
programa
Fundamentos de la IA
10 h
OpenAI ha lanzado recientemente modelos de peso abierto diseñados para un razonamiento potente, tareas agenticas y casos de uso versátiles para programadores. Estos modelos vienen en dos variantes: gpt-oss-120b y gpt-oss-20b. El modelo más pequeño se puede ejecutar localmente en GPU de consumo, mientras que para ejecutar gpt-oss-120b se necesitan 80 GB de VRAM y una configuración informática más robusta, que muchos usuarios pueden no tener.
Para ayudar, he recopilado una lista de formas fáciles y gratuitas de acceder al modelo más completo. Puedes ejecutar el modelo localmente utilizando Ollama, Transformers o el marco vLLM. También hay aplicaciones de chat gratuitas donde puedes probar el modelo, así como numerosos proveedores de inferencia de modelos de lenguaje grande (LLM) rápidos y gratuitos que puedes probar. Además, puedes visitar el mercado de LLM para encontrar las mejores opciones que se adapten a tu caso de uso. Consulta nuestra guía independiente sobre cómo configurar y ejecutar GPT-OSS localmente con Ollama.
OpenAI GPT-OSS es una serie de modelos de peso abierto que permite a los usuarios descargarlos y ejecutarlos en cualquier sistema. También puedes utilizarlo localmente para compilar aplicaciones y crear proyectos. Este modelo está disponible tanto para uso comercial como para uso de código abierto.
En esta parte, aprenderemos a ejecutar el gran modelo GPT-OSS-120B en hardware de consumo.
Con Ollama, no necesitas necesariamente una GPU; puedes ejecutar el modelo íntegramente en tu CPU y RAM. Sin embargo, la generación de tokens será significativamente más lenta sin la aceleración de la GPU.
Si tienes una configuración con varias GPU, puedes descargar algunas capas del modelo a la GPU, lo que mejorará considerablemente la velocidad de generación. Para configurarlo correctamente, se necesitan algunos conocimientos técnicos y realizar algunos ajustes.
Fuente: gpt-oss
Para empezar, instala Ollama en Linux.
curl -fsSL https://ollama.com/install.sh | sh A continuación, ejecuta el siguiente comando para descargar y ejecutar el gpt-oss-120b .
ollama run gpt-oss:120bAsí de sencillo.
Con la biblioteca Transformers, puedes descargar y cargar el modelo, ejecutar la inferencia, ajustar el modelo e integrarlo directamente en tu aplicación.
Para modelos con 120 000 millones de parámetros, tendrás que implementar la fragmentación del modelo en varias GPU. Además, es posible que tengas que utilizar una cuantificación de 8 bits o 4 bits para que el modelo quepa en la memoria.
Si tu VRAM sigue siendo insuficiente, puedes descargar algunas capas a la CPU. Este proceso requiere más experiencia y conocimientos técnicos, pero si estás familiarizado con los pasos necesarios, se puede llevar a cabo sin problemas.
Fuente: openai/gpt-oss-120b
Instala los paquetes necesarios:
pip install -U transformers kernels torchAquí tienes un ejemplo de uso: Crea el canal de generación de texto, proporciónale un mensaje y, a continuación, ejecuta el canal para generar una respuesta.
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-120b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "What is the best DataCamp course to learn AI?"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])vLLM es un motor de inferencia de alto rendimiento diseñado específicamente para la generación rápida y de alto rendimiento de texto, lo que lo hace perfecto para implementaciones a nivel de producción.
Se puede implementar de varias maneras: en tu servidor local para desarrollo y pruebas, en una nube privada para uso interno de la empresa, o en pequeñas empresas y startups que buscan un mayor control y privacidad de los datos sin depender de API externas.
Fuente: GPT OSS - Recetas vLLM
Utiliza uv pip para instalar más rápidamente los paquetes de Python.
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-matchEjecuta el siguiente comando en tu terminal para descargar el modelo e iniciar el servidor vLLM:
vllm serve openai/gpt-oss-120bUna vez en ejecución, vLLM iniciará un servidor API local (por defecto: http://localhost:8000) al que podrás enviar consultas mediante solicitudes HTTP e integrarlo directamente en tus aplicaciones.
Las aplicaciones de chat con IA te permiten probar diferentes modelos sin necesidad de configuración. Todo lo que tienes que hacer es visitar la URL y registrarte. Puedes disfrutar de las funciones que ofrecen estas aplicaciones.
En esta sección, exploraremos el chat oficial y la aplicación de chat T3, que proporcionan acceso gratuito a los nuevos modelos OpenAI GPT-OSS.
Gpt-oss es el sitio web oficial donde puedes probar los dos modelos de código abierto de OpenAI. Se ha creado en colaboración con Hugging Face, por lo que tendrás que iniciar sesión con tu cuenta de Hugging Face para desbloquear todas las funciones de los modelos.

Fuente: Gpt-oss
La aplicación es totalmente gratuita y ofrece chats ilimitados. Puedes experimentar con diferentes niveles de razonamiento, cambiar entre modos e incluso pedirle que cree una aplicación web completa desde cero. Es muy rápido y no requiere configuración.
Me encanta T3 Chat desde que lo descubrí. Proporciona un acceso ultrarrápido tanto a modelos de código abierto como a modelos propietarios. Piensa en ello como una aplicación al estilo ChatGPT, pero para todo tipo de modelos de IA, incluyendo generación de imágenes, modelos de lenguaje visual y modelos de lenguaje de gran tamaño.
Actualmente, T3 Chat ofrece acceso gratuito tanto a GPT-OSS 20B como a GPT-OSS 120B. Todo lo que tienes que hacer es registrarte y empezar a disfrutar de acceso completo a estas modelos.

Fuente: t3.chat
¿Lo mejor? Su interfaz de usuario limpia e intuitiva y la forma en que se muestran los resultados generados.
Los proveedores de inferencia alojan grandes modelos de lenguaje en sus propios servidores y proporcionan a los usuarios acceso a través de API o web, lo que les permite integrar estos modelos directamente en sus aplicaciones sin tener que ejecutar un servidor de inferencia en su propia infraestructura. Esto facilita a los programadores el uso de potentes modelos sin preocuparse por la implementación, el escalado o el mantenimiento.
En esta sección, exploraremos algunos proveedores de inferencia súper rápidos y gratuitos que puedes utilizar ahora mismo para acceder a la variante 120B del modelo GPT-OSS.
Cerebras es uno de los proveedores de inferencia LLM más rápidos del mundo, capaz de entregar hasta 1400 tokens por segundo con solicitudes simultáneas. Esto lo convierte en una opción excelente para crear sistemas de IA en tiempo real en los que la velocidad es fundamental.
Sin embargo, hay algunas consideraciones que debes tener en cuenta:
Fuente: cerebras.ai
Cerebras no es compatible con OpenAI SDK, por lo que tendrás que instalar su propio SDK:
pip install --upgrade cerebras_cloud_sdkA continuación, crea el cliente utilizando la clave API, crea la función de finalización del chat y, a continuación, genera la respuesta como un flujo.
import os
from cerebras.cloud.sdk import Cerebras
client = Cerebras(
# This is the default and can be omitted
api_key=os.environ.get("CEREBRAS_API_KEY")
)
stream = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "Who was Leonardo Da Vinci?"
}
],
model="gpt-oss-120b",
stream=True,
max_completion_tokens=65536,
temperature=1,
top_p=1,
reasoning_effort="high"
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")Soy un gran admirador de Groq porque proporcionan puntos finales de inferencia rápidos y asequibles para modelos de código abierto populares. Actualmente, puedes acceder a la variante 120B del GPT-OSS de OpenAI de forma gratuita, aunque con una tasa de solicitud limitada.
Puedes probar el modelo directamente en Groq Studio antes de integrarlo en tus aplicaciones, lo que facilita la experimentación y el ajuste de tus indicaciones.
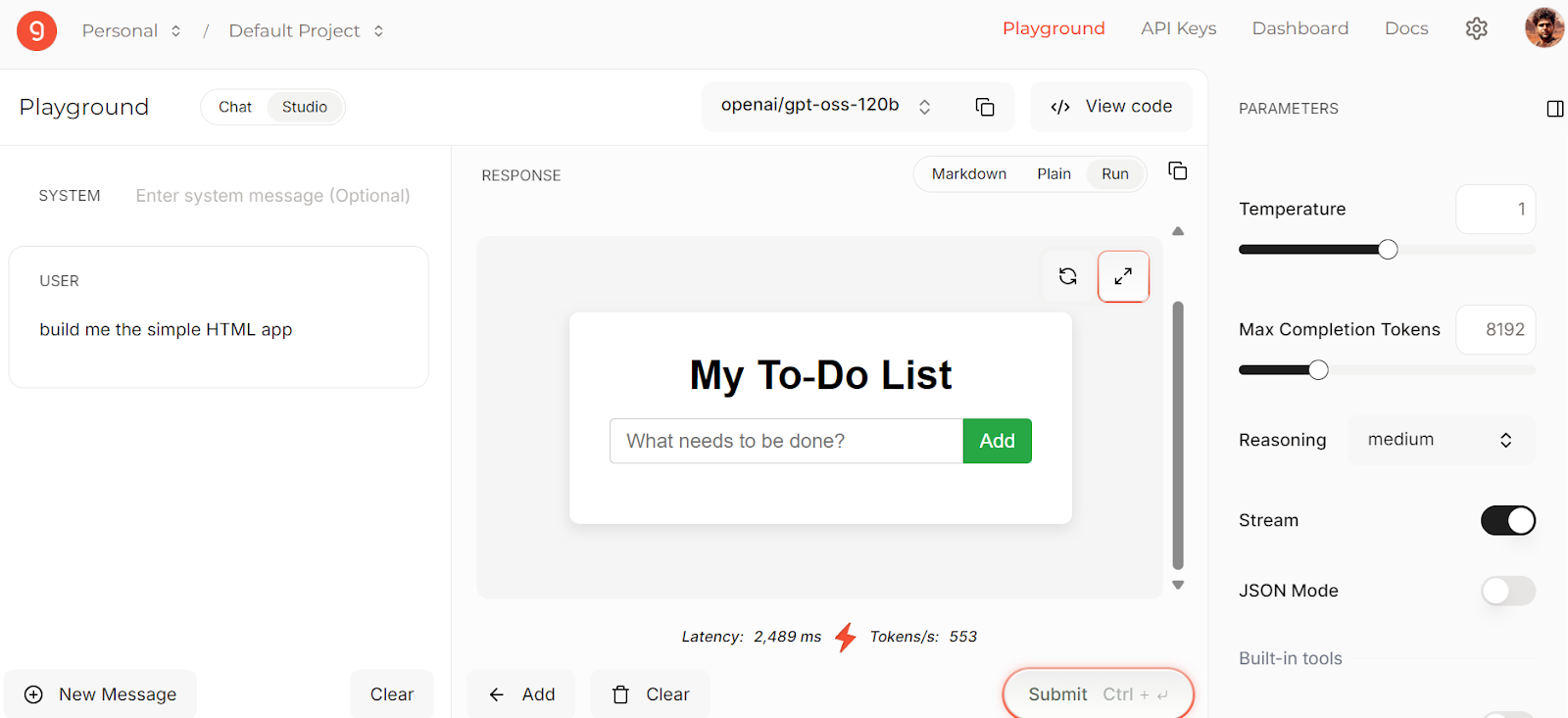
Fuente: Groq
Groq es compatible con OpenAI, lo que significa que puedes utilizar el SDK de Python de OpenAI para acceder a sus modelos. Sin embargo, Groq también ofrece su propio SDK optimizado, que está mejor adaptado a su infraestructura, y es el que utilizaremos aquí.
Instala el SDK de Groq:
pip install groqCrea el cliente Groq con la clave API y, a continuación, crea las completaciones de chat utilizando el nombre del modelo y otros argumentos para transmitir la respuesta.
from groq import Groq
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "user",
"content": "What is the meaning of life?"
}
],
temperature=1,
max_completion_tokens=8192,
top_p=1,
reasoning_effort="medium",
stream=True,
stop=None
)
for chunk in completion:
print(chunk.choices[0].delta.content or "", end="")Baseten es una potente plataforma de inferencia y entrenamiento diseñada para implementar, escalar y gestionar modelos de IA con control total. Lo mejor es que está a la altura de Groq y Cerebras en cuanto a velocidad de generación de tokens.
Al registrarte, recibirás 5 $ de crédito para implementación y 1 $ para acceso a la API. Puedes utilizar este dinero para acceder a los servicios de la plataforma.
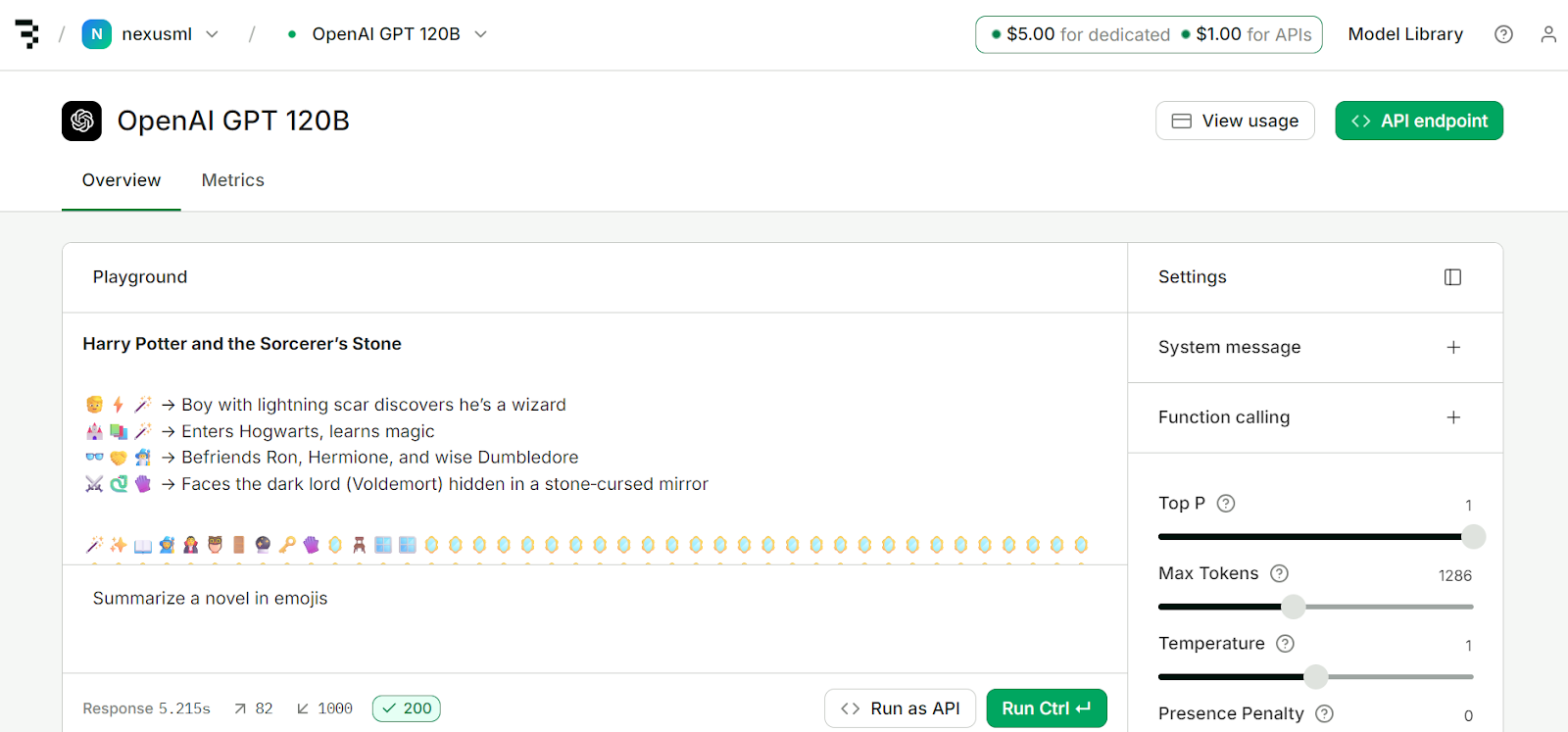
Fuente: API del modelo | Baseten
Baseten es compatible con OpenAI y no tiene su propio SDK, por lo que utilizaremos el SDK de Python de OpenAI para acceder al punto final del modelo. Para ello, debes instalar el paquete Python de OpenAI:
pip install openaiA continuación, crea el cliente utilizando tu clave API y la URL base. A continuación, puedes crear completaciones de chat especificando el nombre del modelo y otros parámetros. Por último, puedes generar respuestas en streaming.
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("BASETEN_API_KEY"),
base_url="https://inference.baseten.co/v1"
)
response = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "user",
"content": "Implement Hello World in Python"
}
],
stop=[],
stream=True,
stream_options={
"include_usage": True,
"continuous_usage_stats": True
},
top_p=1,
max_tokens=1286,
temperature=1,
presence_penalty=0,
frequency_penalty=0
)
for chunk in response:
if chunk.choices and chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
El mercado LLM te permite acceder a modelos de lenguaje de gran tamaño, tanto de código abierto como cerrado, en un solo lugar. Todos los modelos de código abierto están alojados en OpenRouter, lo que te permite utilizar una API unificada sin preocuparte por el coste, la disponibilidad o el rendimiento.
En esta sección, revisaremos dos de los mercados LLM más populares, OpenRouter y Requesty. Ambas plataformas ofrecen acceso gratuito al modelo GPT-OSS 12B.
OpenRouter proporciona una API unificada que te permite acceder a cientos de modelos de IA a través de un único punto final. Gestiona automáticamente las alternativas y selecciona las opciones más rentables para tus solicitudes.
Puedes experimentar con diferentes modelos utilizando su LLM Playground, que te permite probar y comparar los resultados antes de integrarlos en tu flujo de trabajo.
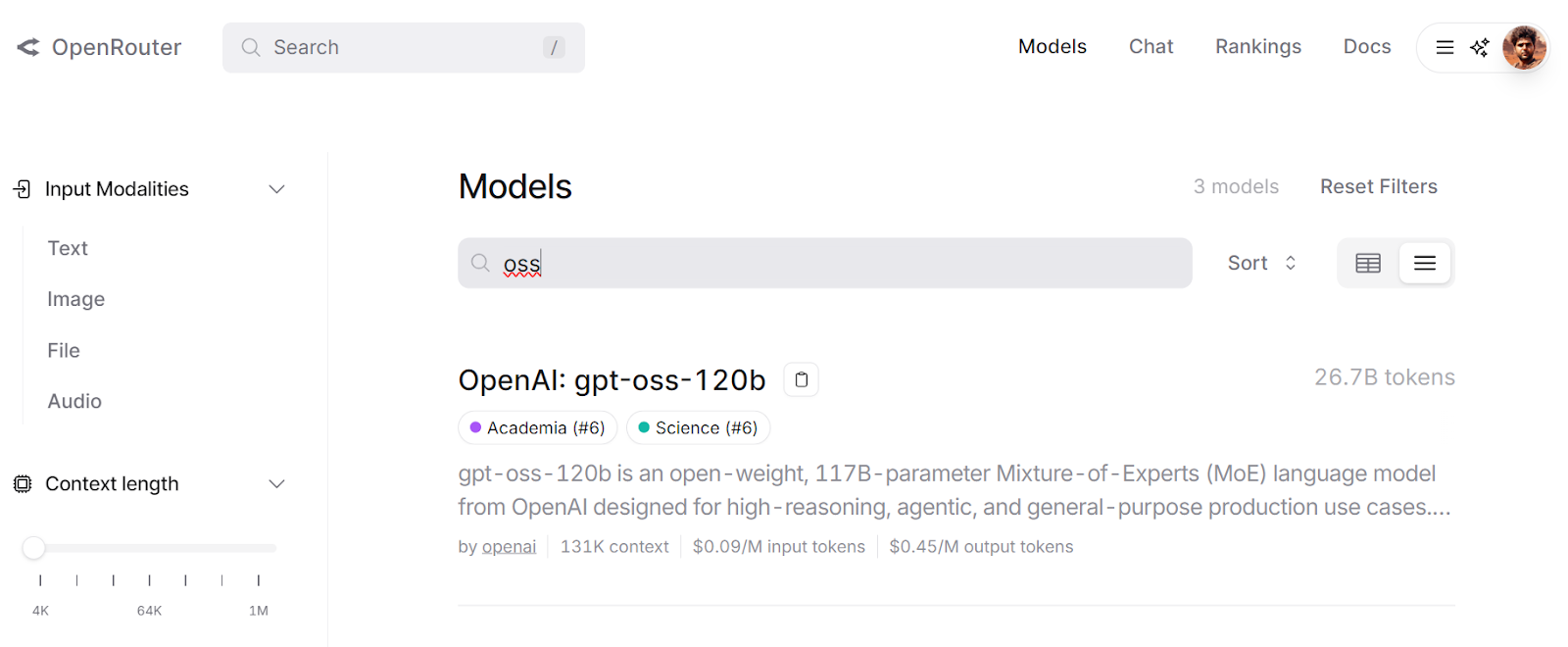
Fuente: gpt-oss-120b
Integrar OpenRouter es muy sencillo; solo tienes que cambiar la URL base y proporcionar tu clave API. El resto de la implementación sigue siendo igual que con la API de OpenAI.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What is the meaning of life?"}],
)
print(completion.choices[0].message.content)Requesty es similar a OpenRouter, pero enruta de forma inteligente tus solicitudes a través de más de 170 modelos de IA, incluido GPT‑OSS 120B. Esto te ayuda a:
Puedes explorar modelos en el menú Chat, consultar la tabla de clasificación, ver tu panel de uso y añadir integraciones directas.
Al registrarte, recibirás 1 $ en créditos gratuitos, lo que te permitirá probar incluso los modelos de pago.

Fuente: Solicitud
Para integrar Requesty, simplemente actualiza la URL base, la clave API y los encabezados predeterminados en tu código SDK de Python de OpenAI.
Si deseas utilizar un modelo gratuito, asegúrate de seleccionar los proporcionados por Groq.
import os
import openai
ROUTER_API_KEY = os.getenv("REQUESTY_API_KEY")
client = openai.OpenAI(
api_key=ROUTER_API_KEY,
base_url="https://router.requesty.ai/v1",
default_headers={"Authorization": f"Bearer {ROUTER_API_KEY}"},
)
# Example request
response = client.chat.completions.create(
model="groq/openai/gpt-oss-120b",
messages=[{"role": "user", "content": "Hello, who are you?"}],
)
# Print the result
print(response.choices[0].message.content)Tras una larga espera, OpenAI ha lanzado finalmente un LLM de código abierto. Esto significa que ahora puedes ajustarlo, ejecutarlo localmente y tener control total sobre la generación de resultados. Tú tienes el control; incluso puedes crear productos basados en él sin compartir tus datos con OpenAI ni pagar por el acceso a la API.
Este es un gran paso adelante para la IA y, con el tiempo, veremos nuevos y mejorados modelos basados en los modelos y marcos de código abierto de OpenAI. Si quieres empezar a experimentar ahora mismo, puedes:
Si acabas de empezar tu andadura en el mundo de la IA, no te pierdas nuestro programa de habilidades Fundamentos de la IA , que cubre temas como los LLM, ChatGPT, la IA generativa, la ética de la IA y la ingeniería de prompts.
Los mejores cursos de IA
programa
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Matt Crabtree
13 min
blog
Abid Ali Awan
9 min
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali



