
programa
Fundamentos de la IA
10 h
HumanEval es un conjunto de datos de referencia desarrollado por OpenAI que evalúa el rendimiento de los grandes modelos lingüísticos (LLM) en tareas de generación de código. Se ha convertido en una herramienta importante para evaluar las capacidades de los modelos de IA en la comprensión y generación de código.
En este tutorial, aprenderemos sobre HumanEval y la métrica pass@k. Además, evaluaremos la capacidad de generación de código del modelo codeparrot-small en 164 problemas.
Para el proceso de evaluación HumanEval, utilizaremos el método Cara Abrazada para cargar el conjunto de datos, el modelo y las métricas necesarias. Si eres relativamente nuevo en el mundo de los LLM y todo lo que pueden conseguir, echa un vistazo a nuestro curso Curso de desarrollo de grandes modelos lingüísticos.

Imagen del autor
HumanEval fue desarrollado por OpenAI como un conjunto de datos de evaluación diseñado específicamente para grandes modelos lingüísticos. Sirve como punto de referencia para evaluar los LLM en tareas de generación de código, centrándose en la capacidad de los modelos para comprender el lenguaje, razonar y resolver problemas relacionados con algoritmos y matemáticas sencillas.
El conjunto de datos consta de 164 problemas de programación escritos a mano, cada uno de los cuales incluye una firma de función, un docstring, un cuerpo y varias pruebas unitarias, con una media de 7,7 pruebas por problema.
En el siguiente ejemplo, clonaremos el repositorio de evaluación humana, instalaremos los paquetes Python necesarios y, a continuación, ejecutaremos la evaluación de la corrección funcional en el conjunto de datos de ejemplo.
$ git clone https://github.com/kingabzpro/human-eval
$ pip install -e human-eval
$ evaluate_functional_correctness data/example_samples.jsonl --problem_file=data/example_problem.jsonlObtenemos el resultado en términos de pass@k, y, en nuestro caso, pass@1. Esta métrica indica la tasa de éxito del 50% de un modelo en el primer intento. Conoceremos esta métrica en detalle en la siguiente sección.
Reading samples...
6it [00:00, 2465.79it/s]
Running test suites...
100%|█████████████████████████████████████████████| 6/6 [00:03<00:00, 1.97it/s]
Writing results to data/example_samples.jsonl_results.jsonl...
100%|██████████████████████████████████████████| 6/6 [00:00<00:00, 12035.31it/s]
{'pass@1': 0.4999999999999999}Lee la evaluación del LLM en: Métricas, Metodologías, Buenas Prácticas blog para aprender a evaluar los LLM utilizando métricas clave, metodologías y buenas prácticas para tomar decisiones informadas.
HumanEval es diferente de las métricas tradicionales basadas en las coincidencias. Utiliza un enfoque más práctico denominado "corrección funcional", que emplea la métrica pass@k para evaluar la probabilidad de que al menos una de las k mejores muestras de código generadas para un problema supere las pruebas unitarias.
Este cambio de la similitud textual a la corrección funcional proporciona una evaluación más significativa de la capacidad de un modelo para resolver retos de programación. Este proceso es similar a cómo los desarrolladores prueban su código mediante pruebas unitarias para evaluar su corrección.
A continuación podemos ver la fórmula matemática para calcular la métrica pass@k:
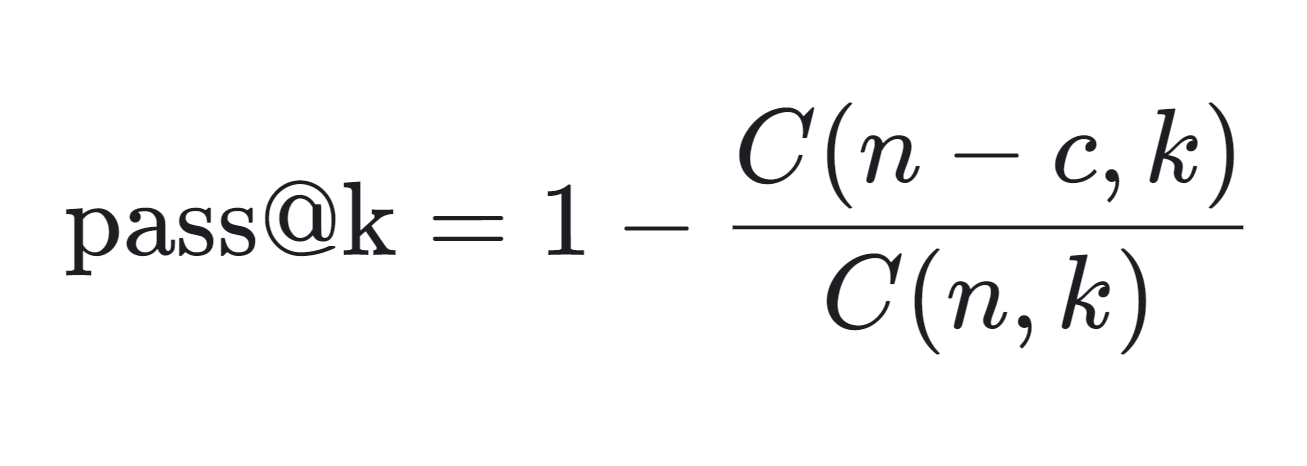
La métrica pass@k se calcula del siguiente modo:
La métrica pass@k es especialmente útil para evaluar el rendimiento práctico de los modelos de generación de código, ya que refleja la probabilidad de generar una solución correcta en un número limitado de intentos.
La métrica se utiliza mucho en entornos competitivos, como las tablas de clasificación alojadas en Papeles con Códigodonde los modelos se clasifican en función de sus puntuaciones pass@k, incluyendo pass@10 y pass@100.
HumanEval garantiza que el código generado es sintácticamente correcto y funcionalmente eficaz.
En este proyecto, cargaremos el OpenAI HumanEval y ejecutaremos la evaluación de la corrección funcional en el conjunto de datos codeparrot/codeparrot-pequeño.
Estamos seleccionando un modelo de generación de código más pequeño para acelerar el tiempo de evaluación, ya que vamos a ejecutar varios bucles: bucle externo 164 (Número de problemas) y bucle interno 5 (número de muestras generadas para un solo problema).
Empezaremos instalando el programa Evalúa Python Library de Hugging Face. Evaluate es una potente biblioteca que te permite evaluar fácilmente modelos de aprendizaje automático y conjuntos de datos de diversos dominios con una sola línea de código, garantizando la coherencia y la reproducibilidad, ya sea en máquinas locales o en configuraciones de entrenamiento distribuidas.
%%capture
%pip install evaluateAdemás, configura una variable de entorno que nos permita ejecutar la evaluación del modelo.
import os
os.environ["HF_ALLOW_CODE_EVAL"] = "1"
os.environ["TOKENIZERS_PARALLELISM"] = "false"Cargaremos el conjunto de datos openai_humaneval de Cara Abrazada. Este conjunto de datos contiene 164 problemas de programación en Python e incluye texto natural en inglés encontrado en comentarios y docstrings.
También cargaremos la métrica de evaluación code_eval, que nos permitirá ejecutar la prueba comparativa HumanEval.
from datasets import load_dataset
from evaluate import load
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from tqdm import tqdm
# Load HumanEval dataset
human_eval = load_dataset("openai_humaneval")['test']
# Load code evaluation metric
code_eval_metric = load("code_eval")Carga el modelo CodeParrot y el tokenizador del Hub Cara Abrazada. CodeParrot es un modelo basado en GPT-2 con 110 millones de parámetros que han sido entrenados específicamente para generar código Python.
# Specify the model name or path
model_name = "codeparrot/codeparrot-small"
# Load the model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
model.eval()Establece pad_token_id y pad_token_id y cambia el tamaño de las incrustaciones del modelo si se añaden los nuevos tokens.
# Set pad_token_id and pad_token_id if not already set
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = 0 # Commonly used pad token ID
if tokenizer.eos_token_id is None:
tokenizer.eos_token_id = 2 # Commonly used eos token ID for Llama
# Ensure the tokenizer has the pad and eos tokens
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({'pad_token': '<pad>'})
if tokenizer.eos_token is None:
tokenizer.add_special_tokens({'eos_token': '</s>'})
# Resize model embeddings if new tokens were added
if len(tokenizer) > model.config.vocab_size:
model.resize_token_embeddings(len(tokenizer))Esta es la sección principal donde ocurre la magia. Ejecutaremos HumanEval para cinco muestras por problema, con un total de 164 problemas para evaluar. El bucle externo extraerá la pregunta y la prueba del conjunto de datos. Utilizando el indicador, generará cinco muestras diferentes para el mismo problema.
Al final de este proceso, tendremos dos listas: test_cases y candidates.
Esta configuración permite evaluar y comparar exhaustivamente las soluciones generadas con los casos de prueba.
# Set the number of candidates per problem
num_samples_per_problem = 5 # Adjust as needed for pass@k computation
# Lists to store test cases and predictions
test_cases = []
candidates = []
# Create a progress bar for the outer loop (problems)
print("Generating code solutions...")
for problem in tqdm(human_eval, desc="Problems", unit="problem"):
prompt = problem['prompt']
test_code = problem['test']
# Store the test cases
test_cases.append(test_code)
# Generate multiple candidate solutions for each problem
problem_candidates = []
# Create a progress bar for the inner loop (samples per problem)
for _ in range(num_samples_per_problem):
# Encode the prompt and get attention mask
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# Generate code with attention mask and proper token IDs
with torch.no_grad():
outputs = model.generate(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
max_length=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
num_return_sequences=1,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
generated_code = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Remove the prompt from the generated code
generated_code = generated_code[len(prompt):]
problem_candidates.append(generated_code)
# Add the candidates for the current problem
candidates.append(problem_candidates)
print("Code generation complete.")Salida:
Generating code solutions...
Problems: 100%|██████████| 164/164 [34:35<00:00, 12.66s/problem]
Code generation complete.Ahora calcularemos el porcentaje de aprobados con distintos valores de k (1 y 5) para las muestras de código generadas, comparándolas con los casos de prueba de referencia, utilizando una métrica de evaluación pass@k, y luego obtendremos el porcentaje de aprobados para cada valor de k.
# Compute pass@k
k_values = [1, 5]
print("Evaluating generated code...")
pass_at_k, results = code_eval_metric.compute(
references=test_cases,
predictions=candidates,
k=k_values,
num_workers=4, # Adjust based on your system
timeout=10.0, # Adjust the timeout as needed
)
# Print the results
for k in k_values:
print(f"Pass@{k}: {pass_at_k[f'pass@{k}'] * 100:.2f}%")Los resultados muestran que el 27,07% de las muestras de código generadas superan los criterios de evaluación cuando se considera el candidato principal (Pass@1), mientras que el 65,85% los superan cuando se consideran los cinco candidatos principales (Pass@5). Este rendimiento se considera bueno, sobre todo porque estamos utilizando un modelo de lenguaje más pequeño para generar el código Python.
Sin embargo, si se compara con la GPT-4o, que tiene una tasa de Pass@1 del 90,2%, los resultados parecen ser deficientes.
Evaluating generated code...
Pass@1: 27.07%
Pass@5: 65.85%Si tienes problemas para ejecutar el código anterior, comprueba HumanEval con el cuaderno DeepEval cuaderno Kaggle.
También puedes aprender a agilizar tus evaluaciones LLM con MLflow siguiendo el Evaluación de LLMs con MLflow tutorial.
El conjunto de datos HumanEval es relativamente sencillo y puede que sólo represente parcialmente los retos de programación del mundo real. Además, preocupa el sobreajuste, ya que los modelos podrían entrenarse en conjuntos de datos similares, lo que podría mejorar el rendimiento en HumanEval específicamente.
Por lo tanto, al evaluar los modelos de grandes lenguajes (LLM) por sus capacidades de generación de código, es esencial tener en cuenta múltiples métricas de rendimiento, como MBPP (Mostly Basic Python Problems), ClassEval, DevQualityEval y otras.
Completa los Fundamentos de la IA y adquiere conocimientos prácticos sobre temas populares de IA como ChatGPT, grandes modelos de lenguaje, IA generativa y mucho más.
Los mejores cursos de IA
programa
programa
programa