El panorama del aprendizaje automático y el procesamiento del lenguaje natural (PLN) está en continua evolución, y OpenAI lidera constantemente el camino hacia la innovación.
La introducción de sus modelos text-embedding-3-large y text-embedding-3-small marca una nueva era en este campo, destinada a cambiar la forma en que los desarrolladores y los profesionales de la IA abordan las tareas de análisis e incrustación de textos.
En el complejo mundo de la inteligencia artificial, las incrustaciones son cruciales para convertir el complicado lenguaje humano en algo que las máquinas puedan entender y procesar. Este nuevo modelo de OpenAI representa un importante paso adelante para los desarrolladores y aspirantes a profesionales de los datos.
Este artículo pretende explicar los modelos de incrustación de texto-3-grande y de incrustación de texto-3-pequeño, ofreciendo una visión de sus funciones básicas, diversas aplicaciones y cómo utilizarlos eficazmente.
Al explorar los fundamentos de la incrustación de texto y destacar las nuevas funciones y usos prácticos del modelo, el artículo pretende proporcionar a los lectores la información necesaria para utilizar esta herramienta avanzada en sus proyectos.
Además, cubrirá los aspectos básicos para empezar a utilizar el modelo, compartirá consejos para mejorar las tareas de incrustación y debatirá el amplio impacto de este progreso tecnológico en el campo de la PNL.
Comprender la incrustación de texto
Antes de entrar en las particularidades del nuevo modelo, es útil una breve visión general de las incrustaciones de texto para comprenderlo mejor.
Las incrustaciones de texto son representaciones numéricas del texto que captan la semántica, o el significado, de palabras, frases o documentos enteros. Son fundamentales en muchas tareas de PNL, como el análisis de sentimientos, la clasificación de textos, etc.
Nuestra Introducción a las inc rustaciones de texto con la API OpenAI proporciona una guía completa sobre el uso de la API OpenAI para crear incrustaciones de texto. Descubre sus aplicaciones en la clasificación de textos, la recuperación de información y la detección de similitudes semánticas.
A continuación se muestra una ilustración utilizando un modelo de incrustación:
- Los documentos a representar están a la izquierda
- El modelo de incrustación en el centro, y
- Las incrustaciones correspondientes de cada documento están a la derecha

Ilustración de incrustaciones de texto
Si eres nuevo en este concepto, considera la posibilidad de explorar nuestro curso Introducción a las incrustaciones con la API OpenAI. Explica cómo aprovechar las incrustaciones de OpenAI mediante la API de OpenAI para crear incrustaciones a partir de datos textuales y empezar a desarrollar aplicaciones del mundo real.
Nuevas incrustaciones de OpenAI de un vistazo
Anunciados el 25 de enero de 2024, estos modelos son los últimos y más potentes modelos de incrustación diseñados para representar texto en un espacio de alta dimensión, lo que facilita una mejor comprensión del texto.
El texto-incrustado-3-pequeño está optimizado para la latencia y el almacenamiento. Por otro lado, incrustar-texto-3-grande es una buena opción para una mayor precisión, y también podemos aprovechar el nuevo parámetro de dimensiones para mantener la incrustación a 1536 en lugar del tamaño nativo de 3072 sin que ello afecte al rendimiento general.
Análisis comparativo
Antes del lanzamiento, el modelo de incrustación de texto-ada-2 se situaba en lo más alto de la clasificación de todos los modelos de incrustación anteriores de OpenAI, y la siguiente tabla proporciona una rápida visión general de la evaluación comparativa entre estos tres modelos.
|
Modelo |
Dimensión |
Ficha máxima |
Límite de conocimientos |
Precios ($/1k fichas) |
MIRACL medio |
Media MTEB |
|
ada v2 |
1536 |
8191 |
Septiembre de 2021 |
0.0001 |
31.4 |
61.0 |
|
text-embedding-3-small |
0.00002 |
44.0 |
62.3 |
|||
|
text-embedding-3-large |
3072 |
0.00013 |
54.9 |
64.6 |
A partir de las métricas proporcionadas, podemos observar una mejora en el rendimiento de ada v2 (text-embedding-ada-002) a text-embedding-3-large en las pruebas de referencia MIRACL y MTEB. Esto sugiere que text-embedding-3-large, al tener más dimensiones (3072), ofrece mejor calidad de incrustación que los otros dos, lo que se correlaciona directamente con la mejora de las puntuaciones de referencia.
El aumento de las dimensiones de texto-incrustado-ada-002 y texto-incrustado-3-pequeño (ambos 1536) a texto-incrustado-3-grande (3072) sugiere un modelo más complejo que puede capturar un conjunto más rico de características en sus incrustaciones. Sin embargo, esto también conlleva un precio más elevado por cada 1.000 fichas procesadas, lo que indica un compromiso entre rendimiento y coste.
Dependiendo de los requisitos específicos de una tarea (por ejemplo, la necesidad de capacidades multilingües, la complejidad del texto que hay que incrustar o las limitaciones presupuestarias), se podría elegir un modelo diferente.
Para tareas que requieran incrustaciones de alta calidad en varios idiomas y tareas, puede ser preferible la incrustación de texto-3-grande, a pesar de su mayor coste. En cambio, para aplicaciones con limitaciones presupuestarias más estrictas o en las que la precisión ultraalta no sea tan crítica, la incrustación de texto-ada-002 o la incrustación de texto-3-pequeña podrían ser opciones más adecuadas.
Aplicaciones de Text-Embedding-3-Large
Las tecnologías de incrustación han sido notablemente beneficiosas para muchas aplicaciones modernas de procesamiento y comprensión del lenguaje natural. La elección entre modelos más potentes, como text-embedding-3-large, y opciones más económicas, como text-embedding-3-small, puede influir en el rendimiento y la rentabilidad de las aplicaciones de PNL.
A continuación se presentan tres ilustraciones de casos de uso de ambos modelos, que demuestran su versatilidad e impacto en escenarios del mundo real.
Aplicaciones de text-embedding-3-large
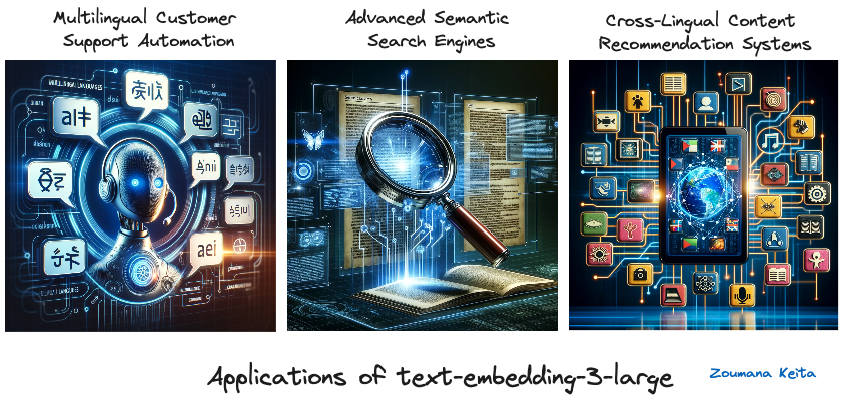
Aplicaciones de text-embedding-3-large (imágenes generadas con GPT-4)
Automatización multilingüe de la atención al cliente
Con su rendimiento superior en la comprensión y el procesamiento de 18 idiomas diferentes, text-embedding-3-large puede alimentar chatbots de atención al cliente y sistemas de respuesta automatizada para empresas globales, garantizando una asistencia precisa y consciente del contexto en diversos entornos lingüísticos.
Buscadores semánticos avanzados
Aprovechando sus incrustaciones de alta dimensión, la incrustación de texto-3-grande puede mejorar los algoritmos de los motores de búsqueda, permitiéndoles comprender mejor los matices de las consultas de búsqueda y recuperar resultados más relevantes y ajustados al contexto, especialmente en campos especializados como la investigación jurídica o médica.
Sistemas de recomendación de contenidos multilingües
Para las plataformas que alojan una amplia gama de contenidos multilingües, como los servicios de streaming o los agregadores de noticias, la incrustación de texto-3-large puede analizar las preferencias de los usuarios y los contenidos en varios idiomas, recomendando contenidos muy relevantes a los usuarios, independientemente de las barreras lingüísticas.
Aplicaciones de text-embedding-3-small

Aplicaciones de text-embedding-3-small (Imagen generada con GPT-4)
Análisis de sentimientos rentable
Para las nuevas y medianas empresas que desean conocer el sentimiento de los clientes mediante la monitorización de las redes sociales o el análisis de sus opiniones, la incrustación de texto-3-small ofrece una solución económica pero eficaz para medir la opinión pública y la satisfacción de los clientes.
Categorización de contenidos escalable
Las plataformas de contenidos con grandes volúmenes de datos, como blogs o sitios de comercio electrónico, pueden utilizar la incrustación de texto-3-pequeño para categorizar automáticamente contenidos o productos. Su eficacia y menor coste lo hacen ideal para manejar grandes conjuntos de datos sin comprometer la precisión.
Herramientas eficaces para el aprendizaje de idiomas
Las aplicaciones educativas que necesitan soluciones escalables y rentables para ofrecer ejercicios de aprendizaje de idiomas, como relacionar palabras con significados o revisar la gramática, pueden beneficiarse de la incrustación de texto-3-small. Su equilibrio entre rendimiento y asequibilidad favorece el desarrollo de contenidos educativos interactivos centrados en los idiomas.
Estas aplicaciones muestran cómo la incrustación de texto 3 grande y la incrustación de texto 3 pequeña pueden desplegarse de forma óptima en diversos sectores, alineando sus puntos fuertes con las necesidades específicas de cada aplicación para mejorar el rendimiento, la experiencia del usuario y la rentabilidad.
Guía paso a paso para utilizar las nuevas incrustaciones de OpenAI
Ahora tenemos todas las herramientas que necesitamos para proceder a la aplicación tanto de text-embedding-3-large, text-embedding-3-small, como de ada-v2 en un escenario de similitud de documentos.
Todo el código de este tutorial está disponible en un libro de trabajo de DataLab. Crea una copia de este libro de trabajo para ejecutar el código sin tener que instalar nada en tu ordenador.
Acerca de los datos
- Este es el conjunto de datos CORD-19, un recurso de más de 59.000 artículos académicos, incluidos más de 48.000 con texto completo, sobre COVID-19, SARS-CoV-2 y coronavirus relacionados.
- Estos datos han sido puestos a libre disposición por la Casa Blanca y una coalición de destacados grupos de investigación para ayudar a la investigación mundial a generar ideas en apoyo de la lucha en curso contra esta enfermedad infecciosa.
- Se puede descargar desde esta página en Kaggle.
- Puedes encontrar más detalles sobre el conjunto de datos en esta página.
Antes de seguir adelante, es importante considerar la instalación e importación de las siguientes bibliotecas para el éxito de este proyecto.
Utilizando la sentencia %%bash, podemos instalar varias bibliotecas sin utilizar el signo de exclamación (!).
%%bash
pip -q install tiktoken
pip -q install openaiAhora, las bibliotecas se pueden importar de la siguiente manera:
import os
import tiktoken
import numpy as np
import pandas as pd
from openai import OpenAI
from sklearn.metrics.pairwise import cosine_similarityEntendamos el papel de cada biblioteca:
- os: Proporciona una forma de utilizar funciones dependientes del sistema operativo, como leer o escribir en el sistema de archivos.
- tiktoken: Se encarga de las tareas de tokenización específicas del tratamiento de documentos científicos.
- numpy (np): Añade soporte para matrices y arrays multidimensionales de gran tamaño, junto con una gran colección de funciones matemáticas de alto nivel para operar con estos arrays, cruciales para la informática científica.
- pandas (pd): Ofrece estructuras de datos y operaciones para manipular tablas numéricas y series temporales, esenciales para manejar conjuntos de datos científicos.
- openai.OpenAI: Sirve de interfaz con la API de OpenAI, permitiendo la interacción con modelos de aprendizaje automático para tareas como generar incrustaciones para textos científicos.
- sklearn.metrics.pairwise.cosine_similarity: Calcula la similitud coseno entre vectores, útil en el análisis de similitud de documentos científicos.
Exploración de datos
El marco de datos original tiene más de 1 Gb, y sólo se carga una muestra de 1000 observaciones aleatorias por simplicidad.
scientific_docs = pd.read_parquet("./data/cord19_df_sample.parquet")Utilizando la función .head(), podemos ver las 2 primeras filas de los datos, y el resultado está en la animación de abajo.
scientific_docs.head(2)
Dos primeras filas de datos
El cuerpo, el título y el resumen de un documento científico determinado pueden bastar para representarlo. Esos tres atributos se concatenan para obtener una única representación textual de cada documento.
Antes, veamos el porcentaje de valores perdidos en cada una de estas tres columnas:
percent_missing = scientific_docs.isnull().sum() * 100 / len(scientific_docs)
percent_missing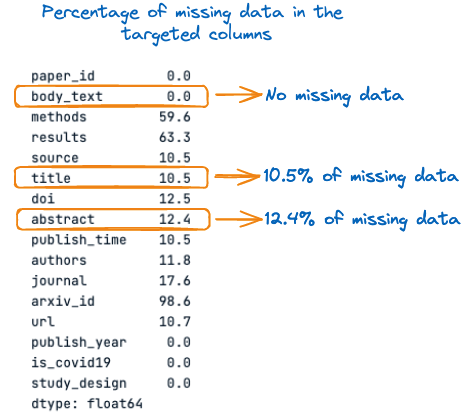
Porcentaje de datos que faltan en las columnas objetivo
En la imagen anterior, podemos observar que el título y el resumen tienen valores ausentes, respectivamente el 10,5% y el 12,4%. Por tanto, es importante rellenar esos valores perdidos con cadenas vacías antes de la concatenación para evitar la pérdida de información.
El proceso global de rellenar los valores que faltan y concatenar las columnas se realiza mediante la siguiente función.
def concatenate_columns_with_null_handling(df, body_text_column,
abstract_column,
title_column,
new_col_name):
df[new_col_name] = df[body_text_column].fillna('') + df[abstract_column].fillna('') + df[title_column].fillna('')
return dfTras ejecutar la función de concatenación en los datos originales y comprobar las 3 primeras filas, podemos observar que la concatenación se ha realizado correctamente.
new_scientific_docs = concatenate_columns_with_null_handling(scientific_docs,
"body_text",
"abstract",
"title",
"concatenated_text")new_scientific_docs.head(3)La nueva columna añadida es texto_concatenado.
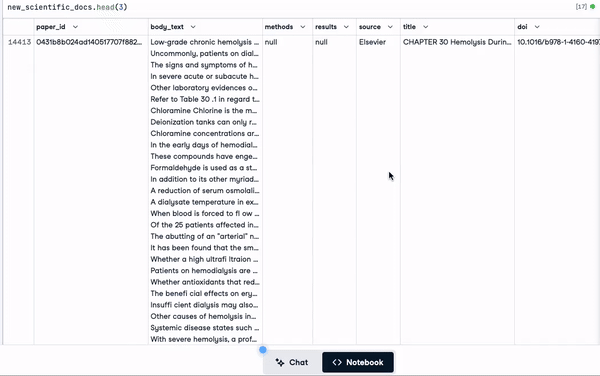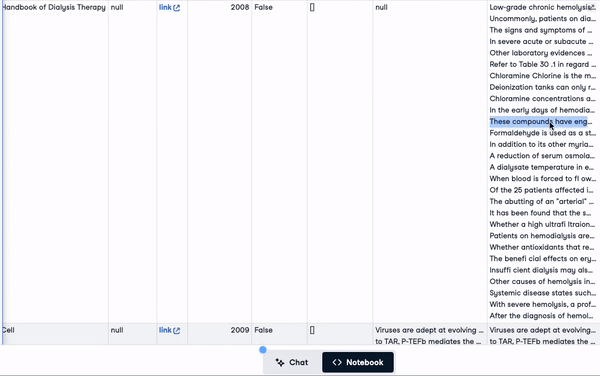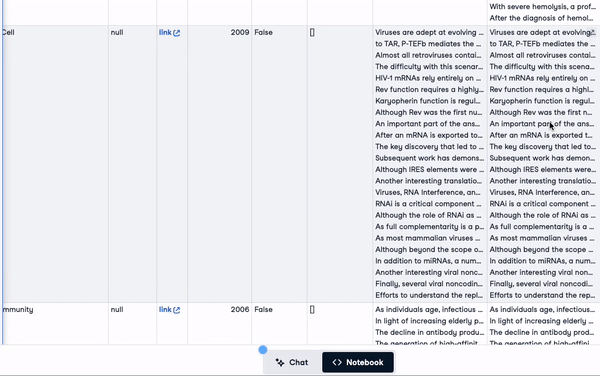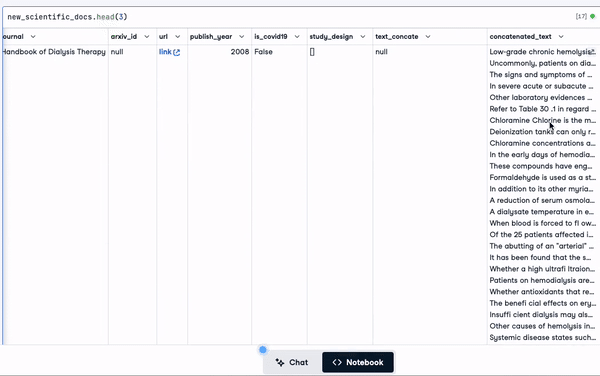
Las 3 primeras filas con la nueva columna añadida
El siguiente paso es aplicar las incrustaciones en la nueva columna utilizando los distintos modelos de incrustación mencionados en este artículo. Pero antes veamos la distribución de la longitud de las fichas.
El objetivo de este análisis es cotejar la limitación máxima de tokens del modelo con el número real de tokens de un documento determinado.
Pero primero tenemos que contar el número total de tokens que hay en cada documento, y eso se consigue utilizando la función de ayuda num_tokens_from_text y el codificador cl100k_base.
def num_tokens_from_text(text: str, encoding_name="cl100k_base"):
"""
Returns the number of tokens in a text string.
"""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(text))
return num_tokensAntes de aplicar la función al conjunto de datos, veamos cómo funciona con el texto siguiente: Este artículo trata sobre las nuevas incrustaciones de OpenAI.
text = "This article is about new OpenAI Embeddings"
num_tokens = num_tokens_from_text(text)
print(f"Number of tokens: {num_tokens}")Tras ejecutar correctamente el código anterior, podemos ver que el texto tiene 10 tokens.
![]()
Número de fichas del texto
Con confianza, podemos aplicar la función a todo el texto del marco de datos utilizando la expresión lambda del siguiente modo:
new_scientific_docs['num_tokens'] = new_scientific_docs["concatenated_text"].apply(lambda x: num_tokens_from_text(x))Podemos contar el número total de documentos que tienen más de 8191 tokens filtrando todo el número de tokens y comprobando cuál es superior al límite real de tokens de 8191.
smaller_tokens_docs = new_scientific_docs[new_scientific_docs['num_tokens'] <= 8191]
len(smaller_tokens_docs)⇒ Salida: 764
Esto significa que 764 documentos de 1000 cumplen el requisito del límite máximo de tokens, y vamos a utilizar esos documentos para simplificar.
Se pueden aplicar técnicas avanzadas para procesar el conjunto restante de documentos que tienen más de 8191 tokens.
Una de esas técnicas consiste en tomar la media de todas las incrustaciones de un mismo documento. Otra técnica consiste en tomar los 8191 primeros tokens del documento. Este enfoque no es eficaz porque puede provocar una pérdida de información.
Asegurémonos de restablecer el índice del marco de datos para que empiece de cero.
smaller_tokens_docs_reset = smaller_tokens_docs.reset_index(drop=True)Ejecutar incrustaciones
Se satisfacen todos los requisitos para obtener la representación de incrustación de todos los documentos, y esto se hace para cada modelo de incrustación.
El primer paso consiste en adquirir la credencial OpenAI y configurar el cliente como se indica a continuación:
os.environ["OPENAI_API_KEY"] = "YOUR KEY"
client = OpenAI()A continuación, la siguiente función de ayuda ayuda a generar la incrustación proporcionando el modelo de incrustación y el texto que se va a incrustar.
def get_embedding(text_to_embbed, model_ID):
text = text_to_embbed.replace("\n", " ")
return client.embeddings.create(input = [text_to_embbed],
model=model_ID).data[0].embeddingAhora se crea un nuevo marco de datos con tres columnas adicionales correspondientes a la incrustación de cada uno de los tres modelos :
- text-embedding-3-small
- text-embedding-3-large
- text-embedding-ada-002
smaller_tokens_docs_reset['text-embedding-3-small'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-3-small"))
smaller_tokens_docs_reset['text-embedding-3-large'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-3-large"))
smaller_tokens_docs_reset['text-embedding-ada-002'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-ada-002"))Tras ejecutar correctamente el código anterior, podemos ver que se han añadido las columnas de incrustación correspondientes.
smaller_tokens_docs_reset.head(1)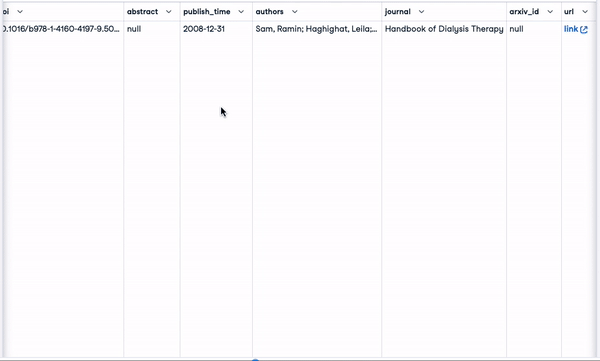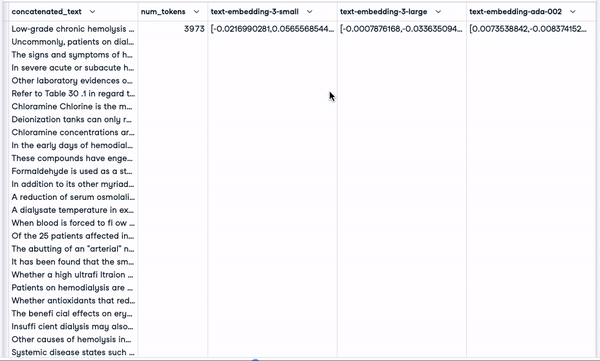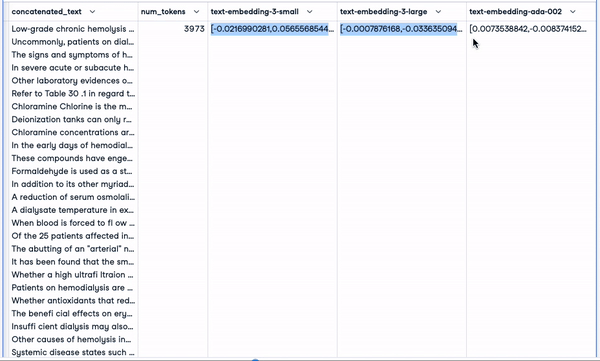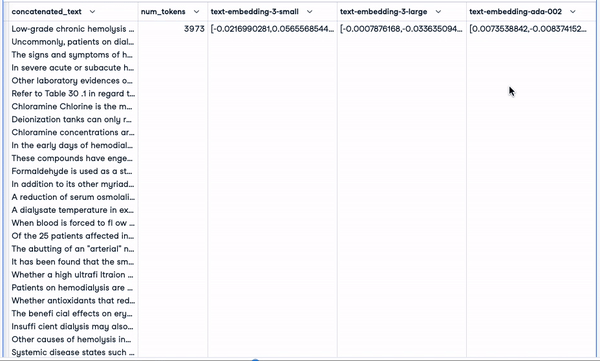
Nuevo marco de datos con columnas de incrustación relevantes
Búsqueda por similitud
Esta sección utiliza la técnica de similitud del coseno con cada uno de los enfoques de incrustación anteriores para encontrar los 3 documentos más similares a ese documento concreto.
La siguiente función de ayuda toma cuatro parámetros principales:
- El marco de datos actual
- El índice del texto del que queremos encontrar los documentos más parecidos
- La incrustación específica que debe utilizarse
- Los documentos más similares que queremos, y es el 3 por defecto.
def find_top_N_similar_documents(df, chosen_index,
embedding_column_name,
top_N=3):
chosen_document_embedding = np.array(df.iloc[chosen_index][embedding_column_name]).reshape(1, -1)
embedding_matrix = np.vstack(df[embedding_column_name])
similarity_scores = cosine_similarity(chosen_document_embedding, embedding_matrix)[0]
df_temp = df.copy()
df_temp['similarity_to_chosen'] = similarity_scores
similar_documents = df_temp.drop(index=chosen_index).sort_values(by='similarity_to_chosen', ascending=False)
top_N_similar = similar_documents.head(top_N)
return top_N_similar[[concatenated_text, 'similarity_to_chosen']]A continuación, buscamos los documentos más parecidos al primer documento (índice=0)
Este es el aspecto del primer documento:
chosen_index = 0
first_document_data = smaller_tokens_docs_reset.iloc[0]["concatenated_text"]
print(first_document_data)
Contenido del primer documento (versión concatenada)
La función de búsqueda de similitudes puede ejecutarse del siguiente modo:
top_3_similar_3_small = find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-3-small")
top_3_similar_3_large= find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-3-large")
top_3_similar_ada_002 = find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-ada-002")Tras procesar las tareas de similitud, el resultado puede mostrarse como sigue:
print("Top 3 Similar Documents with :")
print("--> text-embedding-3-small")
print(top_3_similar_3_small)
print("\n")
print("--> text-embedding-3-large")
print(top_3_similar_3_large)
print("\n")
print("--> text-embedding-ada-002")
print(top_3_similar_ada_002)
print("\n")
Los 3 documentos más similares utilizando cada modelo de incrustación
Observación del resultado
El modelo "texto-incrustado-3-pequeño" muestra puntuaciones de similitud moderadas en torno a 0,54, mientras que el "texto-incrustado-3-grande" tiene puntuaciones ligeramente superiores, lo que indica una mejor captura de la similitud.
El modelo "texto-incrustado-ada-002" muestra puntuaciones de similitud significativamente más altas, con la puntuación máxima cercana a 0,85, lo que sugiere una similitud muy fuerte con el documento elegido.
Sin embargo, el Documento 372 es un resultado superior común en todos los modelos, lo que indica su relevancia constante para la consulta. Las puntuaciones variables entre modelos ponen de manifiesto el impacto de la elección del modelo de incrustación en los resultados de similitud.
Conclusión
En conclusión, los nuevos modelos text-embedding-3-large y text-embedding-3-small de OpenAI representan un salto significativo en el ámbito del procesamiento del lenguaje natural, al ofrecer una representación más matizada y de alta dimensión de los datos textuales.
Como se demuestra en el artículo, la elección entre estos modelos puede influir sustancialmente en el resultado de varias tareas de PNL, como la similitud de documentos, el análisis de sentimientos y los sistemas de apoyo multilingüe. Mientras que el text-embedding-3-grande proporciona una mayor precisión debido a sus mayores dimensiones, el text-embedding-3-pequeño ofrece un equilibrio entre eficacia y rendimiento para aplicaciones sensibles a los costes.
El análisis comparativo reveló que la incrustación de texto-3-grande supera a sus predecesoras, estableciendo un nuevo estándar en este campo. Las aplicaciones de estos modelos en el mundo real son enormes, y van desde mejorar la atención al cliente hasta potenciar sofisticados motores de búsqueda y sistemas de recomendación de contenidos.
Navegando por la guía detallada que se proporciona, los profesionales del campo estarán equipados para tomar decisiones informadas sobre qué modelo utilizar en función de la complejidad de la tarea, las limitaciones presupuestarias y la necesidad de capacidades multilingües.
En última instancia, la elección del modelo debería ajustarse a las exigencias específicas del proyecto en cuestión, aprovechando los puntos fuertes de la incrustación de texto-3-grande para tareas que requieran una gran fidelidad y de la incrustación de texto-3-pequeña para fines más generales. La aparición de estos modelos subraya el compromiso de OpenAI con el avance de la tecnología de IA y la evolución continua de las herramientas de aprendizaje automático.
¿Qué hacer a partir de ahora?
Nuestro artículo, La API OpenAI en Python, es una hoja de trucos que te ayuda a aprender lo básico para aprovechar una de las API de IA más potentes que existen, la API OpenAI.
Nuestra sesión de código "Ajuste fino de GPT3. 5 con la API de OpenAI" proporciona las guías para utilizar la API de OpenAI y Python para empezar a ajustar GPT3.5, ayudando a aprender cuándo puede ser beneficioso ajustar modelos lingüísticos de gran tamaño, cómo utilizar las herramientas de ajuste fino de la API de OpenAI y, por último, comprender el flujo de trabajo del ajuste fino.
