
Programa
OpenAI Fundamentals
15 h
O GPT-OSS 20B é um modelo de linguagem de peso aberto da série gpt-oss da OpenAI, projetado para baixa latência e casos de uso especializados. Tem 21 bilhões de parâmetros (3,6 bilhões ativos) e é otimizado para funcionar bem em hardware comum, precisando de só uns 16 GB de memória, graças àquantização MXFP4 d .
Apesar de ser menor que o GPT-OSS 120B, ele ainda suporta recursos avançados como níveis de raciocínio configuráveis (baixo, médio, alto), acesso completo à cadeia de pensamento para depuração e transparência, e recursos de agência como chamada de funções, navegação na web e execução de código.
Neste guia, vou te mostrar todo o processo de configuração e ajuste fino do GPT-OSS 20B. Isso inclui:
Lembre-se de que este tutorial é para pesquisa e educação, e não para diagnóstico ou tratamento de pacientes.

Imagem do autor
Mesmo que o modelo GPT-OSS tenha 21 bilhões de parâmetros, ainda precisa de bastante memória GPU, pelo menos 80 GB de VRAM pra rodar o modelo direitinho. Uma maneira rápida de começar é iniciar uma instância RunPod H100 ou um ambiente GPU semelhante com alta memória.

Quando o ambiente estiver pronto, instale todos os pacotes Python necessários para processamento de dados, ajuste fino do modelo e programa de experimentos:
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U trackio
%pip install -U openai-harmony
%pip install -U tiktoken
%pip install -U pyctcdecodePor fim, entre no Hugging Face Hub usando sua chave API. Isso vai te ajudar a salvar e compartilhar o modelo ajustado e o tokenizador direto na sua conta Hugging Face:
from huggingface_hub import notebook_login
notebook_login()Depois, carregamos o GPT-OSS 20B com quantização MXFP4, mas imediatamente desquantizamos os pesos para bfloat16 no carregamento, usando atenção ansiosa, cache desativado e posicionamento automático do dispositivo.
import torch
from transformers import AutoModelForCausalLM, Mxfp4Config
quantization_config = Mxfp4Config(dequantize=True)
model_kwargs = dict(
attn_implementation="eager",
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
use_cache=False,
device_map="auto",
)
model = AutoModelForCausalLM.from_pretrained("openai/gpt-oss-20b", **model_kwargs)Além do modelo, também precisamos do tokenizador do mesmo repositório. O tokenizador é responsável por transformar o texto em tokens (IDs) que o modelo consegue processar e, depois, decifrar os resultados do modelo de volta em texto que a gente consegue entender.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")O OpenAI Harmony é um formato de resposta especializado que os modelos GPT-OSS usam pra organizar conversas, resultados de raciocínio e chamadas de função de um jeito consistente.
Ele define como as mensagens são organizadas entre as funções (sistema, desenvolvedor, usuário, assistente) e permite que o modelo gere resultados em vários canais — por exemplo, separando o raciocínio da cadeia de pensamentos, os preâmbulos de chamada de ferramentas e as respostas finais voltadas para o usuário.
Nesta seção, vamos criar uma função que pegará uma pergunta e uma resposta e as formatará em um prompt de conversa no estilo Harmony. Ele usa a biblioteca openai_harmony para codificar a conversa de forma estruturada.
from openai_harmony import (
load_harmony_encoding, HarmonyEncodingName,
Conversation, Message, Role,
SystemContent, DeveloperContent, ReasoningEffort
)
enc = load_harmony_encoding(HarmonyEncodingName.HARMONY_GPT_OSS)
def render_pair_harmony(question, answer):
convo = Conversation.from_messages([
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions(
"You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. "
"Respond with ONLY the final diagnosis/cause in ≤5 words."
)
),
Message.from_role_and_content(Role.USER, question.strip()),
Message.from_role_and_content(Role.ASSISTANT, answer.strip()),
])
tokens = enc.render_conversation(convo)
text = enc.decode(tokens)
return textAgora vamos carregar o conjunto de dados de perguntas e respostas médicas (FreedomIntelligence/medical-o1-verifiable-problem ) e vamos aplicar a função prompt_style_harmony a cada exemplo. O texto transformado é guardado numa nova coluna chamada “texto”, dando um formato limpo e orientado por instruções que se alinha com o estilo de prompt do desenvolvedor.
from datasets import load_dataset
def prompt_style_harmony(examples):
qs = examples["Open-ended Verifiable Question"]
ans = examples["Ground-True Answer"]
outputs = {"text": []}
for q, a in zip(qs, ans):
rendered = render_pair_harmony(q, a)
outputs["text"].append(rendered)
return outputs
dataset = load_dataset(
"FreedomIntelligence/medical-o1-verifiable-problem",
split="train[0:1000]"
)
dataset = dataset.map(prompt_style_harmony, batched=True)
print(dataset.column_names)
print(dataset[0]["text"])O conjunto de dados agora tem uma nova coluna “texto”, que guarda a conversa formatada pelo Harmony. Isso inclui:
['Open-ended Verifiable Question', 'Ground-True Answer', 'text']
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>An 88-year-old woman with osteoarthritis is experiencing mild epigastric discomfort and has vomited material resembling coffee grounds multiple times. Considering her use of naproxen, what is the most likely cause of her gastrointestinal blood loss?<|end|><|start|>assistant<|message|>Gastric ulcer<|end|>Antes de treinar o modelo, é importante avaliar seu desempenho inicial para comparar depois do ajuste fino. Pra fazer isso, a gente define uma função auxiliar render_inference_harmony que prepara um prompt no estilo Harmony com as instruções do desenvolvedor e a pergunta do usuário, mas deixa a resposta do assistente em branco pra o modelo completar.
def render_inference_harmony(question):
convo = Conversation.from_messages([
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions(
"You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. "
"Respond with ONLY the final diagnosis/cause in ≤5 words."
)
),
Message.from_role_and_content(Role.USER, question.strip()),
])
tokens = enc.render_conversation_for_completion(convo, Role.ASSISTANT)
text = enc.decode(tokens)
return textDepois, pegamos a primeira amostra do conjunto de dados, formatamos usando essa função, tokenizamos e passamos pelo modelo para gerar uma resposta:
question = dataset[0]["Open-ended Verifiable Question"]
text = render_inference_harmony(question)
inputs = tokenizer(
[text + tokenizer.eos_token], return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=20,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])Neste teste, a resposta do modelo é visivelmente mais longa e descritiva do que o solicitado, mesmo que as instruções do desenvolvedor pedissem explicitamente um diagnóstico conciso (≤5 palavras).
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>An 88-year-old woman with osteoarthritis is experiencing mild epigastric discomfort and has vomited material resembling coffee grounds multiple times. Considering her use of naproxen, what is the most likely cause of her gastrointestinal blood loss?<|end|><|start|>assistant<|return|>We have an old woman with NSAID use causing ulcer bleed. The question: "An 88Em vez de só responder “Úlcera gástrica” (o rótulo da verdade fundamental), o modelo deu uma explicação detalhada sobre o uso de AINEs e o sangramento da úlcera.
dataset[0]["Ground-True Answer"]'Gastric ulcer'Para ajustar o modelo de forma eficiente, usamos LoRA (Low-Rank Adaptation), que nos permite treinar apenas um pequeno subconjunto de parâmetros, mantendo o modelo base congelado. Isso reduz bastante o uso de memória e o custo do treinamento.
Começamos definindo um adaptador de camada ( LoraConfig ) que especifica a classificação, o fator de escala e as camadas-alvo específicas onde os adaptadores LoRA serão inseridos.
from peft import LoraConfig, get_peft_model
peft_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules="all-linear",
target_parameters=[
"7.mlp.experts.gate_up_proj",
"7.mlp.experts.down_proj",
"15.mlp.experts.gate_up_proj",
"15.mlp.experts.down_proj",
"23.mlp.experts.gate_up_proj",
"23.mlp.experts.down_proj",
],
)
peft_model = get_peft_model(model, peft_config)
peft_model.print_trainable_parameters()Existem apenas cerca de 15 milhões de parâmetros (≈0,07% do modelo completo) que podem ser treinados, e o tamanho do adaptador é de cerca de 16 MB, um grande ganho de eficiência em comparação com o ajuste fino completo.
trainable params: 15,040,512 || all params: 20,929,797,696 || trainable%: 0.0719Depois, vamos configurar o treinamento usando o método ` SFTConfig ` da biblioteca ` trl `. Isso inclui hiperparâmetros como taxa de aprendizagem, tamanho do lote, acumulação de gradiente, taxa de aquecimento e tipo de agendador:
from trl import SFTConfig
training_args = SFTConfig(
learning_rate=2e-4,
gradient_checkpointing=True,
num_train_epochs=1,
logging_steps=10,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_length=2048,
warmup_ratio=0.03,
lr_scheduler_type="cosine_with_min_lr",
lr_scheduler_kwargs={"min_lr_rate": 0.1},
output_dir="gpt-oss-20b-medical-qa",
report_to="trackio",
push_to_hub=True,
)Com o conjunto de dados pronto, o adaptador LoRA conectado e os argumentos de treinamento configurados, agora podemos começar o processo de ajuste fino. Usamos o SFTTrainer da biblioteca trl, que simplifica o ajuste supervisionado ao lidar com o modelo, o tokenizador, o conjunto de dados e o loop de treinamento em um só lugar:
from trl import SFTTrainer
trainer = SFTTrainer(
model=peft_model,
args=training_args,
train_dataset=dataset,
processing_class=tokenizer,
)
trainer.train()Durante o treinamento, a perda diminui aos poucos, mostrando que o modelo está aprendendo a alinhar suas respostas com o conjunto de dados de perguntas e respostas médicas no formato Harmony.
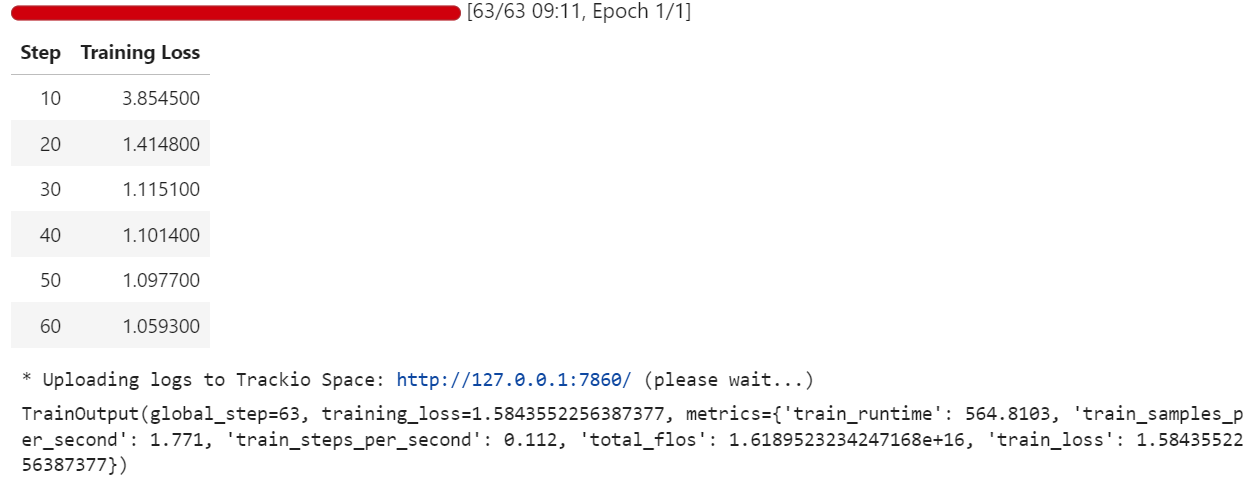
Quando o treinamento estiver pronto, a gente salva o modelo ajustado localmente e depois manda ele pro Hugging Face Hub. É importante ressaltar que só os pesos do adaptador LoRA (não o modelo 20B completo) são carregados, tornando o repositório leve e fácil de compartilhar:
trainer.save_model(training_args.output_dir)
trainer.push_to_hub(dataset_name="kingabzpro/gpt-oss-20b-medical-qa")
Isso cria um novo repositório de modelos no Hugging Face em: kingabzpro/gpt-oss-20b-medical-qa.
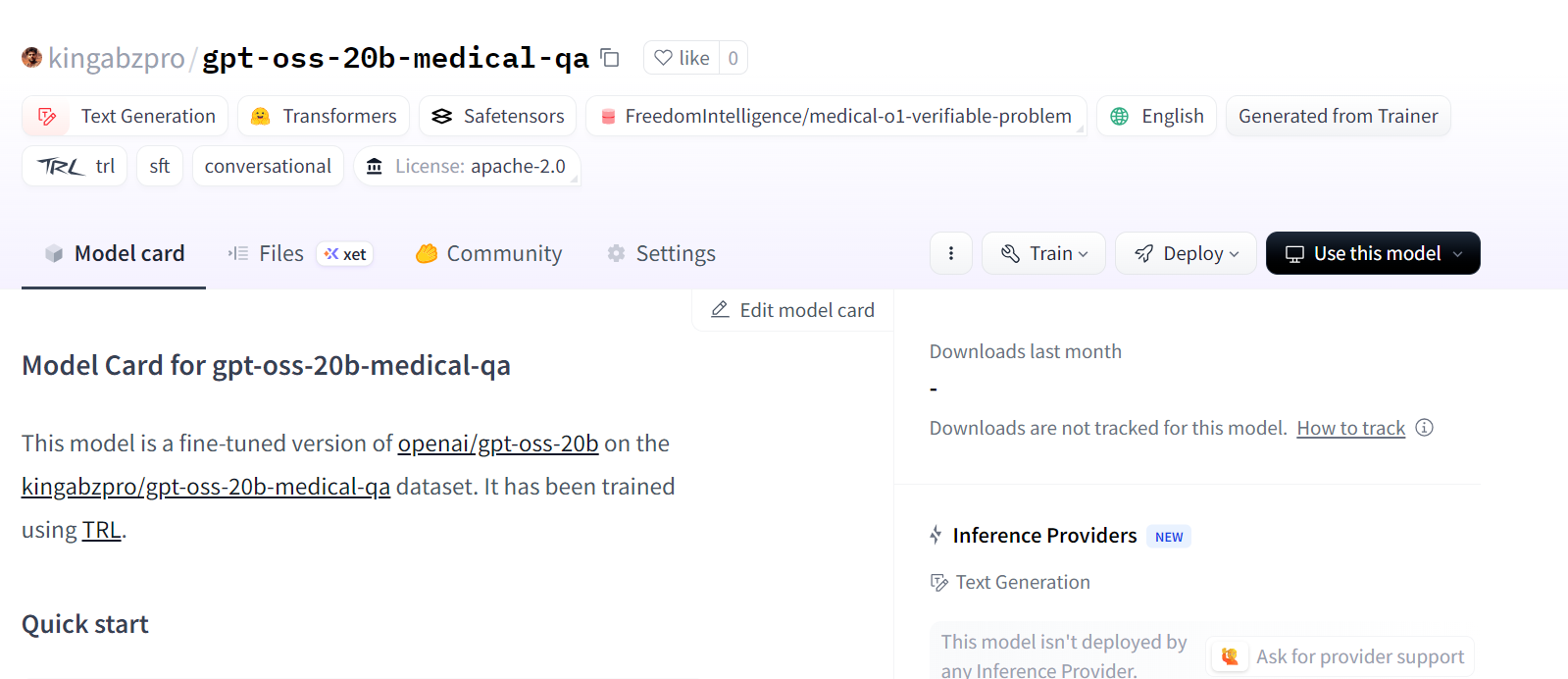
Fonte: kingabzpro/gpt-oss-20b-medical-qa
Depois de ajustar tudo, a gente pode testar o modelo pra ver se ele tá seguindo melhor as instruções do desenvolvedor. Para fazer isso, primeiro carregamos o modelo base GPT-OSS 20B e, em seguida, anexamos os adaptadores LoRA ajustados.
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")
# Load the original model first
model_kwargs = dict(attn_implementation="eager", torch_dtype="auto", use_cache=True, device_map="auto")
base_model = AutoModelForCausalLM.from_pretrained("openai/gpt-oss-20b", **model_kwargs).cuda()
# Merge fine-tuned weights with the base model
peft_model_id = "gpt-oss-20b-medical-qa"
model = PeftModel.from_pretrained(base_model, peft_model_id)
model = model.merge_and_unload()Depois, fazemos uma inferência em uma amostra do conjunto de dados. A pergunta é formatada no estilo Harmony, tokenizada, passada pelo modelo e decodificada de volta em texto:
question = dataset[0]["Open-ended Verifiable Question"]
text = render_inference_harmony(question)
inputs = tokenizer(
[text + tokenizer.eos_token], return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=20,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])O modelo ajustado agora dá uma resposta curta e precisa. Isso está bem mais próximo do rótulo da verdade fundamental (“Úlcera gástrica”) e segue a restrição de ≤5 palavras.
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>An 88-year-old woman with osteoarthritis is experiencing mild epigastric discomfort and has vomited material resembling coffee grounds multiple times. Considering her use of naproxen, what is the most likely cause of her gastrointestinal blood loss?<|end|><|start|>assistant<|return|><|message|>Stomach ulcer<|end|><|return|>Também podemos testar outra amostra para confirmar a consistência:
question = dataset[10]["Open-ended Verifiable Question"]
text = render_inference_harmony(question)
inputs = tokenizer(
[text + tokenizer.eos_token], return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=20,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])Perfeito. O modelo ajustado gerou respostas concisas, precisas e que seguem as instruções.
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>What substance is primarily filtered in the renal tubules with minimal secretion or re-absorption?<|end|><|start|>assistant<|return|><|message|>creatinine<|end|><|return|>É um momento super legal para a galera que curte IA de código aberto. Mesmo que os novos modelos GPT-OSS ainda não estejam no topo dos benchmarks, eles parecem bem promissores, principalmente nas suas respectivas classes de parâmetros, onde modelos menores ainda podem dar resultados impressionantes.
Neste tutorial, ajustamos o modelo GPT-OSS 20B para responder perguntas médicas usando adaptadores LoRA e o estilo de prompt Harmony. Os resultados são animadores: o modelo ajustado dá respostas diretas e precisas, alinhadas com as tarefas de raciocínio clínico. Com mais épocas de treinamento, conjuntos de dados maiores e prompts de sistema refinados, o desempenho pode ser melhorado ainda mais.
Se você está procurando um curso prático para se familiarizar com o ajuste fino, não deixe de conferir Ajuste fino com Llama 3.
Principais cursos da OpenAI
Programa
Curso
Curso
blog
Josep Ferrer
8 min
blog
Abid Ali Awan
9 min
Tutorial
Moez Ali
Tutorial
Josep Ferrer
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali



