programa
Fundamentos del negocio de la IA
12 h
¿Te has preguntado alguna vez cómo dan respuestas tan precisas a tus preguntas asistentes digitales como Alexa o Asistente de Google?
La magia que hay detrás de esto se llama generación mejorada por recuperación (RAG), y combina la recuperación de información con técnicas de generación de lenguaje. Un elemento clave en este proceso es el grafo de conocimiento, que ayuda a estos asistentes a acceder a un enorme conjunto de información estructurada para mejorar sus respuestas.
En este tutorial, exploraremos los grafos de conocimiento y cómo pueden utilizarse para crear aplicaciones RAG con el fin de obtener respuestas más exactas y pertinentes.
Empezaremos por los fundamentos de los grafos de conocimiento y su papel en RAG. Los compararemos con las bases de datos de vectores y aprenderemos cuándo es mejor utilizar una u otra opción. A continuación, crearemos un grafo de conocimiento a partir de datos de texto, lo almacenaremos en una base de datos y lo utilizaremos para buscar información pertinente para las consultas de los usuarios. También ampliaremos este enfoque para manejar distintos tipos de datos y formatos de archivo más allá del texto simple.
Si quieres saber más sobre RAG, consulta este artículo sobre generación mejorada por recuperación.
Los grafos de conocimiento representan información en un formato estructurado interconectado. Constan de entidades (nodos) y relaciones (bordes) entre esas entidades. Las entidades pueden representar objetos, conceptos o ideas reales, y las relaciones describen cómo están conectadas esas entidades.
La intuición que subyace a los grafos de conocimiento es imitar la forma en que los humanos entienden el mundo y razonan sobre él. No almacenamos información en silos aislados, sino que establecemos conexiones entre distintos datos, formando una red de conocimiento rica e interconectada.
Los grafos de conocimiento nos ayudan a ver cómo están conectadas las entidades, pues muestran claramente las relaciones entre distintas entidades. Explorar estas conexiones nos permite buscar nueva información y sacar conclusiones a las que sería difícil llegar a partir de datos separados.
Veamos un ejemplo.
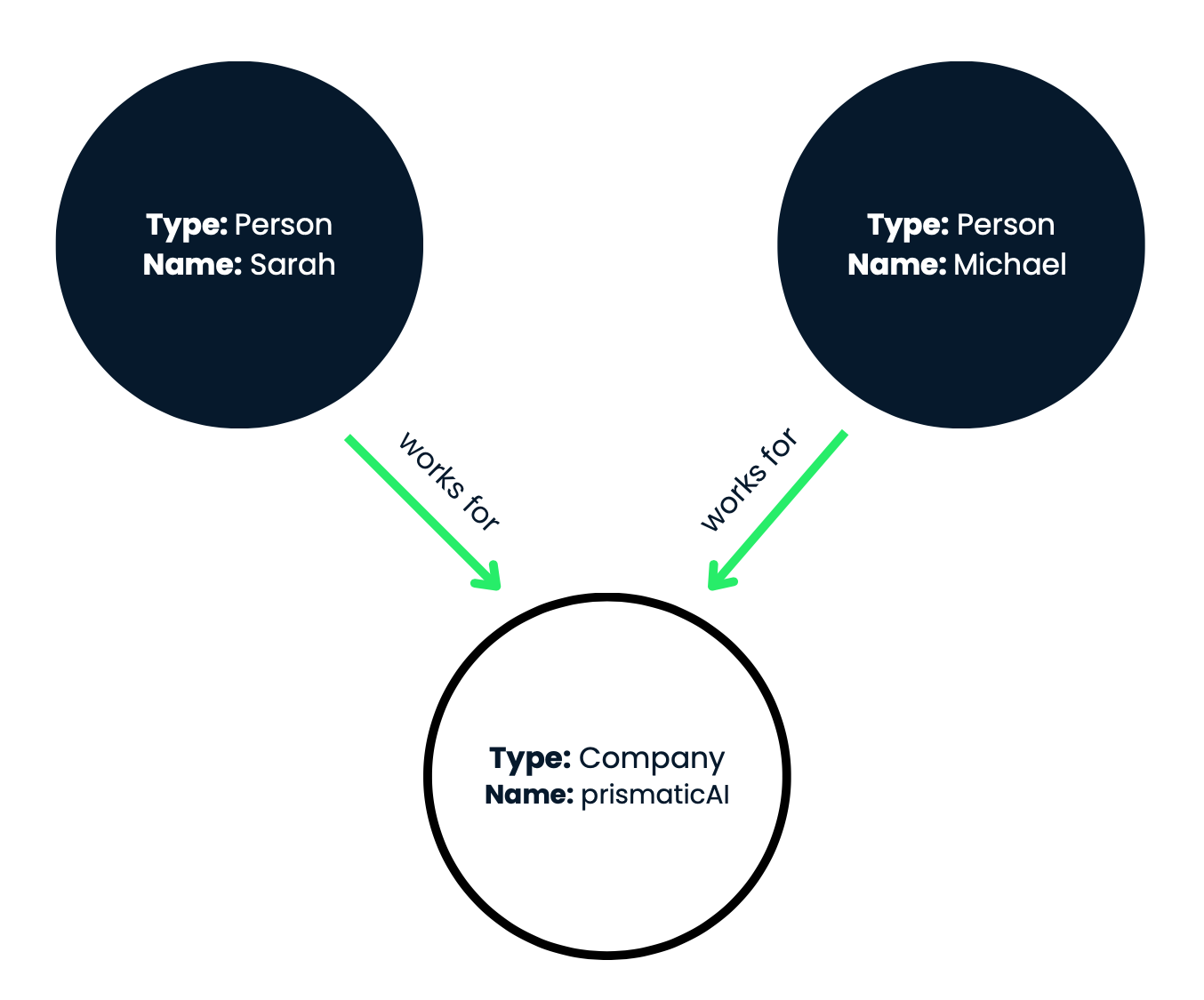
Figura 1: En esta representación visual, los nodos se muestran como círculos y las relaciones se representan como flechas etiquetadas que conectan los nodos.
Este grafo de conocimiento capta eficazmente las relaciones laborales entre Sarah y Michael y la empresa prismaticAI. En nuestro ejemplo, tenemos tres nodos:
En resumen, tenemos dos nodos de persona (Sarah y Michael) y un nodo de empresa (prismaticAI). Ahora, veamos las relaciones (bordes) entre estos nodos:
Uno de los potentes aspectos de los grafos de conocimiento es la capacidad de consultar y atravesar las relaciones entre entidades para extraer información pertinente o inferir nuevo conocimiento. Exploremos cómo podemos hacerlo con nuestro ejemplo de grafo de conocimiento.
En primer lugar, tenemos que determinar qué información queremos recuperar del grafo de conocimiento. Por ejemplo:
Consulta 1: ¿Dónde trabaja Sarah?
Para responder a la consulta, tenemos que buscar el punto de partida adecuado en el grafo de conocimiento. En este caso, queremos partir del nodo que representa a Sarah.
Desde el punto de partida (el nodo de Sarah), seguimos el borde de relación "trabaja en" saliente. Este borde conecta el nodo de Sarah con el nodo que representa a prismaticAI. Atravesando la relación "trabaja en", podemos concluir que Sarah trabaja en prismaticAI.
Respuesta 1: Sarah trabaja en prismaticAI.
Probemos con otra consulta:
Consulta 2: ¿Quién trabaja en prismaticAI?
Esta vez, queremos partir del nodo que representa a prismaticAI.
Desde el nodo de prismaticAI, seguimos los bordes de relación "trabaja en" hacia atrás. Esto nos llevará a los nodos que representan a las personas que trabajan en prismaticAI. Atravesando las relaciones "trabaja en" en sentido inverso, podemos identificar que tanto Sarah como Michael trabajan en prismaticAI.
Respuesta 2: Sarah y Michael trabajan en prismaticAI.
¡Un ejemplo más!
Consulta 3: ¿Michael trabaja en la misma empresa que Sarah?
Podemos partir del nodo de Sarah o del nodo de Michael. Empecemos desde el nodo de Sarah.
Seguimos la relación "trabaja en" para llegar al nodo de prismaticAI.
A continuación, comprobamos si Michael también tiene una relación "trabaja en" que lleve al mismo nodo de prismaticAI. Puesto que tanto Sarah como Michael tienen una relación "trabaja en" con el nodo de prismaticAI, podemos concluir que trabajan en la misma empresa.
Respuesta 3: Sí, Michael trabaja en la misma empresa que Sarah (prismaticAI).
Atravesar las relaciones del grafo de conocimiento nos permite extraer datos específicos y comprender las conexiones entre entidades. Los grafos de conocimiento pueden ser mucho más complejos, con numerosos nodos y relaciones, lo que permite representar intrincado conocimiento real de forma estructurada e interconectada.
Las aplicaciones RAG combinan recuperación de información y generación de lenguaje natural para ofrecer respuestas pertinentes y coherentes a las consultas o prompts de los usuarios. Los grafos de conocimiento ofrecen varias ventajas que los hacen especialmente adecuados para estas aplicaciones. Veamos las principales ventajas:
Como aprendimos en la sección anterior, los grafos de conocimiento representan información de forma estructurada, con entidades (nodos) y sus relaciones (bordes). Esta representación estructurada hace más fácil la recuperación de información pertinente para una consulta o una tarea determinadas, si la comparamos con los datos de texto no estructurados.
En nuestro ejemplo de grafo de conocimiento podemos recuperar fácilmente información sobre quién trabaja en prismaticAI siguiendo las relaciones "trabaja en".
Los grafos de conocimiento captan las relaciones entre entidades, lo que permite una comprensión más profunda del contexto en el que se presenta la información. Esta comprensión contextual es crucial para generar respuestas coherentes y pertinentes en las aplicaciones RAG.
Volviendo a nuestro ejemplo, comprender la relación "trabaja en" entre Sarah, Michael y prismaticAI permitiría a una aplicación RAG proporcionar respuestas más pertinentes contextualmente sobre su empleo.
Atravesar las relaciones de un grafo de conocimiento permite a las aplicaciones RAG hacer inferencias y derivar nuevo conocimiento que puede no estar explícitamente indicado. Esta capacidad de razonamiento inferencial mejora la calidad de las respuestas generadas y las completa.
Atravesando las relaciones, una aplicación RAG puede inferir que Sarah y Michael trabajan en la misma empresa, aunque esta información no se indique directamente.
Los grafos de conocimiento pueden integrar información de varias fuentes, lo que permite a las aplicaciones RAG utilizar bases de conocimiento diversas y complementarias. Esta integración de conocimiento puede dar lugar a respuestas más completas.
Podríamos añadir información de diversas fuentes sobre empresas, empleados y sus funciones a nuestro ejemplo de grafo de conocimiento y proporcionar una imagen más completa para generar respuestas.
Los grafos de conocimiento proporcionan una representación transparente del conocimiento utilizado para generar respuestas. Esta transparencia es clave para explicar el razonamiento que hay detrás de la salida generada, lo que es importante en muchas aplicaciones, como los sistemas de búsqueda de respuestas.
La explicación de la respuesta 3 de nuestro ejemplo podría ser: Sí, Michael trabaja en la misma empresa que Sarah. He llegado a esta conclusión identificando que Sarah trabaja en prismaticAI y, a continuación, verificando que Michael también tiene una relación "trabaja en" con prismaticAI. Como ambos tienen esta relación con la misma entidad, puedo inferir que trabajan en la misma empresa.
Esta transparencia en el proceso de razonamiento permite a usuarios y desarrolladores comprender cómo ha llegado la aplicación RAG a su respuesta: no es una caja negra. Además, aumenta la confianza en el sistema, ya que el proceso de toma de decisiones se expone claramente y puede verificarse con el grafo de conocimiento.
Por otra parte, si hay incoherencias o falta información en el grafo de conocimiento, la explicación puede ayudar a identificar y resolver esos problemas, lo que mejorará la exactitud de las respuestas y las completará.
Utilizando grafos de conocimiento, las aplicaciones RAG pueden crear respuestas más exactas, claras y comprensibles. Esto los hace útiles para diferentes tareas del procesamiento del lenguaje natural.
Al crear aplicaciones RAG, puedes encontrarte con dos enfoques diferentes: los grafos de conocimiento y las bases de datos de vectores. Aunque ambos se utilizan para representar y recuperar información, difieren en sus estructuras de datos subyacentes y en la forma en que manejan la información.
Exploremos las principales diferencias entre estos dos enfoques:
|
Característica |
Grafos de conocimiento |
Bases de datos de vectores |
|
Representación de datos |
Entidades (nodos) y relaciones (bordes) entre entidades, que forman una estructura de grafo. |
Vectores de alta dimensionalidad, cada uno representando un dato (por ejemplo, documento o frase). |
|
Mecanismos de recuperación |
Atravesar la estructura del grafo y seguir las relaciones entre entidades. Permite la inferencia y la derivación de nuevo conocimiento. |
Similitud vectorial basada en un parámetro de similitud (por ejemplo, similitud coseno). Devuelve los vectores más similares y la información asociada. |
|
Interpretabilidad |
Representación del conocimiento interpretable por el ser humano. La estructura de grafo y las relaciones etiquetadas aclaran las conexiones entre entidades. |
Menos interpretables para los humanos debido a las representaciones numéricas de alta dimensionalidad. Dificultad para comprender directamente las relaciones o el razonamiento que hay detrás de la información recuperada. |
|
Integración de conocimiento |
Facilita la integración representando entidades y relaciones en una estructura de grafo unificada. Integración perfecta si las entidades y las relaciones se asignan correctamente. |
Más difícil. Requiere técnicas como la alineación de espacios vectoriales o métodos por conjuntos para combinar información. Garantizar la compatibilidad vectorial puede no ser trivial. |
|
Razonamiento inferencial |
Permite el razonamiento inferencial atravesando la estructura de grafo y aprovechando las relaciones entre entidades. Descubre conexiones implícitas y deriva nueva información. |
Más limitado. Depende de la similitud vectorial y puede pasar por alto relaciones o inferencias implícitas. Puede identificar información similar, pero no relaciones complejas de grafos de conocimiento. |
Tanto los grafos de conocimiento como las bases de datos de vectores tienen sus puntos fuertes y sus casos de uso, y la elección de unos u otras depende de los requisitos específicos de tu aplicación. Los grafos de conocimiento son excelentes para representar conocimiento estructurado y razonar sobre él, y las bases de datos de vectores son adecuadas para tareas que dependen en gran medida de la similitud semántica y la recuperación de información basada en representaciones vectoriales.
Puedes aprender más sobre bases de datos de vectores en esta introducción a las bases de datos de vectores para machine learning. Consulta además las cinco bases de datos de vectores más populares.
En esta sección, exploraremos cómo implementar un grafo de conocimiento para mejorar el proceso de generación de lenguaje de una aplicación RAG.
Veremos los siguientes pasos clave:
Al final de esta sección, tendrás una sólida comprensión de la implementación de grafos de conocimiento en aplicaciones RAG, lo que te permitirá construir sistemas de generación de lenguaje más inteligentes y contextualizados.
Antes de empezar, asegúrate de que tienes instalado lo siguiente:
pip install langchain)pip install llama-index)El primer paso es cargar y preprocesar los datos de texto de los que extraeremos el grafo de conocimiento. En este ejemplo, utilizaremos un fragmento de texto que describe una empresa tecnológica llamada prismaticAI, sus empleados y sus funciones.
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
# Load text data
text = """Sarah is an employee at prismaticAI, a leading technology company based in Westside Valley. She has been working there for the past three years as a software engineer.
Michael is also an employee at prismaticAI, where he works as a data scientist. He joined the company two years ago after completing his graduate studies.
prismaticAI is a well-known technology company that specializes in developing cutting-edge software solutions and artificial intelligence applications. The company has a diverse workforce of talented individuals from various backgrounds.
Both Sarah and Michael are highly skilled professionals who contribute significantly to prismaticAI's success. They work closely with their respective teams to develop innovative products and services that meet the evolving needs of the company's clients."""
loader = TextLoader(text)
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=20)
texts = text_splitter.split_documents(documents)Empezamos importando las clases necesarias de LangChain: TextLoader y CharacterTextSplitter. TextLoader carga los datos de texto, y CharacterTextSplitter divide el texto en fragmentos para un procesamiento más eficiente.
A continuación, definimos los datos de texto como una variable de cadena multilínea text.
A continuación, utilizamos TextLoader para cargar los datos de texto directamente desde la variable de texto. El método loader.load() devuelve una lista de objetos Document, cada uno de los cuales contiene un fragmento del texto.
Para dividir el texto en fragmentos más manejables, creamos una instancia de CharacterTextSplitter con un chunk_size de 200 caracteres y un chunk_overlap de 20 caracteres. El parámetro chunk_overlap garantiza que haya cierto solapamiento entre fragmentos adyacentes, lo que puede ser útil para mantener el contexto durante el proceso de extracción de conocimiento.
Por último, utilizamos el método split_documents de CharacterTextSplitter para dividir los objetos Document en fragmentos, que se almacenan en la variable de texto como una lista de objetos Document.
Preprocesar los datos de texto de esta forma nos permite prepararlos para el siguiente paso, en el que inicializaremos un modelo de lenguaje y lo utilizaremos para extraer un grafo de conocimiento de los fragmentos de texto.
Tras cargar y preprocesar los datos de texto, el siguiente paso es inicializar un modelo de lenguaje y utilizarlo para extraer un grafo de conocimiento de los fragmentos de texto. En este ejemplo, utilizaremos el modelo de lenguaje OpenAI proporcionado por LangChain.
from langchain.llms import OpenAI
from langchain.transformers import LLMGraphTransformer
import getpass
import os
# Load environment variable for OpenAI API key
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Initialize LLM
llm = OpenAI(temperature=0)
# Extract Knowledge Graph
llm_transformer = LLMGraphTransformer(llm=llm)
graph_documents = llm_transformer.convert_to_graph_documents(texts)En primer lugar, importamos las clases necesarias de LangChain: OpenAI y LLMGraphTransformer. OpenAI es un contenedor del modelo de lenguaje OpenAI, que utilizaremos para extraer el grafo de conocimiento. LLMGraphTransformer es una clase utilidad que ayuda a convertir los datos de texto en una representación de grafo de conocimiento.
A continuación, cargamos la clave de API OpenAI desde una variable de entorno. Esta es una práctica recomendada de seguridad para evitar la codificación rígida de credenciales confidenciales en tu código.
A continuación, inicializamos una instancia del modelo de lenguaje OpenAI con una temperatura de 0. El parámetro de temperatura controla la aleatoriedad de la salida del modelo: los valores más bajos producen respuestas más deterministas.
Tras inicializar el modelo de lenguaje, creamos una instancia de LLMGraphTransformer y le pasamos el objeto llm inicializado. La clase LLMGraphTransformer convierte los fragmentos de texto (texts) en una representación de grafo de conocimiento.
Por último, llamamos al método convert_to_graph_documents de LLMGraphTransformer y pasamos la lista de textos. Este método utiliza el modelo de lenguaje para analizar los fragmentos de texto y extraer entidades, relaciones y otros tipos de información estructurada pertinentes, que a continuación se representan como grafo de conocimiento. El grafo de conocimiento resultante se almacena en la variable graph_documents.
Hemos inicializado un modelo de lenguaje y lo hemos utilizado para extraer un grafo de conocimiento de los datos de texto. En el siguiente paso, almacenaremos el grafo de conocimiento en una base de datos para persistencia y consultas.
Tras extraer el grafo de conocimiento de los datos de texto, es importante almacenarlo en un formato persistente y consultable. En este tutorial, utilizaremos Neo4j para almacenar el grafo de conocimiento.
from langchain.graph_stores import Neo4jGraphStore
# Store Knowledge Graph in Neo4j
graph_store = Neo4jGraphStore(url="neo4j://your_neo4j_url", username="your_username", password="your_password")
graph_store.write_graph(graph_documents)En primer lugar, importamos la clase Neo4jGraphStore de LangChain. Esta clase proporciona una cómoda interfaz para interactuar con una base de datos Neo4j y almacenar grafos de conocimiento.
A continuación, creamos una instancia de Neo4jGraphStore proporcionando los datos de conexión necesarios: la URL de la base de datos Neo4j, el nombre de usuario y la contraseña. Asegúrate de sustituir "your_neo4j_url", "your_username" y "your_password" por los valores correspondientes de tu instancia de Neo4j.
Por último, llamamos al método write_graph de la instancia graph_store y pasamos la lista graph_documents obtenida en el paso anterior. Este método serializa el grafo de conocimiento y lo escribe en la base de datos Neo4j.
Almacenar el grafo de conocimiento en una base de datos Neo4j nos permite asegurarnos de que sea persistente y se pueda consultar y recuperar fácilmente cuando sea necesario. La estructura de grafo de Neo4j permite representar y atravesar con eficiencia las complejas relaciones y entidades presentes en el grafo de conocimiento.
En el siguiente paso, configuraremos los componentes para recuperar conocimiento del grafo y generar respuestas utilizando el contexto recuperado.
Es importante señalar que, aunque este tutorial utiliza Neo4j como base de datos orientada a grafos, LangChain también admite otras bases de datos orientadas a grafos, como Amazon Neptune y bases de datos compatibles con TinkerPop, como Gremlin Server. Puedes cambiar Neo4jGraphStore por la implementación de almacén de grafos adecuada para la base de datos que elijas.
Ahora que hemos almacenado el grafo de conocimiento en una base de datos, podemos configurar los componentes para recuperar el conocimiento pertinente del grafo en función de las consultas del usuario y generar respuestas utilizando el contexto recuperado. Esta es la funcionalidad principal de una aplicación RAG.
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import KnowledgeGraphRAGRetriever
from llama_index.core.response_synthesis import ResponseSynthesizer
# Retrieve Knowledge for RAG
graph_rag_retriever = KnowledgeGraphRAGRetriever(storage_context=graph_store.storage_context, verbose=True)
query_engine = RetrieverQueryEngine.from_args(graph_rag_retriever)En primer lugar, importamos las clases necesarias de LlamaIndex: RetrieverQueryEngine, KnowledgeGraphRAGRetriever y ResponseSynthesizer.
RetrieverQueryEngine es un motor de consulta que utiliza un recuperador para obtener el contexto pertinente de una fuente de datos (en nuestro caso, el grafo de conocimiento) y, a continuación, sintetiza una respuesta utilizando ese contexto.
KnowledgeGraphRAGRetriever es un recuperador especializado que puede recuperar información pertinente de un grafo de conocimiento almacenado en una base de datos.
ResponseSynthesizer se encarga de generar una respuesta final combinando el contexto recuperado con un modelo de lenguaje.
A continuación, creamos una instancia de KnowledgeGraphRAGRetriever pasando storage_context de nuestra instancia graph_store. Este storage_context contiene la información necesaria para conectarse a la base de datos Neo4j, en la que hemos almacenado el grafo de conocimiento, y consultarla. También configuramos verbose=True para activar el registro detallado durante el proceso de recuperación.
A continuación, inicializamos un RetrieverQueryEngine utilizando el método from_args y pasando nuestra instancia graph_rag_retriever. Este motor de consulta se encargará de todo el proceso de recuperar el contexto pertinente del grafo de conocimiento y generar una respuesta basada en ese contexto.
Con estos componentes configurados, ya estamos listos para consultar el grafo de conocimiento y generar respuestas utilizando el contexto recuperado. En el siguiente paso, veremos cómo hacerlo en la práctica.
Por último, podemos consultar el grafo de conocimiento y generar respuestas utilizando el contexto recuperado.
def query_and_synthesize(query):
retrieved_context = query_engine.query(query)
response = response_synthesizer.synthesize(query, retrieved_context)
print(f"Query: {query}")
print(f"Answer: {response}\n")
# Initialize the ResponseSynthesizer instance
response_synthesizer = ResponseSynthesizer(llm)
# Query 1
query_and_synthesize("Where does Sarah work?")
# Query 2
query_and_synthesize("Who works for prismaticAI?")
# Query 3
query_and_synthesize("Does Michael work for the same company as Sarah?")En este ejemplo, definimos tres consultas diferentes relacionadas con los empleados y la empresa descritos en los datos de texto. Para cada consulta, utilizamos el query_engine para recuperar el contexto pertinente del grafo de conocimiento, creamos una instancia de ResponseSynthesizer y llamamos a su método synthesize con la consulta y el contexto recuperado.
El ResponseSynthesizer utiliza el modelo de lenguaje y el contexto recuperado para generar una respuesta final a la consulta, que a continuación se imprime en la consola, coincidiendo con las respuestas de la primera sección de este artículo.
Aunque el tutorial demuestra el uso de un grafo de conocimiento para aplicaciones RAG con texto relativamente sencillo, los casos reales suelen implicar conjuntos de datos más complejos y diversos. Además, los datos de entrada pueden tener diferentes formatos de archivo más allá del texto simple. En esta sección, exploraremos cómo puede ampliarse la aplicación RAG basada en grafos de conocimiento para manejar tales casos.
A medida que aumentan el tamaño y la complejidad de los datos de entrada, el proceso de extracción de grafos de conocimiento puede resultar más difícil. He aquí algunas estrategias para manejar conjuntos de datos grandes y diversos:
En casos reales, los datos pueden tener diferentes formatos de archivo, como PDF, documentos de Word, hojas de cálculo o incluso formatos de datos estructurados como JSON o XML. Para manejar estos diferentes tipos de archivo, puedes utilizar las siguientes estrategias:
Estas estrategias te ayudarán a ampliar la aplicación RAG basada en grafos de conocimiento para manejar conjuntos de datos más complejos y diversos, así como una gama más amplia de tipos de archivo.
Es importante tener en cuenta que, a medida que aumenta la complejidad de los datos de entrada, el proceso de extracción de grafos de conocimiento puede requerir más personalización y ajuste específicos del dominio para garantizar resultados exactos y fiables.
Configurar grafos de conocimiento para aplicaciones RAG en el mundo real puede ser una tarea compleja que plantea varios retos. Exploremos algunos:
Construir un grafo de conocimiento de alta calidad es un proceso complejo y lento que requiere un alto grado de pericia en el dominio y esfuerzo. Extraer entidades, relaciones y hechos de diversas fuentes de datos e integrarlos en un grafo de conocimiento coherente puede ser todo un reto, sobre todo cuando se trata de conjuntos de datos grandes y diversos. Requiere comprender el dominio, identificar la información pertinente y estructurar dicha información de forma que capte con exactitud las relaciones y la semántica.
Es frecuente que las aplicaciones RAG deban integrar datos de varias fuentes heterogéneas, cada una con su estructura, su formato y su semántica. Garantizar la coherencia de los datos, resolver conflictos y asignar entidades y relaciones en distintas fuentes de datos no es trivial. Exige cuidado en la limpieza, la transformación y la asignación de datos para garantizar que el grafo de conocimiento represente con precisión la información procedente de diversas fuentes.
Los grafos de conocimiento no son estáticos. Deben actualizarse y mantenerse continuamente a medida que se dispone de nueva información o cambia la información existente. Garantizar la actualización y la coherencia del grafo de conocimiento con respecto a las cambiantes fuentes de datos puede ser un proceso que consuma muchos recursos. Requiere supervisar los cambios de las fuentes de datos, identificar las actualizaciones pertinentes y propagar esas actualizaciones al grafo de conocimiento manteniendo su integridad y su coherencia.
A medida que aumentan el tamaño y la complejidad del grafo de conocimiento, garantizar un almacenamiento, una recuperación y unas consultas eficientes de los datos del grafo se convierte en un reto cada vez mayor. Pueden surgir problemas de escalabilidad y rendimiento, sobre todo en aplicaciones RAG a gran escala con grandes volúmenes de consultas. La optimización de las técnicas de almacenamiento, indexación y procesamiento de consultas del grafo de conocimiento es crucial para mantener niveles de rendimiento aceptables.
Aunque los grafos de conocimiento destacan en la representación de relaciones complejas y en el razonamiento multisalto, formular y ejecutar consultas complejas que aprovechen estas capacidades puede ser difícil. El desarrollo de algoritmos eficientes de procesamiento de consultas y razonamiento es un ámbito de investigación activo. Comprender las capacidades de lenguaje de consulta y razonamiento del sistema de grafos de conocimiento es importante para utilizar eficazmente todo su potencial.
Faltan estándares ampliamente adoptados para representar y consultar grafos de conocimiento, lo que puede causar problemas de interoperabilidad y dependencia del proveedor. Los distintos sistemas de grafos de conocimiento pueden utilizar distintos modelos de datos, lenguajes de consulta y API, lo que dificulta el cambio de uno a otro o la integración con otros sistemas. Adoptar o desarrollar estándares puede facilitar la interoperabilidad y reducir la dependencia del proveedor.
Aunque los grafos de conocimiento pueden proporcionar un razonamiento explicable y transparente, garantizar que el proceso de razonamiento sea fácilmente interpretable y comprensible para los usuarios finales puede ser un reto, sobre todo en el caso de consultas o rutas de razonamiento complejas. Desarrollar interfaces fáciles de usar y explicaciones que comuniquen claramente el proceso de razonamiento y sus suposiciones subyacentes es importante para la confianza y la adopción por parte del usuario.
Según el dominio y la aplicación, puede haber retos adicionales específicos de ese dominio, como manejar terminología, ontologías o formatos de datos específicos del dominio. Por ejemplo, en el dominio médico, tratar con terminologías médicas complejas, sistemas de codificación y cuestiones de privacidad puede añadir capas de complejidad a la configuración y el uso del grafo de conocimiento.
A pesar de estos retos, los grafos de conocimiento ofrecen ventajas significativas a las aplicaciones RAG, sobre todo en cuanto a representación de conocimiento estructurado, razonamiento complejo y resultados explicables y transparentes. Abordar estos retos mediante un cuidadoso diseño de grafos de conocimiento, estrategias de integración de datos y técnicas eficientes de procesamiento de consultas es crucial para implementar aplicaciones RAG basadas en grafos de conocimiento.
En este tutorial, hemos explorado el poder de los grafos de conocimiento para crear respuestas más exactas, informativas y contextualmente pertinentes. Empezamos por comprender los conceptos fundamentales de los grafos de conocimiento y su papel en las aplicaciones RAG. A continuación, en un ejemplo práctico, extrajimos un grafo de conocimiento de datos de texto, lo almacenamos en una base de datos Neo4j y lo utilizamos para recuperar contexto pertinente para las consultas de los usuarios. Por último, demostramos cómo utilizar el contexto recuperado para generar respuestas utilizando el conocimiento estructurado del grafo.
Si quieres saber más sobre IA y LLM, echa un vistazo a este programa de seis cursos sobre Fundamentos de la IA.
Espero que este tutorial te resulte útil y divertido. Nos vemos en el próximo.
¡Feliz programación!
Más información sobre la IA y los LLM
programa
Curso
Curso
Tutorial
Ryan Ong
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Zoumana Keita

