Die Landschaft des maschinellen Lernens und der natürlichen Sprachverarbeitung (NLP) entwickelt sich ständig weiter, wobei OpenAI immer wieder den Weg zu Innovationen weist.
Die Einführung der Modelle text-embedding-3-large und text-embedding-3-small läutet eine neue Ära in diesem Bereich ein und wird die Art und Weise verändern, wie Entwickler und KI-Praktiker an Textanalyse und Einbettungsaufgaben herangehen.
In der komplexen Welt der künstlichen Intelligenz sind Einbettungen entscheidend, um komplizierte menschliche Sprache in etwas zu verwandeln, das Maschinen verstehen und verarbeiten können. Dieses neue Modell von OpenAI ist ein bedeutender Schritt nach vorn für Entwickler und angehende Datenpraktiker.
In diesem Artikel werden die Modelle text-embedding-3-large und text-embedding-3-small erläutert und Einblicke in ihre Kernfunktionen, verschiedene Anwendungen und ihre effektive Nutzung gegeben.
Indem er die Grundlagen der Texteinbettung erforscht und die neuen Funktionen und praktischen Anwendungen des Modells hervorhebt, will der Artikel den Lesern die notwendigen Informationen geben, um dieses fortschrittliche Werkzeug in ihren Projekten einzusetzen.
Außerdem werden die Grundlagen für den Einstieg in das Modell behandelt, Tipps zur Verbesserung von Einbettungsaufgaben gegeben und die weitreichenden Auswirkungen dieses technologischen Fortschritts auf den NLP-Bereich diskutiert.
Texteinbettungen verstehen
Bevor wir uns mit den Besonderheiten des neuen Modells befassen, ist ein kurzer Überblick über Texteinbettungen nützlich für ein besseres Verständnis.
Texteinbettungen sind numerische Darstellungen von Texten, die die Semantik oder Bedeutung von Wörtern, Sätzen oder ganzen Dokumenten erfassen. Sie sind grundlegend für viele NLP-Aufgaben, wie z.B. Sentimentanalyse, Textklassifizierung und mehr.
Unsere Einführung in Texteinbettungen mit der OpenAI API bietet eine vollständige Anleitung zur Verwendung der OpenAI API für die Erstellung von Texteinbettungen. Entdecke ihre Anwendungen in den Bereichen Textklassifizierung, Information Retrieval und semantische Ähnlichkeitserkennung.
Unten siehst du eine Illustration anhand eines Einbettungsmodells:
- Die darzustellenden Dokumente sind auf der linken Seite
- Das Einbettungsmodell in der Mitte, und
- Die entsprechenden Einbettungen jedes Dokuments sind auf der rechten Seite

Illustration von Texteinbettungen
Für diejenigen, die mit diesem Konzept noch nicht vertraut sind, empfehlen wir unseren Kurs Einführung in Embeddings mit der OpenAI API. Es wird erklärt, wie du die OpenAI-Einbettungen über die OpenAI-API nutzen kannst, um Einbettungen aus Textdaten zu erstellen und mit der Entwicklung realer Anwendungen zu beginnen.
Neue OpenAI Embeddings auf einen Blick
Diese am 25. Januar 2024 angekündigten Modelle sind die neuesten und leistungsstärksten Einbettungsmodelle, die entwickelt wurden, um Text im hochdimensionalen Raum darzustellen und so ein besseres Verständnis von Text zu ermöglichen.
Das text-embedding-3-small ist für Latenz und Speicherung optimiert. Andererseits ist text-embedding-3-large eine gute Option für eine höhere Genauigkeit, und wir können auch den neuen Dimensions-Parameter nutzen, um die Einbettung bei 1536 statt der nativen Größe von 3072 zu halten, ohne die Gesamtleistung zu beeinträchtigen.
Benchmarking-Analyse
Vor der Veröffentlichung stand das text-embedding-ada-2 an der Spitze aller bisherigen OpenAI-Einbettungsmodelle. Die folgende Tabelle gibt einen schnellen Überblick über das Benchmarking zwischen diesen drei Modellen.
|
Modell |
Dimension |
Max Token |
Wissensabgrenzung |
Preisgestaltung ($/1k Token) |
MIRACL-Durchschnitt |
MTEB-Durchschnitt |
|
ada v2 |
1536 |
8191 |
September 2021 |
0.0001 |
31.4 |
61.0 |
|
text-embedding-3-small |
0.00002 |
44.0 |
62.3 |
|||
|
text-embedding-3-large |
3072 |
0.00013 |
54.9 |
64.6 |
Anhand der bereitgestellten Metriken können wir eine Leistungsverbesserung von ada v2 (text-embedding-ada-002) zu text-embedding-3-large bei den beiden Benchmarks MIRACL und MTEB feststellen. Dies deutet darauf hin, dass text-embedding-3-large mit mehr Dimensionen (3072) eine bessere Einbettungsqualität bietet als die anderen beiden, was direkt mit den besseren Benchmark-Ergebnissen korreliert.
Die Zunahme der Dimensionen von text-embedding-ada-002 und text-embedding-3-small (beide 1536) zu text-embedding-3-large (3072) deutet auf ein komplexeres Modell hin, das eine größere Anzahl von Merkmalen in seinen Einbettungen erfassen kann. Allerdings ist dies auch mit einem höheren Preis pro 1.000 verarbeitete Token verbunden, was auf einen Kompromiss zwischen Leistung und Kosten hinweist.
Je nach den spezifischen Anforderungen einer Aufgabe (z. B. dem Bedarf an Mehrsprachigkeit, der Komplexität des einzubettenden Textes oder Budgetbeschränkungen) kann man ein anderes Modell wählen.
Für Aufgaben, die qualitativ hochwertige Einbettungen für mehrere Sprachen und Aufgaben erfordern, könnte text-embedding-3-large trotz seiner höheren Kosten vorzuziehen sein. Für Anwendungen, bei denen das Budget knapper ist oder bei denen es nicht so sehr auf höchste Präzision ankommt, könnten dagegen text-embedding-ada-002 oder text-embedding-3-small die geeigneteren Optionen sein.
Anwendungen von Text-Embedding-3-Large
Einbettungstechnologien haben sich für viele moderne Anwendungen zur Verarbeitung und zum Verstehen natürlicher Sprache als äußerst nützlich erwiesen. Die Wahl zwischen leistungsfähigeren Modellen wie text-embedding-3-large und kostengünstigeren Optionen wie text-embedding-3-small kann die Leistung und Kosteneffizienz von NLP-Anwendungen beeinflussen.
Im Folgenden werden drei Anwendungsfälle für beide Modelle vorgestellt, die ihre Vielseitigkeit und ihre Auswirkungen in realen Szenarien zeigen.
Anwendungen von text-embedding-3-large
Anwendungen von text-embedding-3-large (mit GPT-4 erzeugte Bilder)
Automatisierung des mehrsprachigen Kundensupports
Mit seiner überragenden Leistung beim Verstehen und Verarbeiten von 18 verschiedenen Sprachen kann text-embedding-3-large Chatbots für den Kundensupport und automatische Antwortsysteme für globale Unternehmen antreiben und so eine genaue, kontextbezogene Unterstützung über verschiedene Sprachgrenzen hinweg gewährleisten.
Erweiterte semantische Suchmaschinen
Durch die hochdimensionale Einbettung kann text-embedding-3-large die Algorithmen von Suchmaschinen verbessern, so dass sie die Nuancen von Suchanfragen besser verstehen und relevantere, kontextbezogene Ergebnisse abrufen können, insbesondere in spezialisierten Bereichen wie der juristischen oder medizinischen Forschung.
Sprachübergreifende Inhaltsempfehlungssysteme
Für Plattformen, die eine Vielzahl mehrsprachiger Inhalte anbieten, wie z.B. Streaming-Dienste oder Nachrichten-Aggregatoren, kann text-embedding-3-large die Vorlieben und Inhalte der Nutzer/innen in mehreren Sprachen analysieren und den Nutzer/innen unabhängig von Sprachbarrieren hochrelevante Inhalte empfehlen.
Anwendungen von text-embedding-3-small

Anwendungen von text-embedding-3-small (Bild erzeugt mit GPT-4)
Kostengünstige Stimmungsanalyse
Für Startups und mittelständische Unternehmen, die die Stimmung ihrer Kunden durch Social-Media-Monitoring oder Feedback-Analysen verstehen wollen, bietet text-embedding-3-small eine budgetfreundliche und dennoch effektive Lösung, um die öffentliche Meinung und die Kundenzufriedenheit zu messen.
Skalierbare Kategorisierung von Inhalten
Content-Plattformen mit großen Datenmengen, wie Blogs oder E-Commerce-Seiten, können text-embedding-3-small nutzen, um Inhalte oder Produkte automatisch zu kategorisieren. Durch seine Effizienz und die geringeren Kosten ist es ideal für die Bearbeitung großer Datenmengen, ohne dass die Genauigkeit darunter leidet.
Effiziente Tools zum Sprachenlernen
Bildungs-Apps, die skalierbare und kosteneffiziente Lösungen für Sprachlernübungen benötigen, wie z. B. das Zuordnen von Wörtern zu Bedeutungen oder die Überprüfung der Grammatik, können von text-embedding-3-small profitieren. Sein ausgewogenes Verhältnis von Leistung und Erschwinglichkeit unterstützt die Entwicklung interaktiver, sprachorientierter Bildungsinhalte.
Diese Anwendungen zeigen, wie text-embedding-3-large und text-embedding-3-small in verschiedenen Bereichen optimal eingesetzt werden können, indem ihre Stärken mit den spezifischen Anforderungen der jeweiligen Anwendung in Einklang gebracht werden, um die Leistung, das Nutzererlebnis und die Kosteneffizienz zu verbessern.
Eine Schritt-für-Schritt-Anleitung zur Verwendung der neuen OpenAI Embeddings
Wir haben jetzt alle Werkzeuge, die wir brauchen, um mit der Implementierung von text-embedding-3-large, text-embedding-3-small und ada-v2 in einem Szenario der Dokumentenähnlichkeit fortzufahren.
Der gesamte Code in diesem Lernprogramm ist in einer DataLab-Arbeitsmappe verfügbar. Erstelle eine Kopie dieser Arbeitsmappe, um den Code auszuführen, ohne dass du etwas auf deinem Computer installieren musst.
Über die Daten
- Dies ist der CORD-19-Datensatz, eine Ressource mit über 59.000 wissenschaftlichen Artikeln, davon über 48.000 mit Volltext, über COVID-19, SARS-CoV-2 und verwandte Coronaviren.
- Diese Daten wurden vom Weißen Haus und einer Koalition führender Forschungsgruppen frei zugänglich gemacht, um die globale Forschung bei der Gewinnung von Erkenntnissen für den laufenden Kampf gegen diese Infektionskrankheit zu unterstützen.
- Es kann von dieser Seite auf Kaggle heruntergeladen werden.
- Weitere Informationen über den Datensatz findest du auf dieser Seite.
Bevor du weitermachst, ist es für den Erfolg dieses Projekts wichtig, dass du die folgenden Bibliotheken installierst und importierst.
Mit der %%bash-Anweisung können wir mehrere Bibliotheken installieren, ohne das Ausrufezeichen (!) zu verwenden.
%%bash
pip -q install tiktoken
pip -q install openaiJetzt können die Bibliotheken wie folgt importiert werden:
import os
import tiktoken
import numpy as np
import pandas as pd
from openai import OpenAI
from sklearn.metrics.pairwise import cosine_similarityLasst uns die Rolle der einzelnen Bibliotheken verstehen:
- os: Bietet eine Möglichkeit, betriebssystemabhängige Funktionen wie das Lesen oder Schreiben im Dateisystem zu nutzen.
- tiktoken: Erledigt Tokenisierungsaufgaben, die speziell für die Verarbeitung wissenschaftlicher Dokumente gelten.
- numpy (np): Unterstützt große, mehrdimensionale Arrays und Matrizen sowie eine große Sammlung mathematischer Funktionen, die mit diesen Arrays arbeiten und für wissenschaftliche Berechnungen wichtig sind.
- pandas (pd): Bietet Datenstrukturen und Operationen für die Bearbeitung von numerischen Tabellen und Zeitreihen, die für den Umgang mit wissenschaftlichen Datensätzen unerlässlich sind.
- openai.OpenAI: Dient als Schnittstelle zur API von OpenAI und ermöglicht die Interaktion mit maschinellen Lernmodellen für Aufgaben wie die Erstellung von Einbettungen für wissenschaftliche Texte.
- sklearn.metrics.pairwise.cosine_similarity: Berechnet die Kosinusähnlichkeit zwischen Vektoren, die bei der Ähnlichkeitsanalyse von wissenschaftlichen Dokumenten nützlich ist.
Datenexploration
Der ursprüngliche DataFrame ist mehr als 1 GB groß, und der Einfachheit halber wird nur eine Stichprobe von 1000 zufälligen Beobachtungen geladen.
scientific_docs = pd.read_parquet("./data/cord19_df_sample.parquet")Mit der Funktion .head() können wir die ersten 2 Zeilen der Daten sehen, und das Ergebnis siehst du in der Animation unten.
scientific_docs.head(2)
Die ersten beiden Zeilen der Daten
Der Hauptteil, der Titel und die Zusammenfassung eines wissenschaftlichen Dokuments können ausreichen, um dieses Dokument darzustellen. Diese drei Attribute werden miteinander verknüpft, um eine einzige Textdarstellung für jedes Dokument zu erhalten.
Vorher wollen wir uns noch den Prozentsatz der fehlenden Werte in jeder dieser drei Spalten ansehen:
percent_missing = scientific_docs.isnull().sum() * 100 / len(scientific_docs)
percent_missing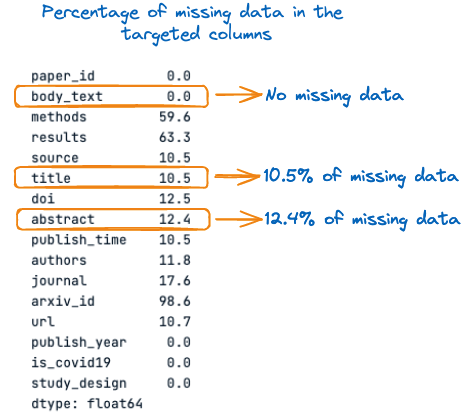
Prozentsatz der fehlenden Daten in den Zielspalten
Aus dem obigen Bild geht hervor, dass im Titel und in der Zusammenfassung 10,5 % bzw. 12,4 % der Werte fehlen. Daher ist es wichtig, diese fehlenden Werte vor der Verkettung mit leeren Zeichenfolgen zu füllen, um Informationsverluste zu vermeiden.
Der gesamte Prozess des Auffüllens der fehlenden Werte und der Verkettung der Spalten wird mit der folgenden Funktion durchgeführt.
def concatenate_columns_with_null_handling(df, body_text_column,
abstract_column,
title_column,
new_col_name):
df[new_col_name] = df[body_text_column].fillna('') + df[abstract_column].fillna('') + df[title_column].fillna('')
return dfNachdem wir die Verkettungsfunktion auf die Originaldaten angewendet und die ersten 3 Zeilen überprüft haben, können wir feststellen, dass die Verkettung erfolgreich war.
new_scientific_docs = concatenate_columns_with_null_handling(scientific_docs,
"body_text",
"abstract",
"title",
"concatenated_text")new_scientific_docs.head(3)Die neu hinzugefügte Spalte heißt concatenated_text.
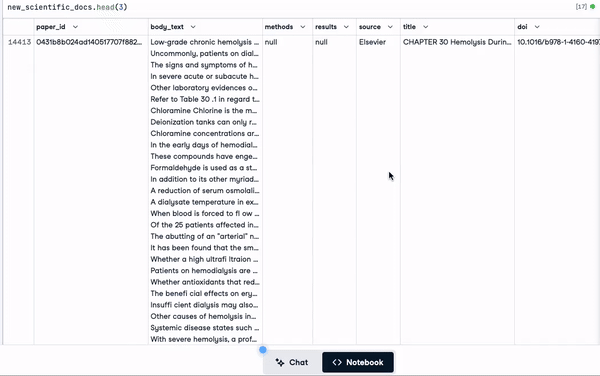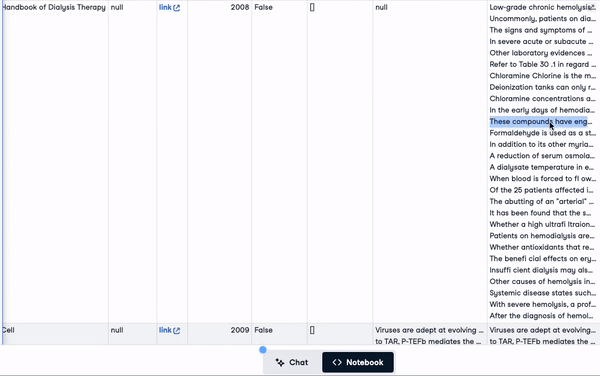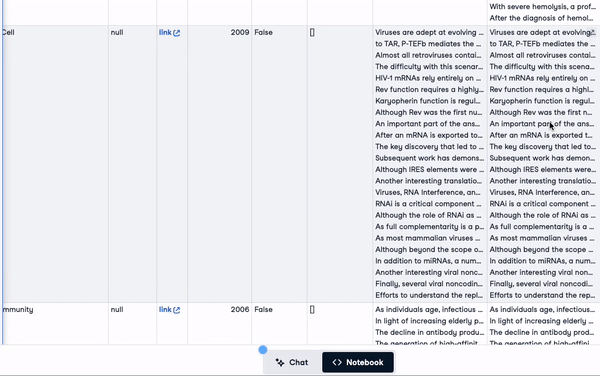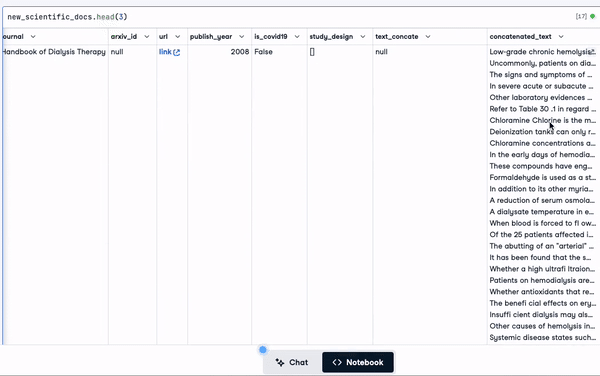
Die ersten 3 Zeilen mit der neu hinzugefügten Spalte
Der nächste Schritt besteht darin, die Einbettungen auf die neue Spalte anzuwenden und dabei die verschiedenen in diesem Artikel erwähnten Einbettungsmodelle zu verwenden. Aber vorher wollen wir uns noch die Verteilung der Länge der Token ansehen.
Das Ziel dieser Analyse ist es, die maximale Token-Begrenzung des Modells mit der tatsächlichen Anzahl von Token in einem bestimmten Dokument zu vergleichen.
Aber zuerst müssen wir die Gesamtzahl der Token in jedem Dokument zählen. Das erreichen wir mit der Hilfsfunktion num_tokens_from_text und dem cl100k_base-Encoder.
def num_tokens_from_text(text: str, encoding_name="cl100k_base"):
"""
Returns the number of tokens in a text string.
"""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(text))
return num_tokensBevor wir die Funktion auf den gesamten Datensatz anwenden, wollen wir sehen, wie sie mit dem folgenden Text funktioniert: In diesem Artikel geht es um neue OpenAI Embeddings.
text = "This article is about new OpenAI Embeddings"
num_tokens = num_tokens_from_text(text)
print(f"Number of tokens: {num_tokens}")Nachdem wir den obigen Code erfolgreich ausgeführt haben, können wir sehen, dass der Text 10 Token hat.
![]()
Anzahl der Token im Text
Wenn wir uns sicher sind, können wir die Funktion auf den gesamten Text im DataFrame anwenden, indem wir den Lambda-Ausdruck wie folgt verwenden:
new_scientific_docs['num_tokens'] = new_scientific_docs["concatenated_text"].apply(lambda x: num_tokens_from_text(x))Wir können die Gesamtzahl der Dokumente zählen, die mehr als 8191 Token enthalten, indem wir alle Token filtern und prüfen, welche über der tatsächlichen Tokengrenze von 8191 liegen.
smaller_tokens_docs = new_scientific_docs[new_scientific_docs['num_tokens'] <= 8191]
len(smaller_tokens_docs)⇒ Ausgang: 764
Das bedeutet, dass 764 von 1000 Dokumenten die Anforderung der maximalen Token-Grenze erfüllen, und wir verwenden diese Dokumente der Einfachheit halber.
Die verbleibenden Dokumente, die mehr als 8191 Token enthalten, können mit fortgeschrittenen Techniken bearbeitet werden.
Eine dieser Techniken besteht darin, den Durchschnitt aller Einbettungen eines einzelnen Dokuments zu ermitteln. Eine andere Technik besteht darin, die ersten 8191 Token des Dokuments zu nehmen. Dieser Ansatz ist nicht effizient, weil er zu Informationsverlusten führen kann.
Stellen wir sicher, dass wir den Index des DataFrames zurücksetzen, damit er bei Null beginnt.
smaller_tokens_docs_reset = smaller_tokens_docs.reset_index(drop=True)Einbettungen ausführen
Alle Anforderungen werden erfüllt, um die Einbettungsrepräsentation aller Dokumente zu erhalten, und dies geschieht für jedes Einbettungsmodell.
Der erste Schritt besteht darin, die OpenAI-Zugangsdaten zu erwerben und den Client wie folgt zu konfigurieren:
os.environ["OPENAI_API_KEY"] = "YOUR KEY"
client = OpenAI()Dann hilft die folgende Hilfsfunktion dabei, die Einbettung zu erstellen, indem sie das Einbettungsmodell und den einzubettenden Text bereitstellt.
def get_embedding(text_to_embbed, model_ID):
text = text_to_embbed.replace("\n", " ")
return client.embeddings.create(input = [text_to_embbed],
model=model_ID).data[0].embeddingEs wird nun ein neuer DataFrame mit drei zusätzlichen Spalten erstellt, die der Einbettung jedes der drei Modelle entsprechen:
- text-embedding-3-small
- text-embedding-3-large
- text-embedding-ada-002
smaller_tokens_docs_reset['text-embedding-3-small'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-3-small"))
smaller_tokens_docs_reset['text-embedding-3-large'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-3-large"))
smaller_tokens_docs_reset['text-embedding-ada-002'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-ada-002"))Nachdem wir den obigen Code erfolgreich ausgeführt haben, können wir sehen, dass die entsprechenden Einbettungsspalten hinzugefügt wurden.
smaller_tokens_docs_reset.head(1)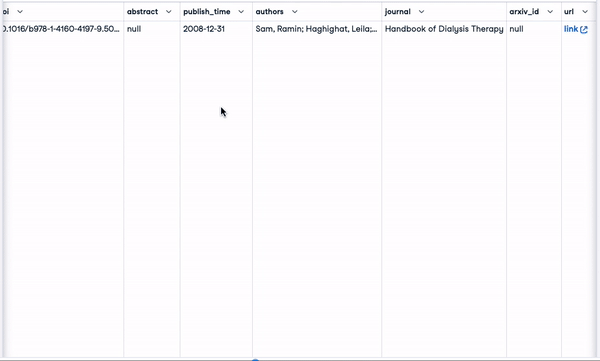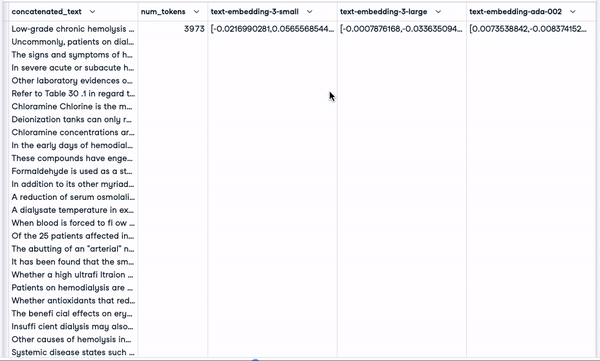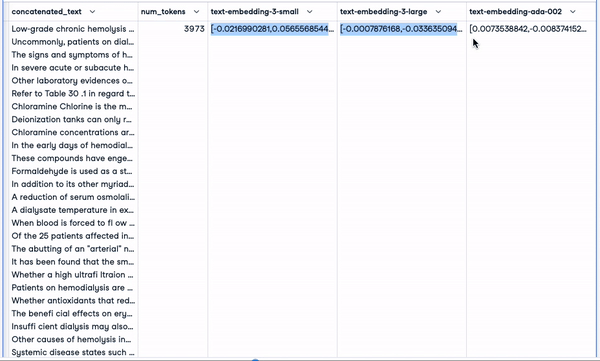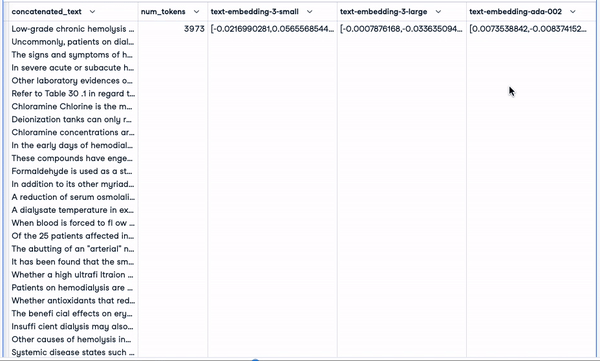
Neuer DataFrame mit relevanten Einbettungsspalten
Ähnlichkeitssuche
In diesem Abschnitt wird die Cosinus-Ähnlichkeitstechnik für jeden der oben genannten Einbettungsansätze verwendet, um die 3 ähnlichsten Dokumente zu einem bestimmten Dokument zu finden.
Die folgende Hilfsfunktion benötigt vier Hauptparameter:
- Der aktuelle DataFrame
- Der Index des Textes, zu dem wir die ähnlichsten Dokumente finden wollen
- Die spezifische Einbettung, die verwendet werden soll
- Wir wollen die ähnlichsten Dokumente, und das sind standardmäßig 3.
def find_top_N_similar_documents(df, chosen_index,
embedding_column_name,
top_N=3):
chosen_document_embedding = np.array(df.iloc[chosen_index][embedding_column_name]).reshape(1, -1)
embedding_matrix = np.vstack(df[embedding_column_name])
similarity_scores = cosine_similarity(chosen_document_embedding, embedding_matrix)[0]
df_temp = df.copy()
df_temp['similarity_to_chosen'] = similarity_scores
similar_documents = df_temp.drop(index=chosen_index).sort_values(by='similarity_to_chosen', ascending=False)
top_N_similar = similar_documents.head(top_N)
return top_N_similar[[concatenated_text, 'similarity_to_chosen']]Im folgenden Abschnitt finden wir die Dokumente, die dem ersten Dokument am ähnlichsten sind (Index=0)
So sieht das erste Dokument aus:
chosen_index = 0
first_document_data = smaller_tokens_docs_reset.iloc[0]["concatenated_text"]
print(first_document_data)
Inhalt des ersten Dokuments (verkettete Version)
Die Ähnlichkeitssuche kann wie folgt durchgeführt werden:
top_3_similar_3_small = find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-3-small")
top_3_similar_3_large= find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-3-large")
top_3_similar_ada_002 = find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-ada-002")Nachdem die Ähnlichkeitsaufgaben bearbeitet wurden, kann das Ergebnis wie folgt angezeigt werden:
print("Top 3 Similar Documents with :")
print("--> text-embedding-3-small")
print(top_3_similar_3_small)
print("\n")
print("--> text-embedding-3-large")
print(top_3_similar_3_large)
print("\n")
print("--> text-embedding-ada-002")
print(top_3_similar_ada_002)
print("\n")
Top 3 der ähnlichsten Dokumente mit jedem Einbettungsmodell
Beobachtung des Ergebnisses
Das Modell "text-embedding-3-small" zeigt moderate Ähnlichkeitswerte um 0,54, während das Modell "text-embedding-3-large" etwas höhere Werte aufweist, was auf eine bessere Erfassung der Ähnlichkeit hindeutet.
Das Modell "text-embedding-ada-002" zeigt deutlich höhere Ähnlichkeitswerte, wobei der Spitzenwert bei 0,85 liegt, was auf eine sehr starke Ähnlichkeit mit dem gewählten Dokument hindeutet.
Das Dokument 372 ist jedoch ein gemeinsames Top-Ergebnis für alle Modelle, was auf seine gleichbleibende Relevanz für die Suchanfrage hindeutet. Die unterschiedlichen Ergebnisse zwischen den Modellen verdeutlichen die Auswirkungen der Wahl des Einbettungsmodells auf die Ähnlichkeitsergebnisse.
Fazit
Zusammenfassend lässt sich sagen, dass die neuen Modelle text-embedding-3-large und text-embedding-3-small von OpenAI einen bedeutenden Sprung im Bereich der Verarbeitung natürlicher Sprache darstellen, da sie eine differenziertere und hochdimensionale Darstellung von Textdaten ermöglichen.
Wie in dem Artikel gezeigt wird, kann die Wahl zwischen diesen Modellen das Ergebnis verschiedener NLP-Aufgaben wie Dokumentenähnlichkeit, Sentimentanalyse und mehrsprachige Unterstützungssysteme erheblich beeinflussen. Während der text-embedding-3-large aufgrund seiner größeren Abmessungen eine höhere Genauigkeit bietet, bietet der text-embedding-3-small ein ausgewogenes Verhältnis von Effizienz und Leistung für kostensensible Anwendungen.
Eine Benchmarking-Analyse ergab, dass das Text-Embedding-3-Large seine Vorgänger übertrifft und einen neuen Standard in diesem Bereich setzt. Die realen Anwendungsmöglichkeiten für diese Modelle sind vielfältig und reichen von der Verbesserung des Kundensupports bis hin zu ausgefeilten Suchmaschinen und Empfehlungssystemen für Inhalte.
Mit Hilfe des detaillierten Leitfadens können die Praktiker vor Ort fundierte Entscheidungen darüber treffen, welches Modell sie je nach Komplexität der Aufgabe, Budgetbeschränkungen und dem Bedarf an Mehrsprachigkeit einsetzen sollten.
Letztendlich sollte sich die Wahl des Modells an den spezifischen Anforderungen des jeweiligen Projekts orientieren und die Stärken von text-embedding-3-large für Aufgaben, die eine hohe Wiedergabetreue erfordern, und text-embedding-3-small für allgemeinere Zwecke nutzen. Die Einführung dieser Modelle unterstreicht das Engagement von OpenAI für die Weiterentwicklung von KI-Technologien und die kontinuierliche Weiterentwicklung von Machine-Learning-Tools.
Wie geht es jetzt weiter?
Unser Artikel Die OpenAI API in Python ist ein Spickzettel, mit dem du die Grundlagen lernst, wie du eine der leistungsfähigsten KI-APIs nutzen kannst, die es gibt: die OpenAI API.
Unsere Code Along Session Feinabstimmung von GPT3.5 mit OpenAI API bietet Anleitungen zur Verwendung von OpenAI API und Python, um mit der Feinabstimmung von GPT3.5 zu beginnen. Sie hilft zu lernen, wann eine Feinabstimmung großer Sprachmodelle von Vorteil sein kann, wie man die Feinabstimmungstools in der OpenAI API verwendet und schließlich den Arbeitsablauf der Feinabstimmung versteht.

