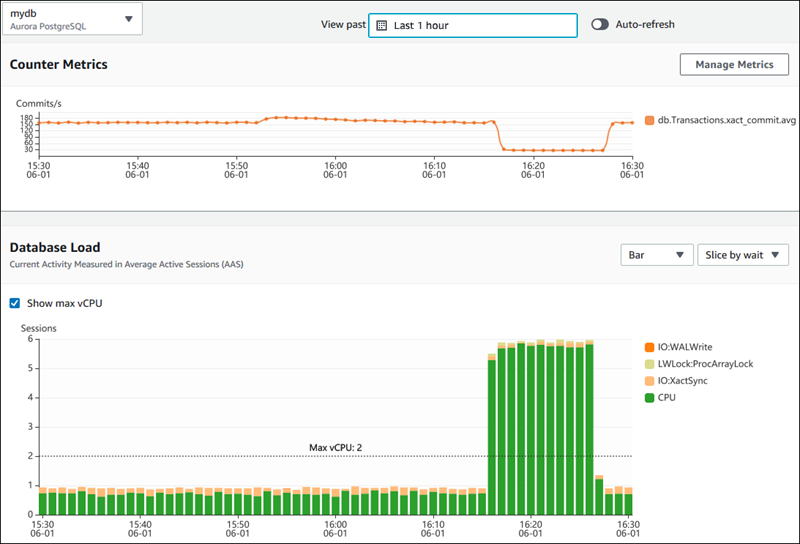
El panel de AWS Performance Insights muestra las métricas de rendimiento de la base de datos. Fuente: Documentos AWS
Aurora está diseñada para escalar automáticamente ajustando la capacidad de almacenamiento según sea necesario. Sin embargo, puede ser necesario ajustar manualmente los recursos informáticos, como la CPU y la memoria, en función de la carga de trabajo.
Aurora ofrece opciones para escalar la capacidad de lectura añadiendo réplicas de lectura, que distribuyen el tráfico de lectura y mejoran el rendimiento.
Cuando la alta disponibilidad es crítica, un clúster Aurora puede configurarse con múltiples réplicas en diferentes Zonas de Disponibilidad para garantizar la redundancia de conmutación por error.
La optimización del rendimiento en Amazon Aurora garantiza una ejecución eficaz de las consultas y la escalabilidad. Repasemos algunas buenas prácticas en esta sección.
Optimizar el rendimiento de las consultas en Amazon Aurora es crucial para mantener una base de datos de alto rendimiento.
EXPLAIN or EXPLAIN ANALYZE en las consultas SQL ayuda a identificar los cuellos de botella y proporciona información sobre los planes de ejecución . SELECT * (que recupera datos innecesarios), normalizar el esquema de la base de datos para reducir la redundancia y aprovechar las estrategias de partición pueden aumentar el rendimiento.Para manejar cargas de alto tráfico, Amazon Aurora soporta réplicas de lectura que ayudan a distribuir las consultas de lectura intensiva entre varias instancias.
Las réplicas de lectura reducen la carga de la instancia primaria de la base de datos al procesar las peticiones de lectura por separado, lo que mejora la capacidad de respuesta y reduce la latencia.
Para configurar una réplica de lectura de Aurora, tendrás que seleccionar un clúster de Aurora existente y activar la replicación con una configuración mínima. Aurora sincroniza automáticamente los datos entre la instancia primaria y sus réplicas, garantizando la coherencia de los datos sin intervención manual.
El mecanismo de replicación de Aurora es altamente eficiente, permitiendo una sincronización de datos casi en tiempo real con un retardo de replicación inferior a un segundo.
Las aplicaciones que realizan frecuentes operaciones de lectura, como los cuadros de mando de informes o los servicios de análisis, pueden beneficiarse significativamente de las réplicas de lectura dirigiendo a estas instancias las consultas de lectura intensiva.
En caso de fallo de una instancia primaria, puede promoverse una réplica de lectura para que se convierta en la nueva instancia primaria con un tiempo de inactividad mínimo, garantizando una alta disponibilidad y la continuidad de la empresa.
La imagen siguiente muestra cómo las réplicas Aurora entre regiones pueden ayudar en la recuperación ante desastres y la alta disponibilidad.
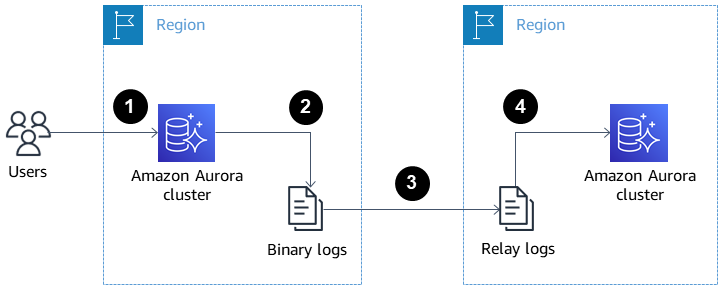
Réplicas de lectura Aurora entre regiones para recuperación ante desastres y alta disponibilidad. Fuente: Documentos AWS
El almacenamiento en caché es una potente técnica para mejorar el rendimiento de la base de datos, reduciendo la carga de consultas directas a Aurora. Una capa de almacenamiento en caché puede acelerar significativamente la recuperación de datos para consultas de acceso frecuente.
Amazon ElastiCache, compatible con Redis y Memcached, se utiliza habitualmente junto con Aurora para almacenar los resultados de las consultas y evitar consultas redundantes a la base de datos.
Integrar el almacenamiento en caché en la arquitectura de una aplicación puede ayudar a mejorar los tiempos de respuesta, preservando al mismo tiempo los recursos informáticos de la base de datos.
Las estrategias de almacenamiento en caché, como el write-through caching (en el que los datos se escriben simultáneamente en la caché y en Aurora) y el lazy loading (en el que los datos sólo se almacenan en caché cuando se solicitan) ayudan a optimizar el rendimiento en función de los patrones de uso.
Configurar un tiempo de vida (TTL) adecuado para los datos almacenados en caché garantiza que ésta se mantenga fresca y evita la recuperación de datos obsoletos.
Asegurar tu base de datos Aurora es crucial para proteger los datos sensibles y garantizar el cumplimiento de la normativa. Repasemos las mejores prácticas en esta sección.
La seguridad de los datos es fundamental para la gestión de bases de datos, y AWS Aurora proporciona sólidos mecanismos de cifrado para proteger los datos sensibles.
Estas medidas de encriptación pueden ayudarte a cumplir las mejores prácticas de seguridad y los requisitos normativos.
La imagen siguiente muestra cómo AWS KMS se integra con Amazon Aurora para cifrar tu base de datos.
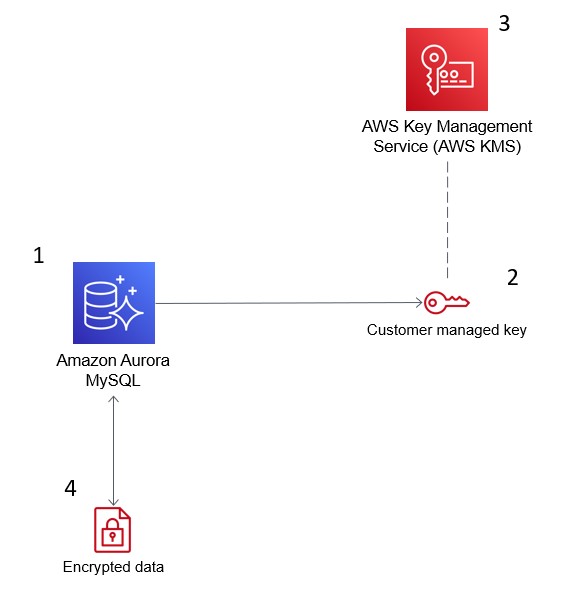
El Servicio de Administración de Claves (KMS) de AWS cifra los datos en Amazon Aurora por motivos de seguridad. Fuente: Blogs de AWS
El control de acceso en Aurora se gestiona a través de AWS IAM, que permite a los administradores definir permisos detallados basados en roles de usuario.
Debes aplicar los principios de acceso de mínimo privilegio, que minimizan los riesgos de seguridad y mantienen un control estricto sobre el acceso a la base de datos.
La imagen siguiente muestra cómo se puede configurar la autenticación IAM para asegurar el acceso a la base de datos PostgreSQL de Amazon Aurora.
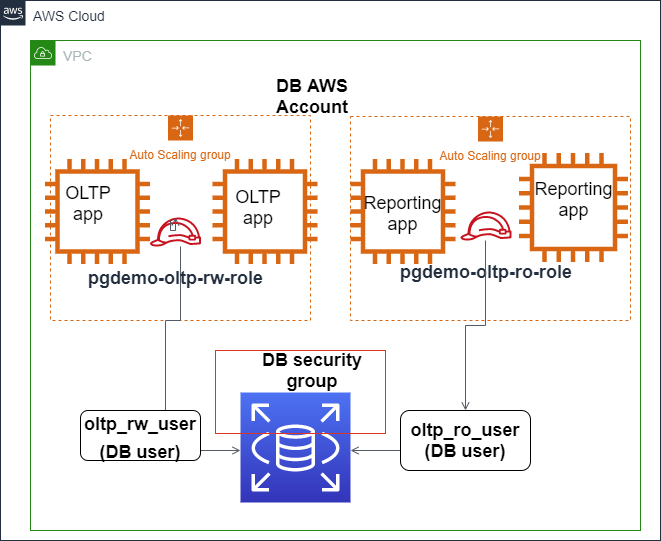
La autenticación IAM se integra con Amazon Aurora PostgreSQL. Fuentee: Blogs de AWS
Supervisar y auditar la actividad de la base de datos es esencial para el cumplimiento de la seguridad y la resolución de problemas.
Aurora proporciona varios mecanismos de registro, como registros de errores, registros de consultas lentas y registros generales, que ayudan a los administradores a seguir la actividad de la base de datos e identificar posibles problemas. Estos registros pueden activarse a través de la consola de administración de AWS y almacenarse en Amazon CloudWatch para su análisis centralizado.
Analizar estos registros puede ayudar a los administradores a optimizar la ejecución de consultas, detectar intentos de acceso no autorizados y garantizar la estabilidad de la base de datos.
Para gestionar y optimizar eficazmente los costes en Amazon Aurora, debes comprender su estructura de precios. ¡Vamos a repasarlo!
El modelo de precios de Amazon Aurora se basa en varios factores, como las horas de instancia, el consumo de almacenamiento, las solicitudes de E/S y la transferencia de datos.
A diferencia de las bases de datos tradicionales, que requieren un aprovisionamiento inicial de infraestructura, el modelo de pago por uso de Aurora permite a las empresas pagar sólo por los recursos que consumen.
Las instancias de cálculo se facturan en función de la clase de instancia y del tiempo de actividad, mientras que el almacenamiento se escala dinámicamente, eliminando la necesidad de ajustes manuales.
La siguiente imagen muestra un desglose de los distintos componentes de los precios de Amazon Aurora. Sin embargo, ten en cuenta que los precios pueden cambiar, por lo que siempre es mejor refer a la página de precios de Aurora para obtener la información más actualizada.
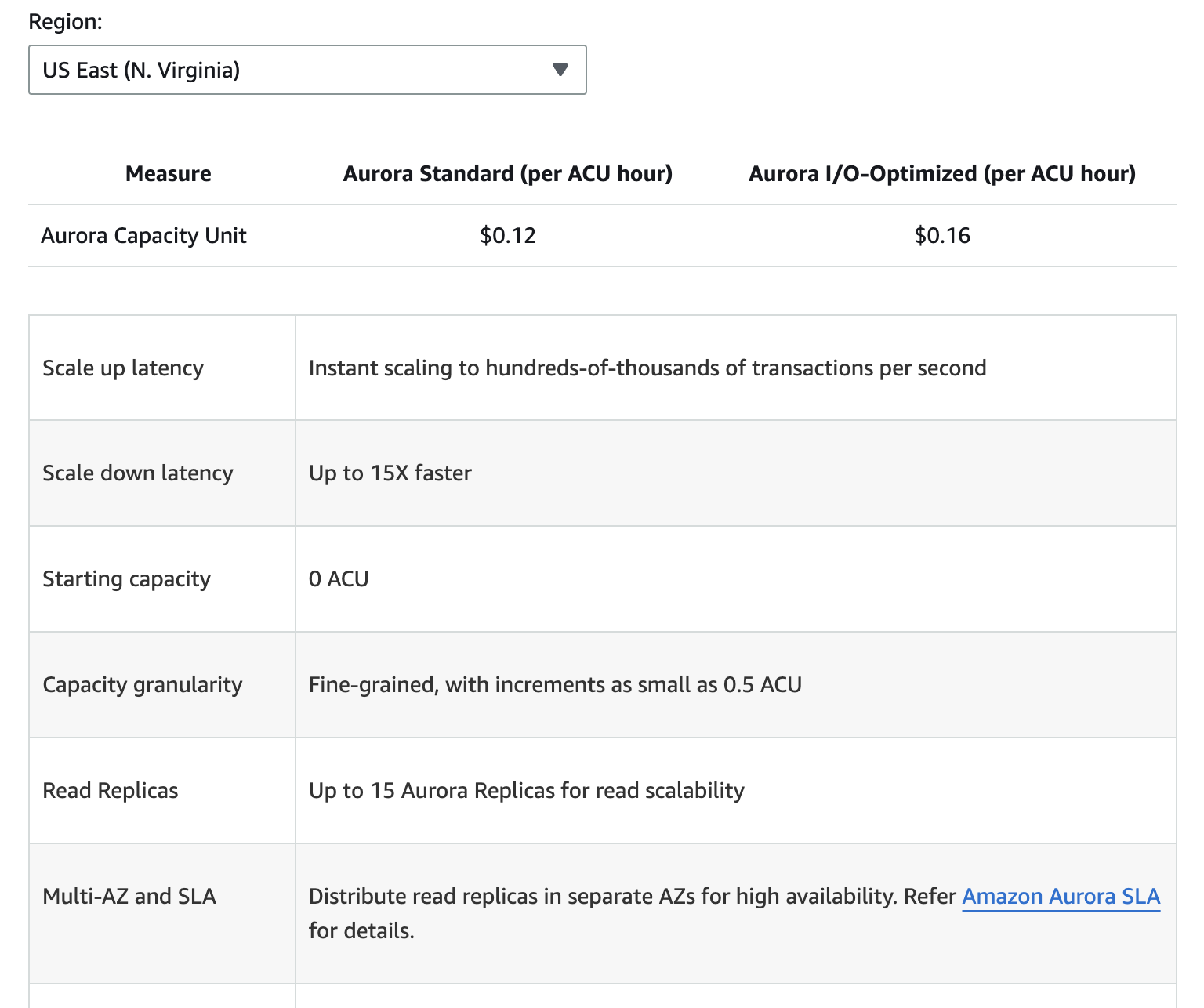
Los costes adicionales incluyen el almacenamiento de copia de seguridad más allá del nivel gratuito asignado, las solicitudes de E/S de lectura y escritura, y las tarifas de transferencia de datos para la replicación entre regiones.
Comprender estos componentes de los precios puede ayudarte a prever los gastos y a tomar decisiones informadas sobre el uso de la base de datos.
Para gestionar los costes con eficacia, las organizaciones pueden aplicar varias estrategias de optimización.
Seleccionar el tamaño de instancia adecuado garantizará que los recursos de la base de datos se ajusten a las demandas de la carga de trabajo sin sobreaprovisionar.
> Si quieres profundizar en la gestión de costes, referirte al curso de Seguridad y Gestión de Costes de AWS.
Después de trabajar con Amazon Aurora en varias empresas durante bastante tiempo, puedo afirmar con seguridad que se trata de una solución de base de datos potente y escalable que facilita la administración sin comprometer el rendimiento; probablemente estarás de acuerdo después de leer este tutorial.
Merece la pena tener en cuenta Aurora si buscas una base de datos relacional nativa de la nube que sea compatible con MySQL y PostgreSQL, al tiempo que reduce la sobrecarga operativa. Ha sido revolucionario en algunos de mis proyectos, y te recomiendo encarecidamente que investigues sus capacidades si trabajas con bases de datos de AWS.
Si eres nuevo en las bases de datos de AWS, ¡aprender los conceptos fundamentales mediante cursoscomo AWS Cloud Practitioner (CLF-C02 ) puede ser beneficioso!
Aprende más sobre AWS con estos cursos
programa
Curso
Curso
blog
Srujana Maddula
13 min
blog
Joleen Bothma
12 min
blog
Kurtis Pykes
15 min
Tutorial
Tim Lu
Tutorial
Anneleen Rummens
Tutorial
Anneleen Rummens