
Cursus
AWS Cloud Practitioner (CLF-C02)
10 h
Ayant utilisé Amazon Aurora pendant un certain temps dans diverses entreprises, j'ai pu constater de première main qu'il excelle en tant que moteur de base de données relationnelle entièrement géré, offrant de hautes performances, une grande évolutivité et une grande fiabilité.
En tant que solution cloud native prenant en charge MySQL et PostgreSQL, Aurora est un excellent choix pour les entreprises qui ont besoin d'une haute disponibilité et d'une mise à l'échelle automatique. Comme AWS gère automatiquement les sauvegardes, le basculement et la réplication, l'utilisation d'Aurora vous permet d'accroître l'efficacité de la base de données tout en réduisant les coûts de maintenance.
Dans ce tutoriel, je vous guiderai dans la mise en place d'une instance Aurora, sa gestion efficace, l'optimisation des performances et la garantie de la sécurité et de la rentabilité.
Amazon Aurora est une base de données relationnelle basée sur le cloud qui surpasse les bases traditionnelles MySQL et PostgreSQL grâce à une mise à l'échelle dynamique des ressources de stockage et de calcul.
Selon AWS, Aurora peut fournir undébit jusqu' à cinq fois supérieur àcelui de MySQL et trois fois supérieur à celui de PostgreSQL, grâce à son architecture distribuée et hautement disponible.
Aurora est doté de fonctionnalités telles que les sauvegardes automatisées, les répliques en lecture pour la mise à l'échelle horizontale et les mécanismes de basculement qui garantissent un temps d'arrêt minimal.
La couche de stockage d'Aurora est conçue pour être tolérante aux pannes et s'auto-réparer.
En outre, les données sont automatiquement répliquées sur plusieurs zones de disponibilité (AZ) afin de garantir leur durabilité.
L'image ci-dessous donne une vue d'ensemble de l'architecture et des principales caractéristiques d'Amazon Aurora.
La relation entre le volume du cluster, l'instance de la base de données de l'auteur et les instances de la base de données du lecteur dans un cluster Aurora. Doncurce : Documents AWS
Le moteur de base de données surveille en permanence les requêtes et optimise les plans d'exécution, ce qui permet d'améliorer considérablement l'efficacité.
L'un des principaux avantages d'Aurora est sa compatibilité avec les bases de donnéesMySQLet PostgreSQLexistantes, ce qui permet aux entreprises de migrer facilement sans avoir à modifier leurs applications en profondeur.
La structure des coûts d'Aurora est également attrayante. Il facture sur la base de l'utilisation réelle des ressources de calcul et de stockage. Ce modèle de coût élimine la nécessité de surprovisionner l'infrastructure, ce qui permet d'économiser de l'argent.
> Si vous souhaitez mieux comprendre les options de stockage AWS, consultez ce tutoriel sur le stockage AWS.tions de stockage AWS, consultez ce tutoriel sur le stockage AWS.
La mise en place d'AWS Aurora implique la création d'un cluster de base de données, la configuration des paramètres de sécurité et la garantie d'un accès correct au réseau. C'est ce que nous allons faire dans cette section !
> Si vous êtes novice en matière d'AWS, envisagez de revoir les sujets fondamentaux à l'aide du cours Introduction à l'AWS. Introduction à AWS avant de vous plonger dans Aurora.
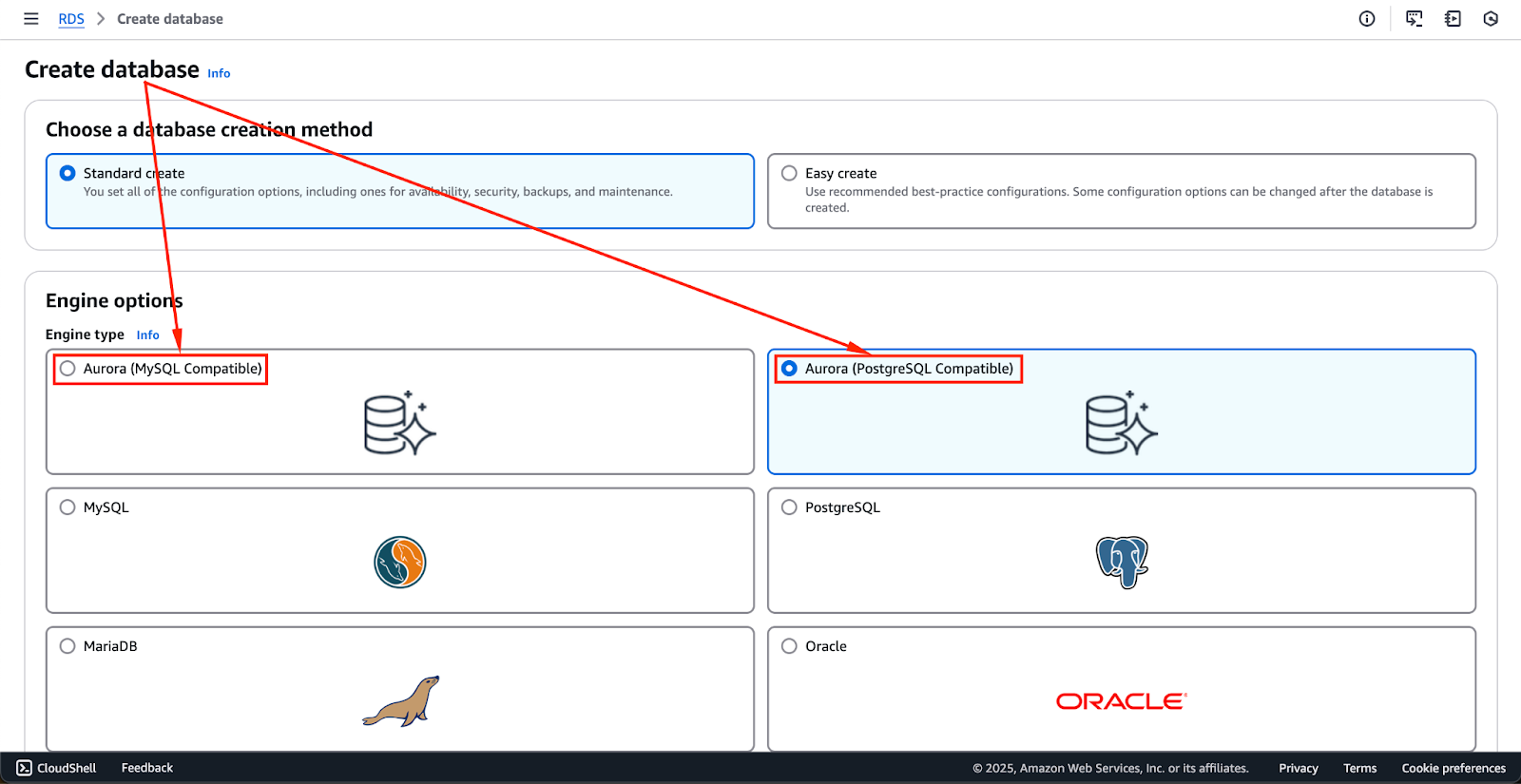
La mise en place d'un cluster de base de données Aurora nécessite quelques étapes clés, notamment la sélection du moteur de base de données approprié, la configuration des paramètres de sécurité et la définition des spécifications de l'instance.
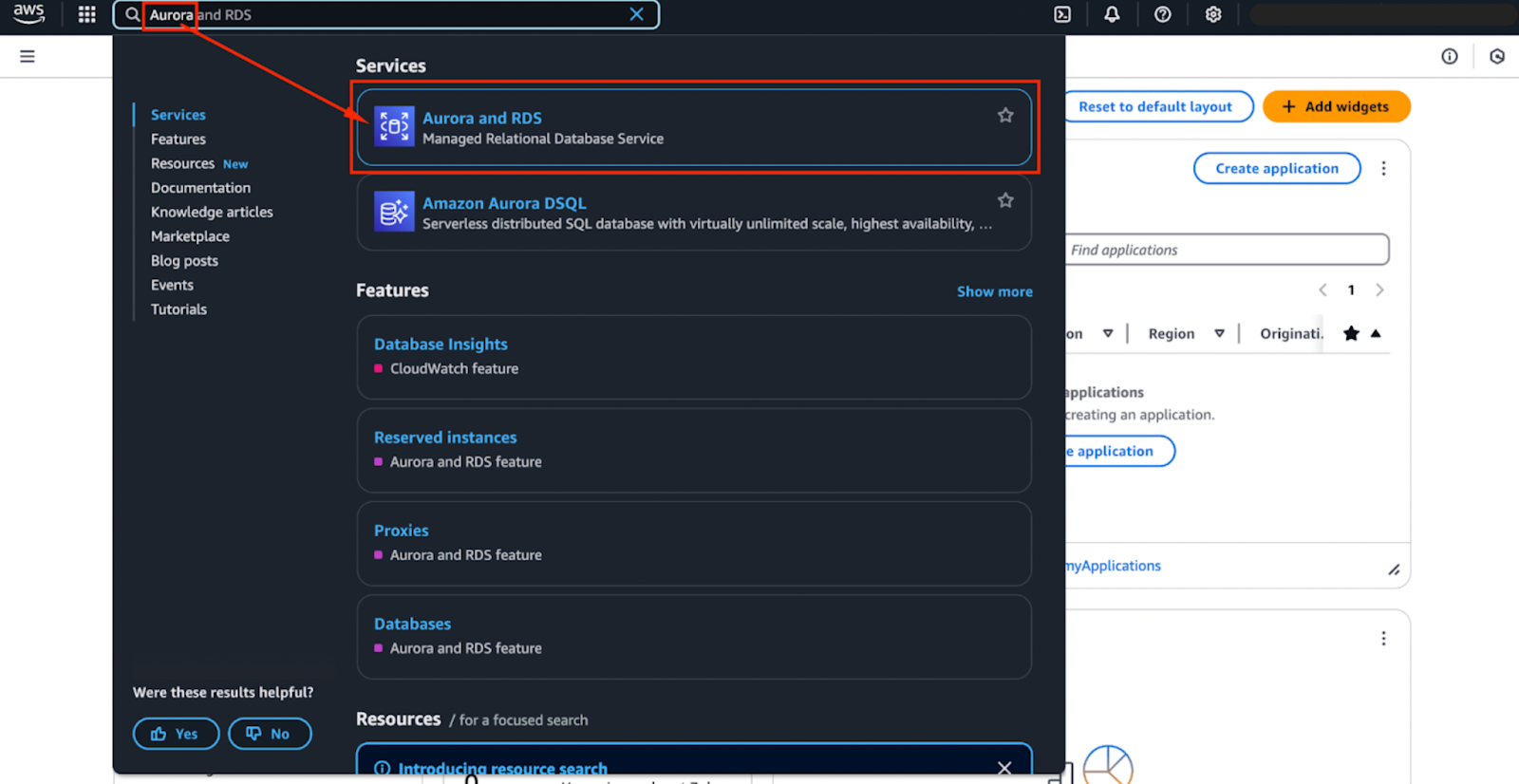
L'image ci-dessous montre les options de moteur actuellement disponibles. Ceux-ci pourraient changer à l'avenir, mais les deux premières options - Aurora (compatible avec MySQL) et Aurora (compatible avec PostgreSQL) - sont les moteurs Aurora.
L'image ci-dessous met en évidence la "Disponibilité et durabilité où vous pouvez configurer ces paramètres.
L'image ci-dessous met en évidence la rubrique "Connectivité où vous pouvez établir et personnaliser ces configurations.
Après avoir passé en revue toutes les configurations, vous pouvez procéder à la création du cluster Aurora. L'image ci-dessous montre le bouton"Créer une base de données" de sur lequel vous pouvez cliquer pour lancer le processus de création.
Le processus de provisionnement peut prendre plusieurs minutes, en fonction de la taille de l'instance sélectionnée et des paramètres du réseau.
> Si vous êtes novice en matière de services AWS, vous pouvez passer en revue le cours AWS Cloud Technology Services.e cours sur la technologie et les services du cloud AWS peut vous aider à comprendre les concepts clés d' AWS relatifs à l' installation d'Aurora.e peut vous aider à comprendre les concepts clés d'AWS relatifs à l'installation d'Aurora.
La sécurité est essentielle à la gestion d'une base de données Aurora, et AWS fournit de nombreux outils permettant d'appliquer des contrôles d'accès stricts.
> Pour approfondir la sécurisation des environnements AWS, jetez un coup d'œil surau cours AWS Security and Cost Management (Sécurité AWS et gestion des coûts). Si vous souhaitez en savoir plus sur le fonctionnement de la gestion des identités et des accès (IAM) et sur la manière de la mettre en œuvre efficacement, jetez un coup d'œil à ce guide sur la gestion des identités et des accès (IAM) d'AWS.
La connexion à AWS Aurora est essentielle pour interagir avec la base de données. Vous pouvez le faire à l'aide d'outils ou d'applications client. Voyons comment dans cette section !
Une fois que la base de données Aurora est opérationnelle, vous devez établir une connexion pour commencer à interagir avec la base de données.
Pour Aurora MySQL, des clients de base de données courants tels que MySQL Workbench et HeidiSQL peuvent être utilisés pour se connecter. Vous pouvez également utiliser des interfaces de ligne de commande.
La connexion nécessite de spécifier le point de terminaison de la base de données, qui peut être trouvé dans la console de gestion AWS.
En utilisant le CLI MySQL, la connexion peut être établie avec la commande suivante :
mysql -h your-cluster-endpoint -u admin -pAprès avoir saisi le mot de passe principal, vous devriez être en mesure d'exécuter des requêtes SQL, de créer des tableaux et de gérer des données.
Pour Aurora PostgreSQL, vous pouvez vous connecter à l'aide d'outils tels que pgAdmin ou l'interface de ligne de commande PostgreSQL (psql).
La commande de connexion dans psql suit ce format :
psql -h your-cluster-endpoint -U admin -d yourdatabasenameComme pour MySQL, vous devez saisir les informations d'identification correctes pour accéder à la base de données.
Une fois l'accès obtenu, vous devriez être en mesure d'exécuter des requêtes SQL, de créer des tableaux et de gérer des données.
Les applications qui doivent interagir avec Aurora doivent être configurées avec les chaînes de connexion à la base de données appropriées. En général, ces chaînes de connexion se composent du nom d'utilisateur, du mot de passe, du numéro de port et du point de terminaison.
Il est recommandé d'utiliser la mise en commun des connexions pour optimiser les performances et réduire la charge de travail liée à l'établissement de nouvelles connexions pour chaque requête.
Des bibliothèques populaires telles que SQLAlchemy pour Python ou JDBC pour Java offrent des moyens efficaces de gérer les connexions dans un environnement applicatif.
La gestion efficace d'AWS Aurora implique d'assurer la protection des données, de surveiller les performances et de dimensionner les ressources en fonction des besoins. Dans cette section, nous allons passer en revue ces pratiques.
AWS Aurora propose des sauvegardes automatisées qui capturent et stockent en permanence les modifications apportées aux bases de données dans Amazon S3. Ces sauvegardes sont conservées en fonction de paramètres définis par l'utilisateur, ce qui permet de les restaurer à n'importe quel moment de la période de conservation.
Outre les sauvegardes automatisées, vous pouvez également créer des instantanés manuels qui persistent au-delà de la fenêtre de rétention. Les instantanés manuels sont particulièrement utiles pour l'archivage à long terme ou avant d'effectuer des mises à jour importantes de la base de données.
Lorsque j'ai travaillé sur un projet avec une application critique, nous avons programmé des sauvegardes automatisées toutes les deux heures. Toutefois, avant d'apporter des modifications ou des mises à jour à l'application, nous créons manuellement une sauvegarde afin de pouvoir revenir en arrière si nécessaire. Cela démontre que les sauvegardes automatisées et manuelles peuvent être utilisées ensemble de manière efficace.
L'image ci-dessous montre comment AWS Backup peut être utilisé pour la reprise après sinistre avec Amazon Aurora.
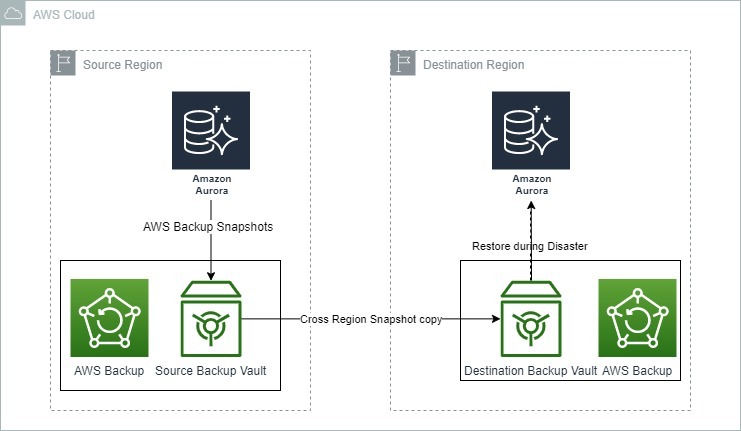
Options de sauvegarde et de restauration pour Amazon Aurora. Source : Blogs AWS
Le contrôle des performances est essentiel pour maintenir une base de données saine.
AWS CloudWatch fournit des mesures en temps réel qui permettent de suivre l'utilisation du processeur, l'utilisation de la mémoire, les entrées/sorties du disque et le trafic réseau.
La configuration des alarmes CloudWatch peut aider les administrateurs à être avertis lorsque les seuils de performance sont dépassés, ce qui permet une gestion proactive de la base de données.
En outre, AWS Performance Insights offre une analyse détaillée des requêtes afin d'identifier et d'optimiser les requêtes les plus lentes.
L'image ci-dessous montre comment AWS Performance Insights fournit des informations sur les performances des bases de données.
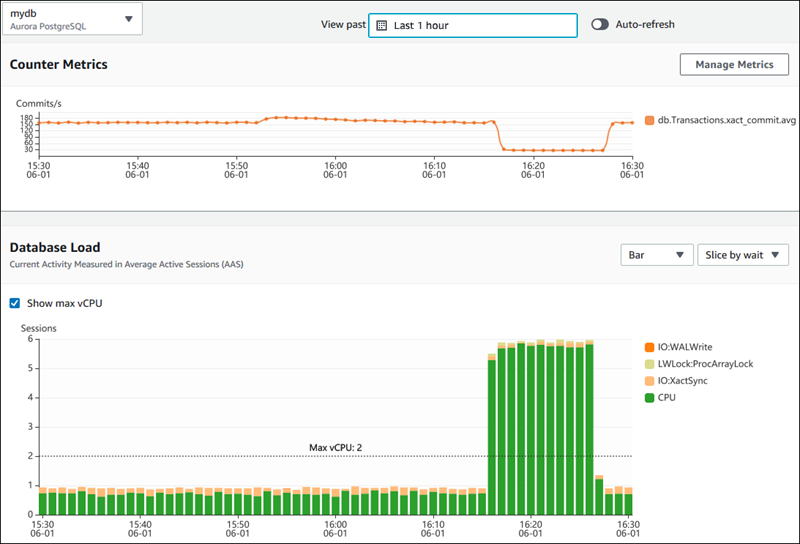
Tableau de bord AWS Performance Insights affichant les mesures de performance de la base de données. Source : Documents AWS
Aurora est conçu pour évoluer automatiquement en ajustant la capacité de stockage en fonction des besoins. Cependant, les ressources informatiques telles que les unités centrales et la mémoire peuvent devoir être ajustées manuellement en fonction de la charge de travail.
Aurora propose des options pour augmenter la capacité de lecture en ajoutant des répliques de lecture, qui répartissent le trafic de lecture et améliorent les performances.
Lorsque la haute disponibilité est essentielle, un cluster Aurora peut être configuré avec plusieurs répliques dans différentes zones de disponibilité pour assurer la redondance du basculement.
L'optimisation des performances dans Amazon Aurora garantit l'efficacité de l'exécution des requêtes et l'évolutivité. Dans cette section, nous allons passer en revue quelques bonnes pratiques.
L'optimisation des performances des requêtes dans Amazon Aurora est cruciale pour maintenir une base de données performante.
EXPLAIN or EXPLAIN ANALYZE dans les requêtes SQL permet d'identifier les goulets d'étranglement et donne un aperçu des plans d'exécution. SELECT * (qui récupère des données inutiles), la normalisation du schéma de la base de données pour réduire la redondance et l'utilisation de stratégies de partitionnement peuvent conduire à des gains de performance.Pour gérer les charges de trafic élevées, Amazon Aurora prend en charge les répliques de lecture qui permettent de répartir les requêtes intensives en lecture sur plusieurs instances.
Les répliques de lecture réduisent la charge de l'instance de base de données principale en traitant les demandes de lecture séparément, ce qui améliore la réactivité et réduit la latence.
Pour mettre en place un réplica de lecture Aurora, vous devrez sélectionner un cluster Aurora existant et activer la réplication avec une configuration minimale. Aurora synchronise automatiquement les données entre l'instance primaire et ses répliques, assurant ainsi la cohérence des données sans intervention manuelle.
Le mécanisme de réplication d'Aurora est très efficace, permettant une synchronisation des données en temps quasi réel avec un délai de réplication inférieur à une seconde.
Les applications qui effectuent des opérations de lecture fréquentes, telles que les tableaux de bord de reporting ou les services d'analyse, peuvent bénéficier de manière significative des répliques de lecture en dirigeant les requêtes lourdes de lecture vers ces instances.
En cas de défaillance d'une instance primaire, une réplique en lecture peut être promue pour devenir la nouvelle instance primaire avec un temps d'arrêt minimal, ce qui garantit une haute disponibilité et la continuité de l'activité.
L'image ci-dessous montre comment les répliques Aurora interrégionales peuvent contribuer à la reprise après sinistre et à la haute disponibilité.
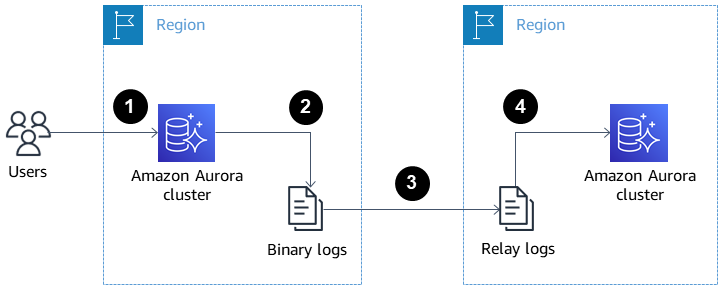
Répliques de lecture Aurora interrégionales pour la reprise après sinistre et la haute disponibilité. Source : Documents AWS
La mise en cache est une technique puissante qui permet d'améliorer les performances des bases de données en réduisant la charge des requêtes directes sur Aurora. Une couche de mise en cache peut accélérer de manière significative la recherche de données pour les requêtes fréquentes.
Amazon ElastiCache, qui prend en charge Redis et Memcached, est couramment utilisé avec Aurora pour stocker les résultats des requêtes et éviter les requêtes redondantes dans la base de données.
L'intégration de la mise en cache dans l'architecture d'une application peut contribuer à améliorer les temps de réponse tout en préservant les ressources informatiques de la base de données.
Les stratégies de mise en cache telles que la mise en cache par écriture (où les données sont écrites simultanément dans le cache et dans Aurora) et le chargement paresseux (où les données ne sont mises en cache que lorsqu'elles sont demandées) permettent d'optimiser les performances en fonction des schémas d'utilisation.
La configuration d'une durée de vie appropriée pour les données mises en cache permet de garantir la fraîcheur du cache et d'éviter la récupération de données périmées.
La sécurisation de votre base de données Aurora est essentielle pour protéger les données sensibles et garantir la conformité. Passons en revue les meilleures pratiques dans cette section.
La sécurité des données est fondamentale pour la gestion des bases de données, et AWS Aurora fournit des mécanismes de chiffrement robustes pour protéger les données sensibles.
Ces mesures de cryptage peuvent vous aider à vous conformer aux meilleures pratiques de sécurité et aux exigences réglementaires.
L'image ci-dessous montre comment AWS KMS s'intègre à Amazon Aurora pour crypter votre base de données.
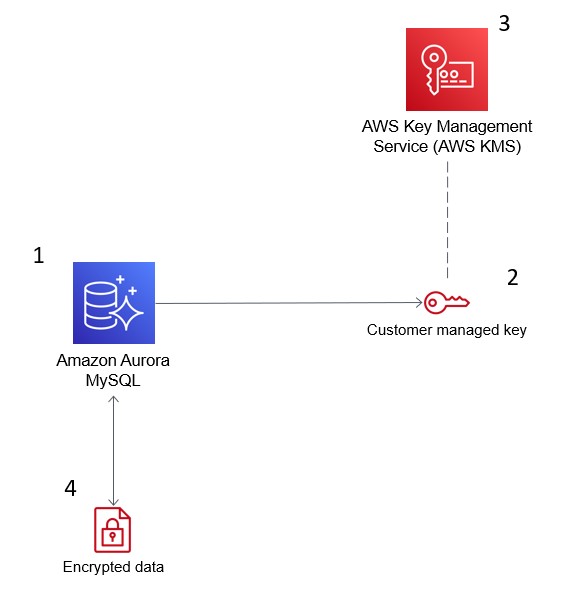
AWS Key Management Service (KMS) chiffre les données dans Amazon Aurora pour assurer la conformité de la sécurité. Source : Blogs AWS
Le contrôle d'accès à Aurora est géré par AWS IAM, qui permet aux administrateurs de définir des autorisations fines basées sur les rôles des utilisateurs.
Vous devez appliquer les principes d'accès au moindre privilège, qui minimisent les risques de sécurité et maintiennent un contrôle strict sur l'accès à la base de données.
L'image ci-dessous montre comment l'authentification IAM peut être configurée pour sécuriser l'accès à la base de données Amazon Aurora PostgreSQL.
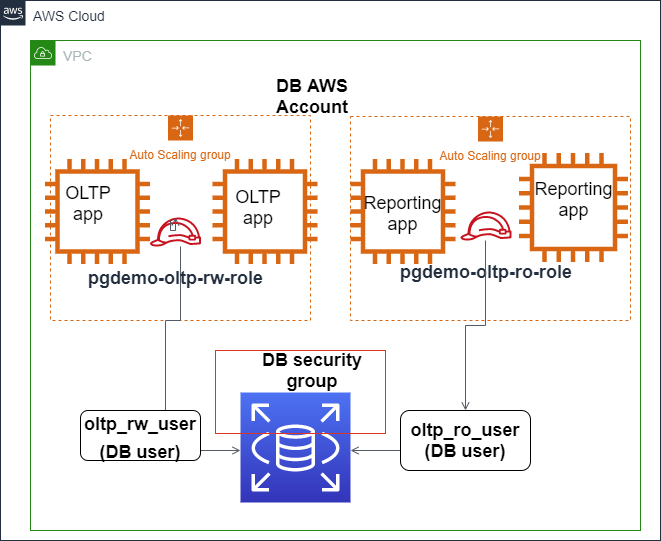
L'authentification IAM s'intègre à Amazon Aurora PostgreSQL. Sourcee : Blogs AWS
Le contrôle et l'audit de l'activité de la base de données sont essentiels pour assurer le respect des règles de sécurité et le dépannage.
Le cursus propose plusieurs mécanismes de journalisation, notamment des journaux d'erreurs, des journaux de requêtes lentes et des journaux généraux, qui aident les administrateurs à suivre l'activité de la base de données et à identifier les problèmes potentiels. Ces journaux peuvent être activés via la console de gestion AWS et stockés dans Amazon CloudWatch pour une analyse centralisée.
L'analyse de ces journaux peut aider les administrateurs à optimiser l'exécution des requêtes, à détecter les tentatives d'accès non autorisé et à garantir la stabilité de la base de données.
Pour gérer et optimiser efficacement les coûts dans Amazon Aurora, vous devez comprendre sa structure de prix. Passons-le en revue !
Le modèle de tarification d'Amazon Aurora est basé sur plusieurs facteurs, notamment les heures d'instance, la consommation de stockage, les demandes d'E/S et le transfert de données.
Contrairement aux bases de données traditionnelles qui nécessitent un provisionnement initial de l'infrastructure, le modèle "pay-as-you-go" d'Aurora permet aux entreprises de ne payer que pour les ressources qu'elles consomment.
Les instances de calcul sont facturées en fonction de la classe d'instance et du temps de fonctionnement, tandis que le stockage est dimensionné de manière dynamique, ce qui élimine le besoin d'ajustements manuels.
L'image ci-dessous présente les différentes composantes de la tarification pour Amazon Aurora. Cependant, gardez à l'esprit que les prix peuvent changer et qu'il est donc préférable de consulter la page des prix d'Aurora surpour obtenir les informations les plus récentes.
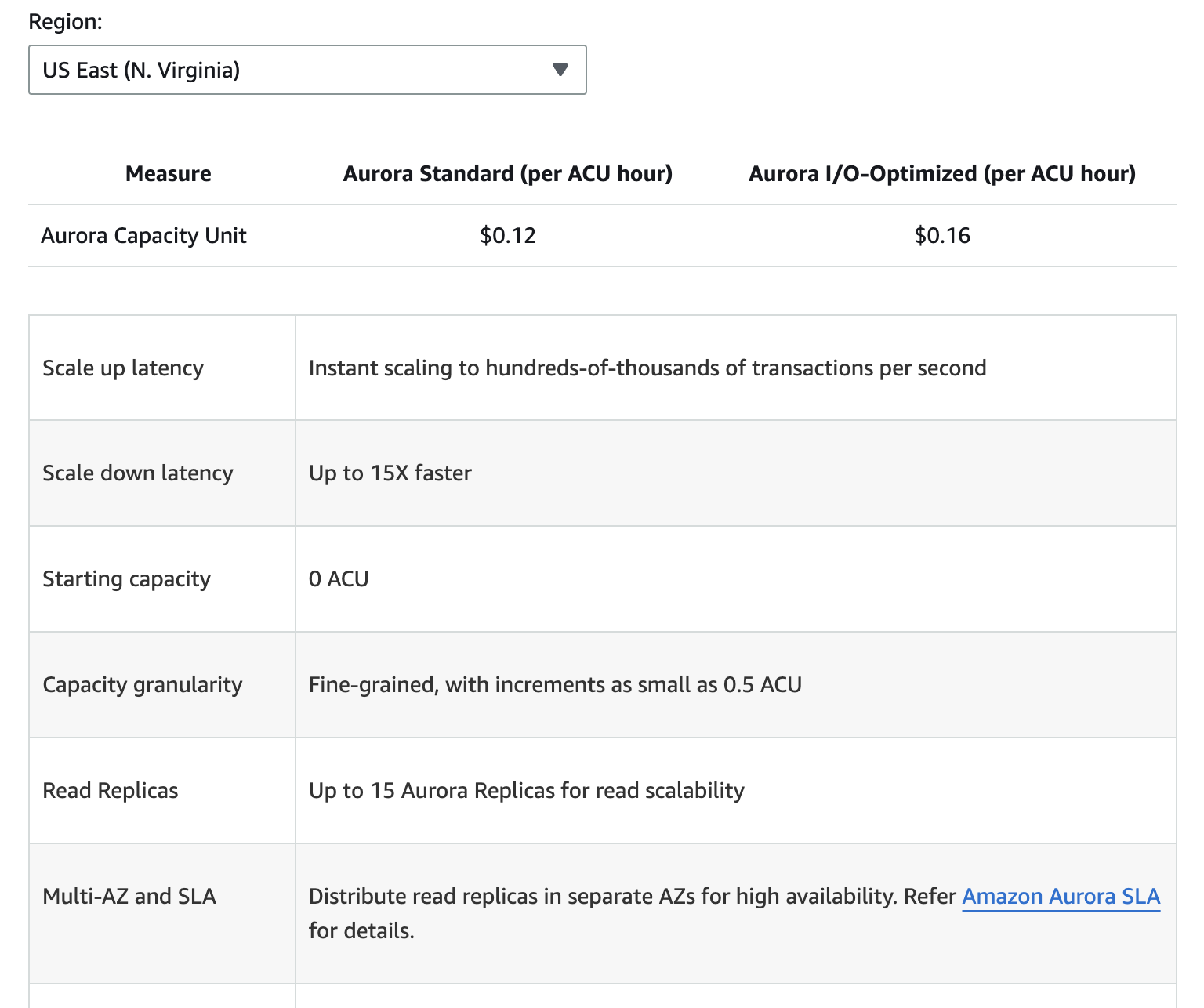
Les coûts supplémentaires comprennent le stockage de sauvegarde au-delà du niveau gratuit alloué, les demandes d'E/S en lecture et en écriture, et les frais de transfert de données pour la réplication interrégionale.
La compréhension de ces éléments de tarification peut vous aider à prévoir vos dépenses et à prendre des décisions éclairées concernant l'utilisation de la base de données.
Pour gérer efficacement les coûts, les organisations peuvent mettre en œuvre plusieurs stratégies d'optimisation.
Le choix d'une taille d'instance appropriée permet de s'assurer que les ressources de la base de données correspondent aux exigences de la charge de travail sans surprovisionnement.
> Si vous souhaitez en savoir plus sur la gestion des coûts, consultez le cours Sécurité et gestion des coûts AWS.euillez consulter le cours sur la sécurité et la gestion des coûts d'AWS.
Après avoir travaillé pendant un certain temps avec Amazon Aurora au sein de plusieurs entreprises, je peux affirmer en toute confiance qu'il s'agit d'une solution de base de données puissante et évolutive qui facilite la gestion sans compromettre les performances - vous en conviendrez probablement après avoir suivi ce tutoriel.
Aurora mérite d'être pris en compte si vous recherchez une base de données relationnelle native au cloud qui prend en charge MySQL et PostgreSQL tout en réduisant les frais généraux d'exploitation. Il s'est avéré révolutionnaire dans certains de mes projets, et je vous recommande vivement de vous pencher sur ses capacités si vous travaillez avec des bases de données AWS.
Si vous êtes novice en matière de bases de données AWS, l'apprentissage des concepts fondamentaux grâce à des courstels que AWS Cloud Practitioner (CLF-C02) peut s'avérer bénéfique !
Apprenez-en plus sur AWS grâce à ces cours !
Cursus
Cours
Cours