
Cursus
Principes fondamentaux de l'IA
10 h
OpenAI a récemment publié des modèles à poids ouvert conçus pour un raisonnement puissant, des tâches agentique et des cas d'utilisation polyvalents pour les développeurs. Ces modèles sont disponibles en deux variantes : gpt-oss-120b et gpt-oss-20b. Le modèle plus petit peut être exécuté localement sur des cartes graphiques grand public, tandis que l'exécutionde gpt-oss-120b nécessite 80 Go de mémoire vidéo et une configuration informatique plus robuste, dont de nombreux utilisateurs ne disposent pas.
Pour vous aider, j'ai dressé une liste de moyens gratuits et faciles d'accéder au modèle complet. Vous pouvez exécuter le modèle localement à l'aide d'Ollama, de Transformers ou du framework vLLM. Il existe également des applications de chat gratuites qui vous permettent de tester le modèle, ainsi que de nombreux fournisseurs d'inférence rapide et gratuite pour les modèles linguistiques de grande taille (LLM) que vous pouvez essayer. De plus, vous pouvez visiter la place de marché LLM afin de trouver les options les mieux adaptées à votre cas d'utilisation. Veuillez consulter notre guide séparé sur la comment configurer et exécuter GPT-OSS localement avec Ollama.
OpenAI GPT-OSS est une série de modèles ouverts permettant aux utilisateurs de les télécharger et de les exécuter sur n'importe quel système. Vous pouvez également l'utiliser localement pour développer des applications et créer des projets. Ce modèle est disponible pour une utilisation commerciale et open source.
Dans cette partie, nous allons découvrir comment exécuter le modèle GPT-OSS-120B sur du matériel grand public.
Avec Ollama, il n'est pas nécessaire de disposer d'un GPU ; vous pouvez exécuter le modèle entièrement sur votre CPU et votre RAM. Cependant, la génération de jetons sera considérablement ralentie sans l'accélération GPU.
Si vous disposez d'une configuration à plusieurs GPU, vous pouvez décharger certaines couches du modèle vers le GPU, ce qui améliorera considérablement la vitesse de génération. Cela nécessite certaines connaissances techniques et une configuration pour être correctement mis en place.
Source : gpt-oss
Pour commencer, veuillez installer Ollama sur Linux.
curl -fsSL https://ollama.com/install.sh | sh Ensuite, exécutez la commande suivante pour télécharger et exécuter le fichier gpt-oss-120b .
ollama run gpt-oss:120bC'est aussi simple que cela.
Grâce à la bibliothèque Transformers, vous pouvez télécharger et charger le modèle, exécuter l'inférence, affiner le modèle et l'intégrer directement dans votre application.
Pour les modèles comportant 120 milliards de paramètres, il sera nécessaire de mettre en œuvre le partitionnement du modèle sur plusieurs GPU. De plus, il peut être nécessaire d'utiliser une quantification 8 bits ou 4 bits pour adapter le modèle à la mémoire.
Si votre mémoire VRAM reste insuffisante, vous pouvez transférer certaines couches vers le processeur. Ce processus nécessite davantage d'expérience et de connaissances techniques, mais si vous maîtrisez les étapes nécessaires, il est tout à fait réalisable.
Source : openai/gpt-oss-120b
Veuillez installer les paquets nécessaires :
pip install -U transformers kernels torchVoici un exemple d'utilisation : Créez le pipeline de génération de texte, fournissez-lui une invite, puis exécutez le pipeline pour générer une réponse.
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-120b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "What is the best DataCamp course to learn AI?"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])vLLM est un moteur d'inférence haute performance spécialement conçu pour la génération rapide et à haut débit de texte, ce qui le rend idéal pour les déploiements à l'échelle industrielle.
Il peut être déployé de plusieurs façons : sur votre serveur local pour le développement et les tests, sur un cloud privé à usage interne, ou dans les petites entreprises et les startups qui recherchent un meilleur contrôle et une plus grande confidentialité des données sans dépendre d'API externes.
Source : GPT OSS - Recettes vLLM
Veuillez utiliser uv pip pour une installation plus rapide des paquets Python.
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-matchVeuillez exécuter la commande suivante dans votre terminal pour télécharger le modèle et lancer le serveur vLLM :
vllm serve openai/gpt-oss-120bUne fois lancé, vLLM démarre un serveur API local (par défaut : http://localhost:8000) que vous pouvez interroger via des requêtes HTTP et intégrer directement dans vos applications.
Les applications de chat IA vous permettent d'essayer différents modèles sans aucune configuration requise. Il vous suffit de vous rendre sur l'URL et de vous inscrire. Vous pouvez profiter des fonctionnalités offertes par ces applications.
Dans cette section, nous explorerons le chat officiel et l'application de chat T3, qui offrent tous deux un accès gratuit aux nouveaux modèles OpenAI GPT-OSS.
Gpt-oss est le site officiel de site web officiel sur lequel vous pouvez tester les deux modèles open source d'OpenAI. Il a été créé en collaboration avec Hugging Face. Vous devrez donc vous connecter à votre compte Hugging Face pour débloquer toutes les fonctionnalités des modèles.

Source : Gpt-oss
L'application est entièrement gratuite et offre un nombre illimité de résultats de chat. Vous pouvez tester différents niveaux de raisonnement, passer d'un mode à l'autre et même lui demander de créer une application web complète à partir de zéro. Il est extrêmement rapide et ne nécessite aucune configuration.
J'apprécie beaucoup T3 Chat depuis que je l'ai découvert. Il offre un accès ultra-rapide à des modèles open source et propriétaires. Considérez-le comme une application de type ChatGPT, mais pour tous les types de modèles d'IA, y compris la génération d'images, les modèles de langage visuel et les grands modèles linguistiques.
Actuellement, T3 Chat offre un accès gratuit à GPT-OSS 20B et GPT-OSS 120B. Il vous suffit de vous inscrire et de commencer à profiter d'un accès complet à ces modèles.

Source : t3.chat
Le plus intéressant ? Son interface utilisateur claire et intuitive, ainsi que la manière dont les résultats générés sont présentés de manière élégante.
Les fournisseurs d'inférence hébergent de grands modèles linguistiques sur leurs propres serveurs et fournissent aux utilisateurs un accès API ou Web, leur permettant d'intégrer ces modèles directement dans leurs applications sans avoir à exécuter un serveur d'inférence sur leur propre infrastructure. Cela permet aux développeurs d'utiliser facilement des modèles performants sans se soucier du déploiement, de la mise à l'échelle ou de la maintenance.
Dans cette section, nous examinerons quelques fournisseurs d'inférence ultra-rapides et gratuits que vous pouvez utiliser dès maintenant pour accéder à la variante 120B du modèle GPT-OSS.
Cerebras est l'un des fournisseurs d'inférence LLM les plus rapides au monde, capable de fournir jusqu'à 1 400 jetons par seconde avec des requêtes simultanées. Cela en fait un excellent choix pour la création de systèmes d'IA en temps réel où la vitesse est essentielle.
Cependant, il convient de prendre en compte certains éléments :
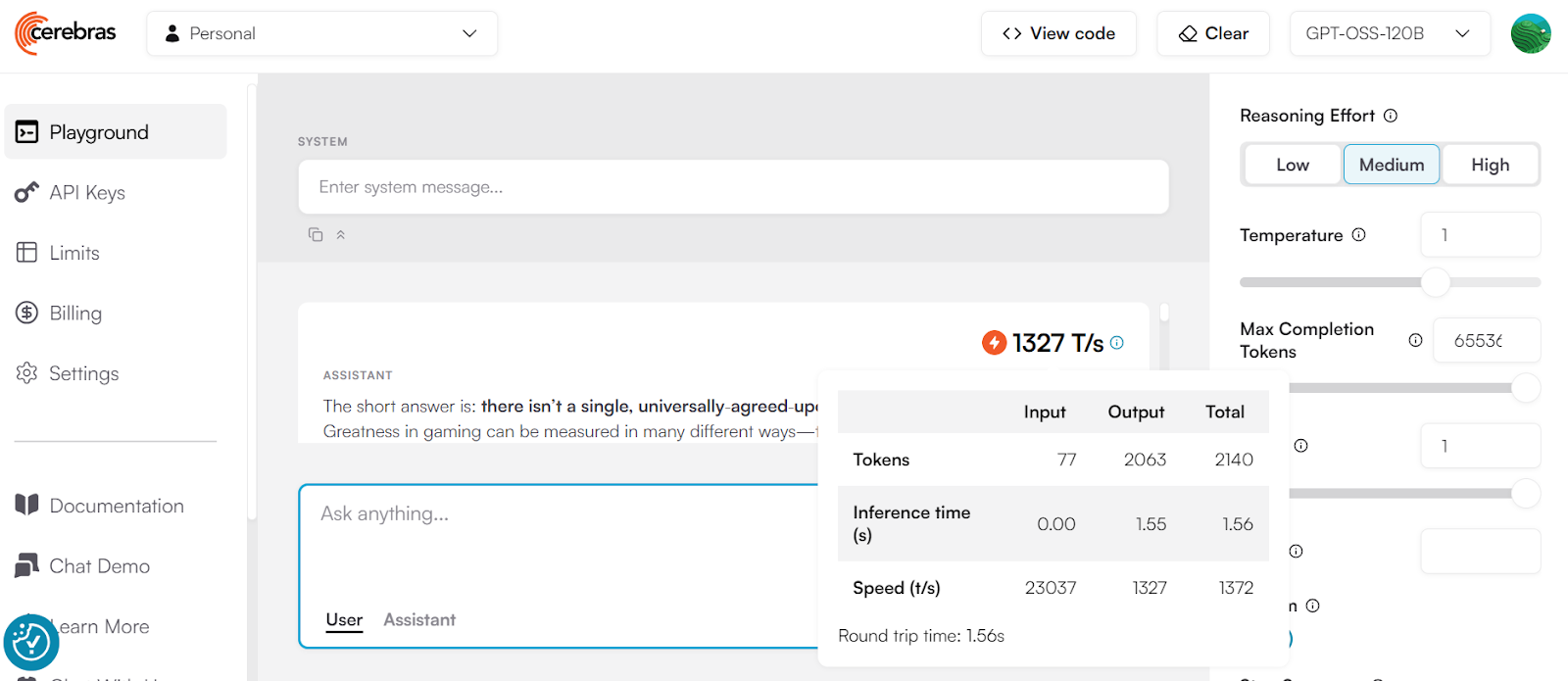
Source : cerebras.ai
Cerebras n'est pas compatible avec le SDK OpenAI. Vous devrez donc installer leur propre SDK :
pip install --upgrade cerebras_cloud_sdkEnsuite, veuillez créer le client à l'aide de la clé API, créer la fonction de complétion du chat, puis générer la réponse sous forme de flux.
import os
from cerebras.cloud.sdk import Cerebras
client = Cerebras(
# This is the default and can be omitted
api_key=os.environ.get("CEREBRAS_API_KEY")
)
stream = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "Who was Leonardo Da Vinci?"
}
],
model="gpt-oss-120b",
stream=True,
max_completion_tokens=65536,
temperature=1,
top_p=1,
reasoning_effort="high"
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")Je suis un grand admirateur de Groq car ils fournissent des points de terminaison d'inférence rapides et abordables pour les modèles open source populaires. Actuellement, vous pouvez accéder gratuitement à la variante 120B du GPT-OSS d'OpenAI, mais avec un nombre de requêtes limité.
Vous pouvez tester le modèle directement dans Groq Studio avant de l'intégrer à vos applications, ce qui vous permet d'expérimenter et d'affiner facilement vos invites.
Source : Groq
Groq est compatible avec OpenAI, ce qui signifie que vous pouvez utiliser le SDK Python OpenAI pour accéder à leurs modèles. Cependant, Groq propose également son propre SDK optimisé, mieux adapté à son infrastructure, et c'est celui que nous utiliserons ici.
Veuillez installer le SDK Groq :
pip install groqVeuillez créer le client Groq à l'aide de la clé API, puis créez les complétions de chat à l'aide du nom du modèle et d'autres arguments pour diffuser la réponse.
from groq import Groq
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "user",
"content": "What is the meaning of life?"
}
],
temperature=1,
max_completion_tokens=8192,
top_p=1,
reasoning_effort="medium",
stream=True,
stop=None
)
for chunk in completion:
print(chunk.choices[0].delta.content or "", end="")Baseten est une plateforme d'inférence et de formation performante conçue pour déployer, faire évoluer et gérer des modèles d'IA avec un contrôle total. Le plus remarquable est qu'il est comparable à Groq et Cerebras en termes de vitesse de génération de jetons.
Lors de votre inscription, vous recevez 5 $ de crédit de déploiement et 1 $ pour l'accès à l'API. Vous pouvez utiliser cet argent pour accéder aux services de la plateforme.
Source : API du modèle | Baseten
Baseten est compatible avec OpenAI et ne dispose pas de son propre SDK. Nous utiliserons donc le SDK Python OpenAI pour accéder au point de terminaison du modèle. Pour ce faire, vous devez installer le paquet Python OpenAI :
pip install openaiEnsuite, veuillez créer le client à l'aide de votre clé API et de l'URL de base. Ensuite, vous pouvez créer des compléments de conversation en spécifiant le nom du modèle et d'autres paramètres. Enfin, vous pouvez générer des réponses en continu.
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("BASETEN_API_KEY"),
base_url="https://inference.baseten.co/v1"
)
response = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "user",
"content": "Implement Hello World in Python"
}
],
stop=[],
stream=True,
stream_options={
"include_usage": True,
"continuous_usage_stats": True
},
top_p=1,
max_tokens=1286,
temperature=1,
presence_penalty=0,
frequency_penalty=0
)
for chunk in response:
if chunk.choices and chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
La place de marché LLM vous permet d'accéder à des modèles linguistiques volumineux, open source et propriétaires, à partir d'un seul et même endroit. Tous les modèles open source sont hébergés sur OpenRouter, ce qui vous permet d'utiliser une API unifiée sans vous soucier du coût, de la disponibilité ou des performances.
Dans cette section, nous examinerons deux des places de marché LLM les plus populaires, OpenRouter et Requesty. Les deux plateformes offrent un accès gratuit au modèle GPT-OSS 12B.
OpenRouter fournit une API unifiée qui vous donne accès à des centaines de modèles d'IA via un seul point de terminaison. Il gère automatiquement les solutions de repli et sélectionne les options les plus rentables pour vos demandes.
Vous pouvez tester différents modèles à l'aide de leur LLM Playground, qui vous permet de tester et de comparer les résultats avant de les intégrer à votre flux de travail.
Source : gpt-oss-120b
L'intégration d'OpenRouter est simple : il suffit de modifier l'URL de base et de fournir votre clé API. Le reste de la mise en œuvre reste identique à celle de l'API OpenAI.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What is the meaning of life?"}],
)
print(completion.choices[0].message.content)Requesty est similaire à OpenRouter, mais il achemine intelligemment vos requêtes vers plus de 170 modèles d'IA, dont GPT-OSS 120B. Cela vous aide à :
Vous pouvez explorer les modèles dans le menu Chat, consulter le classement, afficher votre tableau de bord d'utilisation et ajouter des intégrations directes.
Lorsque vous vous inscrivez, vous recevez 1 $ de crédits gratuits, ce qui vous permet d'essayer même les modèles payants.

Source : Demande
Pour intégrer Requesty, veuillez mettre à jour l'URL de base, la clé API et les en-têtes par défaut dans votre code OpenAI Python SDK.
Si vous souhaitez utiliser un modèle gratuit, veuillez sélectionner ceux fournis par Groq.
import os
import openai
ROUTER_API_KEY = os.getenv("REQUESTY_API_KEY")
client = openai.OpenAI(
api_key=ROUTER_API_KEY,
base_url="https://router.requesty.ai/v1",
default_headers={"Authorization": f"Bearer {ROUTER_API_KEY}"},
)
# Example request
response = client.chat.completions.create(
model="groq/openai/gpt-oss-120b",
messages=[{"role": "user", "content": "Hello, who are you?"}],
)
# Print the result
print(response.choices[0].message.content)Après une longue attente, OpenAI a enfin publié un LLM open source. Cela signifie que vous pouvez désormais l'ajuster, l'exécuter localement et contrôler entièrement la génération de ses résultats. Vous êtes aux commandes ; vous pouvez même créer des produits autour de cette technologie sans partager vos données avec OpenAI ni payer pour accéder à l'API.
Il s'agit d'une avancée majeure pour l'IA. Au fil du temps, nous verrons apparaître de nouveaux modèles améliorés, basés sur les modèles et les frameworks open source d'OpenAI. Si vous souhaitez commencer à expérimenter dès maintenant, vous pouvez :
Si vous débutez dans le domaine de l'IA, nous vous invitons à consulter notre cursus sur les fondamentaux de l'IA qui couvre des sujets tels que les LLM, ChatGPT, l'IA générative, l'éthique de l'IA et l'ingénierie rapide.
Meilleures formations en IA
Cursus
Cours
Cours