
Cursus
Fondamentaux d’OpenAI
15 h
Le GPT-OSS 20B est un modèle linguistique à poids ouvert de la série gpt-oss d'OpenAI, conçu pour une faible latence et des cas d'utilisation spécialisés. Il dispose de 21 milliards de paramètres (dont 3,6 milliards actifs) et est optimisé pour fonctionner efficacement sur du matériel grand public, ne nécessitant qu'environ 16 Go de mémoire grâce àla quantification MXFP4 d' .
Bien qu'il soit plus petit que le GPT-OSS 120B, il prend tout de même en charge des fonctionnalités avancées telles que niveaux de raisonnement configurables (faible, moyen, élevé), un accès complet à la chaîne de pensée pour le débogage et la transparence, et des des capacités d'agent telles que l'appel de fonctions, la navigation sur le Web et l'exécution de code.
Dans ce guide, je vous accompagnerai tout au long du processus complet de configuration et de réglage de GPT-OSS 20B. Cela comprend :
Veuillez noter que ce tutoriel est destiné à la recherche et à l'enseignement, et non au diagnostic ou au traitement des patients.

Image par l'auteur
Bien que le modèle GPT-OSS dispose de 21 milliards de paramètres, il nécessite tout de même une mémoire GPU importante, au moins 80 Go de VRAM, pour fonctionner correctement. Une méthode rapide pour démarrer est de lancer une instance RunPod H100 ou un environnement GPU similaire à mémoire élevée.

Une fois l'environnement prêt, veuillez installer tous les paquets Python requis pour le traitement des données, le réglage fin du modèle et le cursus des expériences :
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U trackio
%pip install -U openai-harmony
%pip install -U tiktoken
%pip install -U pyctcdecodeEnfin, veuillez vous connecter au Hugging Face Hub à l'aide de votre clé API. Cela vous permettra d'enregistrer et de partager le modèle et le tokenizer optimisés directement sur votre compte Hugging Face :
from huggingface_hub import notebook_login
notebook_login()Ensuite, nous chargeons le GPT-OSS 20B avec la quantification MXFP4, mais nous déquantifions immédiatement les poids en bfloat16 lors du chargement, en utilisant l'attention anticipée, le cache désactivé et le placement automatique des périphériques.
import torch
from transformers import AutoModelForCausalLM, Mxfp4Config
quantization_config = Mxfp4Config(dequantize=True)
model_kwargs = dict(
attn_implementation="eager",
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
use_cache=False,
device_map="auto",
)
model = AutoModelForCausalLM.from_pretrained("openai/gpt-oss-20b", **model_kwargs)En plus du modèle, nous avons également besoin du tokenizer provenant du même référentiel. Le tokeniseur est chargé de convertir le texte en tokens (identifiants) que le modèle peut traiter, puis de décoder les résultats du modèle en texte lisible par l'utilisateur.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")OpenAI Harmony est un format de réponse spécialisé utilisé par les modèles GPT-OSS pour structurer les conversations, les résultats de raisonnement et les appels de fonction de manière cohérente.
Il définit la manière dont les messages sont organisés entre les différents rôles (système, développeur, utilisateur, assistant) et permet au modèle de produire des résultats sur plusieurs canaux, par exemple en séparant le raisonnement en chaîne, les préambules d'appel d'outils et les réponses finales destinées à l'utilisateur.
Dans cette section, nous allons créer une fonction qui prendra une question et une réponse et les mettra en forme dans une invite de conversation de style Harmony. Il utilise la bibliothèque openai_harmony pour encoder la conversation de manière structurée.
from openai_harmony import (
load_harmony_encoding, HarmonyEncodingName,
Conversation, Message, Role,
SystemContent, DeveloperContent, ReasoningEffort
)
enc = load_harmony_encoding(HarmonyEncodingName.HARMONY_GPT_OSS)
def render_pair_harmony(question, answer):
convo = Conversation.from_messages([
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions(
"You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. "
"Respond with ONLY the final diagnosis/cause in ≤5 words."
)
),
Message.from_role_and_content(Role.USER, question.strip()),
Message.from_role_and_content(Role.ASSISTANT, answer.strip()),
])
tokens = enc.render_conversation(convo)
text = enc.decode(tokens)
return textNous allons maintenant charger l'ensemble de données de questions-réponses médicales (FreedomIntelligence/medical-o1-verifiable-problem ) et appliquer la fonction prompt_style_harmony à chaque exemple. Le texte transformé est stocké dans une nouvelle colonne intitulée « texte », ce qui donne un format clair, basé sur des instructions, qui correspond au style d'invite du développeur.
from datasets import load_dataset
def prompt_style_harmony(examples):
qs = examples["Open-ended Verifiable Question"]
ans = examples["Ground-True Answer"]
outputs = {"text": []}
for q, a in zip(qs, ans):
rendered = render_pair_harmony(q, a)
outputs["text"].append(rendered)
return outputs
dataset = load_dataset(
"FreedomIntelligence/medical-o1-verifiable-problem",
split="train[0:1000]"
)
dataset = dataset.map(prompt_style_harmony, batched=True)
print(dataset.column_names)
print(dataset[0]["text"])L'ensemble de données contient désormais une nouvelle colonne « texte », qui contient la conversation au format Harmony. Cela comprend :
['Open-ended Verifiable Question', 'Ground-True Answer', 'text']
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>An 88-year-old woman with osteoarthritis is experiencing mild epigastric discomfort and has vomited material resembling coffee grounds multiple times. Considering her use of naproxen, what is the most likely cause of her gastrointestinal blood loss?<|end|><|start|>assistant<|message|>Gastric ulcer<|end|>Avant de former le modèle, il est essentiel d'évaluer ses performances de base afin de pouvoir les comparer après le réglage fin. Pour ce faire, nous définissons une fonction d'aide render_inference_harmony qui prépare une invite de type Harmony contenant les instructions précises du développeur et la question de l'utilisateur, mais laisse la réponse de l'assistant vide afin que le modèle puisse la compléter.
def render_inference_harmony(question):
convo = Conversation.from_messages([
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions(
"You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. "
"Respond with ONLY the final diagnosis/cause in ≤5 words."
)
),
Message.from_role_and_content(Role.USER, question.strip()),
])
tokens = enc.render_conversation_for_completion(convo, Role.ASSISTANT)
text = enc.decode(tokens)
return textEnsuite, nous prenons le premier échantillon de l'ensemble de données, le formatons à l'aide de cette fonction, le tokenisons et le transmettons au modèle afin de générer une réponse :
question = dataset[0]["Open-ended Verifiable Question"]
text = render_inference_harmony(question)
inputs = tokenizer(
[text + tokenizer.eos_token], return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=20,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])Dans ce test, la réponse du modèle est nettement plus longue et plus descriptive que ce qui était demandé, alors que les instructions du développeur demandaient explicitement un diagnostic concis (≤ 5 mots).
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>An 88-year-old woman with osteoarthritis is experiencing mild epigastric discomfort and has vomited material resembling coffee grounds multiple times. Considering her use of naproxen, what is the most likely cause of her gastrointestinal blood loss?<|end|><|start|>assistant<|return|>We have an old woman with NSAID use causing ulcer bleed. The question: "An 88Au lieu de simplement répondre « Ulcère gastrique » (l'étiquette de référence), le modèle a fourni une explication détaillée sur l'utilisation des AINS et les saignements ulcéreux.
dataset[0]["Ground-True Answer"]'Gastric ulcer'Afin d'ajuster efficacement le modèle, nous utilisons LoRA (Low-Rank Adaptation), qui nous permet de ne former qu'un petit sous-ensemble de paramètres tout en conservant le modèle de base figé. Cela réduit considérablement l'utilisation de la mémoire et les coûts de formation.
Nous commençons par définir un adaptateur LoRA ( LoraConfig ) qui spécifie le rang, le facteur d'échelle et les couches cibles spécifiques où les adaptateurs LoRA seront insérés.
from peft import LoraConfig, get_peft_model
peft_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules="all-linear",
target_parameters=[
"7.mlp.experts.gate_up_proj",
"7.mlp.experts.down_proj",
"15.mlp.experts.gate_up_proj",
"15.mlp.experts.down_proj",
"23.mlp.experts.gate_up_proj",
"23.mlp.experts.down_proj",
],
)
peft_model = get_peft_model(model, peft_config)
peft_model.print_trainable_parameters()Seuls environ 15 millions de paramètres (≈0,07 % du modèle complet) sont entraînables, et la taille de l'adaptateur est d'environ 16 Mo, ce qui représente un gain d'efficacité considérable par rapport à un réglage fin complet.
trainable params: 15,040,512 || all params: 20,929,797,696 || trainable%: 0.0719Ensuite, nous configurons le paramétrage de l'entraînement à l'aide de la fonction ` SFTConfig ` de la bibliothèque ` trl `. Cela inclut les hyperparamètres tels que le taux d'apprentissage, la taille des lots, l'accumulation des gradients, le ratio de préchauffage et le type de planificateur :
from trl import SFTConfig
training_args = SFTConfig(
learning_rate=2e-4,
gradient_checkpointing=True,
num_train_epochs=1,
logging_steps=10,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_length=2048,
warmup_ratio=0.03,
lr_scheduler_type="cosine_with_min_lr",
lr_scheduler_kwargs={"min_lr_rate": 0.1},
output_dir="gpt-oss-20b-medical-qa",
report_to="trackio",
push_to_hub=True,
)Une fois l'ensemble de données préparé, l'adaptateur LoRA connecté et les arguments d'entraînement configurés, nous pouvons maintenant lancer le processus de réglage fin. Nous utilisons l'SFTTrainer de la bibliothèque trl, qui simplifie le réglage fin supervisé en gérant le modèle, le tokenizer, l'ensemble de données et la boucle d'entraînement en un seul endroit :
from trl import SFTTrainer
trainer = SFTTrainer(
model=peft_model,
args=training_args,
train_dataset=dataset,
processing_class=tokenizer,
)
trainer.train()Au cours de l'entraînement, la perte diminue progressivement, ce qui indique que le modèle apprend à aligner ses réponses sur l'ensemble de données de questions-réponses médicales au format Harmony.
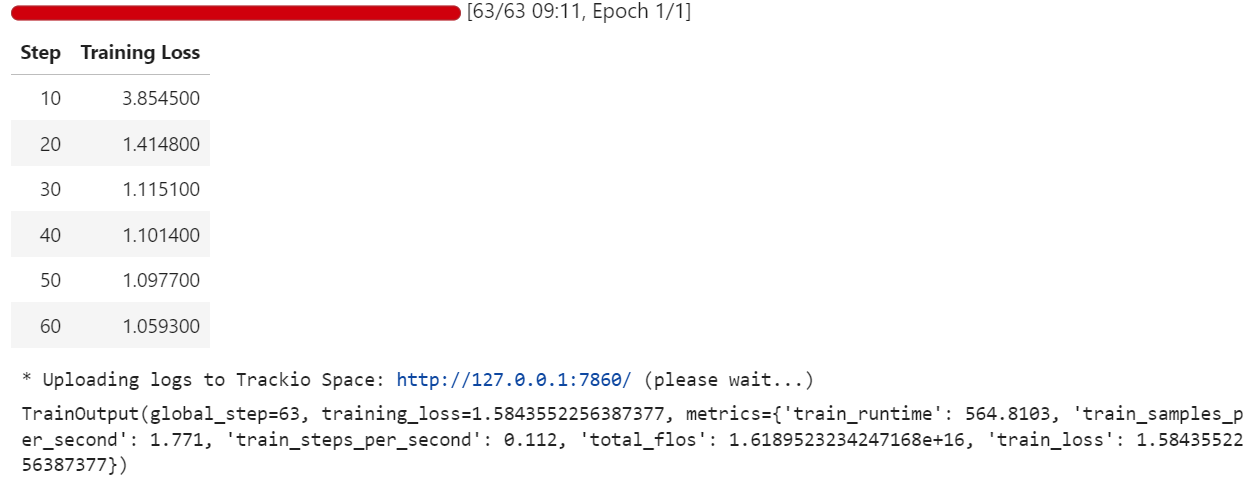
Une fois la formation terminée, nous enregistrons le modèle optimisé localement, puis nous le transférons vers le Hugging Face Hub. Il est important de noter que seuls les poids de l'adaptateur LoRA (et non le modèle 20B complet) sont téléchargés, ce qui rend le référentiel léger et facile à partager :
trainer.save_model(training_args.output_dir)
trainer.push_to_hub(dataset_name="kingabzpro/gpt-oss-20b-medical-qa")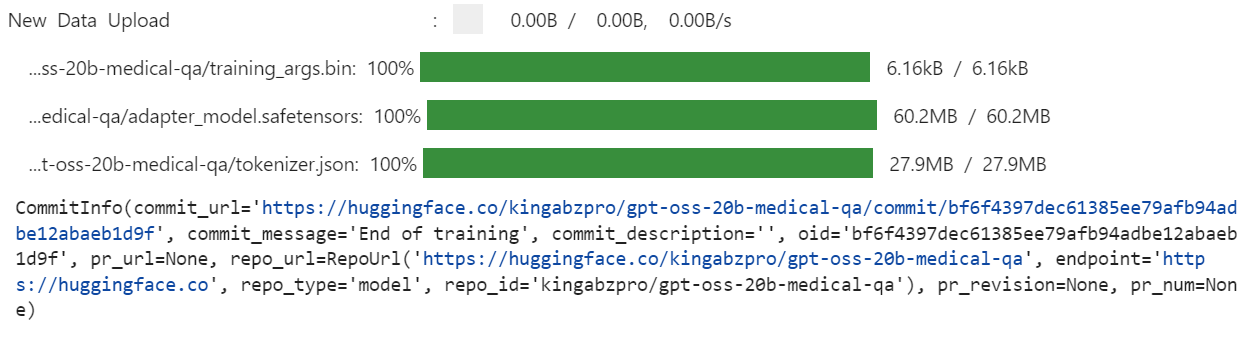
Cela crée un nouveau référentiel de modèles sur Hugging Face sous : kingabzpro/gpt-oss-20b-medical-qa.
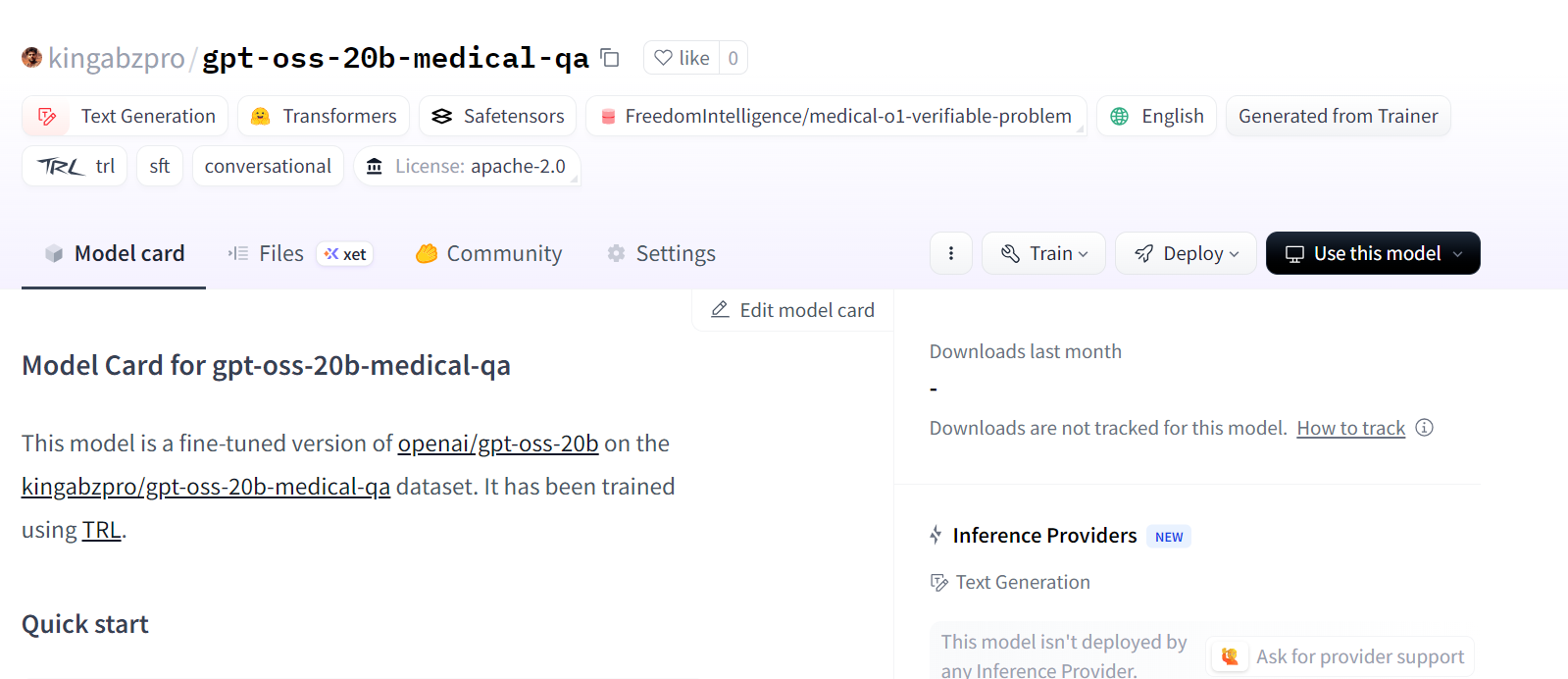
Source : kingabzpro/gpt-oss-20b-medical-qa
Après avoir procédé à des ajustements, nous pouvons tester le modèle afin de vérifier s'il respecte désormais plus fidèlement les instructions du développeur. Pour ce faire, nous chargeons d'abord le modèle de base GPT-OSS 20B, puis nous y ajoutons les adaptateurs LoRA optimisés.
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")
# Load the original model first
model_kwargs = dict(attn_implementation="eager", torch_dtype="auto", use_cache=True, device_map="auto")
base_model = AutoModelForCausalLM.from_pretrained("openai/gpt-oss-20b", **model_kwargs).cuda()
# Merge fine-tuned weights with the base model
peft_model_id = "gpt-oss-20b-medical-qa"
model = PeftModel.from_pretrained(base_model, peft_model_id)
model = model.merge_and_unload()Ensuite, nous effectuons une inférence sur un échantillon tiré de l'ensemble de données. La question est formatée selon le style Harmony, tokenisée, transmise au modèle, puis décodée à nouveau en texte :
question = dataset[0]["Open-ended Verifiable Question"]
text = render_inference_harmony(question)
inputs = tokenizer(
[text + tokenizer.eos_token], return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=20,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])Le modèle optimisé fournit désormais une réponse concise et précise. Cette étiquette est beaucoup plus proche de l'étiquette de référence (« Ulcère gastrique ») et respecte la contrainte de ≤ 5 mots.
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>An 88-year-old woman with osteoarthritis is experiencing mild epigastric discomfort and has vomited material resembling coffee grounds multiple times. Considering her use of naproxen, what is the most likely cause of her gastrointestinal blood loss?<|end|><|start|>assistant<|return|><|message|>Stomach ulcer<|end|><|return|>Nous pouvons également tester un autre échantillon afin de confirmer la cohérence :
question = dataset[10]["Open-ended Verifiable Question"]
text = render_inference_harmony(question)
inputs = tokenizer(
[text + tokenizer.eos_token], return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=20,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])Parfait. Le modèle optimisé a généré des réponses concises, précises et conformes aux instructions.
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>What substance is primarily filtered in the renal tubules with minimal secretion or re-absorption?<|end|><|start|>assistant<|return|><|message|>creatinine<|end|><|return|>C'est une période passionnante pour la communauté open source spécialisée dans l'intelligence artificielle. Même si les nouveaux modèles GPT-OSS ne sont pas encore en tête des classements, ils sont très prometteurs, en particulier dans leurs classes de paramètres respectives, où les modèles plus petits peuvent encore fournir des résultats impressionnants.
Dans ce tutoriel, nous avons optimisé le modèle GPT-OSS 20B pour répondre à des questions médicales à l'aide d'adaptateurs LoRA et du style d'invite Harmony. Les résultats sont encourageants : le modèle affiné fournit des réponses concises et précises, en accord avec les tâches de raisonnement clinique. Grâce à davantage d'époches d'entraînement, à des ensembles de données plus volumineux et à des invites système perfectionnées, les performances peuvent être encore améliorées.
Si vous recherchez un cours pratique pour vous familiariser avec le réglage fin, veuillez consulter Réglage fin avec Llama 3.
Meilleurs cours OpenAI
Cursus
Cours
Cours