programa
Fundamentos de la IA
10 h
La incrustación de texto (igual que la incrustación de palabras) es una técnica transformadora del procesamiento del lenguaje natural (PLN) que ha mejorado la forma en que las máquinas entienden y procesan el lenguaje humano.
La incrustación de texto convierte el texto en bruto en vectores numéricos, lo que permite a los ordenadores comprenderlo mejor.
La razón es sencilla: los ordenadores sólo piensan en números y no pueden entender palabras humanas de forma independiente. Gracias a las incrustaciones de texto, a los ordenadores les resulta más fácil leer, comprender textos y dar respuestas más precisas a las consultas.
En este artículo, diseccionaremos el significado de la incrustación de texto, su importancia, evolución, casos de uso, principales modelos e intuición.
Las incrustaciones de texto son una forma de convertir palabras o frases de un texto en datos numéricos que una máquina pueda entender. Piensa en ello como convertir un texto en una lista de números, donde cada número capta una parte del significado del texto. Esta técnica ayuda a las máquinas a captar el contexto y las relaciones entre las palabras.
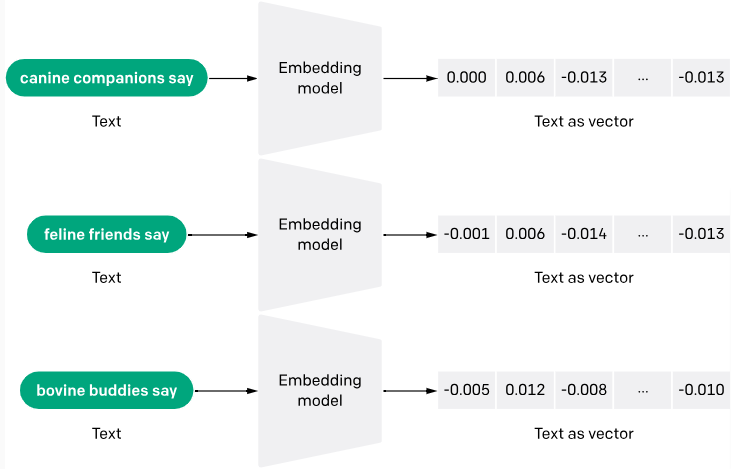
El proceso de generación de incrustaciones de texto suele implicar redes neuronales que aprenden a codificar el significado semántico de las palabras en densos vectores de números reales. Métodos como Word2Vec y GloVe son populares para generar estas incrustaciones mediante el análisis de la concurrencia de palabras dentro de grandes trozos de texto.
Puedes obtener más información sobre la incrustación de texto con la API de OpenAI y ver una aplicación práctica en otro artículo.
Los modelos lingüísticos convencionales consideraban las palabras como unidades independientes. Las incrustaciones de palabras abordan este problema situando las palabras que comparten significados o contextos cerca unas de otras dentro de un espacio multidimensional.
He aquí algunas razones más por las que la incrustación de texto es importante:
Las incrustaciones ayudan a los modelos a generalizar mejor palabras o frases nuevas y desconocidas utilizando el contexto aprendido de los datos de entrenamiento. Esto es especialmente útil en lenguas dinámicas en las que surgen nuevas palabras con frecuencia.
Las incrustaciones se utilizan ampliamente como características en diversas tareas de machine learning, como la clasificación de documentos, el análisis de sentimientos y la traducción automática. Mejoran el rendimiento de los algoritmos al proporcionar una forma rica y condensada de datos que capta las propiedades textuales básicas.
Las incrustaciones de texto son capaces de manejar múltiples idiomas identificando y representando las similitudes semánticas entre estos diferentes idiomas. Un ejemplo es el modelo LaBSE (Language-agnostic BERT Sentence Embedding), que ha demostrado una notable capacidad para producir incrustaciones de frases en 109 idiomas.
Los métodos tradicionales, como la codificación one-hot, pueden generar datos dispersos (sobre todo porque la mayoría de las observaciones tienen valor 0) y vectores de alta dimensión, que resultan ineficaces para vocabularios extensos. Las incrustaciones reducen la dimensionalidad y la complejidad computacional, lo que las hace más adecuadas para manejar datos de texto extensos.
Las incrustaciones de texto son representaciones vectoriales densas de datos textuales, en las que palabras y documentos con significados similares se representan mediante vectores similares en un espacio vectorial de alta dimensión.
La intuición que subyace a las incrustaciones de texto es captar las relaciones semánticas y contextuales entre los elementos del texto, lo que permite a los modelos de machine learning razonar sobre los datos textuales y procesarlos con mayor eficacia.
Una de las principales intuiciones que subyacen a la incrustación de textos es la hipótesis distribucional, según la cual las palabras o frases que aparecen en contextos similares tienden a tener significados similares.
Por ejemplo, tomemos las palabras "rey" y "reina". Aunque no son sinónimos, comparten un contexto similar relacionado con la realeza y la monarquía. Las incrustaciones de texto pretenden captar esta similitud semántica representando estas palabras con vectores próximos en el espacio vectorial.
Otra intuición que subyace a las incrustaciones de texto es la idea de las operaciones en el espacio vectorial. Al representar el texto como vectores numéricos, podemos utilizar operaciones de espacio vectorial como la suma, la resta y la similitud coseno para capturar y manipular las relaciones semánticas entre palabras y frases. Consideremos el siguiente ejemplo:
rey - hombre + mujer ≈ reina
En este ejemplo, la operación vectorial "rey - hombre + mujer" podría dar como resultado un vector muy próximo a la incrustación de "reina", capturando la relación analógica entre estas palabras.
Otra intuición que me gustaría señalar es la reducción de la dimensionalidad en la incrustación de texto. Las representaciones de texto dispersas tradicionales, como la codificación one-hot, pueden tener una dimensionalidad extremadamente alta (igual al tamaño del vocabulario). Por otro lado, las incrustaciones de texto suelen tener una dimensionalidad más baja (por ejemplo, 300 dimensiones), lo que les permite captar las características más destacadas del texto al tiempo que reducen el ruido y la complejidad computacional.
Utilizaré el ejemplo de un restaurante para ilustrar una intuición general de las incrustaciones de palabras:
Imagina que tienes un corpus de reseñas de restaurantes y quieres crear un sistema que clasifique automáticamente el sentimiento de cada reseña como positivo o negativo. Recomiendo utilizar incrustaciones de texto para representar cada reseña como un vector denso, de modo que capte el significado semántico y el sentimiento expresado en el texto.
Veamos dos reseñas:
Reseña 1: "La comida estaba deliciosa y el servicio fue excelente. Recomiendo encarecidamente este restaurante".
Reseña 2: "La comida era mediocre y el servicio deficiente. No volveré".
Aunque estas reseñas no compartan muchas palabras, sus incrustaciones deberían distar unas de otras en el espacio vectorial, reflejando el contraste de los sentimientos expresados. Las palabras de sentimiento positivo como "delicioso" y "excelente" en la Reseña 1 tendrían incrustaciones más cercanas a la región positiva del espacio vectorial, mientras que las palabras de sentimiento negativo como "mediocre" y "deficiente" en la Reseña 2 tendrían incrustaciones más cercanas a la región negativa.
Mediante el entrenamiento de un modelo de machine learning en estas incrustaciones de texto, puedes aprender a asignar los patrones semánticos y la información de sentimiento codificada en las incrustaciones a las etiquetas de sentimiento correspondientes (positivas o negativas), clasificando con precisión nuevas reseñas no vistas.
Según el libro "Embeddings in Natural Language Processing: Theory and Advances in Vector Representations of Meaning" - de Mohammad Taher Pilehvar y José Camacho-Collados, las incrustaciones de texto
"se popularizaron sobre todo después de 2013, con la introducción de Word2vec".
Ese año supuso un gran avance para la incrustación de textos. Sin embargo, la investigación sobre la incrustación de textos se remonta a los años cincuenta. Aunque esta sección no es exhaustiva, abarcaré algunos de los principales hitos en la evolución de la incrustación de textos.
Entre las décadas de 1950 y 2000, métodos como la codificación one-hot y la bolsa de palabras (Bag-of-Words, BoW) eran la norma. Por desgracia, estos métodos no eran muy suficientes y planteaban algunos retos, como:
TF-IDF (Term Frequency-Inverse Document Frequency) fue otro de los primeros intentos en los años 70 de capturar textos como números. Este enfoque calcula el peso de cada palabra no sólo por su frecuencia en un documento específico, sino también por su frecuencia en todos los documentos, asignando valores más altos a las palabras menos comunes. Aunque mejoraba la codificación one-hot al ofrecer más información, seguía quedándose corta a la hora de captar el significado semántico de las palabras.
Según IBM, la década de 2000 empezó con los investigadores,
"explorando los modelos lingüísticos neuronales (NLM), que utilizan redes neuronales para modelar las relaciones entre palabras en un espacio continuo. Estos primeros modelos sentaron las bases para el posterior desarrollo de la incrustación de palabras".
Un ejemplo temprano es la introducción de los "modelos lingüísticos probabilísticos neuronales" por Bengio et al. en torno al año 2000, cuyo objetivo era aprender representaciones distribuidas de las palabras.
Más tarde, en 2013, Word2Vec entró en escena como el modelo revolucionario que introdujo la idea de convertir palabras en vectores numéricos. Estos vectores captaban las similitudes semánticas, de modo que las palabras con significados similares acababan más cerca en el espacio vectorial. Era como crear un mapa de palabras basado en sus relaciones.
En 2014, se presentó GloVe en un documento de investigación titulado "Glove: Global Vectors for Word Representation" de Jeffery Pennington y sus coautores. GloVe mejoró Word2Vec al comprender mejor los significados de las palabras teniendo en cuenta tanto el contexto inmediato de una palabra como el uso general en todo el corpus.
Durante este periodo, salieron a la luz métodos como los mecanismos de atención (2017) y el Aprendizaje por Transferencia y Contexto (2018).
Los mecanismos de atención permiten a los modelos centrarse en partes concretas de una frase y asignarles distintos pesos en función de su importancia. Esto ayudó al modelo a comprender las relaciones entre las palabras y cómo contribuyen a su significado.
Por ejemplo, en esta frase, "El rápido zorro marrón salta sobre el perro perezoso", el mecanismo de atención podría prestar más atención a "rápido" y "salta" a la hora de predecir la siguiente palabra, en comparación con "el" o "marrón".
En cambio, el método Aprendizaje por Transferencia y Contexto acogió favorablemente el uso de modelos preentrenados. Técnicas como ULMFiT y BERT permitieron afinar estos modelos preentrenados para tareas específicas. Esto significaba que se necesitaban menos datos y potencia de cálculo para obtener un alto rendimiento.
La incrustación de API es un enfoque reciente de la incrustación de texto. Aunque puede ser reciente, su aparición gradual se remonta a la década de 2010, cuando las soluciones de IA basadas en la nube y los avances en modelos preentrenados se estaban generalizando.
Avancemos hasta la década de 2020. La adopción de API ha crecido de forma masiva en la comunidad de desarrolladores, y también lo ha hecho la incrustación de API. Una API de incrustación facilita la obtención de textos mediante modelos preformados.
Un buen ejemplo de API de incrustación es la API de incrustación de OpenAI. OpenAI presentó su API de incrustación con importantes actualizaciones en diciembre de 2022. Esta API ofrece un modelo unificado conocido como text-embedding-ada-002, que integra capacidades de varios modelos anteriores en un único modelo. Este modelo se ha diseñado para sobresalir en tareas como la búsqueda de texto, la búsqueda de códigos y la similitud de frases.
Analicemos algunos casos de uso de la incrustación de texto.
Las incrustaciones de palabras permiten a los motores de búsqueda comprender el significado subyacente de su consulta y encontrar documentos relevantes, aunque no contengan las palabras exactas utilizadas. Esto es especialmente útil para búsquedas ambiguas o para encontrar contenidos similares.
Las plataformas de comercio electrónico, las redes sociales y los servicios de streaming son ejemplos comunes de aplicaciones que utilizan incrustaciones de texto para recomendar productos o contenidos basándose en preferencias anteriores. Analizando las descripciones y reseñas de los artículos con los que has interactuado, pueden sugerirte productos similares que podrían interesarte.
Meta (Facebook) utiliza incrustaciones de texto para su búsqueda social. Puedes obtener más información en este resumen.
La incrustación de textos va más allá de la traducción de palabras una a una. Tiene en cuenta el contexto y el significado del texto, lo que da lugar a traducciones más precisas y naturales.
Los chatbots con incrustación de texto pueden entender la intención de las preguntas y responder de forma más razonable y atractiva. Pueden analizar el sentimiento del mensaje y ajustar su estilo de comunicación en consecuencia.
Las incrustaciones de palabras pueden utilizarse para generar distintos formatos de texto creativos, como descripciones de productos o publicaciones en redes sociales. Las marcas también pueden utilizar las incrustaciones de texto para analizar las conversaciones en las redes sociales y comprender el sentimiento de los clientes hacia sus productos o servicios.
A continuación te presentamos los mejores modelos de incrustación de texto, tanto de código abierto como de código cerrado:
Como ya hemos comentado, Word2Vec es uno de los modelos pioneros de incrustación de texto. Fue desarrollado por Tomas Mikolov y sus colegas de Google. Word2Vec utiliza redes neuronales poco profundas para generar vectores de palabras que capturan las similitudes semánticas.
Word2Vec utiliza dos arquitecturas de modelos: Continuous Bag-of-Words (CBOW) y Skip-Gram. CBOW predice una palabra basándose en el contexto que la rodea, mientras que Skip-Gram predice las palabras circundantes basándose en una palabra dada. Este proceso ayuda a codificar las relaciones semánticas entre las palabras.
Librerías populares de procesamiento del lenguaje natural (PLN) como Gensim y spaCY ofrecen implementaciones de Word2Vec. Puedes encontrar la versión de código abierto de Word2vec alojada en Google y publicada bajo la licencia Apache 2.0.
GloVe, de Stanford, es otro modelo muy utilizado. Se centra en captar tanto el contexto local como el global mediante el análisis de las estadísticas de concurrencia de palabras dentro de un gran corpus de textos. GloVe construye una matriz de concurrencia de palabras y luego la factoriza para obtener vectores de palabras. Este proceso tiene en cuenta las concurrencias de palabras cercanas y lejanas, lo que conduce a una comprensión global del significado de las palabras.
GloVe también es de código abierto. Los vectores GloVe preentrenados están disponibles para su descarga, y también se pueden encontrar implementaciones en bibliotecas como Gensim.
FastText, desarrollado por Facebook (ahora Meta), es una extensión de Word2Vec que resuelve la limitación de no manejar palabras fuera de vocabulario (out-of-vocabulary, OOV). Incorpora información de subpalabras para representar palabras, lo que permite crear incrustaciones de palabras no vistas.
FastText descompone las palabras en n-gramas de caracteres (subpalabras). De forma similar a Word2Vec, entrena vectores de palabras basados en estas unidades de subpalabras. Esto permite al modelo representar nuevas palabras basándose en el significado de las subpalabras que las componen.
FastText es de código abierto y está disponible a través de la biblioteca FastText. También se pueden descargar vectores FastText preformados para varios idiomas.
La incrustación v3 (Text-embedding-3) es la última versión de los modelos de incrustación de OpenAIs. Los modelos vienen en dos clases: text-embedding-3-small (el modelo más pequeño) y text-embedding-3-large (el modelo más grande). Son de código cerrado y se necesita una API de pago para acceder a ellas.
Los modelos Text-embedding-3 transforman el texto en representaciones numéricas descomponiéndolo primero en tokens (palabras o subpalabras). Cada ficha se asigna a un vector en un espacio de alta dimensión. A continuación, un codificador convertidor analiza estos vectores, teniendo en cuenta el contexto de cada palabra en función de su entorno.
Por último, el modelo genera un único vector que representa el texto completo y capta su significado global y las relaciones entre las palabras que lo componen. La versión grande presenta una arquitectura más compleja y una mayor dimensionalidad para una precisión potencialmente mayor, mientras que la versión pequeña prioriza la velocidad y la eficiencia con una arquitectura más sencilla y una dimensionalidad menor.
Para saber más sobre las incrustaciones de OpenAI, consulta nuestra guía: Explorando Text-Embedding-3-Large: Guía completa de las nuevas incrustaciones de OpenAI.
USE es un modelo de incrustación de frases de código cerrado creado por Google AI. Convierte el texto en incrustaciones de alta dimensión que reflejan los significados semánticos de frases o párrafos cortos.
A diferencia de los modelos que incorporan palabras sueltas, USE maneja frases enteras utilizando una red neuronal profunda preentrenada en un corpus de texto diverso. Este diseño te permite capturar las relaciones semánticas con eficacia, produciendo vectores de tamaño fijo para frases de longitud variable que mejoran la eficiencia computacional.
Google proporciona acceso a través de su repositorio TensorFlow Hub.
En esta guía se ofrece una introducción exhaustiva a las incrustaciones de texto, su significado, su importancia y los principales hitos de su evolución. También examinamos los casos de uso de la incrustación de texto y los principales modelos de incrustación de texto.
Para conocer en profundidad la IA, el procesamiento del lenguaje natural (PLN) y la incrustación de texto, consulta estos recursos:
Más información sobre IA con DataCamp
programa
Curso
Curso
blog
Javier Canales Luna
10 min
blog
Bhavishya Pandit
8 min
blog
Dimitri Didmanidze
7 min
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer