
Lernpfad
Grundlagen der KI
10 Std.
OpenAI hat vor kurzem Modelle mit offener Gewichtung rausgebracht, die für leistungsstarkes Denken, agentenbasierte Aufgaben und verschiedene Anwendungsfälle für Entwickler gedacht sind. Diese Modelle gibt's in zwei Varianten: gpt-oss-120b und gpt-oss-20b. Das kleinere Modell kann lokal auf Consumer-GPUs laufen, während„ “ gpt-oss-120b 80 GB VRAM und eine leistungsstärkere Computerausstattung braucht, die viele Nutzer vielleicht nicht haben.
Um dir zu helfen, habe ich eine Liste mit kostenlosen und einfachen Möglichkeiten zusammengestellt, wie du auf das größere Modell zugreifen kannst. Du kannst das Modell lokal mit Ollama, Transformers oder dem vLLM-Framework ausführen. Es gibt auch kostenlose Chat-Apps, wo du das Modell ausprobieren kannst, sowie viele schnelle und kostenlose Anbieter für die Inferenz großer Sprachmodelle (LLM), die du testen kannst. Außerdem kannst du auf dem LLM-Marktplatz nach den besten Optionen für deinen Anwendungsfall suchen. Schau dir unseren separaten Leitfaden an, , wie du GPT-OSS lokal mit Ollama einrichten und ausführen kannst.
OpenAI GPT-OSS ist eine offene Modellreihe, die du auf jeden Rechner runterladen und nutzen kannst. Du kannst es auch lokal zum Erstellen von Anwendungen und Projekten verwenden. Dieses Modell kann sowohl kommerziell als auch unter einer Open-Source-Lizenz genutzt werden.
In diesem Teil zeigen wir dir, wie du das große Modell GPT-OSS-120B auf normaler Hardware laufen lassen kannst.
Mit Ollama brauchst du nicht unbedingt eine GPU; du kannst das Modell komplett auf deiner CPU und deinem RAM ausführen. Ohne GPU-Beschleunigung dauert die Token-Generierung allerdings deutlich länger.
Wenn du mehrere GPUs hast, kannst du ein paar Modellschichten auf die GPU auslagern, was die Generierungsgeschwindigkeit echt verbessert. Für die richtige Einrichtung braucht man ein bisschen technisches Wissen und muss ein paar Einstellungen machen.
Quelle: gpt-oss
Installiere Ollama auf Linux, um loszulegen.
curl -fsSL https://ollama.com/install.sh | sh Dann mach den folgenden Befehl, um das gpt-oss-120b .
ollama run gpt-oss:120bSo einfach ist das.
Mit der Transformers-Bibliothek kannst du das Modell runterladen und laden, Inferenz ausführen, das Modell optimieren und direkt in deine Anwendung integrieren.
Für Modelle mit 120 Milliarden Parametern musst du das Modell-Sharding über mehrere GPUs verteilen. Außerdem musst du vielleicht eine 8-Bit- oder 4-Bit-Quantisierung verwenden, damit das Modell in den Speicher passt.
Wenn dein VRAM immer noch nicht reicht, kannst du ein paar Ebenen auf die CPU auslagern. Dieser Prozess braucht mehr Erfahrung und technisches Wissen, aber wenn du die notwendigen Schritte kennst, ist das machbar.
Quelle: openai/gpt-oss-120b
Installier die benötigten Pakete:
pip install -U transformers kernels torchHier ein Beispiel für die Verwendung: Mach die Pipeline für die Textgenerierung klar, gib ihr eine Eingabeaufforderung und starte sie, um eine Antwort zu generieren.
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-120b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "What is the best DataCamp course to learn AI?"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])vLLM ist eine leistungsstarke Inferenz-Engine, die speziell für die schnelle und effiziente Textgenerierung entwickelt wurde und sich daher super für den Einsatz in der Produktion eignet.
Es kann auf verschiedene Arten eingesetzt werden: auf deinem lokalen Server für Entwicklung und Tests, in einer privaten Cloud für den internen Gebrauch im Unternehmen oder in kleinen Unternehmen und Start-ups, die mehr Kontrolle und Datenschutz wollen, ohne auf externe APIs angewiesen zu sein.
Quelle: GPT OSS – vLLM-Rezepte
Verwende uv pip, um Python-Pakete schneller zu installieren.
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-matchMach den folgenden Befehl in deinem Terminal ab, um das Modell runterzuladen und den vLLM-Server zu starten:
vllm serve openai/gpt-oss-120bSobald vLLM läuft, startet es einen lokalen API-Server (Standard: http://localhost:8000), den du über HTTP-Anfragen abfragen und direkt in deine Anwendungen integrieren kannst.
Mit KI-Chat-Apps kannst du verschiedene Modelle ausprobieren, ohne irgendwas einrichten zu müssen. Du musst nur die URL aufrufen und dich anmelden. Du kannst die Funktionen dieser Apps nutzen.
In diesem Abschnitt schauen wir uns den offiziellen Chat und die T3-Chat-App an, die beide kostenlosen Zugang zu den neuen OpenAI GPT-OSS-Modellen bieten.
Gpt-oss ist die offizielle Website, auf der du beide Open-Source-Modelle von OpenAI ausprobieren kannst. Es wurde zusammen mit Hugging Face entwickelt, also musst du dich mit deinem Hugging Face-Konto anmelden, um alle Funktionen der Modelle nutzen zu können.

Quelle: Gpt-oss
Die App ist komplett kostenlos und du kannst so viel chatten, wie du willst. Du kannst mit verschiedenen Argumentationsebenen experimentieren, zwischen Modi wechseln und sogar eine komplette Webanwendung von Grund auf erstellen lassen. Es ist superschnell und du musst nichts einrichten.
Ich liebe den T3 Chat, seit ich ihn entdeckt habe. Es bietet superschnellen Zugriff auf Open-Source- und proprietäre Modelle. Stell dir das wie eine ChatGPT-App vor, aber für alle Arten von KI-Modellen, einschließlich Bildgenerierung, Bildverarbeitungsmodellen und großen Sprachmodellen.
Im Moment kannst du bei T3 Chat sowohl GPT-OSS 20B als auch GPT-OSS 120B kostenlos nutzen. Du musst dich nur anmelden und schon kannst du alle Funktionen dieser Models nutzen.

Quelle: t3.chat
Das Beste daran? Die übersichtliche, intuitive Benutzeroberfläche und die ansprechende Darstellung der generierten Ergebnisse.
Inferenzanbieter hosten große Sprachmodelle auf ihren eigenen Servern und geben Nutzern API- oder Webzugriff, sodass sie diese Modelle direkt in ihre Anwendungen integrieren können, ohne einen Inferenzserver auf ihrer eigenen Infrastruktur betreiben zu müssen. So können Entwickler ganz einfach leistungsstarke Modelle nutzen, ohne sich um die Bereitstellung, Skalierung oder Wartung kümmern zu müssen.
In diesem Abschnitt schauen wir uns ein paar superschnelle und kostenlose Inferenzanbieter an, die du sofort nutzen kannst, um auf die 120B-Variante des GPT-OSS-Modells zuzugreifen.
Cerebras ist einer der schnellsten Anbieter von LLM-Inferenzlösungen weltweit und kann bis zu 1.400 Tokens pro Sekunde bei gleichzeitigen Anfragen liefern. Das macht es super für Echtzeit-KI-Systeme, wo es auf Schnelligkeit ankommt.
Allerdings gibt es ein paar Dinge zu beachten:
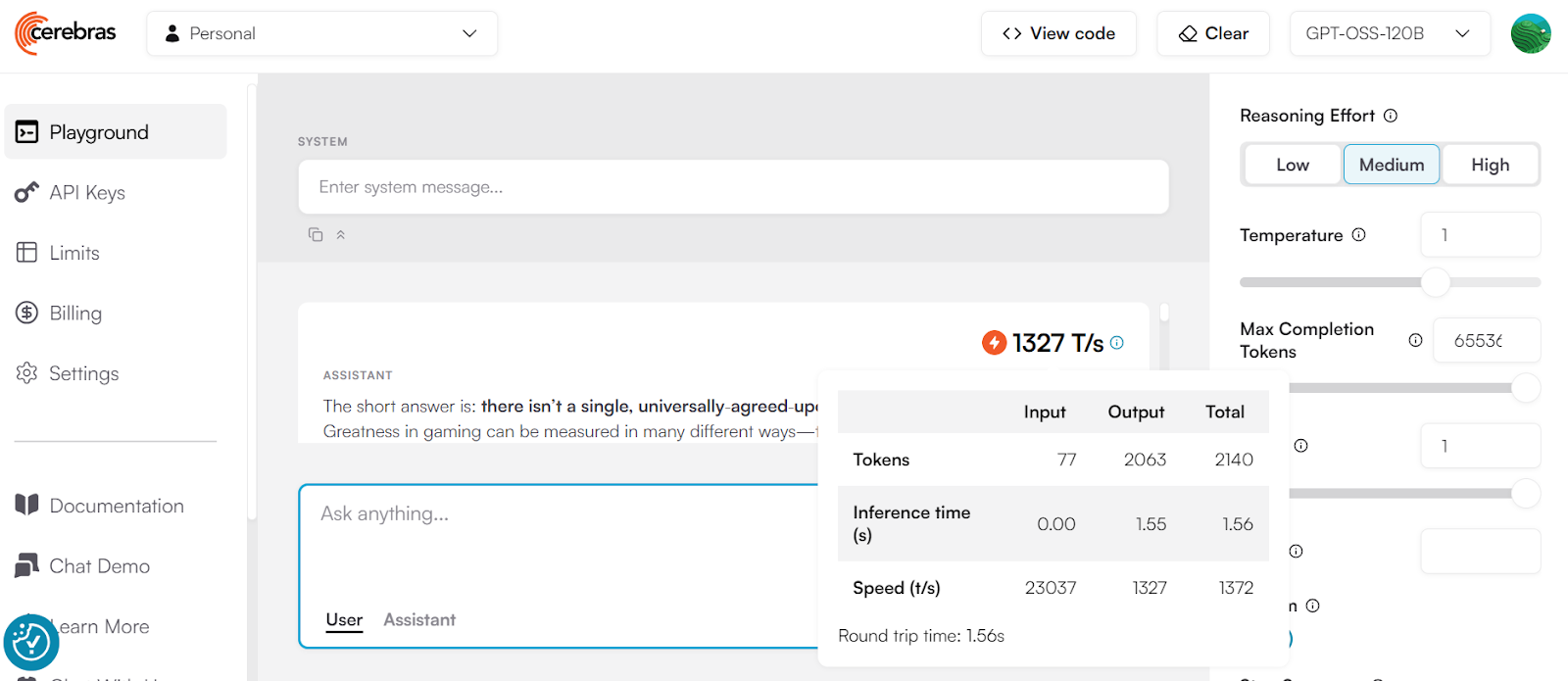
Quelle: cerebras.ai
Cerebras ist nicht mit dem OpenAI SDK kompatibel, du musst also das eigene SDK installieren:
pip install --upgrade cerebras_cloud_sdkDanach machst du den Client mit dem API-Schlüssel, erstellst die Chat-Abschlussfunktion und generierst die Antwort als Stream.
import os
from cerebras.cloud.sdk import Cerebras
client = Cerebras(
# This is the default and can be omitted
api_key=os.environ.get("CEREBRAS_API_KEY")
)
stream = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "Who was Leonardo Da Vinci?"
}
],
model="gpt-oss-120b",
stream=True,
max_completion_tokens=65536,
temperature=1,
top_p=1,
reasoning_effort="high"
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")Ich bin ein großer Fan von Groq, weil sie schnelle und bezahlbare Inferenz-Endpunkte für beliebte Open-Source-Modelle anbieten. Im Moment kannst du die 120B-Version von OpenAI's GPT-OSS kostenlos nutzen, allerdings mit einer begrenzten Anzahl an Anfragen.
Du kannst das Modell direkt in Groq Studio ausprobieren, bevor du es in deine Anwendungen integrierst. So kannst du ganz einfach experimentieren und deine Eingabeaufforderungen optimieren.
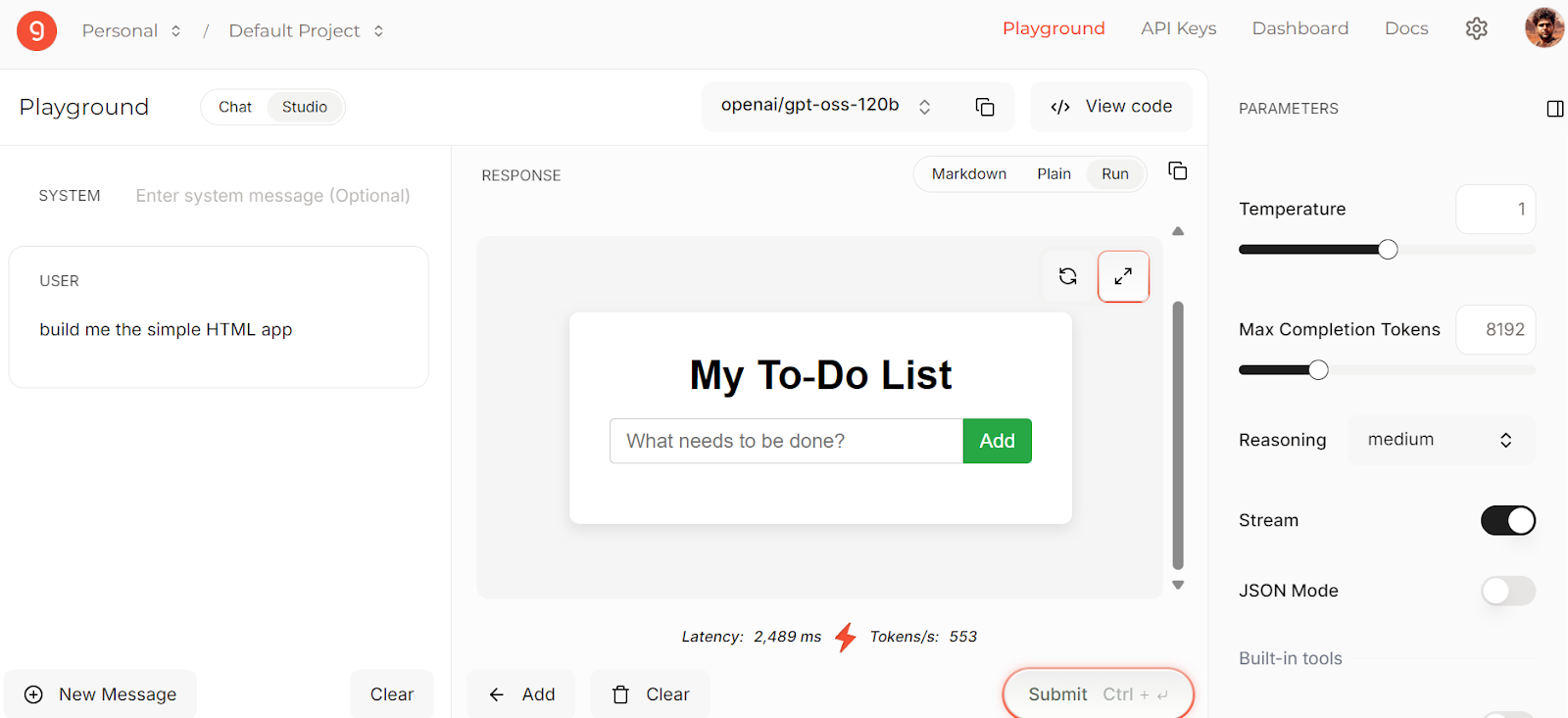
Quelle: Groq
Groq ist mit OpenAI kompatibel, was bedeutet, dass du das OpenAI Python SDK verwenden kannst, um auf ihre Modelle zuzugreifen. Groq hat aber auch ein eigenes optimiertes SDK, das besser auf ihre Infrastruktur abgestimmt ist, und das werden wir hier verwenden.
Installier das Groq SDK:
pip install groqErstell den Groq-Client mit dem API-Schlüssel und dann die Chat-Vervollständigungen mit dem Modellnamen und anderen Argumenten, um die Antwort zu streamen.
from groq import Groq
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "user",
"content": "What is the meaning of life?"
}
],
temperature=1,
max_completion_tokens=8192,
top_p=1,
reasoning_effort="medium",
stream=True,
stop=None
)
for chunk in completion:
print(chunk.choices[0].delta.content or "", end="")Baseten ist eine leistungsstarke Plattform für Inferenz und Training, die entwickelt wurde, um KI-Modelle mit voller Kontrolle einzusetzen, zu skalieren und zu verwalten. Das Beste daran ist, dass es in Sachen Token-Generierungsgeschwindigkeit mit Groq und Cerebras mithalten kann.
Wenn du dich anmeldest, bekommst du 5 $ Guthaben für die Bereitstellung und 1 $ für den API-Zugang. Mit dem Geld kannst du die Dienste der Plattform nutzen.
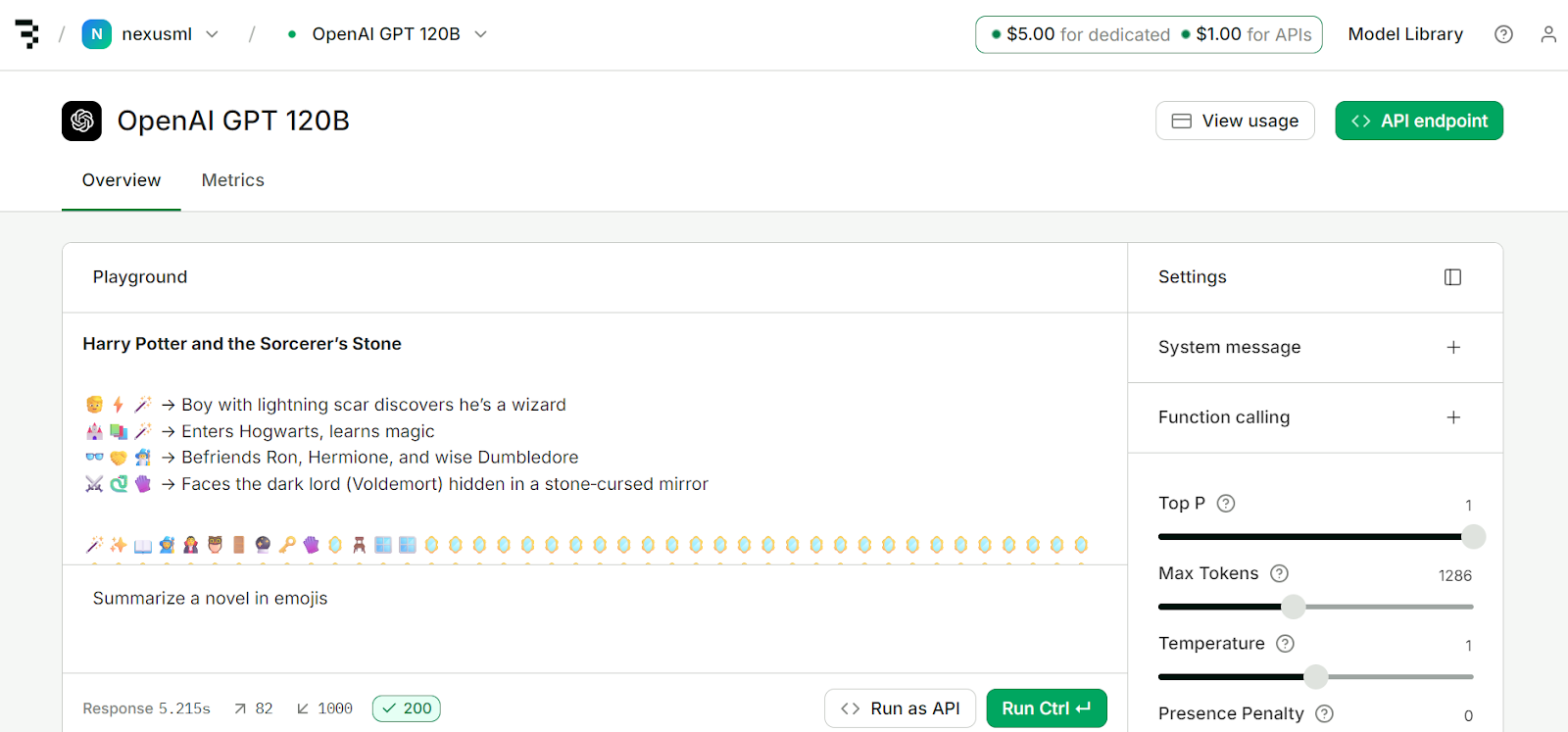
Quelle: Modell-API | Baseten
Baseten ist mit OpenAI kompatibel und hat kein eigenes SDK, also werden wir das OpenAI Python SDK benutzen, um auf den Modell-Endpunkt zuzugreifen. Dazu musst du das OpenAI Python-Paket installieren:
pip install openaiErstell dann den Client mit deinem API-Schlüssel und der Basis-URL. Danach kannst du Chat-Vervollständigungen erstellen, indem du den Modellnamen und andere Parameter angibst. Zum Schluss kannst du gestreamte Antworten machen.
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("BASETEN_API_KEY"),
base_url="https://inference.baseten.co/v1"
)
response = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "user",
"content": "Implement Hello World in Python"
}
],
stop=[],
stream=True,
stream_options={
"include_usage": True,
"continuous_usage_stats": True
},
top_p=1,
max_tokens=1286,
temperature=1,
presence_penalty=0,
frequency_penalty=0
)
for chunk in response:
if chunk.choices and chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
Auf dem LLM-Marktplatz kannst du auf offene und geschlossene große Sprachmodelle an einem Ort zugreifen. Alle Open-Source-Modelle werden auf OpenRouter gehostet, sodass du eine einheitliche API nutzen kannst, ohne dir Gedanken über Kosten, Verfügbarkeit oder Leistung machen zu müssen.
In diesem Abschnitt schauen wir uns zwei der beliebtesten LLM-Marktplätze an: OpenRouter und Requesty. Beide Plattformen bieten kostenlosen Zugriff auf das GPT-OSS 12B-Modell.
OpenRouter bietet eine einheitliche API, mit der du über einen einzigen Endpunkt auf Hunderte von KI-Modellen zugreifen kannst. Es kümmert sich automatisch um Fallbacks und wählt die günstigsten Optionen für deine Anfragen aus.
Du kannst mit verschiedenen Modellen im LLM Playground herumspielen, um die Ergebnisse zu testen und zu vergleichen, bevor du sie in deinen Arbeitsablauf integrierst.
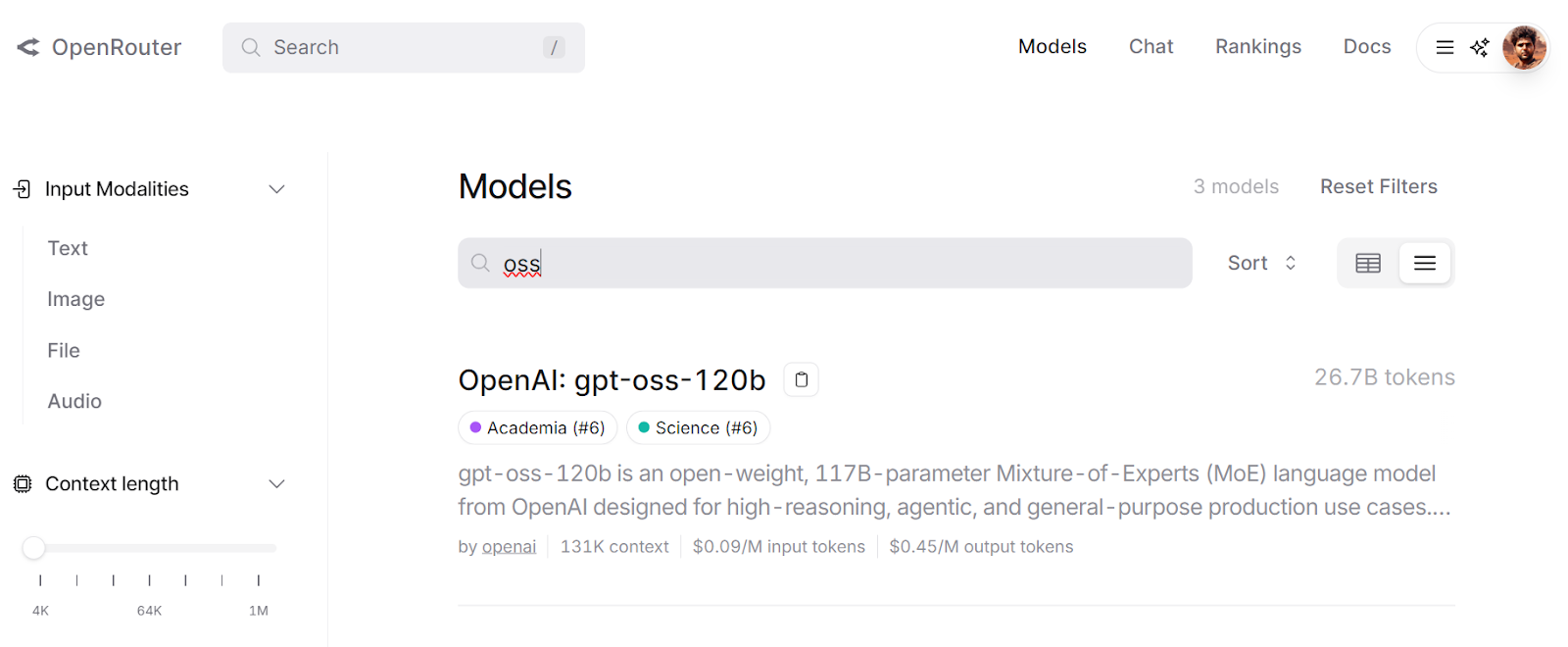
Quelle: gpt-oss-120b
OpenRouter ist ganz einfach zu integrieren: . Du musst nur die Basis-URL ändern und deinen API-Schlüssel eingeben. Der Rest der Implementierung bleibt wie bei der OpenAI-API.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What is the meaning of life?"}],
)
print(completion.choices[0].message.content)Requesty ist ähnlich wie OpenRouter, leitet deine Anfragen aber clever über mehr als 170 KI-Modelle, darunter GPT-OSS 120B. Das hilft dir:
Im Chat-Menü kannst du Modelle erkunden, die Rangliste checken, dein Nutzungs-Dashboard ansehen und direkte Integrationen hinzufügen.
Wenn du dich anmeldest, bekommst du 1 $ Gratis-Guthaben, mit dem du sogar kostenpflichtige Models ausprobieren kannst.

Quelle: Anfrage
Um Requesty einzubinden, musst du nur die Basis-URL, den API-Schlüssel und die Standard-Header in deinem OpenAI Python SDK-Code anpassen.
Wenn du ein kostenloses Modell verwenden möchtest, wähl unbedingt eines von Groq aus.
import os
import openai
ROUTER_API_KEY = os.getenv("REQUESTY_API_KEY")
client = openai.OpenAI(
api_key=ROUTER_API_KEY,
base_url="https://router.requesty.ai/v1",
default_headers={"Authorization": f"Bearer {ROUTER_API_KEY}"},
)
# Example request
response = client.chat.completions.create(
model="groq/openai/gpt-oss-120b",
messages=[{"role": "user", "content": "Hello, who are you?"}],
)
# Print the result
print(response.choices[0].message.content)Nach langem Warten hat OpenAI endlich ein Open-Source-LLM veröffentlicht. Das heißt, du kannst es jetzt feinabstimmen, lokal ausführen und hast die volle Kontrolle über die Ausgabe. Du hast die Kontrolle; du kannst sogar Produkte darauf aufbauen, ohne deine Daten mit OpenAI zu teilen oder für den API-Zugang zu bezahlen.
Das ist ein großer Schritt für die KI, und mit der Zeit werden wir neue und bessere Modelle sehen, die auf den Open-Source-Modellen und Frameworks von OpenAI aufbauen. Wenn du gleich loslegen willst, kannst du Folgendes tun:
Wenn du gerade erst mit KI anfängst, solltest du dir unbedingt unseren Lernpfad „Grundlagen der KI“ , der Themen wie LLMs, ChatGPT, generative KI, KI-Ethik und Prompt Engineering behandelt.
Die besten KI-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Matt Crabtree
