The landscape of machine learning and natural language processing (NLP) is continuously evolving, with OpenAI consistently leading the way toward innovation.
The introduction of its text-embedding-3-large, and text-embedding-3-small models marks a new era in the field, set to change how developers and AI practitioners approach text analysis and embedding tasks.
In the complex world of artificial intelligence, embeddings are crucial for turning complicated human language into something machines can understand and process. This new model from OpenAI represents a significant step forward for developers and aspiring data practitioners.
This article aims to explain the text-embedding-3-large, and text-embedding-3-small models, offering insights into their core functions, various applications, and how to use them effectively.
By exploring the basics of text embeddings and highlighting the model's new features and practical uses, the article intends to provide readers with the necessary information to use this advanced tool in their projects.
Additionally, it will cover the basics of getting started with the model, share tips for improving embedding tasks, and discuss the wide-reaching impact of this technological progress on the NLP field.
Understanding Text Embeddings
Before diving into the specifics of the new model, a brief overview of text embeddings is useful for a better understanding.
Text embeddings are numerical representations of text that capture the semantics, or meaning, of words, phrases, or entire documents. They are foundational in many NLP tasks, such as sentiment analysis, text classification, and more.
Our Introduction to Text Embeddings with the OpenAI API provides a complete guide on using the OpenAI API for creating text embeddings. Discover their applications in text classification, information retrieval, and semantic similarity detection.
Below is an illustration using an embedding model:
- The documents to represent are on the left
- The embedding model in the middle, and
- The corresponding embeddings of each document are on the right

Text embeddings illustration
For those new to this concept, consider exploring our Introduction to Embeddings with the OpenAI API course. It explains how to harness OpenAI’s embeddings via the OpenAI API to create embeddings from textual data and begin developing real-world applications.
New OpenAI Embeddings at a Glance
Announced on January 25, 2024, these models are the latest and most powerful embedding models designed to represent text in high-dimensional space, making it easier to have a better understanding of text.
The text-embedding-3-small is optimized for latency and storage. On the other hand, text-embedding-3-large is a good option for higher accuracy, and we can also take advantage of the new dimensions parameter to keep the embedding at 1536 instead of the native size of 3072 without impacting the overall performance.
Benchmarking analysis
Before the release, the text-embedding-ada-2 was at the top of the leaderboard of all the previous OpenAI embedding models, and the following table provides a quick overview of the benchmarking between these three models.
|
Model |
Dimension |
Max token |
Knowledge cutoff |
Pricing ($/1k tokens) |
MIRACL average |
MTEB average |
|
ada v2 |
1536 |
8191 |
September 2021 |
0.0001 |
31.4 |
61.0 |
|
text-embedding-3-small |
0.00002 |
44.0 |
62.3 |
|||
|
text-embedding-3-large |
3072 |
0.00013 |
54.9 |
64.6 |
From the provided metrics, we can observe an improvement in performance from ada v2 (text-embedding-ada-002) to text-embedding-3-large on both MIRACL and MTEB benchmarks. This suggests that text-embedding-3-large, having more dimensions (3072), offers better embedding quality compared to the other two, which directly correlates with improved benchmark scores.
The increase in dimensions from text-embedding-ada-002 and text-embedding-3-small (both 1536) to text-embedding-3-large (3072) suggests a more complex model that can capture a richer set of features in its embeddings. However, this also comes with a higher pricing per 1,000 tokens processed, indicating a trade-off between performance and cost.
Depending on the specific requirements of a task (e.g., the need for multilingual capabilities, the complexity of the text to be embedded, or budget constraints), one might choose a different model.
For tasks requiring high-quality embeddings across multiple languages and tasks, text-embedding-3-large might be preferable despite its higher cost. In contrast, for applications with tighter budget constraints or where ultra-high precision might not be as critical, text-embedding-ada-002 or text-embedding-3-small could be more suitable options.
Applications of Text-Embedding-3-Large
Embedding technologies have been remarkably beneficial to many modern natural language processing and understanding applications. The choice between more powerful models like text-embedding-3-large and more economical options like text-embedding-3-small can influence the performance and cost-efficiency of NLP applications.
Below are three illustrations of use cases for both model, demonstrating their versatility and impacts in real-world scenarios.
Applications of text-embedding-3-large
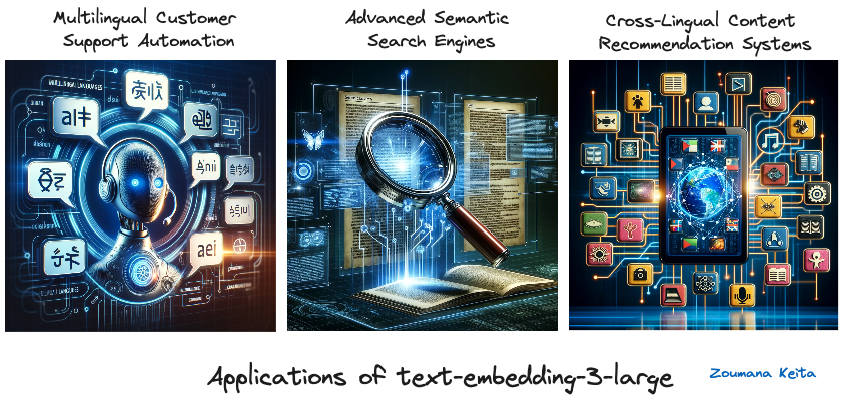
Applications of text-embedding-3-large (images generated using GPT-4)
Multilingual customer support automation
With its superior performance in understanding and processing 18 different languages, text-embedding-3-large can power customer support chatbots and automated response systems for global companies, ensuring accurate, context-aware support across diverse linguistic backgrounds.
Advanced semantic search engines
Leveraging its high-dimensional embeddings, text-embedding-3-large can enhance search engine algorithms, enabling them to understand the nuances of search queries better and retrieve more relevant, contextually matched results, especially in specialized fields like legal or medical research.
Cross-lingual content recommendation systems
For platforms hosting a wide array of multilingual content, such as streaming services or news aggregators, text-embedding-3-large can analyze user preferences and content in multiple languages, recommending highly relevant content to users regardless of language barriers.
Applications of text-embedding-3-small

Applications of text-embedding-3-small (Image generated using GPT-4)
Cost-effective sentiment analysis
For startups and mid-sized businesses looking to understand customer sentiment through social media monitoring or feedback analysis, text-embedding-3-small offers a budget-friendly yet effective solution for gauging public opinion and customer satisfaction.
Scalable content categorization
Content platforms with large volumes of data, such as blogs or e-commerce sites, can utilize text-embedding-3-small to automatically categorize content or products. Its efficiency and lower cost make it ideal for handling vast datasets without compromising on accuracy.
Efficient language learning tools
Educational apps that require scalable and cost-effective solutions to provide language learning exercises, such as matching words to meanings or grammar checking, can benefit from text-embedding-3-small. Its balance of performance and affordability supports the development of interactive, language-focused educational content.
These applications showcase how text-embedding-3-large and text-embedding-3-small can be optimally deployed in various sectors, aligning their strengths with the specific needs of each application for enhanced performance, user experience, and cost efficiency.
A Step-By-Step Guide to Using the New OpenAI Embeddings
We now have all the tools we need to proceed with the implementation of both text-embedding-3-large, text-embedding-3-small, and ada-v2 in a scenario of document similarity.
All the code in this tutorial is available in a DataLab workbook. Create a copy of this workbook to run the code without having to install anything on your computer.
About the data
- This is the CORD-19 data set, a resource of over 59,000 scholarly articles, including over 48,000 with full text, about COVID-19, SARS-CoV-2, and related coronaviruses.
- This data has been made freely available by the White House and a coalition of leading research groups to help global research generate insights in support of the ongoing fight against this infectious disease.
- It is downloadable from this page on Kaggle.
- Further details about the dataset can be found on this page.
Before moving further, it is important to consider installing and importing the following libraries for the success of this project.
Using the %%bash statement, we can install multiple libraries without using the exclamation (!) mark.
%%bash
pip -q install tiktoken
pip -q install openaiNow, the libraries can be imported as follows:
import os
import tiktoken
import numpy as np
import pandas as pd
from openai import OpenAI
from sklearn.metrics.pairwise import cosine_similarityLet’s understand the role of each library:
- os: Provides a way to use operating system-dependent functionality like reading or writing to the filesystem.
- tiktoken: Handles tokenization tasks specific to processing scientific documents.
- numpy (np): Adds support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical functions to operate on these arrays, crucial for scientific computing.
- pandas (pd): Offers data structures and operations for manipulating numerical tables and time series, essential for handling scientific datasets.
- openai.OpenAI: Serves as the interface to OpenAI's API, allowing for interaction with machine learning models for tasks such as generating embeddings for scientific texts.
- sklearn.metrics.pairwise.cosine_similarity: Computes the cosine similarity between vectors, useful in scientific document similarity analysis.
Data Exploration
The original dataframe is more than 1Gb, and only a sample of 1000 random observations is loaded for simplicity’s sake.
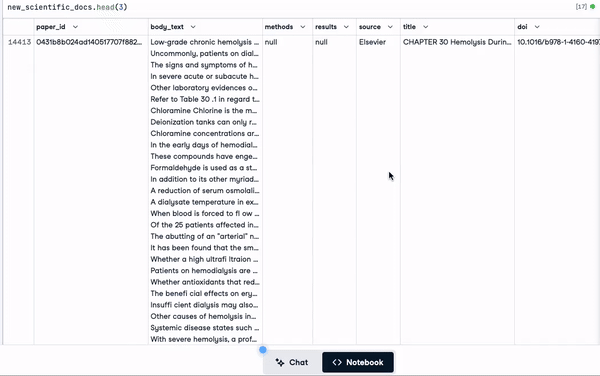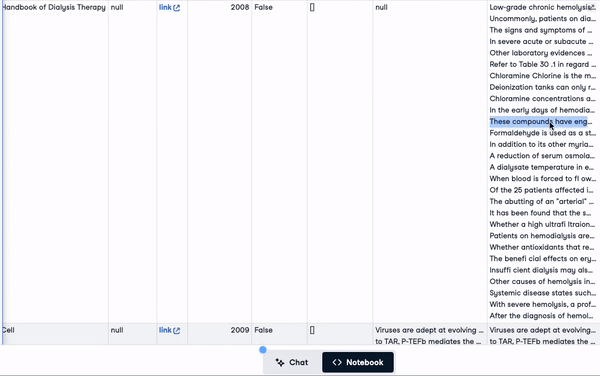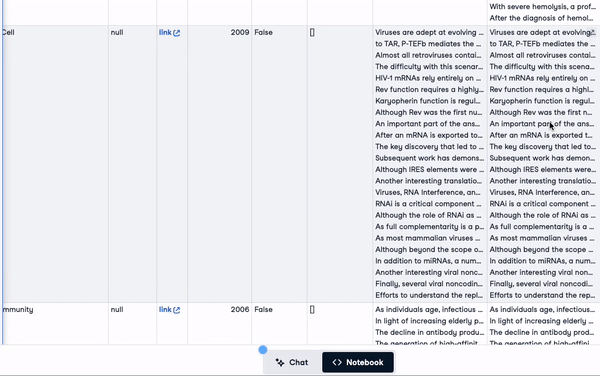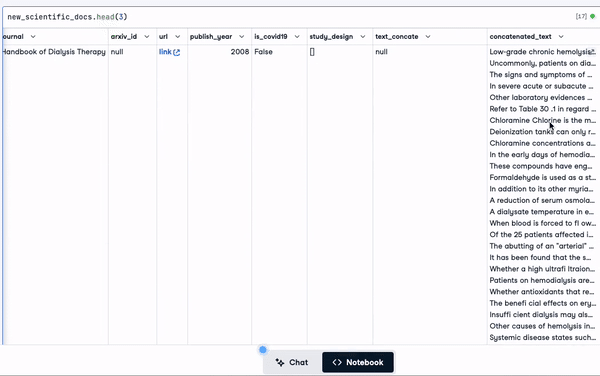
scientific_docs = pd.read_parquet("./data/cord19_df_sample.parquet")Using the .head() function, we can see the first 2 rows of the data, and the result is in the animation below.
scientific_docs.head(2)
First two rows of the data
The body, title, and abstract of a given scientific document can be enough to represent that document. Those three attributes are concatenated to get a single textual representation for each document.
Before that, let's see the percentage of missing values within each of these three columns:
percent_missing = scientific_docs.isnull().sum() * 100 / len(scientific_docs)
percent_missing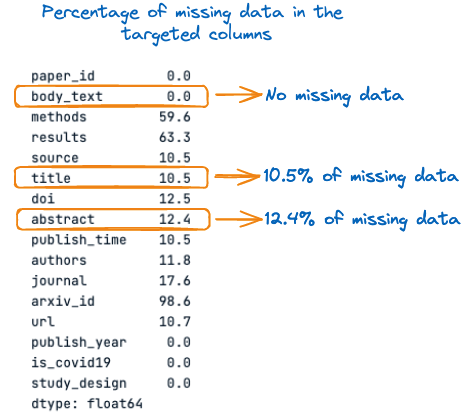
Percentage of missing data in the targeted columns
From the above image, we can observe that the title and abstract have missing values, respectively 10.5% and 12.4%. Hence, it is important to fill those missing values with empty strings before the concatenation to avoid information loss.
The overall process of filling the missing values and concatenating the columns is achieved using the following function.
def concatenate_columns_with_null_handling(df, body_text_column,
abstract_column,
title_column,
new_col_name):
df[new_col_name] = df[body_text_column].fillna('') + df[abstract_column].fillna('') + df[title_column].fillna('')
return dfAfter running the concatenation function on the original data and checking the first 3 rows, we can notice that the concatenation is successful.
new_scientific_docs = concatenate_columns_with_null_handling(scientific_docs,
"body_text",
"abstract",
"title",
"concatenated_text")new_scientific_docs.head(3)The newly added column is concatenated_text.
First 3 rows with the newly added column
The next step is to apply the embeddings on the new column using the different embedding models mentioned in this article. But before that let’s see the distribution of the length of the tokens.
The goal of this analysis is to check the maximum token limitation of the model against the actual number of tokens within a given document.
But first, we need to count the total number of tokens within each document, and that is achieved using the helper function num_tokens_from_text and the cl100k_base encoder.
def num_tokens_from_text(text: str, encoding_name="cl100k_base"):
"""
Returns the number of tokens in a text string.
"""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(text))
return num_tokensBefore applying the function to the overall dataset, let’s see how it works against the following text: This article is about new OpenAI Embeddings.
text = "This article is about new OpenAI Embeddings"
num_tokens = num_tokens_from_text(text)
print(f"Number of tokens: {num_tokens}")After successfully executing the above code, we can see that the text has 10 tokens.
![]()
Number of tokens in the text
With confidence, we can apply the function to the whole text in the dataframe using the lambda expression as follows:
new_scientific_docs['num_tokens'] = new_scientific_docs["concatenated_text"].apply(lambda x: num_tokens_from_text(x))We can count the total number of documents having more than 8191 tokens by filtering all the number of tokens and checking which one is higher than the actual token limit of 8191.
smaller_tokens_docs = new_scientific_docs[new_scientific_docs['num_tokens'] <= 8191]
len(smaller_tokens_docs)⇒ Output: 764
This means that 764 documents out of 1000 meets the requirement of the maximum token limit, and we are using those documents for simplicity's sake.
Advanced technics can be applied to process the remaining set of documents that have more than 8191 tokens.
One of those techniques is to take the average of all the embeddings of a single document. Another technique consists of taking the first 8191 tokens of the document. This approach is not efficient because it can lead to information loss.
Let’s make sure to reset the index of the dataframe so that it starts from zero.
smaller_tokens_docs_reset = smaller_tokens_docs.reset_index(drop=True)Execute embeddings
All the requirements are satisfied to get the embedding representation of all the documents, and this is done for each embedding model.
The first step is to acquire the OpenAI credential and configure the client as follows:
os.environ["OPENAI_API_KEY"] = "YOUR KEY"
client = OpenAI()Then, the following helper function helps generate the embedding by providing the embedding model and the text to be embedded.
def get_embedding(text_to_embbed, model_ID):
text = text_to_embbed.replace("\n", " ")
return client.embeddings.create(input = [text_to_embbed],
model=model_ID).data[0].embeddingA new dataframe is now created with three additional columns corresponding to the embedding of each of the three models :
- text-embedding-3-small
- text-embedding-3-large
- text-embedding-ada-002
smaller_tokens_docs_reset['text-embedding-3-small'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-3-small"))
smaller_tokens_docs_reset['text-embedding-3-large'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-3-large"))
smaller_tokens_docs_reset['text-embedding-ada-002'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-ada-002"))After successfully running the above code, we can see that the relevant embedding columns have been added.
smaller_tokens_docs_reset.head(1)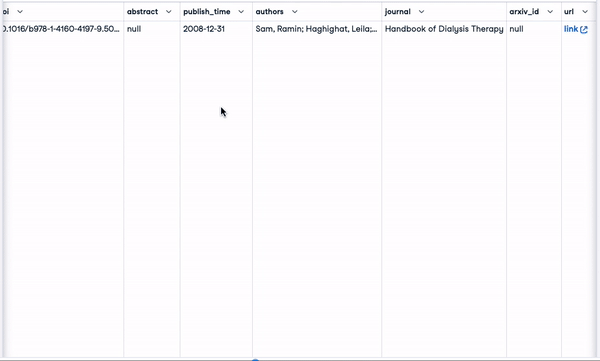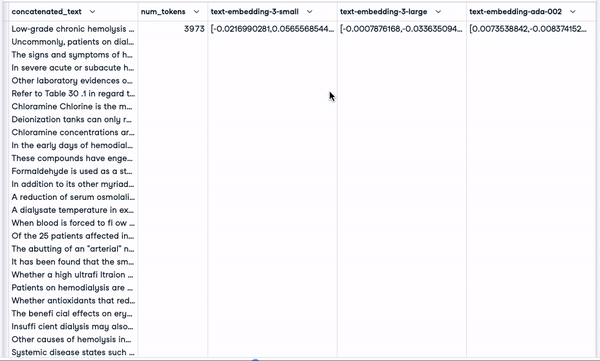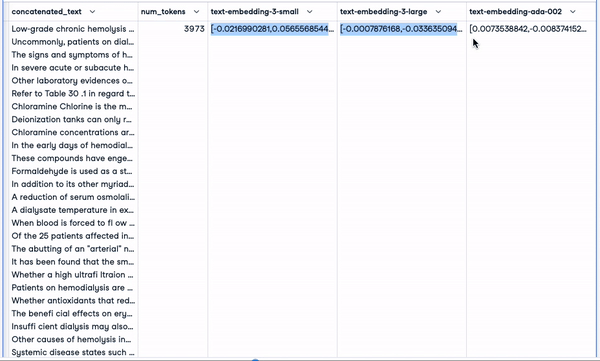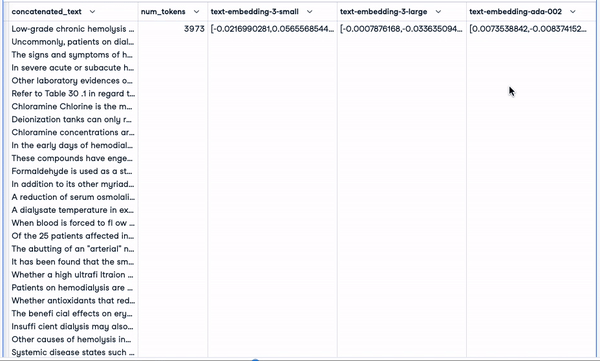
New dataframe with relevant embedding columns
Similarity search
This section uses the cosine similarity technique against each one of the above embedding approaches to find the top 3 similar documents to that specific document.
The following helper function takes four main parameters:
- The current dataframe
- The index of the text we want to find the most similar documents to
- The specific embedding to be used
- The top most similar documents we want, and it is 3 by default.
def find_top_N_similar_documents(df, chosen_index,
embedding_column_name,
top_N=3):
chosen_document_embedding = np.array(df.iloc[chosen_index][embedding_column_name]).reshape(1, -1)
embedding_matrix = np.vstack(df[embedding_column_name])
similarity_scores = cosine_similarity(chosen_document_embedding, embedding_matrix)[0]
df_temp = df.copy()
df_temp['similarity_to_chosen'] = similarity_scores
similar_documents = df_temp.drop(index=chosen_index).sort_values(by='similarity_to_chosen', ascending=False)
top_N_similar = similar_documents.head(top_N)
return top_N_similar[[concatenated_text, 'similarity_to_chosen']]In the following section, we are finding the most similar documents to the first document (index=0)
This is what the first document looks like:
chosen_index = 0
first_document_data = smaller_tokens_docs_reset.iloc[0]["concatenated_text"]
print(first_document_data)
Content of the first document (concatenated version)
The similarity search function can be run as follows:
top_3_similar_3_small = find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-3-small")
top_3_similar_3_large= find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-3-large")
top_3_similar_ada_002 = find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-ada-002")After processing the similarity tasks, the result can be displayed as follows:
print("Top 3 Similar Documents with :")
print("--> text-embedding-3-small")
print(top_3_similar_3_small)
print("\n")
print("--> text-embedding-3-large")
print(top_3_similar_3_large)
print("\n")
print("--> text-embedding-ada-002")
print(top_3_similar_ada_002)
print("\n")
Top 3 most similar documents using each embedding model
Observation of the result
The "text-embedding-3-small" model shows moderate similarity scores around 0.54, while the "text-embedding-3-large" has slightly higher scores, indicating a better capture of similarity.
The "text-embedding-ada-002" model shows significantly higher similarity scores, with the top score close to 0.85, suggesting a very strong similarity with the chosen document.
However, Document 372 is a common top result across all models, hinting at its consistent relevance to the query. The varying scores between models highlight the impact of the choice of embedding model on similarity results.
Conclusion
In conclusion, OpenAI's new text-embedding-3-large and text-embedding-3-small models represent a significant leap in the realm of natural language processing, offering a more nuanced and high-dimensional representation of text data.
As demonstrated in the article, the choice between these models can substantially impact the outcome of various NLP tasks such as document similarity, sentiment analysis, and multilingual support systems. While the text-embedding-3-large provides higher accuracy due to its increased dimensions, the text-embedding-3-small offers a balance of efficiency and performance for cost-sensitive applications.
Benchmarking analysis revealed that the text-embedding-3-large outperforms its predecessors, setting a new standard in the field. The real-world applications for these models are vast, ranging from enhancing customer support to powering sophisticated search engines and content recommendation systems.
By navigating the detailed guide provided, practitioners in the field are equipped to make informed decisions about which model to use based on the complexity of the task, budget constraints, and the need for multilingual capabilities.
Ultimately, the choice of model should align with the specific demands of the project at hand, leveraging the strengths of text-embedding-3-large for tasks requiring high fidelity and text-embedding-3-small for more general purposes. The advent of these models underscores OpenAI's commitment to advancing AI technology and the continuous evolution of machine learning tools.
Where to go from here?
Our article, The OpenAI API in Python, is a cheat sheet that helps you learn the basics of how to leverage one of the most powerful AI APIs out there, then OpenAI API.
Our code along session Fine-tuning GPT3.5 with OpenAI API provides the guides to using OpenAI API and Python to get started fine-tuning GPT3.5, helping learn when fine-tuning large language models can be beneficial, how to use the fine-tuning tools in the OpenAI API and finally understand the workflow of fine-tuning.




