
Programa
Profissional de nuvem da AWS (CLF-C02)
10 h
Tendo usado o Amazon Aurora por algum tempo em várias empresas, vi em primeira mão como ele se destaca como um mecanismo de banco de dados relacional totalmente gerenciado, oferecendo alto desempenho, escalabilidade e confiabilidade.
Como uma solução nativa da nuvem que suporta MySQL e PostgreSQL, o Aurora é uma excelente opção para empresas que exigem alta disponibilidade e dimensionamento automático. Como o AWS gerencia backups, failover e replicação automaticamente, o uso do Aurora permite que você aumente a eficiência do banco de dados e reduza os custos de manutenção.
Neste tutorial, orientarei você na configuração de uma instância do Aurora, gerenciando-a com eficiência, otimizando o desempenho e garantindo a segurança e a relação custo-benefício.
O Amazon Aurora é um banco de dados relacional baseado em nuvem que supera o desempenho do MySQL e do PostgreSQL tradicionais, dimensionando dinamicamente os recursos de armazenamento e computação.
De acordo com a AWS, o Aurora pode oferecer até cinco vezes ataxa de transferência do MySQL padrão e três vezes o desempenho do PostgreSQL padrão, devido à sua arquitetura distribuída e altamente disponível.
O Aurora foi desenvolvido com recursos como backups automatizados, réplicas de leitura para dimensionamento horizontal e mecanismos de failover que garantem o mínimo de tempo de inatividade.
A camada de armazenamento do Aurora foi projetada para ser tolerante a falhas e autorrecuperável.
Além disso, os dados são replicados automaticamente em várias zonas de disponibilidade (AZs) para garantir a durabilidade.
A imagem abaixo fornece uma visão geral de alto nível da arquitetura e dos principais recursos do Amazon Aurora.
A relação entre o volume do cluster, a instância de BD do gravador e as instâncias de BD do leitor em um cluster do Aurora. Portanto,urce: Documentos da AWS
O mecanismo de banco de dados monitora continuamente as consultas e otimiza os planos de execução, o que leva a melhorias significativas na eficiência.
Um dos principais benefícios do Aurora é sua compatibilidade com os bancos de dadosMySQLe PostgreSQLexistentes, o que facilita a migração das empresas sem a necessidade de modificar extensivamente seus aplicativos.
A estrutura de custos da Aurora também é atraente. Ele cobra com base no uso real dos recursos de computação e armazenamento. Esse modelo de custo elimina a necessidade de provisionamento excessivo da infraestrutura, o que, por sua vez, economiza dinheiro.
> Se você estiver interessado em uma compreensão mais ampla das opções de armazenamento do AWS, confira estevocê pode conferir este tutorial de armazenamento da AWS.
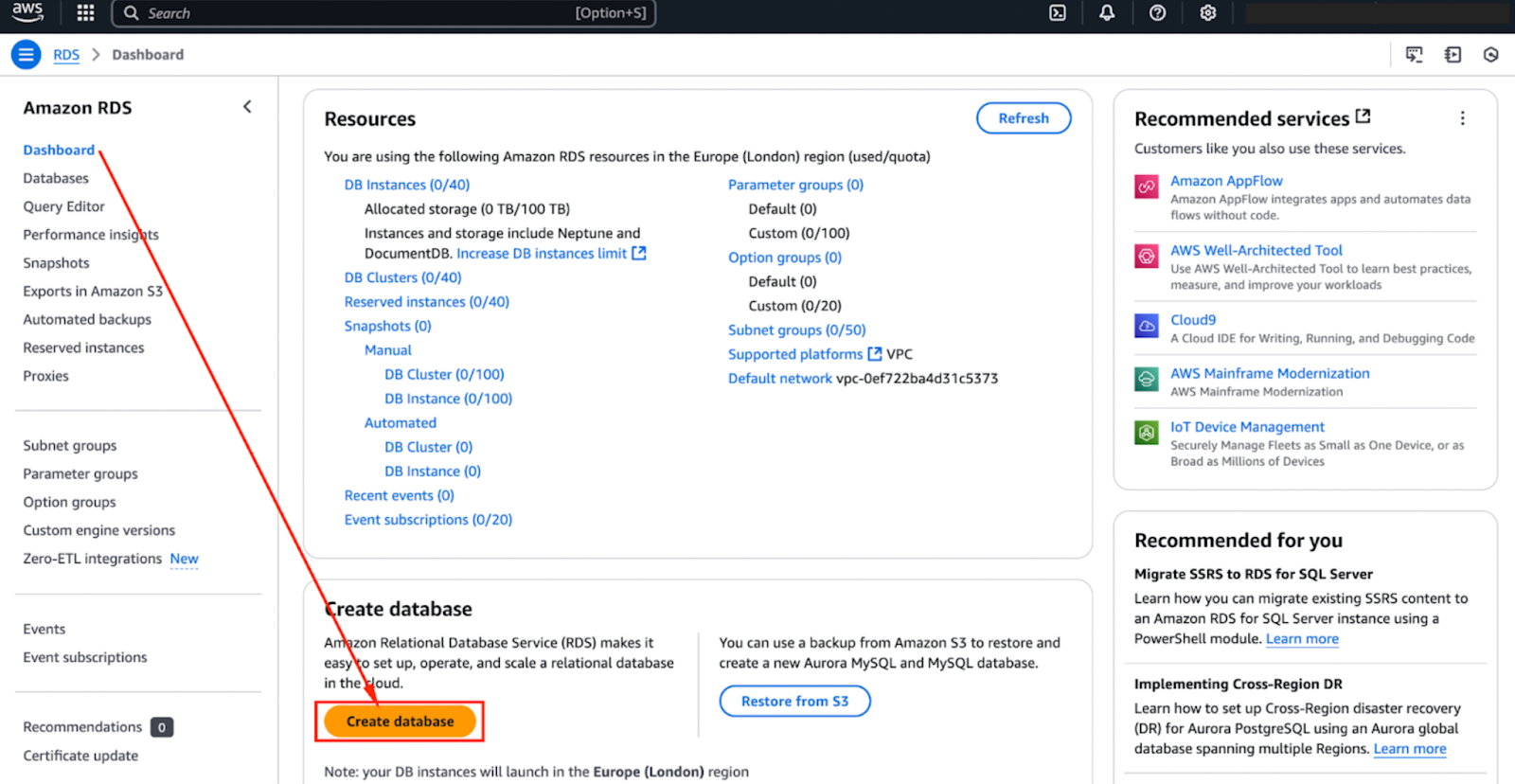
A configuração do AWS Aurora envolve a criação de um cluster de banco de dados, a definição de configurações de segurança e a garantia de acesso adequado à rede. Vamos fazer isso nesta seção!
> Se você for novo na AWS, considere a possibilidade de revisar os tópicos básicos com oo curso Introdução ao AWS antes de você se aprofundar no Aurora.
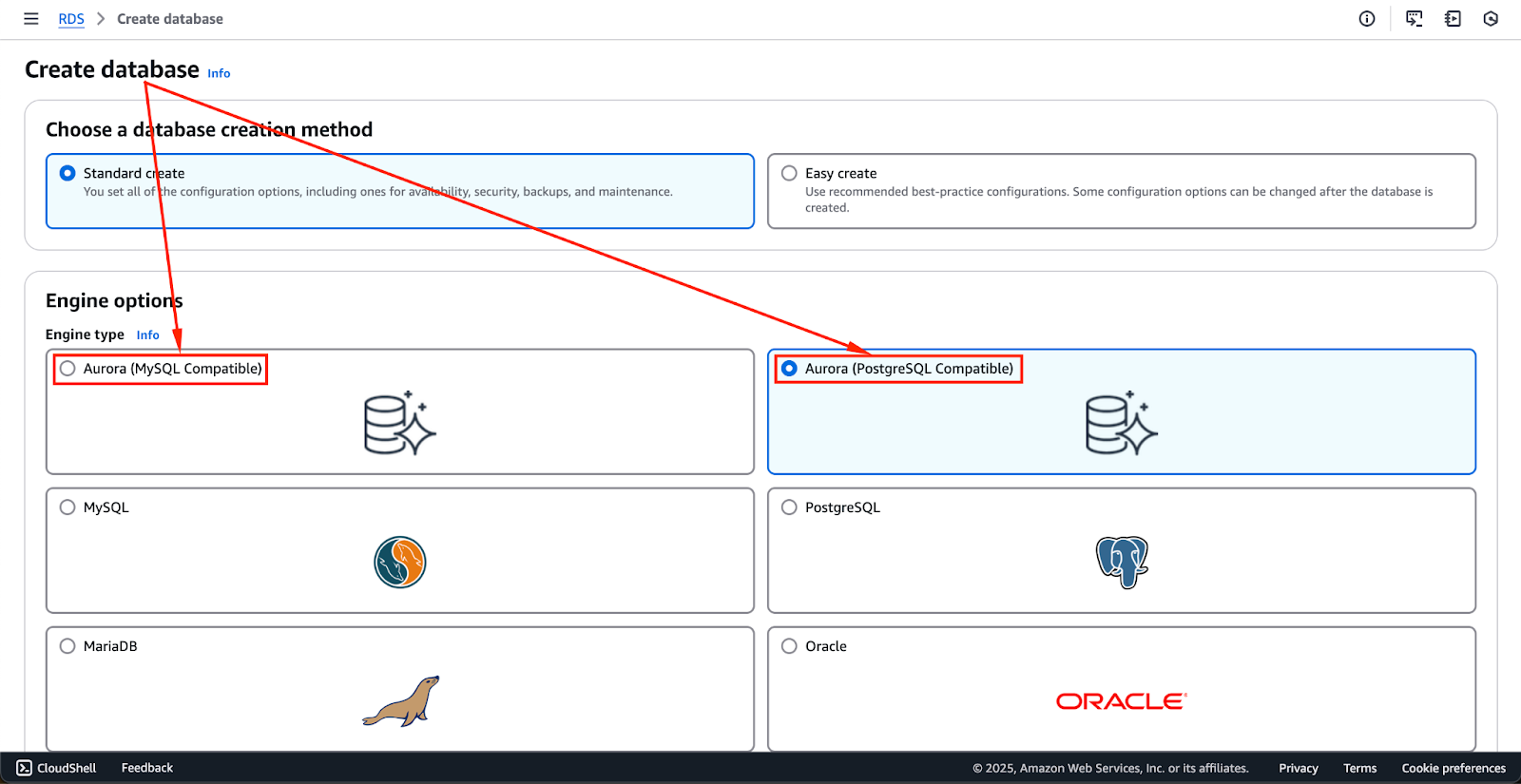
A configuração de um cluster de banco de dados do Aurora requer algumas etapas importantes, incluindo a seleção do mecanismo de banco de dados apropriado, a configuração das definições de segurança e a definição das especificações da instância.
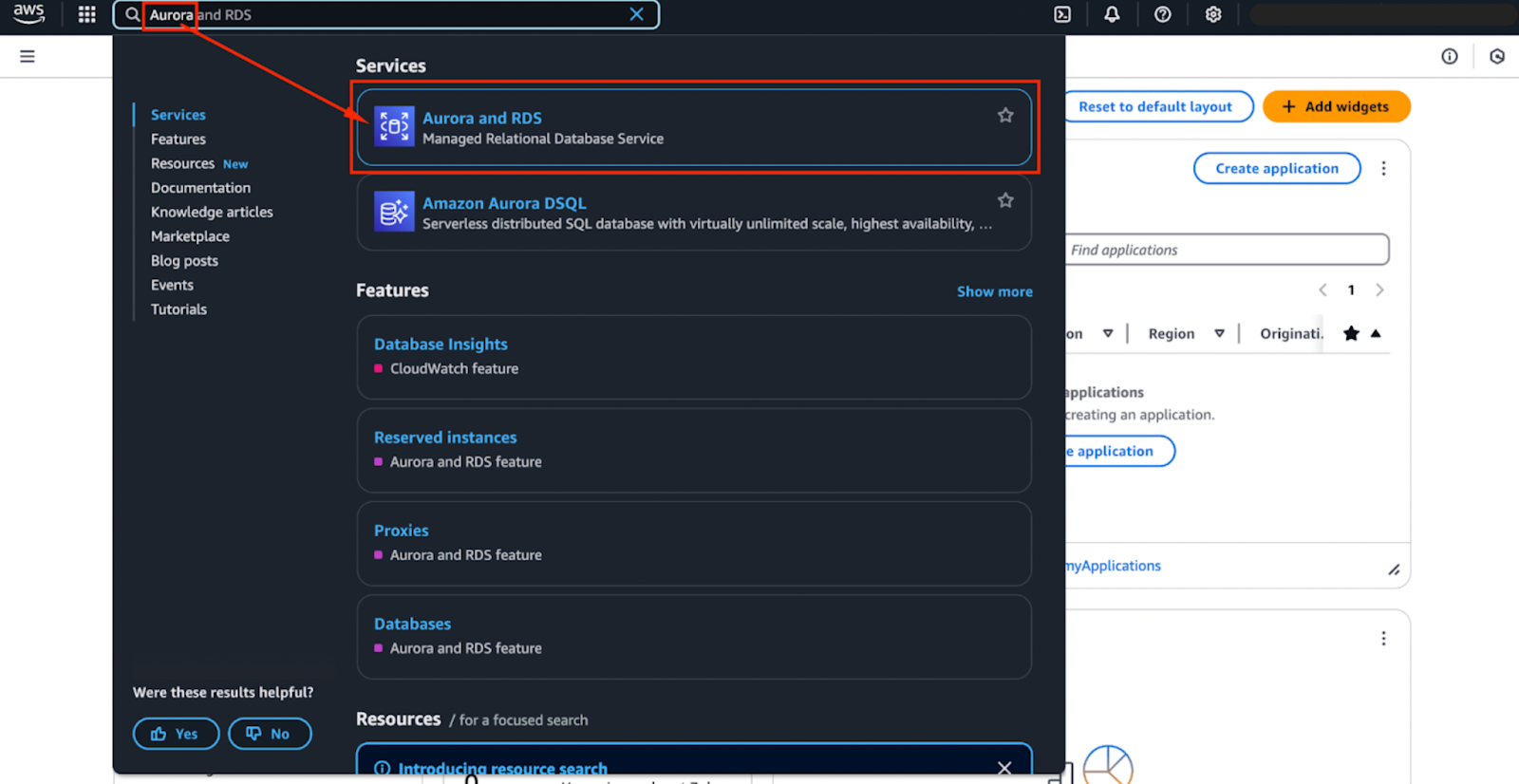
A imagem abaixo mostra as opções de motor que estão disponíveis no momento. Isso pode mudar no futuro, mas as duas primeiras opções - Aurora (compatível com MySQL) e Aurora (compatível com PostgreSQL) - são os mecanismos Aurora.
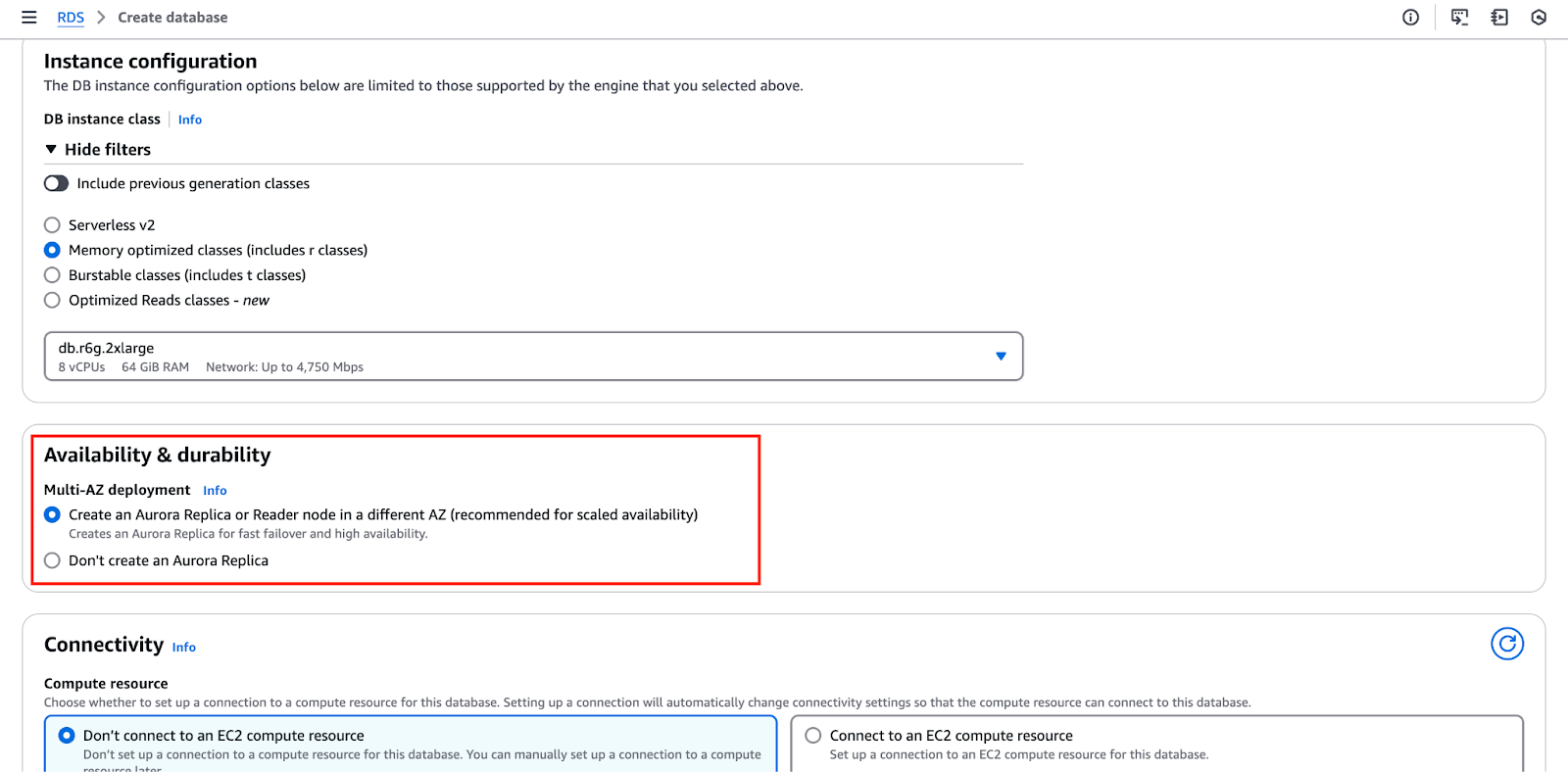
A imagem abaixo destaca a "Disponibilidade e durabilidade" na qual você pode definir essas configurações.
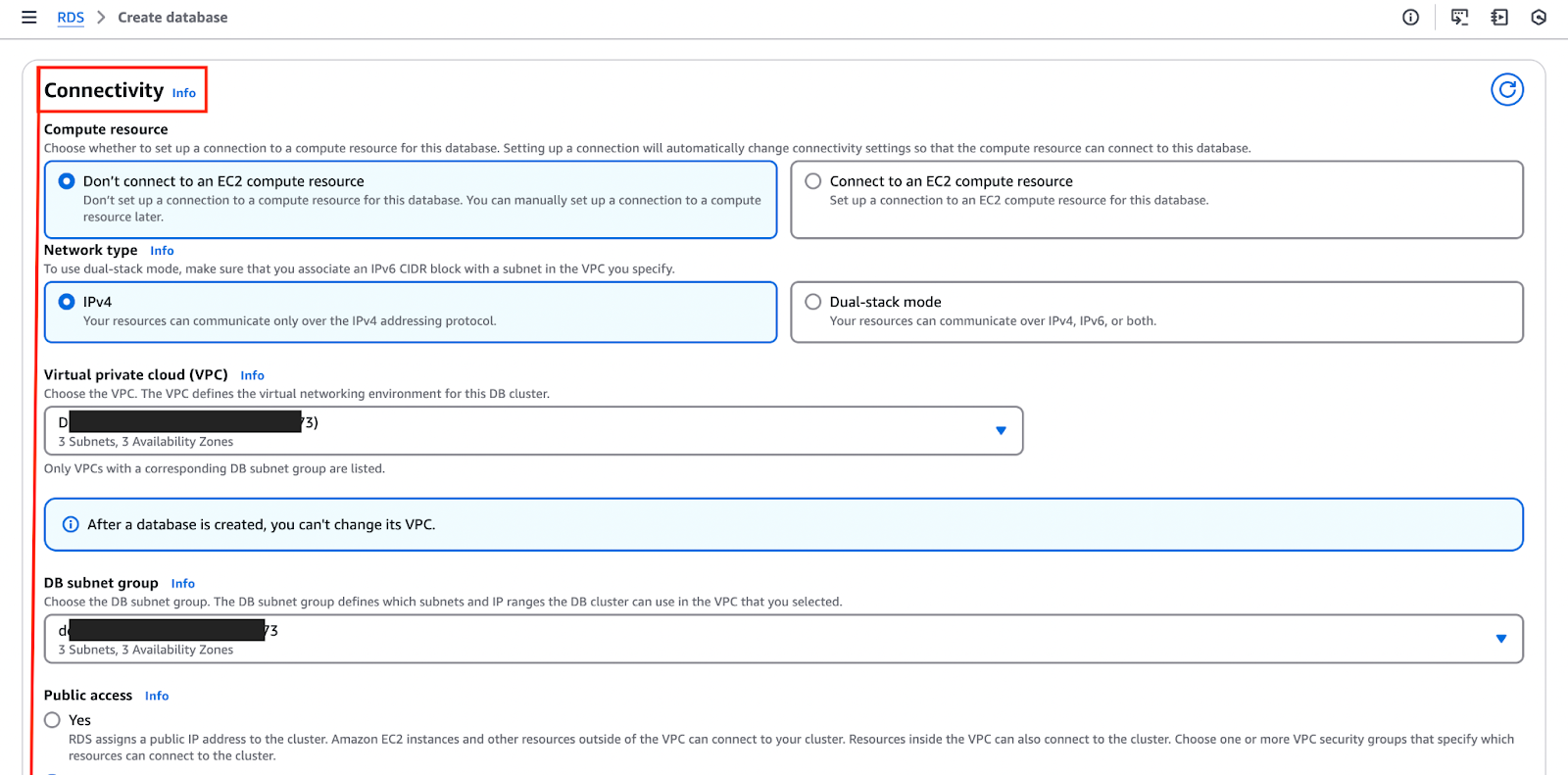
A imagem abaixo destaca a seção "Conectividade" na qual você pode definir e personalizar essas configurações.
Depois de revisar todas as configurações, você pode prosseguir com a criação do cluster do Aurora. A imagem abaixo mostra o botão "Create Database" (Criar banco de dados) no qual você pode clicar para iniciar o processo de criação.
O processo de provisionamento pode levar vários minutos, dependendo do tamanho da instância selecionada e das configurações de rede.
> Se você for novo nos serviços da AWS, revise ovocê pode entender os principais conceitos da AWS relevantes para a configuração do Aurora.pode ajudar você a entender os principais conceitos do AWS relevantes para a configuração do Aurora.
A segurança é fundamental para o gerenciamento de um banco de dados Aurora, e o AWS fornece várias ferramentas para aplicar controles de acesso fortes.
> Para se aprofundar na proteção de ambientes AWS, dê uma olhada emno curso AWS Security and Cost Management. Se você quiser saber mais sobre como o IAM funciona e como implementá-lo de forma eficaz, dê uma olhada este guia sobre o AWS Identity and Access Management (IAM).
A conexão com o AWS Aurora é essencial para que você possa interagir com o banco de dados. Você pode fazer isso por meio de ferramentas ou aplicativos do cliente. Vamos ver como nesta seção!
Quando o banco de dados do Aurora estiver em funcionamento, você precisará estabelecer uma conexão para começar a interagir com o banco de dados.
Para o Aurora MySQL, você pode usar clientes de banco de dados comuns, como o MySQL Workbench e o HeidiSQL, para se conectar. Como alternativa, você pode usar interfaces de linha de comando.
A conexão requer a especificação do endpoint do banco de dados, que pode ser encontrado no AWS Management Console.
Usando a CLI do MySQL, a conexão pode ser estabelecida com o seguinte comando:
mysql -h your-cluster-endpoint -u admin -pDepois de inserir a senha mestre, você poderá executar consultas SQL, criar tabelas e gerenciar dados.
Para o Aurora PostgreSQL, você pode se conectar usando ferramentas como o pgAdmin ou a interface de linha de comando do PostgreSQL (psql).
O comando de conexão no psql segue este formato:
psql -h your-cluster-endpoint -U admin -d yourdatabasenameAssim como no MySQL, as credenciais corretas devem ser inseridas para que você possa acessar o banco de dados.
Depois de obter acesso, você deverá ser capaz de executar consultas SQL, criar tabelas e gerenciar dados.
Os aplicativos que precisam interagir com o Aurora devem ser configurados com as cadeias de conexão de banco de dados apropriadas. Normalmente, essas cadeias de conexão consistem no nome de usuário, na senha, no número da porta e no ponto de extremidade.
É recomendável que você use o pooling de conexões para otimizar o desempenho e reduzir a sobrecarga de estabelecer novas conexões para cada solicitação.
Bibliotecas populares, como SQLAlchemy para Python ou JDBC para Java, fornecem maneiras eficientes de gerenciar conexões em um ambiente de aplicativo.
O gerenciamento eficaz do AWS Aurora envolve garantir a proteção dos dados, monitorar o desempenho e dimensionar os recursos conforme necessário. Nesta seção, analisaremos essas práticas.
O AWS Aurora oferece backups automatizados que capturam e armazenam continuamente as alterações do banco de dados no Amazon S3. Esses backups são retidos com base em configurações definidas pelo usuário, permitindo a restauração para qualquer ponto dentro do período de retenção.
Além dos backups automatizados, você também pode criar instantâneos manuais que persistem além da janela de retenção. Os instantâneos manuais são particularmente úteis para arquivamento de longo prazo ou antes de realizar atualizações importantes no banco de dados.
Quando trabalhei em um projeto com um aplicativo essencial, programamos backups automatizados a cada duas horas. No entanto, antes de fazer qualquer alteração ou atualização no aplicativo, criávamos manualmente um backup para garantir que pudéssemos reverter a situação, se necessário. Isso demonstra como os backups automatizados e manuais podem ser usados juntos de forma eficaz.
A imagem abaixo mostra como o AWS Backup pode ser usado para recuperação de desastres com o Amazon Aurora.
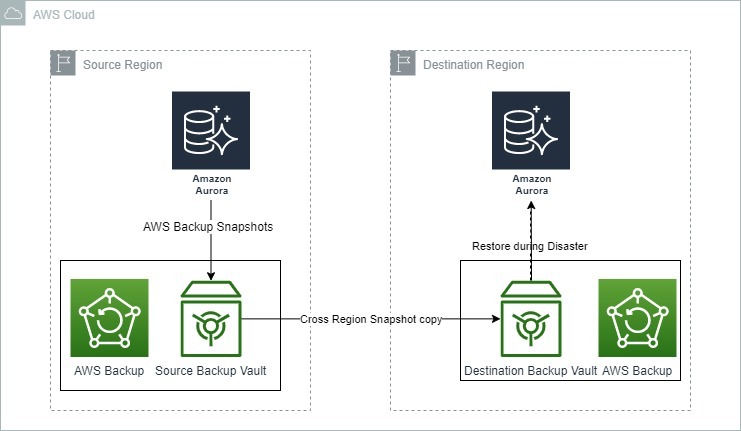
Opções de backup e recuperação para o Amazon Aurora. Fonte: Blogs da AWS
O monitoramento do desempenho é essencial para manter um banco de dados saudável.
O AWS CloudWatch fornece métricas em tempo real que rastreiam a utilização da CPU, o uso da memória, a E/S do disco e o tráfego de rede.
A configuração do CloudWatch Alarms pode ajudar os administradores a serem notificados quando os limites de desempenho forem excedidos, permitindo o gerenciamento proativo do banco de dados.
Além disso, o AWS Performance Insights oferece análise detalhada de consultas para identificar e otimizar as consultas de execução lenta.
A imagem abaixo demonstra como o AWS Performance Insights fornece insights sobre o desempenho do banco de dados.
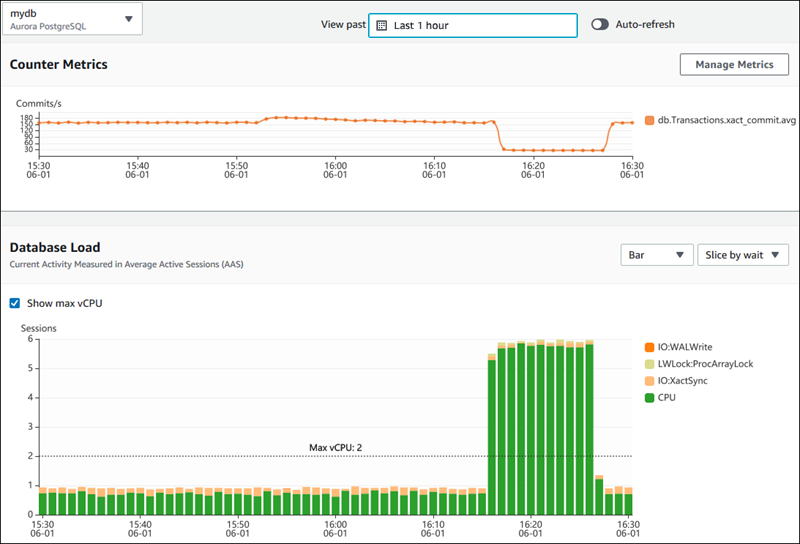
Painel do AWS Performance Insights que exibe métricas de desempenho do banco de dados. Fonte: Documentos da AWS
O Aurora foi projetado para ser dimensionado automaticamente, ajustando a capacidade de armazenamento conforme necessário. No entanto, os recursos de computação, como CPUs e memória, podem precisar ser ajustados manualmente, dependendo da carga de trabalho.
O Aurora oferece opções para dimensionar a capacidade de leitura adicionando réplicas de leitura, que distribuem o tráfego de leitura e melhoram o desempenho.
Quando a alta disponibilidade é essencial, um cluster do Aurora pode ser configurado com várias réplicas em diferentes zonas de disponibilidade para garantir a redundância de failover.
A otimização do desempenho no Amazon Aurora garante a execução eficiente de consultas e a escalabilidade. Vamos examinar algumas práticas recomendadas nesta seção.
A otimização do desempenho das consultas no Amazon Aurora é fundamental para manter um banco de dados de alto desempenho.
EXPLAIN or EXPLAIN ANALYZE em consultas SQL ajuda a identificar gargalos e fornece informações sobre os planos de execução . SELECT * (que recupera dados desnecessários), normalizar o esquema do banco de dados para reduzir a redundância e aproveitar as estratégias de particionamento podem levar a ganhos de desempenho.Para lidar com cargas de alto tráfego, o Amazon Aurora suporta réplicas de leitura que ajudam a distribuir consultas de leitura intensiva em várias instâncias.
As réplicas de leitura reduzem a carga sobre a instância primária do banco de dados, processando as solicitações de leitura separadamente, o que melhora a capacidade de resposta e diminui a latência.
Para configurar uma réplica de leitura do Aurora, você precisará selecionar um cluster do Aurora existente e ativar a replicação com configuração mínima. O Aurora sincroniza automaticamente os dados entre a instância primária e suas réplicas, garantindo a consistência dos dados sem intervenção manual.
O mecanismo de replicação do Aurora é altamente eficiente, permitindo a sincronização de dados quase em tempo real com um atraso de replicação de menos de um segundo.
Os aplicativos que realizam operações de leitura frequentes, como painéis de relatórios ou serviços de análise, podem se beneficiar significativamente das réplicas de leitura, direcionando as consultas de leitura pesada para essas instâncias.
Em caso de falha de uma instância primária, uma réplica de leitura pode ser promovida para se tornar a nova instância primária com o mínimo de tempo de inatividade, garantindo alta disponibilidade e continuidade dos negócios.
A imagem abaixo mostra como as réplicas do Aurora entre regiões podem ajudar na recuperação de desastres e na alta disponibilidade.
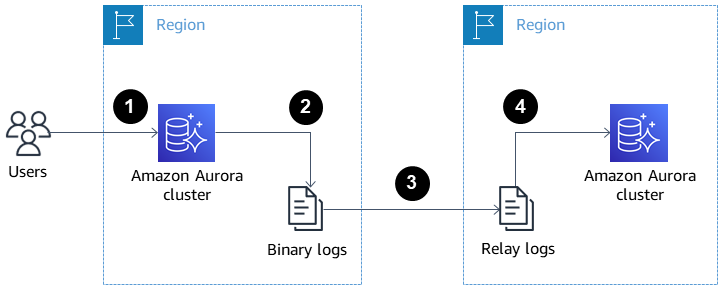
Réplicas de leitura Aurora entre regiões para recuperação de desastres e alta disponibilidade. Fonte: Documentos da AWS
O armazenamento em cache é uma técnica poderosa para melhorar o desempenho do banco de dados, reduzindo as cargas de consulta direta no Aurora. Uma camada de cache pode acelerar significativamente a recuperação de dados para consultas acessadas com frequência.
O Amazon ElastiCache, que suporta Redis e Memcached, é comumente usado junto com o Aurora para armazenar resultados de consultas e evitar consultas redundantes ao banco de dados.
A integração do cache à arquitetura de um aplicativo pode ajudar a melhorar os tempos de resposta e, ao mesmo tempo, preservar os recursos de computação do banco de dados.
As estratégias de cache, como o cache write-through (em que os dados são gravados no cache e no Aurora simultaneamente) e o lazy loading (em que os dados são armazenados em cache somente quando solicitados), ajudam a otimizar o desempenho com base nos padrões de uso.
A configuração de um tempo de vida útil (TTL) adequado para os dados em cache garante que o cache permaneça atualizado e evita a recuperação de dados obsoletos.
A segurança do banco de dados do Aurora é fundamental para proteger dados confidenciais e garantir a conformidade. Vamos analisar as práticas recomendadas nesta seção.
A segurança dos dados é fundamental para o gerenciamento de bancos de dados, e o AWS Aurora oferece mecanismos de criptografia robustos para proteger dados confidenciais.
Essas medidas de criptografia podem ajudar você a cumprir as práticas recomendadas de segurança e os requisitos regulamentares.
A imagem abaixo demonstra como o AWS KMS se integra ao Amazon Aurora para criptografar seu banco de dados.
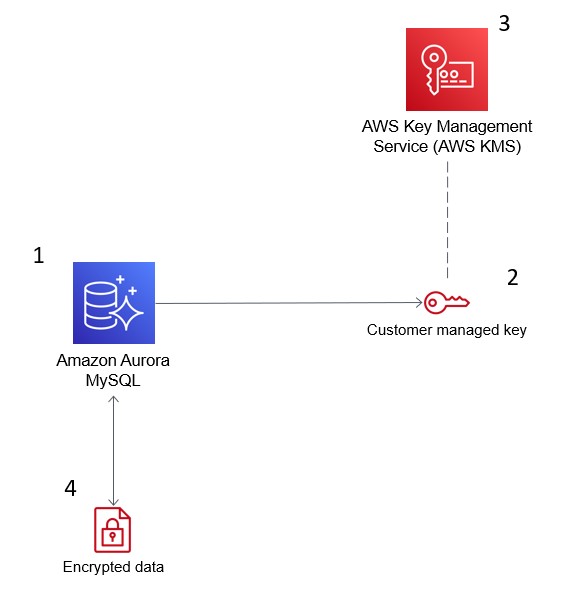
O AWS Key Management Service (KMS) criptografa os dados no Amazon Aurora para conformidade com a segurança. Fonte: Blogs da AWS
O controle de acesso no Aurora é gerenciado pelo AWS IAM, que permite que os administradores definam permissões refinadas com base nas funções do usuário.
Você deve aplicar os princípios de acesso com privilégios mínimos, que minimizam os riscos de segurança e mantêm um controle rigoroso sobre o acesso ao banco de dados.
A imagem abaixo mostra como a autenticação IAM pode ser configurada para proteger o acesso ao banco de dados PostgreSQL do Amazon Aurora.
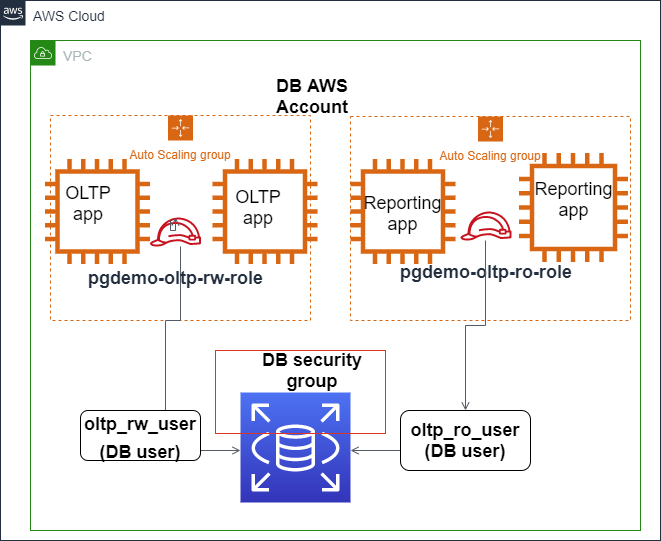
A autenticação IAM se integra ao Amazon Aurora PostgreSQL. Fontee: Blogs da AWS
O monitoramento e a auditoria da atividade do banco de dados são essenciais para a conformidade com a segurança e a solução de problemas.
O programa Aurora fornece vários mecanismos de registro, incluindo registros de erros, registros de consultas lentas e registros gerais, que ajudam os administradores a rastrear a atividade do banco de dados e identificar possíveis problemas. Esses registros podem ser ativados por meio do console de gerenciamento do AWS e armazenados no Amazon CloudWatch para análise centralizada.
A análise desses logs pode ajudar os administradores a otimizar a execução de consultas, detectar tentativas de acesso não autorizado e garantir a estabilidade do banco de dados.
Para gerenciar e otimizar efetivamente os custos na Amazon Aurora, você deve entender sua estrutura de preços. Vamos revisar!
O modelo de preços do Amazon Aurora baseia-se em vários fatores, incluindo horas de instância, consumo de armazenamento, solicitações de E/S e transferência de dados.
Ao contrário dos bancos de dados tradicionais que exigem provisionamento inicial da infraestrutura, o modelo de pagamento conforme o uso do Aurora permite que as empresas paguem apenas pelos recursos que consomem.
As instâncias de computação são cobradas com base na classe da instância e no tempo de atividade, enquanto o armazenamento é dimensionado dinamicamente, eliminando a necessidade de ajustes manuais.
A imagem abaixo fornece um detalhamento dos diferentes componentes de preço do Amazon Aurora. No entanto, lembre-se de que os preços podem mudar, portanto, é sempre melhor você acessar a página de preços da Aurora para obter as informações mais atualizadas.
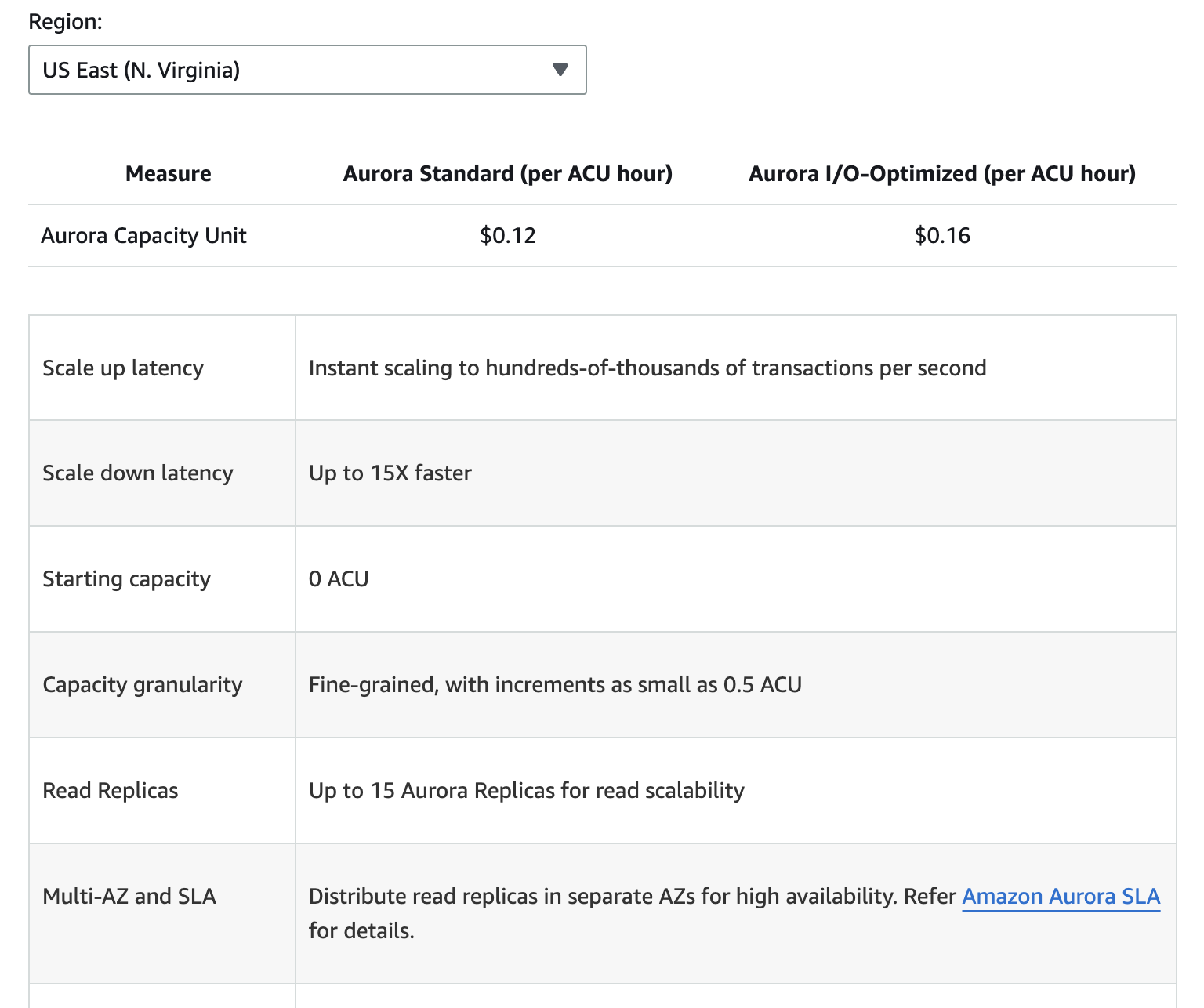
Os custos adicionais incluem armazenamento de backup além da camada gratuita alocada, solicitações de E/S de leitura e gravação e taxas de transferência de dados para replicação entre regiões.
A compreensão desses componentes de preço pode ajudar você a prever despesas e tomar decisões informadas sobre o uso do banco de dados.
Para gerenciar os custos de forma eficaz, as organizações podem implementar várias estratégias de otimização.
A seleção do tamanho adequado da instância garantirá que os recursos do banco de dados estejam alinhados com as demandas de carga de trabalho sem excesso de provisionamento.
> Se você quiser obter mais informações sobre o gerenciamento de custos, referir-se ao curso AWS Security and Cost Management.
Depois de trabalhar com o Amazon Aurora em várias empresas por um bom tempo, posso dizer com confiança que é uma solução de banco de dados poderosa e escalável que facilita o gerenciamento sem comprometer o desempenho - você provavelmente concordará depois de ler este tutorial.
Vale a pena considerar o Aurora se você estiver procurando um banco de dados relacional nativo da nuvem que suporte MySQL e PostgreSQL e, ao mesmo tempo, reduza a sobrecarga operacional. Ele tem sido revolucionário em alguns dos meus projetos, e recomendo fortemente que você analise seus recursos se estiver trabalhando com bancos de dados da AWS.
Se você é novo nos bancos de dados da AWS, aprender os conceitos fundamentais por meio de cursoscomo o AWS Cloud Practitioner (CLF-C02) pode ser benéfico!
Saiba mais sobre a AWS com estes cursos!
Programa
Curso
Curso
blog
Srujana Maddula
13 min
Tutorial
Tim Lu
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev