Le paysage de l'apprentissage automatique et du traitement du langage naturel (NLP) est en constante évolution, et l'OpenAI est toujours à la pointe de l'innovation.
L'introduction de ses modèles text-embedding-3-large et text-embedding-3-small marque une nouvelle ère dans le domaine et devrait changer la façon dont les développeurs et les praticiens de l'IA abordent les tâches d'analyse et d'insertion de texte.
Dans le monde complexe de l'intelligence artificielle, les enchâssements sont essentiels pour transformer un langage humain compliqué en quelque chose que les machines peuvent comprendre et traiter. Ce nouveau modèle de l'OpenAI représente une avancée significative pour les développeurs et les praticiens des données en herbe.
Cet article vise à expliquer les modèles text-embedding-3-large et text-embedding-3-small, en donnant un aperçu de leurs fonctions principales, de leurs diverses applications et de la manière de les utiliser efficacement.
En explorant les bases des text embeddings et en mettant en évidence les nouvelles fonctionnalités et les utilisations pratiques du modèle, l'article vise à fournir aux lecteurs les informations nécessaires à l'utilisation de cet outil avancé dans leurs projets.
En outre, il couvrira les bases de l'utilisation du modèle, partagera des conseils pour améliorer les tâches d'intégration et discutera de l'impact étendu de ce progrès technologique sur le domaine de la PNL.
Comprendre les emboîtements de texte
Avant de plonger dans les spécificités du nouveau modèle, il est utile de donner un bref aperçu des enchâssements de texte pour mieux les comprendre.
Les text embeddings sont des représentations numériques du texte qui capturent la sémantique, ou le sens, des mots, des phrases ou des documents entiers. Ils sont essentiels dans de nombreuses tâches de TAL, telles que l'analyse des sentiments, la classification des textes, etc.
Notre introduction aux incorporations de texte avec l'API OpenAI fournit un guide complet sur l'utilisation de l'API OpenAI pour créer des incorporations de texte. Découvrez leurs applications dans la classification des textes, la recherche d'informations et la détection de similarités sémantiques.
Vous trouverez ci-dessous une illustration à l'aide d'un modèle d'intégration :
- Les documents à représenter sont à gauche
- Le modèle d'intégration au milieu, et
- Les intégrations correspondantes de chaque document se trouvent à droite.

Illustration d'incrustations de texte
Pour ceux qui ne connaissent pas encore ce concept, nous vous conseillons de suivre notre cours Introduction to Embeddings with the OpenAI API. Il explique comment exploiter les embeddings d'OpenAI via l'API OpenAI pour créer des embeddings à partir de données textuelles et commencer à développer des applications réelles.
Coup d'œil sur les nouveaux encodages de l'OpenAI
Annoncés le 25 janvier 2024, ces modèles sont les derniers et les plus puissants modèles d'intégration conçus pour représenter le texte dans un espace à haute dimension, ce qui permet de mieux comprendre le texte.
Le text-embedding-3-small est optimisé pour la latence et le stockage. D'autre part, text-embedding-3-large est une bonne option pour une plus grande précision, et nous pouvons également tirer parti du nouveau paramètre de dimensions pour maintenir l'intégration à 1536 au lieu de la taille native de 3072 sans impact sur les performances globales.
Analyse comparative
Avant la publication, le text-embedding-ada-2 était en tête du classement de tous les modèles d'intégration OpenAI précédents, et le tableau suivant donne un aperçu rapide de l'analyse comparative entre ces trois modèles.
|
Model |
Dimension |
Jeton maximum |
Critères d'évaluation des connaissances |
Prix ($/1k tokens) |
Moyenne de MIRACL |
Moyenne de la MTEB |
|
ada v2 |
1536 |
8191 |
Septembre 2021 |
0.0001 |
31.4 |
61.0 |
|
text-embedding-3-small |
0.00002 |
44.0 |
62.3 |
|||
|
text-embedding-3-large |
3072 |
0.00013 |
54.9 |
64.6 |
D'après les mesures fournies, nous pouvons observer une amélioration des performances entre ada v2 (text-embedding-ada-002) et text-embedding-3-large sur les benchmarks MIRACL et MTEB. Cela suggère que text-embedding-3-large, ayant plus de dimensions (3072), offre une meilleure qualité d'intégration que les deux autres, ce qui est directement corrélé avec l'amélioration des résultats des tests de référence.
L'augmentation des dimensions entre text-embedding-ada-002 et text-embedding-3-small (tous deux 1536) et text-embedding-3-large (3072) suggère un modèle plus complexe capable de capturer un ensemble plus riche de caractéristiques dans ses encastrements. Toutefois, cela s'accompagne également d'un prix plus élevé pour 1 000 jetons traités, ce qui indique un compromis entre la performance et le coût.
En fonction des exigences spécifiques d'une tâche (par exemple, le besoin de capacités multilingues, la complexité du texte à intégrer ou les contraintes budgétaires), on peut choisir un modèle différent.
Pour les tâches nécessitant des encodages de haute qualité dans plusieurs langues et pour plusieurs tâches, text-embedding-3-large pourrait être préférable malgré son coût plus élevé. En revanche, pour les applications soumises à des contraintes budgétaires plus strictes ou pour lesquelles une précision extrême n'est pas aussi importante, les options text-embedding-ada-002 ou text-embedding-3-small pourraient être plus appropriées.
Applications du Text-Embedding-3-Large
Les technologies d'intégration ont été remarquablement utiles à de nombreuses applications modernes de traitement et de compréhension du langage naturel. Le choix entre des modèles plus puissants comme text-embedding-3-large et des options plus économiques comme text-embedding-3-small peut influencer la performance et la rentabilité des applications NLP.
Vous trouverez ci-dessous trois illustrations de cas d'utilisation pour les deux modèles, démontrant leur polyvalence et leur impact dans des scénarios réels.
Applications de text-embedding-3-large
Applications du text-embedding-3-large (images générées à l'aide de GPT-4)
Automatisation du support client multilingue
Grâce à ses performances supérieures en matière de compréhension et de traitement de 18 langues différentes, le text-embedding-3-large peut alimenter les chatbots d'assistance à la clientèle et les systèmes de réponse automatisés des entreprises internationales, garantissant ainsi une assistance précise et adaptée au contexte dans des contextes linguistiques divers.
Moteurs de recherche sémantique avancés
Grâce à ses enchâssements à haute dimension, le text-embedding-3-large peut améliorer les algorithmes des moteurs de recherche, en leur permettant de mieux comprendre les nuances des requêtes et d'extraire des résultats plus pertinents et adaptés au contexte, en particulier dans des domaines spécialisés tels que la recherche juridique ou médicale.
Systèmes de recommandation de contenu multilingue
Pour les plateformes hébergeant un large éventail de contenus multilingues, comme les services de diffusion en continu ou les agrégateurs d'actualités, l'intégration de texte 3-large peut analyser les préférences des utilisateurs et les contenus en plusieurs langues, en recommandant des contenus très pertinents aux utilisateurs, quelles que soient les barrières linguistiques.
Applications de text-embedding-3-small

Applications de text-embedding-3-small (Image générée avec GPT-4)
Analyse des sentiments à moindre coût
Pour les startups et les entreprises de taille moyenne qui cherchent à comprendre le sentiment des clients par le biais d'une surveillance des médias sociaux ou d'une analyse des commentaires, l'insertion de texte-3-small offre une solution économique mais efficace pour mesurer l'opinion publique et la satisfaction des clients.
Catégorisation évolutive du contenu
Les plateformes de contenu contenant de grands volumes de données, telles que les blogs ou les sites de commerce électronique, peuvent utiliser le text-embedding-3-small pour catégoriser automatiquement le contenu ou les produits. Son efficacité et son faible coût en font un outil idéal pour traiter de vastes ensembles de données sans compromettre la précision.
Des outils d'apprentissage des langues efficaces
Les applications éducatives qui nécessitent des solutions évolutives et rentables pour proposer des exercices d'apprentissage des langues, tels que l'association de mots à leur signification ou la vérification de la grammaire, peuvent bénéficier de l'intégration de texte-3-small. Son équilibre entre performances et prix abordable favorise le développement de contenus éducatifs interactifs axés sur les langues.
Ces applications illustrent la manière dont text-embedding-3-large et text-embedding-3-small peuvent être déployés de manière optimale dans divers secteurs, en alignant leurs forces sur les besoins spécifiques de chaque application pour améliorer les performances, l'expérience de l'utilisateur et la rentabilité.
Un guide pas à pas pour utiliser les nouveaux Embeddings d'OpenAI
Nous disposons à présent de tous les outils nécessaires à la mise en œuvre de text-embedding-3-large, text-embedding-3-small et ada-v2 dans un scénario de similarité de documents.
Tout le code de ce tutoriel est disponible dans un classeur DataLab. Créez une copie de ce classeur pour exécuter le code sans avoir à installer quoi que ce soit sur votre ordinateur.
A propos des données
- Il s'agit de l'ensemble de données CORD-19, une ressource de plus de 59 000 articles scientifiques, dont plus de 48 000 en texte intégral, sur COVID-19, SARS-CoV-2 et les coronavirus apparentés.
- Ces données ont été mises à disposition gratuitement par la Maison Blanche et une coalition de groupes de recherche de premier plan afin d'aider la recherche mondiale à générer des informations pour soutenir la lutte actuelle contre cette maladie infectieuse.
- Il est téléchargeable à partir de cette page sur Kaggle.
- Vous trouverez plus de détails sur l'ensemble de données sur cette page.
Avant d'aller plus loin, il est important d'installer et d'importer les bibliothèques suivantes pour la réussite de ce projet.
En utilisant l'instruction %%bash, nous pouvons installer plusieurs bibliothèques sans utiliser le point d'exclamation ( !).
%%bash
pip -q install tiktoken
pip -q install openaiLes bibliothèques peuvent maintenant être importées comme suit :
import os
import tiktoken
import numpy as np
import pandas as pd
from openai import OpenAI
from sklearn.metrics.pairwise import cosine_similarityComprenons le rôle de chaque bibliothèque :
- os : Permet d'utiliser des fonctionnalités dépendantes du système d'exploitation, telles que la lecture ou l'écriture dans le système de fichiers.
- tiktoken : Gère les tâches de tokenisation spécifiques au traitement des documents scientifiques.
- numpy (np) : Prise en charge de tableaux et de matrices multidimensionnels de grande taille, ainsi que d'une vaste collection de fonctions mathématiques de haut niveau permettant d'exploiter ces tableaux, ce qui est essentiel pour le calcul scientifique.
- pandas (pd) : Propose des structures de données et des opérations pour manipuler des tableaux numériques et des séries temporelles, indispensables pour traiter des ensembles de données scientifiques.
- openai.OpenAI : Il sert d'interface à l'API d'OpenAI, permettant d'interagir avec des modèles d'apprentissage automatique pour des tâches telles que la génération d'embeddings pour des textes scientifiques.
- sklearn.metrics.pairwise.cosine_similarity : Calcule la similarité cosinus entre les vecteurs, utile dans l'analyse de similarité des documents scientifiques.
Data Exploration
Le DataFrame original fait plus de 1Gb, et seul un échantillon de 1000 observations aléatoires est chargé pour des raisons de simplicité.
scientific_docs = pd.read_parquet("./data/cord19_df_sample.parquet")En utilisant la fonction .head(), nous pouvons voir les 2 premières lignes des données, et le résultat est dans l'animation ci-dessous.
scientific_docs.head(2)
Les deux premières lignes des données
Le corps, le titre et le résumé d'un document scientifique donné peuvent suffire à représenter ce document. Ces trois attributs sont concaténés pour obtenir une représentation textuelle unique pour chaque document.
Avant cela, voyons le pourcentage de valeurs manquantes dans chacune de ces trois colonnes :
percent_missing = scientific_docs.isnull().sum() * 100 / len(scientific_docs)
percent_missing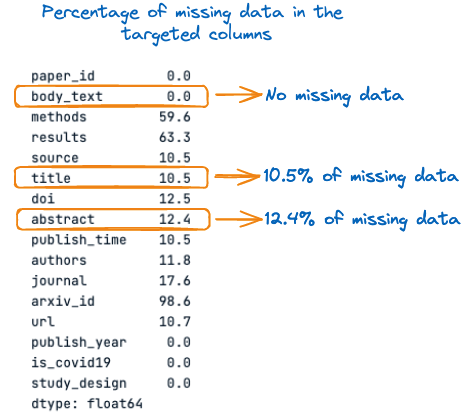
Pourcentage de données manquantes dans les colonnes ciblées
Dans l'image ci-dessus, nous pouvons observer que le titre et le résumé ont des valeurs manquantes, respectivement 10,5 % et 12,4 %. Il est donc important de compléter ces valeurs manquantes par des chaînes vides avant la concaténation afin d'éviter toute perte d'information.
Le processus global de remplissage des valeurs manquantes et de concaténation des colonnes est réalisé à l'aide de la fonction suivante.
def concatenate_columns_with_null_handling(df, body_text_column,
abstract_column,
title_column,
new_col_name):
df[new_col_name] = df[body_text_column].fillna('') + df[abstract_column].fillna('') + df[title_column].fillna('')
return dfAprès avoir exécuté la fonction de concaténation sur les données originales et vérifié les trois premières lignes, nous pouvons constater que la concaténation est réussie.
new_scientific_docs = concatenate_columns_with_null_handling(scientific_docs,
"body_text",
"abstract",
"title",
"concatenated_text")new_scientific_docs.head(3)La colonne nouvellement ajoutée est concatenated_text.
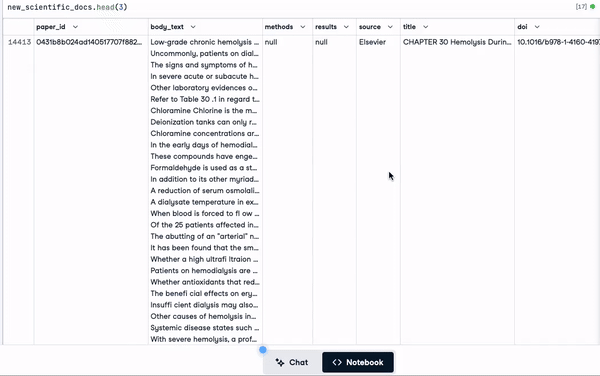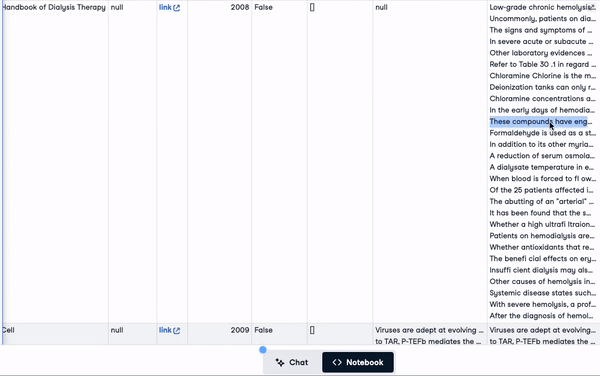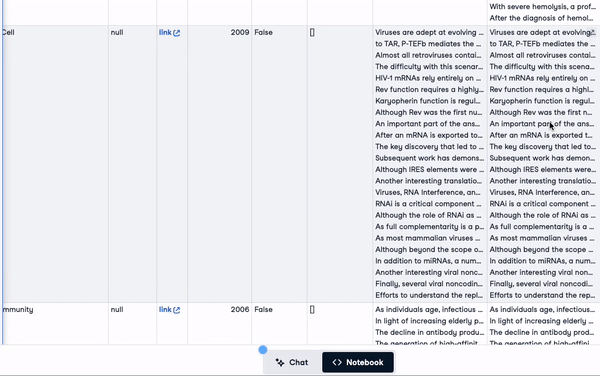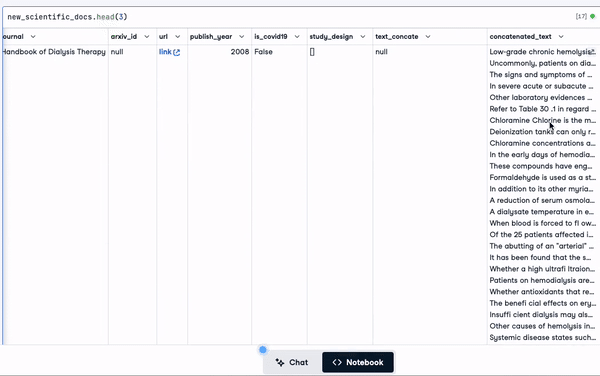
Les 3 premières lignes avec la colonne nouvellement ajoutée
L'étape suivante consiste à appliquer les encastrements à la nouvelle colonne en utilisant les différents modèles d'encastrement mentionnés dans cet article. Mais avant cela, voyons la distribution de la longueur des jetons.
L'objectif de cette analyse est de vérifier la limite maximale de tokens du modèle par rapport au nombre réel de tokens dans un document donné.
Mais tout d'abord, nous devons compter le nombre total de tokens dans chaque document, ce que nous faisons en utilisant la fonction d'aide num_tokens_from_text et l'encodeur cl100k_base.
def num_tokens_from_text(text: str, encoding_name="cl100k_base"):
"""
Returns the number of tokens in a text string.
"""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(text))
return num_tokensAvant d'appliquer la fonction à l'ensemble des données, voyons comment elle fonctionne avec le texte suivant : Cet article porte sur les nouveaux Embeddings de l'OpenAI.
text = "This article is about new OpenAI Embeddings"
num_tokens = num_tokens_from_text(text)
print(f"Number of tokens: {num_tokens}")Après avoir exécuté avec succès le code ci-dessus, nous pouvons voir que le texte contient 10 tokens.
![]()
Nombre de tokens dans le texte
En toute confiance, nous pouvons appliquer la fonction à l'ensemble du texte du DataFrame à l'aide de l'expression lambda suivante :
new_scientific_docs['num_tokens'] = new_scientific_docs["concatenated_text"].apply(lambda x: num_tokens_from_text(x))Nous pouvons compter le nombre total de documents ayant plus de 8191 jetons en filtrant tous les nombres de jetons et en vérifiant lequel est supérieur à la limite réelle de 8191 jetons.
smaller_tokens_docs = new_scientific_docs[new_scientific_docs['num_tokens'] <= 8191]
len(smaller_tokens_docs)⇒ Sortie : 764
Cela signifie que 764 documents sur 1 000 satisfont à la limite maximale de jetons, et nous utilisons ces documents pour des raisons de simplicité.
Des techniques avancées peuvent être appliquées pour traiter le reste des documents qui contiennent plus de 8191 tokens.
L'une de ces techniques consiste à prendre la moyenne de toutes les intégrations d'un seul document. Une autre technique consiste à prendre les 8191 premiers tokens du document. Cette approche n'est pas efficace car elle peut entraîner une perte d'informations.
Veillons à réinitialiser l'index de la DataFrame de manière à ce qu'il commence à zéro.
smaller_tokens_docs_reset = smaller_tokens_docs.reset_index(drop=True)Exécuter les encastrements
Toutes les conditions sont remplies pour obtenir la représentation de l'intégration de tous les documents, et ce pour chaque modèle d'intégration.
La première étape consiste à obtenir la carte d'identité OpenAI et à configurer le client comme suit :
os.environ["OPENAI_API_KEY"] = "YOUR KEY"
client = OpenAI()Ensuite, la fonction d'aide suivante permet de générer l'intégration en fournissant le modèle d'intégration et le texte à intégrer.
def get_embedding(text_to_embbed, model_ID):
text = text_to_embbed.replace("\n", " ")
return client.embeddings.create(input = [text_to_embbed],
model=model_ID).data[0].embeddingUn nouveau DataFrame est maintenant créé avec trois colonnes supplémentaires correspondant à l'intégration de chacun des trois modèles :
- text-embedding-3-small
- text-embedding-3-large
- text-embedding-ada-002
smaller_tokens_docs_reset['text-embedding-3-small'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-3-small"))
smaller_tokens_docs_reset['text-embedding-3-large'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-3-large"))
smaller_tokens_docs_reset['text-embedding-ada-002'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-ada-002"))Après avoir exécuté avec succès le code ci-dessus, nous pouvons voir que les colonnes d'intégration appropriées ont été ajoutées.
smaller_tokens_docs_reset.head(1)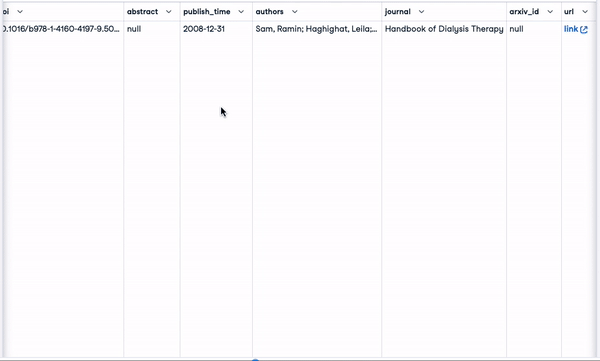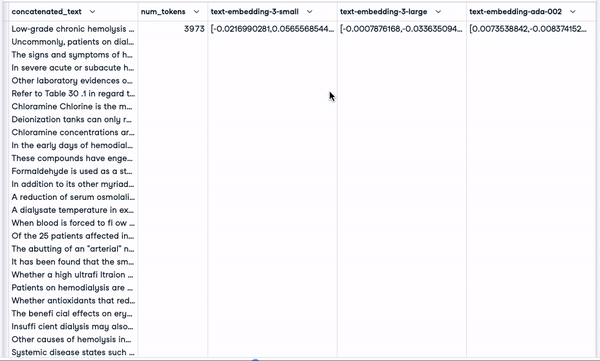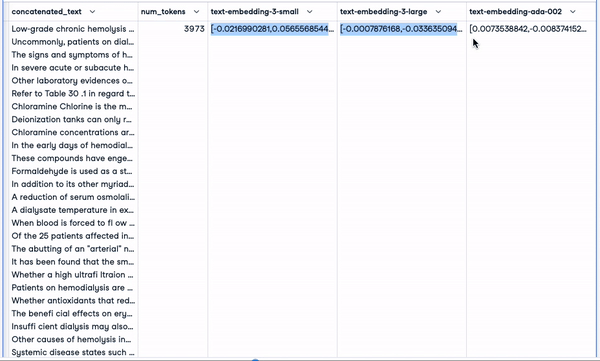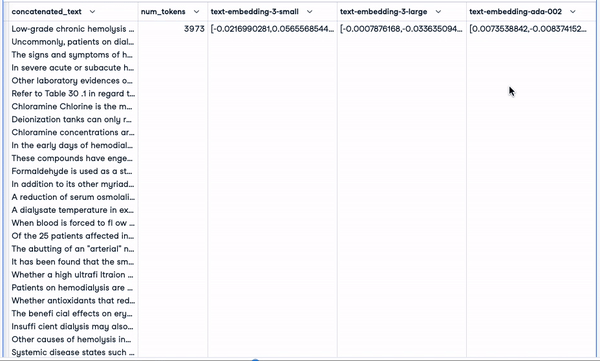
Nouvelle DataFrame avec des colonnes d'intégration pertinentes
Recherche de similitude
Cette section utilise la technique de similarité cosinus par rapport à chacune des approches d'intégration ci-dessus pour trouver les trois documents les plus similaires à ce document spécifique.
La fonction d'aide suivante prend quatre paramètres principaux :
- Le DataFrame actuel
- L'index du texte pour lequel nous voulons trouver les documents les plus similaires.
- L'intégration spécifique à utiliser
- Les documents les plus similaires que nous voulons, et c'est 3 par défaut.
def find_top_N_similar_documents(df, chosen_index,
embedding_column_name,
top_N=3):
chosen_document_embedding = np.array(df.iloc[chosen_index][embedding_column_name]).reshape(1, -1)
embedding_matrix = np.vstack(df[embedding_column_name])
similarity_scores = cosine_similarity(chosen_document_embedding, embedding_matrix)[0]
df_temp = df.copy()
df_temp['similarity_to_chosen'] = similarity_scores
similar_documents = df_temp.drop(index=chosen_index).sort_values(by='similarity_to_chosen', ascending=False)
top_N_similar = similar_documents.head(top_N)
return top_N_similar[[concatenated_text, 'similarity_to_chosen']]Dans la section suivante, nous recherchons les documents les plus similaires au premier document (index=0).
Voici à quoi ressemble le premier document :
chosen_index = 0
first_document_data = smaller_tokens_docs_reset.iloc[0]["concatenated_text"]
print(first_document_data)
Contenu du premier document (version concaténée)
La fonction de recherche de similarité peut être exécutée comme suit :
top_3_similar_3_small = find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-3-small")
top_3_similar_3_large= find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-3-large")
top_3_similar_ada_002 = find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-ada-002")Après avoir traité les tâches de similarité, le résultat peut être affiché comme suit :
print("Top 3 Similar Documents with :")
print("--> text-embedding-3-small")
print(top_3_similar_3_small)
print("\n")
print("--> text-embedding-3-large")
print(top_3_similar_3_large)
print("\n")
print("--> text-embedding-ada-002")
print(top_3_similar_ada_002)
print("\n")
Les 3 documents les plus similaires en utilisant chaque modèle d'intégration
Observation du résultat
Le modèle "text-embedding-3-small" présente des scores de similarité modérés autour de 0,54, tandis que le modèle "text-embedding-3-large" présente des scores légèrement plus élevés, ce qui indique une meilleure capture de la similarité.
Le modèle "text-embedding-ada-002" présente des scores de similarité nettement plus élevés, le score le plus élevé étant proche de 0,85, ce qui suggère une très forte similarité avec le document choisi.
Cependant, le document 372 est un premier résultat commun à tous les modèles, ce qui indique qu'il est toujours pertinent par rapport à la requête. Les scores variables entre les modèles mettent en évidence l'impact du choix du modèle d'intégration sur les résultats de similarité.
Conclusion
En conclusion, les nouveaux modèles text-embedding-3-large et text-embedding-3-small d'OpenAI représentent une avancée significative dans le domaine du traitement du langage naturel, offrant une représentation plus nuancée et hautement dimensionnelle des données textuelles.
Comme le montre l'article, le choix entre ces modèles peut avoir un impact considérable sur le résultat de diverses tâches de TAL, telles que la similarité des documents, l'analyse des sentiments et les systèmes d'aide multilingue. Alors que le Text-embedding-3-Large offre une plus grande précision grâce à ses dimensions plus importantes, le Text-embedding-3-Small offre un équilibre entre l'efficacité et la performance pour les applications sensibles aux coûts.
L'analyse comparative a révélé que le text-embedding-3-large est plus performant que ses prédécesseurs, établissant ainsi une nouvelle norme dans le domaine. Les applications de ces modèles dans le monde réel sont vastes, allant de l'amélioration de l'assistance à la clientèle à l'alimentation de moteurs de recherche sophistiqués et de systèmes de recommandation de contenu.
En naviguant dans le guide détaillé fourni, les praticiens sur le terrain sont équipés pour prendre des décisions éclairées sur le modèle à utiliser en fonction de la complexité de la tâche, des contraintes budgétaires et de la nécessité d'avoir des capacités multilingues.
En fin de compte, le choix du modèle devrait s'aligner sur les exigences spécifiques du projet en question, en tirant parti des points forts du text-embedding-3-large pour les tâches nécessitant une grande fidélité et du text-embedding-3-small pour des objectifs plus généraux. L'arrivée de ces modèles souligne l'engagement de l'OpenAI à faire progresser la technologie de l'IA et l'évolution continue des outils d'apprentissage automatique.
Que faire maintenant ?
Notre article, L'API OpenAI en Python, est une antisèche qui vous aide à apprendre les bases de l'exploitation de l'une des API d'IA les plus puissantes qui soient, à savoir l'API OpenAI.
Notre session "code along" " Fine-tuning GPT3.5 with OpenAI API " fournit les guides pour utiliser OpenAI API et Python pour commencer à affiner GPT3.5, en aidant à apprendre quand l'affinage de grands modèles de langage peut être bénéfique, comment utiliser les outils d'affinage dans OpenAI API et enfin comprendre le flux de travail de l'affinage.
