
Lernpfad
OpenAI Grundlagen
15 Std.
Die GPT-OSS 20B ist ein offenes Sprachmodell aus der gpt-oss-Serie von OpenAI, das für niedrige Latenzzeiten und spezielle Anwendungsfälle entwickelt wurde . Es hat 21 Milliarden Parameter (3,6 Milliarden aktiv) und ist so optimiert, dass es auf handelsüblicher Hardware gut läuft. Dankder MXFP4-Quantisierung von„ “ braucht es nur etwa 16 GB Speicher.
Obwohl es kleiner ist als das GPT-OSS 120B, unterstützt es trotzdem coole Funktionen wie konfigurierbare Argumentationsstufen (niedrig, mittel, hoch), vollständigen Zugriff auf die Gedankenkette für Debugging und Transparenz sowie Agentenfunktionen wie Funktionsaufrufe, Webbrowsing und Codeausführung.
In dieser Anleitung zeige ich dir, wie du GPT-OSS 20B einrichtest und optimierst. Das umfasst:
Denk dran, dass dieses Tutorial nur für Forschung und Ausbildung gedacht ist und nicht für die Diagnose oder Behandlung von Patienten.

Bild vom Autor
Obwohl das GPT-OSS-Modell 21 Milliarden Parameter hat, braucht es trotzdem viel GPU-Speicher, mindestens 80 GB VRAM, um das Modell gut laufen zu lassen. Ein schneller Weg, um loslegen ist, eine RunPod H100-Instanz oder eine ähnliche GPU-Umgebung mit viel Speicher zu starten.

Sobald die Umgebung fertig ist, installiere alle Python-Pakete, die du für die Datenverarbeitung, die Feinabstimmung des Modells und die Nachverfolgung von Experimenten brauchst:
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U trackio
%pip install -U openai-harmony
%pip install -U tiktoken
%pip install -U pyctcdecodeZum Schluss logg dich mit deinem API-Schlüssel beim Hugging Face Hub ein. Damit kannst du das fein abgestimmte Modell und den Tokenizer direkt in deinem Hugging Face-Konto speichern und teilen:
from huggingface_hub import notebook_login
notebook_login()Als Nächstes laden wir das GPT-OSS 20B mit MXFP4-Quantisierung, dequantisieren die Gewichte aber sofort beim Laden auf bfloat16, wobei wir Eager Attention, deaktivierten Cache und automatische Geräteplatzierung nutzen.
import torch
from transformers import AutoModelForCausalLM, Mxfp4Config
quantization_config = Mxfp4Config(dequantize=True)
model_kwargs = dict(
attn_implementation="eager",
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
use_cache=False,
device_map="auto",
)
model = AutoModelForCausalLM.from_pretrained("openai/gpt-oss-20b", **model_kwargs)Neben dem Modell brauchen wir auch den Tokenizer aus demselben Repository. Der Tokenizer macht es möglich, Text in Tokens (IDs) umzuwandeln, die das Modell verarbeiten kann, und dann die Ergebnisse des Modells wieder in lesbaren Text zurückzuverwandeln.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")OpenAI Harmony ist ein spezielles Antwortformat, das von den GPT-OSS-Modellen verwendet wird, um Gespräche, Schlussfolgerungen und Funktionsaufrufe auf einheitliche Weise zu strukturieren.
Es legt fest, wie Nachrichten zwischen Rollen (System, Entwickler, Benutzer, Assistent) organisiert werden, und ermöglicht es dem Modell, über mehrere Kanäle auszugeben – zum Beispiel durch die Trennung von Gedankengängen, Einleitungen zum Aufruf von Tools und endgültigen Antworten für den Benutzer.
In diesem Abschnitt erstellen wir eine Funktion, die eine Frage und eine Antwort nimmt und sie zu einer Konversationsaufforderung im Harmony-Stil formatiert. Es nutzt die Bibliothek „ openai_harmony “, um die Unterhaltung strukturiert zu verschlüsseln.
from openai_harmony import (
load_harmony_encoding, HarmonyEncodingName,
Conversation, Message, Role,
SystemContent, DeveloperContent, ReasoningEffort
)
enc = load_harmony_encoding(HarmonyEncodingName.HARMONY_GPT_OSS)
def render_pair_harmony(question, answer):
convo = Conversation.from_messages([
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions(
"You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. "
"Respond with ONLY the final diagnosis/cause in ≤5 words."
)
),
Message.from_role_and_content(Role.USER, question.strip()),
Message.from_role_and_content(Role.ASSISTANT, answer.strip()),
])
tokens = enc.render_conversation(convo)
text = enc.decode(tokens)
return textJetzt laden wir den medizinischen Q&A-Datensatz (FreedomIntelligence/medical-o1-verifiable-problem ) und wenden die Funktion prompt_style_harmony auf jedes Beispiel an. Der umgewandelte Text wird in einer neuen Spalte namens „text“ gespeichert, was ein übersichtliches, anweisungsorientiertes Format ergibt, das zum Eingabestil des Entwicklers passt.
from datasets import load_dataset
def prompt_style_harmony(examples):
qs = examples["Open-ended Verifiable Question"]
ans = examples["Ground-True Answer"]
outputs = {"text": []}
for q, a in zip(qs, ans):
rendered = render_pair_harmony(q, a)
outputs["text"].append(rendered)
return outputs
dataset = load_dataset(
"FreedomIntelligence/medical-o1-verifiable-problem",
split="train[0:1000]"
)
dataset = dataset.map(prompt_style_harmony, batched=True)
print(dataset.column_names)
print(dataset[0]["text"])Der Datensatz hat jetzt eine neue Spalte „Text“, die die Konversation im Harmony-Format enthält. Das umfasst:
['Open-ended Verifiable Question', 'Ground-True Answer', 'text']
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>An 88-year-old woman with osteoarthritis is experiencing mild epigastric discomfort and has vomited material resembling coffee grounds multiple times. Considering her use of naproxen, what is the most likely cause of her gastrointestinal blood loss?<|end|><|start|>assistant<|message|>Gastric ulcer<|end|>Bevor du das Modell trainierst, solltest du unbedingt seine Basisleistung checken, damit du sie nach der Feinabstimmung vergleichen kannst. Dafür machen wir eine Hilfsfunktion namens „ render_inference_harmony “, die eine Aufforderung im Harmony-Stil vorbereitet, die die genauen Anweisungen des Entwicklers und die Frage des Benutzers enthält, aber die Antwort des Assistenten leer lässt, damit das Modell sie vervollständigen kann.
def render_inference_harmony(question):
convo = Conversation.from_messages([
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions(
"You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. "
"Respond with ONLY the final diagnosis/cause in ≤5 words."
)
),
Message.from_role_and_content(Role.USER, question.strip()),
])
tokens = enc.render_conversation_for_completion(convo, Role.ASSISTANT)
text = enc.decode(tokens)
return textAls Nächstes holen wir uns die erste Probe aus dem Datensatz, formatieren sie mit dieser Funktion, zerlegen sie in Token und schicken sie durch das Modell, um eine Antwort zu bekommen:
question = dataset[0]["Open-ended Verifiable Question"]
text = render_inference_harmony(question)
inputs = tokenizer(
[text + tokenizer.eos_token], return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=20,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])In diesem Test ist die Antwort vom Modell deutlich länger und ausführlicher als gewünscht, obwohl in den Entwickleranweisungen ausdrücklich um eine kurze Diagnose (≤5 Wörter) gebeten wurde.
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>An 88-year-old woman with osteoarthritis is experiencing mild epigastric discomfort and has vomited material resembling coffee grounds multiple times. Considering her use of naproxen, what is the most likely cause of her gastrointestinal blood loss?<|end|><|start|>assistant<|return|>We have an old woman with NSAID use causing ulcer bleed. The question: "An 88Anstatt einfach „Magengeschwür“ (die richtige Antwort) zu sagen, hat das Modell eine ausführliche Erklärung über die Einnahme von NSAIDs und Magengeschwürblutungen gegeben.
dataset[0]["Ground-True Answer"]'Gastric ulcer'Um das Modell effizient zu optimieren, nutzen wir LoRA (Low-Rank Adaptation), mit dem wir nur einen kleinen Teil der Parameter trainieren können, während das Basismodell unverändert bleibt. Das spart echt viel Speicherplatz und macht das Training billiger.
Zuerst definieren wir einen „ LoraConfig “, der den Rang, den Skalierungsfaktor und die spezifischen Zielschichten angibt, wo LoRA-Adapter eingefügt werden sollen.
from peft import LoraConfig, get_peft_model
peft_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules="all-linear",
target_parameters=[
"7.mlp.experts.gate_up_proj",
"7.mlp.experts.down_proj",
"15.mlp.experts.gate_up_proj",
"15.mlp.experts.down_proj",
"23.mlp.experts.gate_up_proj",
"23.mlp.experts.down_proj",
],
)
peft_model = get_peft_model(model, peft_config)
peft_model.print_trainable_parameters()Es gibt nur etwa 15 Millionen Parameter (≈0,07 % des gesamten Modells), die trainierbar sind, und die Größe des Adapters liegt bei etwa 16 MB, was im Vergleich zur vollständigen Feinabstimmung einen enormen Effizienzgewinn bedeutet.
trainable params: 15,040,512 || all params: 20,929,797,696 || trainable%: 0.0719Als Nächstes richten wir das Training mit „ SFTConfig “ aus der Bibliothek „ trl “ ein. Dazu gehören Hyperparameter wie Lernrate, Batchgröße, Gradientenakkumulation, Warmup-Verhältnis und Scheduler-Typ:
from trl import SFTConfig
training_args = SFTConfig(
learning_rate=2e-4,
gradient_checkpointing=True,
num_train_epochs=1,
logging_steps=10,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
max_length=2048,
warmup_ratio=0.03,
lr_scheduler_type="cosine_with_min_lr",
lr_scheduler_kwargs={"min_lr_rate": 0.1},
output_dir="gpt-oss-20b-medical-qa",
report_to="trackio",
push_to_hub=True,
)Nachdem wir den Datensatz vorbereitet, den LoRA-Adapter angeschlossen und die Trainingsargumente konfiguriert haben, können wir jetzt mit dem Feinabstimmungsprozess loslegen. Wir nutzen das „ SFTTrainer ” aus der Bibliothek „ trl ”, das das überwachte Fine-Tuning vereinfacht, indem es das Modell, den Tokenizer, den Datensatz und die Trainingsschleife an einem Ort verwaltet:
from trl import SFTTrainer
trainer = SFTTrainer(
model=peft_model,
args=training_args,
train_dataset=dataset,
processing_class=tokenizer,
)
trainer.train()Während des Trainings wird der Verlust immer kleiner, was zeigt, dass das Modell lernt, seine Antworten an den medizinischen Q&A-Datensatz im Harmony-Format anzupassen.
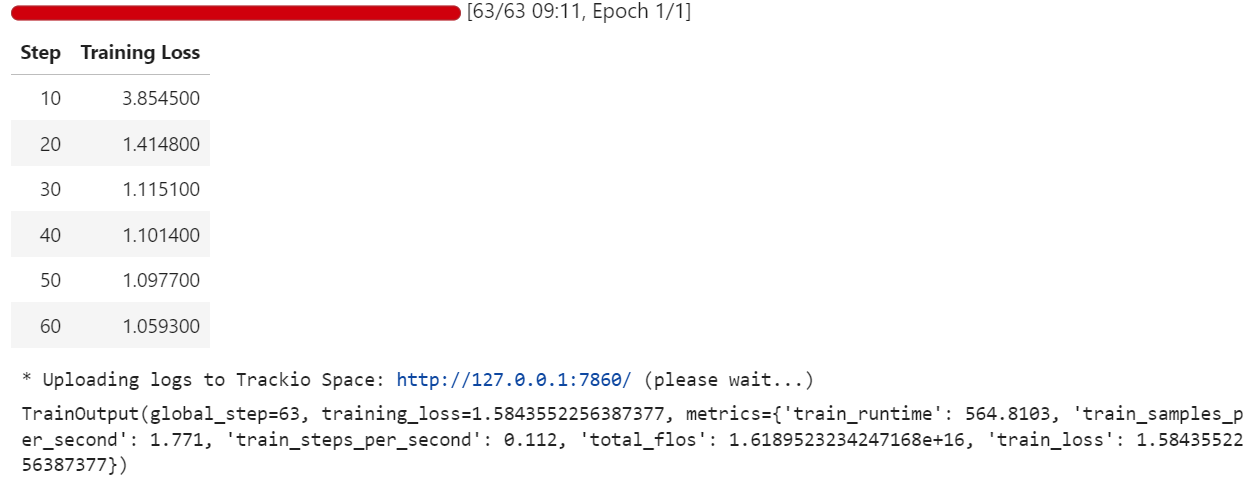
Sobald das Training abgeschlossen ist, speichern wir das fein abgestimmte Modell lokal und übertragen es dann an den Hugging Face Hubübertragen. Wichtig ist, dass nur die Gewichte des LoRA-Adapters (nicht das komplette 20B-Modell) hochgeladen werden, was das Repository leicht und einfach zu teilen macht:
trainer.save_model(training_args.output_dir)
trainer.push_to_hub(dataset_name="kingabzpro/gpt-oss-20b-medical-qa")
Damit erstellst du ein neues Modell-Repository auf Hugging Face unter: kingabzpro/gpt-oss-20b-medical-qa.
Quelle: kingabzpro/gpt-oss-20b-medical-qa
Nach der Feinabstimmung können wir das Modell testen, um zu sehen, ob es jetzt besser den Vorgaben des Entwicklers entspricht. Dafür laden wir erst mal das Basis-Modell GPT-OSS 20B und hängen dann die fein abgestimmten LoRA-Adapter dran.
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained("openai/gpt-oss-20b")
# Load the original model first
model_kwargs = dict(attn_implementation="eager", torch_dtype="auto", use_cache=True, device_map="auto")
base_model = AutoModelForCausalLM.from_pretrained("openai/gpt-oss-20b", **model_kwargs).cuda()
# Merge fine-tuned weights with the base model
peft_model_id = "gpt-oss-20b-medical-qa"
model = PeftModel.from_pretrained(base_model, peft_model_id)
model = model.merge_and_unload()Als Nächstes machen wir eine Inferenz für eine Stichprobe aus dem Datensatz. Die Frage wird im Harmony-Stil formatiert, in Token zerlegt, durch das Modell geschickt und wieder in Text zurückverwandelt:
question = dataset[0]["Open-ended Verifiable Question"]
text = render_inference_harmony(question)
inputs = tokenizer(
[text + tokenizer.eos_token], return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=20,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])Das optimierte Modell liefert jetzt eine kurze und genaue Antwort. Das ist viel näher am richtigen Label („Magengeschwür“) und hält sich an die Regel von ≤5 Wörtern.
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>An 88-year-old woman with osteoarthritis is experiencing mild epigastric discomfort and has vomited material resembling coffee grounds multiple times. Considering her use of naproxen, what is the most likely cause of her gastrointestinal blood loss?<|end|><|start|>assistant<|return|><|message|>Stomach ulcer<|end|><|return|>Wir können auch noch eine Probe testen, um die Konsistenz zu checken:
question = dataset[10]["Open-ended Verifiable Question"]
text = render_inference_harmony(question)
inputs = tokenizer(
[text + tokenizer.eos_token], return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=20,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])Super. Das fein abgestimmte Modell hat präzise, genaue und anweisungsgetreue Antworten erzeugt.
<|start|>developer<|message|># Instructions
You are a medical expert with advanced knowledge in clinical reasoning and diagnostics. Respond with ONLY the final diagnosis/cause in ≤5 words.<|end|><|start|>user<|message|>What substance is primarily filtered in the renal tubules with minimal secretion or re-absorption?<|end|><|start|>assistant<|return|><|message|>creatinine<|end|><|return|>Es sind spannende Zeiten für die Open-Source-KI-Community. Auch wenn die neuen GPT-OSS-Modelle vielleicht noch nicht die Benchmarks anführen, sind sie echt vielversprechend, vor allem in ihren jeweiligen Parameterklassen, wo kleinere Modelle trotzdem beeindruckende Ergebnisse liefern können.
In diesem Tutorial haben wir das GPT-OSS 20B-Modell für medizinische Fragen mit LoRA-Adaptern und dem Harmony-Prompt-Stil optimiert. Die Ergebnisse sind echt vielversprechend: Das optimierte Modell liefert präzise und genaue Antworten, die auf klinische Denkaufgaben abgestimmt sind. Mit mehr Trainingsphasen, größeren Datensätzen und verbesserten Systemaufforderungen kann die Leistung noch weiter gesteigert werden.
Wenn du nach einem praktischen Kurs suchst, um dich mit der Feinabstimmung vertraut zu machen, solltest du dir unbedingt Fine-Tuning mit Llama 3.
Die besten OpenAI-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Matt Crabtree