
programa
Fundamentos de OpenAI
15 h
El GPT-OSS 20B es un modelo de lenguaje de peso abierto de la serie gpt-oss de OpenAI, diseñado para casos de uso especializados y de baja latencia. Cuenta con 21 000 millones de parámetros (3600 millones activos) y está optimizado para funcionar de manera eficiente en hardware de consumo, ya que solo requiere unos 16 GB de memoria gracias ala cuantificación MXFP4 ( ).
A pesar de ser más pequeño que el GPT-OSS 120B, sigue admitiendo funciones avanzadas como niveles de razonamiento configurables (bajo, medio, alto), acceso completo a la cadena de pensamiento para la depuración y la transparencia, y capacidades agenticas como llamada de funciones, navegación web y ejecución de código.
En esta guía, te guiaré a través del proceso completo de configuración y ajuste de GPT-OSS 20B. Esto incluye:
Recuerda que este tutorial está destinado a la investigación y la educación, y no al diagnóstico ni al tratamiento de pacientes.

Imagen del autor
Aunque el modelo GPT-OSS tiene 21 000 millones de parámetros, sigue requiriendo una memoria GPU considerable, al menos 80 GB de VRAM para manejar el modelo cómodamente. Una forma rápida de empezar es lanzando una instancia RunPod H100 o un entorno GPU similar con mucha memoria.

Una vez que el entorno esté listo, instala todos los paquetes Python necesarios para el procesamiento de datos, el ajuste de modelos y el programa de experimentos:
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U trackio
%pip install -U openai-harmony
%pip install -U tiktoken
%pip install -U pyctcdecodePor último, inicia sesión en Hugging Face Hub con tu clave API. Esto te permitirá guardar y compartir el modelo ajustado y el tokenizador directamente en tu cuenta de Hugging Face:
from huggingface_hub import notebook_login
notebook_login()A continuación, cargamos el GPT-OSS 20B con cuantificación MXFP4, pero inmediatamente descuantificamos los pesos a bfloat16 al cargarlos, utilizando atención anticipada, caché desactivada y colocación automática de dispositivos.
import torch
from transformers import AutoModelForCausalLM, Mxfp4Config
quantization_config = Mxfp4Config(dequantize=True)
model_kwargs = dict(
attn_implementation="eager",
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
use_cache=False,
device_map="auto",
)
model = AutoModelForCausalLM.from_pretrained("openai/gpt-oss-20b", **model_kwargs)Además del modelo, también necesitamos el tokenizador del mismo repositorio. El tokenizador se encarga de convertir el texto en tokens (identificadores) que el modelo puede procesar y, a continuación, descodificar los resultados del modelo de nuevo en texto legible para los humanos.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")OpenAI Harmony es un formato de respuesta especializado utilizado por los modelos GPT-OSS para estructurar conversaciones, resultados de razonamiento y llamadas a funciones de manera coherente.
Define cómo se organizan los mensajes entre las diferentes funciones (sistema, programadores, usuario, asistente) y permite que el modelo genere resultados a través de múltiples canales, por ejemplo, separando el razonamiento de la cadena de pensamiento, los preámbulos de llamada a herramientas y las respuestas finales dirigidas al usuario.
En esta sección, crearemos una función que tomará una pregunta y una respuesta y las formateará en un mensaje de conversación al estilo Harmony. Utiliza la biblioteca openai_harmony para codificar la conversación de forma estructurada.
from openai_harmony import (
load_harmony_encoding, HarmonyEncodingName,
Conversation, Message, Role,
SystemContent, DeveloperContent, ReasoningEffort
)
enc = load_harmony_encoding(HarmonyEncodingName.HARMONY_GPT_OSS)
def render_pair_harmony(question, answer):
convo = Conversation.from_messages([
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions(
"You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. "
"Respond with ONLY the final diagnosis/cause in ≤5 words."
)
),
Message.from_role_and_content(Role.USER, question.strip()),
Message.from_role_and_content(Role.ASSISTANT, answer.strip()),
])
tokens = enc.render_conversation(convo)
text = enc.decode(tokens)
return textAhora cargaremos el conjunto de datos de preguntas y respuestas médicas (FreedomIntelligence/medical-o1-verifiable-problem ) y aplicaremos la función prompt_style_harmony a cada ejemplo. El texto transformado se almacena en una nueva columna llamada «texto», lo que proporciona un formato limpio y basado en instrucciones que se ajusta al estilo de las indicaciones de los programadores.
from datasets import load_dataset
def prompt_style_harmony(examples):
qs = examples["Open-ended Verifiable Question"]
ans = examples["Ground-True Answer"]
outputs = {"text": []}
for q, a in zip(qs, ans):
rendered = render_pair_harmony(q, a)
outputs["text"].append(rendered)
return outputs
dataset = load_dataset(
"FreedomIntelligence/medical-o1-verifiable-problem",
split="train[0:1000]"
)
dataset = dataset.map(prompt_style_harmony, batched=True)
print(dataset.column_names)
print(dataset[0]["text"])El conjunto de datos ahora contiene una nueva columna «texto», que contiene la conversación con formato Harmony. Esto incluye:
['Open-ended Verifiable Question', 'Ground-True Answer', 'text']
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>An 88-year-old woman with osteoarthritis is experiencing mild epigastric discomfort and has vomited material resembling coffee grounds multiple times. Considering her use of naproxen, what is the most likely cause of her gastrointestinal blood loss?<|end|><|start|>assistant<|message|>Gastric ulcer<|end|>Antes de entrenar el modelo, es importante evaluar su rendimiento de referencia para compararlo después del ajuste fino. Para ello, definimos una función auxiliar render_inference_harmony que prepara un mensaje al estilo Harmony que contiene las instrucciones estrictas de los programadores y la pregunta del usuario, pero deja la respuesta del asistente en blanco para que el modelo la complete.
def render_inference_harmony(question):
convo = Conversation.from_messages([
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions(
"You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. "
"Respond with ONLY the final diagnosis/cause in ≤5 words."
)
),
Message.from_role_and_content(Role.USER, question.strip()),
])
tokens = enc.render_conversation_for_completion(convo, Role.ASSISTANT)
text = enc.decode(tokens)
return textA continuación, tomamos la primera muestra del conjunto de datos, la formateamos utilizando esta función, la tokenizamos y la pasamos por el modelo para generar una respuesta:
question = dataset[0]["Open-ended Verifiable Question"]
text = render_inference_harmony(question)
inputs = tokenizer(
[text + tokenizer.eos_token], return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=20,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])En esta prueba, el resultado del modelo es notablemente más largo y descriptivo de lo solicitado, a pesar de que las instrucciones de los programadores pedían explícitamente un diagnóstico conciso (≤5 palabras).
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>An 88-year-old woman with osteoarthritis is experiencing mild epigastric discomfort and has vomited material resembling coffee grounds multiple times. Considering her use of naproxen, what is the most likely cause of her gastrointestinal blood loss?<|end|><|start|>assistant<|return|>We have an old woman with NSAID use causing ulcer bleed. The question: "An 88En lugar de responder simplemente «Úlcera gástrica» (la etiqueta de verdad fundamental), el modelo generó una explicación detallada sobre el uso de AINE y la hemorragia por úlcera.
dataset[0]["Ground-True Answer"]'Gastric ulcer'Para ajustar el modelo de manera eficiente, utilizamos LoRA (Low-Rank Adaptation), que nos permite entrenar solo un pequeño subconjunto de parámetros mientras mantenemos congelado el modelo base. Esto reduce drásticamente el uso de memoria y el costo de formación.
Comenzamos definiendo un adaptador de red ( LoraConfig ) que especifica el rango, el factor de escala y las capas objetivo específicas donde se insertarán los adaptadores LoRA.
from peft import LoraConfig, get_peft_model
peft_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules="all-linear",
target_parameters=[
"7.mlp.experts.gate_up_proj",
"7.mlp.experts.down_proj",
"15.mlp.experts.gate_up_proj",
"15.mlp.experts.down_proj",
"23.mlp.experts.gate_up_proj",
"23.mlp.experts.down_proj",
],
)
peft_model = get_peft_model(model, peft_config)
peft_model.print_trainable_parameters()Solo hay unos 15 millones de parámetros (≈0,07 % del modelo completo) que se pueden entrenar, y el tamaño del adaptador es de unos 16 MB, lo que supone una enorme ganancia de eficiencia en comparación con el ajuste fino completo.
trainable params: 15,040,512 || all params: 20,929,797,696 || trainable%: 0.0719A continuación, configuramos la configuración de entrenamiento utilizando SFTConfig de la biblioteca trl. Esto incluye hiperparámetros como la tasa de aprendizaje, el tamaño del lote, la acumulación de gradientes, la relación de calentamiento y el tipo de programador:
from trl import SFTConfig
training_args = SFTConfig(
learning_rate=2e-4,
gradient_checkpointing=True,
num_train_epochs=1,
logging_steps=10,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_length=2048,
warmup_ratio=0.03,
lr_scheduler_type="cosine_with_min_lr",
lr_scheduler_kwargs={"min_lr_rate": 0.1},
output_dir="gpt-oss-20b-medical-qa",
report_to="trackio",
push_to_hub=True,
)Con el conjunto de datos preparado, el adaptador LoRA conectado y los argumentos de entrenamiento configurados, ya podemos iniciar el proceso de ajuste fino. Utilizamos el pa quete « SFTTrainer » de la biblioteca « trl », que simplifica el ajuste supervisado al gestionar el modelo, el tokenizador, el conjunto de datos y el bucle de entrenamiento en un solo lugar:
from trl import SFTTrainer
trainer = SFTTrainer(
model=peft_model,
args=training_args,
train_dataset=dataset,
processing_class=tokenizer,
)
trainer.train()Durante el entrenamiento, la pérdida disminuye gradualmente, lo que indica que el modelo está aprendiendo a alinear sus respuestas con el conjunto de datos de preguntas y respuestas médicas con formato Harmony.
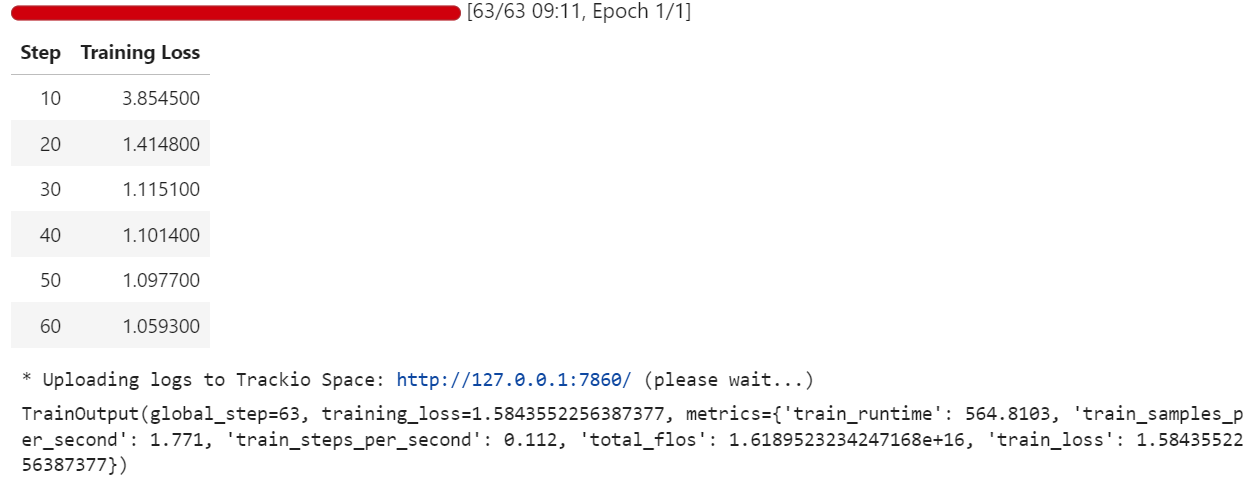
Una vez completado el entrenamiento, guardamos el modelo ajustado localmente y luego lo enviamos al Hugging Face Hub. Es importante destacar que solo se cargan los pesos del adaptador LoRA (no el modelo 20B completo), lo que hace que el repositorio sea ligero y fácil de compartir:
trainer.save_model(training_args.output_dir)
trainer.push_to_hub(dataset_name="kingabzpro/gpt-oss-20b-medical-qa")
Esto crea un nuevo repositorio de modelos en Hugging Face en: kingabzpro/gpt-oss-20b-medical-qa.
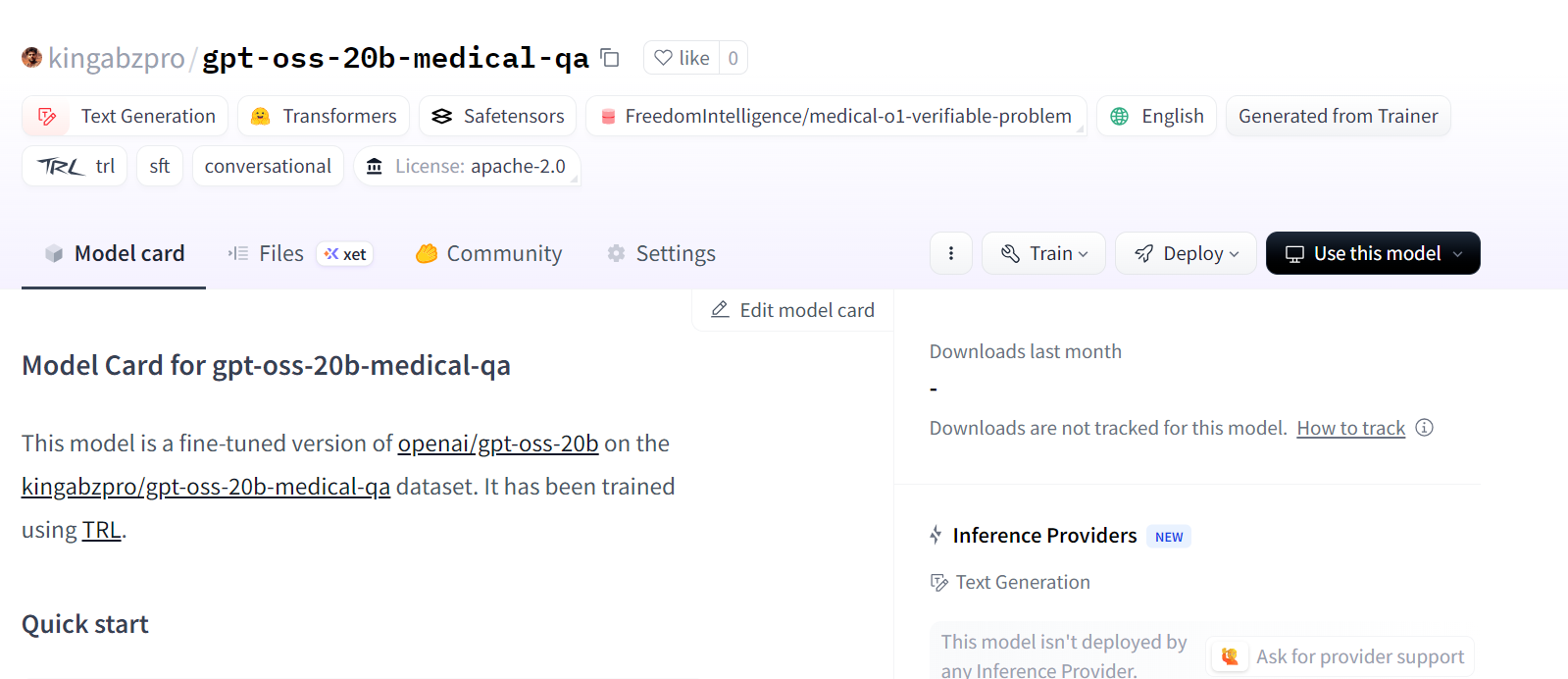
Fuente: kingabzpro/gpt-oss-20b-medical-qa
Tras el ajuste, podemos probar el modelo para verificar si ahora sigue más fielmente las instrucciones de los programadores. Para ello, primero cargamos el modelo base GPT-OSS 20B y, a continuación, añadimos los adaptadores LoRA ajustados.
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")
# Load the original model first
model_kwargs = dict(attn_implementation="eager", torch_dtype="auto", use_cache=True, device_map="auto")
base_model = AutoModelForCausalLM.from_pretrained("openai/gpt-oss-20b", **model_kwargs).cuda()
# Merge fine-tuned weights with the base model
peft_model_id = "gpt-oss-20b-medical-qa"
model = PeftModel.from_pretrained(base_model, peft_model_id)
model = model.merge_and_unload()A continuación, realizamos una inferencia sobre una muestra del conjunto de datos. La pregunta se formatea al estilo Harmony, se tokeniza, se pasa por el modelo y se decodifica de nuevo en texto:
question = dataset[0]["Open-ended Verifiable Question"]
text = render_inference_harmony(question)
inputs = tokenizer(
[text + tokenizer.eos_token], return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=20,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])El modelo ajustado ahora produce una respuesta breve y precisa. Esto se acerca mucho más a la etiqueta de la verdad fundamental («Úlcera gástrica») y cumple la restricción de ≤5 palabras.
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>An 88-year-old woman with osteoarthritis is experiencing mild epigastric discomfort and has vomited material resembling coffee grounds multiple times. Considering her use of naproxen, what is the most likely cause of her gastrointestinal blood loss?<|end|><|start|>assistant<|return|><|message|>Stomach ulcer<|end|><|return|>También podemos analizar otra muestra para confirmar la consistencia:
question = dataset[10]["Open-ended Verifiable Question"]
text = render_inference_harmony(question)
inputs = tokenizer(
[text + tokenizer.eos_token], return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=20,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])Perfecto. El modelo ajustado ha generado respuestas concisas, precisas y que siguen las instrucciones.
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>What substance is primarily filtered in the renal tubules with minimal secretion or re-absorption?<|end|><|start|>assistant<|return|><|message|>creatinine<|end|><|return|>Son tiempos emocionantes para la comunidad de IA de código abierto. Aunque los nuevos modelos GPT-OSS aún no alcancen los primeros puestos en las pruebas comparativas, son muy prometedores, especialmente en sus respectivas clases de parámetros, donde los modelos más pequeños pueden seguir ofreciendo resultados impresionantes.
En este tutorial, hemos ajustado el modelo GPT-OSS 20B para responder preguntas médicas utilizando adaptadores LoRA y el estilo de indicaciones Harmony. Los resultados son alentadores: el modelo ajustado produce respuestas concisas y precisas alineadas con las tareas de razonamiento clínico. Con más épocas de entrenamiento, conjuntos de datos más grandes y indicaciones del sistema más refinadas, el rendimiento puede mejorarse aún más.
Si estás buscando un curso práctico para familiarizarte con el ajuste fino, no dejes de consultar Ajuste fino con Llama 3.
Mejores cursos de OpenAI
programa
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Abid Ali Awan
9 min
blog
Josep Ferrer
8 min
Tutorial
Zoumana Keita
Tutorial
Moez Ali
Tutorial
Abid Ali Awan


