
Lernpfad
AWS Cloud Practitioner (CLF-C02)
10 Std.
Da ich Amazon Aurora schon seit einiger Zeit in verschiedenen Unternehmeneinsetze , habe ich aus erster Hand erfahren, dass es sich um eine vollständig verwaltete relationale Datenbank-Engine handelt, die hohe Leistung, Skalierbarkeit und Zuverlässigkeit bietet.
Als Cloud-native Lösung, die MySQL und PostgreSQL unterstützt, ist Aurora eine ausgezeichnete Wahl für Unternehmen, die hohe Verfügbarkeit und automatische Skalierung benötigen. Da AWS Backups, Failover und Replikation automatisch verwaltet, kannst du mit Aurora die Datenbankeffizienz steigern und gleichzeitig die Wartungskosten senken.
In diesem Tutorial führe ich dich durch die Einrichtung einer Aurora-Instanz, ihre effiziente Verwaltung, die Optimierung der Leistung und die Gewährleistung von Sicherheit und Kosteneffizienz.
Amazon Aurora ist eine Cloud-basierte relationale Datenbank, die herkömmliche MySQL- und PostgreSQL-Datenbanken durch dynamische Skalierung von Speicher- und Rechenressourcen übertrifft.
Laut AWS kann Auroraaufgrund seiner verteilten und hochverfügbaren Architektur einen bis zu fünfmal höherenDurchsatz als Standard-MySQL und die dreifache Leistung von Standard-PostgreSQL bieten.
Aurora verfügt über Funktionen wie automatische Backups, Read Replicas für horizontale Skalierung und Failover-Mechanismen, die minimale Ausfallzeiten gewährleisten.
Die Speicherebene von Aurora ist so konzipiert, dass sie fehlertolerant und selbstheilend ist.
Außerdem werden die Daten automatisch über mehrere Availability Zones (AZs) hinweg repliziert, um ihre Haltbarkeit zu gewährleisten.
Die folgende Abbildung gibt einen Überblick über die Architektur und die wichtigsten Funktionen von Amazon Aurora.
Die Beziehung zwischen dem Cluster-Volume, der Writer-DB-Instanz und den Reader-DB-Instanzen in einem Aurora-Cluster. Source: AWS Docs
Die Datenbank-Engine überwacht Abfragen kontinuierlich und optimiert die Ausführungspläne, was zu erheblichen Effizienzsteigerungen führt.
Einer der Hauptvorteile von Aurora ist die Kompatibilität mit bestehenden MySQL-und PostgreSQL-Datenbanken, was Unternehmen die Migration erleichtert, ohne dass sie ihre Anwendungen umfangreich ändern müssen.
Auch die Kostenstruktur von Aurora ist attraktiv. Die Abrechnung erfolgt nach der tatsächlichen Nutzung von Rechen- und Speicherressourcen. Dieses Kostenmodell macht eine Überversorgung der Infrastruktur überflüssig, was wiederum Geld spart.
> Wenn du an einem umfassenderen Verständnis der AWS-Speicheroptionen interessiert bist, schau dirdann schau dir das AWS Storage Tutorial an.
Die Einrichtung von AWS Aurora umfasst die Erstellung eines Datenbank-Clusters, die Konfiguration von Sicherheitseinstellungen und die Sicherstellung des richtigen Netzwerkzugangs. Das wollen wir in diesem Abschnitt tun!
> Wenn du neu bei AWS bist, solltest du die grundlegenden Themen mit demdem Kurs Einführung in AWS bevor du dich mit Aurora beschäftigst.
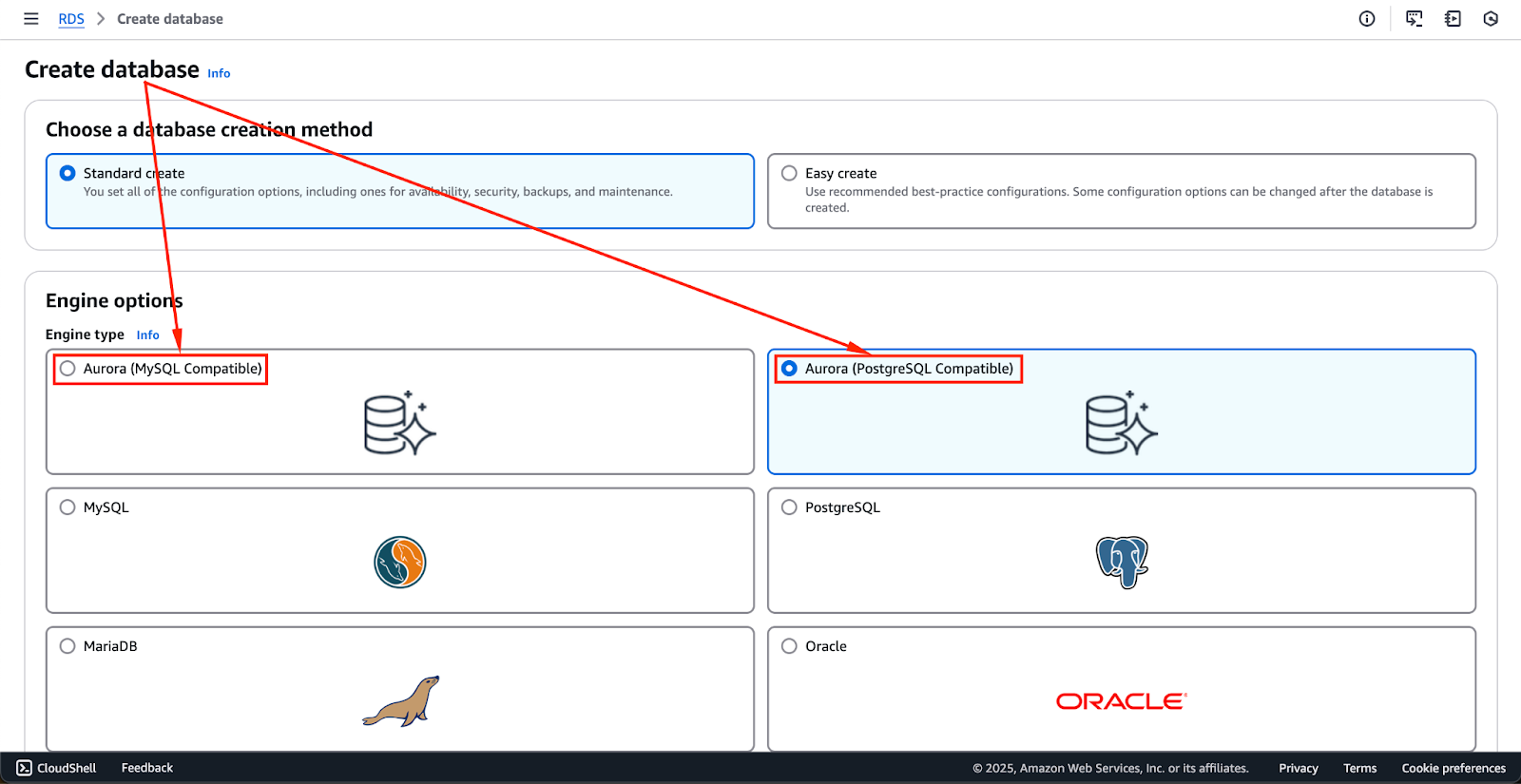
Die Einrichtung eines Aurora-Datenbankclusters erfordert einige wichtige Schritte, darunter die Auswahl der geeigneten Datenbank-Engine, die Konfiguration der Sicherheitseinstellungen und die Festlegung der Instanzspezifikationen.
Die Abbildung unten zeigt die Motoroptionen, die derzeit verfügbar sind. Diese können sich in Zukunft ändern, aber die ersten beiden Optionen - Aurora (MySQL-kompatibel) und Aurora (PostgreSQL-kompatibel) - sind die Aurora-Engines.
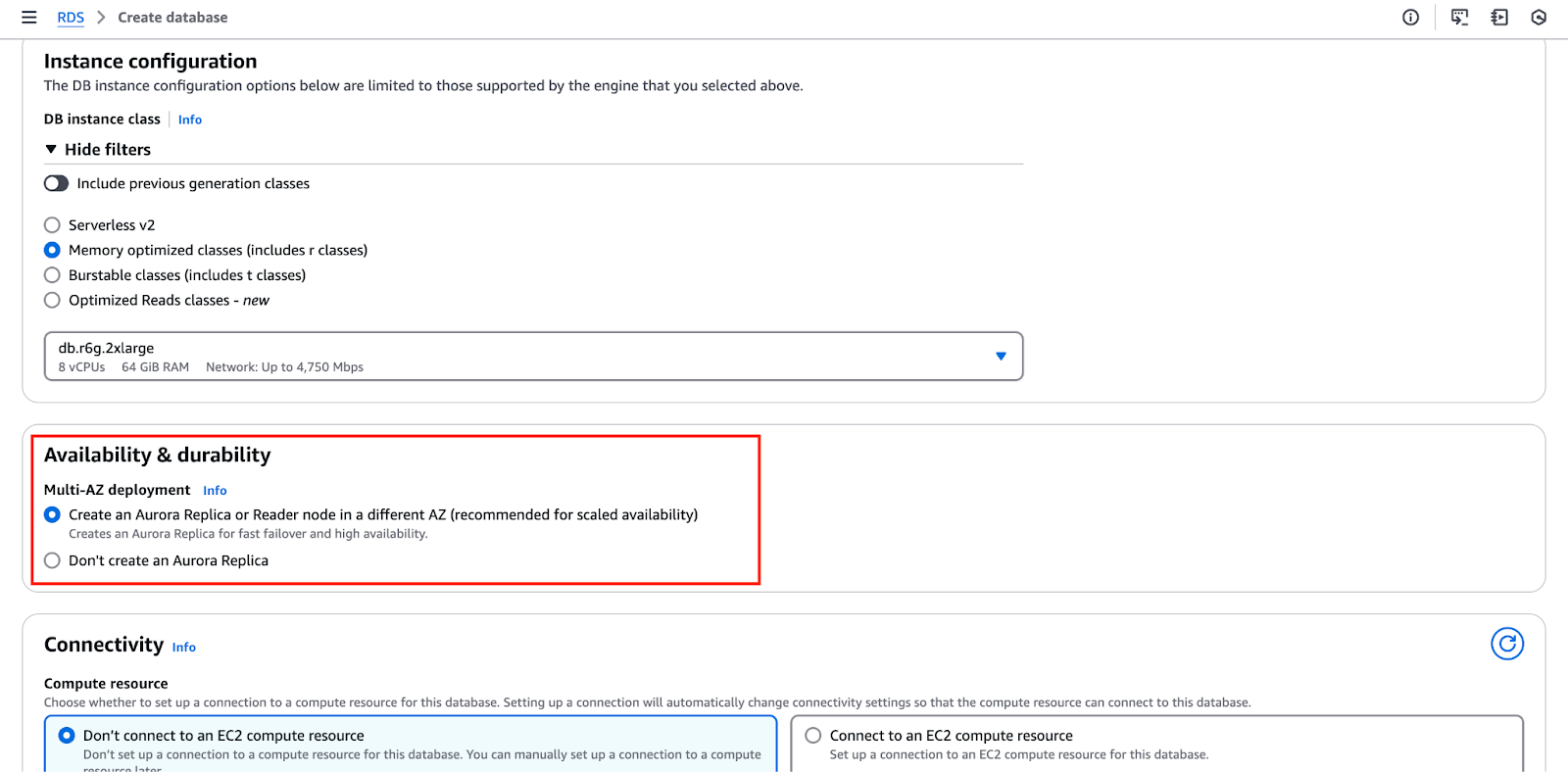
Das Bild unten hebt die "Verfügbarkeit & Haltbarkeit" wo du diese Einstellungen konfigurieren kannst.
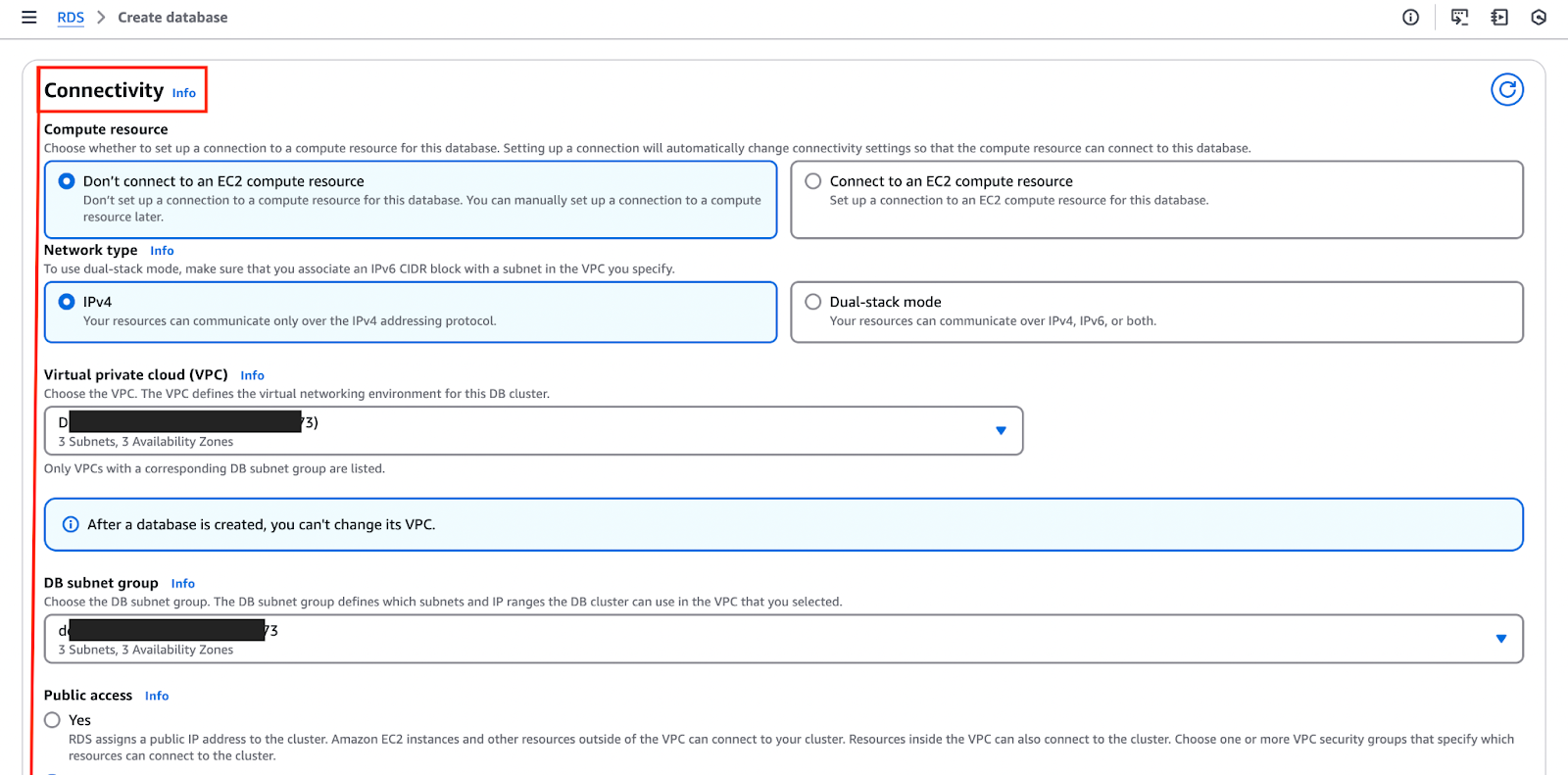
Das Bild unten hebt die "Konnektivität" wo du diese Konfigurationen einrichten und anpassen kannst.
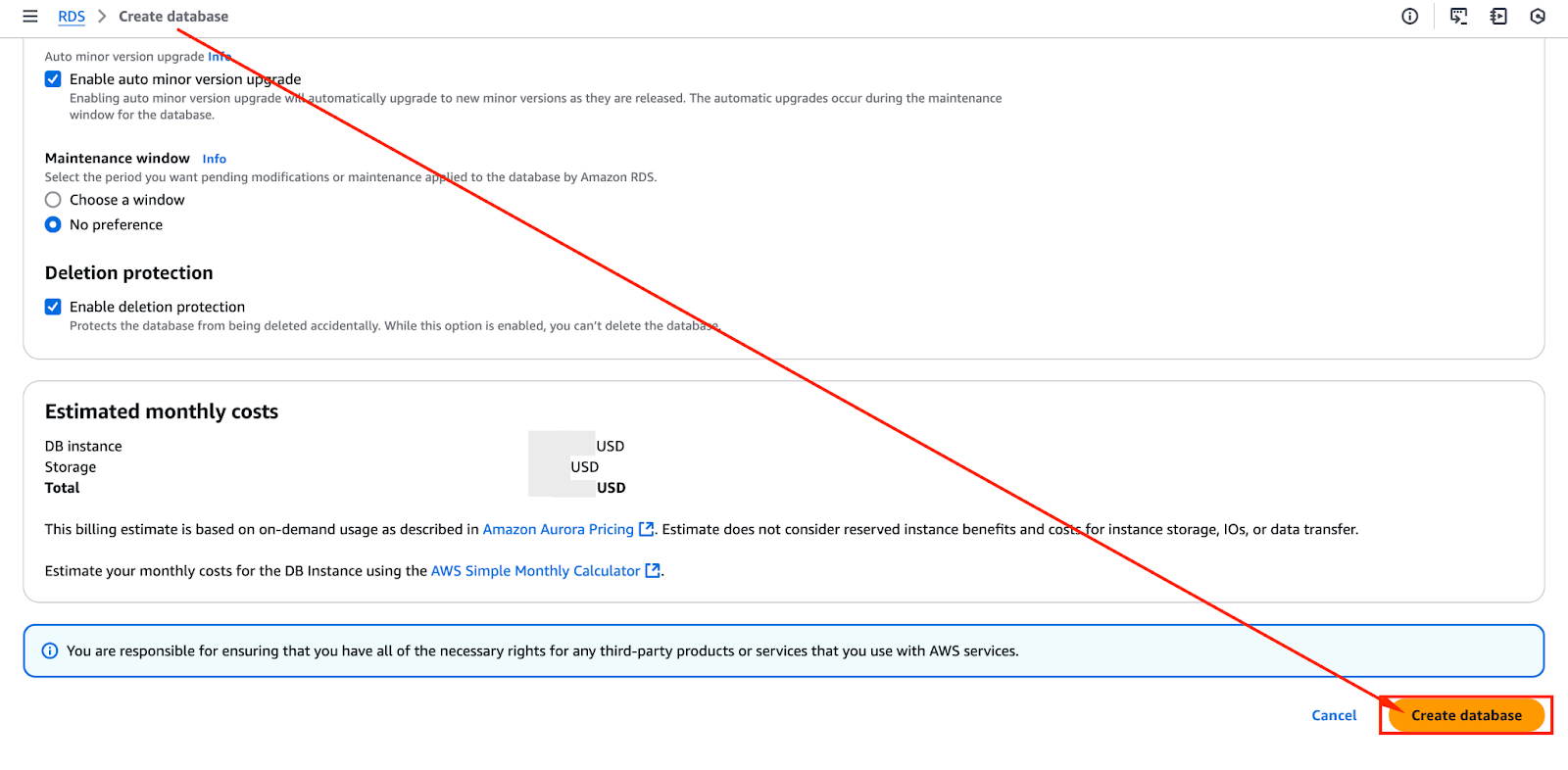
Nachdem du alle Konfigurationen überprüft hast, kannst du mit der Erstellung des Aurora-Clusters fortfahren. Das Bild unten zeigt die Schaltfläche "Datenbank erstellen ", auf die du klicken kannst, um den Erstellungsprozess zu starten.
Der Bereitstellungsprozess kann je nach gewählter Instanzgröße und Netzwerkeinstellungen einige Minuten dauern.
> Wenn du neu bei den AWS-Diensten bist, solltest du dir die AWS Cloud Technology and Services (AWS-Cloud-Technologie und -Services )kann dir helfen, die wichtigsten AWS-Konzepte zu verstehen, die für Aurora relevant sind.
Sicherheit ist für die Verwaltung einer Aurora-Datenbank von entscheidender Bedeutung, und AWS bietet mehrere Tools zur Durchsetzung strenger Zugriffskontrollen.
> Wenn du tiefer in die Sicherung von AWS-Umgebungen eintauchen willst, schau dir den Kurs " AWS Security and Cost Management" unteran. Wenn du mehr darüber erfahren möchtest, wie IAM funktioniert und wie du es effektiv implementieren kannst, wirf einen Blick auf diesen Leitfaden über AWS Identity and Access Management (IAM).
Die Verbindung zu AWS Aurora ist für die Interaktion mit der Datenbank unerlässlich. Du kannst dies entweder über Client-Tools oder Anwendungen tun. In diesem Abschnitt erfährst du, wie das geht!
Wenn die Aurora-Datenbank eingerichtet ist und läuft, musst du eine Verbindung herstellen, um mit der Datenbank zu interagieren.
Für Aurora MySQL können gängige Datenbank-Clients wie MySQL Workbench und HeidiSQL für die Verbindung verwendet werden. Alternativ kannst du auch die Befehlszeilenschnittstelle verwenden.
Für die Verbindung muss der Datenbankendpunkt angegeben werden, der in der AWS Management Console zu finden ist.
Mit der MySQL CLI kann die Verbindung mit folgendem Befehl hergestellt werden:
mysql -h your-cluster-endpoint -u admin -pNach Eingabe des Master-Kennworts solltest du in der Lage sein, SQL-Abfragen auszuführen, Tabellen zu erstellen und Daten zu verwalten.
Für Aurora PostgreSQL kannst du dich mit Tools wie pgAdmin oder dem PostgreSQL Command-Line Interface (psql) verbinden.
Der Verbindungsbefehl in psql folgt diesem Format:
psql -h your-cluster-endpoint -U admin -d yourdatabasenameGenau wie bei MySQL müssen die richtigen Anmeldedaten eingegeben werden, um auf die Datenbank zuzugreifen.
Sobald du Zugang erhalten hast, solltest du in der Lage sein, SQL-Abfragen auszuführen, Tabellen zu erstellen und Daten zu verwalten.
Anwendungen, die mit Aurora interagieren müssen, müssen mit entsprechenden Datenbankverbindungsstrings konfiguriert werden. Normalerweise bestehen diese Verbindungsstrings aus dem Benutzernamen, dem Passwort, der Portnummer und dem Endpunkt.
Es wird empfohlen, Verbindungspooling zu verwenden, um die Leistung zu optimieren und den Overhead zu reduzieren, der durch den Aufbau neuer Verbindungen für jede Anfrage entsteht.
Beliebte Bibliotheken wie SQLAlchemy für Python oder JDBC für Java bieten effiziente Möglichkeiten zur Verwaltung von Verbindungen in einer Anwendungsumgebung.
Zur effektiven Verwaltung von AWS Aurora gehört es, den Datenschutz zu gewährleisten, die Leistung zu überwachen und die Ressourcen nach Bedarf zu skalieren. In diesem Abschnitt werden wir diese Praktiken überprüfen.
AWS Aurora bietet automatische Backups, die kontinuierlich Datenbankänderungen erfassen und in Amazon S3 speichern. Diese Backups werden auf der Grundlage von benutzerdefinierten Einstellungen aufbewahrt und können zu jedem beliebigen Zeitpunkt innerhalb der Aufbewahrungsfrist wiederhergestellt werden.
Zusätzlich zu den automatischen Backups kannst du auch manuelle Snapshots erstellen, die über das Aufbewahrungsfenster hinaus bestehen bleiben. Manuelle Snapshots sind besonders nützlich für die Langzeitarchivierung oder vor größeren Datenbankaktualisierungen.
Als ich an einem Projekt mit einer kritischen Anwendung arbeitete, planten wir alle zwei Stunden automatische Backups. Bevor wir jedoch Änderungen oder Aktualisierungen an der Anwendung vornehmen, erstellen wir manuell eine Sicherungskopie, um sicherzustellen, dass wir bei Bedarf ein Rollback durchführen können. Dies zeigt, wie sowohl automatische als auch manuelle Backups effektiv eingesetzt werden können.
Das Bild unten zeigt, wie AWS Backup für die Notfallwiederherstellung mit Amazon Aurora verwendet werden kann.
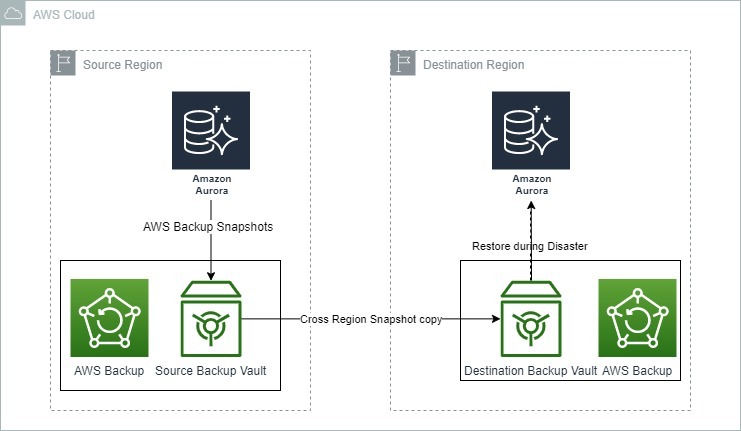
Sicherungs- und Wiederherstellungsoptionen für Amazon Aurora. Quelle: AWS Blogs
Die Leistungsüberwachung ist für die Aufrechterhaltung einer gesunden Datenbank unerlässlich.
AWS CloudWatch bietet Echtzeit-Metriken, die CPU-Auslastung, Speichernutzung, Festplatten-E/A und Netzwerkverkehr verfolgen.
Durch die Einrichtung von CloudWatch Alarms können Administratoren benachrichtigt werden, wenn Leistungsschwellen überschritten werden, was ein proaktives Datenbankmanagement ermöglicht.
Darüber hinaus bietet AWS Performance Insights eine detaillierte Abfrageanalyse, um langsam laufende Abfragen zu identifizieren und zu optimieren.
Die folgende Abbildung zeigt, wie AWS Performance Insights Einblicke in die Datenbankleistung gewährt.
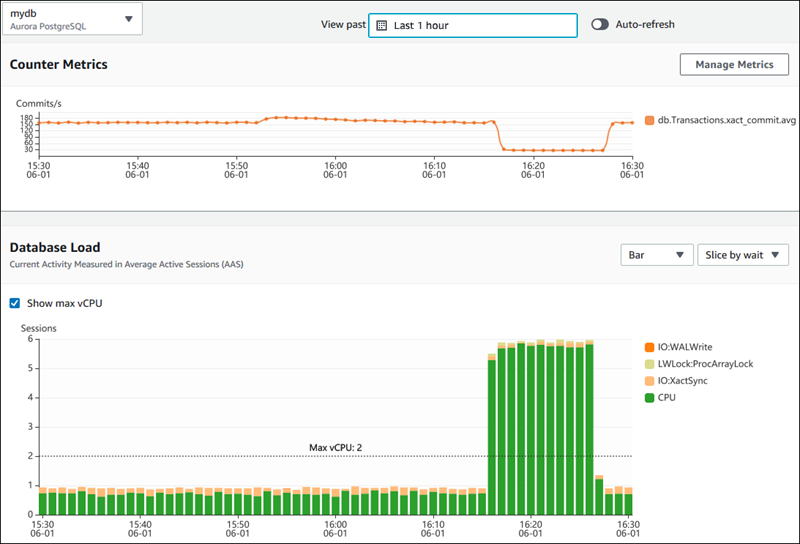
AWS Performance Insights Dashboard, das die Leistungskennzahlen der Datenbank anzeigt. Quelle: AWS Docs
Aurora ist so konzipiert, dass es automatisch skaliert, indem es die Speicherkapazität nach Bedarf anpasst. Allerdings müssen Rechenressourcen wie CPUs und Arbeitsspeicher je nach Arbeitsbelastung möglicherweise manuell angepasst werden.
Aurora bietet Optionen zur Skalierung der Lesekapazität durch Hinzufügen von Read Replicas, die den Leseverkehr verteilen und die Leistung verbessern.
Wenn Hochverfügbarkeit entscheidend ist, kann ein Aurora-Cluster mit mehreren Replikaten in verschiedenen Availability Zones konfiguriert werden, um Failover-Redundanz zu gewährleisten.
Die Optimierung der Leistung in Amazon Aurora sorgt für eine effiziente Abfrageausführung und Skalierbarkeit. In diesem Abschnitt gehen wir auf einige bewährte Verfahren ein.
Die Optimierung der Abfrageleistung in Amazon Aurora ist entscheidend für die Aufrechterhaltung einer hochleistungsfähigen Datenbank.
EXPLAIN or EXPLAIN ANALYZE in SQL-Abfragen hilft dabei, Engpässe zu erkennen und gibt Einblick in die Ausführungspläne . SELECT * (wodurch unnötige Daten abgerufen werden), die Normalisierung des Datenbankschemas zur Reduzierung von Redundanzen und die Nutzung von Partitionierungsstrategien können zu Leistungssteigerungen führen.Zur Bewältigung von hohem Datenverkehr unterstützt Amazon Aurora Read Replicas, die dabei helfen, leseintensive Abfragen auf mehrere Instanzen zu verteilen.
Lesereplikate entlasten die primäre Datenbankinstanz, indem sie Leseanfragen separat verarbeiten, was die Reaktionsfähigkeit verbessert und die Latenzzeit verringert.
Um eine Aurora-Lesereplikation einzurichten, musst du einen bestehenden Aurora-Cluster auswählen und die Replikation mit minimaler Konfiguration aktivieren. Aurora synchronisiert die Daten automatisch zwischen der primären Instanz und ihren Replikaten und stellt so die Datenkonsistenz ohne manuelle Eingriffe sicher.
Der Replikationsmechanismus von Aurora ist hocheffizient und ermöglicht eine Datensynchronisation nahezu in Echtzeit mit einer Replikationsverzögerung von weniger als einer Sekunde.
Anwendungen, die häufig Lesevorgänge durchführen, wie z. B. Reporting-Dashboards oder Analysedienste, können von Read Replicas erheblich profitieren, indem sie leseintensive Abfragen an diese Instanzen leiten.
Im Falle eines Ausfalls der primären Instanz kann eine Read Replica mit minimaler Ausfallzeit zur neuen primären Instanz befördert werden, um hohe Verfügbarkeit und Geschäftskontinuität zu gewährleisten.
Die Abbildung unten zeigt, wie regionsübergreifende Aurora-Replikate bei Disaster Recovery und Hochverfügbarkeit helfen können.
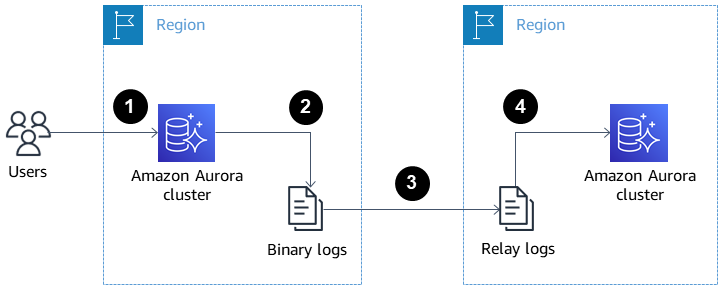
Regionsübergreifende Aurora-Lesereplikate für Disaster Recovery und hohe Verfügbarkeit. Quelle: AWS Docs
Caching ist eine leistungsstarke Technik, um die Datenbankleistung zu verbessern, indem die direkte Abfragelast auf Aurora reduziert wird. Eine Caching-Schicht kann den Datenabruf bei häufig gestellten Abfragen erheblich beschleunigen.
Amazon ElastiCache, der Redis und Memcached unterstützt, wird häufig zusammen mit Aurora verwendet, um Abfrageergebnisse zu speichern und redundante Datenbankabfragen zu vermeiden.
Die Integration von Caching in eine Anwendungsarchitektur kann helfen, die Antwortzeiten zu verbessern und gleichzeitig die Rechenressourcen der Datenbank zu schonen.
Caching-Strategien wie Write-Through-Caching (bei dem die Daten gleichzeitig in den Cache und in Aurora geschrieben werden) und Lazy Loading (bei dem die Daten nur dann in den Cache geladen werden, wenn sie angefordert werden) helfen dabei, die Leistung je nach Nutzungsmuster zu optimieren.
Die Konfiguration einer angemessenen Time-to-Live (TTL) für gecachte Daten stellt sicher, dass der Cache frisch bleibt und verhindert, dass veraltete Daten abgerufen werden.
Die Sicherung deiner Aurora-Datenbank ist wichtig, um sensible Daten zu schützen und die Einhaltung von Vorschriften zu gewährleisten. In diesem Abschnitt gehen wir auf die besten Praktiken ein.
Datensicherheit ist für die Datenbankverwaltung von grundlegender Bedeutung, und AWS Aurora bietet robuste Verschlüsselungsmechanismen, um sensible Daten zu schützen.
Diese Verschlüsselungsmaßnahmen können dir helfen, bewährte Sicherheitspraktiken und gesetzliche Vorschriften einzuhalten.
Die folgende Abbildung zeigt, wie AWS KMS mit Amazon Aurora integriert wird, um deine Datenbank zu verschlüsseln.
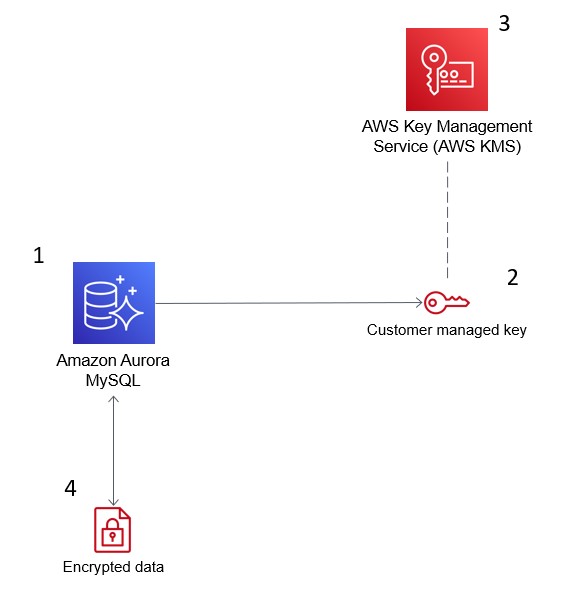
Der AWS Key Management Service (KMS) verschlüsselt die Daten in Amazon Aurora, um die Sicherheit zu gewährleisten. Quelle: AWS Blogs
Die Zugriffskontrolle in Aurora wird über AWS IAM verwaltet, mit dem Administratoren fein abgestufte Berechtigungen auf Basis von Benutzerrollen festlegen können.
Du solltest das Prinzip der geringsten Privilegien durchsetzen, um Sicherheitsrisiken zu minimieren und den Datenbankzugriff streng zu kontrollieren.
Die folgende Abbildung zeigt, wie die IAM-Authentifizierung konfiguriert werden kann, um den Zugriff auf die Amazon Aurora PostgreSQL-Datenbank zu sichern.
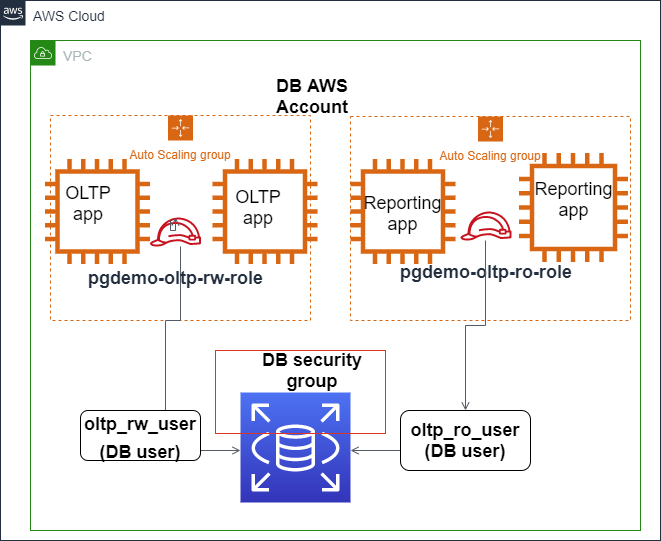
Die IAM-Authentifizierung ist mit Amazon Aurora PostgreSQL integriert. Source: AWS Blogs
Die Überwachung und Prüfung von Datenbankaktivitäten ist für die Einhaltung von Sicherheitsvorschriften und die Fehlerbehebung unerlässlich.
Aurora bietet verschiedene Protokollierungsmechanismen, darunter Fehlerprotokolle, Protokolle für langsame Abfragen und allgemeine Protokolle, die den Administratoren helfen, die Datenbankaktivitäten zu verfolgen und mögliche Probleme zu erkennen. Diese Protokolle können über die AWS Management Console aktiviert und in Amazon CloudWatch zur zentralen Analyse gespeichert werden.
Die Analyse dieser Protokolle kann Administratoren helfen, die Ausführung von Abfragen zu optimieren, unberechtigte Zugriffsversuche zu erkennen und die Stabilität der Datenbank zu gewährleisten.
Um die Kosten in Amazon Aurora effektiv zu verwalten und zu optimieren, musst du die Preisstruktur verstehen. Lass es uns überprüfen!
Das Preismodell von Amazon Aurora basiert auf mehreren Faktoren, darunter Instanzstunden, Speicherverbrauch, E/A-Anfragen und Datentransfer.
Im Gegensatz zu herkömmlichen Datenbanken, bei denen die Infrastruktur im Voraus bereitgestellt werden muss, können Unternehmen mit dem Pay-as-you-go-Modell von Aurora nur für die Ressourcen zahlen, die sie verbrauchen.
Compute-Instanzen werden auf der Grundlage der Instanzklasse und der Betriebszeit abgerechnet, während der Speicher dynamisch skaliert wird, sodass keine manuellen Anpassungen mehr erforderlich sind.
Die folgende Abbildung zeigt eine Aufschlüsselung der verschiedenen Preiskomponenten für Amazon Aurora. Beachte jedoch, dass sich die Preise ändern können. Deshalb ist es immer am besten, die Aurora-Preisseitezu besuchen, um die aktuellsten Informationen zu erhalten.
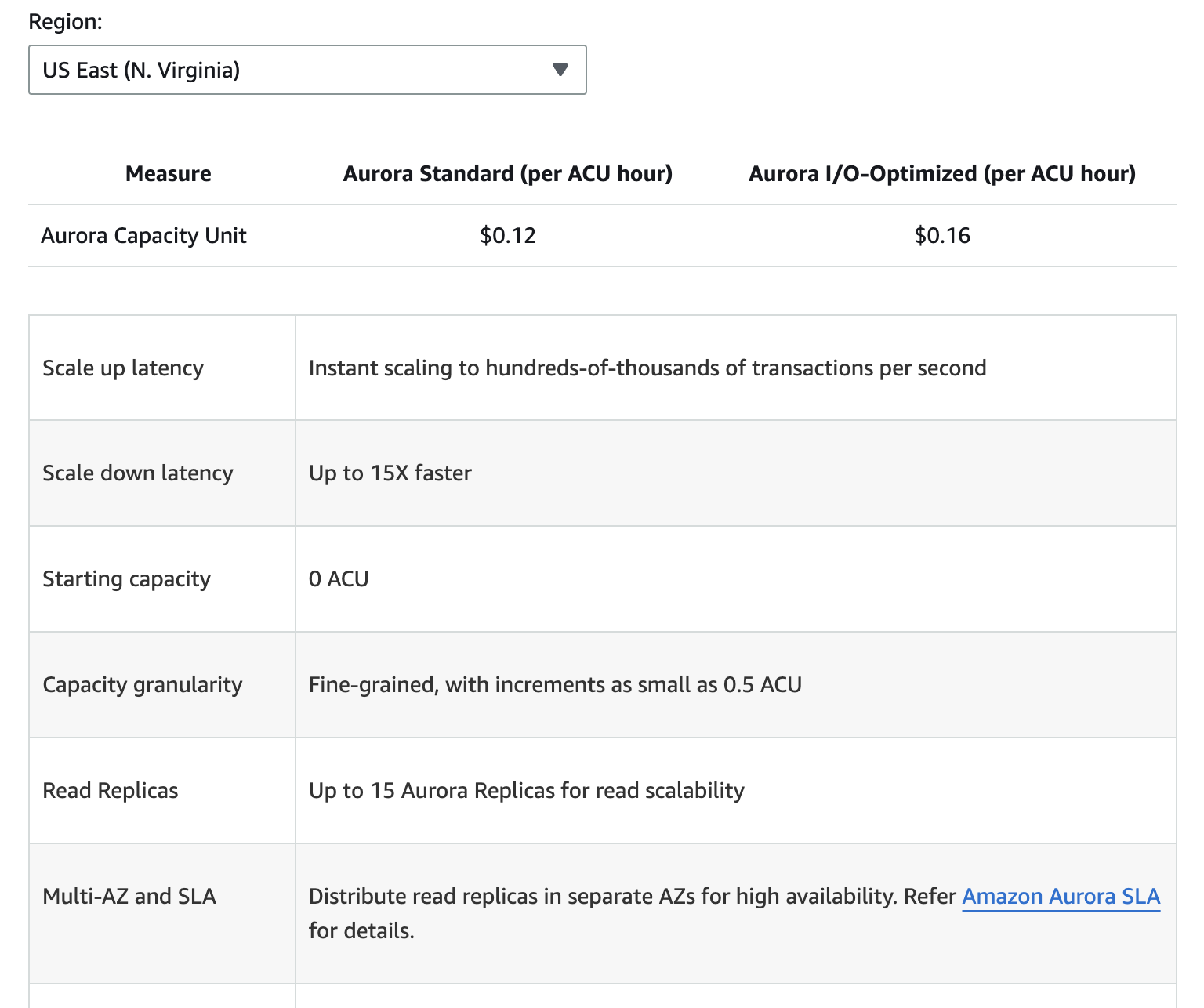
Zu den zusätzlichen Kosten gehören Backup-Speicher über den zugewiesenen freien Speicherplatz hinaus, Lese- und Schreibzugriffe sowie Datenübertragungsgebühren für die regionsübergreifende Replikation.
Wenn du diese Preiskomponenten verstehst, kannst du deine Ausgaben besser einschätzen und fundierte Entscheidungen über die Nutzung der Datenbank treffen.
Um die Kosten effektiv zu verwalten, können Unternehmen verschiedene Optimierungsstrategien anwenden.
Durch die Wahl der richtigen Instanzgröße wird sichergestellt, dass die Datenbankressourcen den Anforderungen der Arbeitslast entsprechen, ohne dass es zu einer Überversorgung kommt.
> Wenn du einen tieferen Einblick in das Kostenmanagement erhalten möchtest, referiere den AWS-Kurs Sicherheit und Kostenmanagement.
Nachdem ich eine ganze Weile mit Amazon Aurora in verschiedenen Unternehmen gearbeitet habe, kann ich mit Sicherheit sagen, dass es sich um eine leistungsstarke und skalierbare Datenbanklösung handelt, die die Verwaltung vereinfacht, ohne die Leistung zu beeinträchtigen - das wirst du nach diesem Tutorial sicher bestätigen.
Aurora ist eine Überlegung wert, wenn du auf der Suche nach einer Cloud-nativen relationalen Datenbank bist, die MySQL und PostgreSQL unterstützt und gleichzeitig den betrieblichen Aufwand reduziert. Sie war in einigen meiner Projekte revolutionär und ich kann nur empfehlen, sich mit ihren Möglichkeiten vertraut zu machen, wenn du mit AWS-Datenbanken arbeitest.
Wenn du neu in AWS-Datenbanken bist,kann das Erlernen grundlegender Konzepte durch Kursewie AWS Cloud Practitioner (CLF-C02) von Vorteil sein!
Lerne mehr über AWS mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
