O cenário do aprendizado de máquina e do processamento de linguagem natural (NLP) está em constante evolução, com a OpenAI liderando consistentemente o caminho para a inovação.
A introdução de seus modelos text-embedding-3-large e text-embedding-3-small marca uma nova era no campo, definida para mudar a forma como os desenvolvedores e profissionais de IA abordam as tarefas de análise e incorporação de texto.
No complexo mundo da inteligência artificial, os embeddings são cruciais para transformar a complicada linguagem humana em algo que as máquinas possam entender e processar. Esse novo modelo da OpenAI representa um avanço significativo para desenvolvedores e aspirantes a profissionais de dados.
Este artigo tem como objetivo explicar os modelos text-embedding-3-large e text-embedding-3-small, oferecendo insights sobre suas funções principais, vários aplicativos e como usá-los de forma eficaz.
Ao explorar os conceitos básicos de incorporação de texto e destacar os novos recursos e usos práticos do modelo, o artigo pretende fornecer aos leitores as informações necessárias para usar essa ferramenta avançada em seus projetos.
Além disso, ele abordará os princípios básicos para você começar a usar o modelo, compartilhará dicas para aprimorar as tarefas de incorporação e discutirá o amplo impacto desse progresso tecnológico no campo da PNL.
Compreensão de Text Embeddings
Antes de nos aprofundarmos nas especificidades do novo modelo, uma breve visão geral das incorporações de texto é útil para que você entenda melhor.
As incorporações de texto são representações numéricas de texto que capturam a semântica, ou o significado, de palavras, frases ou documentos inteiros. Eles são fundamentais em muitas tarefas de PLN, como análise de sentimentos, classificação de textos e muito mais.
Em nossa Introdução a Text Embeddings com a API OpenAI , você encontrará um guia completo sobre como usar a API OpenAI para criar text embeddings. Descubra suas aplicações na classificação de textos, recuperação de informações e detecção de similaridade semântica.
Veja abaixo uma ilustração usando um modelo de incorporação:
- Os documentos a serem representados estão à esquerda
- O modelo de incorporação no meio, e
- Os embeddings correspondentes de cada documento estão à direita

Ilustração de incorporação de texto
Se você ainda não conhece esse conceito, considere explorar nosso curso Introdução a Embeddings com a API OpenAI. Ele explica como você pode aproveitar os embeddings da OpenAI por meio da API da OpenAI para criar embeddings a partir de dados textuais e começar a desenvolver aplicativos do mundo real.
Visão geral dos novos Embeddings da OpenAI
Anunciados em 25 de janeiro de 2024, esses modelos são os mais recentes e avançados modelos de incorporação projetados para representar o texto em um espaço de alta dimensão, facilitando a compreensão do texto.
O text-embedding-3-small é otimizado para latência e armazenamento. Por outro lado, text-embedding-3-large é uma boa opção para maior precisão, e também podemos aproveitar o novo parâmetro de dimensões para manter a incorporação em 1536 em vez do tamanho nativo de 3072 sem afetar o desempenho geral.
Análise de benchmarking
Antes do lançamento, o text-embedding-ada-2 estava no topo da tabela de classificação de todos os modelos anteriores de incorporação da OpenAI, e a tabela a seguir fornece uma visão geral rápida do benchmarking entre esses três modelos.
|
Modelo |
Dimensão |
Token máximo |
Limite de conhecimento |
Preços ($/1k tokens) |
Média MIRACL |
Média do MTEB |
|
ada v2 |
1536 |
8191 |
Setembro de 2021 |
0.0001 |
31.4 |
61.0 |
|
text-embedding-3-small |
0.00002 |
44.0 |
62.3 |
|||
|
text-embedding-3-large |
3072 |
0.00013 |
54.9 |
64.6 |
Com base nas métricas fornecidas, podemos observar uma melhoria no desempenho do ada v2 (text-embedding-ada-002) para text-embedding-3-large nos benchmarks MIRACL e MTEB. Isso sugere que o text-embedding-3-large, com mais dimensões (3072), oferece melhor qualidade de incorporação em comparação com os outros dois, o que se correlaciona diretamente com as melhores pontuações de benchmark.
O aumento nas dimensões de text-embedding-ada-002 e text-embedding-3-small (ambos 1536) para text-embedding-3-large (3072) sugere um modelo mais complexo que pode capturar um conjunto mais rico de recursos em suas incorporações. No entanto, isso também vem com um preço mais alto por 1.000 tokens processados, indicando uma compensação entre desempenho e custo.
Dependendo dos requisitos específicos de uma tarefa (por exemplo, a necessidade de recursos multilíngues, a complexidade do texto a ser incorporado ou restrições orçamentárias), pode-se escolher um modelo diferente.
Para tarefas que exigem incorporações de alta qualidade em vários idiomas e tarefas, o text-embedding-3-large pode ser preferível, apesar de seu custo mais alto. Por outro lado, para aplicativos com restrições orçamentárias mais rígidas ou em que a precisão ultra-alta talvez não seja tão importante, text-embedding-ada-002 ou text-embedding-3-small podem ser opções mais adequadas.
Aplicações de Text-Embedding-3-Large
As tecnologias de incorporação têm sido extremamente benéficas para muitos aplicativos modernos de processamento e compreensão de linguagem natural. A escolha entre modelos mais avançados, como text-embedding-3-large, e opções mais econômicas, como text-embedding-3-small, pode influenciar o desempenho e a relação custo-benefício dos aplicativos de NLP.
Abaixo você encontra três ilustrações de casos de uso para ambos os modelos, demonstrando sua versatilidade e impactos em cenários reais.
Aplicativos do text-embedding-3-large
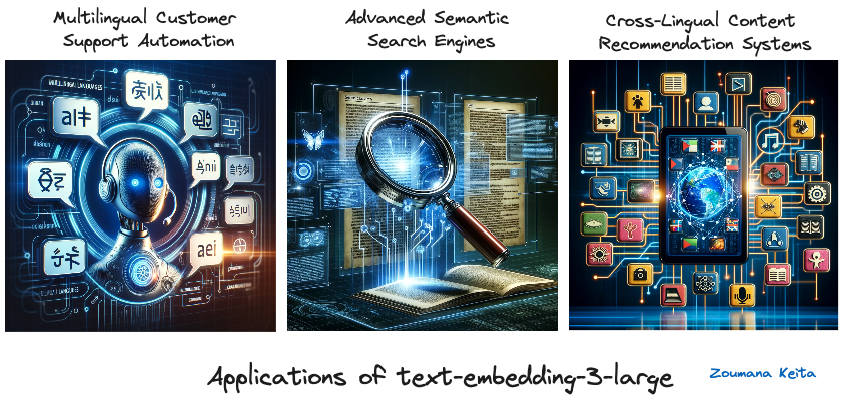
Aplicativos de text-embedding-3-large (imagens geradas usando GPT-4)
Automação do suporte multilíngue ao cliente
Com seu desempenho superior na compreensão e no processamento de 18 idiomas diferentes, o text-embedding-3-large pode alimentar chatbots de suporte ao cliente e sistemas de resposta automatizados para empresas globais, garantindo um suporte preciso e contextualizado em diversas origens linguísticas.
Mecanismos de pesquisa semântica avançada
Aproveitando seus embeddings de alta dimensão, o text-embedding-3-large pode aprimorar os algoritmos dos mecanismos de pesquisa, permitindo que eles entendam melhor as nuances das consultas de pesquisa e recuperem resultados mais relevantes e contextualmente correspondentes, especialmente em campos especializados, como pesquisa jurídica ou médica.
Sistemas de recomendação de conteúdo em vários idiomas
Para plataformas que hospedam uma grande variedade de conteúdo multilíngue, como serviços de streaming ou agregadores de notícias, o text-embedding-3-large pode analisar as preferências do usuário e o conteúdo em vários idiomas, recomendando conteúdo altamente relevante para os usuários, independentemente das barreiras linguísticas.
Aplicativos de text-embedding-3-small

Aplicações de text-embedding-3-small (Imagem gerada usando GPT-4)
Análise de sentimentos econômica
Para startups e empresas de médio porte que buscam entender o sentimento do cliente por meio do monitoramento de mídias sociais ou da análise de feedback, o text-embedding-3-small oferece uma solução econômica e eficaz para avaliar a opinião pública e a satisfação do cliente.
Categorização de conteúdo dimensionável
As plataformas de conteúdo com grandes volumes de dados, como blogs ou sites de comércio eletrônico, podem utilizar o text-embedding-3-small para categorizar automaticamente o conteúdo ou os produtos. Sua eficiência e baixo custo o tornam ideal para lidar com grandes conjuntos de dados sem comprometer a precisão.
Ferramentas eficientes de aprendizado de idiomas
Os aplicativos educacionais que exigem soluções dimensionáveis e econômicas para oferecer exercícios de aprendizado de idiomas, como correspondência de palavras com significados ou verificação gramatical, podem se beneficiar do text-embedding-3-small. Seu equilíbrio entre desempenho e preço acessível permite o desenvolvimento de conteúdo educacional interativo e focado em idiomas.
Esses aplicativos mostram como o text-embedding-3-large e o text-embedding-3-small podem ser implantados de forma ideal em vários setores, alinhando seus pontos fortes com as necessidades específicas de cada aplicativo para melhorar o desempenho, a experiência do usuário e a eficiência de custos.
Um guia passo a passo para você usar os novos Embeddings da OpenAI
Agora temos todas as ferramentas necessárias para prosseguir com a implementação do text-embedding-3-large, text-embedding-3-small e ada-v2 em um cenário de similaridade de documentos.
Todo o código deste tutorial está disponível em uma pasta de trabalho do DataLab. Crie uma cópia desta pasta de trabalho para executar o código sem precisar instalar nada em seu computador.
Sobre os dados
- Esse é o conjunto de dados CORD-19, um recurso de mais de 59.000 artigos acadêmicos, incluindo mais de 48.000 com texto completo, sobre COVID-19, SARS-CoV-2 e coronavírus relacionados.
- Esses dados foram disponibilizados gratuitamente pela Casa Branca e por uma coalizão dos principais grupos de pesquisa para ajudar a pesquisa global a gerar percepções em apoio à luta contínua contra essa doença infecciosa.
- Você pode fazer o download nesta página do Kaggle.
- Mais detalhes sobre o conjunto de dados podem ser encontrados nesta página.
Antes de prosseguir, é importante que você considere a instalação e a importação das seguintes bibliotecas para o sucesso deste projeto.
Usando a instrução %%bash, podemos instalar várias bibliotecas sem usar o ponto de exclamação (!).
%%bash
pip -q install tiktoken
pip -q install openaiAgora, as bibliotecas podem ser importadas da seguinte forma:
import os
import tiktoken
import numpy as np
import pandas as pd
from openai import OpenAI
from sklearn.metrics.pairwise import cosine_similarityVamos entender a função de cada biblioteca:
- os: Fornece uma maneira de usar a funcionalidade dependente do sistema operacional, como ler ou gravar no sistema de arquivos.
- tiktoken: Lida com tarefas de tokenização específicas para o processamento de documentos científicos.
- numpy (np): Adiciona suporte a matrizes e arrays grandes e multidimensionais, além de uma grande coleção de funções matemáticas de alto nível para operar nesses arrays, o que é crucial para a computação científica.
- pandas (pd): Oferece estruturas de dados e operações para manipulação de tabelas numéricas e séries temporais, essenciais para o manuseio de conjuntos de dados científicos.
- openai.OpenAI: Serve como interface para a API da OpenAI, permitindo a interação com modelos de aprendizado de máquina para tarefas como a geração de embeddings para textos científicos.
- sklearn.metrics.pairwise.cosine_similarity: Calcula a similaridade de cosseno entre vetores, útil na análise de similaridade de documentos científicos.
Exploração de dados
O dataframe original tem mais de 1 Gb e, para simplificar, apenas uma amostra de 1.000 observações aleatórias é carregada.
scientific_docs = pd.read_parquet("./data/cord19_df_sample.parquet")Usando a função .head(), podemos ver as duas primeiras linhas dos dados, e o resultado está na animação abaixo.
scientific_docs.head(2)
As duas primeiras linhas dos dados
O corpo, o título e o resumo de um determinado documento científico podem ser suficientes para representar esse documento. Esses três atributos são concatenados para que você obtenha uma única representação textual para cada documento.
Antes disso, vamos ver a porcentagem de valores ausentes em cada uma dessas três colunas:
percent_missing = scientific_docs.isnull().sum() * 100 / len(scientific_docs)
percent_missing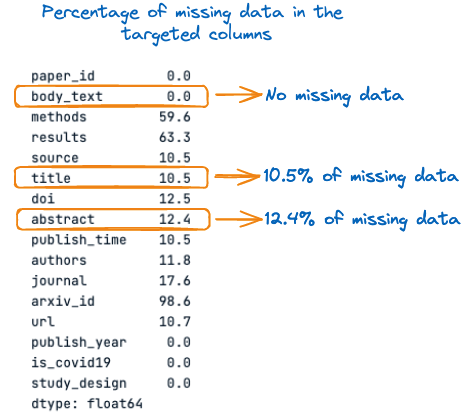
Porcentagem de dados ausentes nas colunas-alvo
Na imagem acima, podemos observar que o título e o resumo têm valores ausentes, respectivamente 10,5% e 12,4%. Por isso, é importante preencher esses valores ausentes com cadeias de caracteres vazias antes da concatenação para evitar a perda de informações.
O processo geral de preenchimento dos valores ausentes e concatenação das colunas é realizado usando a seguinte função.
def concatenate_columns_with_null_handling(df, body_text_column,
abstract_column,
title_column,
new_col_name):
df[new_col_name] = df[body_text_column].fillna('') + df[abstract_column].fillna('') + df[title_column].fillna('')
return dfDepois de executar a função de concatenação nos dados originais e verificar as três primeiras linhas, podemos observar que a concatenação foi bem-sucedida.
new_scientific_docs = concatenate_columns_with_null_handling(scientific_docs,
"body_text",
"abstract",
"title",
"concatenated_text")new_scientific_docs.head(3)A coluna recém-adicionada é concatenated_text.
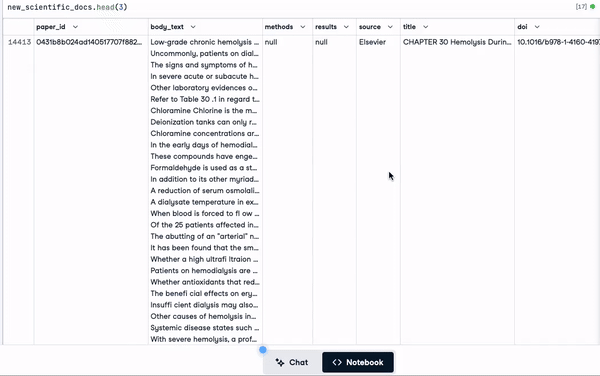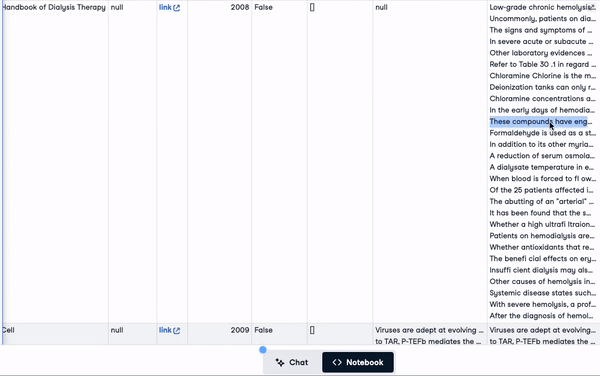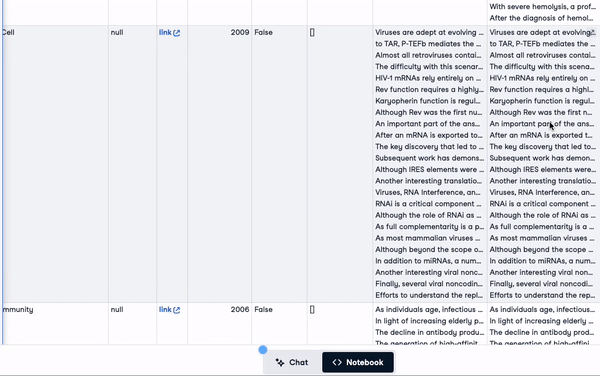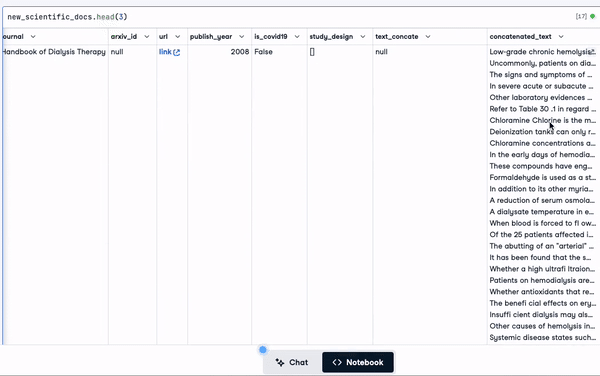
As 3 primeiras linhas com a coluna recém-adicionada
A próxima etapa é aplicar os embeddings na nova coluna usando os diferentes modelos de embedding mencionados neste artigo. Mas antes disso, vamos ver a distribuição do comprimento dos tokens.
O objetivo dessa análise é verificar a limitação máxima de tokens do modelo em relação ao número real de tokens em um determinado documento.
Mas, primeiro, precisamos contar o número total de tokens em cada documento, e isso é feito usando a função auxiliar num_tokens_from_text e o codificador cl100k_base.
def num_tokens_from_text(text: str, encoding_name="cl100k_base"):
"""
Returns the number of tokens in a text string.
"""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(text))
return num_tokensAntes de aplicar a função ao conjunto de dados geral, vamos ver como ela funciona com o texto a seguir: Este artigo é sobre os novos Embeddings da OpenAI.
text = "This article is about new OpenAI Embeddings"
num_tokens = num_tokens_from_text(text)
print(f"Number of tokens: {num_tokens}")Após a execução bem-sucedida do código acima, podemos ver que o texto tem 10 tokens.
![]()
Número de tokens no texto
Com confiança, podemos aplicar a função a todo o texto no dataframe usando a expressão lambda da seguinte forma:
new_scientific_docs['num_tokens'] = new_scientific_docs["concatenated_text"].apply(lambda x: num_tokens_from_text(x))Podemos contar o número total de documentos com mais de 8191 tokens filtrando todo o número de tokens e verificando qual deles é maior do que o limite real de 8191 tokens.
smaller_tokens_docs = new_scientific_docs[new_scientific_docs['num_tokens'] <= 8191]
len(smaller_tokens_docs)⇒ Saída: 764
Isso significa que 764 documentos de 1.000 atendem ao requisito do limite máximo de tokens, e estamos usando esses documentos para simplificar.
Técnicas avançadas podem ser aplicadas para processar o conjunto restante de documentos que têm mais de 8191 tokens.
Uma dessas técnicas é obter a média de todas as incorporações de um único documento. Outra técnica consiste em pegar os primeiros 8191 tokens do documento. Essa abordagem não é eficiente porque pode levar à perda de informações.
Vamos nos certificar de redefinir o índice do dataframe para que ele comece do zero.
smaller_tokens_docs_reset = smaller_tokens_docs.reset_index(drop=True)Executar embeddings
Todos os requisitos são atendidos para que você obtenha a representação de incorporação de todos os documentos, e isso é feito para cada modelo de incorporação.
A primeira etapa é adquirir a credencial do OpenAI e configurar o cliente da seguinte forma:
os.environ["OPENAI_API_KEY"] = "YOUR KEY"
client = OpenAI()Em seguida, a função auxiliar a seguir ajuda a gerar a incorporação, fornecendo o modelo de incorporação e o texto a ser incorporado.
def get_embedding(text_to_embbed, model_ID):
text = text_to_embbed.replace("\n", " ")
return client.embeddings.create(input = [text_to_embbed],
model=model_ID).data[0].embeddingAgora, um novo quadro de dados é criado com três colunas adicionais correspondentes à incorporação de cada um dos três modelos:
- text-embedding-3-small
- text-embedding-3-large
- text-embedding-ada-002
smaller_tokens_docs_reset['text-embedding-3-small'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-3-small"))
smaller_tokens_docs_reset['text-embedding-3-large'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-3-large"))
smaller_tokens_docs_reset['text-embedding-ada-002'] = smaller_tokens_docs_reset["concatenated_text"].apply(lambda x: get_embedding(x, "text-embedding-ada-002"))Depois de executar com êxito o código acima, podemos ver que as colunas de incorporação relevantes foram adicionadas.
smaller_tokens_docs_reset.head(1)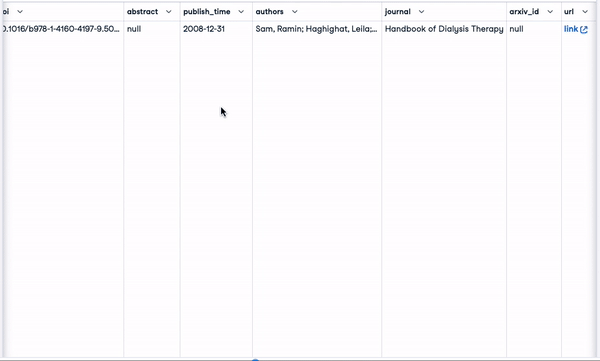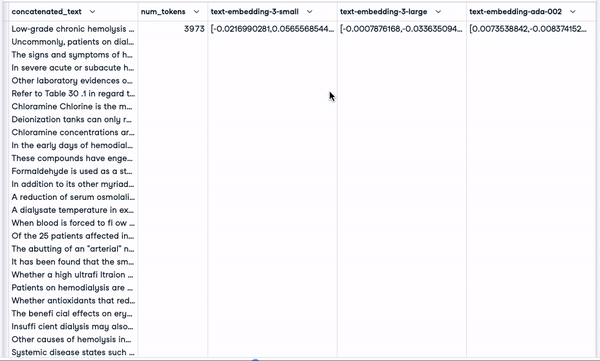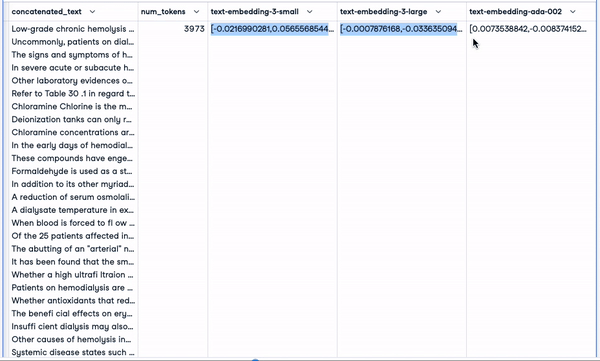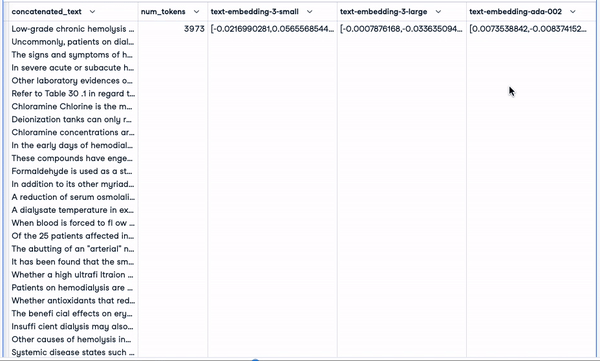
Novo quadro de dados com colunas de incorporação relevantes
Pesquisa de similaridade
Esta seção usa a técnica de similaridade de cosseno em relação a cada uma das abordagens de incorporação acima para encontrar os três principais documentos semelhantes a esse documento específico.
A função auxiliar a seguir recebe quatro parâmetros principais:
- O dataframe atual
- O índice do texto para o qual você deseja encontrar os documentos mais semelhantes
- A incorporação específica a ser usada
- Os principais documentos mais semelhantes que desejamos, que são 3 por padrão.
def find_top_N_similar_documents(df, chosen_index,
embedding_column_name,
top_N=3):
chosen_document_embedding = np.array(df.iloc[chosen_index][embedding_column_name]).reshape(1, -1)
embedding_matrix = np.vstack(df[embedding_column_name])
similarity_scores = cosine_similarity(chosen_document_embedding, embedding_matrix)[0]
df_temp = df.copy()
df_temp['similarity_to_chosen'] = similarity_scores
similar_documents = df_temp.drop(index=chosen_index).sort_values(by='similarity_to_chosen', ascending=False)
top_N_similar = similar_documents.head(top_N)
return top_N_similar[[concatenated_text, 'similarity_to_chosen']]Na seção a seguir, encontraremos os documentos mais semelhantes ao primeiro documento (índice=0)
Esta é a aparência do primeiro documento:
chosen_index = 0
first_document_data = smaller_tokens_docs_reset.iloc[0]["concatenated_text"]
print(first_document_data)
Conteúdo do primeiro documento (versão concatenada)
A função de pesquisa de similaridade pode ser executada da seguinte forma:
top_3_similar_3_small = find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-3-small")
top_3_similar_3_large= find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-3-large")
top_3_similar_ada_002 = find_top_N_similar_documents(smaller_tokens_docs_reset,
chosen_index,
"text-embedding-ada-002")Depois de processar as tarefas de similaridade, o resultado pode ser exibido da seguinte forma:
print("Top 3 Similar Documents with :")
print("--> text-embedding-3-small")
print(top_3_similar_3_small)
print("\n")
print("--> text-embedding-3-large")
print(top_3_similar_3_large)
print("\n")
print("--> text-embedding-ada-002")
print(top_3_similar_ada_002)
print("\n")
Os 3 principais documentos mais semelhantes usando cada modelo de incorporação
Observação do resultado
O modelo "text-embedding-3-small" mostra pontuações de similaridade moderadas em torno de 0,54, enquanto o "text-embedding-3-large" tem pontuações um pouco mais altas, indicando uma melhor captura da similaridade.
O modelo "text-embedding-ada-002" mostra pontuações de similaridade significativamente mais altas, com a pontuação máxima próxima de 0,85, sugerindo uma similaridade muito forte com o documento escolhido.
No entanto, o Documento 372 é um resultado principal comum em todos os modelos, o que indica sua relevância consistente para a consulta. As pontuações variáveis entre os modelos destacam o impacto da escolha do modelo de incorporação nos resultados de similaridade.
Conclusão
Concluindo, os novos modelos text-embedding-3-large e text-embedding-3-small da OpenAI representam um salto significativo no campo do processamento de linguagem natural, oferecendo uma representação mais matizada e de alta dimensão dos dados de texto.
Conforme demonstrado no artigo, a escolha entre esses modelos pode afetar substancialmente o resultado de várias tarefas de PLN, como similaridade de documentos, análise de sentimentos e sistemas de suporte multilíngue. Enquanto o text-embedding-3-large oferece maior precisão devido às suas dimensões maiores, o text-embedding-3-small oferece um equilíbrio entre eficiência e desempenho para aplicativos sensíveis ao custo.
A análise de benchmarking revelou que o text-embedding-3-large supera seus antecessores, estabelecendo um novo padrão no campo. Os aplicativos do mundo real para esses modelos são vastos e vão desde o aprimoramento do suporte ao cliente até a alimentação de sofisticados mecanismos de pesquisa e sistemas de recomendação de conteúdo.
Ao navegar pelo guia detalhado fornecido, os profissionais da área estão preparados para tomar decisões informadas sobre qual modelo usar com base na complexidade da tarefa, nas restrições orçamentárias e na necessidade de recursos multilíngues.
Por fim, a escolha do modelo deve se alinhar às demandas específicas do projeto em questão, aproveitando os pontos fortes do text-embedding-3-large para tarefas que exigem alta fidelidade e do text-embedding-3-small para fins mais gerais. O advento desses modelos ressalta o compromisso da OpenAI com o avanço da tecnologia de IA e a evolução contínua das ferramentas de aprendizado de máquina.
Para onde você vai a partir de agora?
Nosso artigo, A API OpenAI em Python, é uma folha de dicas que ajuda você a aprender os fundamentos de como aproveitar uma das APIs de IA mais avançadas que existem, a API OpenAI.
Nosso código ao longo da sessão Fine-tuning GPT3.5 with OpenAI API fornece os guias para você usar a API OpenAI e o Python para começar a fazer o ajuste fino do GPT3.5, ajudando a aprender quando o ajuste fino de modelos de linguagem grandes pode ser benéfico, como usar as ferramentas de ajuste fino na API OpenAI e, finalmente, entender o fluxo de trabalho do ajuste fino.



