
Lernpfad
Grundlagen der KI
10 Std.
HumanEval ist ein von OpenAI entwickelter Benchmark-Datensatz, der die Leistung von großen Sprachmodellen (LLMs) bei Codegenerierungsaufgaben bewertet. Sie hat sich zu einem wichtigen Werkzeug entwickelt, um die Fähigkeiten von KI-Modellen beim Verstehen und Generieren von Code zu bewerten.
In diesem Lernprogramm lernen wir HumanEval und die pass@k-Metrik kennen. Außerdem werden wir die Codegenerierungsfähigkeiten des codeparrot-small Modells anhand von 164 Problemen bewerten.
Für den HumanEval-Bewertungsprozess werden wir das Hugging Face Ökosystem, um den Datensatz, das Modell und die notwendigen Metriken zu laden. Wenn du relativ neu in der Welt der LLMs bist und wissen willst, was sie alles leisten können, dann schau dir unseren Kurs Große Sprachmodelle entwickeln.

Bild vom Autor
HumanEval wurde von OpenAI als Evaluierungsdatensatz speziell für große Sprachmodelle entwickelt. Er dient als Referenzmaßstab für die Bewertung von LLMs bei Aufgaben zur Codegenerierung und konzentriert sich auf die Fähigkeit der Modelle, Sprache zu verstehen, zu argumentieren und Probleme im Zusammenhang mit Algorithmen und einfacher Mathematik zu lösen.
Der Datensatz besteht aus 164 handgeschriebenen Programmierproblemen, die jeweils eine Funktionssignatur, einen Docstring, einen Body und mehrere Unit-Tests enthalten, mit durchschnittlich 7,7 Tests pro Problem.
Im folgenden Beispiel klonen wir das Repository für die menschliche Bewertung, installieren die erforderlichen Python-Pakete und führen dann die Bewertung der funktionalen Korrektheit mit dem Beispieldatensatz durch.
$ git clone https://github.com/kingabzpro/human-eval
$ pip install -e human-eval
$ evaluate_functional_correctness data/example_samples.jsonl --problem_file=data/example_problem.jsonlWir haben das Ergebnis in Form von pass@k und, in unserem Fall, pass@1. Diese Kennzahl gibt an, wie hoch die Erfolgsquote eines Modells beim ersten Versuch ist. Wir werden diese Metrik im nächsten Abschnitt genauer kennenlernen.
Reading samples...
6it [00:00, 2465.79it/s]
Running test suites...
100%|█████████████████████████████████████████████| 6/6 [00:03<00:00, 1.97it/s]
Writing results to data/example_samples.jsonl_results.jsonl...
100%|██████████████████████████████████████████| 6/6 [00:00<00:00, 12035.31it/s]
{'pass@1': 0.4999999999999999}Lies die LLM-Bewertung: Metriken, Methoden, Best Practices Blog, um zu erfahren, wie man LLMs anhand von Schlüsselmetriken, Methoden und Best Practices bewertet, um fundierte Entscheidungen zu treffen.
HumanEval unterscheidet sich von den traditionellen matchbasierten Metriken. Dabei wird ein praktischerer Ansatz verwendet, der als "funktionale Korrektheit" bezeichnet wird. Dabei wird die pass@k-Metrik verwendet, um die Wahrscheinlichkeit zu bewerten, dass mindestens eines der obersten k-generierten Codebeispiele für ein Problem die Unit-Tests besteht.
Diese Verlagerung von der Textähnlichkeit zur funktionalen Korrektheit ermöglicht eine aussagekräftigere Bewertung der Fähigkeit eines Modells, Programmieraufgaben zu lösen. Dieser Prozess ist vergleichbar mit der Art und Weise, wie Entwickler ihren Code durch Unit-Tests testen, um seine Korrektheit zu überprüfen.
Die mathematische Formel zur Berechnung der pass@k-Metrik findest du unten:
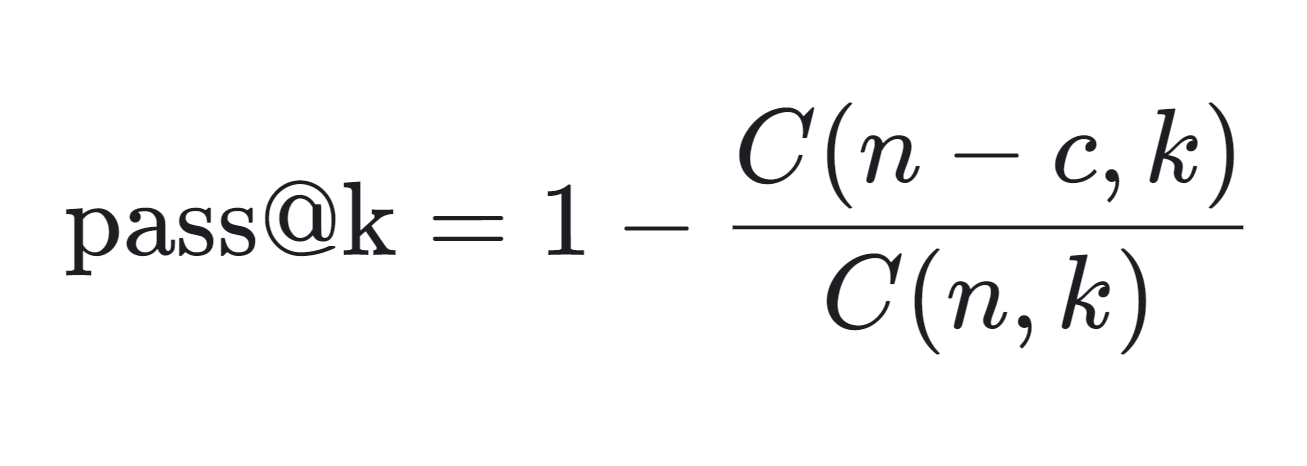
Die pass@k-Metrik wird wie folgt berechnet:
Die pass@k-Kennzahl ist besonders nützlich, um die praktische Leistung von Codegenerierungsmodellen zu bewerten, da sie die Wahrscheinlichkeit widerspiegelt, innerhalb einer begrenzten Anzahl von Versuchen eine richtige Lösung zu generieren.
Die Metrik wird häufig in Wettbewerbsumgebungen verwendet, z. B. in Ranglisten, die von Papers with Codewo die Modelle anhand ihrer pass@k-Punkte, einschließlich pass@10 und pass@100, eingestuft werden.
HumanEval stellt sicher, dass der generierte Code syntaktisch korrekt und funktional wirksam ist.
In diesem Projekt werden wir die OpenAI HumanEval Datensatz und führen die Bewertung der funktionalen Korrektheit auf der codeparrot/codeparrot-small.
Wir wählen ein kleineres Modell für die Codegenerierung, um die Auswertungszeit zu verkürzen, da wir mehrere Schleifen laufen lassen: die äußere Schleife 164 (Anzahl der Probleme) und die innere Schleife 5 (Anzahl der für ein einzelnes Problem generierten Proben).
Wir beginnen mit der Installation der Evaluate Python-Bibliothek von Hugging Face. Evaluate ist eine leistungsstarke Bibliothek, mit der du Machine-Learning-Modelle und -Datensätze in verschiedenen Bereichen mit einer einzigen Codezeile auswerten kannst, um Konsistenz und Reproduzierbarkeit zu gewährleisten, egal ob auf lokalen Rechnern oder in verteilten Trainingssystemen.
%%capture
%pip install evaluateRichte außerdem eine Umgebungsvariable ein, mit der wir die Modellevaluation durchführen können.
import os
os.environ["HF_ALLOW_CODE_EVAL"] = "1"
os.environ["TOKENIZERS_PARALLELISM"] = "false"Wir laden den Datensatz openai_humaneval von Hugging Face. Dieser Datensatz enthält 164 Python-Programmierprobleme mit natürlichem englischen Text in Kommentaren und Docstrings.
Außerdem laden wir die Bewertungsmetrik code_eval, damit wir den HumanEval-Benchmark durchführen können.
from datasets import load_dataset
from evaluate import load
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from tqdm import tqdm
# Load HumanEval dataset
human_eval = load_dataset("openai_humaneval")['test']
# Load code evaluation metric
code_eval_metric = load("code_eval")Lade das CodeParrot-Modell und den Tokenizer aus dem Hugging Face Hub. CodeParrot ist ein GPT-2-basiertes Modell mit 110 Millionen Parametern, das speziell für die Erstellung von Python-Code trainiert wurde.
# Specify the model name or path
model_name = "codeparrot/codeparrot-small"
# Load the model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
model.eval()Setze die pad_token_id und pad_token_id und ändere die Größe der Modelleinbettungen, wenn die neuen Token hinzugefügt werden.
# Set pad_token_id and pad_token_id if not already set
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = 0 # Commonly used pad token ID
if tokenizer.eos_token_id is None:
tokenizer.eos_token_id = 2 # Commonly used eos token ID for Llama
# Ensure the tokenizer has the pad and eos tokens
if tokenizer.pad_token is None:
tokenizer.add_special_tokens({'pad_token': '<pad>'})
if tokenizer.eos_token is None:
tokenizer.add_special_tokens({'eos_token': '</s>'})
# Resize model embeddings if new tokens were added
if len(tokenizer) > model.config.vocab_size:
model.resize_token_embeddings(len(tokenizer))Dies ist der Hauptteil, in dem die Magie passiert. Wir lassen HumanEval für fünf Stichproben pro Problem laufen, so dass wir insgesamt 164 Probleme auswerten können. Die äußere Schleife extrahiert die Aufforderung und den Test aus dem Datensatz. Mit der Eingabeaufforderung werden fünf verschiedene Proben für dasselbe Problem erstellt.
Am Ende dieses Prozesses werden wir zwei Listen haben: test_cases und candidates.
Dieser Aufbau ermöglicht eine umfassende Bewertung und einen Vergleich der generierten Lösungen mit den Testfällen.
# Set the number of candidates per problem
num_samples_per_problem = 5 # Adjust as needed for pass@k computation
# Lists to store test cases and predictions
test_cases = []
candidates = []
# Create a progress bar for the outer loop (problems)
print("Generating code solutions...")
for problem in tqdm(human_eval, desc="Problems", unit="problem"):
prompt = problem['prompt']
test_code = problem['test']
# Store the test cases
test_cases.append(test_code)
# Generate multiple candidate solutions for each problem
problem_candidates = []
# Create a progress bar for the inner loop (samples per problem)
for _ in range(num_samples_per_problem):
# Encode the prompt and get attention mask
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# Generate code with attention mask and proper token IDs
with torch.no_grad():
outputs = model.generate(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
max_length=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
num_return_sequences=1,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
generated_code = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Remove the prompt from the generated code
generated_code = generated_code[len(prompt):]
problem_candidates.append(generated_code)
# Add the candidates for the current problem
candidates.append(problem_candidates)
print("Code generation complete.")Ausgabe:
Generating code solutions...
Problems: 100%|██████████| 164/164 [34:35<00:00, 12.66s/problem]
Code generation complete.Jetzt berechnen wir die Erfolgsquote bei verschiedenen Werten von k (1 und 5) für die generierten Codebeispiele, indem wir sie mit Referenztestfällen vergleichen, indem wir eine pass@k-Bewertungsmetrik verwenden, und geben dann die Erfolgsquote als Prozentsatz für jeden k -Wert aus.
# Compute pass@k
k_values = [1, 5]
print("Evaluating generated code...")
pass_at_k, results = code_eval_metric.compute(
references=test_cases,
predictions=candidates,
k=k_values,
num_workers=4, # Adjust based on your system
timeout=10.0, # Adjust the timeout as needed
)
# Print the results
for k in k_values:
print(f"Pass@{k}: {pass_at_k[f'pass@{k}'] * 100:.2f}%")Die Ergebnisse zeigen, dass 27,07 % der generierten Codebeispiele die Bewertungskriterien erfüllen, wenn der Top-Kandidat (Pass@1) berücksichtigt wird, während 65,85 % die Kriterien erfüllen, wenn die fünf Top-Kandidaten (Pass@5) berücksichtigt werden. Diese Leistung wird als gut angesehen, vor allem weil wir ein kleineres Sprachmodell verwenden, um den Python-Code zu erzeugen.
Im Vergleich zu GPT-4o, das eine Pass@1-Rate von 90,2 % hat, scheinen die Ergebnisse jedoch mangelhaft zu sein.
Evaluating generated code...
Pass@1: 27.07%
Pass@5: 65.85%Wenn du Probleme hast, den obigen Code auszuführen, überprüfe bitte HumanEval mit dem DeepEval Kaggle-Notizbuch.
Du kannst auch lernen, wie du deine LLM-Bewertungen mit MLflow rationalisieren kannst, indem du die LLMs mit MLflow auswerten Tutorial.
Der HumanEval-Datensatz ist relativ einfach und repräsentiert die realen Programmierherausforderungen nur teilweise. Außerdem gibt es Bedenken wegen der Überanpassung, da die Modelle auf ähnlichen Datensätzen trainiert werden könnten, was speziell bei HumanEval zu einer besseren Leistung führen könnte.
Bei der Bewertung von großen Sprachmodellen (LLMs) für die Codegenerierung ist es daher wichtig, mehrere Leistungsmetriken wie MBPP (Mostly Basic Python Problems), ClassEval, DevQualityEval und andere zu berücksichtigen.
Schließe die KI-Grundlagen und gewinne umsetzbares Wissen über beliebte KI-Themen wie chatGPT, große Sprachmodelle, generative KI und mehr.
Top KI-Kurse
Lernpfad
Lernpfad
Lernpfad
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
