Curso
Introducción a la ingeniería de datos
4 h
127.6K
Las soluciones nativas en la nube son cada vez más populares en todos los sectores debido a su seguridad, flexibilidad y escalabilidad. Una de estas soluciones es AWS Glue, que simplifica el procesamiento de datos, un componente esencial para tomar decisiones informadas y optimizar las operaciones empresariales.
En este tutorial, utilizaremos AWS Glue para demostrar una tarea ETL (Extraer, Transformar, Cargar) común: convertir archivos CSV almacenados en un bucket S3 a formato Parquet. Utilizar Parquet mejora tanto la eficacia del procesamiento de datos como el rendimiento de las consultas.
Presentaremos AWS Glue, sus características principales y las ventajas de automatizar la preparación de datos. A continuación, veremos cómo configurar tu cuenta de AWS, crear roles IAM y configurar el acceso a tu bucket S3. Por último, te guiaremos en la creación de un rastreador Glue para escanear tus conjuntos de datos y generar archivos Parquet.
Antes de seguir con los pasos prácticos, entendamos primero qué es AWS Glue y por qué es útil para las tareas de procesamiento de datos.
AWS Glue es un servicio ETL totalmente administrado que facilita la preparación y carga de tus datos para el análisis. Proporciona un entorno sin servidor para crear, ejecutar y supervisar trabajos ETL. AWS Glue descubre y perfila automáticamente tus datos mediante el Catálogo de datos de AWS Glue, recomienda y genera código ETL, y proporciona un programador flexible para gestionar la resolución de dependencias, la monitorización de trabajos y los reintentos.
Comprender las ventajas de AWS Glue te ayudará a apreciar su valor en el flujo de trabajo del procesamiento de datos. Hay varias razones de peso para utilizar AWS Glue y algunas de ellas se ilustran a continuación:
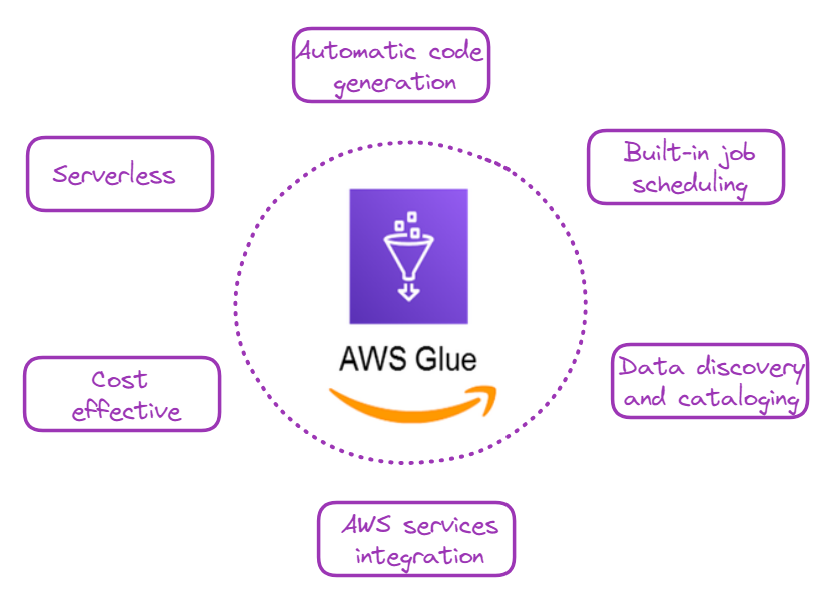
¿Por qué elegir AWS Glue? Imagen del autor
Ahora viene la parte emocionante: vamos a aprender a utilizar Glue para una tarea de tratamiento de datos muy común: convertir archivos CSV a Parquet.
Para los nuevos en AWS, el primer paso sería crear una cuenta e iniciar sesión en la consola de administración.
AWS Identity and Access Management (IAM) permite a los usuarios administrar de forma segura el acceso a los servicios y recursos de AWS.
Necesitamos crear un rol IAM para permitir que Glue acceda a los servicios relevantes. En nuestro caso, el servicio principal al que accedemos es S3, que aloja nuestros archivos CSV.
El tutorial de almacenamiento de AWS es una forma estupenda de que los nuevos usuarios de AWS aprendan más sobre sistemas como S3.
A continuación se describen los pasos principales para crear ese rol IAM, empezando por la Consola de Administración:
AWSGlueServiceRoleAmazonS3FullAccess (Nota: En un entorno de producción, debes crear una política más restrictiva).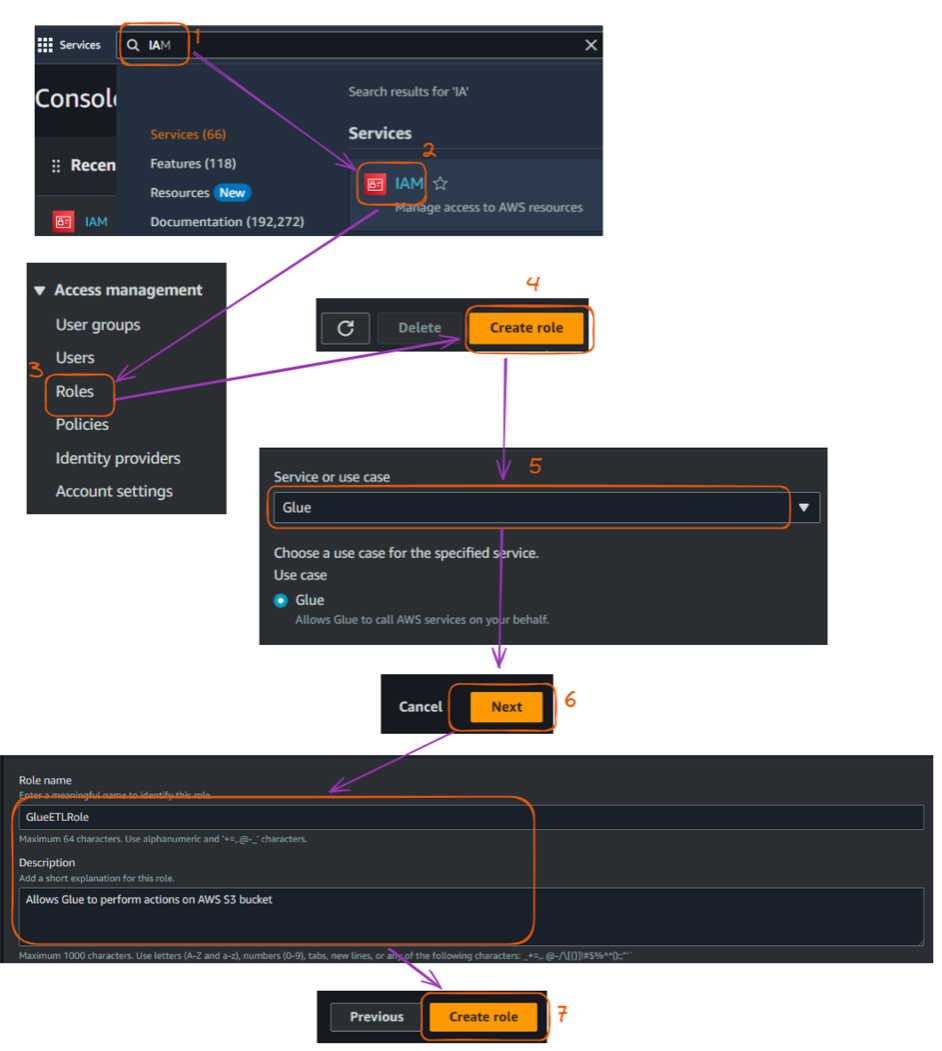
Pasos para crear un rol IAM en la consola de AWS. Imagen del autor
La Guía Completa de AWS IAM recorre los pasos necesarios para utilizar IAM con el fin de proteger los entornos de AWS, administrar el acceso con usuarios, grupos y roles, y esbozar las mejores prácticas para una seguridad sólida.
Almacenaremos tanto los archivos CSV de entrada como los archivos Parquet de salida en Amazon S3.
Los datos de entrada de este ejemplo se crearon con fines ilustrativos y se pueden encontrar en el repositorio GitHub del autor:
athletes.csv: Contiene información sobre los atletas, incluyendo su DNI, nombre, país, deporte y edad.events.csv: Enumera varios eventos, incluyendo ID del evento, deporte, nombre del evento, fecha y lugar.medals.csv: Registra la información sobre las medallas, vinculando las pruebas y los atletas a las medallas que ganaron.Ahora, podemos configurar nuestro bucket S3 de la siguiente manera:
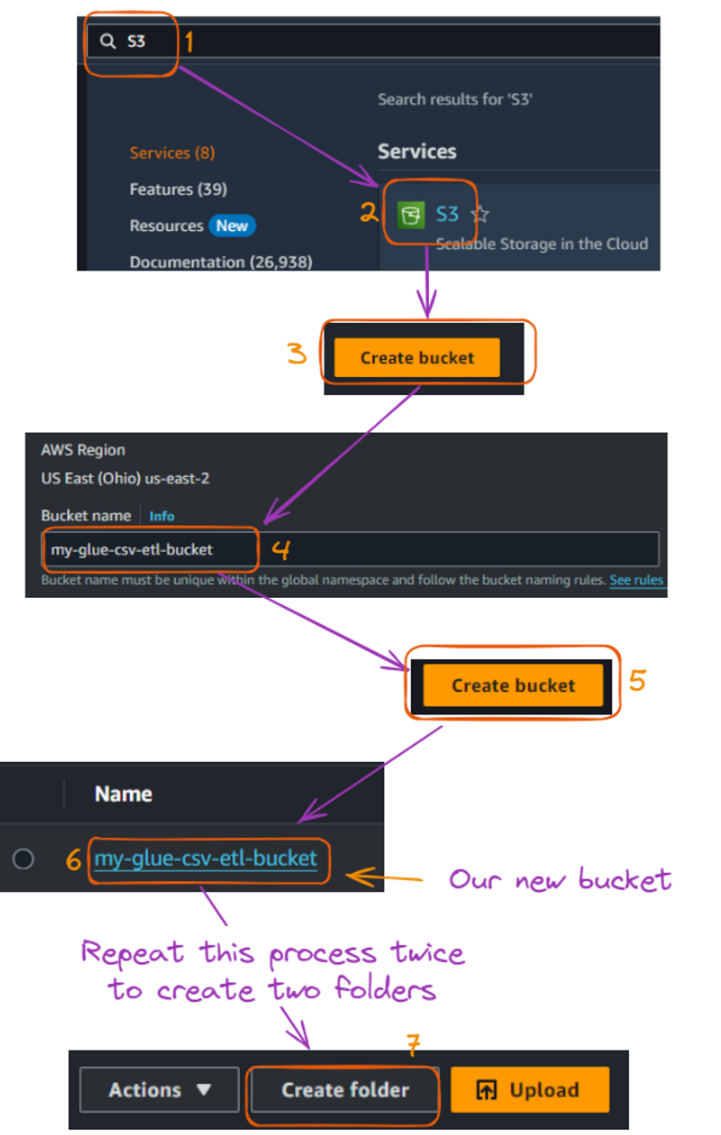
Flujo de creaciones de cubos y carpetas S3. Imagen del autor
Después de crear las dos carpetas, el contenido de tu cubo debería tener este aspecto:
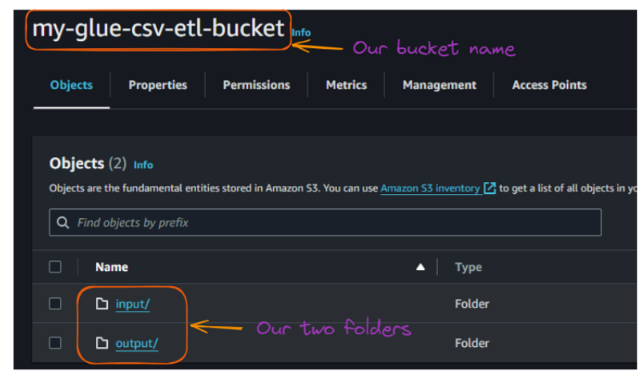
Vista de las carpetas dentro del cubo S3. Imagen del autor
Ahora, podemos subir estos archivos CSV de entrada a la carpeta "entrada".
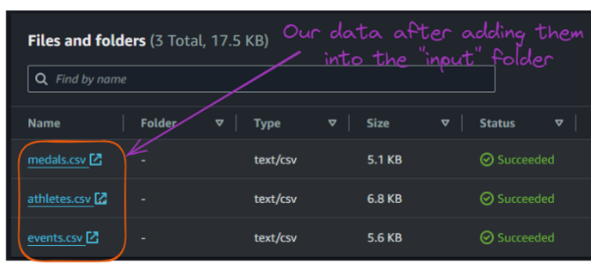
Contenido de la carpeta "entrada" del cubo S3. Imagen del autor
Se utiliza un rastreador Glue para descubrir y catalogar nuestros datos automáticamente. Esta sección explica cómo crear un rastreador que escanee todos los archivos CSV de entrada.
A continuación se explican los pasos principales:
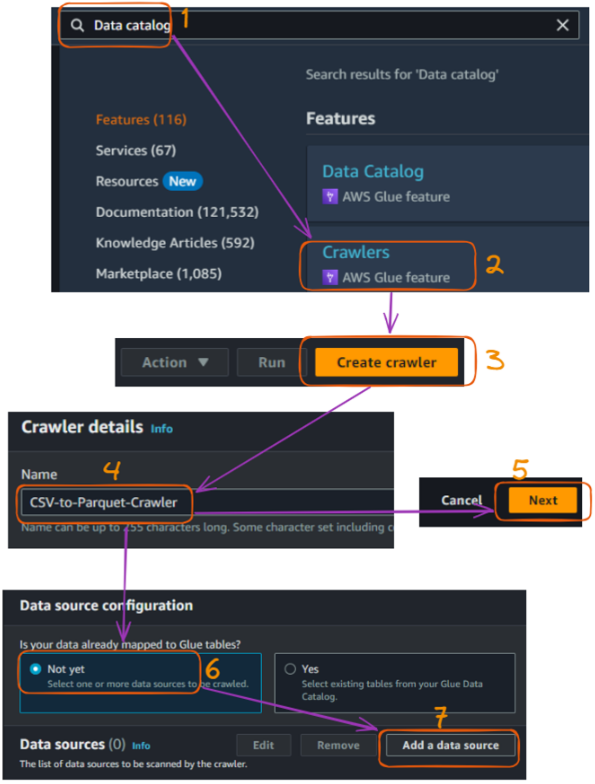
Flujo de creación del rastreador AWS Glue en la consola - parte 1. Imagen del autor
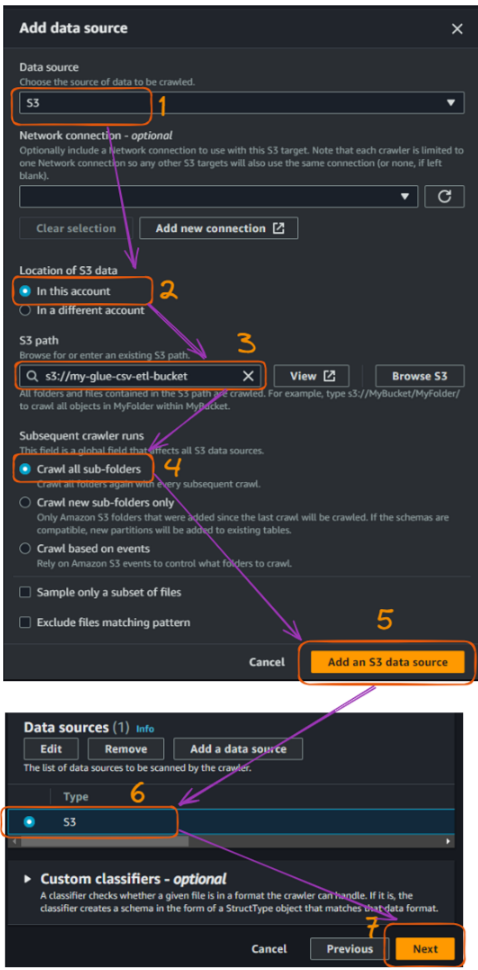
Flujo de creación del rastreador AWS Glue en la consola - parte 2. Imagen del autor
Una vez que hemos conectado el bucket S3, necesitamos conectar el rol IAM que se creó previamente para permitir que Glue acceda a los buckets S3. El nombre de nuestro rol es "GlueETLRole".
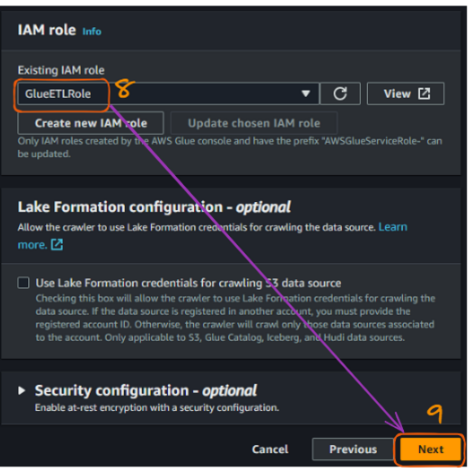
Flujo de creación del rastreador AWS Glue en la consola - parte 3. Imagen del autor
El siguiente paso es crear una base de datos. La base de datos "paris_olympics_db" que crearemos sirve como repositorio central en el Catálogo de Datos de AWS Glue para almacenar y organizar metadatos sobre nuestros archivos CSV.
El catálogo permitirá un descubrimiento eficaz de los datos y simplificará nuestro proceso ETL para combinar y convertir los datos de atletas, eventos y medallas en formato Parquet.
En este momento, todavía no tenemos ninguna base de datos, y los pasos de creación se ilustran a continuación:
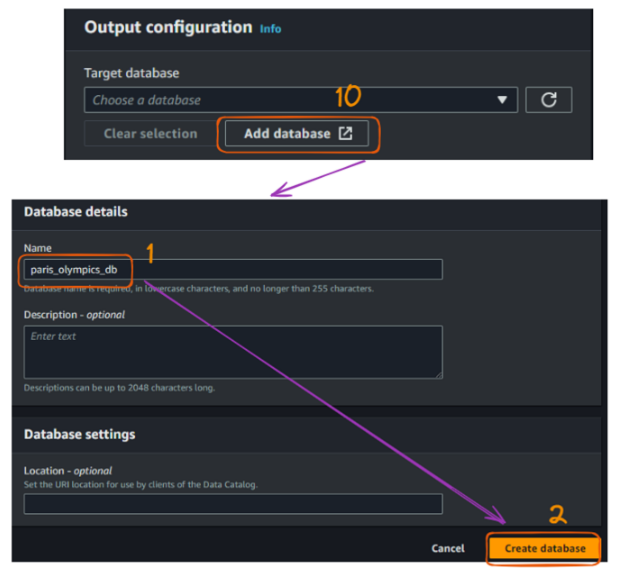
Flujo de creación del rastreador AWS Glue en la consola - parte 4. Imagen del autor
Desde la pestaña original donde conectamos una base de datos, actualiza la sección "Base de datos de destino" y elige la base de datos recién creada. Luego haz clic en "Siguiente".
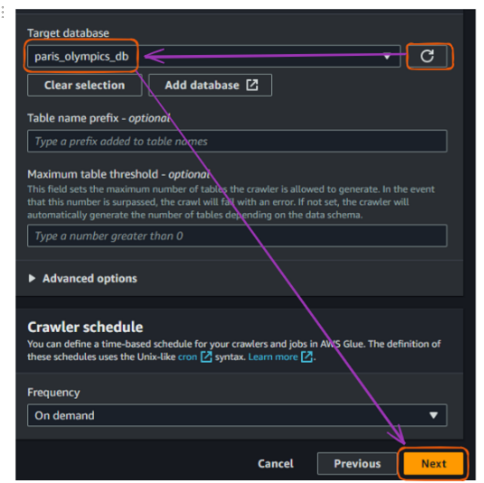
Flujo de creación del rastreador AWS Glue en la consola - parte 5. Imagen del autor
Por último, revísalo todo y haz clic en "Crear rastreador".
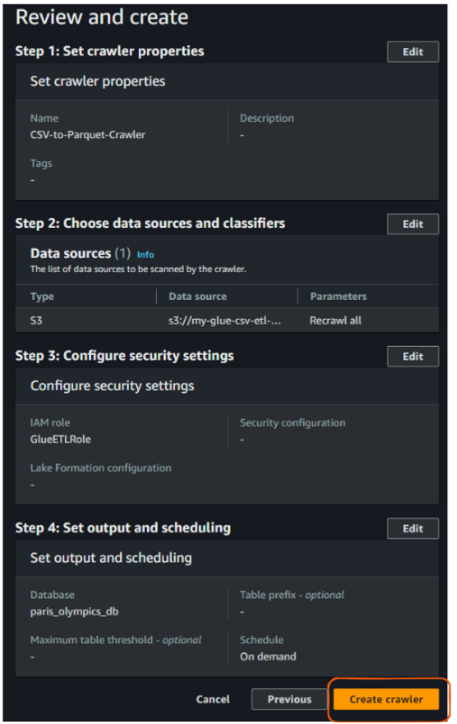
Vista "Revisar y crear" del rastreador AWS Glue. Imagen del autor
Tras la acción anterior de crear un rastreador, deberíamos ver el siguiente resultado confirmando su creación:
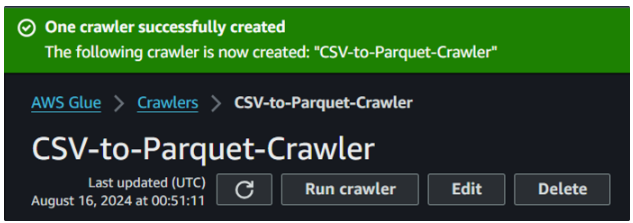
Creación con éxito del rastreador de cola. Imagen del autor
Ahora que hemos creado nuestro rastreador, es hora de ejecutarlo y ver cómo cataloga nuestros datos.
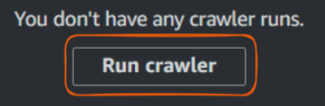
Pega el botón "Ejecutar rastreador". Imagen del autor
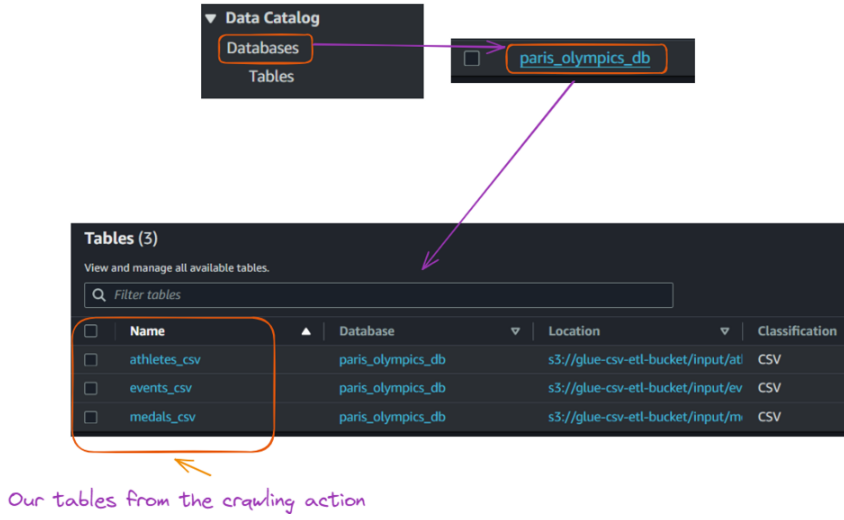
Vista de las tablas creadas en la base de datos a partir de la ejecución del rastreador Glue. Imagen del autor
Con nuestro catálogo de datos creado, ahora podemos crear un trabajo Glue para combinar nuestros archivos CSV y convertirlos al formato Parquet. Esta sección te guía a través de la creación del trabajo Glue y proporciona el código Python necesario.
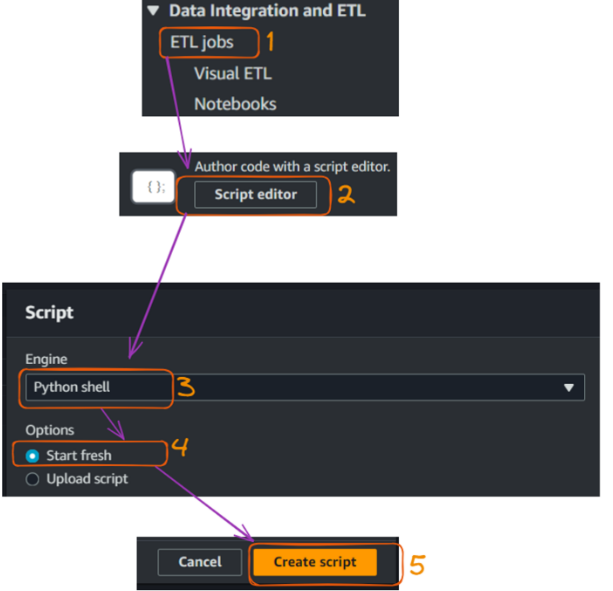
Crear y ejecutar un trabajo de Pegado - parte 1. Imagen del autor
La acción de crear el script abre la siguiente pestaña de script, donde podemos dar un nombre al trabajo, que en nuestro caso es "CS".
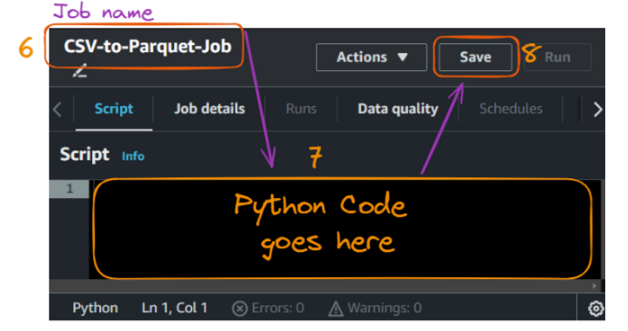
Crear y ejecutar un trabajo de Pegado - parte 2. Imagen del autor
A continuación se indica el código Python correspondiente:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import col, to_date
# Initialize the Spark and Glue contexts
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
# Set Spark configurations for optimization
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
# Get job parameters
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
# Set the input and output paths
input_path = "s3://glue-csv-etl-bucket/input/"
output_path = "s3://glue-csv-etl-bucket/output/"
# Function to read CSV and write Parquet
def csv_to_parquet(input_file, output_file):
try:
# Read CSV
df = spark.read.option("header", "true") \
.option("inferSchema", "true") \
.option("mode", "PERMISSIVE") \
.option("columnNameOfCorruptRecord", "_corrupt_record") \
.csv(input_file)
# Print schema for debugging
print(f"Schema for {input_file}:")
df.printSchema()
# Convert date column if it exists (assuming it's in the format M/d/yyyy)
if "date" in df.columns:
df = df.withColumn("date", to_date(col("date"), "M/d/yyyy"))
# Write Parquet
df.write.mode("overwrite").parquet(output_file)
print(f"Successfully converted {input_file} to Parquet at {output_file}")
print(f"Number of rows processed: {df.count()}")
except Exception as e:
print(f"Error processing {input_file}: {str(e)}")
# List of files to process
files = ["athletes", "events", "medals"]
# Process each file
for file in files:
input_file = f"{input_path}{file}.csv"
output_file = f"{output_path}{file}_parquet"
csv_to_parquet(input_file, output_file)
job.commit()
print("Job completed.")Entendamos brevemente lo que ocurre en el código:
csv_to_parquet() para leer un archivo CSV, imprimir su esquema, convertir una columna de fecha si existe y escribir los datos como un archivo Parquet. Maneja las excepciones durante el proceso.athletes, events, medals) llamando a la función csv_to_parquet() en cada archivo.Antes de ejecutar el trabajo, tenemos que rellenar las siguientes configuraciones adicionales en la sección "Detalles del trabajo":
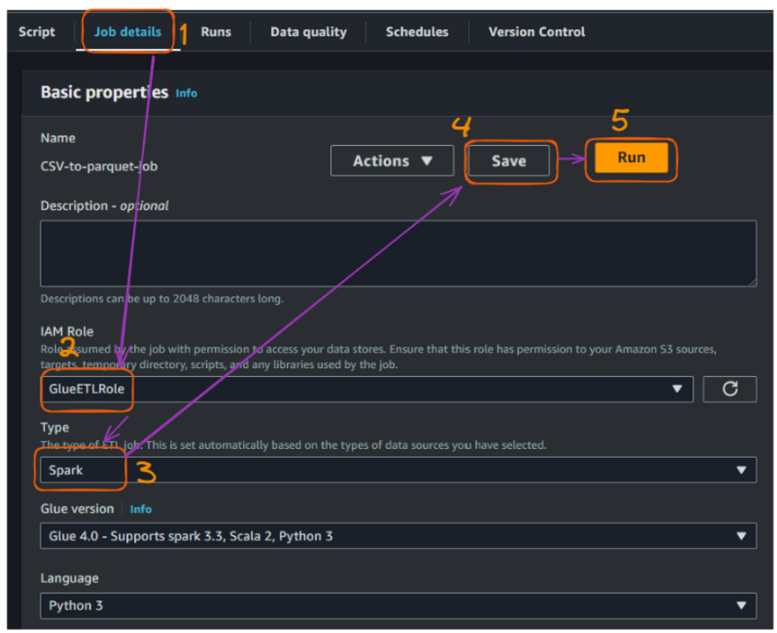
Crear y ejecutar un trabajo de Pegado - parte 3. Imagen del autor
Tras ejecutar correctamente el trabajo, podemos ver más detalles sobre el estado de la ejecución:
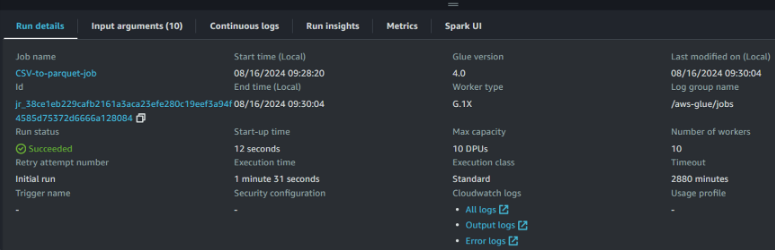
Vista de detalles de ejecución del trabajo de AWS Glue. Imagen del autor
Acceder a los detalles de la ejecución y controlarlos es importante para mantener unos conductos de datos eficientes y fiables. Estas métricas proporcionan información valiosa y nos ayudan en lo siguiente:
La ejecución correcta de este trabajo convirtió cada archivo CSV en su correspondiente archivo Parquet y los almacenó en la carpeta "salida", como se muestra a continuación:
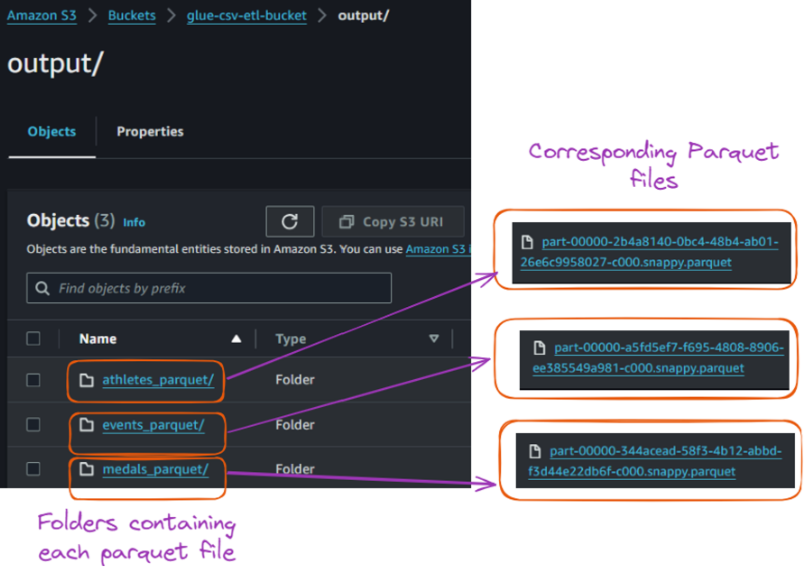
Contenido de la carpeta de salida dentro del cubo S3. Imagen del autor
Este tutorial trata sobre AWS Glue y sus características. Te guió a través de la configuración de un entorno AWS y la exploración de la interfaz de AWS Glue. También te mostró cómo construir y ejecutar un rastreador Glue para catalogar datos, crear un trabajo Glue para transformarlos y convertir con éxito archivos CSV a formato Parquet.
Puedes ampliar lo que has aprendido configurando activadores para automatizar los flujos de trabajo, implementando la gestión de errores y el registro, y optimizando los archivos Parquet para mejorar aún más el rendimiento. También puedes explorar la consulta de tus datos con AWS Athena oAmazon Redshift Spectrum.
Además, controla tu uso y costes de AWS y limpia los recursos cuando ya no sean necesarios para evitar cargos innecesarios.
¡Los cursos Introducción a AWS y Tecnología y servicios en la nube de AWS podrían ser excelentes pasos siguientes para seguir aprendiendo!
El primero ofrece una sólida base de AWS y la computación en la nube, ideal para principiantes o para quienes repasen conceptos clave. La segunda se centra en el aprendizaje práctico, ayudándote a profundizar en tus conocimientos prácticos de los servicios de AWS.
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

¡Aprende más sobre AWS y la ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Joleen Bothma
12 min
blog
DataCamp Team
12 min
Tutorial
Tim Lu
Tutorial
Natassha Selvaraj
Tutorial
Oluseye Jeremiah