
Track
AWS Cloud Practitioner (CLF-C02)
10 hr
Having used Amazon Aurora for a while now at various companies, I have seen firsthand how it excels as a fully managed relational database engine, offering high performance, scalability, and reliability.
As a cloud-native solution that supports MySQL and PostgreSQL, Aurora is an excellent choice for businesses that require high availability and automatic scaling. Because AWS manages backups, failover, and replication automatically, using Aurora allows you to increase database efficiency while lowering maintenance costs.
In this tutorial, I will guide you through setting up an Aurora instance, managing it efficiently, optimizing performance, and ensuring security and cost-effectiveness.
Amazon Aurora is a cloud-based relational database that outperforms traditional MySQL and PostgreSQL by dynamically scaling storage and compute resources.
According to AWS, Aurora can deliver up to five times the throughput of standard MySQL and three times the performance of standard PostgreSQL - due to its distributed and highly available architecture.
Aurora is built with features such as automated backups, read replicas for horizontal scaling, and failover mechanisms that ensure minimal downtime.
The storage layer of Aurora is designed to be fault-tolerant and self-healing.
In addition to this, data is automatically replicated across multiple Availability Zones (AZs) to ensure durability.
The image below provides a high-level overview of Amazon Aurora’s architecture and key features.
The relationship between the cluster volume, writer DB instance, and reader DB instances in an Aurora cluster. Source: AWS Docs
The database engine continuously monitors queries and optimizes execution plans, leading to significant efficiency improvements.
One of Aurora's key benefits is its compatibility with existing MySQL and PostgreSQL databases, which makes it easy for businesses to migrate without needing to modify their applications extensively.
Aurora's cost structure is also attractive. It charges based on the actual usage of compute and storage resources. This cost model eliminates the need to overprovision infrastructure, which in turn saves money.
> If you are interested in a broader understanding of AWS storage options, check out this AWS Storage Tutorial.
Setting up AWS Aurora involves creating a database cluster, configuring security settings, and ensuring proper network access. Let’s do that in this section!
> If you are new to AWS, consider reviewing foundational topics with the Introduction to AWS course before diving into Aurora.
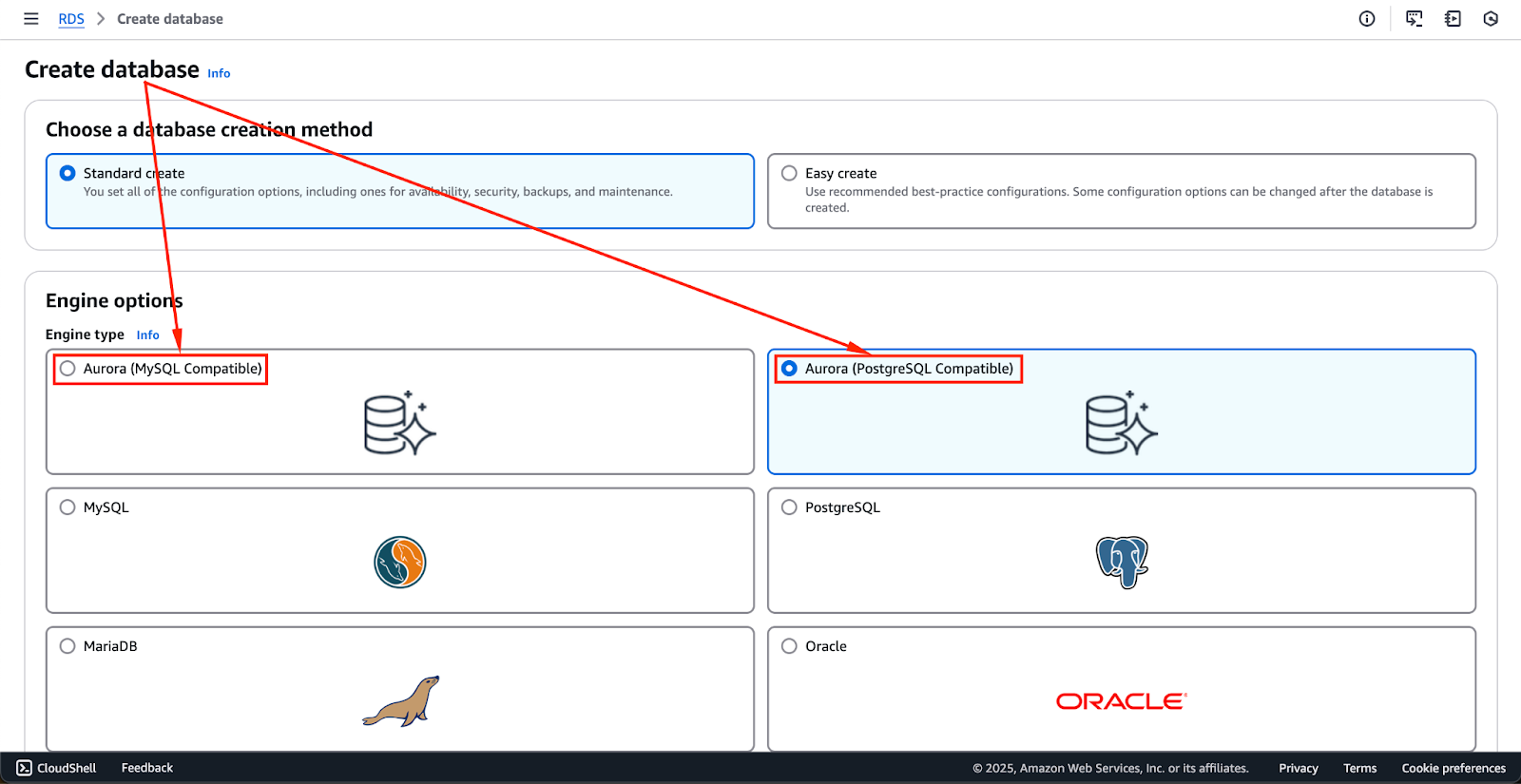
Setting up an Aurora database cluster requires a few key steps, including selecting the appropriate database engine, configuring security settings, and defining instance specifications.
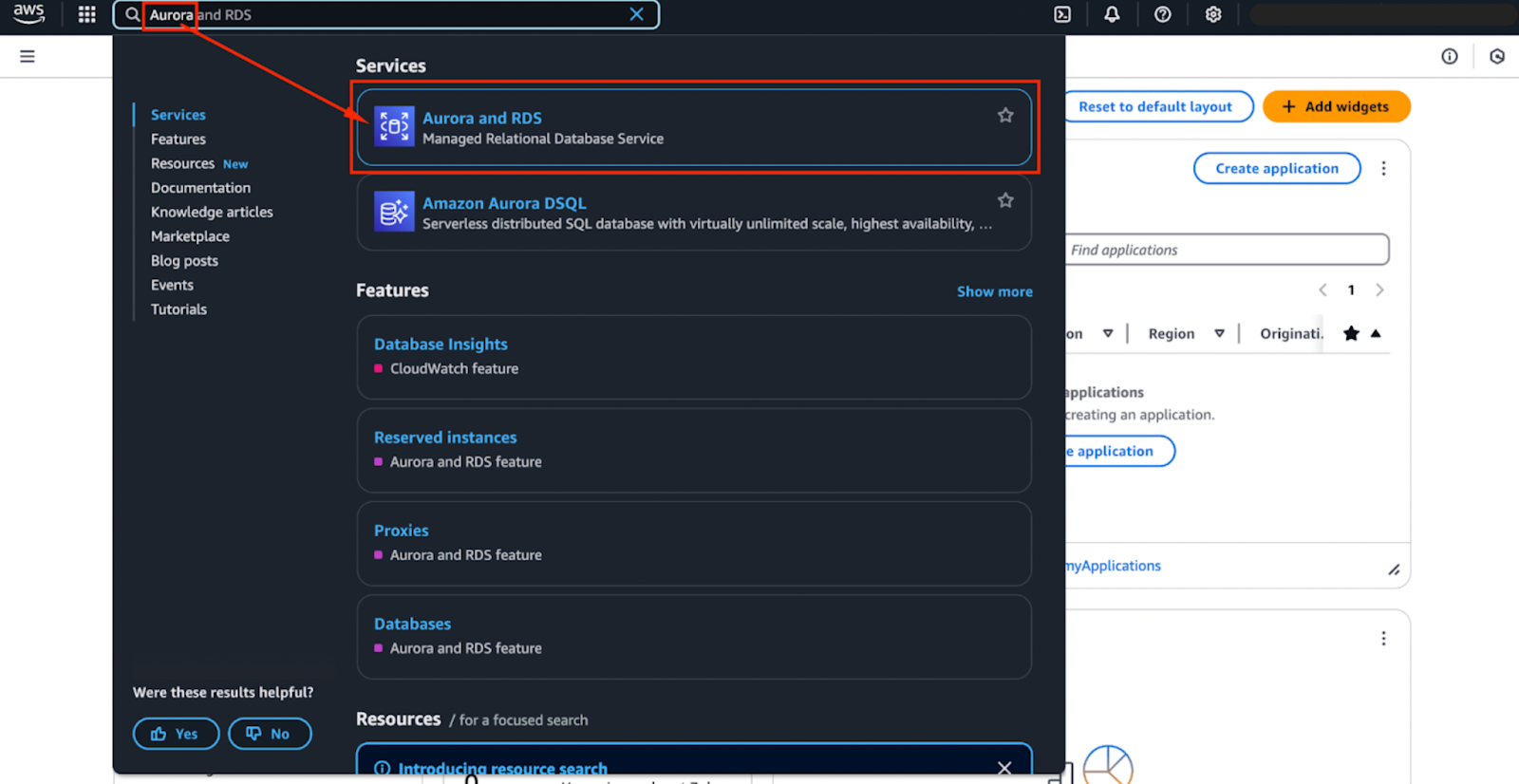
The image below shows the engine options that are currently available. These might change in the future, but the first two options—Aurora (MySQL Compatible) and Aurora (PostgreSQL Compatible)—are the Aurora engines.
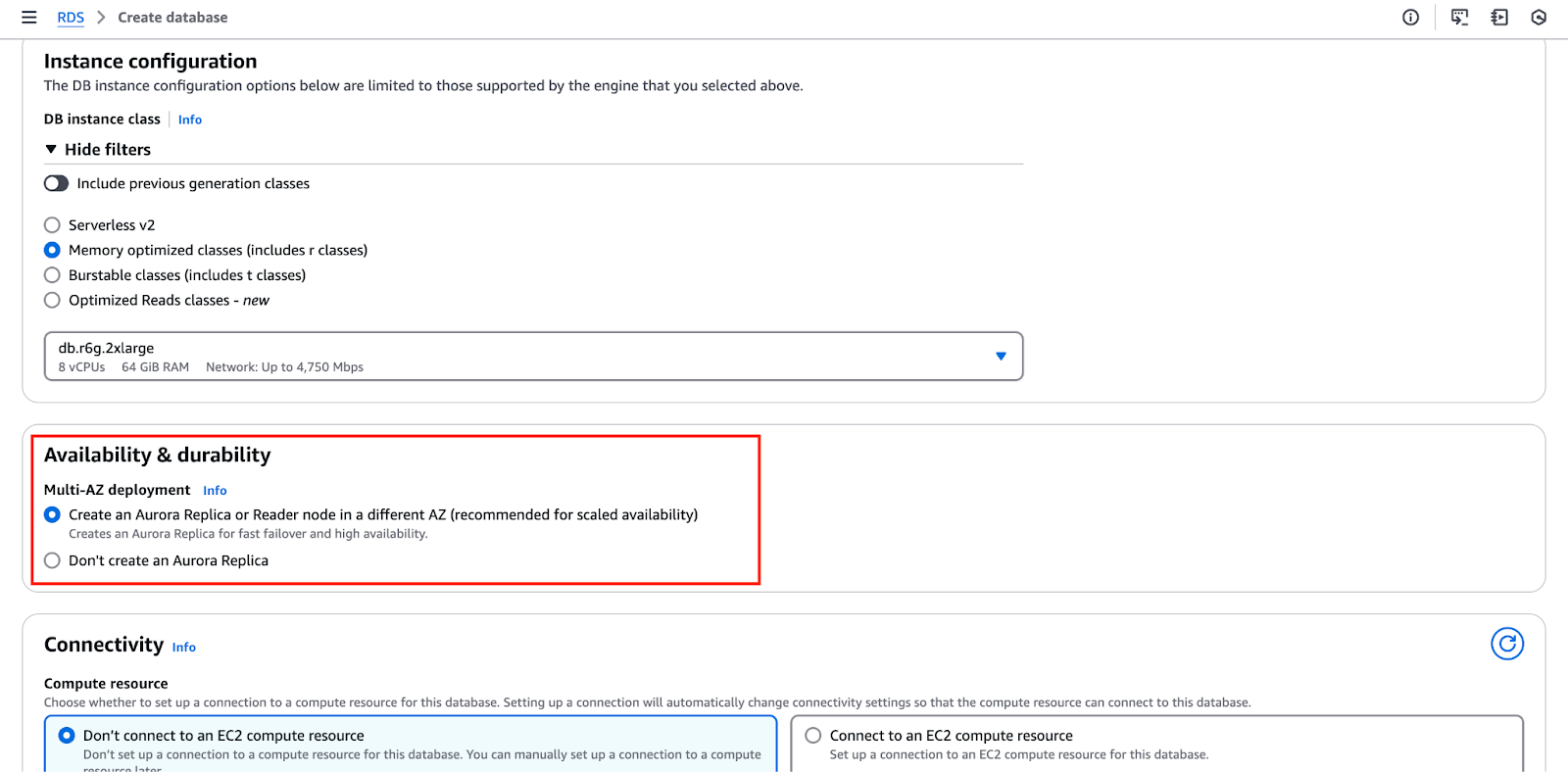
The image below highlights the "Availability & durability" section, where you can configure these settings.
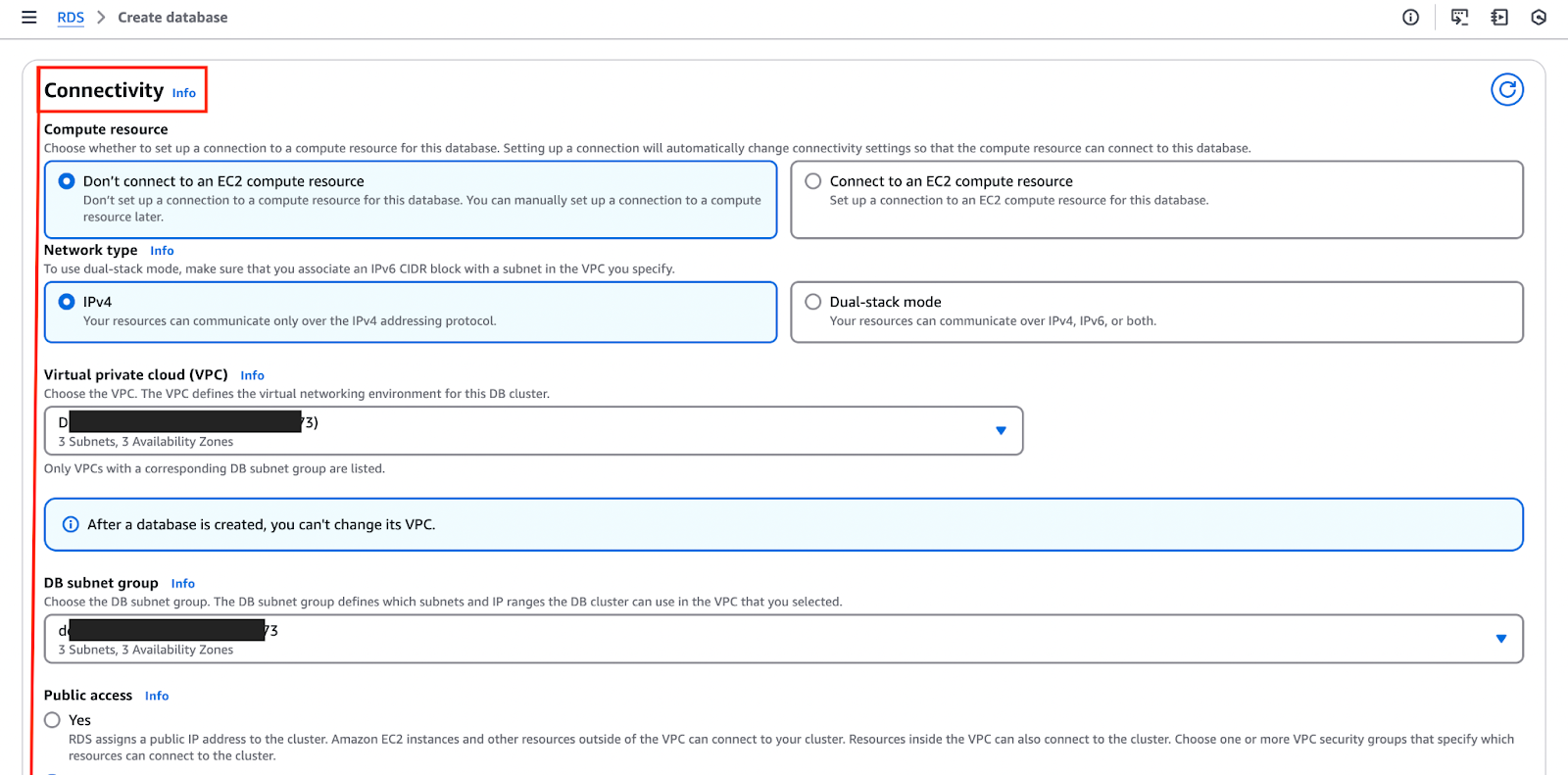
The image below highlights the "Connectivity" section, where you can set up and customize these configurations.
After reviewing all configurations, you can proceed with creating the Aurora cluster. The image below shows the "Create Database" button you can click to initiate the creation process.
The provisioning process may take several minutes, depending on the selected instance size and network settings.
> If you are new to AWS services, reviewing the AWS Cloud Technology and Services course can help you understand key AWS concepts relevant to Aurora setup.
Security is critical to managing an Aurora database, and AWS provides multiple tools to enforce strong access controls.
> For a deeper dive into securing AWS environments, have a look at the AWS Security and Cost Management course. If you want to learn more about how IAM works and how to implement it effectively, have a look at this guide on AWS Identity and Access Management (IAM).
Connecting to AWS Aurora is essential for interacting with the database. You can do this either through client tools or applications. Let’s see how in this section!
Once the Aurora database is up and running, you need to establish a connection to begin interacting with the database.
For Aurora MySQL, common database clients such as MySQL Workbench and HeidiSQL can be used to connect. Alternatively, you could use command-line interfaces.
The connection requires specifying the database endpoint, which can be found in the AWS Management Console.
Using the MySQL CLI, the connection can be established with the following command:
mysql -h your-cluster-endpoint -u admin -pAfter entering the master password, you should be able to execute SQL queries, create tables, and manage data.
For Aurora PostgreSQL, you can connect using tools such as pgAdmin or the PostgreSQL command-line interface (psql).
The connection command in psql follows this format:
psql -h your-cluster-endpoint -U admin -d yourdatabasenameJust like with MySQL, the correct credentials must be entered to access the database.
Once you have gained access, you should be able to execute SQL queries, create tables, and manage data.
Applications that need to interact with Aurora must be configured with appropriate database connection strings. Usually, these connection strings consist of the username, password, port number, and endpoint.
It is recommended that you use connection pooling to optimize performance and reduce the overhead of establishing new connections for every request.
Popular libraries such as SQLAlchemy for Python or JDBC for Java provide efficient ways to manage connections in an application environment.
Effectively managing AWS Aurora involves ensuring data protection, monitoring performance, and scaling resources as needed. In this section, we will review these practices.
AWS Aurora offers automated backups that continuously capture and store database changes in Amazon S3. These backups are retained based on user-defined settings, allowing restoration to any point within the retention period.
In addition to automated backups, you can also create manual snapshots that persist beyond the retention window. Manual snapshots are particularly useful for long-term archival or before performing major database updates.
When I worked on a project with a critical application, we scheduled automated backups every two hours. However, before making any changes or updates to the application, we would manually create a backup to ensure we could roll back if needed. This demonstrates how both automated and manual backups can be effectively used together.
The image below shows how AWS Backup can be used for disaster recovery with Amazon Aurora.
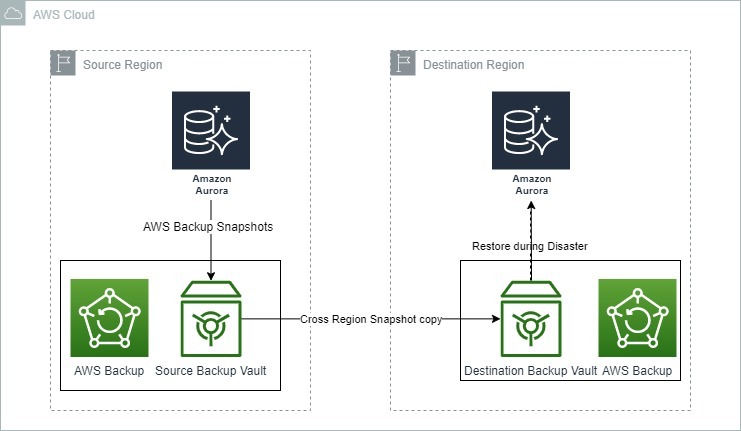
Backup and recovery options for Amazon Aurora. Source: AWS Blogs
Performance monitoring is essential for maintaining a healthy database.
AWS CloudWatch provides real-time metrics that track CPU utilization, memory usage, disk I/O, and network traffic.
Setting up CloudWatch Alarms can help administrators be notified when performance thresholds are exceeded, allowing proactive database management.
In addition to this, AWS Performance Insights offers detailed query analysis to identify and optimize slow-running queries.
The image below demonstrates how AWS Performance Insights provides insights into database performance.
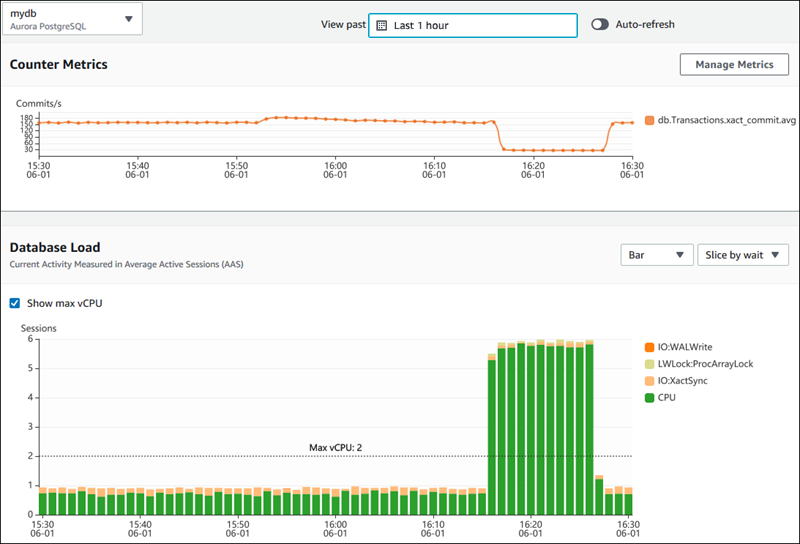
AWS Performance Insights dashboard displaying database performance metrics. Source: AWS Docs
Aurora is designed to scale automatically by adjusting storage capacity as needed. However, compute resources such as CPUs and memory may need to be manually adjusted depending on the workload.
Aurora provides options for scaling read capacity by adding read replicas, which distribute read traffic and improve performance.
When high availability is critical, an Aurora cluster can be configured with multiple replicas across different Availability Zones to ensure failover redundancy.
Optimizing performance in Amazon Aurora ensures efficient query execution and scalability. Let’s go over some best practices in this section.
Optimizing query performance in Amazon Aurora is crucial for maintaining a high-performing database.
EXPLAIN or EXPLAIN ANALYZE in SQL queries helps identify bottlenecks and provides insight into execution plans. SELECT * (which retrieves unnecessary data), normalizing database schema to reduce redundancy, and leveraging partitioning strategies can lead to performance gains.To handle high-traffic loads, Amazon Aurora supports read replicas that help distribute read-intensive queries across multiple instances.
Read replicas reduce the burden on the primary database instance by processing read requests separately, which improves responsiveness and lowers latency.
To set up an Aurora read replica, you will need to select an existing Aurora cluster and enable replication with minimal configuration. Aurora automatically synchronizes data between the primary instance and its replicas, ensuring data consistency without manual intervention.
Aurora’s replication mechanism is highly efficient, allowing near real-time data synchronization with a replication lag of less than a second.
Applications that perform frequent read operations, such as reporting dashboards or analytics services, can benefit significantly from read replicas by directing read-heavy queries to these instances.
In case of a primary instance failure, a read replica can be promoted to become the new primary instance with minimal downtime, ensuring high availability and business continuity.
The image below shows how cross-region Aurora replicas can help with disaster recovery and high availability.
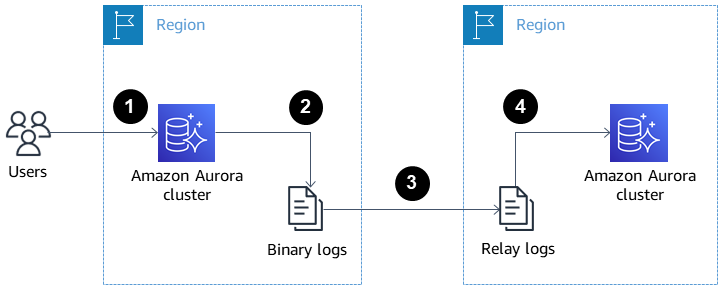
Cross-region Aurora read replicas for disaster recovery and high availability. Source: AWS Docs
Caching is a powerful technique to enhance database performance by reducing direct query loads on Aurora. A caching layer can significantly speed up data retrieval for frequently accessed queries.
Amazon ElastiCache, which supports Redis and Memcached, is commonly used alongside Aurora to store query results and prevent redundant database queries.
Integrating caching into an application architecture can help improve response times while preserving database compute resources.
Caching strategies such as write-through caching (where data is written to both the cache and Aurora simultaneously) and lazy loading (where data is only cached when requested) help optimize performance based on usage patterns.
Configuring an appropriate time-to-live (TTL) for cached data ensures that the cache remains fresh and prevents stale data retrieval.
Securing your Aurora database is crucial for protecting sensitive data and ensuring compliance. Let’s review best practices in this section.
Data security is fundamental to database management, and AWS Aurora provides robust encryption mechanisms to protect sensitive data.
These encryption measures can help you comply with security best practices and regulatory requirements.
The image below demonstrates how AWS KMS integrates with Amazon Aurora to encrypt your database.
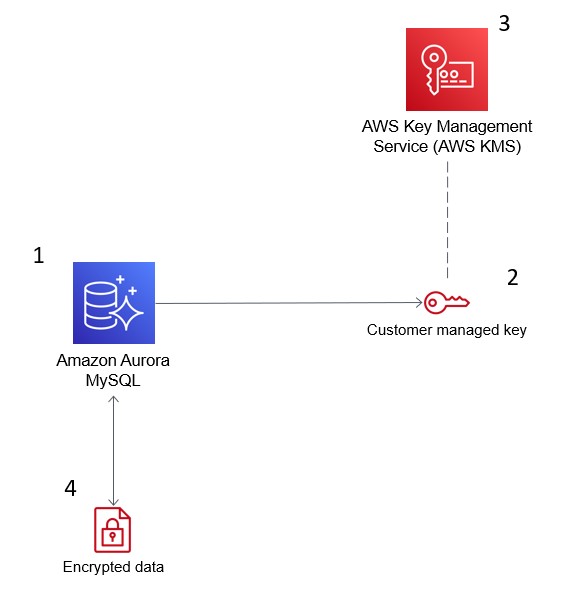
AWS Key Management Service (KMS) encrypts data in Amazon Aurora for security compliance. Source: AWS Blogs
Access control in Aurora is managed through AWS IAM, which allows administrators to define fine-grained permissions based on user roles.
You should enforce the least privilege access principles, which minimize security risks and maintain strict control over database access.
The image below shows how IAM authentication can be configured to secure Amazon Aurora PostgreSQL database access.
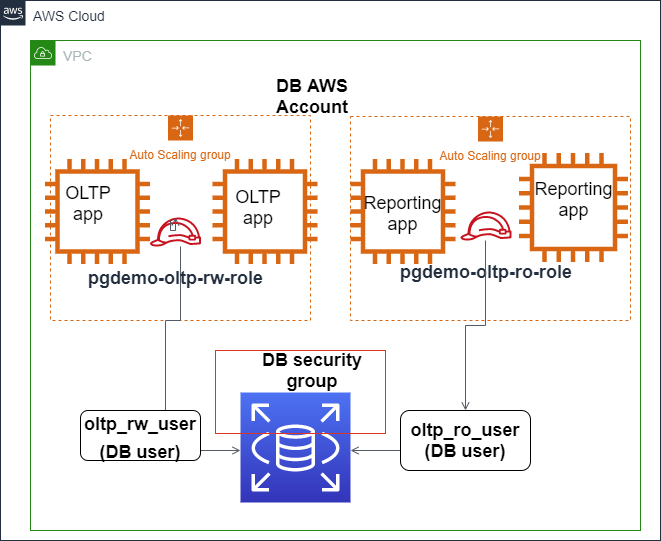
IAM authentication integrates with Amazon Aurora PostgreSQL. Source: AWS Blogs
Monitoring and auditing database activity is essential for security compliance and troubleshooting.
Aurora provides several logging mechanisms, including error logs, slow query logs, and general logs, which help administrators track database activity and identify potential issues. These logs can be enabled through the AWS Management Console and stored in Amazon CloudWatch for centralized analysis.
Analyzing these logs can help administrators optimize query execution, detect unauthorized access attempts, and ensure database stability.
To effectively manage and optimize costs in Amazon Aurora, you must understand its pricing structure. Let’s review it!
Amazon Aurora’s pricing model is based on several factors, including instance hours, storage consumption, I/O requests, and data transfer.
Unlike traditional databases that require upfront infrastructure provisioning, Aurora’s pay-as-you-go model allows businesses to pay only for the resources they consume.
Compute instances are billed based on the instance class and uptime, while storage is dynamically scaled, eliminating the need for manual adjustments.
The image below provides a breakdown of the different pricing components for Amazon Aurora. However, keep in mind that pricing can change, so it is always best to refer to the Aurora pricing page for the most up-to-date information.
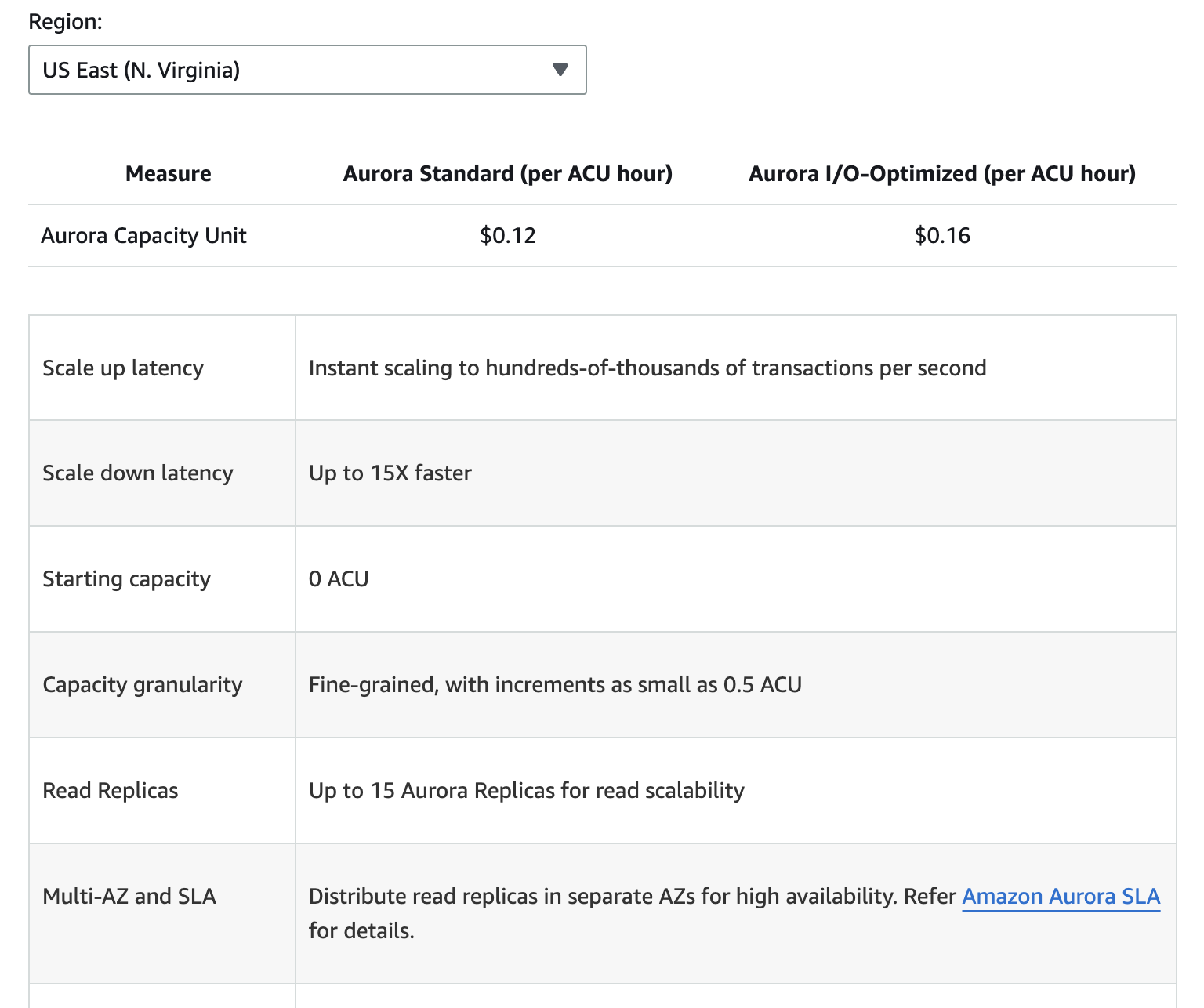
Additional costs include backup storage beyond the allocated free tier, reading and writing I/O requests, and data transfer fees for cross-region replication.
Understanding these pricing components can help you forecast expenses and make informed decisions regarding database usage.
To manage costs effectively, organizations can implement several optimization strategies.
Selecting the appropriate instance size will ensure that database resources align with workload demands without overprovisioning.
> If you want to gain more insight into cost management, refer to AWS Security and Cost Management course.
After working with Amazon Aurora across multiple companies for quite some time, I can confidently say it is a powerful and scalable database solution that makes management easier without compromising performance—you will likely agree after going through this tutorial.
Aurora is worth considering if you are looking for a cloud-native relational database that supports MySQL and PostgreSQL while reducing operational overhead. It has been revolutionary in some of my projects, and I highly recommend looking into its capabilities if you are working with AWS databases.
If you are new to AWS databases, learning fundamental concepts through courses like AWS Cloud Practitioner (CLF-C02) can be beneficial!
Learn more about AWS with these courses!
Track
Course
Course
blog
Vikash Singh
11 min
Tutorial
Don Kaluarachchi
Tutorial
Tim Lu
Tutorial
Joleen Bothma
Tutorial
Anneleen Rummens
Tutorial
Florin Angelescu