
Curso
Implantar soluciones de IA en las empresas
2 h
51.7K
Los sistemas RAG tradicionales recuperan fragmentos de documentos basándose en la similitud semántica, lo que funciona bien para preguntas sencillas. Sin embargo, cuando las consultas requieren sintetizar información dispersa en múltiples documentos o razonar a través de conceptos relacionados, la búsqueda vectorial se queda corta. El sistema recupera fragmentos sin comprender cómo se relacionan entre sí.
GraphRAG no trata los documentos como fragmentos aislados. Crea un gráfico de conocimiento que captura entidades y sus relaciones. Esta estructura permite al sistema recorrer conexiones y responder preguntas que requieren reunir información de múltiples fuentes. Es una de las varias técnicas avanzadas de RAG que abordan las limitaciones de la recuperación básica.
Esta guía explica cómo funciona GraphRAG, los diferentes tipos de consultas (globales, locales y DRIFT) y los pasos prácticos para su implementación. Al final, comprenderás cuándo GraphRAG ofrece ventajas reales sobre el RAG tradicional y cómo empezar a utilizarlo.
Antes de profundizar en la mecánica, es útil comprender por qué surgió la recuperación basada en grafos y qué vacío llena.
El problema fundamentaldel RAG tradicional no es la recuperación ni la generación, sino la representación. Los documentos se dividen en fragmentos, y cada fragmento se convierte en un vector aislado que flota en el espacio de incrustación. Cualquier estructura que existiera en el original (los títulos, el flujo narrativo, a qué se refería cada párrafo) se aplana.
Esto crea problemas para las preguntas que requieren combinar información. Pregunta «¿Cuáles son los temas principales de estos documentos?» y la búsqueda vectorial devolverá fragmentos que contengan la palabra «temas» o términos relacionados. Pero encontrar fragmentos relevantes no es lo mismo que comprender los patrones en todo un corpus. El sistema no tiene forma de recopilar información a gran escala porque solo ve piezas individuales, nunca el panorama completo.
El razonamiento multisalto se enfrenta a un obstáculo similar. Supongamos que la respuesta a una pregunta depende de conectar el concepto A con el concepto B y con el concepto C. El RAG tradicional recupera cada fragmento de forma independiente basándose en la similitud con la consulta. Si B no está cerca de la pregunta, es posible que no se recupere en absoluto, rompiendo la cadena. El sistema encuentra los puntos finales, pero no encuentra la ruta entre ellos.
También hay que tener en cuenta una discrepancia entre el contexto de recuperación y el contexto de búsqueda. Puedes recuperar veinte fragmentos muy relevantes, pero meterlos todos en una indicación no garantiza que el LLM los utilice bien. El artículo «Lost in the middle» muestra que los LLM tienden a centrarse en la información al principio y al final de su ventana de contexto, pasando por alto a menudo lo que se encuentra entre medias. Una mayor recuperación nosignifica automáticamente mejores respuestas.
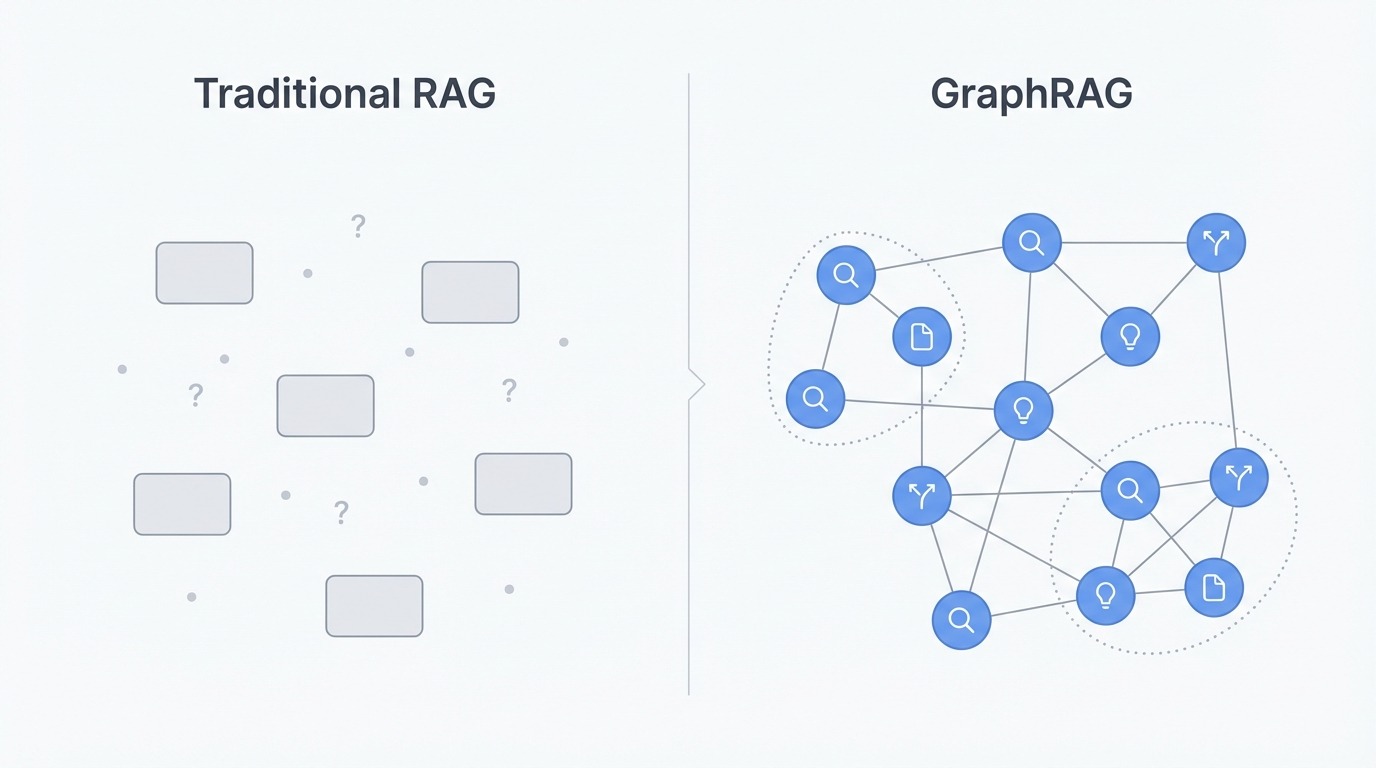
Comparación entre RAG tradicional y GraphRAG. Imagen del autor.
GraphRAG supera estas limitaciones cambiando por completo la representación. En lugar de fragmentos, construye un gráfico de conocimiento en el que las entidades se convierten en nodos y las relaciones se convierten en aristas. Se extraen personas, organizaciones, ubicaciones, conceptos y eventos de los documentos de origen, junto con la forma en que se relacionan entre sí. Esto mantiene la estructura que el fragmentado descarta.
Una vez creado el gráfico, el sistema aplica la detección de comunidades (normalmente el algoritmo de Leiden) para agrupar las entidades relacionadas. Estos grupos se forman en múltiples niveles, algunos estrechos y específicos, otros amplios y temáticos. Las agrupaciones provienen de conexiones reales en los datos, en lugar de límites de documentos o tamaños de fragmentos.
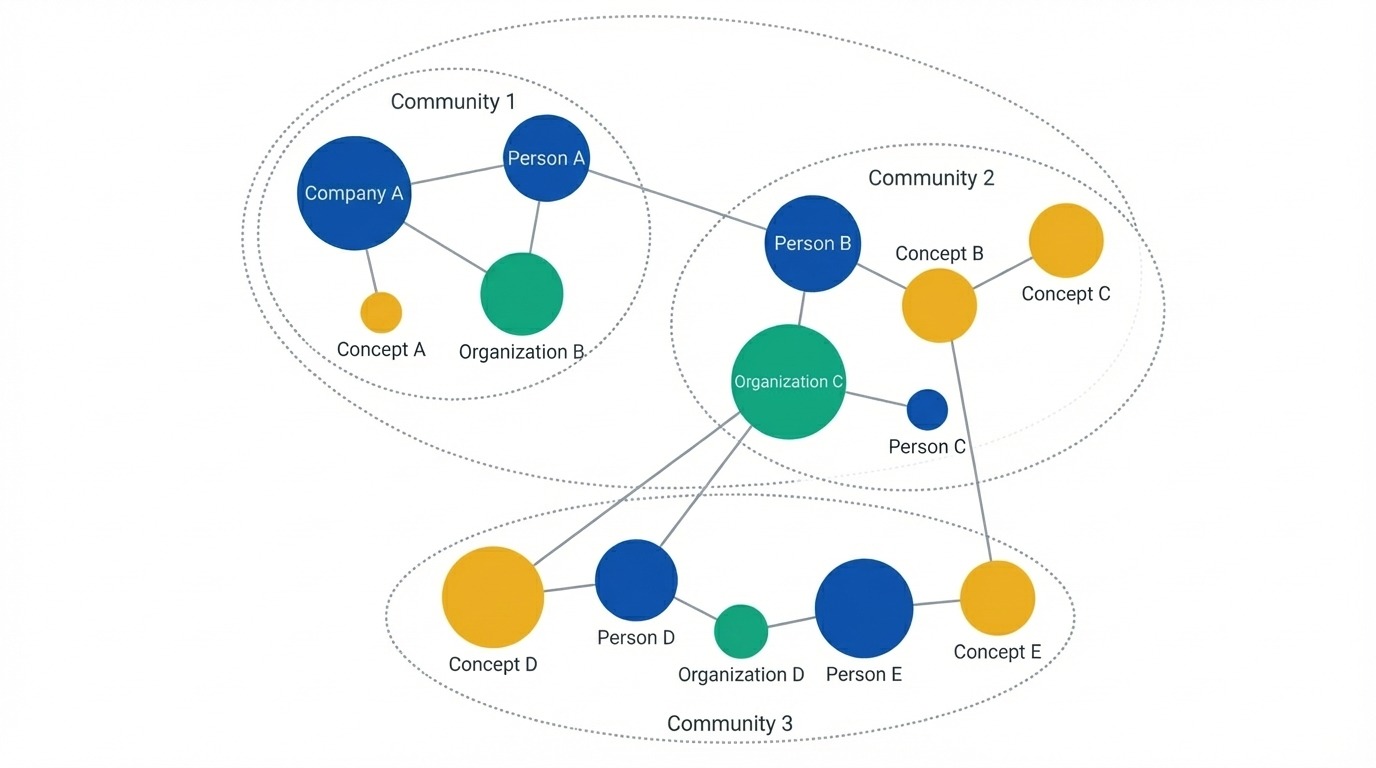
Gráfico de conocimiento que muestra entidades como nodos. Imagen del autor.
Para las preguntas globales, GraphRAG genera previamente resúmenes para cada comunidad antes de que llegue cualquier consulta de los usuarios. Cuando alguien pregunta «¿Cuáles son los temas principales?», el sistema no busca texto coincidente. En su lugar, ejecuta una operación de map-reduce: cada resumen de comunidad produce una respuesta parcial basada en su porción del gráfico, y luego todas las respuestas parciales se combinan en una respuesta final. Esto permite a GraphRAG razonar sobre todo un corpus sin tener que recuperar miles de fragmentos.
Para preguntas de múltiples saltos, el recorrido del gráfico sustituye a la búsqueda por similitud. El sistema puede recorrer los bordes de una entidad a otra, siguiendo cadenas conceptuales que la búsqueda vectorial pasaría por alto. Si A se conecta a B y B se conecta a C, el gráfico sabe que esa ruta existe y puede seguirla.
GraphRAG resulta útil cuando tus preguntas requieren una comprensión global del corpus. Si los usuarios preguntan con frecuencia sobre temas, patrones o resúmenes en grandes colecciones de documentos, la recuperación basada en gráficos superará a los enfoques de fragmentación. Lo mismo ocurre con los dominios con relaciones entre entidades complejas, como los organigramas de empresas, las redes de citas de investigaciones o los historiales de casos legales, en los que es importante seguir las conexiones.
Para búsquedas simples de datos concretos («¿Cuál es el número de teléfono de X?») o conjuntos de documentos pequeños, el RAG tradicional funciona bien y su funcionamiento es más económico. GraphRAG añade una sobrecarga tanto en el tiempo de indexación como en las llamadas LLM, por lo que la recompensa debe justificar la inversión. Comienza con RAG estándar y pasa a GraphRAG cuando alcances sus limitaciones.
La siguiente tabla resume las ventajas y desventajas. Traditional RAG gana en simplicidad y coste, mientras que GraphRAG se impone cuando las preguntas requieren síntesis o razonamiento conectado.
|
Aspecto |
RAG tradicional |
GraphRAG |
|
Representación de datos |
Fragmentos de texto aislados como vectores |
Gráfico de conocimiento con entidades y relaciones |
|
Preservación de la estructura |
Perdido durante la fragmentación |
Mantenido a través de los bordes del gráfico |
|
Consultas globales |
Deficiente (recupera fragmentos, no puede sintetizar) |
Fuerte (map-reduce sobre resúmenes de la comunidad) |
|
Razonamiento multisalto |
Limitado (recuperación independiente de fragmentos) |
Nativo (el recorrido del gráfico sigue las conexiones) |
|
Coste de indexación |
Bajo (solo incrustación) |
Alto (extracción LLM + incrustación + agrupación) |
|
Coste de la consulta |
Bajo |
Varía (lo local es barato, lo global es caro). |
|
Ideal para |
Búsquedas de datos, corpus pequeños |
Preguntas temáticas, ámbitos relacionados |
El proceso tiene dos fases: la indexación crea el gráfico y la consulta lo utiliza.
La indexación transforma los documentos sin procesar en una estructura de conocimiento a través de cinco pasos:
La etapa de extracción es donde se producen la mayoría de las llamadas LLM. Cada fragmento se procesa con una solicitud que pide al modelo que identifique entidades y relaciones. Un fragmento que menciona «OpenAI lanzó GPT-4» genera entidades para ambos, además de una relación que los vincula. El mismo pase captura el tipo de relación. Dado que cada fragmento requiere una llamada LLM, la indexación es la parte más costosa del proceso. El tiempo de consulta es relativamente barato porque el trabajo pesado ya se ha realizado.
La construcción de gráficos se encarga de la resolución de entidades, lo cual puede resultar complicado. «OpenAI», «Open AI» y «la empresa» pueden referirse a la misma entidad en diferentes fragmentos. El sistema fusiona estos duplicados para crear un gráfico limpio.
La detección de comunidades aplica el algoritmo de Leiden para encontrar agrupaciones naturales en múltiples niveles. El nivel 0 puede contener grupos compactos de entre 5 y 10 entidades relacionadas. Los niveles superiores agrupan esos temas en categorías más amplias. Un corpus sobre empresas de IA podría tener comunidades de nivel 0 para empresas individuales, de nivel 1 para «laboratorios de IA» y «fabricantes de chips», y de nivel 2 para abarcar todo el ecosistema tecnológico. A continuación, cada comunidad recibe un resumen generado por LLM en el que se describe lo que representa ese clúster. Estos resúmenes se calculan previamente, antes de que llegue cualquier consulta de los usuarios.
El resultado final no es un índice de recuperación. Es una representación estructurada: gráfico más resúmenes, lista para ser consultada de diferentes maneras.
Una vez creado el gráfico, las consultas se dirigen a diferentes estrategias de recuperación:
El contenido recuperado (resúmenes, entidades, relaciones, texto fuente) se reúne en una indicación, y el LLM genera la respuesta final. Cada estrategia sirve para diferentes tipos de preguntas, que analizaremos a continuación.
GraphRAG ofrece tres estrategias de recuperación distintas, cada una de ellas adecuada para diferentes tipos de preguntas. Elegir la opción adecuada depende de si necesitas una síntesis amplia, información específica sobre una entidad o algo intermedio.
La búsqueda global responde a preguntas que requieren comprender un corpus completo. Preguntas como «¿Cuáles son los temas principales de esta recopilación de documentos?» o «¿Qué patrones se observan en estos informes?» requieren información agregada de todas partes, no extraída de unos pocos fragmentos coincidentes.
El mecanismo es map-reduce sobre resúmenes de la comunidad. En la fase de mapeo, cada resumen de comunidad se procesa de forma independiente: el sistema solicita a un LLM que extraiga los puntos relevantes y califique su importancia. En la fase de reducción, los puntos mejor valorados de todas las comunidades se agregan en una indicación final, y el LLM los sintetiza en una respuesta coherente.
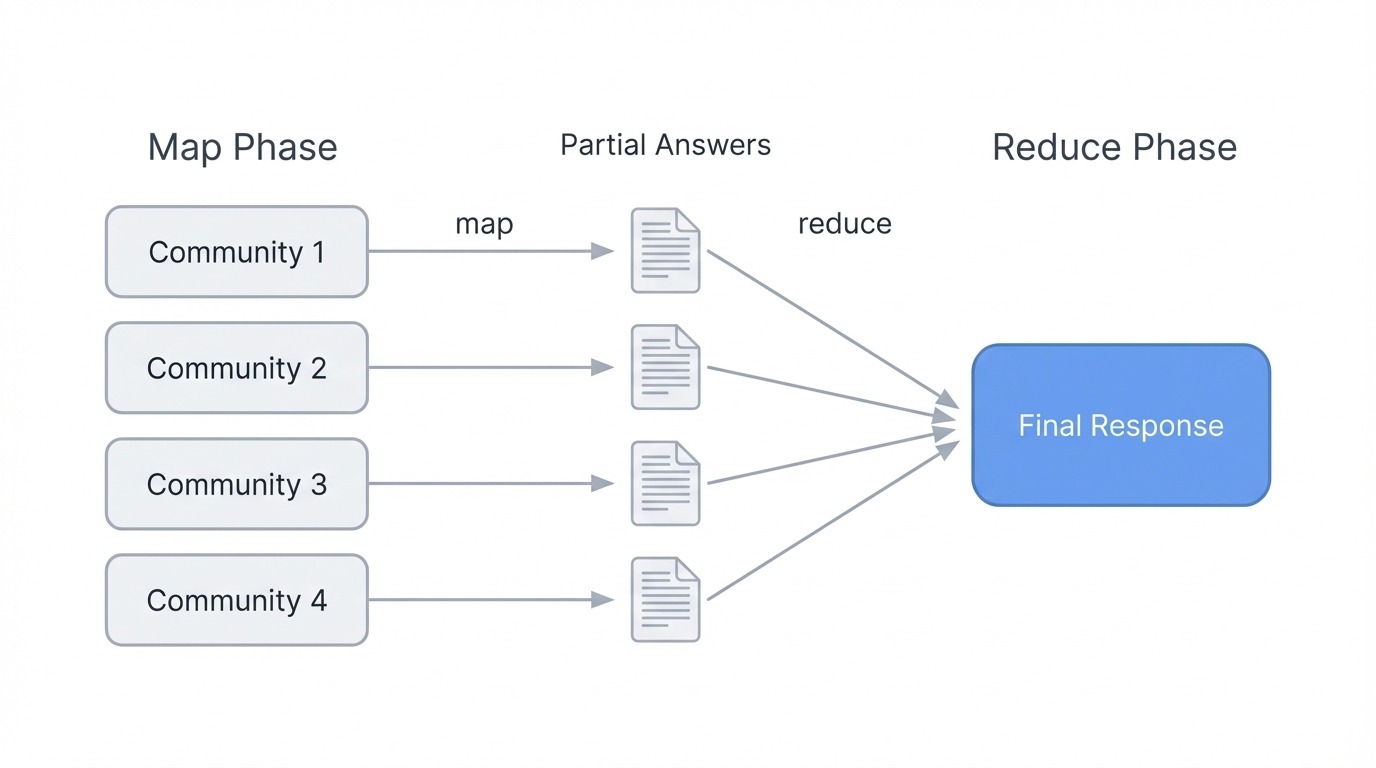
Búsqueda global GraphRAG utilizando map-reduce. Imagen del autor
Esto funciona porque los resúmenes de la comunidad ya recogen lo que trata cada grupo de entidades. El sistema no necesita recuperar miles de fragmentos. En su lugar, razona sobre descripciones precalculadas que representan la estructura del gráfico en cualquier nivel jerárquico que elijas. Los niveles inferiores (comunidades más pequeñas y cerradas) ofrecen respuestas más detalladas, pero cuestan más llamadas LLM. Los niveles más altos (agrupaciones más amplias) funcionan más rápido, pero pueden perder matices.
La búsqueda global requiere más recursos computacionales que los demás modos, ya que procesa todas las comunidades. Úsalo cuando las preguntas realmente requieran una comprensión global del corpus, en lugar de datos específicos.
La búsqueda local gestiona preguntas específicas sobre entidades. «¿Cuáles son las propiedades curativas de la manzanilla?» o «¿Qué ha anunciado Acme Corp sobre sus ganancias del tercer trimestre?» se refieren a entidades concretas y a la información relacionada con ellas.
El proceso de recuperación comienza identificando qué entidades del gráfico están relacionadas con la consulta. Estas entidades se convierten en puntos de entrada para el recorrido. Desde cada nodo inicial, el sistema extrae las entidades conectadas, las relaciones entre ellas, cualquier afirmación o hecho asociado, y la comunidad a la que pertenecen esas entidades. También recupera los fragmentos de texto originales vinculados a esas entidades, proporcionando al LLM tanto datos gráficos estructurados como texto fuente.
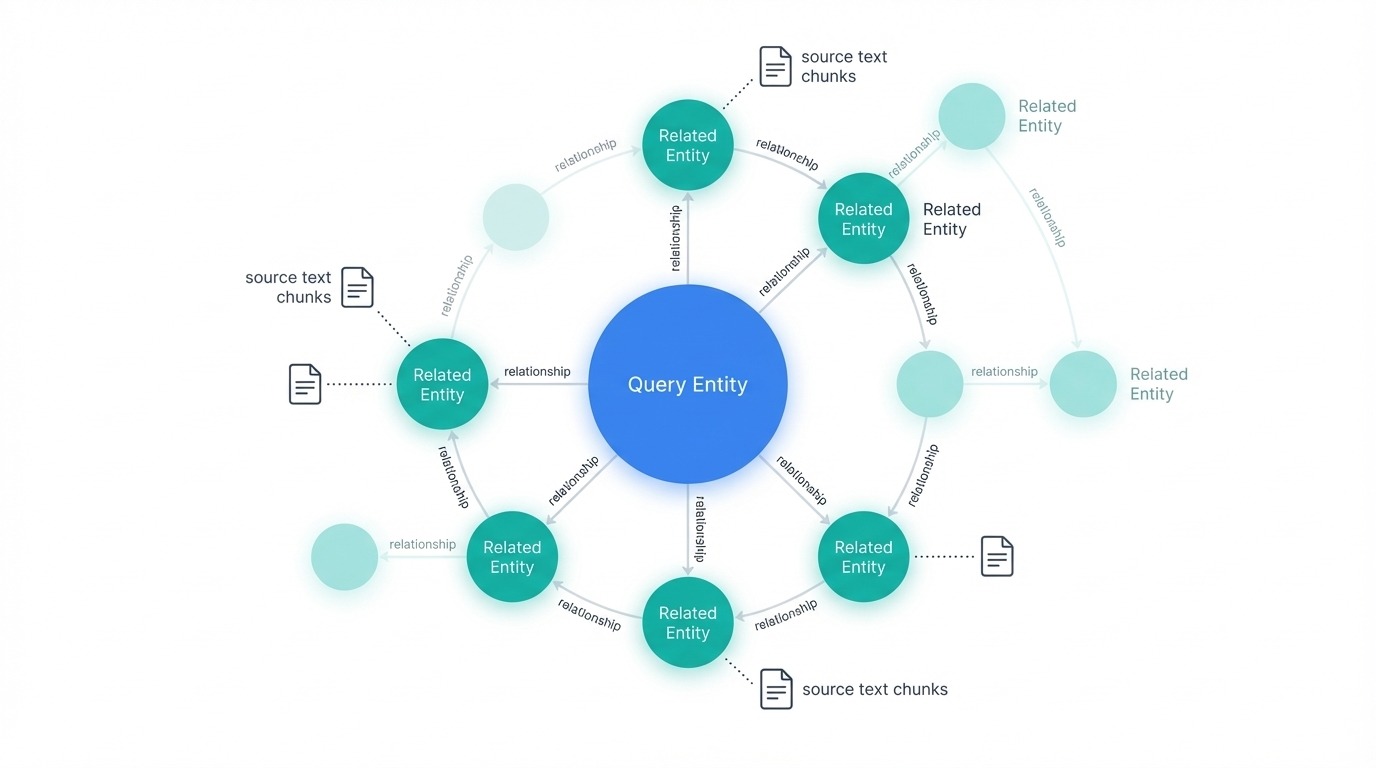
Búsqueda local GraphRAG con nodos relacionados. Imagen del autor
Toda esta información sobre los candidatos se clasifica y filtra para ajustarse a la ventana de contexto. A continuación, el LLM genera una respuesta basada en el contenido recuperado. Dado que la búsqueda local se centra en una parte del gráfico en lugar de en el conjunto, es más rápida y económica que la búsqueda global.
Elige la búsqueda local cuando las preguntas se refieran a cosas, personas, organizaciones o conceptos específicos mencionados en tus documentos.
DRIFT (Razonamiento dinámico e inferencia con recorrido flexible) se sitúa entre lo global y lo local. Maneja consultas complejas que requieren tanto un contexto amplio como detalles específicos.
El proceso tiene tres fases. En primer lugar, la fase inicial compara la consulta con los resúmenes de la comunidad más relevantes desde el punto de vista semántico y genera una respuesta inicial junto con preguntas de seguimiento. En segundo lugar, la fase de seguimiento toma esas preguntas y aplica la búsqueda local para profundizar en áreas específicas, produciendo respuestas intermedias y seguimientos más específicos. En tercer lugar, la fase de salida combina todo en resultados clasificados que equilibran la información global con los detalles locales.
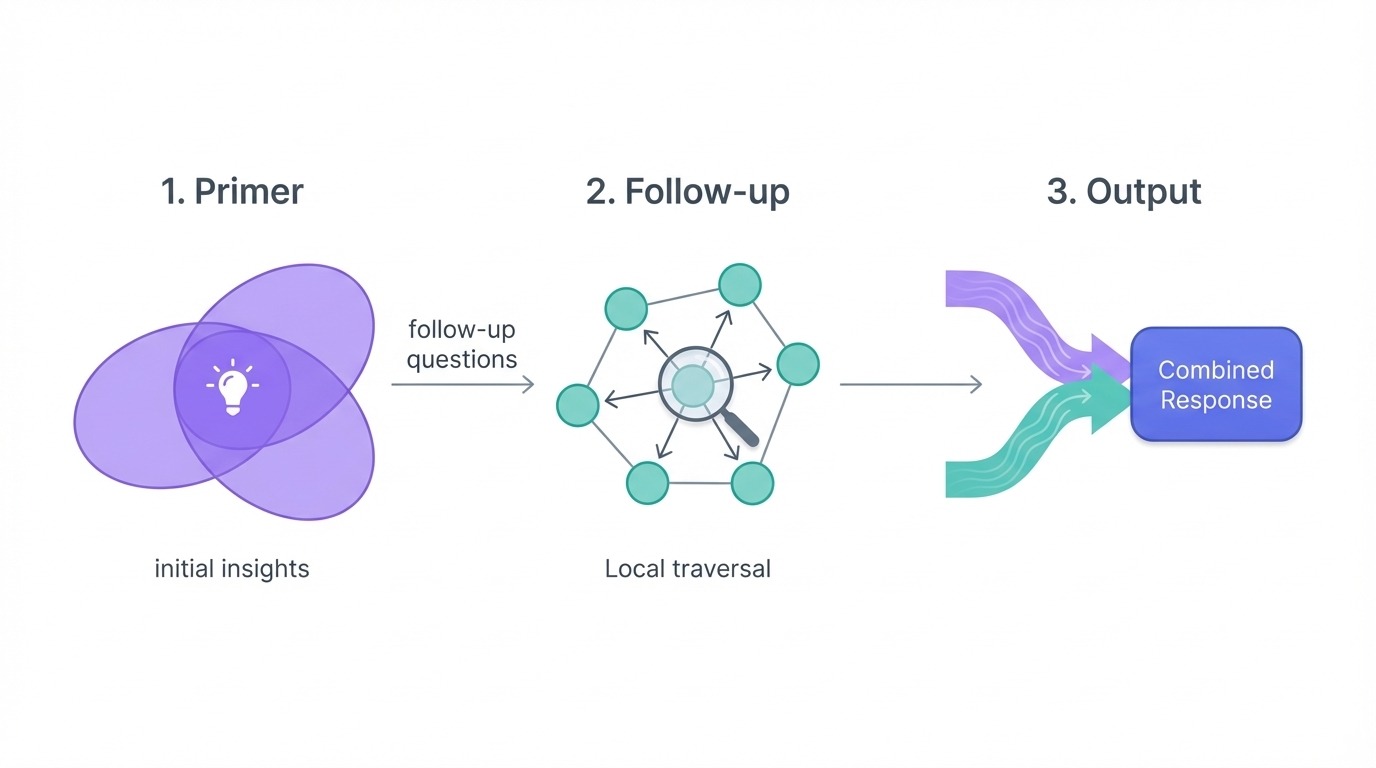
Proceso de búsqueda en tres fases de GraphRAG DRIFT. Imagen del autor.
Lo que hace que DRIFT sea útil es cómo amplía el punto de partida de la búsqueda. Al comenzar con el contexto a nivel comunitario, recupera una mayor variedad de datos que la búsqueda local pura. Pero al refinar mediante el recorrido local, se evita el coste de una búsqueda global completa.
Utiliza DRIFT para preguntas como «¿Cómo se comparan los retos a los que se enfrenta la empresa X con las tendencias generales del sector?», en las que necesitas tanto información específica sobre la entidad como contexto temático.
|
Aspecto |
Global |
Local |
DRIFT |
|
Ideal para |
Temas y patrones generales del corpus |
Preguntas específicas sobre entidades |
Consultas complejas que requieren tanto |
|
Mecanismo |
Map-reduce sobre resúmenes de la comunidad |
Recorrido por el vecindario de entidades |
Fases de preparación → seguimiento → resultados |
|
Velocidad |
Más lento (procesa todas las comunidades) |
Más rápido (recorrido enfocado) |
Medio (comienza amplio, se va estrechando) |
|
Coste |
Más alto |
Más bajo |
Medio |
|
Ejemplo de consulta |
¿Cuáles son los temas principales? |
¿Qué anunció la empresa X? |
¿Cómo se compara X con las tendencias del sector? |
GraphRAG también proporciona una búsqueda vectorial básica como alternativa para consultas sencillas en las que el recorrido del grafo sería excesivo. Sin embargo, para la mayoría de los casos de uso, elegir entre global, local y DRIFT cubre tus necesidades.
En esta sección se explica cómo crear un sistema GraphRAG utilizando la implementación de referencia de Microsoft. Trabajaremos con un pequeño corpus de ensayos de Paul Graham sobre startups para que los ejemplos sean viables y los costes razonables. Si eres nuevo en la combinación de grafos de conocimiento con sistemas de recuperación, eltutorial RAG del grafo de conocimiento « » (El futuro de la recuperación de información) cubre los conceptos fundamentales.
Crea un directorio para el proyecto e inicialízalo con uv, luego instala el paquete graphrag. La biblioteca tiene dependencias importantes (237 paquetes, incluido PyTorch), por lo que la instalación tardará unos cinco minutos:
mkdir ragtest && cd ragtest
uv init
uv add graphrag
graphrag init --root .Esto genera la estructura del proyecto:
ragtest/
├── .env # API key configuration
├── settings.yaml # Pipeline settings
├── prompts/ # LLM prompt templates
│ ├── extract_graph.txt
│ ├── summarize_descriptions.txt
│ └── ...
└── input/ # Your source documents go hereEl directorio prompts/ contiene las plantillas que GraphRAG utiliza para la extracción y resumen de entidades. Puedes personalizarlos según las necesidades específicas de tu dominio, aunque los valores predeterminados funcionan bien para el texto general.
Añade archivos de texto al directorio input/. Para este tutorial, utilizaremos tres ensayos de Paul Graham sobre startups. Tu sitio web utiliza un código HTML mínimo con contenido envuelto en etiquetas ` `, por lo que un analizador sintáctico sencillo extrae el texto de forma limpia:
import urllib.request
from html.parser import HTMLParser
class TextExtractor(HTMLParser):
def __init__(self):
super().__init__()
self.text = []
self.in_font = False
def handle_starttag(self, tag, attrs):
if tag == 'font':
self.in_font = True
def handle_endtag(self, tag):
if tag == 'font':
self.in_font = False
def handle_data(self, data):
if self.in_font:
self.text.append(data)
essays = {
"startupideas": "http://paulgraham.com/startupideas.html",
"do_things_that_dont_scale": "http://paulgraham.com/ds.html",
"startup_growth": "http://paulgraham.com/growth.html"
}
for name, url in essays.items():
with urllib.request.urlopen(url) as response:
html = response.read().decode('utf-8')
parser = TextExtractor()
parser.feed(html)
text = ' '.join(parser.text)
with open(f"input/{name}.txt", "w") as f:
f.write(text)
print(f"Saved {name}.txt ({len(text.split())} words)")Saved startupideas.txt (3000 words)
Saved do_things_that_dont_scale.txt (3000 words)
Saved startup_growth.txt (3000 words)Un total de aproximadamente 9000 palabras repartidas en tres ensayos relacionados temáticamente, suficientes para ver relaciones significativas entre entidades sin incurrir en grandes costes de API.
Edita .env para añadir tu clave API de OpenAI:
GRAPHRAG_API_KEY=your-openai-api-key-hereEl modelo predeterminado settings.yaml funciona desde el primer momento, pero es posible que quieras ajustarlo. El archivo utiliza por defecto el algoritmo de compresión de datos « gpt-4o-mini », que equilibra el coste y la calidad. Consulta lareferencia de configuración completa de para ver todas las opciones disponibles:
models:
default_chat_model:
type: openai_chat
auth_type: api_key
api_key: ${GRAPHRAG_API_KEY}
model: gpt-4o-mini
model_supports_json: true
concurrent_requests: 25
default_embedding_model:
type: openai_embedding
auth_type: api_key
api_key: ${GRAPHRAG_API_KEY}
model: text-embedding-3-smallOtros ajustes destacados en la configuración:
chunks:
size: 1200 # Tokens per chunk
overlap: 100 # Overlap between chunks
extract_graph:
entity_types: [organization, person, geo, event]
max_gleanings: 1 # Additional extraction passes
cluster_graph:
max_cluster_size: 10Construye el gráfico de conocimiento con:
graphrag index --root .El proceso procesa documentos mediante la extracción de entidades, la construcción de gráficos y la detección de comunidades:
├── Loading Input (InputFileType.text) - 3 files loaded (0 filtered) ───
├── create_base_text_units
├── create_final_documents
├── extract_graph
├── finalize_graph
├── create_final_entities
├── create_final_relationships
├── create_final_text_units
├── create_base_entity_graph
├── create_communities
├── create_final_communities
├── create_community_reports
├── generate_text_embeddings
⠋ GraphRAG Indexer
├── All workflows completed successfullyCada paso se basa en el anterior. La fase « extract_graph » realiza la mayor parte de las llamadas LLM, mientras que « create_communities » aplica el algoritmo Leiden para agrupar entidades relacionadas.
Con vuestros tres ensayos, la indexación se completa en unos dos minutos. Puedes inspeccionar los resultados cargando los archivos parquet o comprobando el recuento de filas:
El resultado se guarda en output/ en forma de archivos parquet:
output/
├── documents.parquet
├── entities.parquet
├── relationships.parquet
├── text_units.parquet
├── communities.parquet
├── community_reports.parquet
└── lancedb/ # Vector embeddingsEl formato de parqué hace que todo sea portátil. Puedes cargar estos archivos con pandas para inspeccionar entidades, explorar relaciones o depurar problemas de extracción. El directorio completo del proyecto es lo suficientemente pequeño como para controlar las versiones (menos de 10 MB para este corpus), solo tienes que excluir el archivo .env que contiene tu clave API.
GraphRAG ofrece tres modos de consulta. Probemos cada uno.
Búsqueda global de preguntas temáticas:
graphrag query \
--root . \
--method global \
--query "What are the main themes and lessons about startups in these essays?"SUCCESS: Global Search Response:
The essays present several interconnected themes about startups:
**Growth as the defining characteristic**: A startup isn't just a new company—it's
specifically designed for rapid growth. This growth orientation shapes everything
from idea selection to daily decision-making. The essays suggest using weekly
growth rate as a compass for all strategic choices.
**The power of doing unscalable things**: Counterintuitively, successful startups
often begin with manual, labor-intensive approaches. Stripe's founders would
physically set up new users on the spot. Airbnb's founders went door-to-door
recruiting hosts. These unscalable tactics bootstrap the initial user base.
**Ideas emerge from problems, not brainstorming**: The best startup ideas come
from founders solving their own problems or noticing gaps while "living in the
future." Deliberately trying to generate ideas tends to produce plausible-sounding
but ultimately weak concepts.
**User relationships matter early**: Early users provide irreplaceable feedback.
Founders should go beyond standard customer service to create exceptional
experiences, gathering insights that shape the product.La respuesta sintetiza temas de los tres ensayos, algo que requeriría recuperar y procesar muchos fragmentos con el RAG tradicional. En cambio, la búsqueda global se extrae de los resúmenes de la comunidad, lo que ofrece una visión coherente y de alto nivel.
Búsqueda local de preguntas específicas sobre entidades:
graphrag query \
--root . \
--method local \
--query "What role does Y Combinator play according to these essays?"SUCCESS: Local Search Response:
Y Combinator functions as both an accelerator and a testing ground for startup
principles. According to the essays, YC provides:
**Funding and validation**: YC offers initial funding that lets founders focus
on building rather than fundraising. The program validates ideas through its
selection process.
**Growth measurement framework**: YC tracks startups by weekly growth rate,
with 5-7% weekly growth considered good and 10% exceptional. This metric-driven
approach forces founders to confront whether they're making real progress.
**Network effects**: B2B startups at YC gain immediate access to hundreds of
potential customers—other YC companies. Stripe leveraged this extensively in
its early days.
**Demo Day as forcing function**: The program's structure, culminating in Demo
Day presentations to investors, creates urgency that pushes founders to ship
and iterate quickly.La búsqueda local recorrió el gráfico comenzando por la entidad Y Combinator, incluyendo conceptos relacionados como métricas de crecimiento, Stripe y Demo Day. La respuesta se basa en lo que realmente dicen los ensayos sobre YC, más que en conocimientos generales.
Búsqueda DRIFT para preguntas que requieren amplitud y especificidad:
graphrag query \
--root . \
--method drift \
--query "How do the essays describe the relationship between startup ideas and user problems?"SUCCESS: Drift Search Response:
The essays establish a direct link between viable startup ideas and genuine user
problems through several mechanisms:
**Organic discovery over invention**: Rather than brainstorming ideas, founders
should notice problems they personally experience. Microsoft, Apple, Google, and
Facebook all started this way—founders building something they themselves needed.
**The "well" vs "shallow hole" distinction**: Good ideas serve a small number of
users who desperately need the solution (a narrow, deep well) rather than many
users with mild interest (a broad, shallow hole). Depth of need matters more
than breadth of appeal initially.
**Feedback loops as validation**: Engaging directly with early users reveals
whether the problem is real and the solution fits. This feedback shapes the
product more than any amount of planning.
**Problem-first, solution-second**: The essays warn against "sitcom startup
ideas"—concepts that sound plausible but don't address real pain points. A
social network for pet owners sounds reasonable but lacks urgent demand.DRIFT comenzó con un contexto amplio a nivel comunitario sobre la filosofía de las startups, y luego profundizó en ejemplos específicos, como la analogía del pozo y las ideas de las comedias de situación. El resultado combina una visión temática con detalles concretos del texto original.
Para los sistemas de producción, utiliza directamente la API de Python. El proceso consta de tres partes: cargar la configuración, cargar los datos indexados y ejecutar consultas.
En primer lugar, configura el sistema cargando las variables de entorno y analizando el archivo de configuración:
import os
import yaml
from pathlib import Path
from dotenv import load_dotenv
from graphrag.config.create_graphrag_config import create_graphrag_config
ROOT_DIR = Path(".")
# Load environment variables and config
load_dotenv(ROOT_DIR / ".env")
with open(ROOT_DIR / "settings.yaml") as f:
yaml_content = f.read()
yaml_content = os.path.expandvars(yaml_content) # Expand ${VAR} references
settings = yaml.safe_load(yaml_content)
config = create_graphrag_config(values=settings, root_dir=str(ROOT_DIR))A continuación, carga todos los datos indexados de los archivos parquet. GraphRAG almacena entidades, relaciones, comunidades y fragmentos de texto por separado:
import pandas as pd
output_dir = ROOT_DIR / "output"
entities = pd.read_parquet(output_dir / "entities.parquet")
communities = pd.read_parquet(output_dir / "communities.parquet")
community_reports = pd.read_parquet(output_dir / "community_reports.parquet")
text_units = pd.read_parquet(output_dir / "text_units.parquet")
relationships = pd.read_parquet(output_dir / "relationships.parquet")
print(f"Loaded {len(entities)} entities, {len(relationships)} relationships")Loaded 74 entities, 89 relationshipsPor último, ejecuta consultas utilizando la API asíncrona. La función local_search toma todos los DataFrame más los parámetros de consulta:
import asyncio
from graphrag.api import local_search
async def run_query(query: str):
response, context = await local_search(
config=config,
entities=entities,
communities=communities,
community_reports=community_reports,
text_units=text_units,
relationships=relationships,
covariates=None,
community_level=2,
response_type="Multiple Paragraphs",
query=query,
)
return response
query = "What advice do the essays give about finding startup ideas?"
response = asyncio.run(run_query(query))
print(response)The essays provide several valuable insights into finding startup ideas:
Focus on Growth: A startup is designed to grow quickly. Founders should commit
to seeking ideas that can scale significantly, as this distinguishes startups
from ordinary businesses.
Identify Unmet Needs: Successful startups arise from recognizing problems that
need solving. Founders who can see different problems, particularly those
addressable through technology, are more likely to develop effective solutions.
Leverage Personal Insights: Many successful startups originate from the unique
insights of their founders, often stemming from personal experiences or
frustrations. This personal connection leads to more authentic solutions.
Explore Overlooked Markets: Founders should think outside the box and explore
markets that may be overlooked. Successful startups often emerge from ideas
that seem obvious to the founders but aren't yet recognized broadly.La API de Python te ofrece un control total sobre qué datos cargar, qué nivel de comunidad consultar y cómo dar formato a las respuestas. Para aplicaciones que requieren una lógica de recuperación personalizada o la integración con sistemas existentes, este es el camino a seguir.
El RAG tradicional funciona bien hasta que deja de hacerlo. Sabrás que has llegado al límite cuando los usuarios te pregunten sobre temas o patrones y obtengan como respuesta un batiburrillo de fragmentos vagamente relacionados entre sí en lugar de una respuesta coherente. Ese es el problema que GraphRAG resuelve al intercambiar fragmentos por un gráfico de conocimiento con resúmenes comunitarios precalculados.
Sin embargo, el costo es real. La indexación consume muchas llamadas LLM, y la búsqueda global tampoco es barata. Para una pequeña colección de documentos o búsquedas sencillas, utiliza la búsqueda vectorial.
Pero si tu corpus tiene conexiones ricas entre entidades y a tus usuarios les importan esas conexiones, GraphRAG vale la pena. Elige el tipo de consulta en función de lo que estés preguntando: global para temas, local para entidades específicas, DRIFT cuando necesites ambos. La implementación no es complicada una vez que la has ejecutado una vez, y la salida de parquet hace que todo sea fácil de inspeccionar y depurar.
Aprende con DataCamp
Curso
Curso
Curso