Curso
Introdução à Engenharia de Dados
4 h
127.6K
As soluções nativas da nuvem são cada vez mais populares em todos os setores devido à sua segurança, flexibilidade e escalabilidade. Uma dessas soluções é o AWS Glue, que simplifica o processamento de dados - um componente essencial para tomar decisões informadas e otimizar as operações comerciais.
Neste tutorial, usaremos o AWS Glue para demonstrar uma tarefa comum de ETL (Extrair, Transformar, Carregar): converter arquivos CSV armazenados em um bucket do S3 para o formato Parquet. O uso do Parquet aumenta a eficiência do processamento de dados e o desempenho da consulta.
Apresentaremos o AWS Glue, seus principais recursos e os benefícios de automatizar a preparação de dados. Em seguida, você verá como configurar sua conta do AWS, criar funções de IAM e configurar o acesso ao seu bucket do S3. Por fim, orientaremos você na criação de um rastreador Glue para examinar seus conjuntos de dados e gerar arquivos Parquet.
Antes de prosseguir com as etapas práticas, vamos primeiro entender o que é o AWS Glue e por que ele é útil para tarefas de processamento de dados.
O AWS Glue é um serviço de ETL totalmente gerenciado que facilita a preparação e o carregamento de seus dados para análise. Ele fornece um ambiente sem servidor para criar, executar e monitorar trabalhos de ETL. O AWS Glue descobre e define automaticamente o perfil dos seus dados por meio do AWS Glue Data Catalog, recomenda e gera código ETL e fornece um agendador flexível para lidar com a resolução de dependências, o monitoramento de tarefas e as novas tentativas.
Compreender os benefícios do AWS Glue ajudará você a apreciar seu valor no fluxo de trabalho de processamento de dados. Há vários motivos convincentes para você usar o AWS Glue, e alguns deles estão ilustrados abaixo:
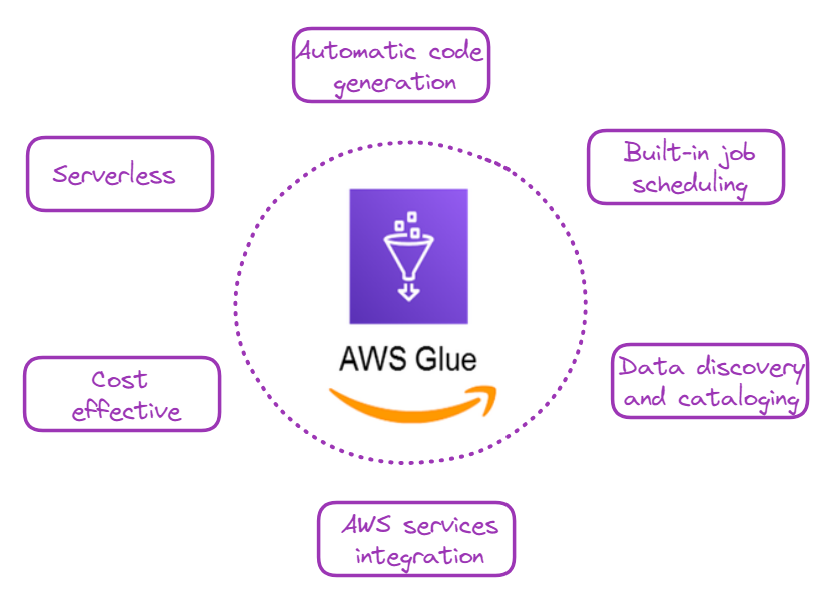
Por que escolher o AWS Glue? Imagem do autor
Agora vem a parte interessante: vamos aprender a usar o Glue para uma tarefa muito comum de processamento de dados: converter arquivos CSV em Parquet.
Para os novatos na AWS, a primeira etapa seria criar uma conta e, em seguida, fazer login no console de gerenciamento.
O AWS Identity and Access Management (IAM) permite que os usuários gerenciem com segurança o acesso aos serviços e recursos do AWS.
Precisamos criar uma função de IAM para permitir que o Glue acesse os serviços relevantes. No nosso caso, o principal serviço que estamos acessando é o S3, que hospeda nossos arquivos CSV.
O tutorial de armazenamento do AWS é uma ótima maneira de os novos usuários do AWS aprenderem mais sobre sistemas como o S3.
As principais etapas para criar essa função IAM estão descritas abaixo, começando pelo Management Console:
AWSGlueServiceRoleAmazonS3FullAccess (Observação: Em um ambiente de produção, você deve criar uma política mais restritiva).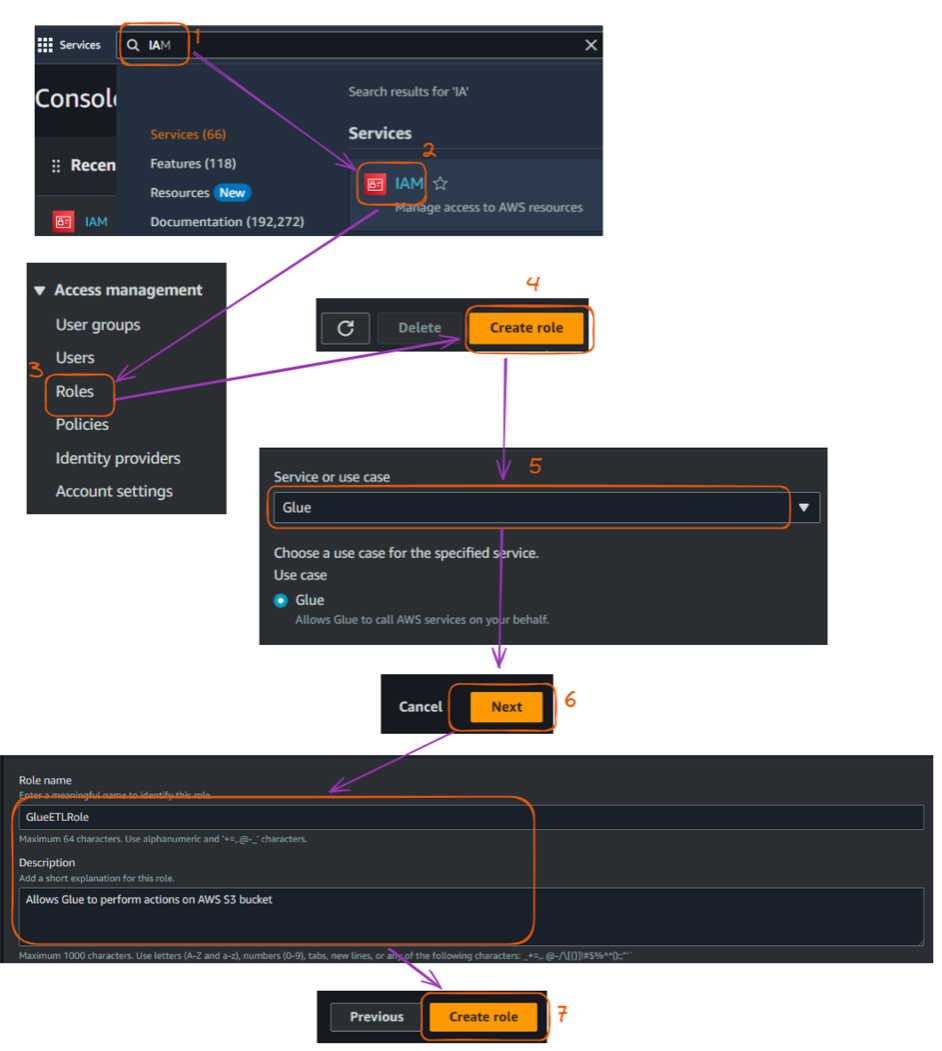
Etapas para criar uma função IAM no console do AWS. Imagem do autor
O Guia completo do AWS IAM apresenta as etapas para usar o IAM para proteger os ambientes da AWS, gerenciar o acesso com usuários, grupos e funções e delinear as práticas recomendadas para uma segurança robusta.
Armazenaremos os arquivos CSV de entrada e os arquivos Parquet de saída no Amazon S3.
Os dados de entrada para este exemplo foram criados para fins ilustrativos e podem ser encontrados no repositório GitHub do autor:
athletes.csv: Contém informações sobre atletas, incluindo sua identificação, nome, país, esporte e idade.events.csv: Lista vários eventos, incluindo ID do evento, esporte, nome do evento, data e local.medals.csv: Registra informações sobre medalhas, vinculando eventos e atletas às medalhas que ganharam.Agora, podemos configurar nosso bucket S3 da seguinte forma:
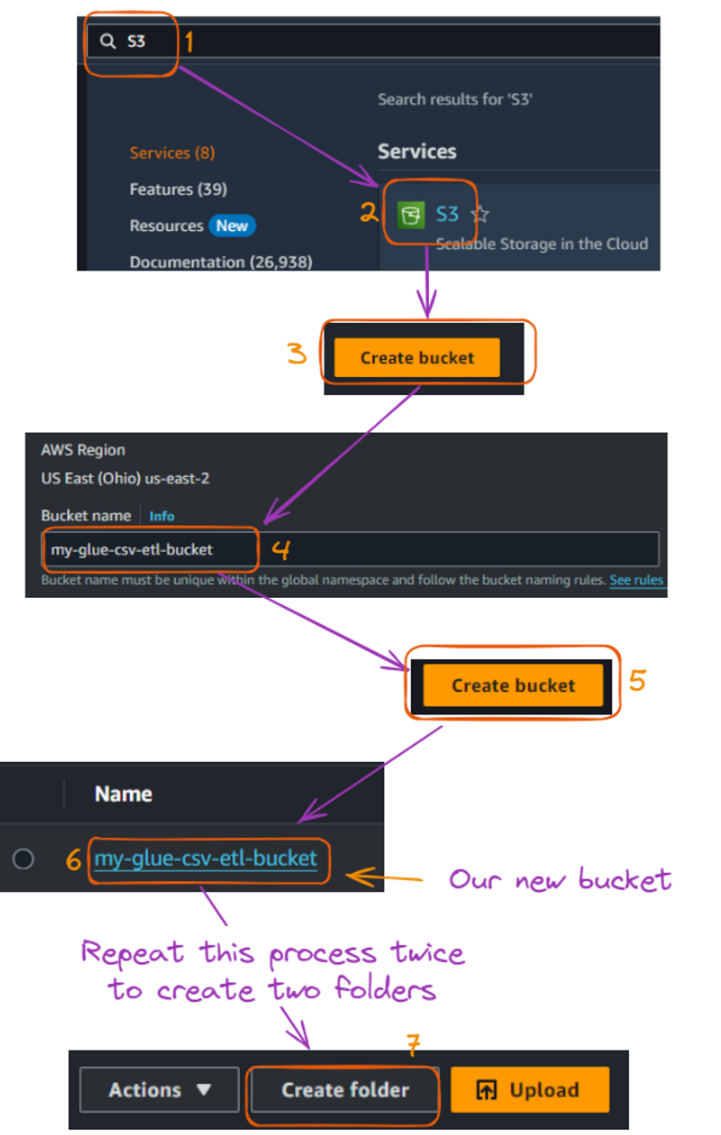
Fluxo de criações de pastas e baldes S3. Imagem do autor
Depois de criar as duas pastas, o conteúdo do seu bucket deverá ter a seguinte aparência:
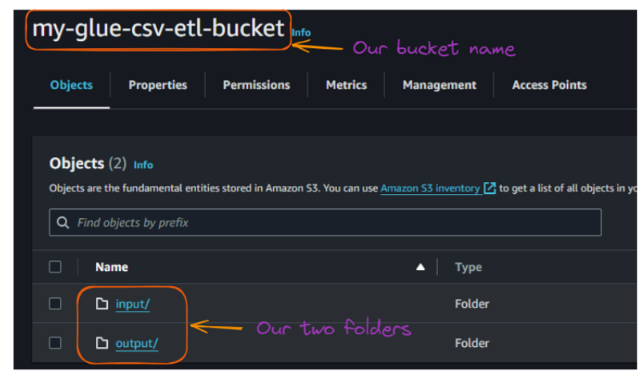
Visualização das pastas dentro do bucket S3. Imagem do autor
Agora, podemos carregar esses arquivos CSV de entrada na pasta "input".
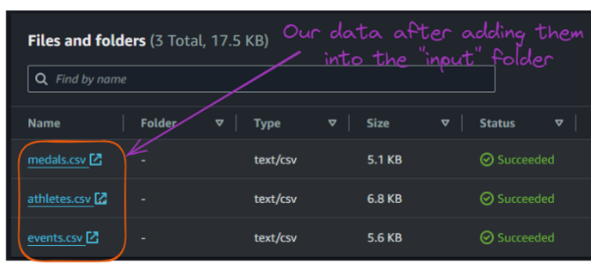
Conteúdo da pasta "input" do bucket S3. Imagem do autor
Um rastreador Glue é usado para descobrir e catalogar nossos dados automaticamente. Esta seção explica como criar um rastreador que analisa todos os arquivos CSV de entrada.
As principais etapas são explicadas a seguir:
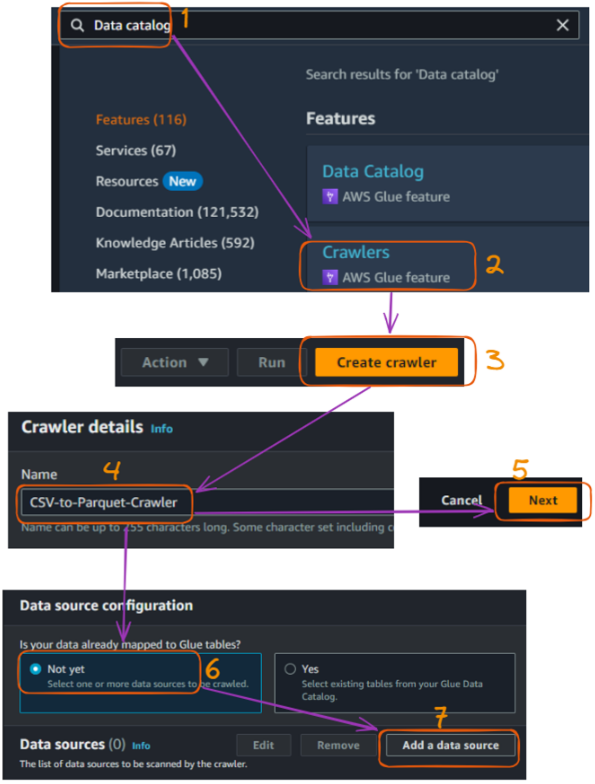
Fluxo de criação do rastreador do AWS Glue no console - parte 1. Imagem do autor
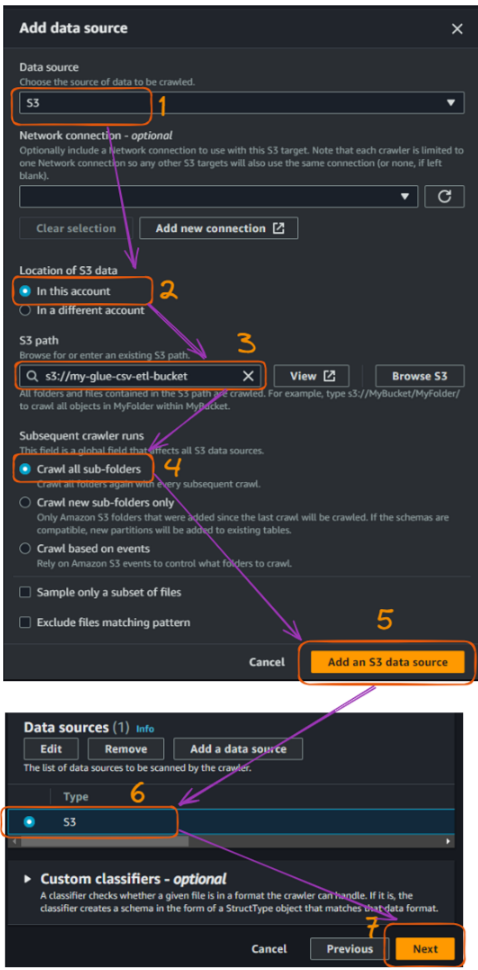
Fluxo de criação do rastreador do AWS Glue no console - parte 2. Imagem do autor
Depois de conectar o bucket do S3, precisamos conectar a função do IAM que foi criada anteriormente para permitir que o Glue acesse os buckets do S3. O nome da nossa função é "GlueETLRole".
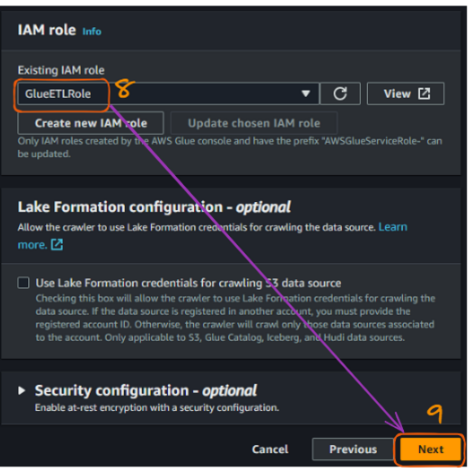
Fluxo de criação do rastreador do AWS Glue no console - parte 3. Imagem do autor
A próxima etapa é criar um banco de dados. O banco de dados "paris_olympics_db" que criaremos serve como um repositório central no AWS Glue Data Catalog para armazenar e organizar metadados sobre nossos arquivos CSV.
O catálogo permitirá a descoberta eficiente de dados e simplificará nosso processo de ETL para combinar e converter os dados de atletas, eventos e medalhas no formato Parquet.
No momento, ainda não temos nenhum banco de dados, e as etapas de criação estão ilustradas abaixo:
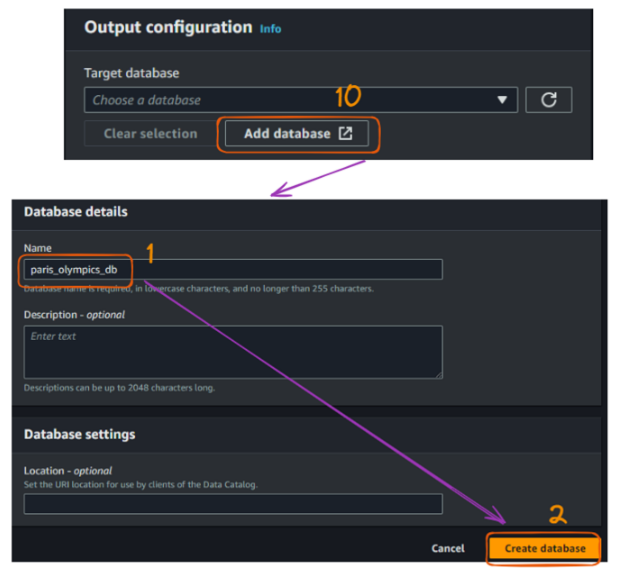
Fluxo de criação do rastreador do AWS Glue no console - parte 4. Imagem do autor
Na guia original em que conectamos um banco de dados, atualize a seção "Target database" (Banco de dados de destino) e escolha o banco de dados recém-criado. Em seguida, clique em "Next".
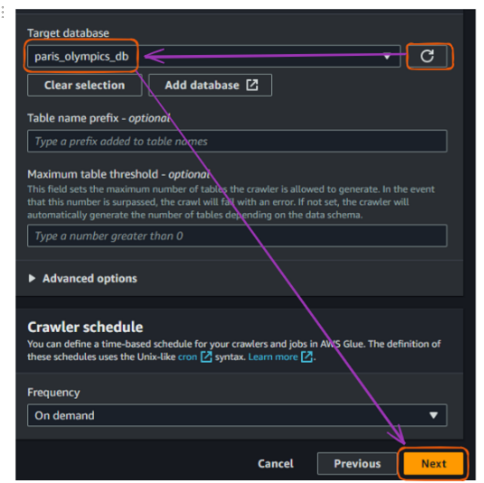
Fluxo de criação do rastreador do AWS Glue no console - parte 5. Imagem do autor
Por fim, revise tudo e clique em "Create crawler".
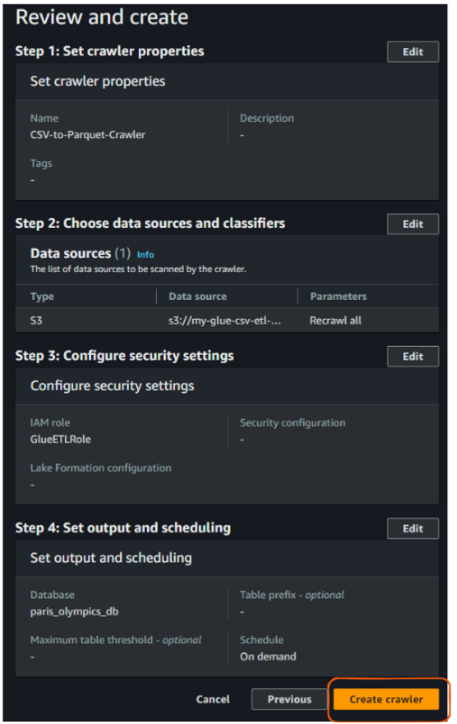
Visualização "Revisar e criar" do rastreador do AWS Glue. Imagem do autor
Após a ação anterior de criar um rastreador, você deverá ver o seguinte resultado confirmando sua criação:
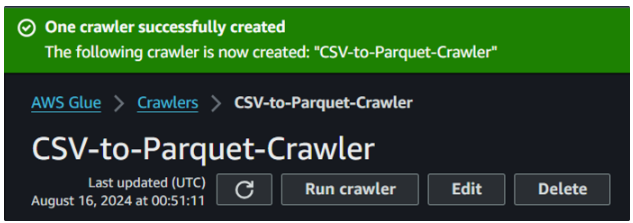
Criação bem-sucedida do rastreador de cola. Imagem do autor
Agora que criamos nosso rastreador, é hora de executá-lo e ver como ele cataloga nossos dados.
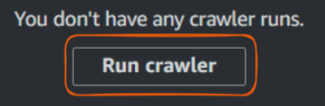
Cole o botão "Run crawler" (Executar rastreador). Imagem do autor
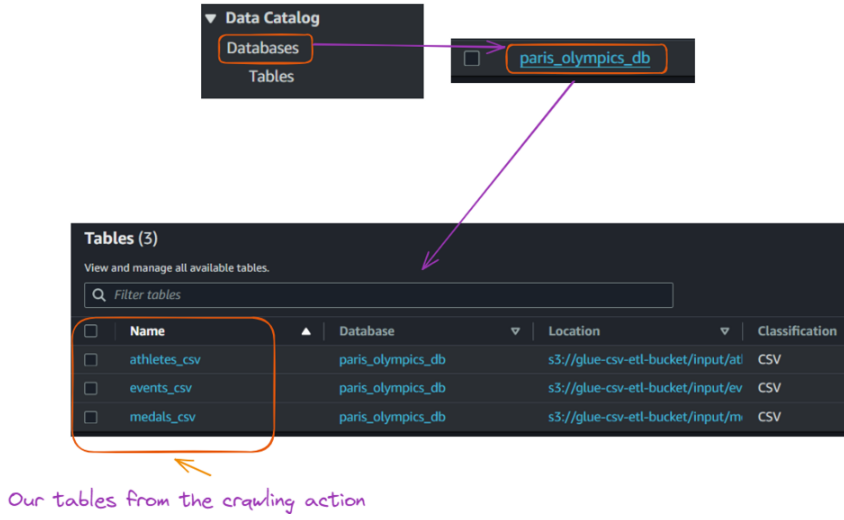
Visualização das tabelas criadas no banco de dados a partir da execução do rastreador Glue. Imagem do autor
Com nosso catálogo de dados criado, agora podemos criar um trabalho Glue para combinar nossos arquivos CSV e convertê-los para o formato Parquet. Esta seção orienta você na criação do trabalho do Glue e fornece o código Python necessário.
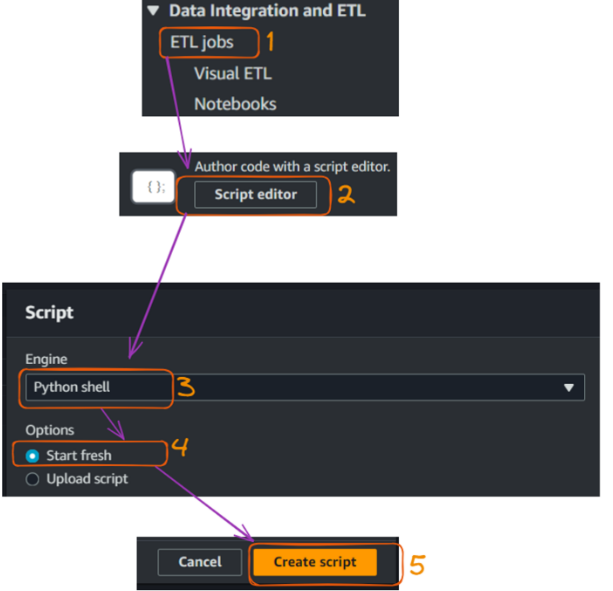
Criação e execução de um trabalho Glue - parte 1. Imagem do autor
A ação de criar o script abre a seguinte guia de script, na qual podemos dar um nome ao trabalho, que é "CS" no nosso caso.
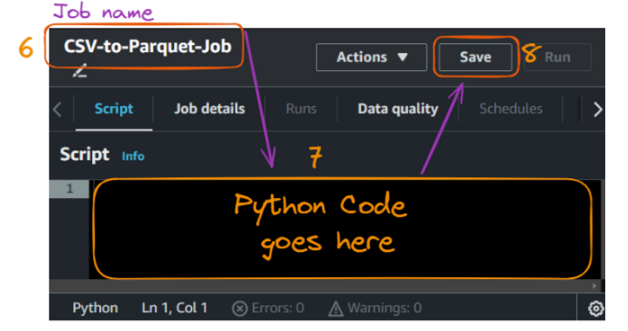
Criação e execução de um trabalho Glue - parte 2. Imagem do autor
O código Python correspondente é fornecido abaixo:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.functions import col, to_date
# Initialize the Spark and Glue contexts
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
# Set Spark configurations for optimization
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
# Get job parameters
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
# Set the input and output paths
input_path = "s3://glue-csv-etl-bucket/input/"
output_path = "s3://glue-csv-etl-bucket/output/"
# Function to read CSV and write Parquet
def csv_to_parquet(input_file, output_file):
try:
# Read CSV
df = spark.read.option("header", "true") \
.option("inferSchema", "true") \
.option("mode", "PERMISSIVE") \
.option("columnNameOfCorruptRecord", "_corrupt_record") \
.csv(input_file)
# Print schema for debugging
print(f"Schema for {input_file}:")
df.printSchema()
# Convert date column if it exists (assuming it's in the format M/d/yyyy)
if "date" in df.columns:
df = df.withColumn("date", to_date(col("date"), "M/d/yyyy"))
# Write Parquet
df.write.mode("overwrite").parquet(output_file)
print(f"Successfully converted {input_file} to Parquet at {output_file}")
print(f"Number of rows processed: {df.count()}")
except Exception as e:
print(f"Error processing {input_file}: {str(e)}")
# List of files to process
files = ["athletes", "events", "medals"]
# Process each file
for file in files:
input_file = f"{input_path}{file}.csv"
output_file = f"{output_path}{file}_parquet"
csv_to_parquet(input_file, output_file)
job.commit()
print("Job completed.")Vamos entender brevemente o que está acontecendo no código:
csv_to_parquet() para ler um arquivo CSV, imprimir seu esquema, converter uma coluna de data, se houver, e gravar os dados como um arquivo Parquet. Trata as exceções durante o processamento.athletes, events, medals) chamando a função csv_to_parquet() em cada arquivo.Antes de executar o trabalho, precisamos preencher as seguintes configurações adicionais na seção "Job details" (Detalhes do trabalho):
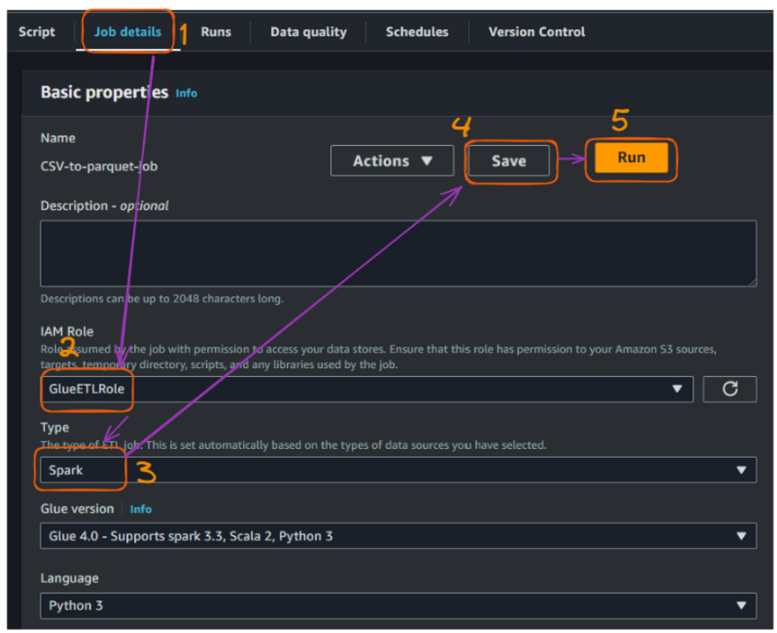
Criação e execução de um trabalho Glue - parte 3. Imagem do autor
Depois de executar o trabalho com êxito, podemos ver mais detalhes sobre o status da execução:
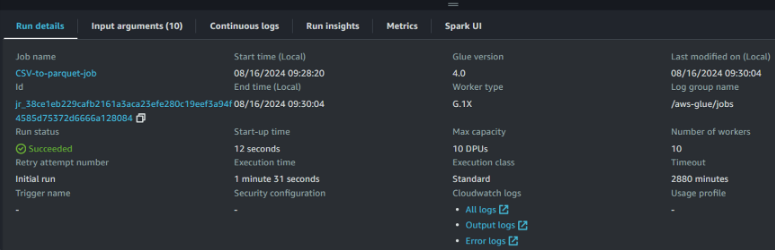
Visualização dos detalhes da execução do trabalho do AWS Glue. Imagem do autor
O acesso e o monitoramento dos detalhes da execução são importantes para manter pipelines de dados eficientes e confiáveis. Essas métricas fornecem insights valiosos e nos ajudam com o seguinte:
A execução bem-sucedida desse trabalho converteu cada arquivo CSV em seu arquivo Parquet correspondente e os armazenou na pasta "output", conforme mostrado abaixo:
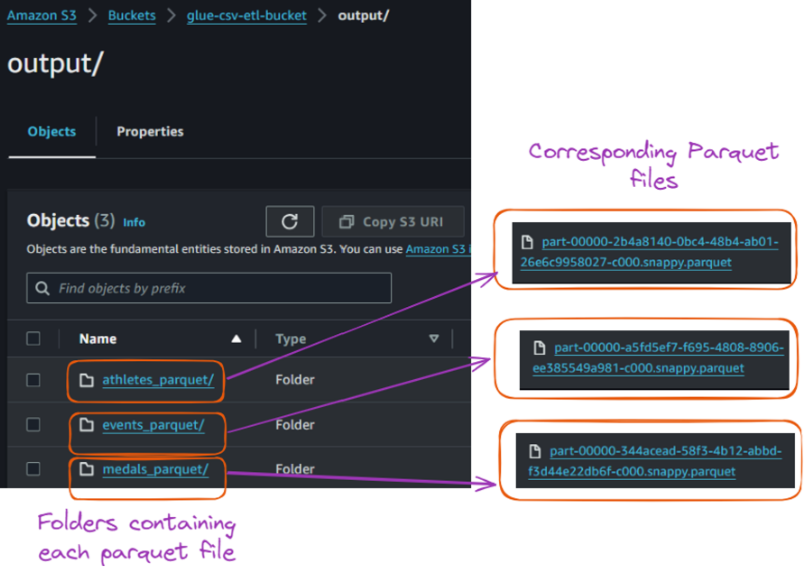
Conteúdo da pasta de saída dentro do bucket S3. Imagem do autor
Este tutorial abordou o AWS Glue e seus recursos. Ele guiou você na configuração de um ambiente do AWS e na exploração da interface do AWS Glue. Ele também mostrou a você como criar e executar um rastreador Glue para catalogar dados, criar um trabalho Glue para transformá-los e converter com êxito arquivos CSV para o formato Parquet.
Você pode expandir o que aprendeu configurando acionadores para automatizar fluxos de trabalho, implementando o tratamento e o registro de erros e otimizando os arquivos Parquet para obter um desempenho ainda melhor. Você também pode explorar a consulta de seus dados com o AWS Athena ouo Amazon Redshift Spectrum.
Além disso, monitore o uso e os custos do AWS e limpe os recursos quando eles não forem mais necessários para evitar cobranças desnecessárias.
Os cursos Introduction to AWS e AWS Cloud Technology and Services podem ser excelentes próximos passos para que você aprenda mais!
O primeiro oferece uma base sólida de AWS e computação em nuvem, ideal para iniciantes ou para aqueles que estão se atualizando sobre os principais conceitos. O segundo concentra-se no aprendizado prático, ajudando você a aprofundar seu conhecimento prático dos serviços da AWS.
Nossos programas de certificação ajudam você a se destacar e a provar que suas habilidades estão prontas para o trabalho para possíveis empregadores.

Saiba mais sobre a AWS e a engenharia de dados com estes cursos!
Curso
Curso
Curso