
Track
AI Fundamentals
10 hr
OpenAI has recently released open-weight models designed for powerful reasoning, agentic tasks, and versatile developer use cases. These models come in two variants: gpt-oss-120b and gpt-oss-20b. The smaller model can be run locally on consumer GPUs, while running gpt-oss-120b requires 80GB of VRAM and a more robust computing setup, which many users may not have.
To help, I have compiled a list of free and easy ways to access the larger model. You can run the model locally using Ollama, Transformers, or the vLLM framework. There are also free chat applications where you can test the model, as well as numerous fast and free large language model (LLM) inference providers that you can try. Additionally, you can visit the LLM marketplace to find the best options suited to your use case. Check out our separate guide on how to set up and run GPT-OSS locally with Ollama.
OpenAI GPT-OSS is an open-weight model series that allows users to download and run it on any system. You can also use it locally to build applications and create projects. This model is available for both commercial and open-source use.
In this part, we will learn about running the large GPT-OSS-120B model on consumer hardware.
With Ollama, you don’t necessarily need a GPU; you can run the model entirely on your CPU and RAM. However, token generation will be significantly slower without GPU acceleration.
If you have a multiple-GPU setup, you can offload some model layers to the GPU, which will greatly improve generation speed. This does require some technical knowledge and configuration to set up properly.
Source: gpt-oss
To get started, install the Ollama on Linux.
curl -fsSL https://ollama.com/install.sh | sh Then, run the following command to download and run the gpt-oss-120b model.
ollama run gpt-oss:120bIt is that simple.
With the Transformers library, you can download and load the model, run inference, fine-tune the model, and integrate it directly into your application.
For models with 120 billion parameters, you will need to implement model sharding across multiple GPUs. Additionally, you may need to use 8-bit or 4-bit quantization to fit the model into memory.
If your VRAM is still insufficient, you can offload some layers to the CPU. This process requires more experience and technical knowledge, but if you are familiar with the necessary steps, it can be managed.
Source: openai/gpt-oss-120b
Install the necessary packages:
pip install -U transformers kernels torchHere is an example of usage: Create the text generation pipeline, provide it with a prompt, and then execute the pipeline to generate a response.
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-120b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "What is the best DataCamp course to learn AI?"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])vLLM is a high-performance inference engine specifically designed for fast and high-throughput text generation, making it perfect for production-level deployments.
It can be deployed in several ways: on your local server for development and testing, on a private cloud for internal company use, or in small companies and startups that seek greater control and data privacy without relying on external APIs.
Source: GPT OSS - vLLM Recipes
Use uv pip for faster installation of Python packages.
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-matchRun the following command in your terminal to download the model and launch the vLLM server:
vllm serve openai/gpt-oss-120bOnce running, vLLM will start a local API server (default: http://localhost:8000) that you can query via HTTP requests and Integrate directly into your applications.
AI chat applications allow you to try out different models without any setup required. All you need to do is visit the URL and sign up. You can enjoy the features offered by these applications.
In this section, we will explore official chat and the T3 chat application, both of which provide free access to the new OpenAI GPT-OSS models.
Gpt-oss is the official website where you can test both of OpenAI’s open-source models. It was created in collaboration with Hugging Face, so you will need to sign in with your Hugging Face account to unlock the full capabilities of the models.

Source: Gpt-oss
The app is completely free with unlimited chat results. You can experiment with different reasoning levels, switch between modes, and even ask it to build a complete web application from scratch. It’s super fast and requires no setup.
I have been loving T3 Chat ever since I discovered it. It provides lightning-fast access to both open-source and proprietary models. Think of it as a ChatGPT-style application, but for all kinds of AI models, including image generation, vision-language models, and large language models.
Currently, T3 Chat offers free-tier access to both GPT-OSS 20B and GPT-OSS 120B. All you need to do is sign up and start enjoying full functional access to these models.

Source: t3.chat
The best part? Its clean, intuitive UI and the way your generated results are beautifully displayed.
Inference providers host large language models on their own servers and give users API or web access, allowing them to integrate these models directly into their applications without having to run an inference server on their own infrastructure. This makes it easy for developers to use powerful models without worrying about deployment, scaling, or maintenance.
In this section, we will explore some super-fast and free inference providers that you can use right now to access the 120B variant of the GPT-OSS model.
Cerebras is one of the fastest LLM inference providers in the world, capable of delivering up to 1,400 tokens per second with concurrent requests. This makes it an excellent choice for building real-time AI systems where speed is critical.
However, there are a few considerations:
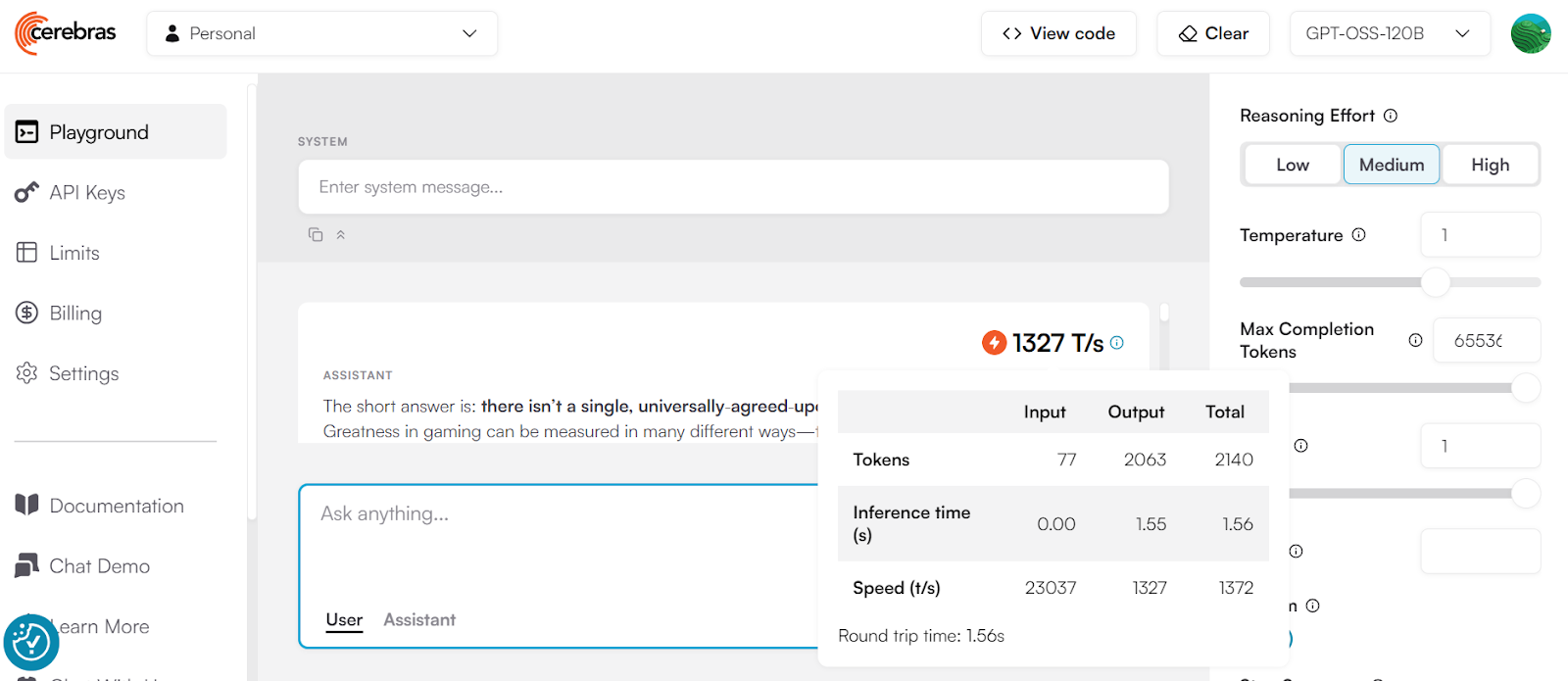
Source: cerebras.ai
Cerebras is not OpenAI SDK compatible, so you will need to install their own SDK:
pip install --upgrade cerebras_cloud_sdkAfter that, create the client using the API key, create the chat completion function, and then generate the response as a stream.
import os
from cerebras.cloud.sdk import Cerebras
client = Cerebras(
# This is the default and can be omitted
api_key=os.environ.get("CEREBRAS_API_KEY")
)
stream = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "Who was Leonardo Da Vinci?"
}
],
model="gpt-oss-120b",
stream=True,
max_completion_tokens=65536,
temperature=1,
top_p=1,
reasoning_effort="high"
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")I am a big fan of Groq because they provide fast and affordable inference endpoints for popular open-source models. Currently, you can access the 120B variant of OpenAI’s GPT-OSS for free, though with a limited request rate.
You can try the model directly in Groq Studio before integrating it into your applications, making it easy to experiment and fine-tune your prompts.
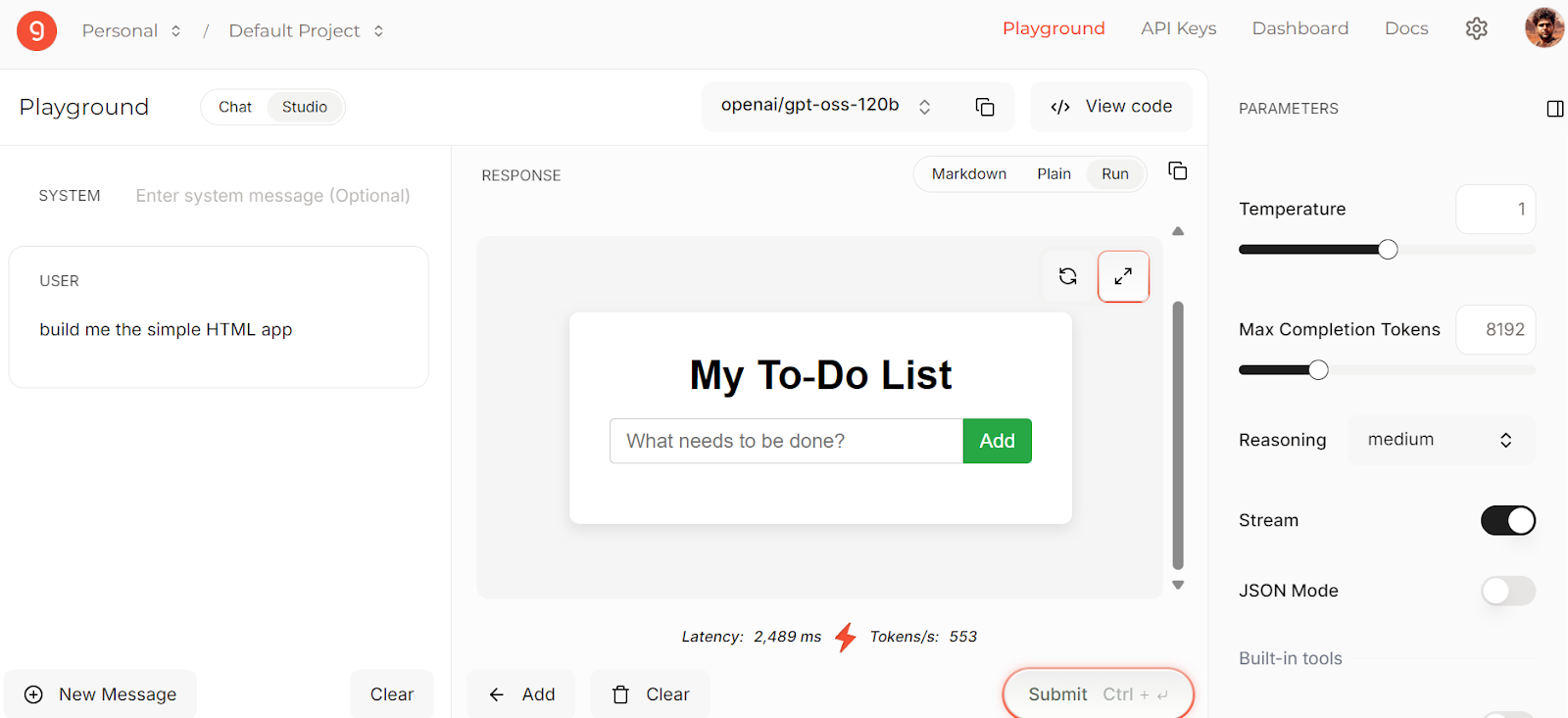
Source: Groq
Groq is OpenAI compatible, meaning you can use the OpenAI Python SDK to access their models. However, Groq also offers its own optimized SDK, which is better tuned for their infrastructure, and that’s what we will use here.
Install the Groq SDK:
pip install groqCreate the Groq client with the API key, and then create the chat completions using the model name and other arguments to stream the response.
from groq import Groq
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "user",
"content": "What is the meaning of life?"
}
],
temperature=1,
max_completion_tokens=8192,
top_p=1,
reasoning_effort="medium",
stream=True,
stop=None
)
for chunk in completion:
print(chunk.choices[0].delta.content or "", end="")Baseten is a powerful inference and training platform designed for deploying, scaling, and managing AI models with full control. The best part is that it is on par with Groq and Cerebras in terms of token generation speed.
When you sign up, you receive $5 of deployment credit and $1 for API access. You can use this money to access the platform's services.
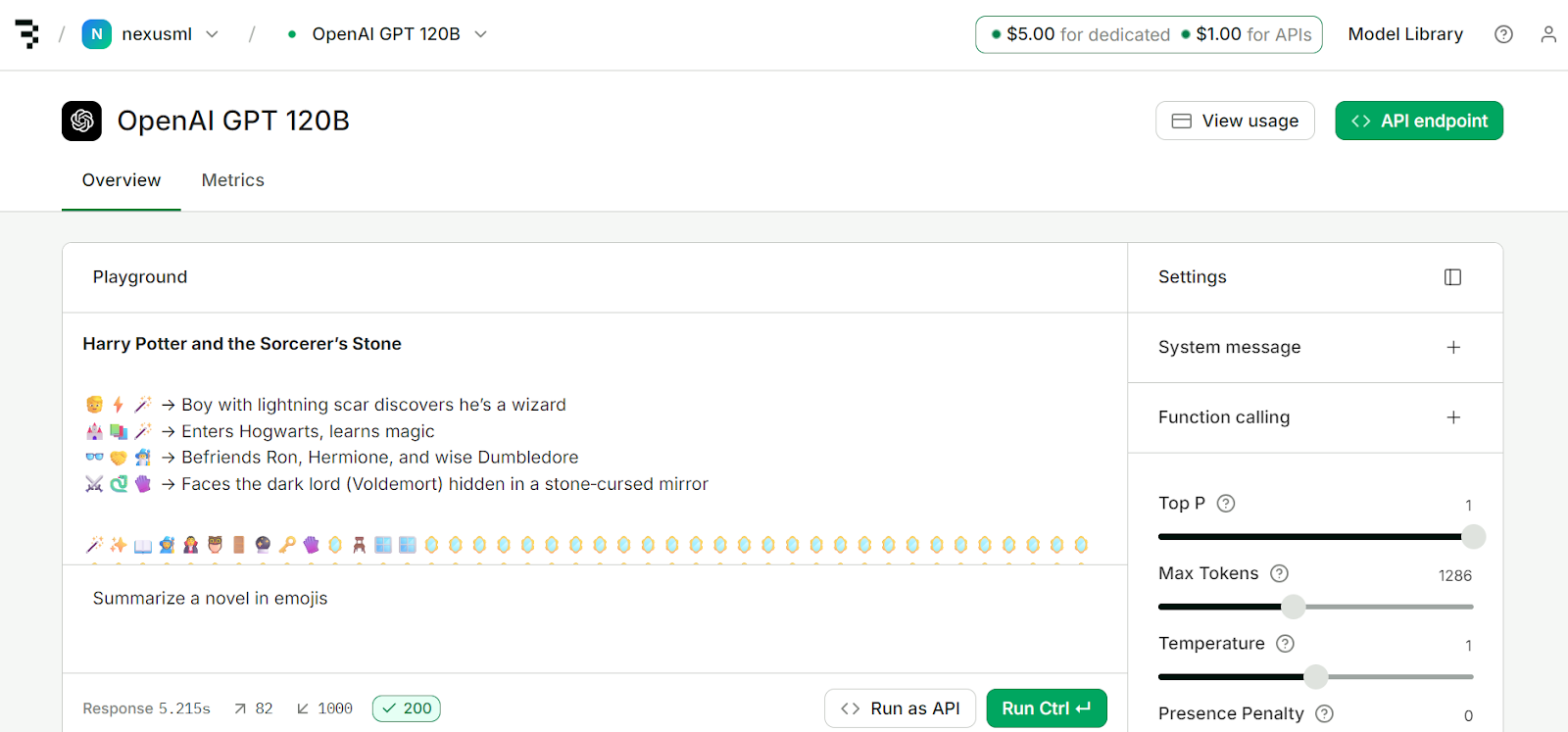
Source: Model API | Baseten
Baseten is compatible with OpenAI and does not have its own SDK, so we will be using the OpenAI Python SDK to access the model endpoint. To do this, you need to install the OpenAI Python package:
pip install openaiNext, create the client using your API key and base URL. After that, you can create chat completions by specifying the model name and other parameters. Finally, you can generate streamed responses.
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("BASETEN_API_KEY"),
base_url="https://inference.baseten.co/v1"
)
response = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{
"role": "user",
"content": "Implement Hello World in Python"
}
],
stop=[],
stream=True,
stream_options={
"include_usage": True,
"continuous_usage_stats": True
},
top_p=1,
max_tokens=1286,
temperature=1,
presence_penalty=0,
frequency_penalty=0
)
for chunk in response:
if chunk.choices and chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
The LLM marketplace allows you to access both open-source and closed-source large language models in one place. All open-source models are hosted on OpenRouter, enabling you to use a unified API without worrying about cost, availability, or performance.
In this section, we will review two of the most popular LLM marketplaces, OpenRouter and Requesty. Both platforms provide free access to the GPT-OSS 12B model.
OpenRouter provides a unified API that gives you access to hundreds of AI models through a single endpoint. It automatically handles fallbacks and selects the most cost‑effective options for your requests.
You can experiment with different models using their LLM Playground, which allows you to test and compare outputs before integrating them into your workflow.
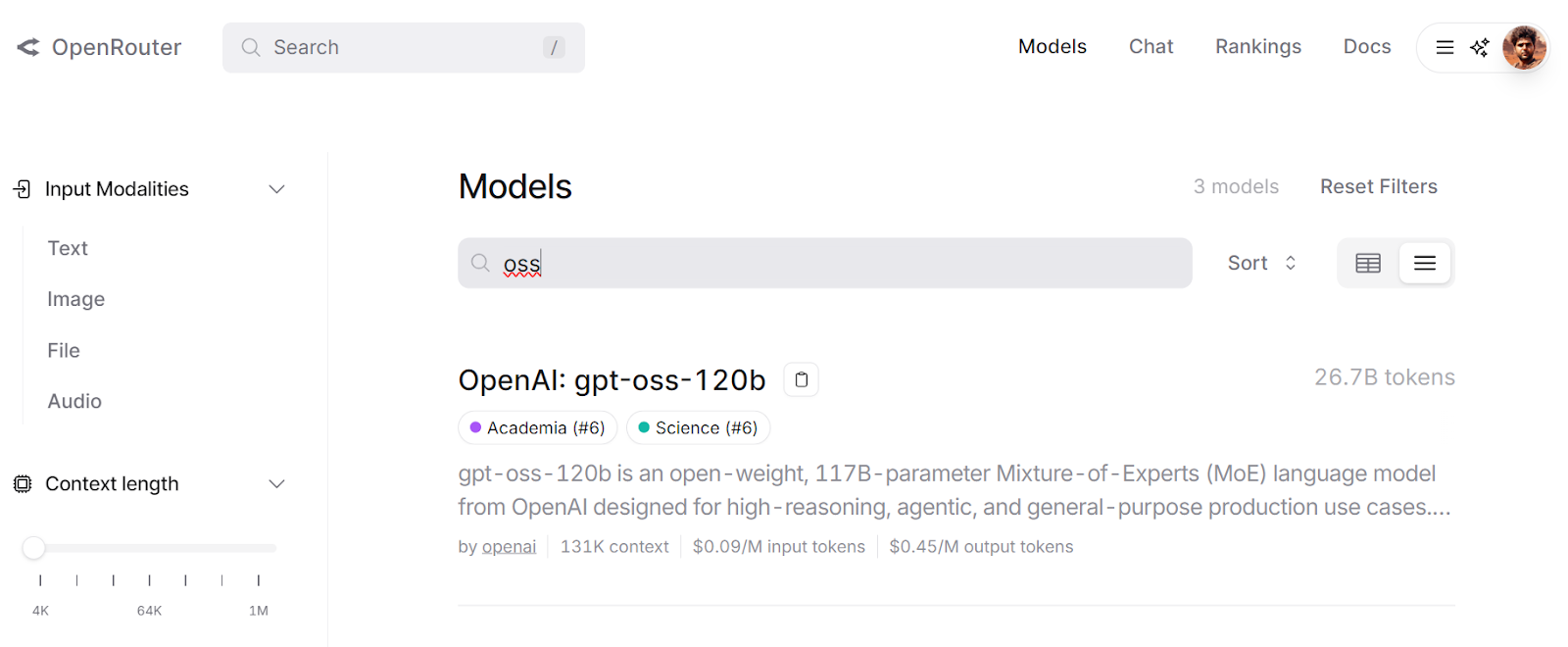
Source: gpt-oss-120b
Integrating OpenRouter is straightforward; simply change the base URL and provide your API key. The rest of the implementation remains the same as with the OpenAI API.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("OPENROUTER_API_KEY"),
)
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What is the meaning of life?"}],
)
print(completion.choices[0].message.content)Requesty is similar to OpenRouter, but it intelligently routes your requests across 170+ AI models, including GPT‑OSS 120B. This helps you:
You can explore models in the Chat menu, check the leaderboard, view your usage dashboard, and add direct integrations.
When you sign up, you receive $1 in free credits, allowing you to try even paid models.

Source: Requesty
To integrate Requesty, simply update the base URL, API key, and default headers in your OpenAI Python SDK code.
If you want to use a free model, make sure to select the ones provided by Groq.
import os
import openai
ROUTER_API_KEY = os.getenv("REQUESTY_API_KEY")
client = openai.OpenAI(
api_key=ROUTER_API_KEY,
base_url="https://router.requesty.ai/v1",
default_headers={"Authorization": f"Bearer {ROUTER_API_KEY}"},
)
# Example request
response = client.chat.completions.create(
model="groq/openai/gpt-oss-120b",
messages=[{"role": "user", "content": "Hello, who are you?"}],
)
# Print the result
print(response.choices[0].message.content)After a long wait, OpenAI has finally released an open-source LLM. This means you can now fine-tune it, run it locally, and have full control over its output generation. You are in charge; you can even build products around it without sharing your data with OpenAI or paying for API access.
This is a big step forward for AI, and over time, we will see new and improved models built on top of OpenAI’s open-source models and frameworks. If you want to start experimenting now, you can:
If you’re just starting out with your AI journey, be sure to check out our AI Fundamentals skill track to cover topics including LLMs, ChatGPT, generative AI, AI ethics, and prompt engineering.
Top AI Courses
Track
Course
Course
blog
Abid Ali Awan
9 min
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
blog
Richie Cotton
8 min
Tutorial
Aashi Dutt
code-along
Dave Wentzel




